0
- 오늘의 목표는 인스타에서 제주도 맛집을 크롤링
- 관련 정보를 카카오 API에서 들고 온 지도 위에 시각화
1 인스타 크롤링
1-1 세팅하고, 인스타 로그인까지
#기본설정. 다음부터 그냥 이거 복사붙여넣기해서
#크롬 드라이버 자동으로 다운받는 webdriver-manager 설치.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
#브라우저 꺼짐 방지
chrome_options = Options()
chrome_options.add_experimental_option("detach", True)
#불필요한 에러 메시지 없애기
chrome_options.add_experimental_option("excludeSwitches", ["enable-logging"]) #셀레니움 로그 무시
#서비스랑 드라이버 객체 생성. 세팅은 아니지만, 이거 안하면 어차피 진행이 안되서.
service = Service(executable_path=ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=chrome_options)- 이건 그냥 selenium 쓸 때 그냥 매번 붙여서 쓰는 설정
import time
#인스타로 이동
driver.get('https://instagram.com')
time.sleep(3)
#모듈 호출
from selenium.webdriver.common.keys import Keys
#인스타 로그인
driver.implicitly_wait(10)
login_id = driver.find_element(By.CSS_SELECTOR, 'input[name="username"]')
login_id.send_keys('아이디') #아이디
login_pwd = driver.find_element(By.CSS_SELECTOR, 'input[name="password"]')
login_pwd.send_keys('비번') #비번
driver.implicitly_wait(10)
login_pwd.submit()
time.sleep(2)
login_id.send_keys(Keys.ENTER)- 인스타로 이동하고, time.sleep(3)은 로그인 될때까지 기다리기
driver.implicity_wait(): Webdriver가 요소 찾을 때까지 최대 지정 시간까지 대기하도록 설정. 이 시간 내에 요소 발견 못하면 예외 발생.- 아이디 입력창, 비밀번호 입력창에 각각 send_keys로 보낸다. 참고로 아이디의 selector는
<input aria-label="전화번호, 사용자 이름 또는 이메일" aria-required="true" autocapitalize="off" autocorrect="off" maxlength="75" class="_aa4b _add6 _ac4d _ap35" dir="" type="text" value="" name="username">와 같이 되어있다. 그래서 input[name='username']. login_pwd.submit(): .submit은 폼(form) 제출에 사용. 현재 요소(여기선 login_pwd)가 속한 폼이 제출. 즉, 로그인 버튼을 클릭하지 않고도 로그인 폼을 서버로 전송.login_id.send_keys(Keys.ENTER): 인스타 아이디창에서 엔터 누르기. 위에서 이미 submit해서 중복 행동인데, 혹시 안먹었으면 실행하는 듯.- 여기서 Keys클래스는 다양한 키보드 키를 나타내는 상수 제공. 엔터, ESC, F1, F2, 화살표 등.
1-2 인스타 검색 결과 단계별로 들고오기
1-2-1 인스타 검색 결과 페이지
def insta_searching(word):
url = 'https://www.instagram.com/explore/tags/' + word
return url- word를 입력해서 그 해쉬태그 검색을 하는 함수를 만든다
1-2-2 첫 번째 게시글 열기
def select_first(driver):
first = driver.find_element(By.CSS_SELECTOR, 'div._aabd')
first.click()
time.sleep(5)- 첫 번째 사진의 selector를 지정해, click한다.
- 로딩되는 시간 5초동안 sleep
1-2-3 콘텐츠 들고오기
def get_content(driver):
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
try:
content = soup.select('div._a9zr')[0].text
except:
content = ' '
tags = re.findall(r'#[^\s#,\\]+', content)
date = soup.select('time._aaqe')[0]['datetime'][:10]
data = [content, date, tags]
return data- html에 driver.page_source로 html의 소스코드를 string을 들고와서, BeautifulSoup 객체로 파싱한다.
'div._a9zr'는<div class= _a9zr>처럼 되어 있는 것이고, 인스타의 글 부분이다.select로 들고 왔기 때문에 하나만 있어도 리스트로 반환된다. =>[0]로 꺼내준다..text로 본문을 꺼낸다.- try, except로 글이 없거나 에러가 뜨면 생략한다.
re.findall(r'#[^\s#,\\]+', content)이 부분은 정규문자열과 패턴 일치하는 걸 모두 찾아오는 건데, 맨 앞의 #는 #로 시작하는 글자라는 뜻. 그 뒤의 []는 문자 집합을 나타내고 여기서 ^가 오면 이 글자들을 제외한 문자들과 매칭한다는 뜻. \s는 공백, #, , , \는 글자 그 자체의 \이므로, 공백, #, \를 제외한 글자를 들고온다는 것. 그리고 +는 앞의 패턴이 하나 이상 반복될 때 매칭.
결국 해시태그로 시작하는 문자열, 그 뒤에 공백, #, , , \ 같은 글자가 안들어간 문자를 반환하는 거다. => 해시태그 추출.'time._aaqe'이 부분은 위의 select와 마찬가지로 [0]으로 추출하는데, 가져오면[<time class="_aaqe" datetime="2024-02-22T05:53:06.000Z" title="2024년 2월 22일">19시간 전</time>]같은 느낌이다.
여기서 19시간 전을 들고오면 바뀌기 때문에, 날짜를 가져오는 게 좋다. 따라서 ['datetime']을 들고오고, 거기서 2024-02-22까지만 들고오기 때문에 [:10].- 그리고 data에 이 모든 정보를 담아서 반환하는 함수다.
1-2-4 다음으로 넘기기
def move_next(driver):
right = driver.find_element(By.CSS_SELECTOR, 'div._aaqg._aaqh')
right.click()
time.sleep(3)- 다음으로 넘기는 버튼을 find해서, click으로 넘기고, 로딩되는 시간을 기다린다.
1-2-5 반복문으로 돌린다.
word = '제주도맛집'
url = insta_searching(word)
driver.get(url)
time.sleep(7)
select_first(driver) # 첫 게시글 열기
results = []
#페이지에 27개 밖에 없어서, 100개 처음에 설정했는데 안넘어간다
target = 20
for i in range(target):
try:
data = get_content(driver)
results.append(data)
move_next(driver)
except:
time.sleep(5)
move_next(driver)
print(results)- 위에서 만든 함수들을 이용해서 자동으로 모든 결과들을 들고온다.
1-3 저장
results_df = pd.DataFrame(results)
results_df.columns = ['content', 'data', 'tags']
results_df.to_excel('../data/jejudo_crawling0.xlsx')1-4 정제, 해시태그 정보 추출
#중복 제거. 매우 중요하다.
results_df.drop_duplicates(subset=['content'], inplace=True)
#해시태그 데이터 불러오기
tags_total = []
for tags in raw_total['tags']:
#2:-2는 이게 str인데, 그 str 안에 ['']이 포함되어 있어서 그거 자르기
tags_list = tags[2:-2].split("', '")
for tag in tags_list:
tags_total.append(tag)
tags_total- 중복값 제거는 매우 중요하다. 특히 광고나 중복 내용 있을 수 있어서.
- tags에는 ['#제주핫플레이스', '#제주여행', '#제주여행', '#제주도여행', '#제주가] 와 같은 문자열로 저장되어 있다. 그래서 앞뒤의 [''] 부분을 잘라내고, ,로 split해서, 그 각자를 또 하나씩 저장한다.
1-5 해시태그 출현 빈도 집계, 그래프와 워드클라우드 시각화로 체크
#모듈 부르기
from collections import Counter
#
tag_counts = Counter(tags_total)
#데이터 확인
tag_counts.most_common(50)
#정제
STOPWORDS = ['#일상', '#선팔', '#제주도', '#jeju', '#반영구', '#제주자연눈썹',
'#서귀포눈썹문신', '#제주눈썹문신', '#소통', '#맞팔']
tag_total_selected = []
for tag in tags_total:
if tag not in STOPWORDS:
tag_total_selected.append(tag)
tag_counts_selected = Counter(tag_total_selected)
tag_counts_selected.most_common(50)Counter()는 파이썬 collections모듈에 포함된 특수한 딕셔너리 서브클래스. 객체를 세서, 요소를 key로, 해당 요소의 카운트를 value로 하는 딕셔너리 형태로 저장.most_common(n)는 상위 n개를 각각 튜플로 구성된 리스트로 반환. n이 없으면 그냥 모든 요소 내림차순으로.- 무의미한 해시태그나, 광고처럼 이상해보이는 해시태그는 제거해서 거른다.
#막대그래프 시각화
#폰트 적용
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import font_manager, rc
font_name = 'malgun gothic'
rc('font', family=font_name)
#시각화에 필요한 데이터 추출
tag_counts_df = pd.DataFrame(tag_counts_selected.most_common(30))
tag_counts_df.columns = ['tags', 'counts']
#시각화
plt.figure(figsize=(10, 8))
sns.barplot(x='counts', y='tags', data=tag_counts_df)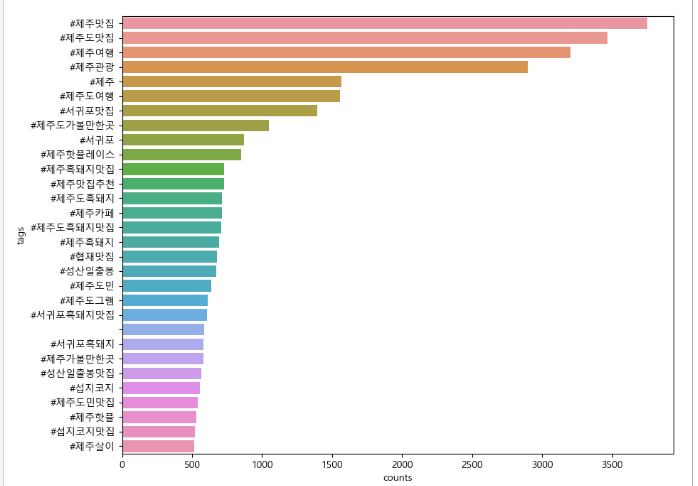
#워드 클라우드 시각화
#모듈 부르기, font 찾기
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import platform
font_path="C:/Windows/Fonts/malgun.ttf"
wc = WordCloud(font_path = font_path,
background_color = 'white',
max_words = 100,
relative_scaling = 0.3,
width = 800,
height = 400,
).generate_from_frequencies(tag_counts_selected)
plt.figure(figsize=(15, 10))
plt.imshow(wc)
plt.axis('off')
plt.savefig('../data/2_tag_wordcloud.png')- 여기서
generate_from_frequencies는 dictionary가 아니라 (word, frequency)형태의 튜플 리스트도 가능.
2 카카오 검색 API 활용 장소 정보 들고오기
2-1 세팅
- Kakao Developers 가입 및 로그인 하기
https://developers.kakao.com/
- Kakao Developers 가입 및 로그인 하기
- 애플리케이션 사용 신청하기
[내 애플리케이션] → [애플리케이션 추가하기] 클릭 => 아무거나 하나 만들기
- 애플리케이션 사용 신청하기
- REST API 키 확인하기
- 참고문서: 문서 --> 지도/로컬 API 가이드 --> 개발 가이드 맨 밑에 --> 더 보기 REST API 레퍼런스 --> https://developers.kakao.com/docs/latest/ko/reference/rest-api-reference ==> 로컬 --> 키워드로 장소 검색 --> https://developers.kakao.com/docs/latest/ko/local/dev-guide#search-by-keyword
2-2 카카오 API에서 정보 들고오는 함수 만들기
searching = '서초 스타벅스'
url = 'https://dapi.kakao.com/v2/local/search/keyword.json?query={}'.format(searching)
headers = {
"Authorization": "KakaoAK REST API키" #KakaoAK {자기API키}
}
places = requests.get(url, headers = headers).json()['documents']- 먼저 requests.get(url, headers=hearders)로 정보를 요청한다.
이때 url은 위에 있는 지역검색 요청 주소다.
searching이라는 키워드를 넣고,
headers에 내 API 키를 같이 넣어 보낸다. headers로 내 API를 같이 보내지 않으면 거부 뜬다.
headers 양식을 잘 맞춘다. - 여기서는 지역검색인데, 카카오 로그인, 카톡 메시지 보내기, 음성, 번역, 비전, 검색 등 여러 기능이 있다.
- 여기서 places는 Response객체로 JSON 데이터로 보낸다. 이를
.json()을 하면 파이썬 딕셔너리로 바뀐다. 아래와 같은 구조로 서초 스타벅스라는 검색 결과들의 각종 정보를 딕셔너리 형태로 보내준다. 그리고 가장 상위에 'documents'라고 되어 있다. 그래서 ['documents']로 빼낸다.

def find_places(searching):
url = 'https://dapi.kakao.com/v2/local/search/keyword.json?query={}'.format(searching)
headers = {
"Authorization": "KakaoAK 자기API키" #KakaoAK 자기API키
}
places = requests.get(url, headers = headers).json()['documents']
place = places[0]
name = place['place_name']
x = place['x']
y = place['y']
data = [name, x, y, searching]
return data- 위의 과정을 함수로 만든다. 이때, place = places[0]는 리스트 안에 1개의 딕셔너리로 들어 있어서 빼내기.
- 위의 이미지에서 본 것처럼 place_name에 가게 이름이 있고, x, y에 위도 경도가 있다. 그것들을 다 빼와서 return.
2-3 데이터 준비
- 인스타에 언급된 장소만 추출 => 카카오 API에서 뽑는다 => 나중에 언급된 횟수랑 같이 시각화
#장소가 포함된 인스타 관련 자료
raw_total = pd.read_excel('../data/insta_data/1_crawling_raw.xlsx')
#위치랑, 그게 몇 번 나왔는지만 추출 => 데이터프레임으로
location_counts = raw_total['place'].value_counts()
location_counts_df = pd.DataFrame(location_counts)
#다시 장소명만 리스트로(value_counts 과정에서 인덱스에 장소명이)
locations = list(location_counts.index)2-4 카카오 API에서 자료 다 들고오기 => 데이터 전처리
#모듈 들고오기
from tqdm import tqdm_notebook
import time
locations_inform = []
for location in tqdm_notebook(locations):
try:
data = find_places(location)
locations_inform.append(data)
time.sleep(0.5)
except:
pass
locations_inform_df = pd.DataFrame(locations_inform)
locations_inform_df.columns = ['name_official', '경도', '위도', '인스타위치명']
locations_inform_df.to_excel('../data/insta_data/33_locations.xlsx')- 위에서 만든 리스트의 장소명들을 하나씩 위에 만든 함수 find_places에 넣는다.
- 그럼 카카오API에 해당 장소 검색해서, 해당 장소명, 위도, 경도를 return한다.
- 그걸 넣어서 데이터로 만든다.
- time.sleep(0.5)로 딜레이 반영.
- 그리고 데이터프레임으로 만들고, 컬럼명해서 저장
#위에 만든 count랑 방금 만든 위치랑 병합
location_data = pd.merge(locations_inform_df, location_counts_df, how='inner',
left_on = 'name_official', right_index=True)
#데이터 중복 점검하기
location_data['name_official'].value_counts()
#장소 이름 기준으로 병합한다
location_data = location_data.pivot_table(index=['name_official', '경도', '위도'],
aggfunc='sum')- merge로 inform이랑 counts랑 병합하는데, inner 즉 두 프렝미에 모두 존재하는 key에 대해서만 조인한다. 그리고 왼쪽은 name열을, 오른쪽은 인덱스가 기준이 된다.
- value_counts로 똑같은 이름이 여러 번 나오는지 센다. 여러 번 나오는 경우가 있다.
- pivot_table을 통해 name_official, 경도, 위도를 기준으로 데이터를 그룹화한다. 이때 집계 함수로 sum을 지정한다. 즉, name_official, 경도, 위도의 값이 같은 행들에 대해 모든 수치형 열의 값을 합산한다. => 데이터 중복값들이 하나로 합쳐진다.
2-5 시각화
2-5-1 개별 표시
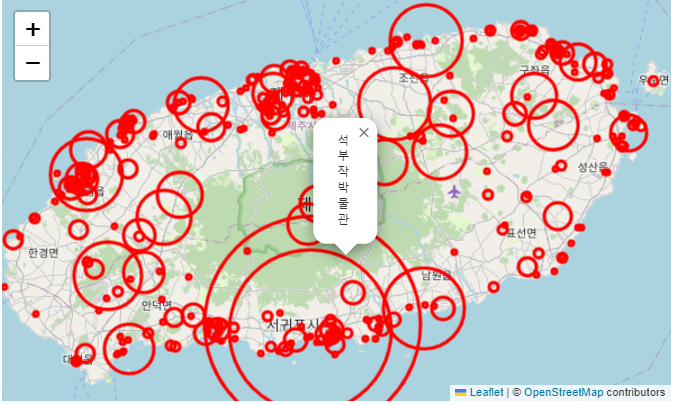
import folium
Mt_Hanla=[33.362500, 126.533694]
map_jeju = folium.Map(location=Mt_Hanla, zoom_start=11)
for i in range(len(location_data)):
name = location_data['name_official'][i] # 공식 명칭
count = location_data['place'][i] # 게시글 개수
size = int(count)*2
long = float(location_data['위도'][i])
lat = float(location_data['경도'][i])
folium.CircleMarker((long, lat), radius=size, color='red', popup=name)\
.add_to(map_jeju)- 먼저 한라산 좌표를 통해 기본 folium.Map을 찍는다.
- 각 데이터에서, name에 명칭을 적고, count에 게시글 개수를 저장한다. => size를 시각화를 잘 하기 위해 count의 2배로 한다. int로 숫자로 만들어서.
- 위도, 경도도 뽑는다.
- CircleMaker로 위도 경도에, 이 사이즈에,
popup=name으로 마커를 클릭하면 이름도 뜰 수 있게 만든다.
2-5-2
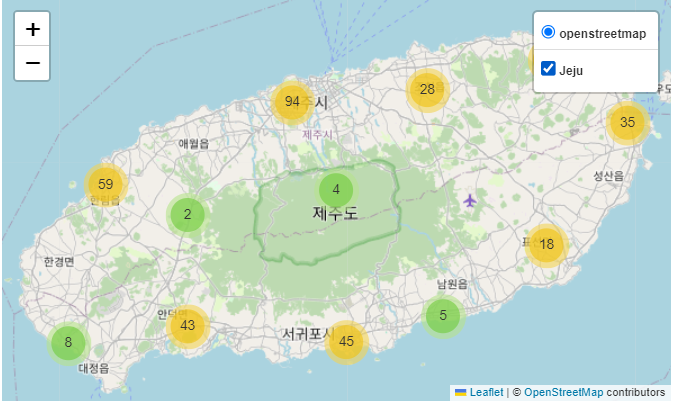
from folium.plugins import MarkerCluster
locations = []
names = []
for i in range(len(location_data)):
data = location_data.iloc[i] # 행 하나씩
locations.append((float(data['위도']),float(data['경도']))) # 위도 , 경도 순으로..
names.append(data['name_official'])
Mt_Hanla =[33.362500, 126.533694]
map_jeju2 = folium.Map(location = Mt_Hanla, zoom_start = 11)
marker_cluster = MarkerCluster(
locations=locations, popups=names,
name='Jeju',
overlay=True,
control=True,
)
marker_cluster.add_to(map_jeju2)
folium.LayerControl().add_to(map_jeju2)
map_jeju2- 먼저 for문으로 위도 경도, 이름을 각각 뽑아서 리스트로 만든다.
- 한라산을 중점으로 folium.Map을 만든다.
MarkerCluster()객체는 지도 위에 표시된 여러 마커들을 클러스터링해서 관리하는 기능이다. 클러스터링된 마커란, 지리적으로 가깝게 위치한 여러 마커를 하나의 그룹으로 묶어서 표시한다.- 매개변수
locations에 지정된 위도, 경도를 마커로 추가.popup으로 각 마커에 팝업으로 표시될 텍스트로 이름들을 설정.name은 이 클러스터 레이어의 이름.overlay이 클러스터 레이어가 오버레이 레이어인지 나타냄. 즉, 기본 지도 레이어 위에 추가적으로 표시되는 레이어인지. True, False.control: LayerControl 위젯으로 제어될 수 있는지. True면 LayerControl으로 클러스터 레이어 표시 여부 선택 가능.
folium.LayerControl(): 생성된 지도 객체에 레이어 컨트롤을 추가. 지도 상으 ㅣ다양한 레이어를 토글(켜고 끄기) 할 수 있게 하는 인터페이스. 아래 사진의 우측 상단.

일본에서 일하는 게임 기획자. 시시해서 죽어버리지 않게, 재밌고 의미 있는 컨텐츠에 관심 있습니다. 그 도구로 데이터, AI도 찝적댑니다.