SELECT
테이블에 데이터를 조회할 때 사용
SELECT문에는 순서가 중요하다.
아래 순서대로 입력하되 중간중간 생략은 가능하다.
SELECT [*]
FROM [TABLE]
WHERE [조건]
GROUP BY [어떤 그룹으로 묶을것인지]
HAVING [그룹에 조건을 입력]
ORDER BY [오름차순]
-- ORDER BY는 오름차순이 기본이고 DESC를 입력하면 내림차순이다.
-- 성능에 안좋은 영향을 줄 수 있어서 필요한 상황이 아니면 사용하지 않는 것이 좋다고한다.INSERT
테이블에 데이터를 삽입할 때 사용
INSERT 문법은 들어가는 값의 순서가 맞아야 한다.
INSERT INTO 테이블(열1,열2....) VALUES (값1,값2...)
-- 테이블 생성 후 데이터 삽입
CREATE TABLE testTbl1 (id int, userName char(3), age int);
INSERT into testTbl1 VALUES (1,'홍길동',25);
INSERT into testTbl1 values(2,'설현',26);
-- 테이블에 값 순서를 입력해서 삽입가능
INSERT INTO testTbl1(age,userName, id) values(28,'아무개',3);
select * from testTbl1AUTO_INCREMENT
1부터 자동으로 값이 증가야여 입력된다.
위에 코드에서 id를 1부터 증가시켜가며 손수 입력했지만
CREATE TABLE testTbl1 (id int AUTO_INCREMENT PRIMARY KEY, -- 이러면 자동으로 입력된다.
userName char(3),
age int);
INSERT INTO testTbl1 values (NULL,'김씨',23),(NULL,'이씨',25); -- null으로 데이터입력만약 1부터 시작이 아니고 100부터 증가하게 하고 싶다면
ALTER TABLE testTbl2 AUTO_INCREMENT=100; -- 이렇게 하면 100부터 시작한다.
-- 만약 증가를 3씩 하고 싶다면
SET @@auto_increment_increment=3; 대량의 데이터 삽입
이미 만들어진 테이블에 다른 테이블에 있는 값을 그대로 넣거나 일부만 넣을 때 사용하는 문법같다.
CREATE TABLE testTbl4 (id int,
Fname varchar(50),
Lname varchar(50));
INSERT into testTbl4
select emp_no, first_name, last_name
from employees.employees;UPDATE
기존의 데이터를 수정하기 위해서 사용한다.
문법
UPDATE 테이블이름
SET 열1 = 값1, 열2=값2 .....
WHERE 조건;실습
SELECT * from testTbl1;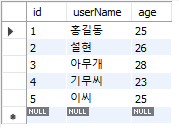
UPDATE testTbl1
set userName = '김씨'
where userName = '기무씨';
SELECT * from testTbl1;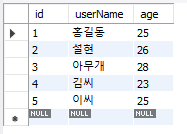
만약 where 을 사용하지 않았다면 이름 전체가 김씨로 변했을 것이다.
DELETE FROM
데이터를 행 단위로 삭제한다.
DELETE FROM 테이블 이름 WHERE 조건;만약, WHERE문이 생략되면 전체 데이터를 삭제한다.
DELETE FROM testTbl1 where userName = '아무개';
SELECT * from testTbl1;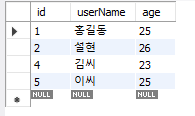
만약 아무개라는 이름이 6건이 있고 이중에 5개만 지우고 싶었다면 마지막에 LIMIT 5;를 입력한다면 가능하다.
대용량 데이터 생성 및 삭제
-
DELECT
- 삭제된 각 행에 대해서 트랜잭션에 기록된다.
- 테이블 용량은 감소하지 않는다.
- 한 행씩 지우기 때문에 속도가 가장 느리다.
- ROLLBACK (O)
-
DROP
- 테이블 자체가 한번에 지워진다.
- DB에서 TABLE을 없애버린다.
- ROLLBACK (X)
-
TRUNCATE
- 테이블에서 모든 행이 제거된다.
- 트랜잭션 로그에 한번만 기록이 되기 때문에 DELETE보다 빠르다.
- 개별적으로 행삭제 불가능(WHERE절과 사용 못함)
- 테이블 용량이 초기화된다.
- ROLLBACK (X)
조건부 데이터 입력, 변경
100건의 데이터를 INSERT하려 할 때 1번에서 오류가 나면 다음 99건은 실행이 되지 않는데
MySQL에서는 오류가 나와도 계속 이어갈 수 있게하는 것을 제공한다.
실습
create table memberTBL (select userID, name, addr From usertbl LIMIT 3);
-- 3개 값만 가져와 생성
ALTER TABLE memberTBL
ADD CONSTRAINT pk_memberTBL PRIMARY KEY (userID);-- userID가 기본키(중복안됨)
select * from memberTBL;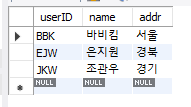
-- userID가 기본키인데 이미 BBK가 있어서 중첩이 되어 에러가 발생한다.
INSERT INTO memberTBL VALUES('BBK','바베큐', 'US'); -- 기본키가 중복되어 에러발생
INSERT INTO memberTBL VALUES('SJH','서장훈', '서울');
INSERT INTO memberTBL VALUES('HJY','현주엽', '경기');
SELECT * from memberTBL;이런 상황에서 MySQL에서 에러난 것을 건너뛰고 나머지를 실행시키는 기능을 제공한다.
-- MySQL에서 제공하는 기능
INSERT IGNORE INTO memberTBL VALUES('BBK','비비코', '미국'); -- 무시하고 지나감
INSERT IGNORE INTO memberTBL VALUES('SJH','서장훈', '서울');
INSERT IGNORE INTO memberTBL VALUES('HJY','현주엽', '경기');
SELECT * FROM memberTBL; 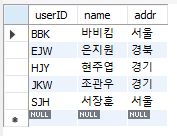
또한 기본키가 중복이 될 때 새로운 값으로 업데이트 시키는 기능도 제공한다.
-- 키가 중복되면 새로 업데이트 하는 문법
INSERT INTO memberTBL VALUES('BBK','비비코','미국')
ON DUPLICATE KEY UPDATE name='바뀐비비코',addr='US';-- 기본키가 중복되니까 바꿔준 것
INSERT INTO memberTBL VALUES('DJM','동이','조선') -- 기본키가 중복되지 않아서 추가된 것
ON DUPLICATE KEY UPDATE name='동이',addr='조선2';
SELECT * FROM memberTBL;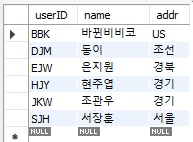
WITH절과 CTE
조회된 결과를 테이블로 만들때 사용한다.
CTE와 파생테이블은 구문이 끝나면 바로 소멸된다. (실존하는 테이블이 아니다)
CTE문은 중복이 가능하다.
WITH절은 CTE를 표현하기 위한 구문이다.
비재귀적 CTE 문법 ( 복잡한 쿼리문을 단순화하는데 사용된다.)
WITH 테이블이름(열1,열2) -- 2. 테이블로 만들고(실존하는 테이블이 아니다)
AS
(
쿼리문 -- 1. 여기서 나온 결과를
)
SELECT 열이름 FROM 테이블이름; -- 3. 원래 테이블처럼 사용 가능하다는 말 같음실습
use sqldb;
select userid AS '사용자',SUM(price*amount) AS '총구매액'
FROM buyTBL GROUP BY userid;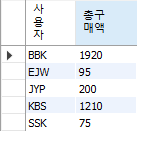
이것을 내림차순으로 할 때 뒤에 이어 붙여서 ORDER BY해도 되는데 복잡해 보일 수 있기 때문에
단순화해 보이려고 할 때 사용하는 것 같음
-- WITH와 CTE
WITH makeTBL(userid,total)
AS
(SELECT userid,SUM(price*amount)
FROM buytbl GROUP BY userid)
SELECT * FROM makeTBL;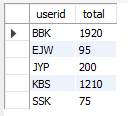
솔직히 단순화? 해주는 느낌인지는 아직 모르겠다.
이런거라면 그냥 처음부터 ORDER BY 사용하는게 코드가 더 짧고 가독성이 좋을거 같다는 개인적인 생각이든다.
라고 할뻔 두번째 실습 하고 생각이 바뀌었다..ㅎㅎ
WITH와 CTE 실습 2
동네별 최고 키를 구하고 그 평균을 구하는 실습
SELECT addr, MAX(height) AS '동네별 최고키'
FROM usertbl
GROUP BY addr;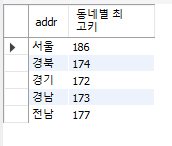
SELECT addr, MAX(height) AS '동네별 최고키'
FROM usertbl
GROUP BY addr;
WITH cte_usertbl(addr,maxHeight)
AS
(SELECT addr,MAX(height) FROM usertbl GROUP BY addr)
SELECT AVG(maxHeight*1.0) AS '각 지역별 최고키의 평균'
FROM cte_usertbl;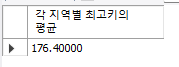
(출처: "이것이 MySQL이다" 학습내용)
