[Prompt Engineering]
1.Chain-of-Thought Prompting Elicits Reasoning in Large Language Models

3가지 LLM 모델에 대해 실험한 결과 CoT Prompt 기술이 다양한 arithmetic, commonsense, symbolic reasoning과 같은 작업에서 성능을 향상 시킴.CoT를 사용한 PaLM 540B 모델은 math word problem에 대한 G
2.Tree of Thoughts: Deliberate Problem Solving with Large Language Models
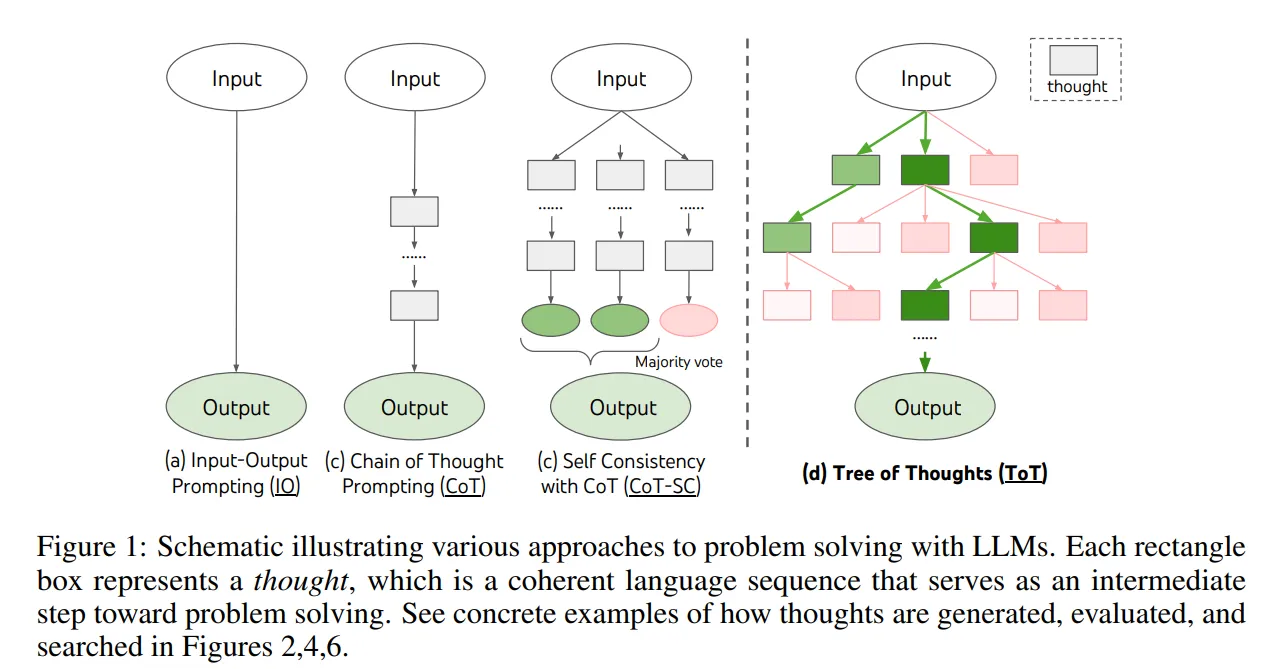
기존 LLM은 Left-To-Right, Token-Level decision Process 방식에 국한되어 있음.탐구, 전략적 예측, 초기 결정의 영향이 큰 task에 대해 부족함이 있음.위 문제들을 해결하기 위해 ToT를 제안coherent unit of thoug
3.ReAct: Synergizing Reasoning and Acting in Language Models

기존 CoT와 같은 방식은 학습된 정보만을 가지고 작동하여 정보가 업데이트 되지 않는 static black box임. 그로인해 Hallucination과 error propagation이 발생.ReAct : reasoning과 acting을 상호보완적으로 결합한 모델
4.Large Language Models are Zero-shot Reasoners

배경 및 목적기존에는 CoT prompting 기법이 few-shot 학습에서 우수한 성능을 보였는데, 이 현상이 few-shot 학습에 의해서 향상 했는지에 대한 조사주요 발견‘step-by-step’이라는 간단한 프롬프트를 추가하여 zero-shot에서도 우수한 성
5.Self-Consistency Improves Chain of Thought Reasoning in Language Models
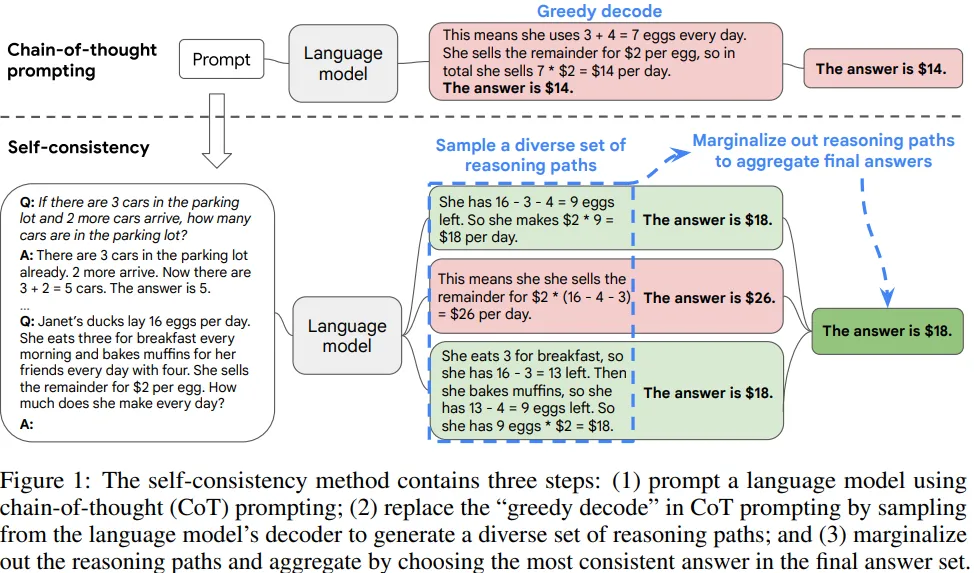
chain-of-thought prompting에서 사용되는 greedy decoding을 대체하기 위해 self-consistency(정답에 도달하는 추론 과정을 여러 개를 생각함)를 제안하여 추론 능력을 향상 시킴.Greedy decode 대신 Sample-and-
6.AUTO GEN: ENABLING NEXT-GEN LLM APPLICATIONS VIA MULTI-AGENT CONVERSATION

encourage divergent thinkingimprove factuality and reasoningprovide guardrailscooperate through conversations : 채팅에 최적화된 LLM(GPT-4)은 피드백 수용 및 대화형 학습을
7.Transformer : Attention Is All You Need

기존 방법론의 한계RNN, LSTM, GRU는 sequential computation로 인해 parallelization이 불가능하고 긴 시퀀스일수록 memory constraints으로 인해 batch size 한계가 있음.Attention 등장입력 및 출력 시퀀스