1 Matplotlib
import matplotlib from plt- 파이썬 시각화 라이브러리. 하위 패키지 pyplot을 불러오면 다양한 시각화 기능 사용 가능.
- 개념
- 이산변수(discrete)
- 연속변수(continuous)
- matplotlib 칼라 코드표 https://matplotlib.org/stable/users/explain/colors/colormaps.html
- https://matplotlib.org/stable/gallery/pie_and_polar_charts/pie_features.html
2 기본 그래프 그리기, 서브플롯
plt.plot(dataset_1['x'], dataset_y['y'])
기본 그래프 그리는 함수. x축 시리즈, y축 시리즈를 각각 입력.plt.show(): 그린 그래프 보여줌!- 각종 매개변수(자료: graph옵션만)
c='g'색깔 지정.marker='0'마커 모양 지정.ls='--': 선 모양 지정
2-1 서브플롯 그리기1
fig = plt.figure()
axes1 = fig.add_subplot(2, 2, 1)
axes2 = fig.add_subplot(2, 2, 2)
axes3 = fig.add_subplot(2, 2, 3)
axes4 = fig.add_subplot(2, 2, 4)
axes1.plot(dataset_1['x'], dataset_1['y'], 'o')
axes2.plot(dataset_2['x'], dataset_2['y'], 'o')
axes3.plot(dataset_3['x'], dataset_3['y'], 'o')
axes4.plot(dataset_4['x'], dataset_4['y'], 'o')
#이름 붙이기
axes1.set_title('dataset_1')
axes2.set_title('dataset_2')
axes3.set_title('dataset_3')
axes4.set_title('dataset_4')
fig.suptitle('Anscombe Data')
fig.set_tight_layout(True) #자동 레이아웃 조정 기능. 여백을 최소화하지만 안겹치게.
plt.show()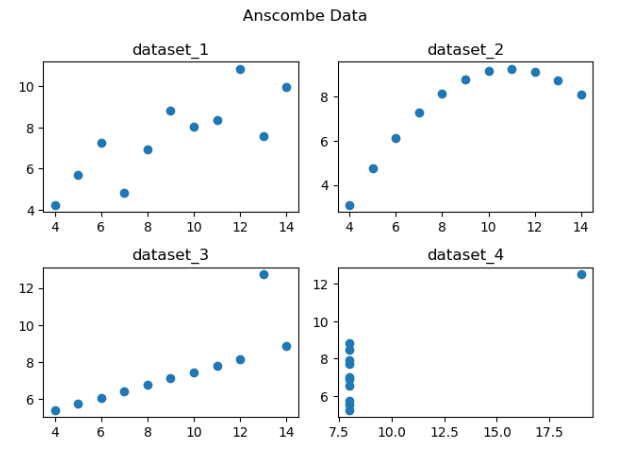
- 먼저 plt.figure()는 전체 그래프 객체.
- fig.add_subplot()은 figure 객체에 subplot을 더 하는 메서드.
(2, 2, 1)은 2행, 2열로 전체 모양을 만들고, 1은 인덱스. - 여기다가
axes.plot으로 각각 그래프를 채워넣음. axes1.set_title('dataset_1'): 그래프 이름 설정fig.suptitle('Anscombe Data'): subplot들 다 포함하는 전체 그래프 이름.ax1.set_xlabel('Time of Day')ax1.set_ylabel('Total Bill')hexbin.set_axis_labels(xlabel='Total Bill', ylabel='Tip')모두 축 이름 설정하는 것. 1, 2는 따로, 3은 한거번에.plt.xscale('log'),plt.yscale('log'): x축과 y축의 스케일을 조정. 이 경우 로그로.fig.set_tight_layout(True): 자동 레이아웃 조정. 여백 최소한.
2-2 서브플롯 그리기2
hist, ax1 = plt.subplots()
sns.histplot(data=tips, x='total_bill', ax=ax1)
plt.show()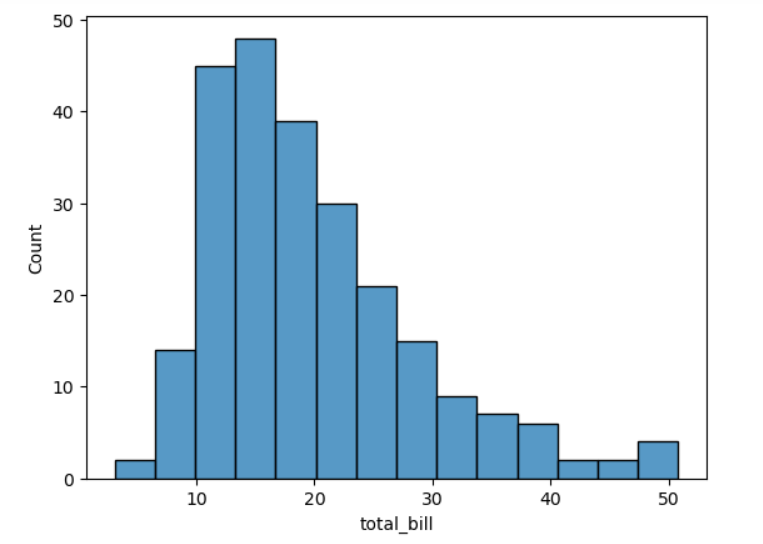
- plt.subplots()로 figure와 subplot을 한거번에 할당 가능.
hist는 figure, ax1는 subplot을 각각 할당. - data는 사용하는 데이터프레임, x는 x축에 사용할 시리즈.
- ax= subplot을 뜻하고, ax=ax1는 기존의 subplot객체를 subplot으로 지정한 것. 지정 안하면 자체적으로 subplot 생성하려고 시도.
f, ax1 = plt.subplots(1, 3, figsize=(16, 8))
raw_data['스트레스'].plot.pie(explode=[0, 0.02], ax=ax1[0],
autopct='%1.1f%%')
ax1[0].set_title('스트레스를 받은 적 있다.')
ax1[0].set_ylabel('')
raw_data['우울감경험률'].plot.pie(explode=[0, 0.02], ax=ax1[1],
autopct='%1.1f%%')
ax1[1].set_title('우울증을 경험한 적 있다.')
ax1[1].set_ylabel('')
raw_data['자살생각율'].plot.pie(explode=[0, 0.02], ax=ax1[2],
autopct='%1.1f%%')
ax1[2].set_title('자살을 고민한 적 있다.')
ax1[2].set_ylabel('')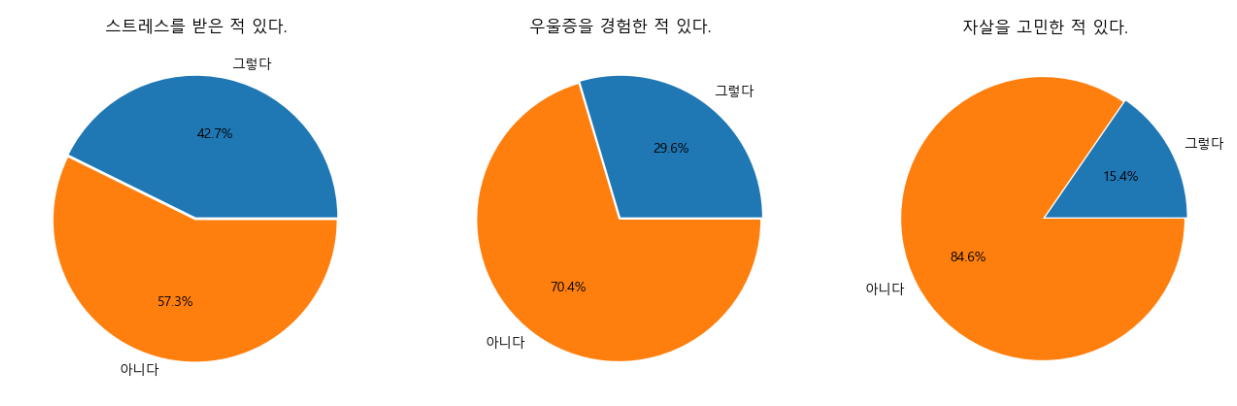
- subplots에서 1은 행 개수, 3은 열 개수, figsize는 figure의 전체 크기(가로, 세로)
- 3개의 subplot이 포함되지만, ax1로 넣었기 때문에 ()튜플 형태로 각각 들어간다. => 1, 2, 3을 [0], [1], [2]로 이용한다
fig, ax1 = plt.subplots(2, 3, figsize=(24, 16))
raw_data['스트레스'].plot.pie(explode=[0, 0.02], ax=ax1[0, 0],
autopct='%1.1f%%')
ax1[0, 0].set_title('스트레스를 받은 적 있다.(2018년)')
ax1[0, 0].set_ylabel('')
raw_data['우울감경험률'].plot.pie(explode=[0, 0.02], ax=ax1[0, 1],
autopct='%1.1f%%')
ax1[0, 1].set_title('우울증을 경험한 적 있다.(2018년)')
ax1[0, 1].set_ylabel('')
raw_data['자살생각율'].plot.pie(explode=[0, 0.02], ax=ax1[0, 2],
autopct='%1.1f%%')
ax1[0, 2].set_title('자살을 고민한 적 있다.(2018년)')
ax1[0, 2].set_ylabel('')
mentalDf['스트레스'].plot.pie(explode=[0, 0.02], ax=ax1[1, 0], autopct='%1.1f%%')
ax1[1, 0].set_title('스트레스를 받은 적 있다(2018년)')
ax1[1, 0].set_ylabel('')
mentalDf['우울감경험률'].plot.pie(explode=[0, 0.02], ax=ax1[1, 1], autopct='%1.1f%%')
ax1[1, 1].set_title('우울증을 경험한 적 있다.(2022년)')
ax1[1, 1].set_ylabel('')
mentalDf['자살생각률'].plot.pie(explode=[0, 0.02], ax=ax1[1, 2], autopct='%1.1f%%')
ax1[1, 2].set_title('자살을 고민한 적 있다.(2022년)')
ax1[1, 2].set_ylabel('')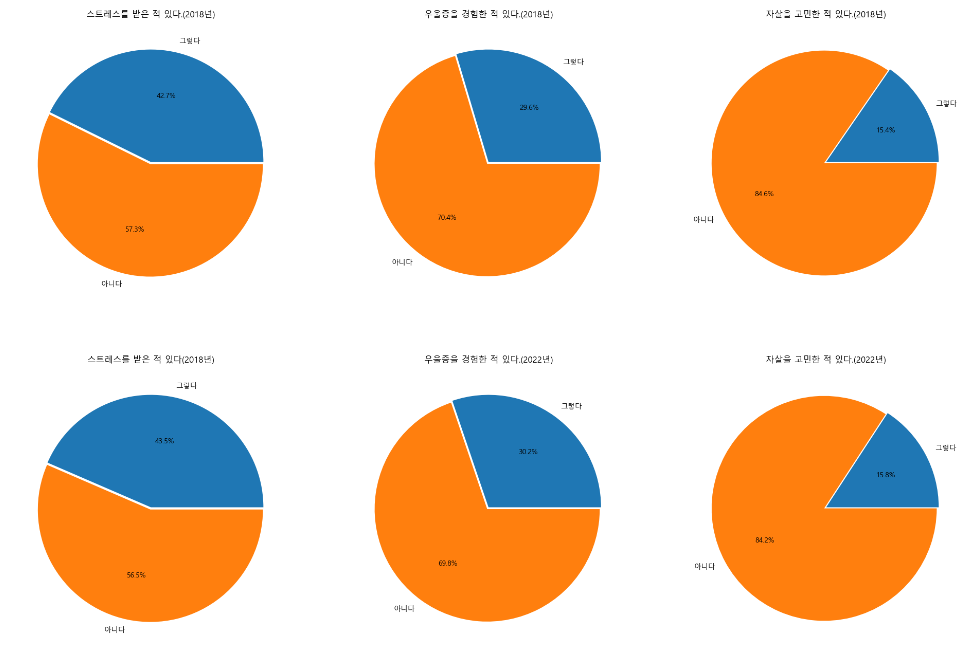
- 이렇게 (2, 3)으로 2차원으로 배열이 되면
[0, 0][0, 1] [0, 2][1, 0] [1, 1][1, 2]로 서브플롯도 지정되어야 한다
혹은 [0][0] [0][1] [0][2] 도 가능
2-3 서브플롯 그리는 순서
#1
fig = plt.figure()
axes1 = fig.add_subplot(1, 2, 1)
axes1 = closing_year.plot()
axes2 = fig.add_subplot(1, 2, 2)
axes2 = closing_year_q.plot()
plt.show()
#2
fig = plt.figure()
axes1 = fig.add_subplot(1, 2, 1)
axes2 = fig.add_subplot(1, 2, 2)
axes1 = closing_year.plot()
axes2 = closing_year_q.plot()
plt.show()- closing_year.plot()라는 pandas의 plot 메서드를 호출하면, 현재 활성화된 matplotlib의 Axes 객체에 그래프를 그린다. 따라서, pandas가 내부적으로 사용하는 Axes 객체는 가장 최근에 호출한 AxesSubplot 객체에 할당된다.
- 따라서, 위의 경우는 1이 변수 선언되고, 1을 plot해서 1에 그려지고, 2가 변수 선언되고, 2를 plot해서 2에 그려진다.
- 아래의 경우 1을 선언, 2를 선언, 그리고 각각 axes1과 axes2에 각각 그리면, 가장 최근에 선언된 2에 둘 다 그려진다.
fig, ax = plt.subplots(1, 2)
closing_year.plot(ax=ax[0])
closing_year_q.plot(ax=ax[1])
plt.show()
fig = plt.figure()
axes1 = fig.add_subplot(1, 2, 1)
axes2 = fig.add_subplot(1, 2, 2)
axes1 = closing_year.plot(ax=axes1)
axes2 = closing_year_q.plot(ax=axes2)
plt.show()- 이렇게 그려도 둘 다 원하는 모양으로 그려진다. ax= 매개변수로 정확하게 지정하는 것.
- 위의 경우 ax는 넘파이어레이 객체고, ax[0]은 Axes 객체.
3 일변량 그래프(히스토그램)
fig = plt.figure()
axes1 = fig.add_subplot(1, 1, 1)
axes1.hist(data=tips, x='total_bill', bins=10)
axes1.set_title('Histogram of Total Bill')
axes1.set_xlabel('Total Bill')
axes1.set_ylabel('Frequency')
plt.show()
- tips는 사용할 데이터프레임, total_bill 은 사용할 컬럼
- bins는 x축 구간 갯수(막대 10개)
4 이변량 그래프
4-1 산점도 그래프
scatter_plot = plt.figure()
axes1 = scatter_plot.add_subplot(1, 1, 1)
axes1.scatter(tips['total_bill'], tips['tip'])
plt.show()
- scatter(x값, y값)
- 매개변수로 s=50하면 마커의 크기 지정.
4-2 박스 그래프
boxplot = plt.figure()
axes1 = boxplot.add_subplot(1, 1, 1)
axes1.boxplot(x = [
tips[tips['sex'] == 'Female']['tip'],
tips[tips['sex'] == 'Male']['tip'] ],
labels = ['Female', 'Male'])
plt.show()
- x에 x축 데이터 종류 2개 리스트로 전달, labels로 각각 이름
- IQR(Interquartile range)(25%, 중간값, 75%), outlier 표시
- 여기서 이상치의 기준은 25~50과 50~75%의 범위를 1.5배 곱하고, 그 밖을 이상치로 규정. 보편적 정의는 아니다.
5 다변량 그래프
colors = {'Female': '#f1a340', 'Male':'#998ec3'}
scatter_plot = plt.figure()
axes1 = scatter_plot.add_subplot(1, 1, 1)
axes1.scatter(data=tips, x='total_bill', y='tip',
s=tips['size']**2*10,
c=tips['sex'].map(colors),
alpha=0.5 )
plt.show()
- 산점도 그래프에, 점의 색깔로 성별 추가, 점의 사이즈로 인원수 추가 => 총 4개의 변수를 표현
- colors = 기존 컬러팔레트 대신, 직접 설정
- data=데이터프레임, x, y 각각 설정
- s= 에 사이즈 * 210으로 값에 따라 바뀌게 설정
- c= 에 색깔이 값에 따라 바뀌도록, 직접 설정한 colors와 매칭
- alpha= 점의 투명도. 0이면 투명, 1은 불투명.
pd.plotting.scatter_matrix(iris_dataframe,
c=y_train, figsize=(15, 15), marker='o',
hist_kwds={'bins': 20}, s=60, alpha=.8)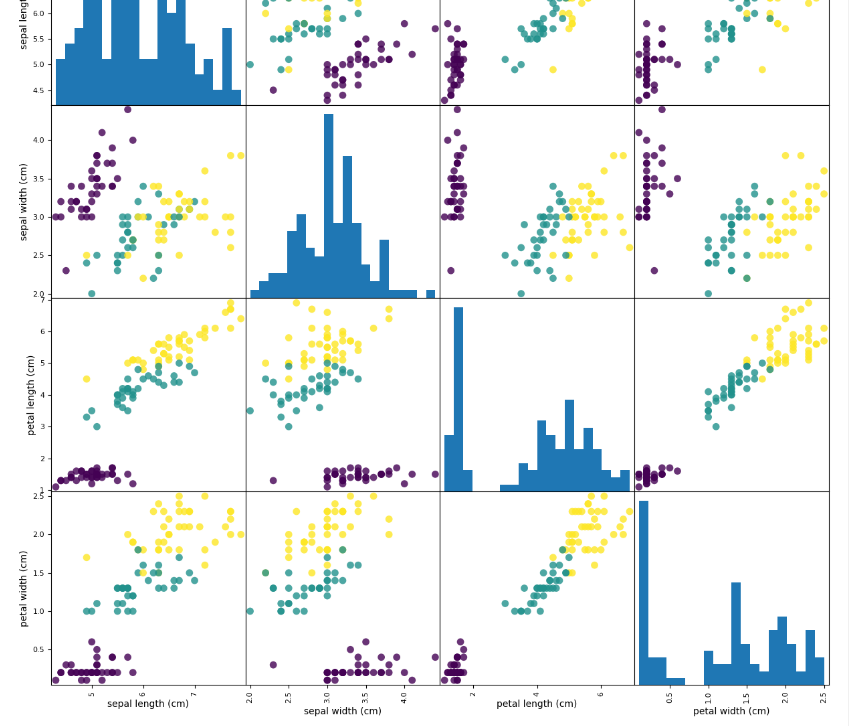
- 데이터프레임의 각 컬럼(특성) 쌍에 대한 산점도를 그리고, 대각선에는 각 변수의 히스토 그램 또는 밀도 그래프.
- 시각화할 DF 객체.
- c: 각 데이터 보인트의 색상 결정하기 위한 배열. 보통 타겟 변수(y_train) 사용해서, 다른 클래스의 데이터 포인트를 다른 색으로 표시.
- figsize 생성될 그래프 크기. 너비, 높이.
- marker: 마커 스타일
- hist_kwd: 히스토 그림 그릴 때 사용할 키워드 인자 딕셔너리 형태로 전달. bins:20은 막대 수를 20개로 설정.
- s: 산점도의 마커 크기.
- alpha: 그래프 투명도 설정. 0~1이고 0이면 투명.
6 원형 그래프
import matplotlib.pyplot as plt
labels1 = 'Frogs', 'Hogs', 'Dogs', 'Logs'
sizes1 =[15, 30, 45, 10]
explode1 = (0, 0.1, 0, 0) # only 'explode' the 2nd slice
fig1, ax1 = plt.subplots()
ax1.pie(sizes1, explode=explode1, labels = labels1,
autopct = '%1.1f%%',
shadow=True,
startangle=90)
ax1.axis('equal')
plt.show()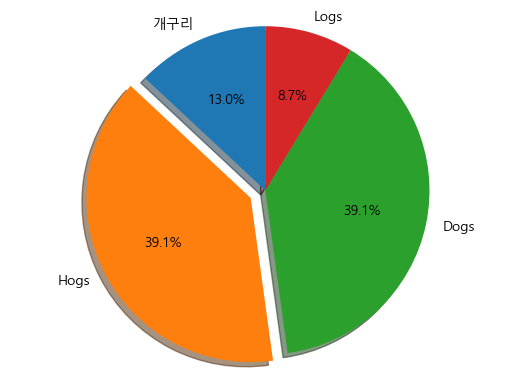
- labels1: 각 부채꼴의 레이블을 정의
- sizes: 각 부채꼴의 크기 비율을 나타냄. 100분율로. 100보다 커도 그냥 100분율 퍼센트로 알아서 계산해서 나옴.
- explode1: 특정 부채꼴 강조 위해 부채꼴 분리되는 정도. 여기서는 2번째만 0.1 분리되도록 설정. 0이면 분리 안됨.
- autopct='%1.1f%%' 부채꼴 위 표시될 텍스트 형식 지정. 소수점 첫째자리까지 표시(%1.1f)하고 백분율로 표시 (%%)
- shadow=True: 그래프에 그림자 효과 추가
- startangle = 90. 90도인 위에서부터 시작. 0도는 xy그래프에서 0. 시계 반대방향으로 돌아감.
- ax1.axis('equal). 서브플롯의 x와 y축 스케일을 설정하는 명령어. 'equal'은 가로세로 비율이 1:1로 똑같이 맞춰짐(원이니까)
auto는 자동으로 축 범위 조정, scaled는 x와 y 스케일 동일하게 유지, tight는 데이터 표시되는 모든 부분이 서브플롯에 표시되게 축 범위 조절, [xmin, xmax, ymin, ymax]로 수동 지정할 수도 df['열이름'].plot.pie(explode=[0, 0.02]): 단순하게 열 원형 그래프로. explode는 위와 같이 띄우기.
7 회귀선 그리기
#2개의 x, y의 회귀식의 계수 구하기
fp1 = np.polyfit(data_result['인구수'], data_result['소계'], 1)
#2개의 값으로 1차 함수 객체 만들기
f1 = np.poly1d(fp1)
#100000~700000개 사이의 100개의 값 넘파이배열 만들기(x로 쓸 것)
fx = np.linspace(100000, 700000, 100)
plt.figure(figsize=(10, 10))
plt.scatter(data_result['인구수'], data_result['소계'], s=50)
plt.plot(fx, f1(fx), ls='dashed', lw = 3, color='g')
plt.show()np.polyfit(x, y, deg): 주어진 데이터에 대해 최소제곱법으로 다항식 계수를 찾아내는 함수. x는 독립변수, y는 종속변수, deg는 다항식 차수.
즉, 여기서는 인구수, 소계의 관계를 1차식으로 표현하고, 그 계수를 구한다.
return값은 numpy 배열로, [0]이 기울기, [1]가 y절편을 나타낸다. e-03은 10의 -3승.
여기서는 기울기와 절편을 fp1에 넣는다.
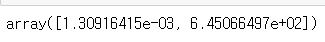
np.poly1d: 다항식 계수를 입력받아, 해당 계수를 가지는 다항식 함수의 객체를 생성한다.
어떤 차수라도 가능하다. 3개의 값을 입력하면, 높은 차수부터 2차, 1차, 상수로 함수가 나온다. 4개의 값을 입력하면 3차, 2차, 1차, 상수로 함수가 나온다.
이 객체는 함수처럼 사용될 수 있다. return값은 poly1d 객체이고, 아래와 같이 나온다.
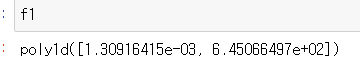
np.linespace(start, stop, num): 시작값과 종료값을 포함하는 범위에서 균일한 간격의 숫자를 생성한다.
여기서는 100,000부터 700,000까지의 인구수 범위에서 100개의 점을 생성한다.- plt.scatter에서 s=50은, 마커의 크기를 지정한다.
plt.plot은 선형회귀모델을 선 그래프로 표시한다. fx를 x값으로(즉, 100000~70000 사이의 100개의 점을), f1(fx)를 y값으로 사용한다.ls='dashed'는 선의 스타일 지정. 점선으로.lw=3: 선의 두께 지정.color='g': 선의 색상 지정.
8 설정
8-1 한글 쓸 때 오류 처리
#자주 쓰는 거니까 그냥 하나 만들어놓고, 그래프 그릴 때마다 카피해서 사용
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
plt.rcParams['axes.unicode_minus'] = False #-깨짐 방지
#f_path = '/Library/Fonts/AppleGothic.ttf' #맥
f_path = 'C:/Windows/Fonts/malgun.ttf'
font_name = font_manager.FontProperties(fname=f_path).get_name()
rc('font', family=font_name)8-2 폰트 세팅(맑은 고딕)
import matplotlib.pyplot as plt
plt.rcParams.update({'font.family' : 'Malgun Gothic'})import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import font_manager, rc
font_name = 'malgun gothic'
rc('font', family=font_name)9 그래프 그릴 때 반복해서 나오는 매개변수 정리
alpha=0.1: 투명도. 0이면 투명, 1이면 불투명.bins=: 히스토그램에서 데이터를 몇 개로 나눌지log=True: 히스토그램에서 y축을 로그스케일로 할지vert=False: 박스 그래프 False로 하면 가로로. 가로로 만든 경우 길이 바꾸려면 xscale로 해야 한다.whis=1.5: 박스 그래프에서 이상치의 범위를 설정하는 매개변수.c=: 색깔을 지정하는 매개변수.
c는 색상을 지정하는 매개변수인데, 하나의 색상 / 색상 시퀀스 / 수치 데이터 3종류가 들어갈 수 있다.
하나의 색상만 들어가면, 그 색상으로 통일된다.
색상 시퀀스를 넣을 때는, 시퀀스의 길이가 데이터 포인트의 수와 동일해야 한다.
수치 데이터를 넣으면, 데이터의 수치에 따라 색상을 매핑한다. 이때 cmap=으로 색상 맵을 가이 지정할 수 있다. 그러면 색상 맵에 따라 수치의 크기를 다른 색상으로 표현한다. 따라서 c = data_result['오차']를 넣으면, 오차가 큰 순서대로 색상이 표현된다.
10 관련 메서드
barplot().set(): seaborn, matplotlib에서 그래프의 여러 속성을 한 번에 설정하는 메서드.- xlim과 ylim: 이는 각각 x축과 y축의 한계를 설정합니다. 예를 들어, xlim=[0, 800]은 x축의 범위를 0부터 800까지로 설정합니다.
- xlabel과 ylabel: x축과 y축에 레이블(설명 텍스트)을 설정합니다.
- title: 그래프의 제목을 설정합니다.
- xticks와 yticks: x축과 y축에 표시될 눈금의 위치를 설정합니다.
- xticklabels와 yticklabels: x축과 y축 눈금에 사용할 레이블을 설정합니다. 이는 각 눈금의 이름을 변경할 때 유용합니다.
- fontsize 또는 size: 텍스트의 크기를 설정합니다.
- color: 텍스트의 색상을 설정합니다.
plt.grid(True, linestyle='-', color='0.75'): 격자선 그리기. 라인 스타일 지정, 색깔은 Matplotlib 색깔 지정가능한데, 그냥 숫자 0.75는 그레이 스케일(0이 검정, 1이 흰색).plt.xlabel()plt.ylabel(): x축, y축 이름 설정.plt.colorbar(): 색상바를 옆에 표시한다.plt.text(x, y, text, fontsize=15)는, x와 y좌표에 text를 fontsize로 표시한다는 뜻이다.
아래와 같이 하면 x는 인구수의 102%로 기존의 약간 오른쪽, y는 소계의 98%로 약간 아래쪽에 위치시킨다. 그리고 index[n]인, 구 이름을 표기시킨다. fontsize는 15로 고정시킨다.
for n in range(10):
plt.text(df_sort['인구수'][n] * 1.02, df_sort['소계'][n]*0.98,
df_sort.index[n], fontsize=15)plt.imshow(): Matplotlib 라이브러리를 사용해서 이미지 데이터 시각화. Numpy 배열 형태의 이미지 데이터 입력 받아서 이미지 형태 그래프로 만든다. 배열이 2차원이면 흑백으로, 3차원이면 컬러 이미지로(마지막 차원 RGB 채널).cmap=: 컬러맵. 여기서 plt.cm.gray는 Matplotlib의 cm(color map)에서 gray. 값이 낮을수록 검은색, 높을수록 흰색으로 표시되도록, 흑백 렌더링에 이용.interpolation=: 이미지가 확대 축소될 때 적용되는 보간법. bilinear은 주변 픽셀의 선형보간, nearest 는 가장 가까운 픽셀값 사용.aspect=: 이미지의 종횡비. auto를 넣으면 축 비율 무시하고, 데이터에 맞게 스케일링.alpha: 투명도. 0은 완전투명. 1은 완전불투명.vmin, vmax: 데이터의 최소 및 최대 값.origin: 이미지 데이터의 원점 위치. upper, 윗쪽 왼쪽이 원점. lower은 아래 왼쪽이 원점.
plt.axis('off'): 축 없앤다.plt.legend(loc=2): legend즉 범례를 추가하고 위치를 지정. 0~10이 있고, 0은 자동, 1은 오른쪽 상단, 2는 왼쪽 상단, 3은 왼쪽 하단, 4는 오른쪽 하단 등등. 'upper right'이라고 해도 됨.plt.savefig('../data/2_tag_wordcloud.png'): 해당 디렉에 이미지 저장.

일본에서 일하는 게임 기획자. 시시해서 죽어버리지 않게, 재밌고 의미 있는 컨텐츠에 관심 있습니다. 그 도구로 데이터, AI도 찝적댑니다.