Machine Learning 기초 강의 정리
1.[Basic] 머신러닝 기본 - 분류, kNN
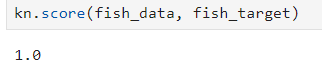
1 기본 개념 1-1 Scikit-learn 다양한 머신러닝 알고리즘 지원(분류, 회귀, 군집화 등). 데이터 마이닝, 데이터 분석 도구. Numpy와 SciPy 라이브러리 위에 구축되어 있음. 1-2 머신러닝 종류 지도학습(Supervised learning) 분류(Classification) 회귀(Regression) 비지도학습(Unsuper...
2.[Basic] Regression - kNN, Linear, 다항회귀, 다중회귀, 과적합과 규제, Ridge, Lasso

train set으로 나온 예측이 일반적으로 test set으로 한 예측보다 좋은 값이 나온다. 이 차이가 적을수록 좋은 모델. 1 kNN Regression 이건 reshape 하기 전의 결과로, 1차원 배열이다. 이건 reshape 한 후의 결과로, 2차원 배열이다. 이유를 설명. 일단 에 넣은 데이터가 각각 perchlength(X), perc...
3.[Basic] 로지스틱 회귀
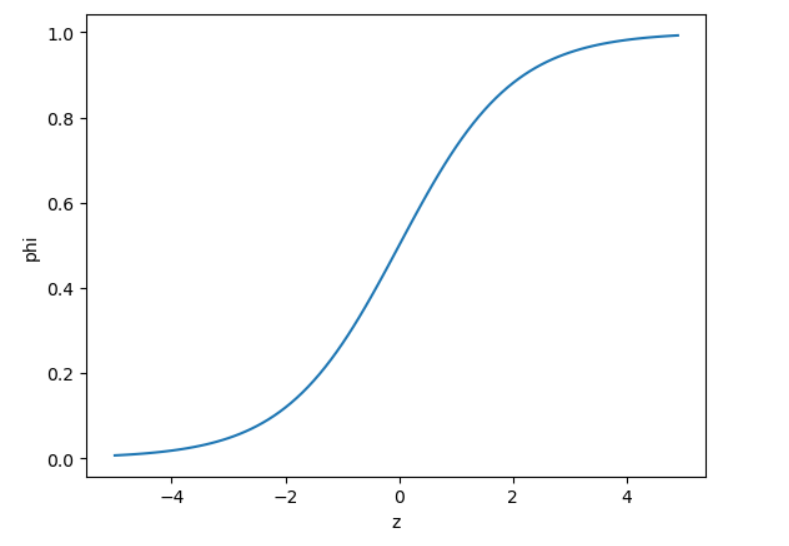
1 로지스틱 회귀 1-1 데이터 만들기, 기존에 했던 kNN 통한 분류 럭키백? 목표: 높이, 깊이, 대각선 길이, 두께로 몸무게 예측하기. 는 (원값-평균)/표준편차 로 표준화하는 과정. 인스턴트 생성, fit(train_input)으로 피팅, transform()으로 표준화. 왜 fit은 train하나로만 하고, tranform은 2개로 나눠서 하는가...
4.[Basic] 확률적 경사 하강법
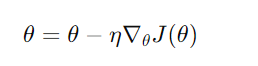
1 확률적 경사 하강법(Stochastic Gradient Descent, SGD) 최적화 문제, 특히 대규모 데이터셋에 대한 머신 러닝 모델의 파라미터를 학습할 때 널리 사용되는 방법. 비용 함수의 경사(기울기)를 사용해서 파라미터를 업데이트 하는 방식으로 모델을 최
5.[Basic] SVM
1 SVM(서포트 벡터 머신) 다른 방법들은 일반적으로 error를 최소화. 하지만 SVM은 마진(margin, 여백)을 최대화한다. 주어진 데이터를 이진 분류한다고 하면, 각 데이터를 고차원 공간에 매핑하고, 주어진 데이터가 어느 카테고리에 속하는지 판단하는 모델을
6.[Basic] Decision Tree(결정 트리), 교차 검증(Cross-validation)
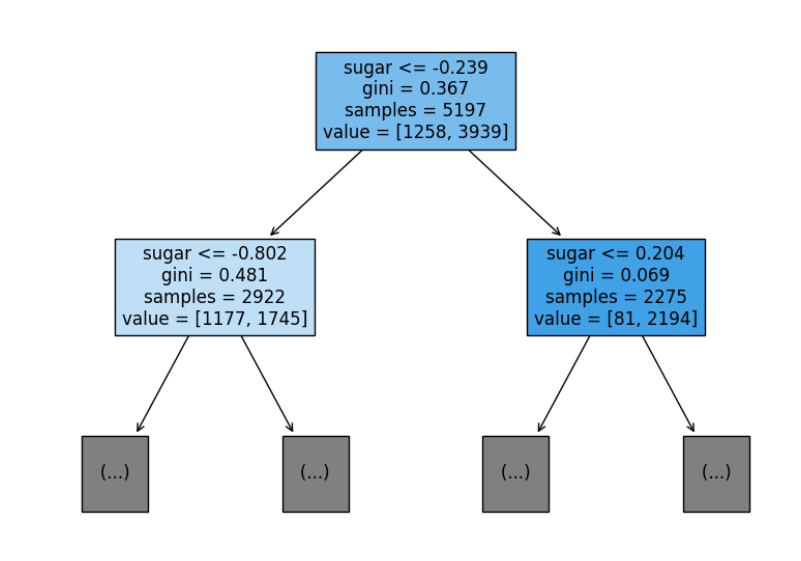
1 Decision Tree 결정트리 분류와 회귀 문제에 사용되는 머신러닝 알고리즘. 데이터를 분석해 데이터 사이 패턴을 학습, 데이터를 가장 잘 구분할 수 있는 특정 기준(질문)에 따라 데이터를 구분하는 걸 반복하는 모델. 한 번의 분기 때마다 변수 영역을 2개로 분리. 분할 기준은 정보 이득(Information Gain), 지니 불순도(Gini Imp...
7.[Basic] 머신러닝 성능값(f1, 오차행렬 등등) + 당뇨병, 자전거 문제

위에서 보면, load_digits는 데이터는 0부터 9까지의 손으로 쓴 숫자 이미지 digits는 딕셔너리 형태고, 거기서 digits.target은 거기서 타겟(즉, 레이블)로 [0~9]로 된 1차원 넘파이 배열. y는 그 중에 ==9로 조건을 걸어서, 9만 True인 불리언 배열. : 실제로 학습 안하고, 단순한 규칙이나 통계 기반으로 예측하는 분류...
8.[Basic] TF-IDF

0 설정 1 TF-IDF TF-IDF(Term Frequency-Inverse Document Frequency): 정보 검색과 텍스트 마이닝에서 널리 사용되는 특성 추출 기법. 각 단어의 중요성을 수치적으로 평가해서 텍스트 특징 나타낸다. TF는 하나의 문서 내의
9.[Basic] 추천 시스템 - 영화 추천
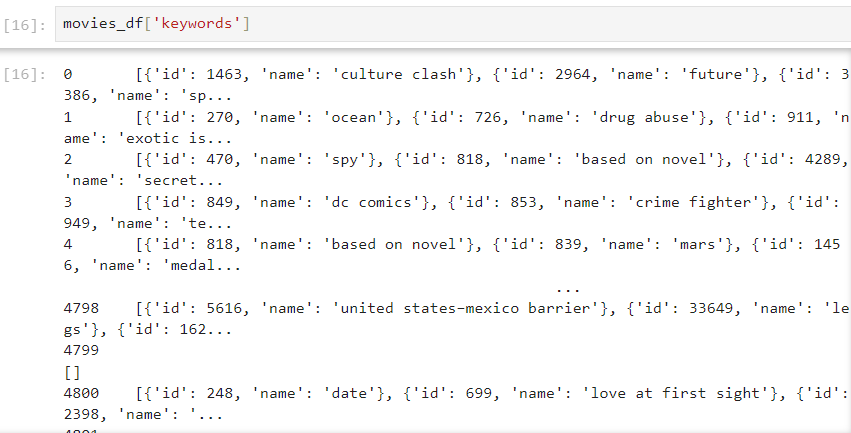
1 장르나 키워드 유사한 영화들 추천 데이터 불러오고 => 필요한 열만 추출 : DataFrame의 출력 옵션 제어. 표시되는 텍스트 열의 최대 너비를 지정. 그 이상은 줄임표로 표시. : 표시되는 최대 행 : 표시되는 최대 열 : 실수 표시할 때 소수점 이하 자릿수 지정 : 문자열을 파이썬 객체로 안전하게 변환해주는 함수. 예를...
10.[Basic] 군집 알고리즘 - Kmeans
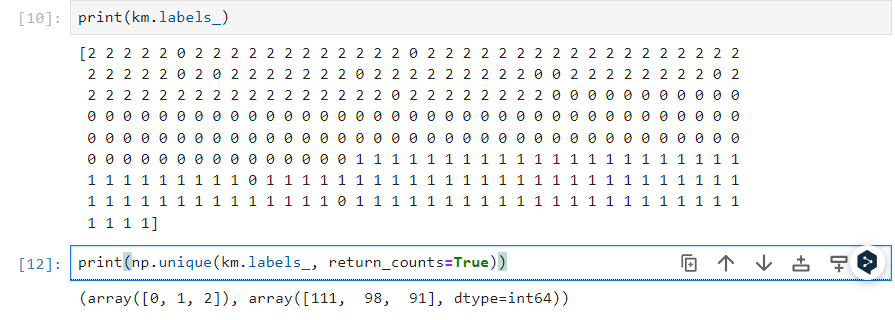
0 군집 알고리즘 군집 알고리즘(Clustering Algorithm)은 비지도 학습(Unsupervised learning)의 한 종류로, 데이터를 서로 유사한 그룹 또는 클러스터로 그룹화하는 알고리즘. 데이터를 자동으로 그룹화해 패턴이나 특징을 발견하고 이해. K-means 계층적 클러스터링 DBSCAN Mean Shift 클러스...
11.[Basic] PCA 분석
PCA(Principal Component Analysis) 분석(주성분 분석)은 다차원 데이터를 저차원 공간으로 차원 축소하는 기법. 데이터 분산을 최대한 보존하면서 차원 축소해서 데이터 시각화, 압축, 노이즈 제거 등의 목적으로 활용. 주성분을 찾아내고 이를 이용해
12.[문제] 뉴스 주제로 분류

1 새 문제 이걸 텍스트 정규화 => 피처 벡터화 => 머신러닝 적용 => 파이프라인 적용 => GridSearchCV로 최적화를 진행할 것. 자연어를 분류하는 문제를 위해, TF-IDF나 CountVectorizer로 단어의 등장 빈도나 중요성을 벡터로 표현해야지, 머신러닝을 돌릴 수 있다. 1-1 데이터 들고오기 188846개 뉴스 문서를 20개 뉴스...
13.[추가] VS studio와 steamlit
1 steamlit 데이터 과학 및 머신러닝 웹 애플리케이션 빠르게 구축하는 라이브러리. 웹 개발 할 줄 모른 채 간단한 python 스크립트로 대화형 웹 앱 만들 수 있다. 2 과정 visual studio coide, anaconda 설치 C/사용자에 Streamlit이라는 폴더 만들기 visual studio에서 파이썬 앱 설치 visual stud...