0. 작성 배경
이전 포스트에서 읽기 부하를 분산시키기 위해 Redis Cache를 활용하였습니다. 이때, TTL을 5초로 두게 되었는데 캐싱과 관련된 내용들에 대해서 더 학습하게 되면서 Hot key에서 발생할 수 있는 여러 문제점들에 대해서 알게 되었습니다.
- Hot key의 경우 sharding시 key의 분배가 개수적으로는 잘 이루어져도 해당 key가 자주 참조 되기 때문에 불균형 문제가 발생할 수 있습니다.
- 또한, 해당 Key가 TTL, Eviction, Shard 삭제 재배치 등의 이유로 다시 DB로 부터 조회(Lazy Loading)되어야 할때 DB에 순간적인 부하가 쏟아진다는 문제가 있습니다. 이 문제를 Cache Stampede 라고 합니다. 이 문제를 해결할 수 있는 해결 법들과 그 중 PER(Probabilistic Early Recomputation)에 대해서 구현해보고 테스트를 진행해보려고 합니다.
1. Hot key와 Cache Stampede문제
1-1. Hot key
- Hot key란 매우 자주 참조되거나 수정될 수 있는 key를 말합니다. 주로 Sharding시 RDBMS, key-value NOSQL등에서 특정 적으로 많이 참조되는 key, record입니다.
- 예를 들어 유튜브의 퓨디파이는 1억명이 넘는 구독자 수를 가지고 있는데 이런 경우 Hot Key에 해당합니다. 해당 유저가 알림을 보내거나 동영상 업로드, 글을 쓸 경우 해당 key에 대한 조회 요청이 쏟아질 것입니다.
1-2. Cache Stampede
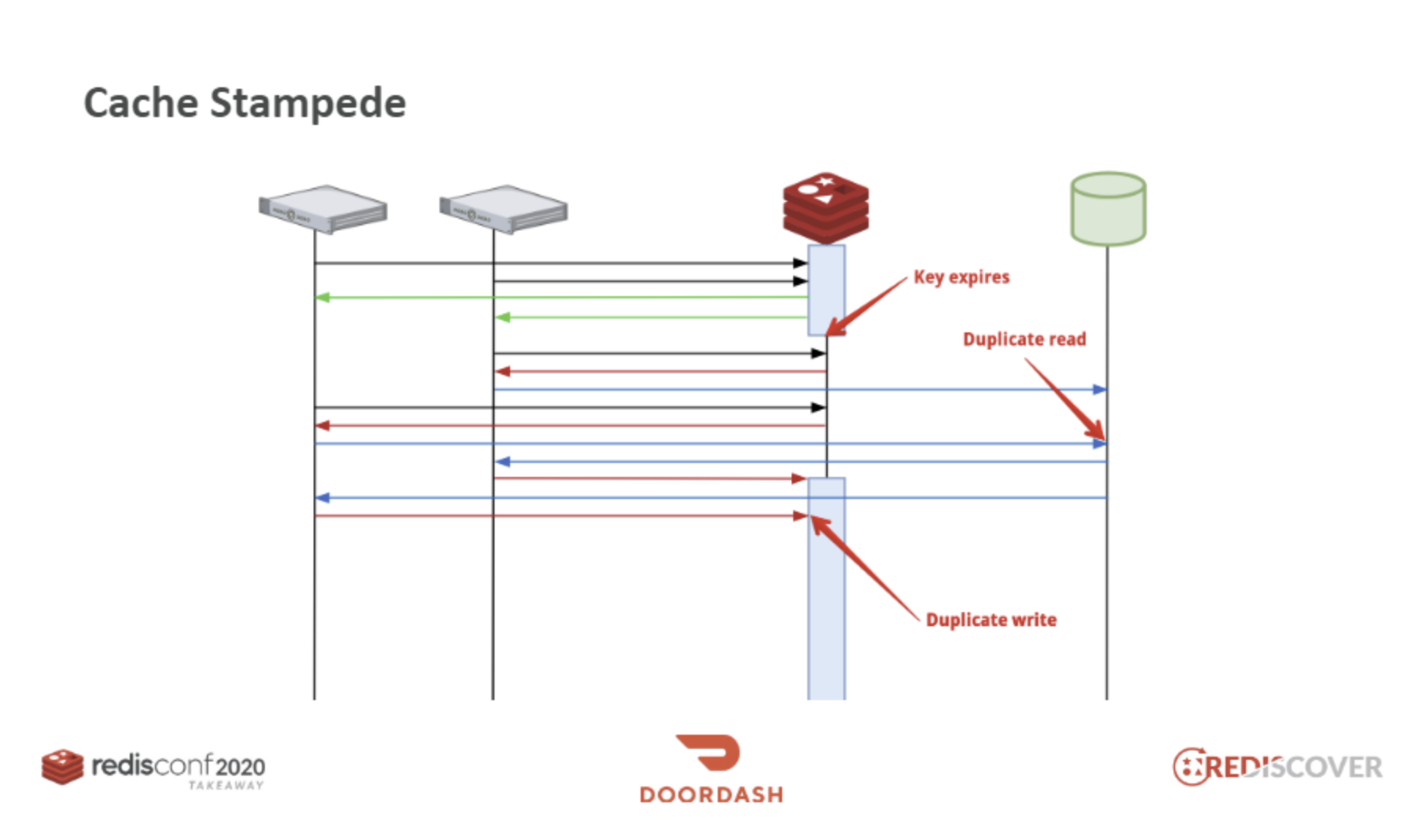
- Stampede는 많은 동물이 갑자기 빠르게 같은 방향으로 돌진하는 현상을 말합니다.
- cache stampede는 캐시 만료로 인해 많은 데이터 조회 요청이 DB로 갑자기 몰리는 현상을 말합니다.
예를 들어 Cache에 Lazy Loading이 0.2s걸리는 요청이 있다고 한고 해당 요청은 10000TPS규모라고 한다면 만료된 순간부터 0.2s동안의 해당 key를 참조하려는 2000개의 요청은 DB로 쏟아지게 되며 조회 후 Redis에 중복해서 2000번의 Write가 발생할 것입니다.
2. Cache Stampede 해결법
2-1. 주기적인 Batch작업을 통한 key 갱신
- TTL을 둔 이유는
- 해당 key의 값을 수정이 일어날때마다 수정하지 않고 만료시켜서 갱신하기 위함입니다.
- 특정 Hot key들의 목록을 만들어두고 해당 key들은 TTL을 주지 않고 주기적으로 DB로 부터 조회하여 갱신해주는 방법이 있습니다.
장점
- 만료가 되지 않음이 보장 되기 때문에 Cache Stampede가 발생하지 않도록 꽤 확실하게 방지할 수 있습니다.
단점
- 추가적인 Batch Server가 필요합니다.
- Hot key를 Manual하게 관리해주어야 합니다. 이를 자동화하더라도 기준을 만들고 자동화하는 로직을 구성해야합니다. 해당 로직이 부적절할 경우 Hot key임에도 관리되지 못하거나 Hot key가 아님에도 관리될 수 있습니다.
2-2. Lazy Loading(Cache Miss)이 발생하는 경우에 Lock을 사용
- Cache Miss가 발생하여 DB를 직접 조회해야할때 Lock을 활용할 수 있습니다. 다른 조회 요청들은 해당 요청이 끝날때까지 대기하게 됩니다.
장점
- Cache Stampede를 방지할 수 있습니다. 중복 조회, 수정이 발생하지 않습니다.
단점
- 캐시 만료 시 Lock으로 인해 요청들이 대기해야하는 것은 변하지 않습니다. 병목지점이 될 수 있습니다.
2-3. Probabilistic Early Expiration(PER)
- 확률적 알고리즘을 활용하여 TTL만료 전에 재갱신함.
장점
- TTL만료자체를 연장할 수 있기 때문에 연장이 지속적으로 이루어진다면 만료시 생길 수 있는 문제를 완벽하게 해결할 수 있음.
- hot key라면 재갱신 확률이 자동적으로 높아지기 때문에 별도로 hot key를 관리할 필요가 없음.
단점
- 확률적으로 갱신하기 때문에 최악의 경우 TTL에 도달하여 Cache Stampede가 발생할 수 있음.
- 최악의 경우를 대비하여 미리 부하테스트를 진행해야하고 적절한 확률상수등을 정해야함.
3.Probabilistic Early Expiration(PER)
Cache Stampede의 장단점 들을 고려하여 PER을 선택하기로 하였습니다. 해당 방법에 대해서 좀 더 자세하게 알아보려고 합니다.
출처
- https://www.youtube.com/watch?v=mPg20ykAFU4
- https://engineering.linecorp.com/en/blog/redis-lua-scripting-atomic-processing-cache
- https://cseweb.ucsd.edu/~avattani/papers/cache_stampede.pdf
3-1. 구체적인 동작 방식
PER의 핵심 개념은 다음 조건들을 만족해야합니다.
1. 만료가 도래하기 전에 갱신한다. 갱신하지 못하면 Cache Stampede가 발생한다.
2. 만료시간에 가까워질 수록 재갱신 확률이 상승한다.
3. 자주 참조되는 key일 수록 재갱신 시도가 증가하므로 재갱신 확률 또한 증가한다.
4. Recompute Time Interval이 클수록 남은 ttl 만료 시간 대비 재갱신 확률이 커야한다.
Pseudo Code
해당 조건들을 만족하기 위해서 XFetch라는 개념을 도입했습니다. 해당 알고리즘은 다음과 같습니다.
- 먼저 Cache로 부터 특정 key에 대해서 읽습니다. 이때 delta는 Recompute time interval, expiry는 만료되는 시각을 의미합니다.
- 만약 value가 존재하지 않는다면 Cache Miss인 상황이므로 Lazy Loading을 진행합니다.(이때 Cache Stampede가 발생합니다. PER의 목적은 Hot key에 대한 value가 존재하지 않는 상황을 방지하는 것 입니다. 어플리케이션 시작 전 초기에 cache데이터를 미리 로딩 해주는 것이 좋습니다.)
- cache hit이 일어나는 경우 바로 해당 데이터를 반환하지 않습니다. 남은 만료시간과 PER GAP(베타 * Recompute time interval * log(0~1난수) )을 비교하여 GAP이 큰 경우에 확률적으로 Recompute를 수행합니다. 재계산된 value를 반환합니다. 왜 GAP이 이렇게 계산되는지는 뒤에 좀더 자세하게 알아보겠습니다.
- PER이 일어났다면 Cache에 갱신된 데이터와, ttl, recompute시간을 새로 기록해줍니다.
3-2. ∆βlog(rand())
PER의 핵심은 TTL까지 남은 시간 <= -∆β log(rand()) 인 경우 해당 키를 갱신하는 것입니다.
그렇다면 이 식은 어떻게 유도 되었을까요? 해당 논문에 자세히 나와있습니다. 수식에 대해서 설명해보겠습니다.
https://cseweb.ucsd.edu/~avattani/papers/cache_stampede.pdf
TTL까지 남은 시간
TTL까지 남은 시간이 많은데 새로 갱신이 이루어지는 것은 비교적 비효율적입니다. 따라서 TTL 까지 남은 시간이 적을 수록 우변 값이 클 확률이 높아지기 때문에 자연스럽게 새로 갱신이 일어날 확률이 높아집니다.
∆(Recompute Time Interval)
한번의 Recompute가 오래 걸리고 무거운 경우 Cache Stampede가 발생했을 때 문제점도 커지게 됩니다. 따라서 해당 값에 비례하도록 구성하여 TTL 만료시간이 비교적 많이 남더라도 갱신이 이루어질 수 있습니다.
β(갱신 빈도 관련 상수, default = 1.0)
갱신이 자주 일어나길 바랄 경우 β를 수정하여 확률을 높일 수 있습니다. 높일 수록 갱신이 잘 발생합니다.
-log(rand())
왜 꼭 log가 되는지 가장 의문이 들었던 부분입니다.
여기서 rand()는 0~1사이의 값을 가집니다. 따라서 해당 값은 0부터 마이너스 무한대까지의 범위를 가집니다.
왜 log를 사용했을까?
포아송 분포
포아송 분포는 독립적으로 일어나는 특정 사건이 일어나는 횟수에 대한 확률분포입니다. 핵심은 사건들이 독립적이라는 점과 이때 사건간의 시간간격은 지수분포를 따른다는 점입니다.
- 결론적으로 말하면 재갱신이라는 사건을 독립사건으로 정의하여 사건 발생 횟수에 대한 확률분포를 포아송 분포로 정의하였기 때문입니다. 포아송 분포에서 사건과 사건 사이의 시간 간격은 지수확률 분포를 따릅니다. 이에 대해 역함수를 취하여 log가 나온것입니다.
- 즉, log(rand())는 포아송 분포에서 각 사건 사이에 시간간격을 의미합니다. TTL만료 시간과 비교하기 좋습니다.
- 또한 위에 있는 논문에서 정규분포와, 지수분포를 가정하고 테스트했을 때 지수분포가 더 적합함을 밝히고 있습니다.(어떤 분포를 따르는지는 사실 정답이 있는 것이 아니라 적합한 것을 찾아가는 과정이라고 합니다.)
4. PER 구현
4-1. Redis Pipeline, Lua Script
- 시리즈의 이전 포스트들에서 Redis Pipeline, Lua Script, Transaction에 대해서 자세하게 설명하고 있으니 참고바랍니다.
https://velog.io/@xogml951/Redis-%EB%8F%99%EC%8B%9C%EC%84%B1-%EB%AC%B8%EC%A0%9C-%EB%B0%A9%EC%A7%80Transaction-Lua-Scriptingcommand를 개별 실행시키지 않은 이유는 여러 커맨드들을 개별 실행할 경우 개별적으로 네트워크 통신을 하여 blocking되는 방식으로 동작하기 때문에 RTT가 증가하고 System call 횟수가 증가하기 때문입니다.
4-1-1. Redis Get의 경우 Lua Script 작성
조회 시 Script를 사용한 이유는 Transaction, Pipeline의 경우 조회의 결과를 반환받을 수 없기 때문입니다.
다음과 같이 실행할 스크립트를 미리 작성해둡니다. 이때 모든 key를 인자로 입력받도록 해야하며 같은 클러스터 노드에 존재해야합니다.
return {redis.call('mget', KEYS[1], KEYS[2]), redis.call('pttl', KEYS[1])};redis.call('mset', KEYS[1], ARGV[1], KEYS[2], ARGV[2]);
redis.call('expire', KEYS[1], ARGV[3]);
redis.call('expire', KEYS[2], ARGV[3]);
4-1-2. DefaultRedisScript Bean 등록
@Configuration
public class LuaScriptConfig {
@Bean
public DefaultRedisScript<List> cacheGetRedisScript(){
DefaultRedisScript<List> redisScript = new DefaultRedisScript<>();
redisScript.setScriptSource(new ResourceScriptSource(new ClassPathResource("luascript/cache_get.lua")));
redisScript.setResultType(List.class);
return redisScript;
}
@Bean
public DefaultRedisScript<List> cacheSetRedisScript(){
DefaultRedisScript<List> redisScript = new DefaultRedisScript<>();
redisScript.setScriptSource(new ResourceScriptSource(new ClassPathResource("luascript/cache_set.lua")));
redisScript.setResultType(List.class);
return redisScript;
}
}4-1-3. redis.execute()로 실행
private final DefaultRedisScript<List> cacheGetRedisScript;
private final DefaultRedisScript<List> cacheSetRedisScript;
public Object probabilisticEarlyRecomputationGet(String originKey, Function<List<Object>, Object> recomputer, List<Object> args, Integer ttl) {
redisTemplate.execute(cacheSetRedisScript, List.of(key, getDeltaKey(key)), data, computationTime, ttl);
}
return data;
} 4-1-4. Redis Write의 경우 Pipelining적용
private void setKeyAndDeltaWithPipeline(Integer ttl, String key, Object data, long computationTime) {
redisTemplate.executePipelined((RedisCallback<Object>) connection -> {
RedisSerializer<String> serializer = redisTemplate.getStringSerializer();
byte[] keyBytes = serializer.serialize(key);
byte[] deltaKeyBytes = serializer.serialize(getDeltaKey(key));
RedisSerializer<Object> valueSerializer = (RedisSerializer<Object>) redisTemplate.getValueSerializer();
byte[] dataBytes = valueSerializer.serialize(data);
byte[] computationTimeBytes = valueSerializer.serialize(computationTime);
connection.set(keyBytes, dataBytes);
connection.set(deltaKeyBytes, computationTimeBytes);
long ttlLong = Long.parseLong(ttl.toString());
Duration duration = Duration.of(ttlLong, ChronoUnit.SECONDS);
connection.expire(keyBytes, duration.getSeconds());
connection.expire(deltaKeyBytes, duration.getSeconds());
return null;
});
}4-2. Probabilistic Early Recomputation(PER)로직 구현
private final DefaultRedisScript<List> cacheGetRedisScript;
private final DefaultRedisScript<List> cacheSetRedisScript;
public Object probabilisticEarlyRecomputationGet(String originKey, Function<List<Object>, Object> recomputer, List<Object> args, Integer ttl) {
//같은 클러스터 key로 보장
String key = hashtags(originKey);
List<Object> ret = (List<Object>)redisTemplate.execute(cacheGetRedisScript, List.of(key, getDeltaKey(key)));
List<Object> valueList = (List<Object>) ret.get(0);
Object data = valueList.get(0);
Long delta = (Long)valueList.get(1);
Long remainTtl = (Long)ret.get(1);
log.debug("data: {}, delta: {}, remainTtl: {}", data, delta, remainTtl);
// 재 갱신을 해야하는 경우.
if (data == null || delta == null || remainTtl == null ||
- delta * BETA * Math.log(randomDoubleGenerator.nextDouble()) >= remainTtl) {
long start = System.currentTimeMillis();
data = recomputer.apply(args);
long computationTime = (System.currentTimeMillis() - start);
setKeyAndDeltaWithPipeline(ttl, key, data, computationTime);
}
return data;
}- 같은 node에 key에 연산을 보내기 위해 저장할때 hashtags활용(redis에서는 중괄호를 key에 넣게 되면 중괄호 내부 내용만을 활용하여 hashslot을 지정합니다.)
- 분기 문에서 Recomputation 여부를 검사하고 가능한 경우 람다로 들어온 람다문을 실행합니다.
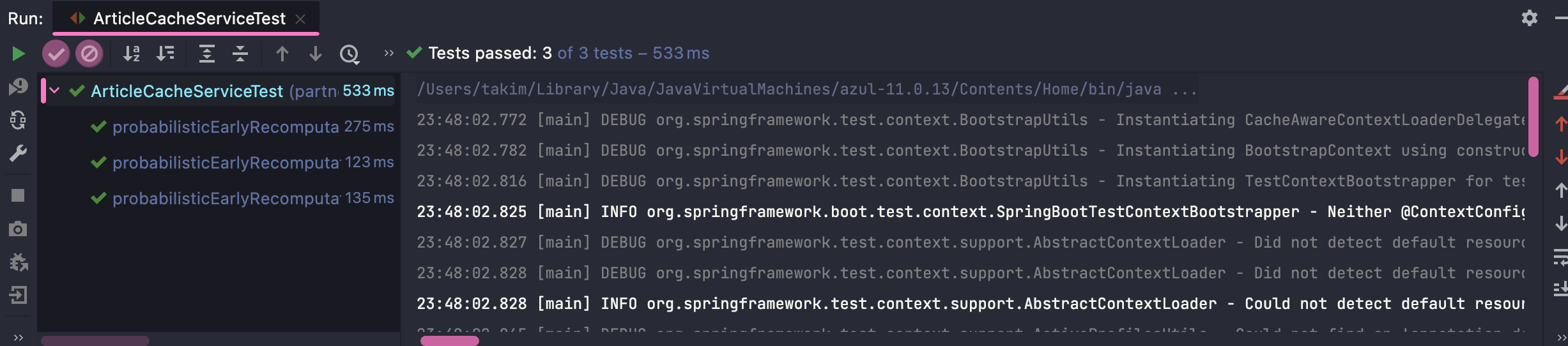
4-3. 동작 테스트
- 캐시가 존재하지 않는경우
- 캐시가 존재하는 경우
- 캐시가 존재하지 않지만 PER이 적용되어야 하는 경우 (확률 계산 부분을 따로 Bean으로 등록하여 Mocking할 수 있도록 하였고 Recomputation 람다의 경우 sleep을 통해 계산시간을 지정.)
@Slf4j
@SpringBootTest(classes = {ArticleCacheService.class, LettuceConnectionConfig.class,
LuaScriptConfig.class})
class ArticleCacheServiceTest {
@MockBean
private ProbabilisticEarlyRecomputationConfig.RandomDoubleGenerator randomDoubleGenerator;
@MockBean
private RedisMessageSubscriber redisMessageSubscriber;
@Autowired
private ArticleCacheService articleCacheService;
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@BeforeEach
void setUp() {
redisTemplate.getConnectionFactory().getConnection().flushAll();
}
@Test
void probabilisticEarlyRecomputationGet_whenCacheDataIsAbsent_thenComputeAndWrite() {
//given
String key = "target1";
// when(randomDoubleGenerator.nextDouble()).thenReturn(0.5);
//when
articleCacheService.probabilisticEarlyRecomputationGet(key, (x) -> {
try {
Thread.sleep(3);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return "a";
}, List.of(), 5);
String value = (String) redisTemplate.opsForValue().get(hashtag(key));
Object delta = redisTemplate.opsForValue().get(getDelta(hashtag(key)));
//then
assertThat(value)
.isEqualTo("a");
assertThat(delta)
.isNotNull();
}
@Test
void probabilisticEarlyRecomputationGet_givenCacheDataPresent_whenRemaintTTLIsMuchLargerThanDelta_thenNotRecompute() {
//given
String key = "target1";
String hashtag = hashtag(key);
redisTemplate.opsForValue().set(hashtag, "a");
redisTemplate.opsForValue().set(getDelta(hashtag), 100l);
Duration duration = Duration.of(5, ChronoUnit.SECONDS);
redisTemplate.expire(hashtag, duration);
redisTemplate.expire(getDelta(hashtag), duration);
when(randomDoubleGenerator.nextDouble()).thenReturn(0.1);
//when
ArrayList<Object> args = new ArrayList<>();
ArrayList<String> check = new ArrayList<>();
args.add(check);
// 100 * betta log(0.1) >= 5000
articleCacheService.probabilisticEarlyRecomputationGet(key, (x) -> {
ArrayList<String> check1 = (ArrayList<String>)(x.get(0));
check1.add("3");
return "a";
}, args, 5);
//실행 되지 않았는지 확인.
assertThat(check).isEmpty();
}
@Test
void probabilisticEarlyRecomputationGet_givenCacheDataPresent_whenRemaintTTLIsSmallerThanDelta_thenRecompute() {
//given
String key = "target1";
String hashtag = hashtag(key);
redisTemplate.opsForValue().set(hashtag, "a");
redisTemplate.opsForValue().set(getDelta(hashtag), 5005l);
Duration duration = Duration.of(5, ChronoUnit.SECONDS);
redisTemplate.expire(hashtag, duration);
redisTemplate.expire(getDelta(hashtag), duration);
when(randomDoubleGenerator.nextDouble()).thenReturn(0.1);
//when
ArrayList<Object> args = new ArrayList<>();
ArrayList<String> check = new ArrayList<>();
args.add(check);
// 100 * betta log(0.1) >= 5000
articleCacheService.probabilisticEarlyRecomputationGet(key, (x) -> {
ArrayList<String> check1 = (ArrayList<String>)(x.get(0));
check1.add("3");
return "a";
}, args, 5);
//실행 되었는지 않았는지 확인.
assertThat(check).isNotEmpty();
}
private String hashtag(String key) {
return "{" + key + "}";
}
private String getDelta(String key) {
return key + "-" + "delta";
}
}
5. 성능 테스트
5-1. 테스트 조건
테스트 조건중 5%가 전체 요청의 80%에 해당한다고 가정하였다. Gaussian Distribution을 활용하여 PageNumber의 값을 정하도록 Jmeter를 설정하였다.
더 트래픽이 집중되도록 하여 TTL 만료로 인한 Hit Miss를 더 잘 보기 위해 이전 테스트보다 요청이 집중된다고 가정하였다.
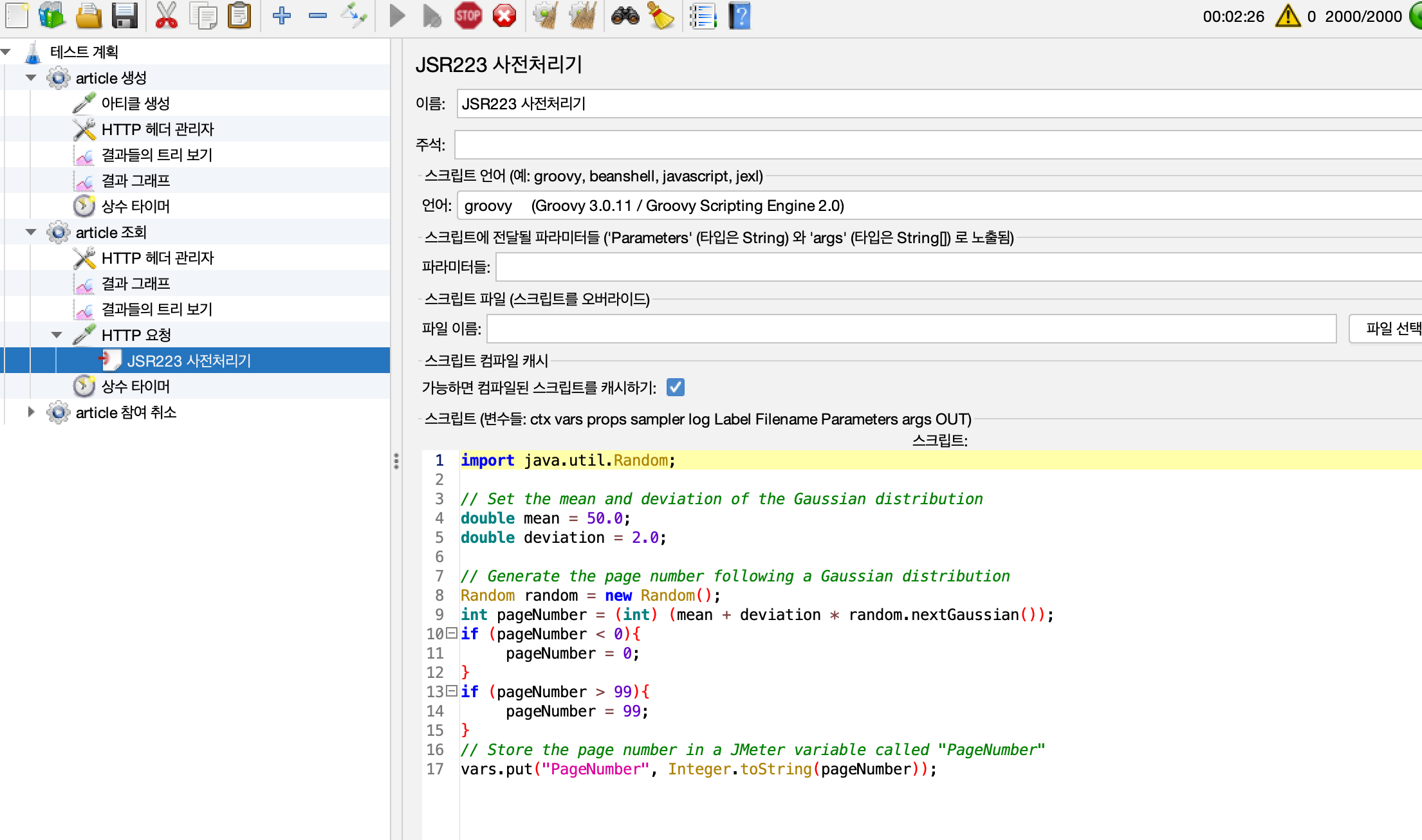
요청 스레드 수 1000 ramp-up 50s
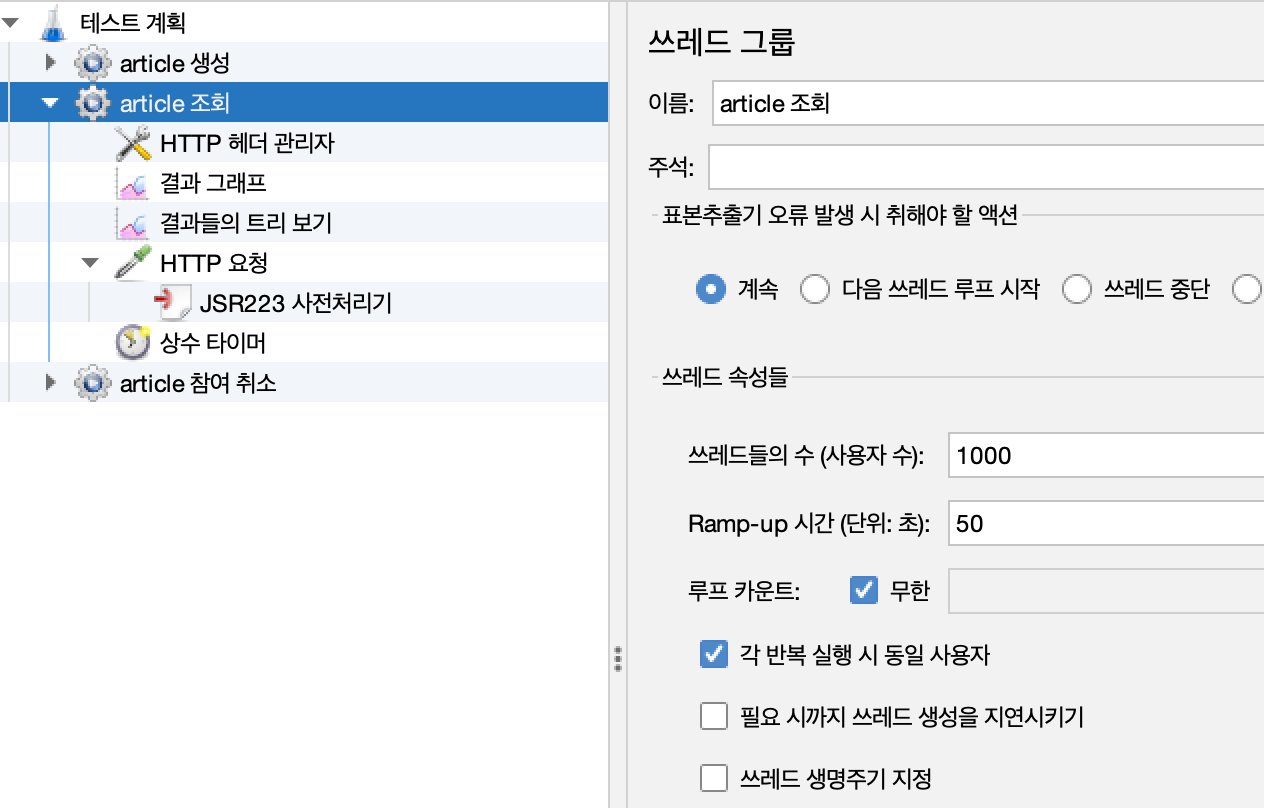
- 데이터 수 약 1000개
평균과 표준편차 결정
평균 50, 표준편차 2인 경우 47.5 ~ 52.5이 나올 경우가 80%가 된다.
- 계산 공식
표준 정규 분포 1.28 이상의 경우가 대략 10%에 해당한다.
x = mean + z * deviation
52.5 =~ 50 + 1.28 * 25분간 실행 후 CacheMiss, Cache Hit 비율 비교할 것입니다.
5-2. PER적용되지 않은 경우
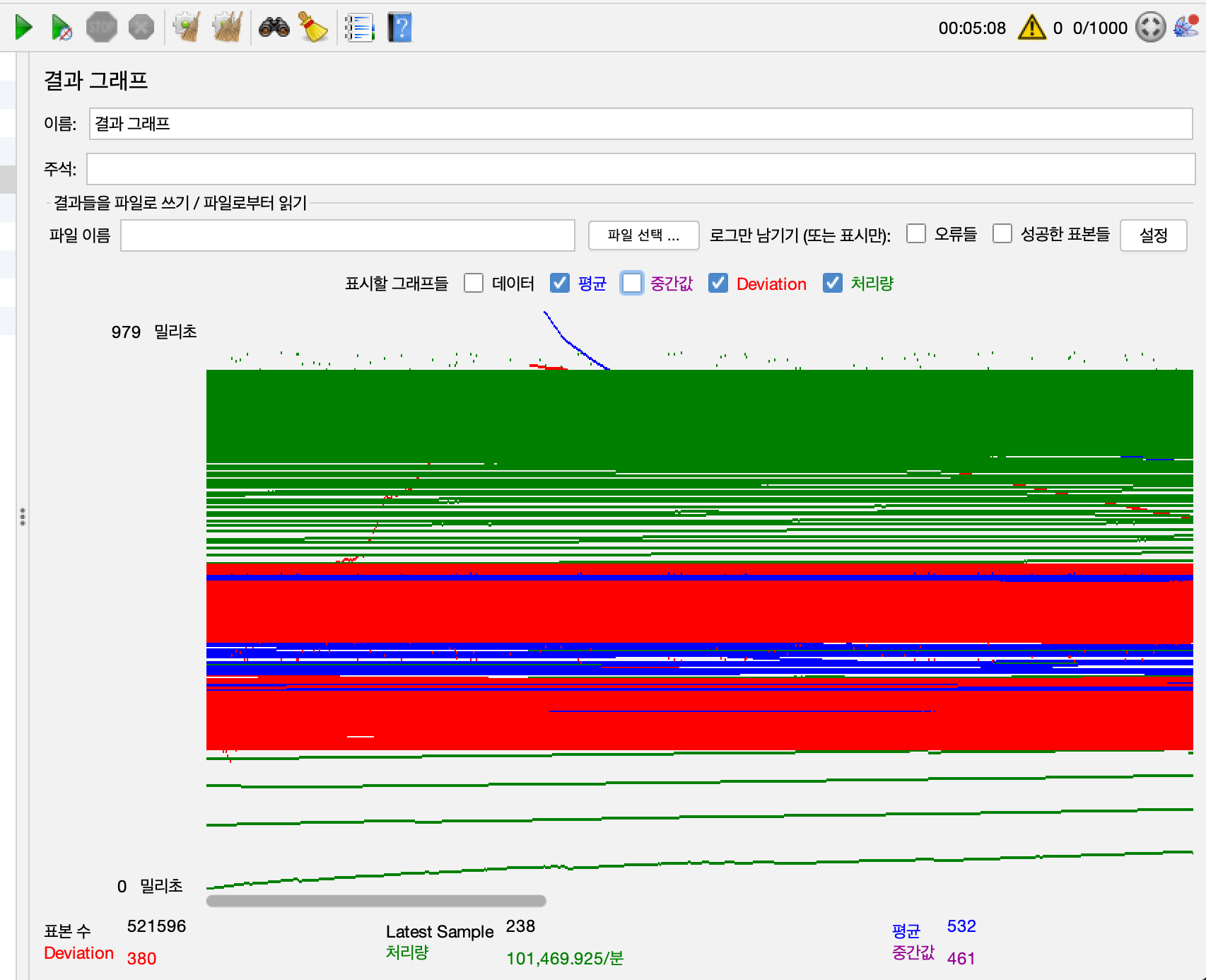
5-2-1.테스트 결과
TPS
- 약 1700TPS
응답 시간
- 평균 0.53S
5-2-2.RDS
CPU

- 45%가량
5-2-3.ElastiCache
CacheHit

CacheMiss

CacheHit Rate

CPU

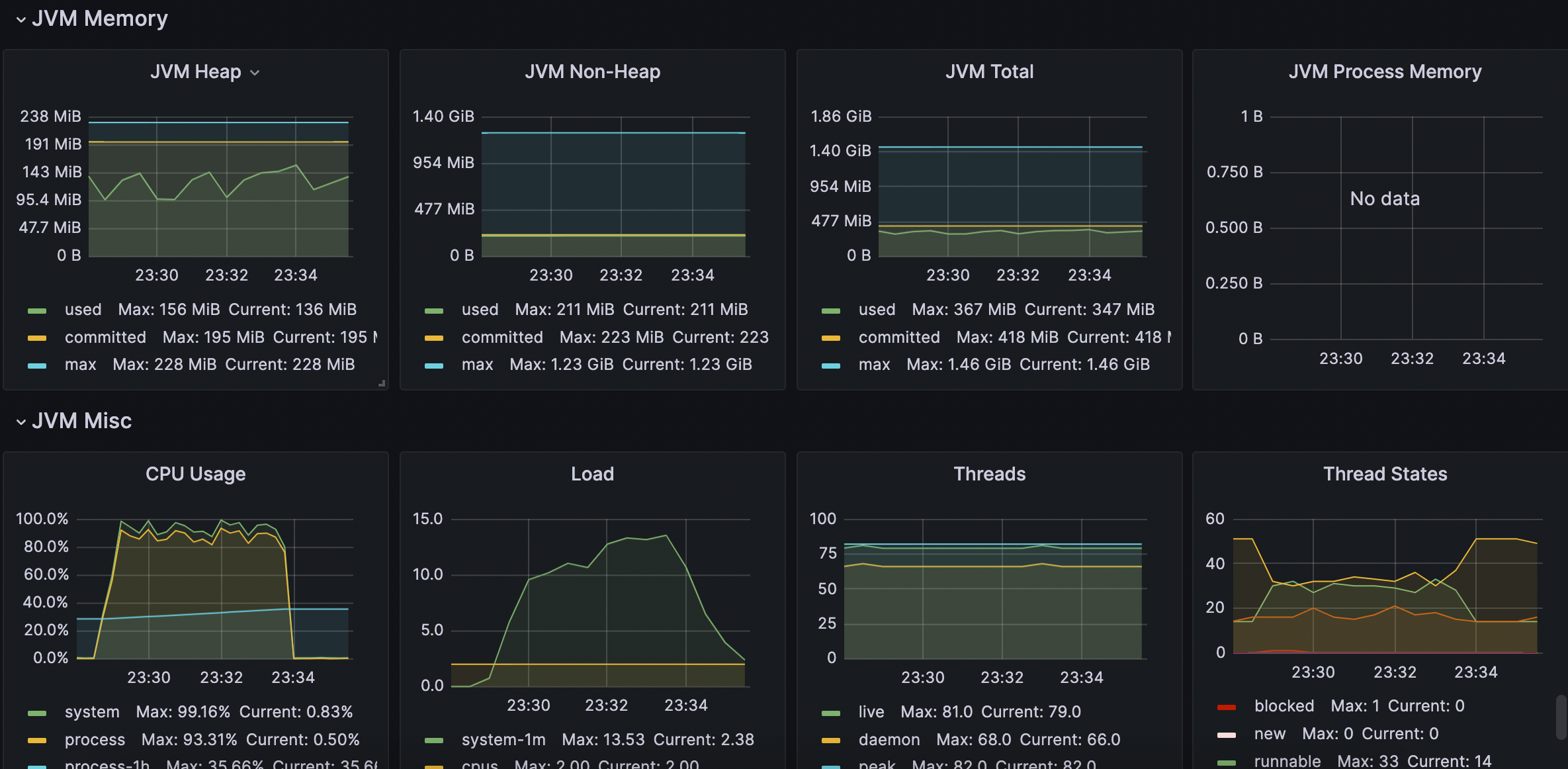
5-2-4.WAS
- CPU, HEAP
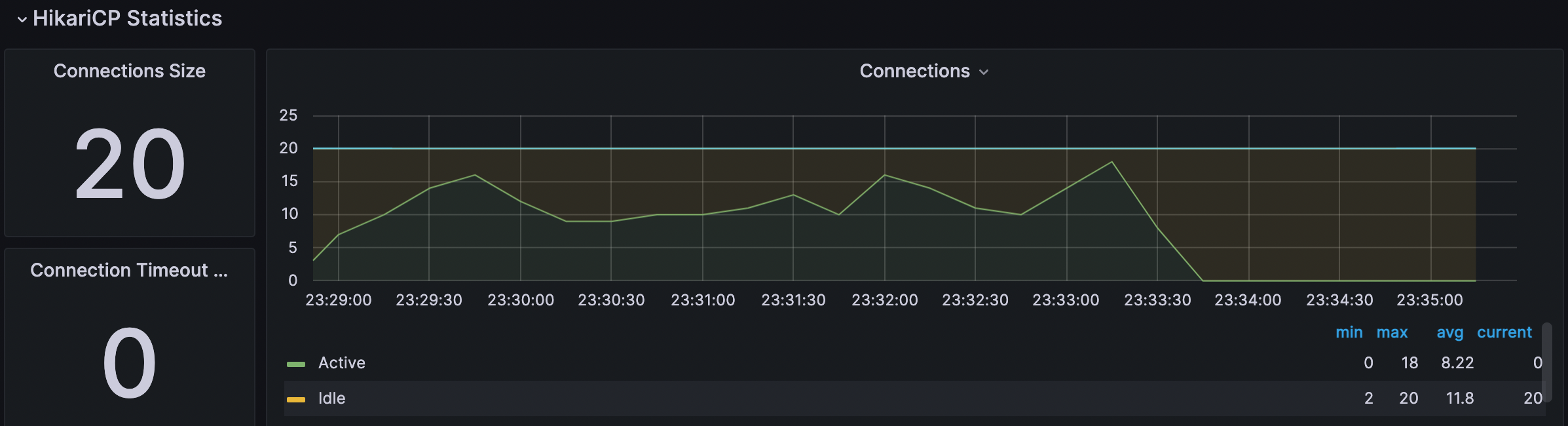
- DBCP
5-2-5. 테스트 결과 종합
1.TPS 1700, 응답시간 0.53s
2.RDS CPU 45%
3.elasticache CacheHit 50k, CacheMiss 1.3k,
CacheHit Ratio 97%
4.WAS CPU 90%, DBCP 10~18(MAX 20)
5-3. PER 적용된 경우
5-3-1.테스트 결과
TPS
- 약 1400TPS
응답 시간
- 평균 0.64S
5-3-2.RDS
CPU
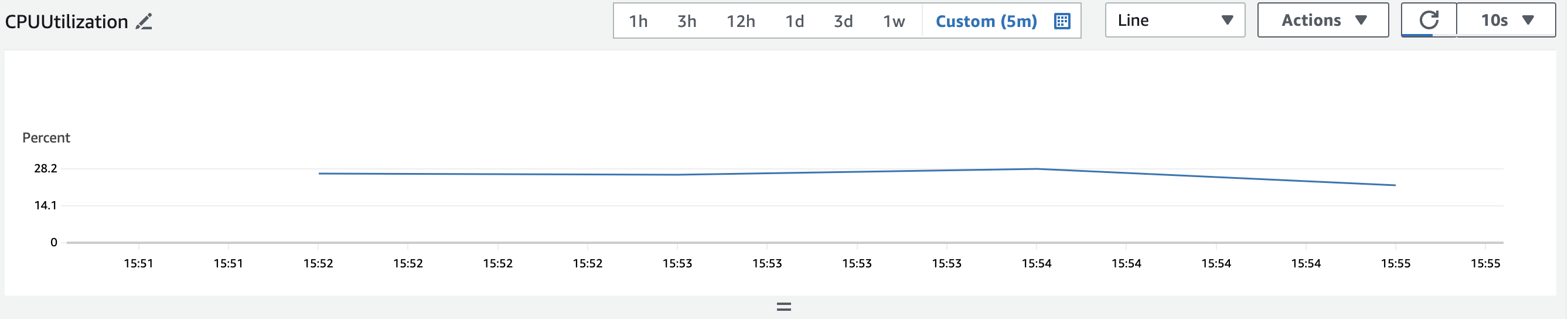
- 28%가량
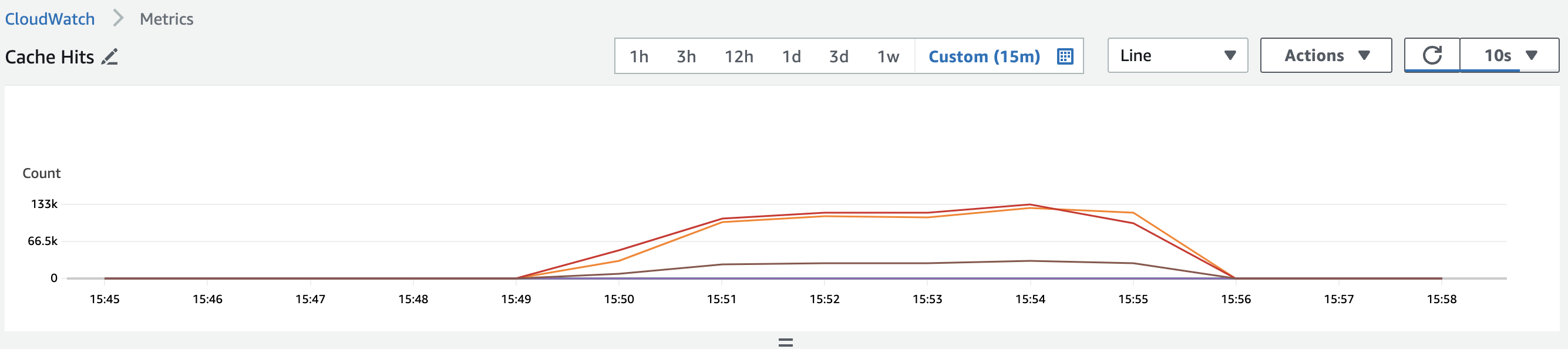
5-3-3.ElastiCache
CacheHit
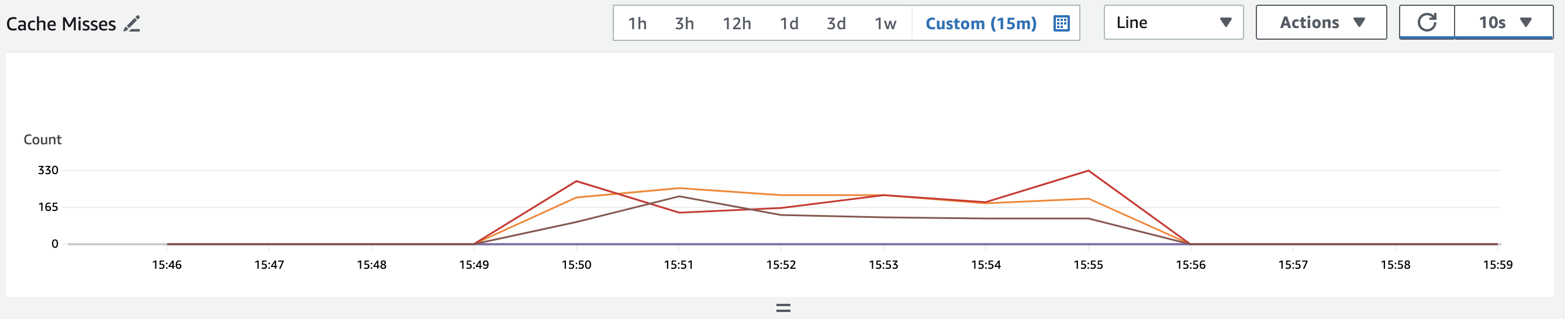
CacheMiss
CacheHit Rate
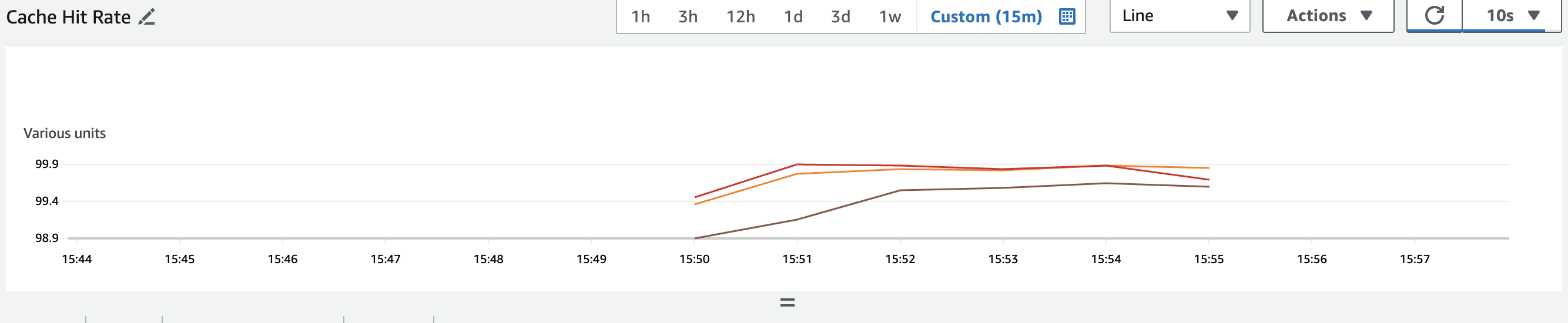
CPU

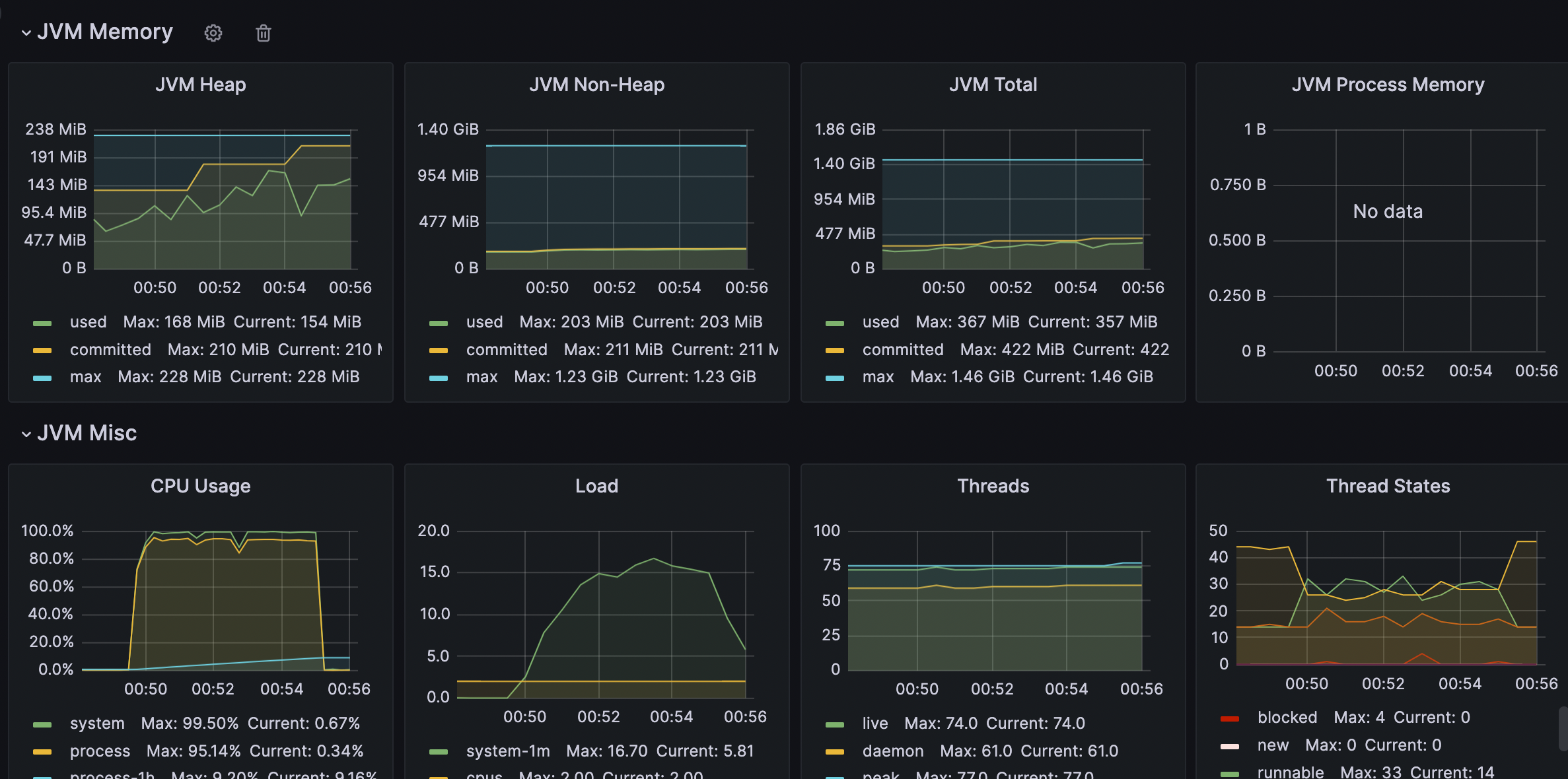
5-3-4.WAS
-
CPU, HEAP
-
DBCP
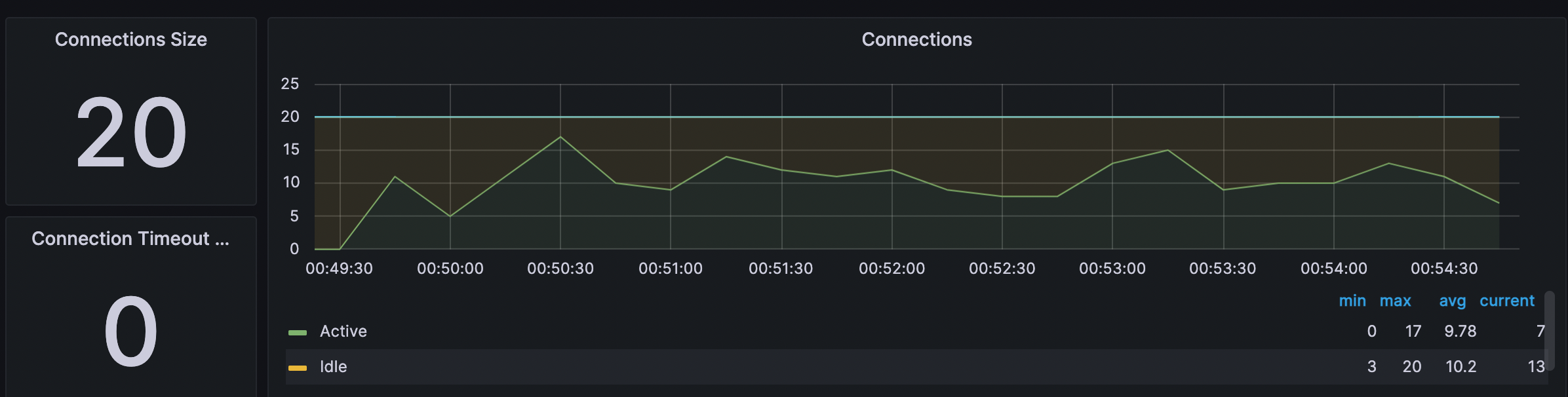
5-3-5. 테스트 결과 종합
1.TPS 1400, 응답시간 0.64s
2.RDS CPU 28%
3.elasticache CacheHit 133k, CacheMiss 0.3k, CacheHit Ratio 99.9%
4.WAS CPU 90%, DBCP 10~18(MAX 20)
6. 테스트 결과 분석
6-1. PER 없는 경우
1.TPS 1700, 응답시간 0.53s
2.RDS CPU 45%
3.elasticache CacheHit 50k, CacheMiss 1.3k,
CacheHit Ratio 97%
4.WAS CPU 90%, DBCP 10~18(MAX 20)
6-2. PER 있는 경우
1.TPS 1400, 응답시간 0.64s
2.RDS CPU 28%
3.elasticache CacheHit 133k, CacheMiss 0.3k, CacheHit Ratio 99.9%
4.WAS CPU 95%, DBCP 10~18(MAX 20)
6-3. 결과 분석
6-3-1. TPS 1700 -> 1400으로 감소
- WAS의 CPU사용률의 max이고 DBCP, RDS, Elasticache의 자원은 여유가 있는 것으로 보아 WAS에서 생긴 병목으로 볼 수 있다. WAS병목을 막기위해 WAS를 더 늘려서 테스트해야할 필요가 있었는데 아쉬운 부분이다. 다만, 테스트 결과분석에는 영향이 없다.
- 그리고 같은 요청인데 TPS가 줄어든 부분은 PER을 적용시 WAS 연산량이 증가하는 부분때문으로 보인다.(recompute 조건 계산, recompute 시간 계산등)
6-3-2. RDS CPU 45% -> 28% 로 총 40%가량 감소.
- PER을 적용한 가장 중요한 부분중 하나이다. TTL로 만료가 되기 전에 계속해서 연장이 되면서 실제 RDS에 조회 요청이 적게 왔다는 증거이며 RDS 부하를 효과적으로 줄였다고 볼 수 있다.
- 시스템 자원을 늘리지 않고 TPS가 15%감소할때 CPU 사용률은 40% 가량 줄였기 때문에 성능 개선이 이루어졌다고 볼 수 있다.
6-3-3. Elasticache CacheHit Ratio 97% -> 99.9%
- Cache Miss가 현저하게 줄었음을 확인할 수 있었다. CacheMiss대비, Cache Hit횟수로보면 약 1/10로 CacheMiss비율이 줄었음을 확인할 수 있다.
현재 테스트의 경우 상당히 제한적인 조건으로 테스트하고 있기 때문에 Hit Ratio가 높게 나왔으며 현실에서는 PER적용 이전, 이후 모두 더 낮을 것이다.
6-3-4. WAS CPU 95%, DBCP 10~18(MAX 20)
WAS는 부하가 한계상태에 도달하였다. WAS가 병목지점이다.
DBCP는 아직 여유가 남아있다.
6-3-5. Elasticache에 가해진 부하 감소
- CPU사용률 3->4%이지만 Cache Hit이 2배가 넘게 증가하였기 때문에 실제 처리량은 훨씬더 많은것으로 보인다. 이에 비해 CPU사용률은 크게 늘지 않았다.
- Elasticache에 가해진 부하가 미비하여 (CPU사용률 3->4%, 및 캐싱 시 메모리는 크게 사용하지 않음.) 크게 체감할 수는 없었다.
7. 결과 종합
- PER 활용 시 RDS의 CPU 사용을 40%가량 줄일 수 있었다.(개선)
- Cache Hit Ratio가 증가하였다.(개선)
- WAS에서는 연산 과정이 더 필요해서 부하가 약간 더 늘어나는 것으로 보인다.(단점)
cf) 실제 상황에서 적용 시
현재 상황의 경우 1400~1700TPS로 테스트하여 CacheMiss로 인한 부하 상승이 덜 체감될 수 있지만 이보다 더 큰 트래픽이 몰려올 경우 Cache Stampede현상으로 인해서 DB, Redis에 부하가 크게 증가할 것이다.
- 따라서 PER을 통한 성능 개선은 더 효과적이라고 기대할 수 있다.
- 다만 테스트 상황은 이상적이고 비교적 규칙적인 요청상황이므로 실제 상황에서는 Cache Hit비율은 많이 떨어질 것이다.
8. 한계점과 개선할점
- Elaticache부하 metrics들을 보면 특정 node에 부하가 집중되어있음을 확인할 수 있다. 그 이유는 특정 Key가 자주 조회 되기 때문일 것이다. Hash Slot이 적용되어 있더라도 특정 Hot key가 자주 접근 되는 것은 막을 수 없다.
- 코드 적으로 PER Get의 경우 CacheManager를 통해 사용되는 @Cacheable에 비해 복잡하다. Service Layer에서 이러한 부가 로직은 감추어 지고 비지니스 로직만 구성되는 것이 좋기 때문에 코드 적인 부분을 개선할 수 있는지 고민해야한다.
참고 문헌
https://cseweb.ucsd.edu/~avattani/papers/cache_stampede.pdf
https://engineering.linecorp.com/en/blog/redis-lua-scripting-atomic-processing-cache
https://redis.io/docs/manual/programmability/lua-api/#global-variables-and-functions
