1. Introduction
- 기존 방법론의 한계
- RNN, LSTM, GRU는 sequential computation로 인해 parallelization이 불가능하고 긴 시퀀스일수록 memory constraints으로 인해 batch size 한계가 있음.
- Attention 등장
- 입력 및 출력 시퀀스 내에서 거리와 무관하게 의존성을 모델링할 수 있음.
- 하지만, recurrent network와 함께 사용됨.
- Transformer 제안
- recurrence를 제거하고 오직 attention을 통해 입력과 출력 간의 global dependencies를 학습.
- 장점
- parallelization(병렬화)
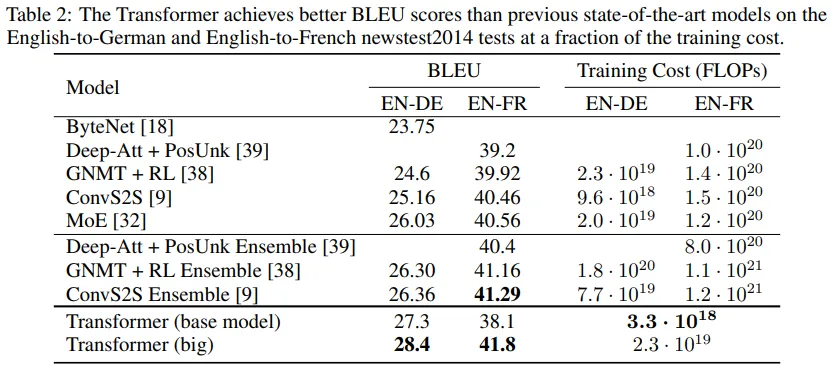
- 8개의 P100 GPU로 12시간 학습하여 SOTA 등극
2. Background
- The goal of reducing sequential computation
-
Extended Neural GPU
-
ByteNet
-
ConvS2S
공통점 : CNN을 basic building block으로 사용. 입력 및 출력 위치에 대해 parallel하게 hidden representations를 계산
문제점 : 먼 위치 간에 dependencies를 학습하기 어려움
-
In the Transformer
- Transformer에서는 두 위치 간 dependencies를 계산하는 데 필요한 연산을 줄임.
- attention-weighted positions의 averaging으로 인해 effective resolution이 감소하는 손실이 발생.
-
- Self-attention(intra-attetion)
- representation of the sequence를 계산하기 위해 sing sequence의 different positions와 관련된 attention.
- 적용 사례:
- 독해(Reading Comprehension)
- 추상적 요약(Abstractive Summarization)
- 텍스트 함의(Textual Entailment)
- task-Independent Sentece Representations 학습
- End-to-end memory networks
- sequence aligned recurrence 대신 Recurrent Attention을 기반으로 함.
- 간단한 언어 QA 와 LM에 효과적임.
3. Model Architecture
3-1 Encoder and Decoder Stacks
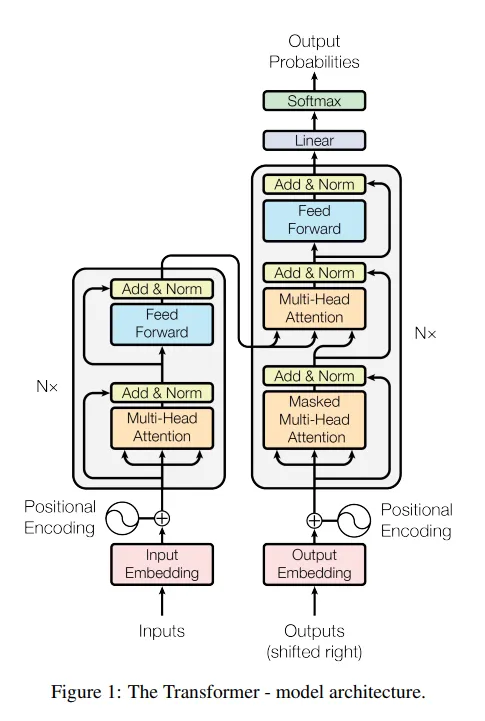
Encoder:
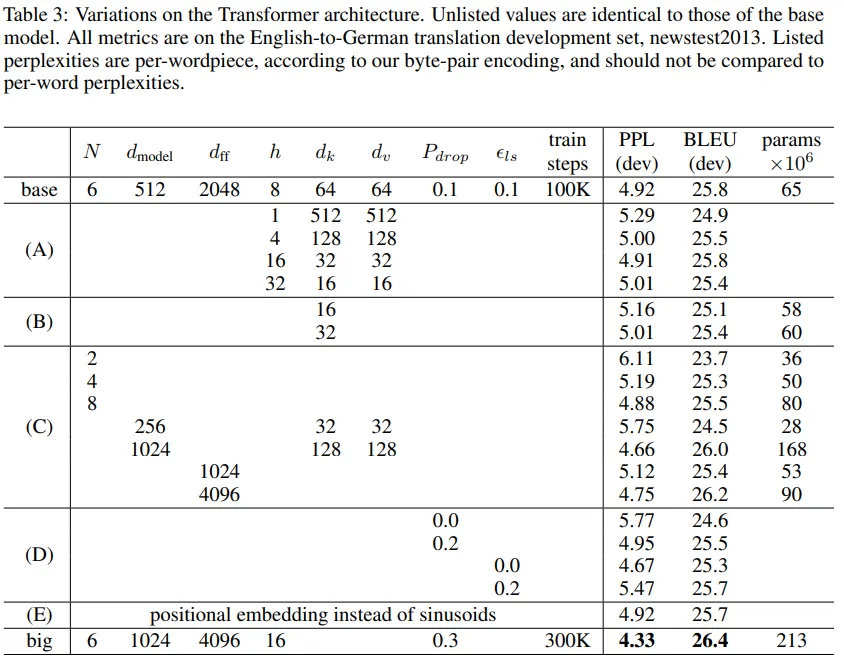
- 6개 Layer로 구성됨.
- Multi-Head Self-Attention : 입력 시퀀스 내에서 모든 위치 간의 관계를 학습
- Position-Wise Fully Connected Feed-Forward Network : 각 위치에 독립적으로 적용되는 비선형 변환.
- Residual Connection과 Layer Normalization 사용
- x : 현재 입력.
- Sublayer(x): sublayer 내부 연산
Decoder:
- 6개 Layer로 구성됨.
- Masked Multi-Head Attention : 현재 위치 이후의 정보가 참조되지 않도록 마스킹 처리
- Auto-Regressive 속성을 보장하기 위해 사용
- Encoder-Decoder Attention : Encoder의 output에 대해 Multi-Head Attention을 적용
- Position-Wise Feed-Forward Network
3-2 Attention
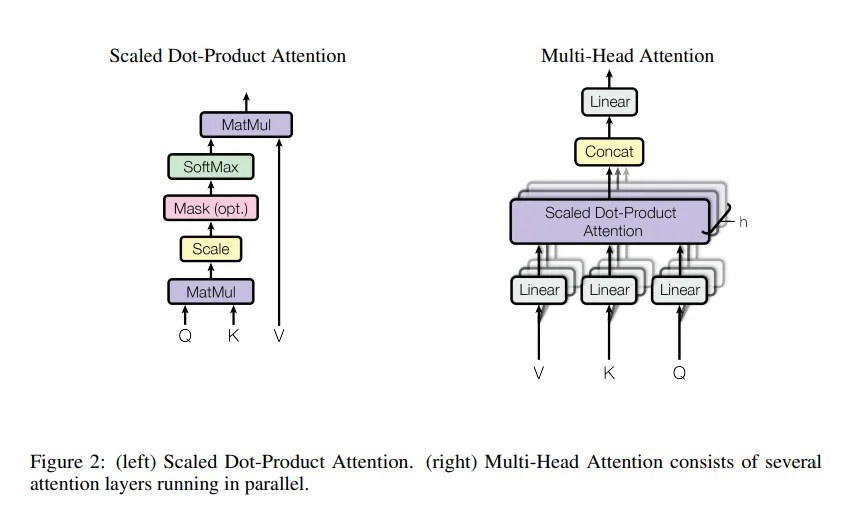
- Attention은 Q, K, V를 입력으로 받아 출력값을 계산하는 메커니즘
- Output : weighted sum of the value
3.2.1 Scaled Dot Product Attention
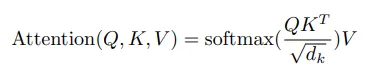
- Q : 집중하고자 하는 정보, 현재 위치(토큰)가 다른 위치(토큰)와 얼마나 관련이 있는지 측정하기 위한 기준 역할
- K : 참조 정보, Query와 비교하여 유사도를 계산하는 데 사용
- V : Q와 K의 유사도에 따라 선택되는 실제 정보
- : Key의 차원
- 모든 Keys를 사용하여 Query의 내적을 사용
- 내적을 를 나누어 스케일링.
- softmax를 적용하여 가중치 벡터 생성
- 가중치를 Value vector에 곱하여 최종 출력 계산
3.2.2 Multi-Head Attention
- 여러 개의 Attention 연산을 병렬적으로 수행하여 다양한 표현(subspace)에 집중
- 각 Attention 헤드는 Query, Key, Value를 고유의 차원으로 투영한 뒤 독립적으로 계산.

- Multi-Head Attention을 통해 다양한 시각으로 학습이 가능하다
- ex) 주어 위주, 동사 위주, 전치사 위주 처럼 다양한 단어나 위치를 기준으로 학습이 가능.
3.2.3 Applications of Attention in our Model
Transformer에서 Multi-Head Attention을 사용하는 세 가지 방식
- Encoder-Decoder Attention
- Q : Decoder의 이전 Layer 출력
- K & V : Encoder의 최종 출력.
- 목적
- Decoder가 입력 시퀀스의 모든 위치를 참조할 수 있도록 함.
- 입력 시퀀스와 출력 시퀀스 간의 관계를 학습
- 작동 방식
- Decoder의 현재 위치가 Encoder의 모든 위치와 상호작용하여 가장 관련 있는 정보를 추출
- 기존 Seq2Seq 모델에서 사용된 Attention과 동일한 역할 수행
- Self-Attention in Encoder
- Q, K, V 모두 Encoder 이전 Layer 출력에서 생성
- 목적
- 입력 시퀀스 내의 모든 위치 간 상호작용 학습
- 각 위치가 입력 시퀀스의 전역적인 정보를 통합할 수 있도록 함.
- 작동 방식
- 입력 시퀀스의 각 위치가 다른 모든 위치와의 유사도를 계산하여 정보 결합
- Encoder의 Self-Attention은 시퀀스 내 모든 위치에 대한 전역 의존성을 모델링.
- Masked Self-Attention in Decoder
- Q,K,V 모두 Decoder의 이전 Layer 출력에서 생성.
- 목적
- Decoder에서 Auto-Regressive 속성을 보장
- 현재 위치가 이후의 정보를 참조하지 못하도록 제한
- 작동 방식
- Scaled Dot-Product Attention에서 Softmax 계산 시, 미래 위치를 마스킹:
- Decoder의 각 위치가 이전 위치와 현재 위치의 정보만 참조 가능.
3-3 Position-wise Feed-Forward Networks
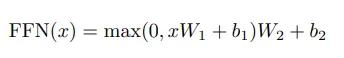
3-4 Embeddings and Softmax
Transformer에서 입력 및 출력 시퀀스를 벡터로 변환하고, 예측 결과를 확률로 변환하는 데 사용
3-5 Positional Encoding
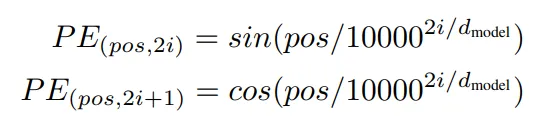
- Positional Encoding은 Transformer가 입력 시퀀스의 위치 정보를 학습할 수 있도록 지원.
- 사인 및 코사인 함수는 서로 다른 주파수를 사용해 각 차원에서 고유한 위치 정보를 부여.
- 고정된 방식은 훈련되지 않은 긴 시퀀스에서도 일반화 가능.
4. Why Self-Attention

- Computational Complexity per Layer
- 각 Layer가 수행해야 할 계산의 양
- Parallelization
- 최소한의 sequential operations으로 얼마나 많은 계산을 병렬로 처리할 수 있는지
- Long-Range Dependency Learning
- 입력과 출력 간의 위치 관계가 멀리 떨어져 있을 때 이 관계를 학습하기 위한 경로 길이.
Result