0 기본 세팅 - googlemaps, folium
- 모듈 2개 설치
pip install googlemaps
pip install folium
0-1 googlemaps
- Python에서 GoogleMapsAPI를 사용하는 클라이언트 라이브러리.
- 구글맵 키 만들기
https://velog.io/@sukqbe/API-%EA%B5%AC%EA%B8%80-%EC%A7%80%EB%8F%84Google-Map-%EC%[…]8%EA%B8%B0-API-Key-%EB%B0%9C%EA%B8%89%EB%B0%9B%EA%B8%B0-qumur49u
#구글맵스 클라이언트 객체 생성
gmaps_key = '구글키'
gmaps = googlemaps.Client(key=gmaps_key)
#검색
tmp = gmaps.geocode('서울중부경찰서', language = 'ko')
#formatted_address값
print(tmp[0].get("formatted_address"))
#위도 경도 정보
tmp_loc = tmp[0].get('geometry')
print('위도 ==>', tmp_loc['location']['lat'])
print('경도 ==>', tmp_loc['location']['lng']) googlemaps.Client(key=): GoogleMapsAPI와 통신할 수 있는 Client 객체를 생성한다. 이 때 key에는 내 구글맵스 키를 입력한다.client객체.geocode('문자열', language='ko'): 지정한 문자열의 주소에 대한 지오코딩 쿼리를 실행하고, 결과를 지정한 언어로 반환한다. 여기서는 한국어.
반환한 값은 주어진 주소에 대한 상세 정보를 포함하는 Json형식.
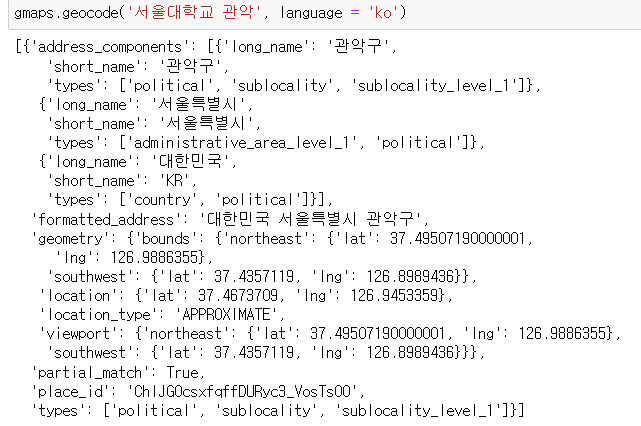
dict.get(key): 딕셔너리 자료형의 키에 해당하는 값을 갖고 오는 것. 특별한 메서드가 아니라.- 여기서 Json자료형이 리스트 안에 딱 1개 들어 있기 때문에, get을 쓰기 위해 tmp[0]으로 접근한다.
formatted_address는 주소가 들어 있다.geometry에는 여러가지 값이 있지만, 위도, 경도 정보가 들어 있다.
tmp[0].get('geometry')['location']['lat']으로 하면 위도, 마지막에['lng']으로 하면 경도를 들고 온다.

0-2 folium
- Python에서 인터랙티브한 지도 생성하는 라이브러리. leaflet.js 기반, 파이썬 데이터 구조를 사용해 지리데이터 시각화, 다양한 지도 스타일과 상호작용 기능 구현.
folium.Map(location=[위도, 경도], zoom_start=13, tiles='OpenStreetMap'): 위도 경도를 숫자로 입력하면, 그 부분을 중심으로 지도 객체(Map)를 만든다.- 매개변수
zoom_start=는 확대 비율이다. 크면 클수록 더 줌 한다.tiles=: 지도의 스타일을 지정한다. OpenStreetMap은 OpenStreetmap에서 제공하는 기본 스타일 지도. 이 외에도 cartodbpositron, Stamen Terrain', 'Stamen Toner', 'Stamen Watercolor', 'CartoDB positron', 'CartoDB dark_matter'등이 있다.
- 매개변수
json.load(open(geo_path, encoding='utf-8')): Json 모듈은 파이썬 표준 라이브러리로, JavaScriptObjectNotation 형식 데이터를 파싱하는 도구다.
json.load 함수는 json 형식 파일을 읽어서, 그 내용을 python 객체로 변환한다.
import json
geo_path = '../data/02. skorea_municipalities_geo_simple.json'
geo_str = json.load(open(geo_path, encoding='utf-8')) - 여기서 geo_path는 대한민국 지자체 경계 정보를 담은 json파일의 경로.
- open함수로 geo_path에 지정된 경로 파일을 UTF-8 인코딩으로 연다.
folium.Choropleth(): 지리적 데이터와 실제 데이터값을 연결, 각 지역의 데이터값에 따라 다른 색상의 영역을 생성한다. 즉, 지도 위의 히트맵.ㄹ- 매개변수
geo_data=: 지리적 경계 정의하는 데이터data=: 각 지역별로 표시하려는 실제 데이터.columns: data 매개변수에서 사용할 데이터플레임 지정. 첫 번째 컬럼은 지역의 이름 또는 ID, 두 번째 컬럼은 해당 지역의 데이터값.fill_color: 채우는데 사용할 지도 색상 팔레트.key_on: geo_data에서 지역의 경계를 정의하는 키와, data 매개변수에서 제공하는 데이터를 연결하는데 사용하는 속성. 보통 GeoJSON의 특성 내 속성에 대한 경로를 문자열로 지정. GeoJSON의 각 특성 ID가 지역 데이터와 연결되어 있으면, feature.id와 같이 사용.
이 json데이터 보면 id: 강동구 이런 식으로 되어 있다. 이걸 일치시키면 된다.
- 매개변수
folium.add_to(): folium 라이브러리의 메서드로, folium의 요소(choropleth, marker, layer) 등을 다른 folium 객체에 추가한다. 주로, folium.Map 객체에 여러 시각적 요소 추가.
map = folium.Map(location=[37.5502, 126.982], zoom_start=11,
tiles='Stamen Toner')
folium.Choropleth(geo_data = geo_str,
data = crime_anal_norm['살인'],
columns = [crime_anal_norm.index, crime_anal_norm['살인']],
fill_color = 'YlGnBu', #PuRd, YlGnBu
key_on = 'feature.id').add_to(map)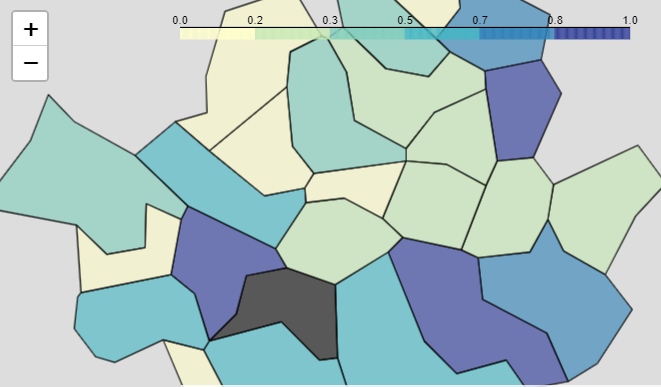
folium.Marker(위도, 경도): 지정한 위도, 경도에 마커를 찍는다.folium.CircleMarker(location=[위도, 경도], radius=, color=, fill_color, fill=True): 원형 마커를 추가.- 매개변수
radius=: 원의 반지름. 여기에 변수의 크기를 넣으면, 변수 따라 달라진다.color=: 원의 윤곽선 지정fill: 원의 내부를 색상으로 채울지.fill_color: fill=True일 때, 원의 내부를 어떤 색상으로 채울지.
- 매개변수
Map.save('.html'): 생성된 folium 지도 객체를 html 파일로 저장. 현재 지도의 상태(추가된 모든 레이어와 설정 포함)을 외부 파일로 내보낼 수 있다.
1 강남 3구 범죄율 분석
1-1 데이터 불러오기 및 정제
crime_anal_police = pd.read_csv('../data/02. crime_in_Seoul.csv', thousands=',', encoding='euc-kr')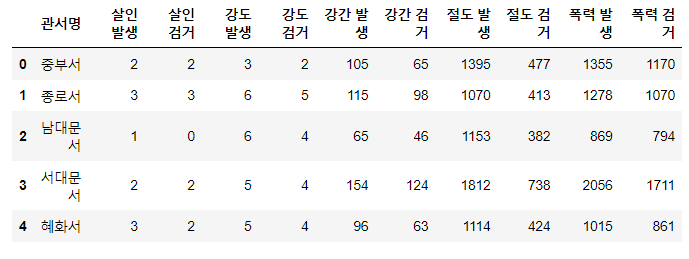
#오류 발생시키는 행 삭제
crime_anal_police.drop([11], inplace = True)
#관서명의 정보를 중부서 => 성루중부경찰서로 바꿔서, 나중에 검색에 이용
station_name = []
for name in crime_anal_police['관서명']:
station_name.append('서울' + str(name[:-1]) + '경찰서')
station_name1-2 googlemaps 이용해서 주소, 위도, 경도 뽑기
station_address = []
station_lat = []
station_lng = []
for name in station_name:
tmp = gmaps.geocode(name, language = 'ko')
station_address.append(tmp[0].get("formatted_address"))
tmp_loc = tmp[0].get('geometry')
station_lat.append(tmp_loc['location']['lat'])
station_lng.append(tmp_loc['location']['lng'])
print('name' + '-->' + tmp[0].get("formatted_address"))- 앞서, station_name에 검색할 경찰서이름의 리스트 만들었다
- tmp = gmaps.geocode에 하나씩 입력해서 검색
- formatted_address로 주소 뽑아서 append
- geometry에서 위도, 경도 뽑아서 각자 append
1-3 구별 데이터 정리
gu_name = []
for name in station_address:
tmp = name.split()
tmp_gu = [gu for gu in tmp if gu[-1] == '구'][0] #구로 끝나는 것을 가져온 후 저장
gu_name.append(tmp_gu)
crime_anal_police['구별'] = gu_name- 주소를 띄어스기별로 쪼개서, 그 중에 마지막 글자가 ~구로 끝나는 것만 저장 => 그걸 ['구별']이라는 column으로 새로 정리
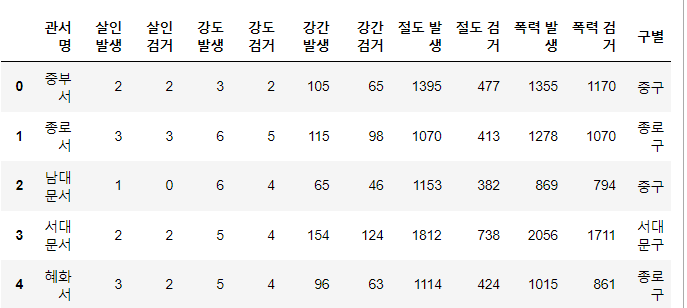
#피봇테이블 만듦
crime_anal = pd.pivot_table(crime_anal_raw, index='구별', aggfunc=np.sum) - 위에도 애초에 서별로 나눠져있었지만, 같은 중구에도 2개의 경찰서가 있다. 즉, 그걸 '구별'이라는 기준으로 합쳐서, 모두 합친다(np.sum).
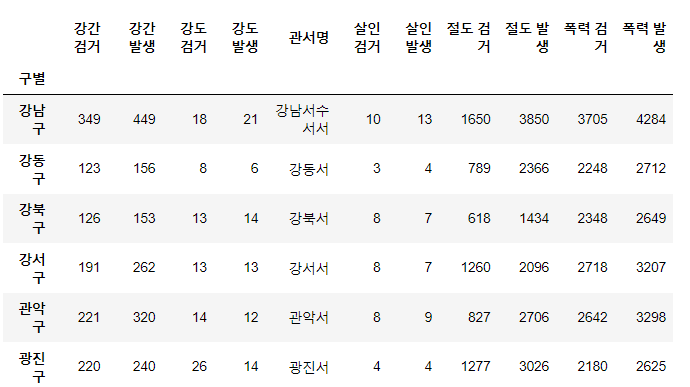
1-4 데이터 전처리
- 우리의 타겟은 검거건수가 아니라 검거율이다. 그래서 검거율로 새 칼럼 넣고, 나머진 지운다.
#검거율 만들고 필요없는 데이터 삭제
crime_anal['강간검거율'] = crime_anal['강간 검거']/crime_anal['강간 발생']*100
crime_anal['강도검거율'] = crime_anal['강도 검거']/crime_anal['강도 발생']*100
crime_anal['살인검거율'] = crime_anal['살인 검거']/crime_anal['살인 발생']*100
crime_anal['절도검거율'] = crime_anal['절도 검거']/crime_anal['절도 발생']*100
crime_anal['폭력검거율'] = crime_anal['폭력 검거']/crime_anal['폭력 발생']*100
del crime_anal['강간 검거']
del crime_anal['강도 검거']
del crime_anal['살인 검거']
del crime_anal['절도 검거']
del crime_anal['폭력 검거']
#100 넘어가는 값 전부 100으로 통일
con_list = ['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']
for column in con_list:
crime_anal.loc[crime_anal[column] > 100, column] = 100
#컬럼명 변경
crime_anal.rename(columns = {'강간 발생':'강간',
'강도 발생':'강도',
'살인 발생':'살인',
'절도 발생':'절도',
'폭력 발생':'폭력'}, inplace=True)- 먼저 새롭게 검거율이란 행 추가하고, 기존에 있던 검거수에 대한 행을 지운다.
- 그리고 검거율이 100이 넘는 곳은 100으로 맞춘다. 여기서 loc을 재밌게 사용. 행은 조건을 걸고, 열은 열이름 사용하는데, 그걸 또 for문으로 돌린다.
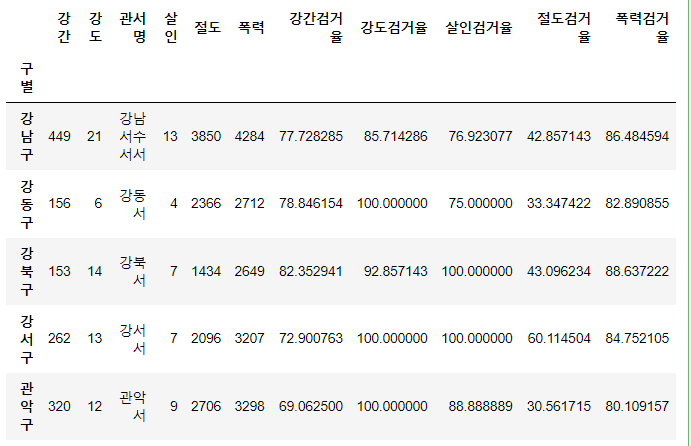
- 다음으로, 값들을 0~1사이의 값으로 바꾸기 위해, min-max 스케일링을 한다.
- min-max 스케일링은 (현재값 - 최솟값) / (최댓값 - 최솟값)
#값 한 번 확인
print(crime_anal['절도'].max())
print(crime_anal['절도'].min())
from sklearn import preprocessing # sklearn에 잇는 전처리를 부름
col = ['강간', '강도', '살인', '절도', '폭력']
x = crime_anal[col].values
min_max_scaler = preprocessing.MinMaxScaler()
x_scaled = min_max_scaler.fit_transform(x.astype(float))
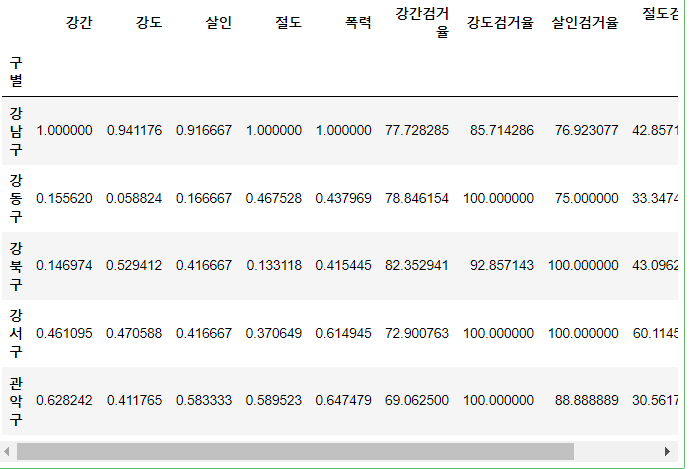
crime_anal_norm = pd.DataFrame(x_scaled, columns = col, index = crime_anal.index)
# 0~1사이의 값으로 값 변경 => 공식: (값 - 최솟값) / (최댓값 - 최소값)
col2 = ['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']
crime_anal_norm[col2] = crime_anal[col2]
crime_anal_norm.head()- 먼저 처리할 데이터 컬럼을 col로 리스트로 만들고 지정
- crime_anal[col].values로, 행별로 값들을 모두 추출한다. 아래와 같은 모양으로 나온다.

from sklearn import preprocessing: 여기서 sklearn은 scikit-learn. 사이킷런은 머신러닝 라이브러리이고, preprocessing은 머신러닝 작업 위한 초기 단계의 관련 툴들. 스케일링, 정규화, 이진화, 인코딩, 결측치 처리 등을 지원한다.preprocessing.MinMaxScalar(): MinMaxScalar 객체를 생성한다. 여기 데이터를 입력하면 min-max 스케일링을 한다.fit_transform: preprocessing에 속한 메서드로, Transformer 클래스를 구현하는 모든 객체에 사용할 수 있다. 훈련 데이터셋에 대한 피팅과 변환을 한 번에 수행한다.
fit단계: minmaxscalar의 경우, 데이터의 최솟값과 최댓값을 계산한다.
transform단계: 학습된 모델을 사용해 데이터를 변환한다. 스케일링의 경우, 실제 데이터값을 정규화된 스케일로 변환한다.x.astype(float): x는 넘파이 배열이다. 넘파이 배열 혹은 DF, 시리즈의 데이터 타입을 바꾸는 메서드고, float으로 바꾼다.
그 데이터를 변환에 적용한다.
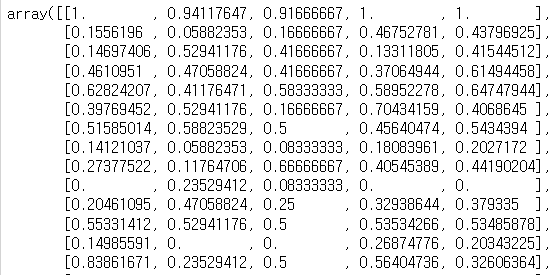
- crime_anal_norm이라는 새로운 데이터 프레임으로 만든다. 이 경우 열이름과 인덱스는 모두 기존의 것을 갖고 와서 사용한다.
- 그리고 정규화하지 않은 열들도 추가한다.
- CCTV 데이터 합치기
result_CCTV = pd.read_csv('../data/01. CCTV_result.csv', encoding='UTF-8',
index_col='구별')
crime_anal_norm[['인구수', 'CCTV']] = result_CCTV[['인구수', '소계']]- 여기서 인덱스가 같아야 합쳐지므로 조심.
- 범죄 5가지를 모두 합친 결과 만들기
col = ['강간','강도','살인','절도','폭력']
crime_anal_norm['범죄'] = np.sum(crime_anal_norm[col], axis=1)
col = ['강간검거율','강도검거율','살인검거율','절도검거율','폭력검거율']
crime_anal_norm['검거'] = np.sum(crime_anal_norm[col], axis=1) 
1-5 시각화
#한글 깨짐 방지용 코드
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
plt.rcParams['axes.unicode_minus'] = False
f_path = "C:/Windows/Fonts/malgun.ttf"
font_name = font_manager.FontProperties(fname=f_path).get_name()
rc('font', family=font_name)
#오류 메시지 제거용
import warnings
warnings.filterwarnings(action='ignore')
import seaborn as sns
sns.pairplot(crime_anal_norm, x_vars=["인구수", "CCTV"],
y_vars=["살인", "강도"], kind='reg', size=3)
plt.show()- 여기서 reg는 선형 회귀선을 포함한 산점도를 그린다.

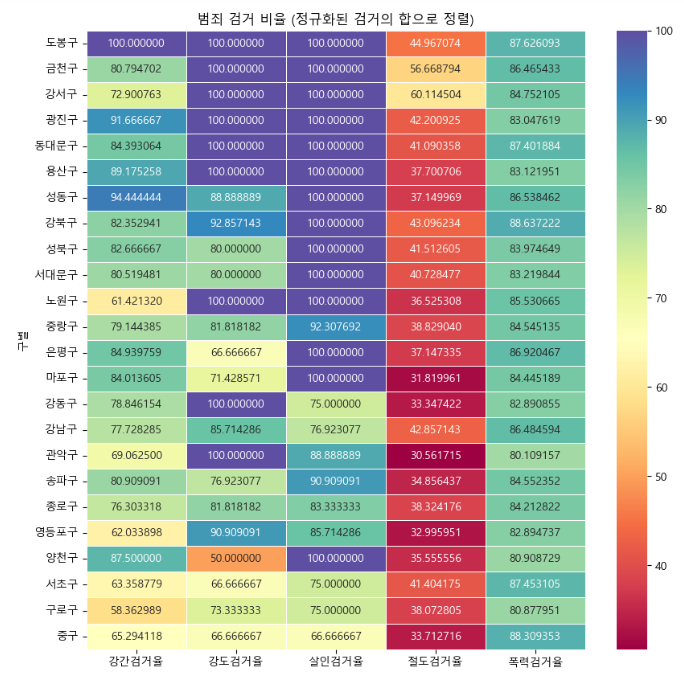
- 검거율 히트맵으로 만들기
#검거율(검거수/최대검거수)
tmp_max = crime_anal_norm['검거'].max()
crime_anal_norm['검거'] = crime_anal_norm['검거'] / tmp_max * 100
#정렬
crime_anal_norm_sort = crime_anal_norm.sort_values(by='검거', ascending=False)
#시각화
target_col = ['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']
plt.figure(figsize = (10,10))
sns.heatmap(crime_anal_norm_sort[target_col], annot=True, fmt='f',
linewidths=.5, cmap='Spectral')
plt.title('범죄 검거 비율 (정규화된 검거의 합으로 정렬)')
plt.show()- 여기서 기존에 crime_anal_norm['검거']는 5개의 범죄 검거율 0~100의 합.
- 이를 현재값/최댓값으로 나눠서 0~100%로 만듦
sns.heatmap(): 히트맵 형태로 시각화. 데이터의 값에 따라 색상의 강도를 다르게 해서 데이터 패턴이나 변화를 보여줌.
- 매개변수
-annot=True: 각 셀에 데이터값 표시.
-fmt=f: annot의 데이터값을 어떻게 표기할지. f는 고정 소수점 형식.
-linewidths=.5: 셀간 경계선 너비.
-cmap=: 히트맵에 사용할 컬러맵.
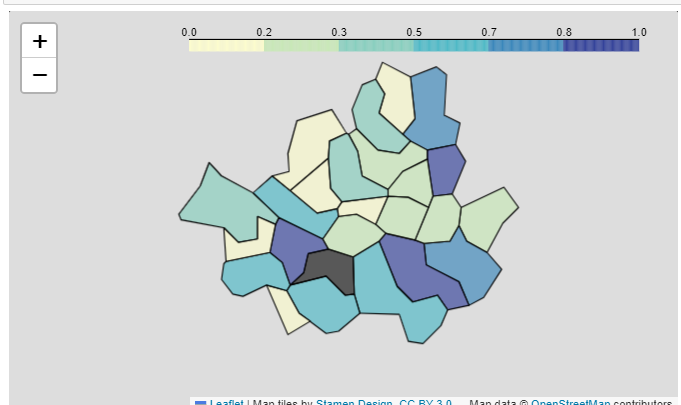
1-6 지도에 시각화
import folium
import pandas as pd
import json
geo_path = '../data/02. skorea_municipalities_geo_simple.json'
geo_str = json.load(open(geo_path, encoding='utf-8')) #json파일 읽어오기
#살인이 많이 일어난 지역 확인 가능
map = folium.Map(location=[37.5502, 126.982], zoom_start=11,
tiles='Stamen Toner')
folium.Choropleth(geo_data = geo_str,
data = crime_anal_norm['살인'],
columns = [crime_anal_norm.index, crime_anal_norm['살인']],
fill_color = 'YlGnBu', #PuRd, YlGnBu
key_on = 'feature.id').add_to(map)
map- folium, json 모듈에 대해서는 위의 folium 부분에 있다.
- json.load로 한국 시도의 경계 json 파일을 읽어와서 파싱한다.
- folium.Map으로 지도를 먼저 그린다. 이때 서울의 위치를 그린다. 여기서 지정 안해놓으면, 위치가 세계지도로 잡힐 수도 있고 그렇기 때문에.
- folium.Choropleth로 그림을 그린다. 여기서 데이터는 ['살인']으로, columns의 첫 번째는 일치하는 위치, 2번째는 실제 사용할 데이터, key_on은 결합할 방식(여기서는 id).
#위도 경도를 데이터프레임에 입력
crime_anal_raw['lat'] = station_lat
crime_anal_raw['lng'] = station_lng
#tmp를 검거율을 합친 값으로 해서 전처리
col = ['살인 검거', '강도 검거', '강간 검거', '절도 검거', '폭력 검거']
tmp = crime_anal_raw[col] / crime_anal_raw[col].max()
crime_anal_raw['검거'] = np.sum(tmp, axis=1)
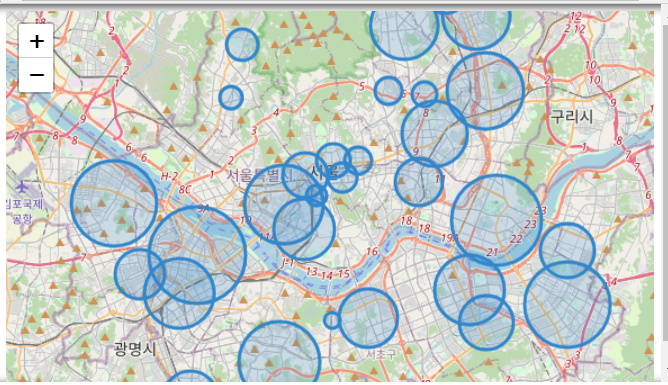
#시각화
map = folium.Map(location=[37.5502, 126.982], zoom_start=11)
#마커 하나씩 찍어주기
for n in crime_anal_raw.index:
folium.CircleMarker([crime_anal_raw['lat'][n], crime_anal_raw['lng'][n]],
radius = crime_anal_raw['검거'][n]*10,
color = '#3186cc', fill_color="#3186cc", fill=True).add_to(map)
map - 먼저 전처리로, 각 열에 지금 행의 검거수/그 열의 최대 검거수로 정규화하고, 그걸 다 더해서 '검거'라는 열을 만든다.
- folium.CircleMarker로 마커를 찍는데, radius에 검거율 * 10을 집어넣어서, 검거율에 따라 크기가 다르게 나타나게 한다.
4 주유소

일본에서 일하는 게임 기획자. 시시해서 죽어버리지 않게, 재밌고 의미 있는 컨텐츠에 관심 있습니다. 그 도구로 데이터, AI도 찝적댑니다.