1 기본 개념
1-1 Scikit-learn
- 다양한 머신러닝 알고리즘 지원(분류, 회귀, 군집화 등). 데이터 마이닝, 데이터 분석 도구. Numpy와 SciPy 라이브러리 위에 구축되어 있음.
1-2 머신러닝 종류
- 지도학습(Supervised learning)
- 분류(Classification)
- 회귀(Regression)
- 비지도학습(Unsupervised learning)
- 군집화(Clustering)
- 차원축소(Dimensionality Reduction)
- 연관 규칙 학습(Association Rule Learning)
- 강화학습(Reinforcement learning)
- 정책학습(Policy learning)
- 가치학습(Value learning)
- 모델기반학습(Mode-based learning)
2 지도학습 - 분류(kNN)
2-1 훈련셋, 테스트셋 구분 없이
- 여기서 쓸 것은 KNN(K-nearest neighbors algorithm).
가장 거리가 가까운 k개의 이웃수를 보고, 제일 많은 걸로 분류.
#도미 35개, 빙어 14개의 길이와 무게 데이터
length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0, 9.8,
10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0, 6.7,
7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
#싸이킷 런이 요구하는 입력 모양
fish_data = [[l, w] for l, w in zip(length, weight)]]
#지도 학습을 위한 정답 데이터. 1과 0의 이진 분류로, 1은 도미, 0은 빙어
fish_target = [1] * 35 + [0]*14- 이렇게 데이터가 있다.
#모듈 호출
from sklearn.neighbors import KNeighborsClassifier
#객체 만들기
kn = KNeighborsClassifier()
#머신러닝 모델 훈련
kn.fit(fish_data, fish_target)
#만든 모델의 결과 확인
kn.score(fish_data, fish_target)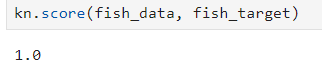
KNeighborsClassifir(): kNN 분류 알고리즘을 구현한 클래스. 매개변수 지정하지 않으면 n_neighbors=5가 디폴트로, 가장 가까운 5개의 이웃을 기반으로 분류 결정kn.n_neighbors = n: 처음 객체 생성할 때KNeighborsClassifir(n_neighbors=49)로 할 수도 있지만, 나중에 이렇게 바꿀 수도.kn.fit(fish_data, fish_target): 모델 훈련. fish_data는 독립 변수를 포함하는 배열이고, [length, weight]와 같은 2차원 리스트. fish_target은 해당 데이터의 레이블(종속 변수)로 학습시킬 정답. => 즉, fit 메서드는 주어진 데이터에 학습해 모델을 생성.kn.score(fish_data, fish_target): 훈련된 모델에 fish_data라는 독립 변수를 입력해 예측 수행, 이 예측이 실제 정답인 fish_target 레이블과 얼마나 잘 일치하는지 측정 => 정확도(accuracy)를 반환. 0은 모든 예측 틀렸고, 1은 모든 예측이 정확하게 일치.
여기서는 모델을 만들 때 쓴 데이터를 똑같이 사용해서 매우 높은 예측값이 나왔고, 100%의 정확도.kn.predict([[30, 600]]): 들어갈 값은 2차원 리스트 입력값. 이런 값의 데이터가 주어졌을 때 1인지 0인지 예측해서 반환. => 이 경우array([1]), 도미로 반환.
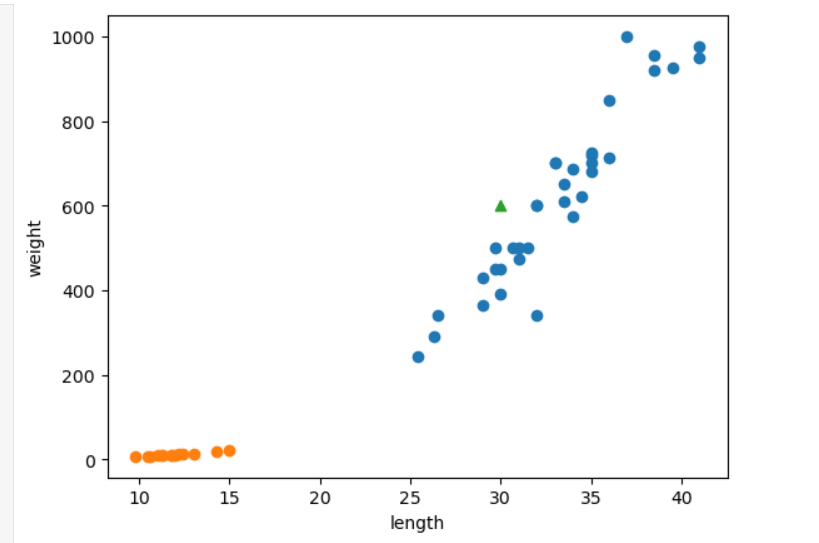
- 아래는 샘플 49개(즉, 모든 데이터) 보고 판단하기 => 이해 돕기 위해서 한 번 해보는 것
kn49 = KNeighborsClassifier(n_neighbors=49)
kn49.fit(fish_data, fish_target)
kn49.score(fish_data, fish_target)
print(35/49)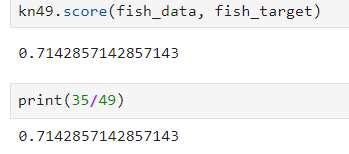
- 여기선 49개의 데이터를 각각 확인할 때, 49개의 가장 가까운 데이터(모든 데이터)를 보고, 어떤 데이터가 더 많은지로 이 데이터의 종류를 판단. 전체 데이터 중 도미가 35, 빙어가 14이기 때문에 => 모든 데이터를 도미로 판단.
따라서 35/49와 똑같이 나온다. 빙어 14개가 잘못 측정 됐기 때문에. - 아래는 몇 개의 k를 설정할 때, 처음으로 정확도가 100이 안되게 되는지 확인
kn = KNeighborsClassifier()
kn.fit(fish_data, fish_target)
for n in range(5, 50):
#최근접 이웃 개수 설정
kn.n_neighbors = n
#점수 계산
score = kn.score(fish_data, fish_target)
#100% 정확도에 미치지 못하는 이웃 개수 출력
if score < 1:
print(n, score)
break- 해보면 결과가 18로 나오고, 18부터 0.97로 떨어진다.
2-2 훈련셋, 데이터셋 구분
input_arr = np.array(fish_data)
target_arr = np.array(fish_target)
np.random.seed(42)
index = np.arange(49)
np.random.shuffle(index)
train_input = input_arr[index[:35]]
train_target = target_arr[index[:35]]
test_input = input_arr[index[35:]]
test_target = target_arr[index[35:]]- 먼저 35개/14개 기준으로 나눈다.
- 그리고 np.array로 만든다. 아래에 index[:35]를 통해, 인덱싱을 할 건데, list는 그런 방식을 지원하지 않고, np.array는 지원하기 때문에.
np.arange(49)는 0~48까지의 넘파이 배열을 만든다. =>np.random.shuffle(index)로 그 배열을 무작위로 섞는다.- 셔플링된 인덱스의 0~34번째를, input_arr에 던져서 그 값들만 훈련에 쓴다. => index[:35]는 array([13, 45, 47, 44, 17, 27, 26, 25, 31, 19, 12, 4, 34, 8, 3, 6, 40, 41, 46, 15, 9, 16, 24, 33, 30, 0, 43, 32, 5, 29, 11, 36, 1, 21, 2])
import matplotlib.pyplot as plt
#행은 전체 선택, 열은 0번째 lenth, 1번째 weight
plt.scatter(train_input[:, 0], train_input[:, 1])
plt.scatter(test_input[:, 0], test_input[:, 1])
plt.xlabel('length')
plt.ylabel('weight')
plt.show()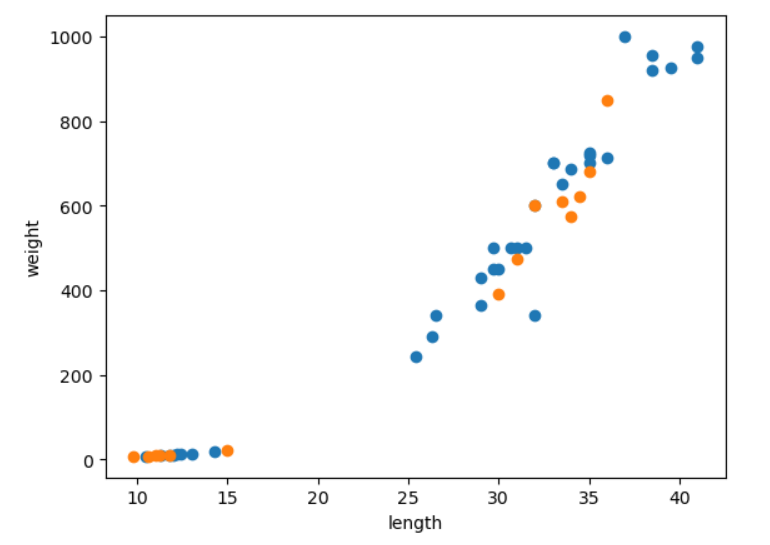
- 파란색은 train set, 주황색은 test set.
kn.fit(train_input, train_target)
kn.score(test_input, test_target)
#모델이 예측한 값
print(kn.predict(test_input))
#진짜 값
print(test_target)
#결과 일치. 따라서 1.0으로 100% 다 맞다
2-3 사이킷런 이용해서 자동 구분
fish_data = np.column_stack((fish_length, fish_weight))
fish_target = np.concatenate((np.one(35), np.zeros(14))
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = \
train_test_split(fish_data, fish_target,
startify=fish_target, random_state=42)np.column_stack((배열1, 배열2)): 배열 1과 배열 2를 열 방향으로 결합해서 2차원 배열 만든다.
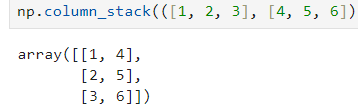
np.concatenate((배열1, 배열2, ...), axis=0): 여러 배열을 주어진 축을 따라 결합. 1로 하면 열 방향으로 결합, 0으로 하면 행 방향으로 결합. 0이 디폴트. => 여기선 135 + 014와 같음train_test_split(X, y, test_size=0.25, random_state=42, stratify=y): 데이터가 있을 때, train_set과 test_set으로 나눠주는 함수. X는 독립 변수 데이터셋(특성들)로 보통 2차원 배열의 형태. y는 종속 변수 또는 타깃 레이블로 1차원 배열 형태다.
test_size는 디폴트가 0.25로 25%를 테스트, random_state는 난수 시드값 지정.
여기서 X는 대문자로, y는 소문자로 표기하는 게 관례.
stratify 매개변수는 데이터셋의 클래스 불균형 해소. 예를 들면, 이진 분류 문제에서 대부분이 정상, 소수만 질병일 때, 무작위로 훈련 세트와 테스트 세트 나누면 정상 샘플의 비율이 매우 높아죠 질벙 상태를 학습 못할 수도 있다. => stratify=y를 설정하면, 타깃 변수 y의 실제 클래스 비율을 유지한 채로 훈련 세트와 테스트 세트를 분할한다.
kn = KNeighborsClassifier()
kn.fit(train_input, train_target)
kn.score(test_input, test_target)2-4 스케일 이슈 해결
- 위에 만든 모델에서 이어간다
print(kn.predict([[25, 150]]))
import matplotlib.pyplot as plt
plt.scatter(train_input[:, 0], train_input[:, 1])
plt.scatter(25, 150, marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()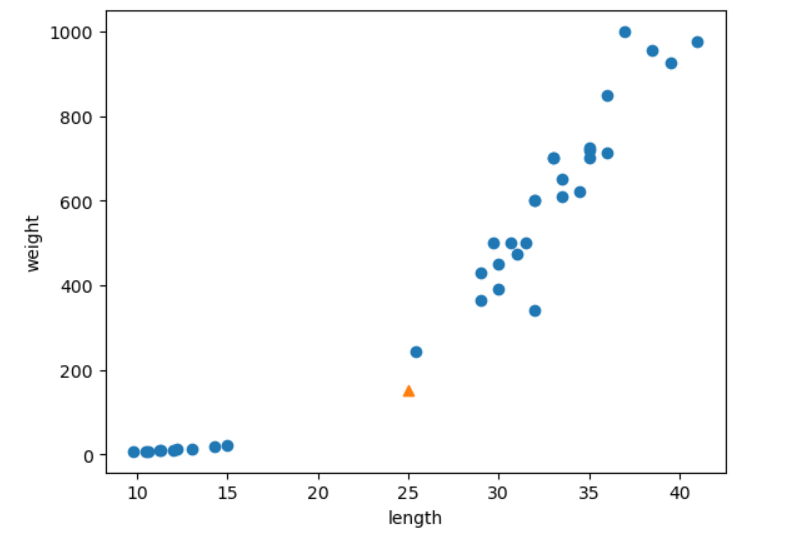
- 위의 시각화 결과를 보면, [25, 150] 값은 도미에 훨씬 가까워 보인다. 하지만 예측은 빙어라고 뜬다. 왜 그럴까?
- 문제는 length는 0~40이고, weight은 0~1000이기 때문. => 아래에 스케일을 똑같이 맞추면 이렇게 된다.
distances, indexes = kn.kneighbors([[25, 150]])
plt.scatter(train_input[:, 0], train_input[:, 1])
plt.scatter(25, 150, marker='^')
plt.scatter(train_input[indexes, 0], train_input[indexes, 1], marker='D')
plt.xlim((0, 1000)) #스케일 조정해서 x도 1000까지
plt.xlabel('length')
plt.ylabel('weight')
plt.show()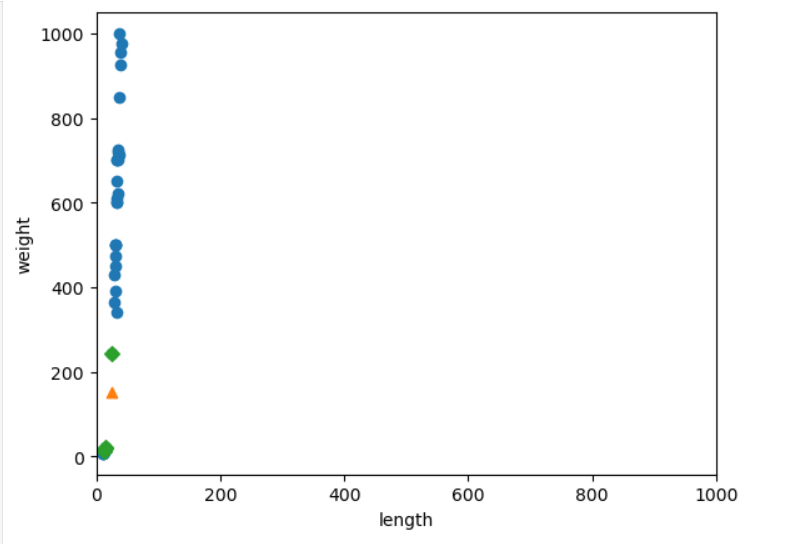
kn.kneighbors([데이터 포인트]): 주어진 데이터 포인트에 대해 kNN을 찾는 기능 제공. 가장 가까운 포인트들까지의 거리와 index 반환.- n_neighbors=로 갯수 설정 가능. 디폴트는 5.
- return_distance=로 반환 값에 이웃까지 거리를 포함하느냐, 인덱스만 반환하느냐. 디폴트는 True.
train_input[:, 0]: numpy의 고급 인덱싱. train_input은 2차원 넘파이 배열로, 트레인셋의 점들이 찍혀있다.
indexes는 위의 kneighbors로 찍힌 가장 가까운 점들의 인덱스.
즉, train_input[indexes]를 하면 가장 가까운 값들의 포인트[x, y]값들의 배열이 나온다.
여기서 [indexes, 0]으로 하면 x값, [indexes, 1]로 하면 y값이 나오는 것.- marker를 설정해서, 가장 가까운 값들만 위치를 바꾼다.
- plt.xlim으로 스케일을 0~1000으로 조정. 그리고 시각화.
- 결과를 보면 length는 값의 차이가 너무 작아 사실상 영향이 없고, weight에 따라서만 판별이 난다.
mean = np.mean(train_input, axis=0)
std = np.std(train_input, axis=0)
train_scaled = (train_input - mean) / std
new = ([25, 150] - mean)/std
plt.scatter(train_scaled[:, 0], train_scaled[:, 1])
plt.scatter(new[0], new[1], marker='^') #x, y이렇게 입력. new로 하면 안됨
plt.xlabel('length')
plt.ylabel('weight')
plt.show()np.mean(train_input, axis=0): 평균 내고, axis=0이면 행 방향으로 평균, axis=1이면 열 방향으로 평균. [x, y]로 된 2차열 배열이므로 axis=0이면 x는 x끼리, y는 y끼리 평균 내서 [x평균, y평균], axis=1이면 [(x+y)/2]값들의 배열.
np.std()도 마찬가지. 표준 편차를 구한다.- 이 식은 Z-score를 구해서 표준화하는 방법. (값-평균)/표준편차.
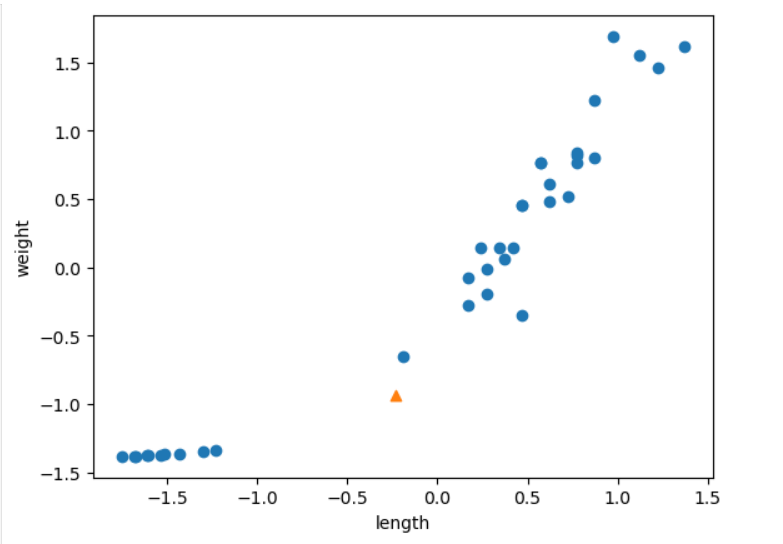
- 이제 표준화 됐으니 예측 새로 한다
kn.fit(train_scaled, train_target)
test_scaled = (test_input - mean) / std
kn.score(test_scaled, test_target)
print(kn.predict([new]))- test 데이터도 스케일링하고 새로 하면, 결과가 1로 나온다.
- 여기서 타겟 데이터는 (1, 0)의 이진이므로 조정하지 않는다.
distances, indexes = kn.kneighbors([new])
plt.scatter(train_scaled[:, 0], train_scaled[:, 1])
plt.scatter(new[0], new[1], marker='^')
plt.scatter(train_scaled[indexes, 0], train_scaled[indexes, 1], marker='D')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()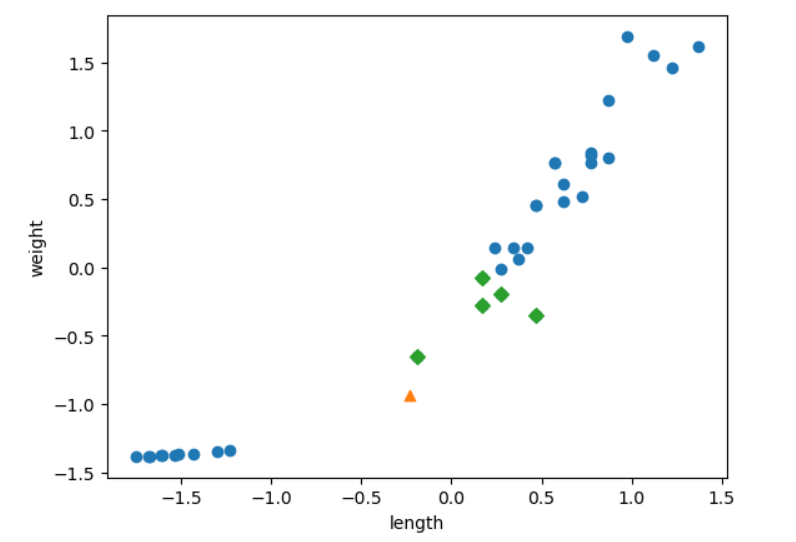
- 같은 방법으로 시각화 해보면, 위와 같이 나온다.
3 iris 이용한 kNN 분류
- 전체적인 프로세스
- 1 데이터 불러오기
- 2 데이터 나누기
- 3 데이터 살펴보기
- 4 머신러닝 모델 만들기
- 5 예측하기
- 6 모델 평가
3-1 데이터 불러오기
- iris는 sklearn에 있는, 전문가들이 이미 만들어놓은 데이터셋 중 하나. iris는 식물을 분류해놓은 데이터.
이 왜에도 boston(보스턴 주택 가격), diabetes(당뇨병), digits(손글씨 숫자 데이터셋), breast_cancer(유방암), wine(와인 데이터셋) 등이 있다.
from sklearn.datasets import load_iris
iris_dataset = load_iris()
print("iris_dataset의 키: \n", iris_dataset.keys())- iris_dataset는 딕셔너리 구조. key는 'data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'
- data는 말 그대로 데이터 본체
- target은 라벨
- target_names는 target이 각각 뭘 나타내는지. 여기선 0, 1, 2가 각각 setosa, versicolor, virginica 라는 꽃 이름이다.
- DSCR은 이 데이터에 대한 설명
- feature_name은 data가 각각 어떤 특성을 나타내는지. 여기선 [sepal length, sepal width, petal length, petal width]의 4가지 데이터다.
iris = iris_dataset['data']
#데이터 파악 작업
iris.shape
iris[:5]
iris_dataset['target'].shape
iris_dataset['target'][:5]
#데이터 프레임 만들기
iris_df = pd.DataFrame(data = iris,
columns = iris_dataset.feature_names) # iris_dataset['feature_names']와 같다
iris_df['label'] = irist_dataset.target
3-2 데이터 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
iris_dataset['data'], iris_dataset['target'],
random_state=0)3-3 데이터 살펴보기
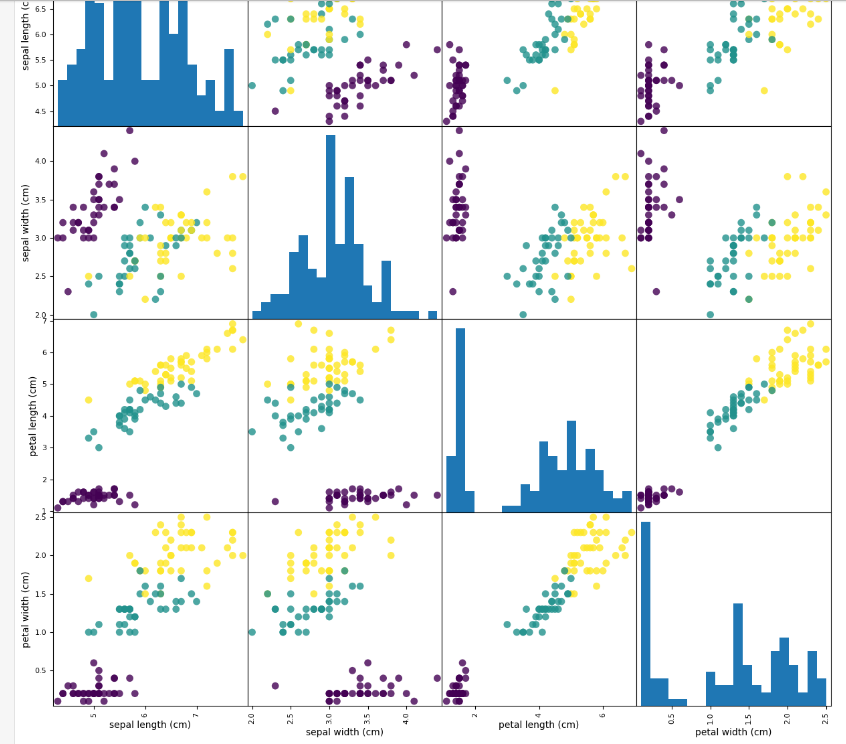
- 머신 러닝 모델 만들기 전에, 머신 러닝 없이도 풀 수 있는 문제인지, 혹은 필요한 정보가 누락되지 않았는지, 비정상적인 값이 있거나 조사. => 산점도 시각화 등으로 확인. => 이를 위해 넘파이 배열을 DF로 변경.
iris_dataframe = pd.DataFrame(
X_train, columns=iris_dataset.feature_names)
pd.plotting.scatter_matrix(iris_dataframe,
c=y_train, figsize=(15, 15), marker='o',
hist_kwds={'bins': 20}, s=60, alpha=.8)pd.plotting.scatter_matrix: 데이터프레임의 각 컬럼(특성) 쌍에 대한 산점도를 그리고, 대각선에는 각 변수의 히스토 그램 또는 밀도 그래프.
- 시각화할 DF 객체.
- c: 각 데이터 보인트의 색상 결정하기 위한 배열. 보통 타겟 변수(y_train) 사용해서, 다른 클래스의 데이터 포인트를 다른 색으로 표시.
- figsize 생성될 그래프 크기. 너비, 높이.
- marker: 마커 스타일
- hist_kwd: 히스토 그림 그릴 때 사용할 키워드 인자 딕셔너리 형태로 전달. bins:20은 막대 수를 20개로 설정.
- s: 산점도의 마커 크기.
- alpha: 그래프 투명도 설정. 0~1이고 0이면 투명.
3-4 모델 만들기, 예측하기, 평가하기
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(X_train, y_train)
X_new = np.array([[5, 2.9, 1, 0.2]])
prediction = knn.predict(X_new)
y_pred = knn.predict(X_test)
print("테스트 세트의 정확도: {:.2f}".format(
np.mean(y_pred == y_test)))- 모델 만들고 => 예측할 np.array를 만들고 => 예측
- 그리고 test 셋을 집어넣은 결과값과, 실제값을 매칭해서 정확도 도출
4 문제 - 농구 선수 포지션 맞추기
df = pd.read_csv('../data/ball.csv')
#이상치 확인
#그래프 보면서 데이터 확인
df_filtered = df[df['Pos'].isin(['SG', 'C'])]
sns.pairplot(df_filtered, hue='Pos', vars=['3P', '2P', 'TRB', 'AST', 'BLK', 'STL'], palette='bright')
plt.show()
#BLK, TRB, 3P가 유의미하게 다르다고 판단
df2 = df.loc[:,['Pos', '3P', 'TRB', 'BLK']]
#데이터 나누기
X = [[i[1][1], i[1][2], i[1][3]] for i in df2.iterrows()]
y = [i[1][0] for i in df2.iterrows()]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2)
#모델 만들고, 예측
kn = KNeighborsClassifier()
kn.fit(X_train, y_train)
kn.score(X_test, y_test)
#예측값이랑 실제값 데이터프레임 만들기
kn.score(X_test, y_test)
result_df = pd.DataFrame({'actual':y_test,
'predicted': predict_values})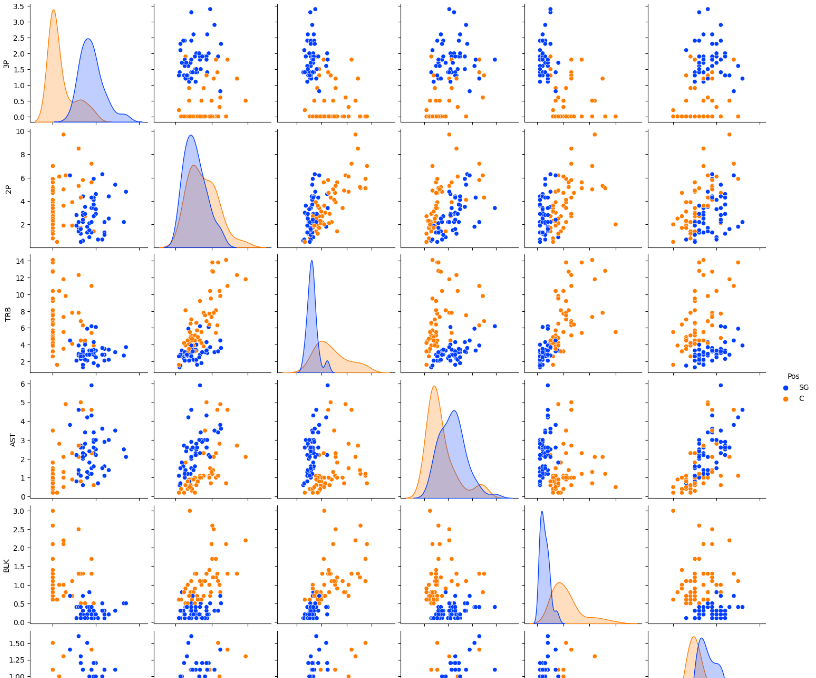
- pairplot 그림의 대각선 부분이, 그 데이터를 포지션 따라 나눈 결과값

일본에서 일하는 게임 기획자. 시시해서 죽어버리지 않게, 재밌고 의미 있는 컨텐츠에 관심 있습니다. 그 도구로 데이터, AI도 찝적댑니다.