1 apply() 메서드
- 판다스 데이터프레임, 시리즈의 각 요소에 함수를 적용하는 메서드. 내장 함수, 사용자 정의 함수, lambda 함수 등을 적용 가능.
- Pandas 없이 그냥 하려면, 배열을 일일히 loop를 돌려가면서 계산값을 구해야하는데, 한 번에 처리 가능(내부 동작이 어떻게 되는지는 더 찾아봐야할 것 같다).
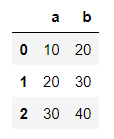
#데이터프레임
import pandas as pd
df = pd.DataFrame({'a': [10, 20, 30],
'b': [20, 30, 40]})
#함수1
def my_sq(x):
return x ** 2
#함수2
def avg_2(x, y):
return (x+y)/2- 이렇게 df와 함수 2가지가 있다고 할 때
sq = df['a'].apply(my_sq)
이렇게 하나의 열에 적용하면 ['a']열 각각에 적용된다.
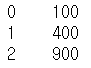
sq2 = df.loc[0].apply(my_sq)
이렇게 하나의 행에 적용하면 0번재 행 각각에 적용된다.
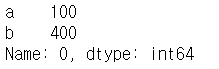
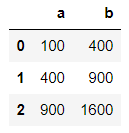
sq3 = df.apply(my_sq)
이렇게 DF 전체에 적용하면, 모든 열에 각각 적용된다.
1-1 axis 지정
- axis=0이면 열 단위로 지정, axis=1이면 행 단위로 지정. default는 0.
print_me가 그냥 들어오는 값을 print하는 함수라고 하면df.apply(print_me, axis=1)으로 하면 한 행씩 출력.
1-2 인수 문제
def avg_2(x, y): return (x+y)/2라는 사용자 정의 함수가 있을 때,
df.apply(avg_2)는 에러가 뜬다.
이유는 인수가 x, y 2개가 들어가야 하는데, 1개만 들어가서.
=> 수정본: 사용자 정의 함수에 df 1개가 들어가서 처리가 되도록 바꿔야 한다.
def avg2(row):
x = row[0]
y = row[1]
return (x+y)/2
def avg3(col):
x = col[0]
y = col[1]
z = col[2]
return (x+y+z)/3- 여기서 함수를 row, col 2가지로 뽑은 이유는, 위에 본 듯이 3행, 2열로 이루진 df에서, axis=0으로 하면 열(column)별로 들어가서, 3개의 값이 한거번에 들어가고, axis=1이면 행(row)별로 들어가서, 2개의 값이 한거번에 들어가서.
어찌 됐건 일치가 안하면 에러가 뜬다.
1-3 람다 함수 사용
df['a_sq_lamb'] = df['a'].apply(lambda x: x**2)
이렇게 람다로 그냥 함수를 바로 넣을 수 있다.
1-3-1 람다와 인수 지정 문제
df['total'] = df.loc[:, ['mid', 'fin']].apply(lambda x: (x['mid'] + x['fin'])/2, axis=1)
열이 mid, fin 2개인 df가 인수로 들어갔는데, df['min'] 이렇게 열 이름을 직접 지정을 해야하기 때문에, 이런 번거로운 모양으로 들어간다.
2 벡터화된 함수 사용
2-1 개념
- 벡터화: 한 번에 여러 개의 데이터를 처리하는 기술. 배열, 행렬 연산을 수행할 때 쓴다.
ex)
a = [1, 2, 3, 4, 5]
b = [6, 7, 8, 9, 10]
#for 루프로 하나씩
for i in range(len(a)):
result.append(a[i] + b[i])
#벡터화를 사용해 덧셈
a = np.array(a)
b = np.array(b)
result a+ b- 여기서 첫 번째는 for로 리스트의 내부를 하나씩 계산을 하고 있고, 두 번째는 배열의 같은 인덱스끼리 한거번에 더하고 있다.
- 이는 넘파이 배열이 벡터화된 연산을 지원하기 때문.
#함수1
def avg_2(x, y):
return (x+y)/2
#함수2
def avg_2_mod(x, y):
if (x==20):
return (np.NaN)
else:
return (x+y)/2
#함수1 사용
avg_2(df["a"],df['b'])
#함수2 사용
avg_2_mod(df['a'], df['b'])- 여기서 함수1은 돌아가지만, 함수2는 에러가 뜬다.
왜냐하면 파이썬은 동적 언어라서, 함수가 받는 인수(x, y)의 데이터타입이 정확하게 지정되지 않는다. 그러므로 x가 일단 아무거나 받는데, 여기서는 df['a'](시리즈, 넘파이배열)을 받는다.
여기서 함수1의 경우, 파이썬(동적 언어)과 넘파이가 벡터화된 함수로 작용한다. 그러면 넘파이나 반복 가능한 객체에 대해 요소별로 연산을 수행할 수 있도록 만들어준다(x와 y라는 배열에서 맞는 인덱스끼리 연산을 해서 그 값들을 return한다).
하지만 함수2의 경우, 벡터화된 함수로 설계되지 않았다. if x==20이란 조건 때문에. 비교 연산에서 x가 시리즈(넘파이 배열)이란 객체 통으로 적용이 되고, 데이터타입이 맞지 않아서 에러가 뜬다. - 여기서 함수2를, 해결 방법으로는 벡터화된 함수로 적용을 하면, 이런 문제를 해결할 수 있다.
list(map(avg_2_mod,df['a'],df['b']))
벡터화된 함수는, 개념으로 보면 이렇게 map으로 처리한 것과 비슷하게 처리되는 것. 이 경우도 똑같은 결과를 얻을 수 있다.
차이는 벡터화된 함수로 하면 numpyarray가 데이터타입이고, map의 경우는 리스트고.
2-2 방법
#1 방법1
avg_2_mod_vec = np.vectorize(avg_2_mod)
#2 방법2
@np.vectorize
def v_avg_2_mod(x, y):
if(x==20):
return (np.NaN)
else:
return (x+y)/2
# 방법3
import numba
@numba.vectorize
def v_avg_2_numba(x, y):
if (int(x)==20):
return np.NaN
else:
return (x+y)/2
v_avg_2_numba(df['a'].values, df['b'].values)- 방법 1과 방법 2는 사실상 같은 방법을 다르게 표현한 것이다.
mp.vectorize(함수명)을 하면 넘파이를 통해 그 함수가 벡터화된 함수로 처리된다.
방법2를 통해 함수 정의 부분에@np.vectorize를 하면 그 함수가 벡터화된 함수로 설계된다. 여기서 @np.vectorize 이 부분을 decorator라고 한다. - numpy의 경우, 파이썬 함수를 벡터화해서 numpy 배열 또는 반복 가능한 객체에 대해 요소별로 연산을 수행할 수 있도록 만들어준다. 파이썬의 일반적인 제한을 따르고, 데이터 유형을 명시해야하는 제약이 없다.
방법 3의 Numba는 JIT 컴파일을 사용해서 벡터화된 함수 생성. 이 경우 함수에 대한 인자와 반환 값을 명시적으로 지정해야 한다.
그리고 마찬가지로 판다스 객체를 처리하는 기능이 Numba에는 없기 때문에, df['a'].values로 넘파이 배열로 변환해서 함수에 전달해야 한다(.values로 하면 그 값들만 넘파이 배열로 추출된다. 그 전에는 시리즈 객체).
#1 벡터라이즈 안쓰고 문제 풀기
def grade(i):
if i >= 90:
return 'A'
elif 90 > i >= 80:
return 'B'
elif 80 > i >= 70:
return 'C'
else:
return 'F'
df['grade'] = df['average'].apply(grade)
#2 벡터라이즈 쓰고 문제 풀기
@np.vectorize
def grade(vec) :
if vec >= 90 :
return 'A'
elif vec >= 80 :
return 'B'
elif vec >= 70 :
return 'C'
else :
return 'F'
df['grade'] = grade(df['average'])3 실습: 결측값 처리
3-1 목표
- 1 seaborn의 titanic 데이터를 들고온다.
- 2 각 열별로 NaN 갯수, NaN과 그렇지 않은 비율을 구하기
- 3 각 행 별로 NaN 갯수 구해서 추가하기
3-2 열별로 처리하기
3-2-1 데이터 불러오기
import seaborn as sns
titanic = sns.load_dataset('titanic')3-2-2 apply 적용할 함수 만들기
import numpy as np
#NaN 갯수 구하기
def count_missing(vec):
null_vec = pd.isnull(vec)
null_count = np.sum(null_vec)
return null_count
#NaN 비율 구하기
def prop_missing(vec):
num = count_missing(vec)
dem = vec.size
return num / dem
#NaN과 아닌 데이터의 비율을 구하기
def prop_complete(vec):
return 1-prop_missing(vec)3-2-3 열별로 적용하기
cmis = titanic.apply(count_missing)
pmis = titanic.apply(prop_missing)
pcom = titanic.apply(prop_complete)3-3 행별로 처리하기
cmis_row = titanic.apply(count_missing, axis=1)
pmis_row = titanic.apply(prop_missing, axis=1)
pcom_row = titanic.apply(prop_complete, axis=1)
#열 추가
titanic['num_missing'] = cmis_row
# NaN이 2개 이상인 값만 가져오기
titanic.loc[titanic.num_missing > 1, :].sample(10)
일본에서 일하는 게임 기획자. 시시해서 죽어버리지 않게, 재밌고 의미 있는 컨텐츠에 관심 있습니다. 그 도구로 데이터, AI도 찝적댑니다.