1 깔끔한 데이터란
- 1 행은 관측값을 나타내야 한다
- 2 열은 변수를 나타내야 한다
- 3 관측 단위별로 데이터표를 구성해야 한다
2 melt 메서드
df.melt() pd.melt(df): 데이터프레임 재구조화하는 함수. 가로로 긴 데이터를 세로로 긴 데이터로 변환한다.
- 매개변수
id_vars: 유지할 열 이름. 재구조화해도 이건 열로 그대로 남아있다. 여러 개면 리스트로 전달.value_vars: 긴 형식으로 변환될 열 지정.var_name: 긴 형식으로 변환되는 열의 이름. 기본값은 variable.value_name: 긴 형식으로 변환되는 값열의 이름. 기본값은 value.col_level: 컬럼명이 멀티 인덱스일 때, 변수이름이 저장되어 있는 레벨 지정.
2-1 열에 값이 포함되어 있는 경우
- 예를 들면, 빌보드에서 노래가 연도별 몇 주차 몇 등이었는지 데이터. 열에 wk1, wk2처럼 주차가 있을 경우.
다른 예로, 종교별 수입을 파악할 때, 수입이 0~2500, 2500~5000 처럼 열에 값이 저장된 경우.
pew_long = pew.melt(id_vars='religion')=> var_name, value_name 지정 안한 경우.
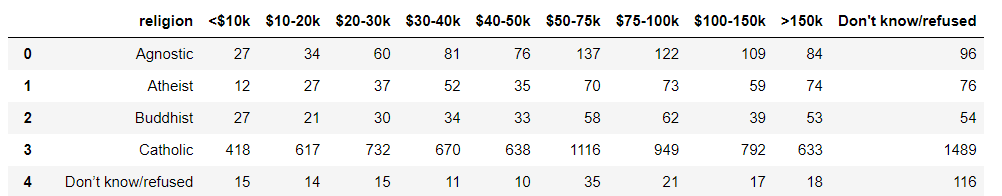
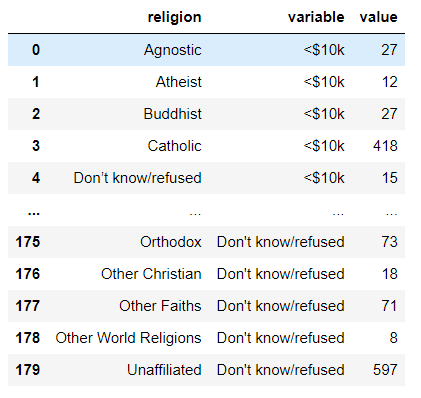
- 이렇게 기존의 열을 variable에, 그에 해당하는 값을 value에 집어넣어서 세로로 쭉 길게.
예시) 4개의 열을 고정, 나머지는 week, rating이라는 열로 바꾸기
billboard_long = billboard.melt(
id_vars=['year','artist', 'track', 'time','date.entered'],
var_name = 'week',
value_name = 'rating')2-2 한 열에 여러 정보가 섞인 경우
- 예를 들면, 나라별 에볼라 환자수와 사망자수가 Cases_Guinea, Death_Guinea처럼 열 별로 있을 때.
ebola_long = ebola.melt(id_vars=['Date', 'Day'])
variable_split = ebola_long.variable.str.split('_')
#분할한 문자열 리스트의 각 값에 접근하려면 get() 메서드를 사용
#인덱스 번호로 접근해도 됨
status_values = variable_split.str.get(0)
country_values = variable_split.str.get(1)
ebola_long['status'] = status_values
ebola_long['country'] = country_values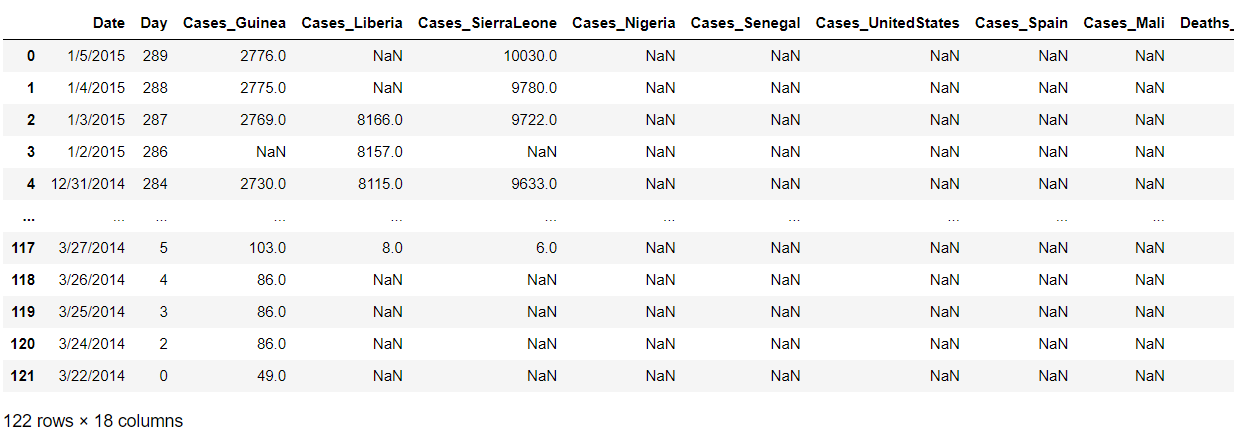
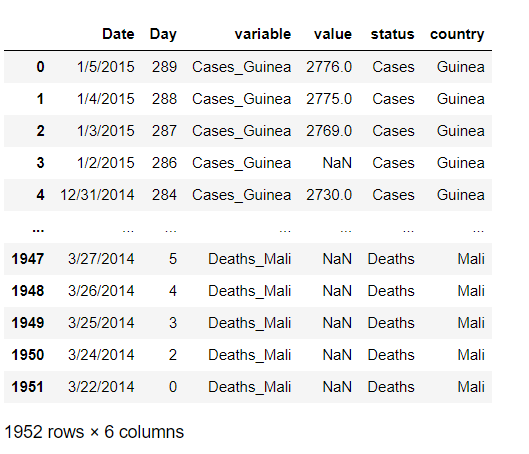
ebola_long = ebola.melt(id_vars=['Date', 'Day'])
variable_split = ebola_long.variable.str.split('_', expand=True)
ebola_long[['status', 'country']] = variable_split- 똑같은 결과. split에서 expand=True로 하면, 나눠진 결과를 곧바로 DataFrame으로 반환. 디폴트는 False고, 그 경우 리스트의 시리즈로 반환해서, 위의 경우는 그걸 일일히 쪼개서 붙인 거.
2-3 행과 열 모두 변수 정리
- 기상청의 날짜별 온도 테이블에서, 열에 d1, d2 이렇게 날짜가 다 열로 되어 있고, element라는 열에 max, min이 따로 표기
- 먼저 melt로 d1, d2 쓸데없는 열들을 다 행으로 변환
=> pivot_table로 element열의 max, min을 별도로 구분한 새로운 table 만들기
=> reset_index()로 인덱스를 깔끔하게 만들기
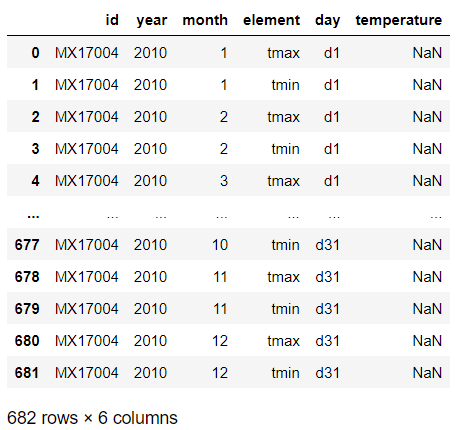
weather_melt = weather.melt(
id_vars=['id', 'year', 'month', 'element'],
var_name='day',
value_name='temperature')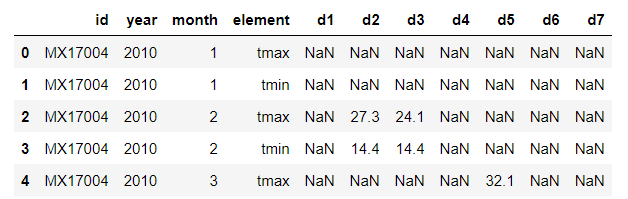
weather_tidy = weather_melt.pivot_table(
index=['id', 'year', 'month', 'day'],
columns='element',
values='temperature')
weather_tidy_flat = weather_tidy.reset_index()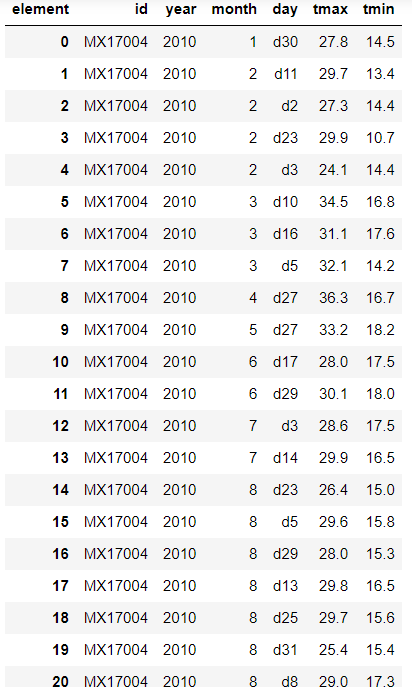
참고로 메서드 체인 이용해서 여러 메서드 한거번에 적용하기. 여기서는 pivot_table과 reset_index() 한거번에
#메서드 체인을 이용하면 element 피벗 단계를 한 번에 수행 가능
#=> 에러. 줄 바뀌는 지점에서 .reset_index()라서
weather_tidy = weather_melt.pivot_table(
index=['id', 'year', 'month', 'day'],
columns='element',
values='temperature')
.reset_index()
#가시성 안좋지만 이렇게 해도 됨
weather_tidy = weather_melt.pivot_table(
index=['id', 'year', 'month', 'day'],
columns='element',
values='temperature').reset_index()
# 줄 바뀌는 지점 조심. 귀찮으면 그냥 묶어라
weather_tidy = (
weather_melt.pivot_table(
index=['id', 'year', 'month', 'day'],
columns='element',
values='temperature')
.reset_index()
)3 Pivot_table
- 데이터프레임 값 요약하거나 집계하는데 사용. 주어진 데이터프레임을 기반으로 새로운 데이터프레임 생성.
pd.pivot_table(df),df.pivot_table() - 매개변수
df: 요약하려는 데이터프레임values=: 집계하려는(즉, 바뀌지 않고 기준이 되는) 열 이름(리스트)index=: 행 인덱스로 사용할 열 이름(리스트)columns=: 열 인덱스로 사용할 열 이름(리스트)aggfunc=: 값을 집계하는 방법 지정. 기본은 meanfill_value=: 결측값을 채울 값margins=: 총계 행 및 열을 추가할지 여부를 나타내는 boolean.
4 glob와 for로 여러 데이터 들고오기
4-1 glob 모듈
import glob
# glob는 저 이름에 해당하는 파일들을 들고오는 것
nyc_taxi_data = glob.glob('../data/fhv_*')
list_taxi_df = []
for csv_filename in nyc_taxi_data:
df = pd.read_csv(csv_filename)
list_taxi_df.append(df)
taxi_loop_concat = pd.concat(list_taxi_df)- glob.glob()는 파일 경로에서, 지정된 패턴과 일치하는 파일의 리스트를 반환하는 함수.
는 0개 이상의 임의의 문자열을 나타냄. 즉 fhv_면, fhv_로 시작하는 모든 이름.
?는 정확히 한 개의 임의문자. - 그 리스트를 for에 넣어서, 하나씩 pd.read_csv하고, 그걸 다 외부의 리스트에 append
=> 그걸 한거번에 concat하는 함수.

일본에서 일하는 게임 기획자. 시시해서 죽어버리지 않게, 재밌고 의미 있는 컨텐츠에 관심 있습니다. 그 도구로 데이터, AI도 찝적댑니다.