1 서울시 구별 CCTV 분석
1-1 데이터 불러오기
#구별 CCTV파일 들고오기
CCTV_Seoul = pd.read_csv('../data/01. CCTV_in_Seoul.csv', encoding='utf-8')
#칼럼 이름 변경
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0] : '구별'},
inplace = True)
#구별 인구 파일 들고오기
pop_seoul = pd.read_excel('../data/01. population_in_Seoul.xls', header = 2,
usecols = 'B, D, G, J, N')
#칼럼명 바꾸기
pop_seoul.columns = ['구별', '인구수', '한국인', '외국인', '고령자']- rename, columns는 칼럼 이름 바꾸는 2가지 방법.
1-2 데이터 파악하기
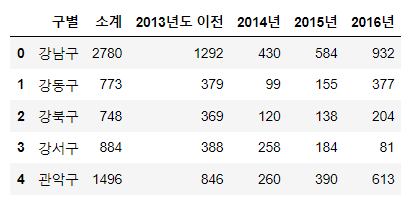
#cctv 총개수가 적은 구 확인
CCTV_Seoul.sort_values(by='소계', ascending=True).head()
#cctv 총개수가 많은 구 확인
CCTV_Seoul.sort_values(by='소계', ascending=False).head()
#2014~16년간 증가율을 새 칼럼으로
CCTV_Seoul['최근증가율'] = (
CCTV_Seoul['2016년'] + CCTV_Seoul['2015년'] + \
CCTV_Seoul['2014년']) / CCTV_Seoul['2013년도 이전'] * 100
CCTV_Seoul.sort_values(by='최근증가율', ascending=False).head()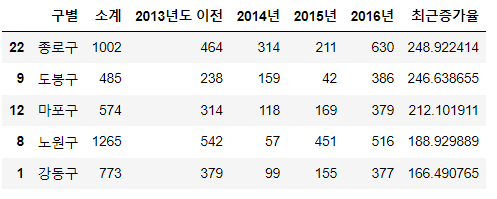
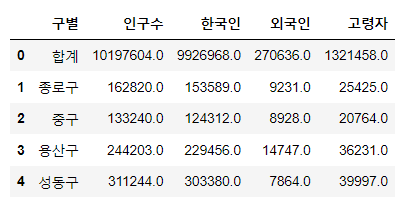
#데이터 확인
pop_seoul.head()
#필요 없는 1행 삭제
pop_seoul.drop([0], inplace=True)
#이상값 확인1 잘못된 값
pop_seoul['구별'].unique()
#이상값 확인2 NaN
pop_seoul[pop_seoul['구별'].isnull()]
#NaN값 처리 - 위에서 26행이 NaN으로 확인
pop_seoul.drop([26], inplace=True)
#결과 다시 확인
pop_seoul['구별'].unique()
#외국인, 고령자 비율을 새 열로
pop_seoul['외국인비율'] = pop_seoul['외국인'] / pop_seoul['인구수'] * 100
pop_seoul['고령자비율'] = pop_seoul['고령자'] / pop_seoul['인구수'] * 100
#데이터 확인
pop_seoul.sort_values(by='인구수', ascending=False).head(5)
pop_seoul.sort_values(by='외국인', ascending=False).head(5)
pop_seoul.sort_values(by='외국인비율', ascending=False).head(5)
pop_seoul.sort_values(by='고령자', ascending=False).head(5)
pop_seoul.sort_values(by='고령자비율', ascending=False).head(5)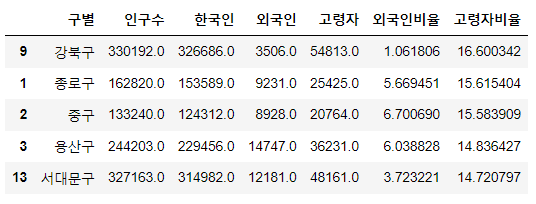
1-3 데이터 합치고 분석
#'구별' 기준으로 merge
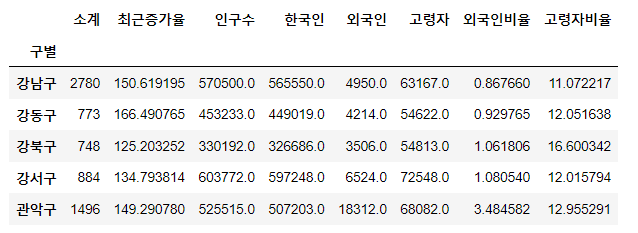
data_result = pd.merge(CCTV_Seoul, pop_seoul, on='구별')
#필요 없는 열 삭제
del data_result['2013년도 이전']
del data_result['2014년']
del data_result['2015년']
del data_result['2016년']
#구별 을 인덱스로 지정
data_result.set_index('구별', inplace = True)- 일반적으로 drop은 행 삭제, del은 열 삭제. 사실 drop으로도 열 삭제도 가능한데, 이게 매개변수 지정 없이 편하다.
1-4 상관관계 분석
- 상관분석(Correlation Analysis)는, 확률론과 통계학에서 두 변수 간에 어떤 선형적 관계를 갖고 있는지를 분석하는 방법. 두 변수는 서로 독립적인 관계로부터 서로 상관된 관계일 수 있으며 이때 두 변수 간의 관계의 강도를 상관관계(Correlation, Correlation coefficient)라고 한다.
- 상관 계수의 절대값이 클수록 두 데이터는 관계가 있다고 본다. 상관계수의 절대값이
- 0.1 이하면 거의 무시
- 0.3 이상이면 약한 상관관계
- 0.7 이상이면 뚜렷한 상관관계라고 한다.
np.corrcoef(변수1, 변수2)
import numpy as np
np.corrcoef(data_result['고령자비율'],data_result['소계'])
np.corrcoef(data_result['외국인비율'],data_result['소계'])
np.corrcoef(data_result['인구수'],data_result['소계'])- 위에서 소계는 cctv 대수.
- CCTV 개수와 고령자비율, 외국인비율, 인구수 이렇게 상관관계를 확인한다.
아래는 cctv개수와 인구수의 상관관계로, 유일하게 0.3을 넘어 약한 상관관계를 나타낸다.

1-5 CCTV와 인구현황 그래프로 분석하기
#한글 깨짐 방지용 코드
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
plt.rcParams['axes.unicode_minus'] = False
f_path = "C:/Windows/Fonts/malgun.ttf"
font_name = font_manager.FontProperties(fname=f_path).get_name()
rc('font', family=font_name)
# cctv 갯수 확인
plt.figure()
data_result['소계'].plot(kind='barh', grid=True, figsize=(10, 10)) #barh에 h는 가로로 그리는거
plt.show()
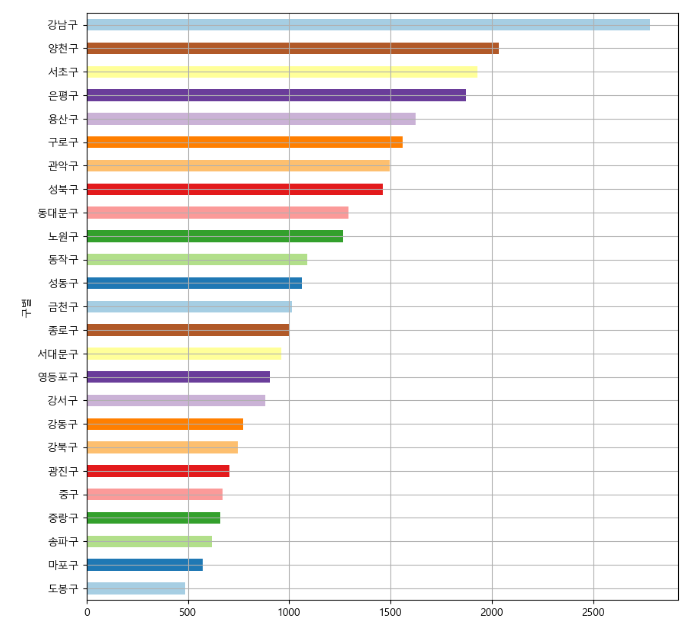
# cctv 갯수 많은 순으로 정렬
plt.figure()
data_result['소계'].sort_values().plot(kind='barh', grid=True, figsize=(10, 10))
plt.show()
# 인구 대비 cctv비율이 높은 구 확인
data_result['CCTV비율'] = data_result['소계'] / data_result['인구수'] * 100
data_result['CCTV비율'].sort_values().plot(kind='barh', grid = True, figsize = (10, 10))
#seaborn 사용해서 컬러 지정
import seaborn as sns
colors = sns.color_palette('Paired',len(data_result.index))
data_result['소계'].sort_values().plot(kind='barh', grid = True, figsize=(10,10), color = colors)
plt.show()- matplotlib으로 figure(새 그림) 생성. 거기다가 pandas 라이브러리로 데이터 수평 막대 시각화.
df['열'].plot(kind='barh', grid=True): pandas에서 DataFrame 객체를 시각화하는 함수.- kind는 종류.
lin,bar,hist,box,kde,area,pie,scatter,hexbin등. 여기서 h는 horizontal로 가로로 그린다는 걸 의미. 따라서barh는 가로로 그린 막대그래프. grid=True는 그래프에 격자를 표시해 가독성을 높인다.
- kind는 종류.
sns.color_palette('Paired',len(data_result.index)): sns.color_pallete()는 Seaborn에서 색상 팔레트를 생성하는 함수. Paired는 색상 이름. len()부분은 생성할 색상 수 지정. index 길이만큼 생성.
1-6 산점도 그래프, 회귀선으로 분석하기
plt.figure(figsize=(6,6))
plt.scatter(data_result['인구수'], data_result['소계'], s=50) #s는 점 사이즈크기
plt.xlabel('인구수')
plt.ylabel('CCTV')
plt.grid() #격자선 그리기
plt.show()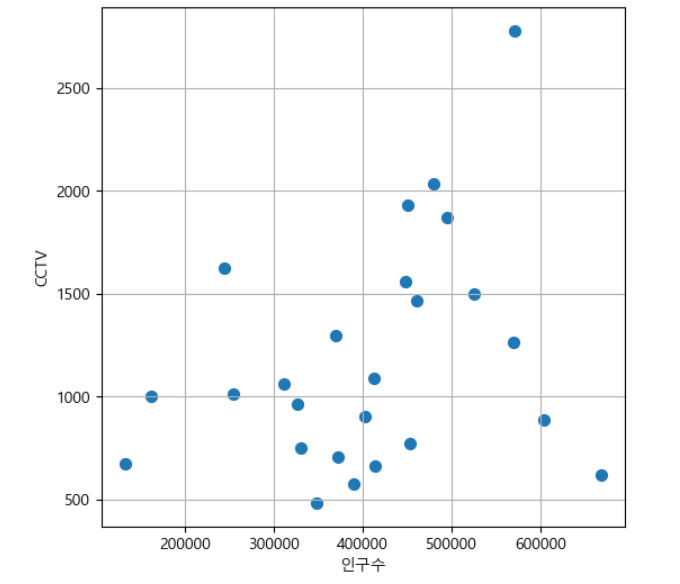
fp1 = np.polyfit(data_result['인구수'], data_result['소계'], 1)
f1 = np.poly1d(fp1) #매개변수로부터 모델 생상
fx = np.linspace(100000, 700000, 100) #시작, 끝(포함), 개수
plt.figure(figsize=(10, 10))
plt.scatter(data_result['인구수'], data_result['소계'], s=50)
plt.plot(fx, f1(fx), ls='dashed', lw = 3, color='g')
plt.xlabel('인구수')
plt.ylabel('CCTV')
plt.grid()
plt.show()np.polyfit(x, y, deg): 주어진 데이터에 대해 최소제곱법으로 다항식 계수를 찾아내는 함수. x는 독립변수, y는 종속변수, deg는 다항식 차수.
즉, 여기서는 인구수, 소계의 관계를 1차식으로 표현하고, 그 계수를 구한다.
return값은 numpy 배열로, [0]이 기울기, [1]가 y절편을 나타낸다. e-03은 10의 -3승.
여기서는 기울기와 절편을 fp1에 넣는다.
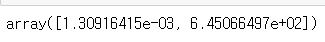
np.poly1d: 다항식 계수를 입력받아, 해당 계수를 가지는 다항식 함수의 객체를 생성한다.
어떤 차수라도 가능하다. 3개의 값을 입력하면, 높은 차수부터 2차, 1차, 상수로 함수가 나온다. 4개의 값을 입력하면 3차, 2차, 1차, 상수로 함수가 나온다.
이 객체는 함수처럼 사용될 수 있다. return값은 poly1d 객체이고, 아래와 같이 나온다.
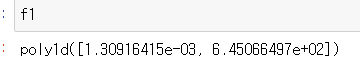
np.linespace(start, stop, num): 시작값과 종료값을 포함하는 범위에서 균일한 간격의 숫자를 생성한다.
여기서는 100,000부터 700,000까지의 인구수 범위에서 100개의 점을 생성한다.- plt.scatter에서 s=50은, 마커의 크기를 지정한다.
plt.plot은 선형회귀모델을 선 그래프로 표시한다. fx를 x값으로(즉, 100000~70000 사이의 100개의 점을), f1(fx)를 y값으로 사용한다.ls='dashed'는 선의 스타일 지정. 점선으로.lw=3: 선의 두께 지정.color='g': 선의 색상 지정.
1-7 좀 더 설득력 있는 자료 만들기
#오차 칼럼 만들기
data_result['오차'] = np.abs(data_result['소계'] - f1(data_result['인구수']))
#오차 큰 순으로 정리
df_sort = data_result.sort_values(by='오차', ascending=False)
plt.figure(figsize=(14,10))
plt.scatter(data_result['인구수'], data_result['소계'],
c = data_result['오차'], s= 50)
plt.plot(fx, f1(fx), ls='dashed', lw = 3, color='g')
for n in range(10):
plt.text(df_sort['인구수'][n] * 1.02, df_sort['소계'][n]*0.98,
df_sort.index[n], fontsize=15) #숫자 조정하면서 텍스트 위치 확인
plt.xlabel('인구수')
plt.ylabel('인구당비율')
plt.colorbar()
plt.grid()
plt.show()- 오차 칼럼을 보면 실제값인 df['소계']와, 추정한 함수f1에 실제 인구수를 넣은 값의 차이를 np.abs로 절댓값으로 구해서 오차를 구하고 있다.
- 그렇게 구한 오차를 칼럼으로 만들어, 오차 큰 지역부터 정렬하고 있다.
- 산점도를 생성하는 plt.scatter에서 c = data_result['오차']를 넣고 있다.
c는 색상을 지정하는 매개변수인데, 하나의 색상 / 색상 시퀀스 / 수치 데이터 3종류가 들어갈 수 있다.
하나의 색상만 들어가면, 그 색상으로 통일된다.
색상 시퀀스를 넣을 때는, 시퀀스의 길이가 데이터 포인트의 수와 동일해야 한다.
수치 데이터를 넣으면, 데이터의 수치에 따라 색상을 매핑한다. 이때 cmap=으로 색상 맵을 가이 지정할 수 있다. 그러면 색상 맵에 따라 수치의 크기를 다른 색상으로 표현한다.
즉, 여기서는 오차의 크기에 따라 산점도의 색상이 바뀌도록 나타내고 있다. - for문은 오차가 큰 상위 10개 지역을 글자로 표기하기 위해 나타낸다.
plt.text(x, y, text, fontsize=15)는, x와 y좌표에 text를 fontsize로 표시한다는 뜻이다.
여기서 x는 인구수의 102%로 기존의 약간 오른쪽, y는 소계의 98%로 약간 아래쪽에 위치시킨다. 그리고 index[n]인, 구 이름을 표기시킨다. fontsize는 15로 고정시킨다.plt.colorbar()는 색상바를 호출해서 표시하고 있다.
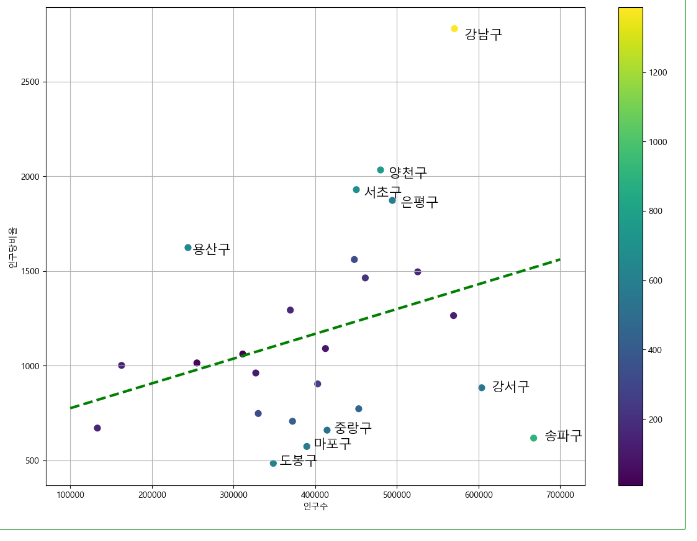
- 결과를 보면, 서울시의 다른 구와 비교했을 때, 강남 양천 서초 은평 용산은 인구대비 CCTV가 많다.

일본에서 일하는 게임 기획자. 시시해서 죽어버리지 않게, 재밌고 의미 있는 컨텐츠에 관심 있습니다. 그 도구로 데이터, AI도 찝적댑니다.