1 로지스틱 회귀
1-1 데이터 만들기, 기존에 했던 kNN 통한 분류
- 럭키백?
- 목표: 높이, 깊이, 대각선 길이, 두께로 몸무게 예측하기.
#데이터 호출
fish = pd.read_csv('~~')
# 값 확인
print(pd.unique(fish['Species']))
#input 데이터와 target 데이터 둘 다 numpy 배열로
fish_input = \
fish[['Weight', 'Length', 'Diagonal', 'Height', 'Width']].to_numpy()
fish_target = fish['Species'].to_numpy()
#train, test 만들기
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(
fish_input, fish_target, random_state=42)
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)StandardScalar는 (원값-평균)/표준편차 로 표준화하는 과정. 인스턴트 생성, fit(train_input)으로 피팅, transform()으로 표준화.- 왜 fit은 train하나로만 하고, tranform은 2개로 나눠서 하는가?
- fit(train_input)으로 train_input의 평균과 표준편차를 계산하고 저장한다. 이렇게 훈련 데이터에 대해서만 fit을 적용. => 여기서 모델이 train 과정에서 사용한 같은 평균과 표준편차를 테스트 데이터에도 적용해서 표준화한다. 모델의 일반화 능력을 테스트할 때 동일한 기준으로 데이터 처리하기 위해.
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier(n_neighbors=3)
kn.fit(train_scaled, train_target)
print(kn.score(train_scaled, train_target))
print(kn.score(test_scaled, test_target))
kn.classes_
kn.predict(test_scaled[:5])
import numpy as np
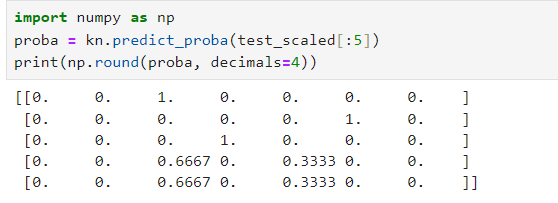
proba = kn.predict_proba(test_scaled[:5])
print(np.round(proba, decimals=4))
distances, indexes = kn.kneighbors(test_scaled[3:4])
train_target[indexes]- kNN 분류 모델을 훈련하고 평가하는 과정.
- 인스턴트 생성, 이때 k=3으로.
- fit으로 train 데이터를 train.
- score로 train데이터와 test 데이터를 각각 실험.
-.classes_속성은 분류기가 학습한 클래스 레이블의 배열을 반환. => 올바르게 됐는지 확인.
- predict로 예상한 결과의 앞 5개를 확인.
-predict_proba는 주어진 입력 데이터에 대해 각 클래스에 속할 확률을 예측해서 반환. 로지스틱 회귀, kNN, Random Forest, Gradient Boosting 같은 알고리즘에 사용. 여기선 총 7개의 분류 기준에 대해 각각의 클래스에 속할 확률을 반환. =>np.round(proba, decimals=4))로 결과를 소수점 넷째 자리까지 반올림하여 출력.

kn.kneighbors()는 주어진 데이터 포인트에서 가장 가까운 이웃을 찾아서, 그 이웃과의 거리(distances)와 훈련 세트 내세어의 인덱스를 반환한다.
1-2 로지스틱 회귀 - 이진 분류
- 로지스틱 회귀(Logistic Regression)은 분류 문제에 사용되는 통계적 모델. 회귀처럼 보이지만, 주로 이진 분류 문제에 적용되어, 결과를 0과 1 사이의 확률로 예측. 따라서 종속 변수가 범주형 데이터일 때 사용.
- 선형 회귀의 출력을 로지스틱(시그모이드) 함수를 통해 0과 1 사이의 값으로 변환. => 이 변환된 값은 특정 클래스에 속할 확률을 나타낸다.

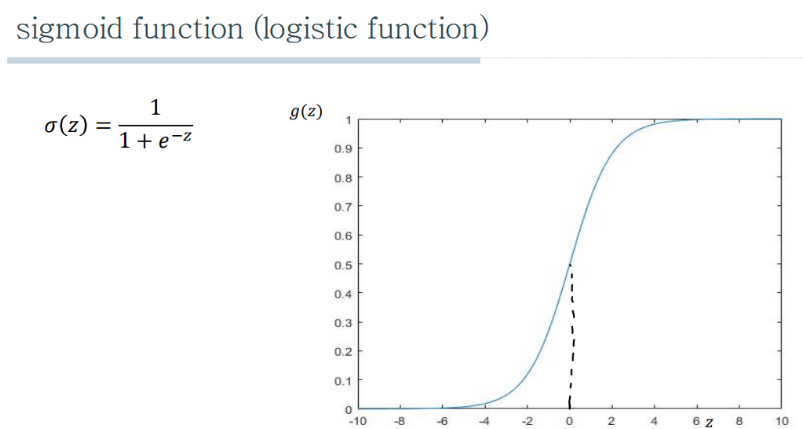
- 여기서 z는 선형 회귀 모델의 출력으로 가중치가 적용된 특성들의 합. z값이 높아질수록 함수값은 1에 가까워지고, z값이 낮아질수록 0에 가까워진다.
- 시그모이드 함수: 0과 1 사이의 확률을 출력하기 위해 선형 회귀 결과를 시그모이드 함수를 통해 변환.
- 확률적 해석: 로지스틱 회귀의 출력을 특정 클래스에 속할 확률로 해석 가능 => 이를 통해 분류 결정을 내린다. 보통 0.5 이상을 한 클래스를, 미만을 다른 클래스로 분류.
- 손실 함수: 로지스틱 회귀는 손실 함수로 로그 손실 또는 교차 엔트로피를 사용. 이 손실 함수를 최소화하는 방향으로 파라미터 학습한다.
- 규제: 과적합 방지하기 위해 L1, L2 같은 규제 사용 가능.
- 로지스틱 회귀 그림으로 보기.
import numpy as np
import matplotlib.pyplot as plt
z = np.arange(-5, 5, 0.1)
phi = 1/(1+np.exp(-z))
plt.plot(z, phi)
plt.xlabel('z')
plt.ylabel('phi')
plt.show()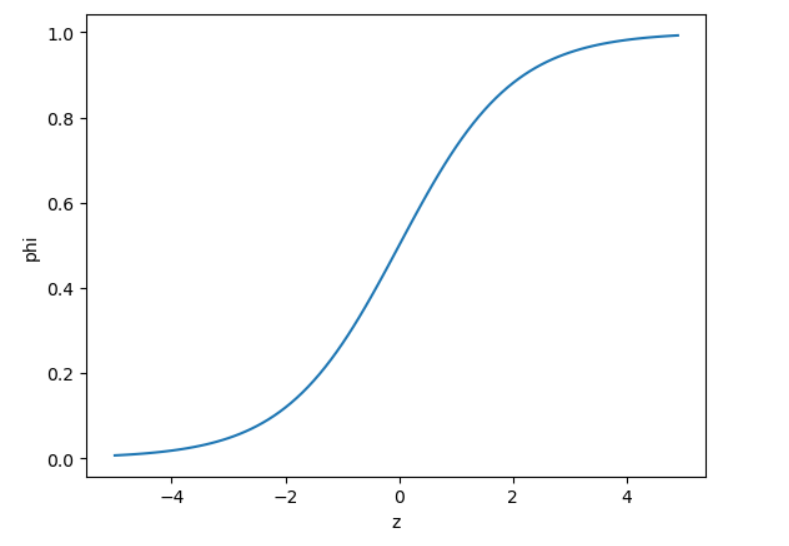
bream_smelt_indexes = \
(train_target == 'Bream') | (train_target == 'Smelt')
train_bream_smelt = train_scaled[bream_smelt_indexes]
target_bream_smelt = train_target[bream_smelt_indexes]
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_bream_smelt, target_bream_smelt)
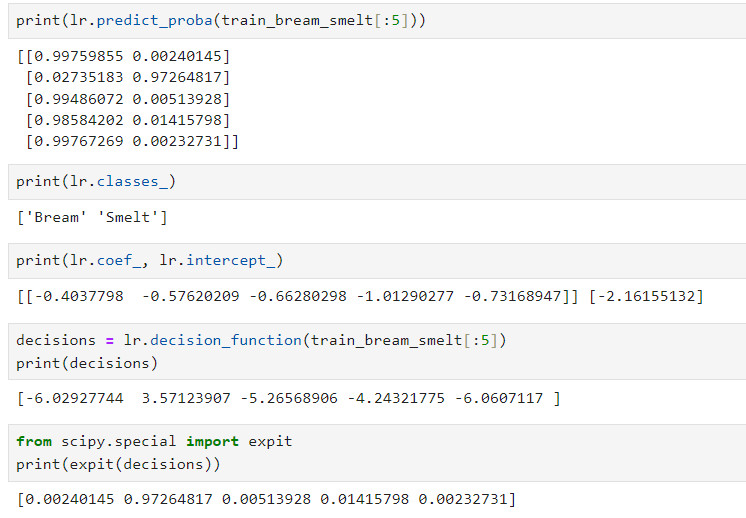
print(lr.predict(train_bream_smelt[:5]))
print(lr.predict_proba(train_bream_smelt[:5]))
print(lr.classes_)
print(lr.coef_, lr.intercept_)
decisions = lr.decision_function(train_bream_smelt[:5])
print(decisions)
from scipy.special import expit
print(expit(decisions))- 이진 분류를 위해 Bream, Smelt의 불리언 배열로 인덱스만 뽑아낸다.
- 그리고 먼저 위에서 z로 표준화된 train_input을 train set으로, train_target을 train_target으로 해서 Bream, Smelt의 인덱스만 뽑아낸다.
LogisticRegression()으로 객체를 만들어서 똑같은 절차로, fit, precidt, predict_proba => lr.classes로 결과 확인
coef_와lr.intercept_는 학습된 모델의 계수(가중치)와 절편을 출력해서 확인.
(lr.coef, lr.intercept)에 대해 [[-0.4037798 -0.57620209 -0.66280298 -1.01290277 -0.73168947]][-2.16155132] 와 같은 입력값이 나왔다면 식은 아래와 같다. 아래의 설명처럼 이런 선형 방정식 z가 시그모이드 함수의 z부분에 속한다.

여기서의 X1~X5는 weight, length, diagonal, height, width.lr.decision_function은 로지스틱 회귀 모델이 내부적으로 계산하는 위의 선형 함수(z)의 결과값으로, 각 샘플이 특정 클래스에 속하는 점수(raw score). 여기서 양수는 양성 클래스(Beam)에 속할 거고, 음수는 (Smelt)에 속할 것. => 이를 시그모이드 함수의 입력값이 된다.expit()는 시그모이드 함수 구현. decision_function의 값을 시그모이드 함수에 적용해서 확률로 변환. 이는predict_proba메서드가 내부적으로 수행하는 작업과 같으며, 해당 샘플이 양성 클래스(여기서는 'Beam')에 속할 확률을 출력. => 실제로 보면 위에서 predict_proba로 나온 값 중 뒤의 값과 같다.
1-3 로지스틱 회귀 - 다중 분류
- 다중 분류할 때의 차이는, 이진분류는 시그모이드 함수 사용, 다중분류는 softmax 함수 사용. 그거 말고는 큰 절차에서 똑같다.
- softmax 함수는 로지스틱 회귀, 신경망이 다중 클래스 분류 문제 다룰 때 사용하는 함수. 각 클래스에 대한 원시 점수(raw score)를 정규화해 각 클래스에 속할 확률 출력. 출력된 확률은 모두 더하면 1이 되어야 하므로, 이런 제약을 만족하도록 설계.

lr = LogisticRegression(C=20, max_iter = 1000)
lr.fit(train_scaled, train_target)
print(lr.score(train_scaled, train_target))
print(lr.score(test_scaled, test_target))
print(lr.predict(test_scaled[:5]))
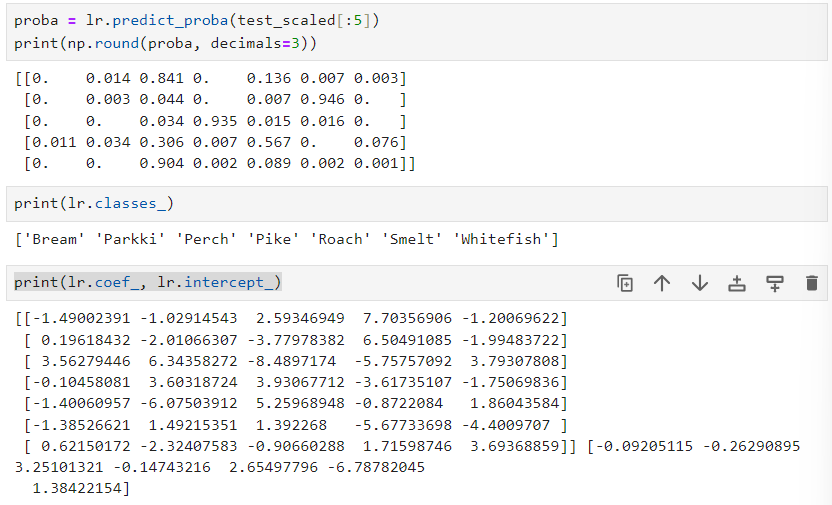
proba = lr.predict_proba(test_scaled[:5])
print(np.round(proba, decimals=3))
print(lr.classes_)
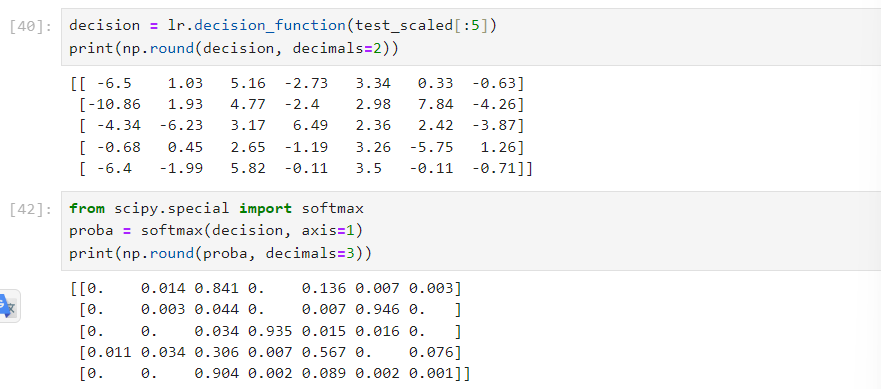
decision = lr.decision_function(test_scaled[:5])
print(np.round(decision, decimals=2))
from scipy.special import softmax
proba = softmax(decision, axis=1)
print(np.round(proba, decimals=3))LogisticRegression(C=20, max_iter = 1000): 위의 이진 분류와 같지만,
C=20은 규제(regularization) 강도의 역수. 규제는 모델의 복잡도를 제한하고 과적합을 방지하는데 사용. C값이 낮을수록 규제가 강해지고, C값이 높을수록 규제가 약해진다.
max_iter=1000은 최적의 모델 파라미터를 찾기 위한 최적화 과정에서 수행되는 반복의 최대 횟수. 로지스틱 회귀는 주로 경사 하강법(Gradient Descent) 또는 그와 유사한 알고리즘 사용. max_iter은 알고리즘이 수렴(convergence)하기 전에 허용되는 반복의 최대 횟수 지정. => 반복이 너무 낮으면 모델이 충분히 수렴 못하고, 반복이 너무 높으면 불필요하게 계산을 많이 사용.- 여기서는 총 7개의 클래스로 분류를 하고, 그래서 predict_proba를 하면 아래와 같이 7개에 대한 각각의 확률이 나온다.
- 그리고 이진 분류와 마찬가지로 decision_function을 통해 z스코어를 구하고, 위의 expit(시그모이드 함수) 대신 softmax를 사용해서 구하면 => 같은 결과가 나온다. (즉, predict를 했을 때 내부에서 이런 과정을 거친다)
- 하나씩 이해를 해보면,
coef_와intercept_는 각 클래스에 대한 회귀 계수와 절편을 담고 있다. 즉, 아래와 같이 각 클래스가 될 확률에 대한 선형 회귀 함수 z가 아래와 같다.

- 즉, 첫 번째 클래스(0번째 인덱스)가 될 확률은 아래와 같다.
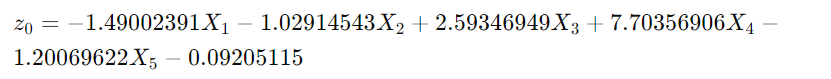
- 이를 softmax 함수의 zi에 넣어서 원시 점수를 계산한다.
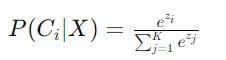
lr.decision_function는 위의 zi식에 값을 실제로 입력해서 구한 원시 점수.softmax()로 softmax에 위의 원시 스코어를 넣으면 predict_proba와 같은 결과가 나온다. 여기서 axis=1은 함수가 데이터의 각 행(row)에 대해 동작하도록 지시. 각 행에 대해 독립적으로 소프트 맥스 함수를 적용.
즉, 다중 클래스 분류에서 각 샘플(행)이 여러 클래스(열)에 대한 점수를 가지므로.

일본에서 일하는 게임 기획자. 시시해서 죽어버리지 않게, 재밌고 의미 있는 컨텐츠에 관심 있습니다. 그 도구로 데이터, AI도 찝적댑니다.