1. 문제 상황 요약
추가적인 요청 부하 증가(요청 스레드 3배 증가)시 DB에서 병목 발생
- Article 조회 기준
1. 240TPS
2. 응답 시간: 5.5s- Article 참여, 취소 기준
1. 22TPS
2. 응답 시간: 5.5s
2. DB병목이 문제가 되는 이유와 해결법
2-1. 왜 DB가 병목일까?
- 상태를 가지고 있기 때문에 Scale out이 힘들다. WAS는 Stateless하게 유지한다면 Scale out을 얼마든지 할 수 있다.
- Redis와 같은 NOSQL에 비해서 관계형 데이터베이스의 특성상 Master의 Scale out(특히 Sharding, Sharding)이 힘들다.
RDBMS sharding이 힘든이유
1. 구현의 복잡성
2. 일단, Sharding을 할 경우 UnSharding으로 되돌리는 것이 힘들다.
3. 해싱 알고리즘에 따라 특정 shard로 몰릴 수 있다.
4. 다른 shard에 있는 node를 같이 조회해야하는 쿼리는 성능이 안 좋을 수 밖에 없다.
- key-value구조의 redis는 Master를 쉽게 Sharding할 수 있다. key값을 hash slot에 넣어 해당하는 master node로 할당하면 되기 때문이다. 하지만 DB는 테이블간의 관계성 때문에 sharding을 할 경우 join이 제한될 수 있다.
2-2. DB 병목 해결법
- RDBMS자체의 성능을 잘 이끌어 낼 수 있는 방향으로 쿼리를 튜닝하거나 구조를 개선한다.
- 인덱스 적용등을 놓치지 않았는지
- 록을 최소화 하는 방향으로 개선
- 반정규화
- 쿼리 튜닝
- RDBMS를 Scale up, Scale out한다.
- Replication(조회부하를 Replica node를 통해 분산시킬 수 있다.)
- Sharding(Master자체를 늘릴 수 있지만 관계형 데이터베이스는 Sharding에 의한 제한점이 크다.)
- Cache, Event Queue등을 보조 하여 활용한다.
- Redis는 Scale out에 매우 유리하다. 특히, RDBMS와 다르게 적은 제약으로 Master node를 Sharding 할 수 있다.
- Event Queue를 통해 비동기적으로 처리한다.
3. 캐시를 통해 DB부하 분산하여 병목 해결
캐시를 통해 조회 부하를 분산하여 해결하기로 결정하였음.
이 과정에서 캐시 전략및 트레이드오프를 고려하여 적절한 선택을 하였음.
3-1. 캐시 주요 결정 사항
3-1-1. 분산 캐시
- Local Cache를 사용하면 네트워크 통신을 하지 않기 때문에 조회 시 분산 캐시를 활용하는 것보다 훨씬 더 빠르게 조회할 수 있음.
- 하지만, WAS의 Heap memory를 차지하며 데이터 일관성이 더 약해지는 트레이드오프를 고려하여였음.
- 원래 목적은 DB분산 부하가 주된 목적이기 때문에 분산 캐시를 최종적으로 선택하기로 결정하였음.
3-1-2. Redis vs Memcached (Redis 선택)
https://www.imaginarycloud.com/blog/redis-vs-memcached/
- Redis의 경우 다양
- 한 자료구조를 지원한다.
- In-memory이지만 RDB, AOF등을 활용하여 데이터를 백업할 수 있다.
- Scale out 특히 sharding에 유리하고 Clustering을 통해 데이터를 이중화 하여 fail over시 자동복구 할 수 있다.
- Memcached의 경우 scale out 시 Application 에서 로직을 작성해주어야 한다.
3-1-3. write-around
-
DB에만 쓰고 Cache에는 쓰지 않는 전략을 선택.
-
Article 목록으로 받아들여온 경우 데이터 특성상 write-through를 통해 DB와 데이터 정합성을 맞추기 위해서 큰 비용이 발생함.
-
TTL을 통해 적절한 만료시간을 주어 잘못된 데이터가 사용자에게 오래 조회 되지 않도록 함.
-
사용자는 Article 목록 -> Article 단건 상세 -> Article 참여, 취소 등으로 대부분 행동할 것이기 때문에 목록에서 잘못된 데이터가 잠시 보여도 단건에서는 실제 데이터가 보이게 할 수 있음.
3-1-4. TTL 5초
- write-around전략을 선택 했을 때 TTL은 데이터 정합성과 성능 사이에서 트레이드 오프
- TTL을 짧게 유지할 경우 성능은 조금 떨어지지만 데이터가 빠르게 update되고 길 경우 성능은 조금 낫지만 예전 데이터로 조회되는 시간이 길어짐
- 사용자 상황과 성능을 고려하여 5초로 설정
3-1-5. cache-aside(lazy loading)
- 읽는 상황의 경우 캐시에서 먼저 읽는 cache-aside방식을 선택하였음.
3-1-6. Least Frequently Used
- Eviction의 경우 실제 상황에서 테스트 해보아야 정확하게 결정할 수 있지만 실 유저가 테스트가 가능할 만큼 확보 되어있지는 않으므로 가장 기본적인 선택인 LFU를 선택.
4. 부하 테스트 조건 설정
4-1. 조회 요청 Gaussian Distribution
사용자들이 요청하는 목록이 가장 자주 요청되는 경우 20%가 전체 요청의 80에 해당한다고 가정하였다. 이를 위해 Gaussian Distribution을 활용하여 PageNumber의 값을 정하도록 Jmeter를 설정하였다.
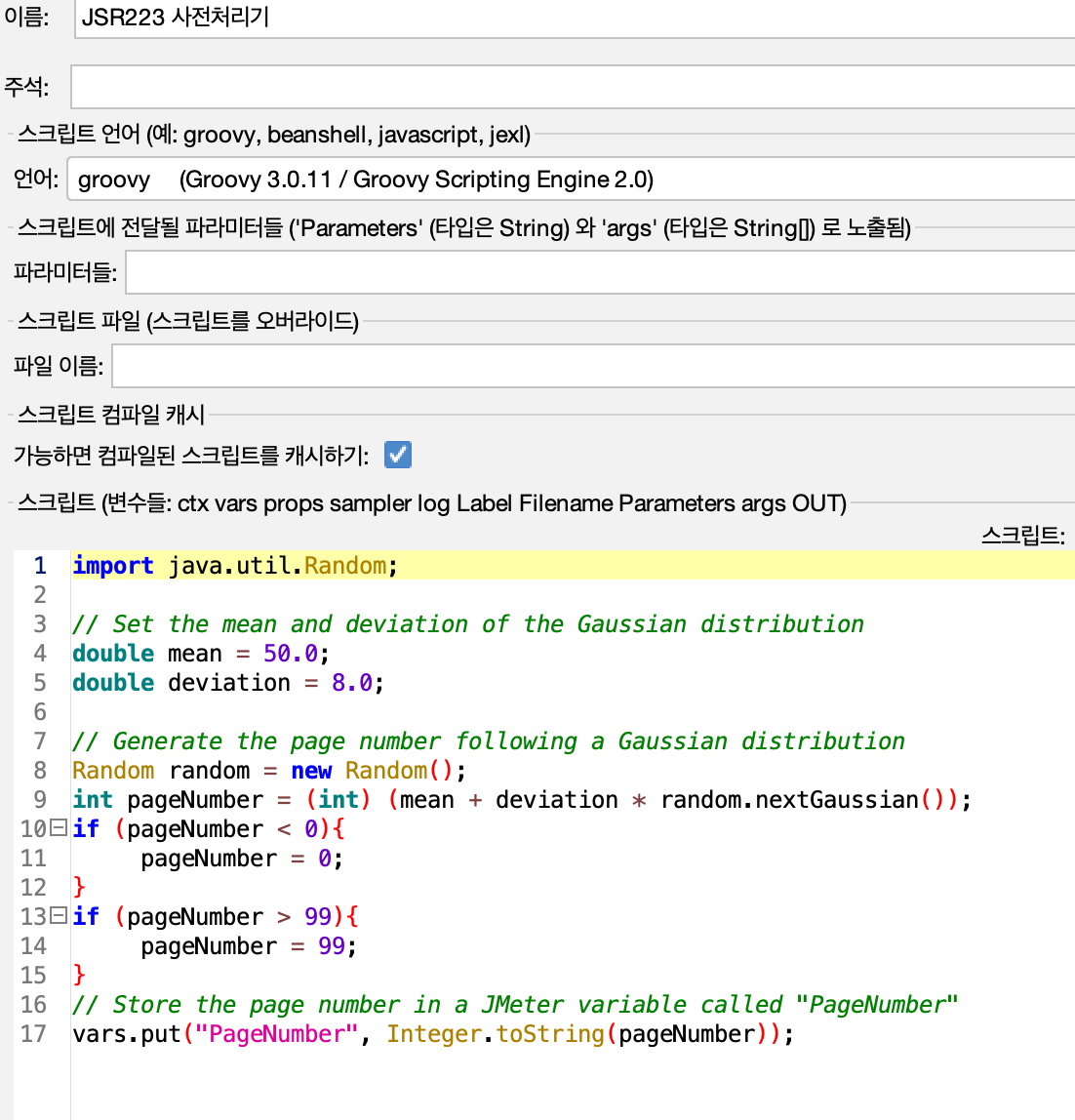
- 데이터 수 약 1000개
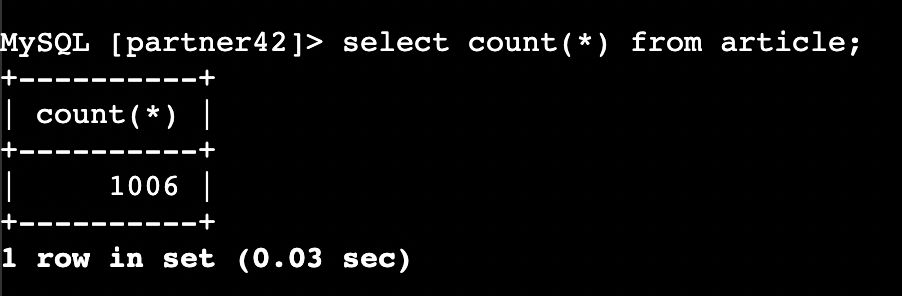
평균과 표준편차 결정
평균 50, 표준편차 8인 경우 40 ~ 60이 나올 경우가 80%가 된다.
- 계산 공식
표준 정규 분포 1.28 이상의 경우가 대략 10%에 해당한다.
x = mean + z * deviation
60 =~ 50 + 1.28 * 8
4-2. 요청 조건
- 조회
- 참여및 취소
cache를 제외한 나머지 조건은 cache가 없던 이전 포스트 상황과 동일.
https://velog.io/@xogml951/Scalability-Test-Thread-Pool-DBCP-%EC%A0%81%EC%A0%95-%EC%84%A4%EC%A0%95%EA%B0%92-%EC%B0%BE%EA%B8%B0
5. Spring Boot Redis Caching 기능 구현
5-1. CacheManager
- RedisTemplate등을 통해 직접 cache-aside로직을 구현하기 보다는 CacheManager를 통해 핵심 비지니스 로직만 코드에 남도록 관심사를 분리할 수 있다.
- Value Serializer로 Default인 JdkSerializationRedisSerializer을 사용하게된다. 이 경우 Serializable interface를 구현해야한다.
- TTL 5초
private static final Integer DEFAULT_EXPIRE_SECOND = 60 * 5;
private static final String ARTICLES_CACHE_NAME = "articles";
private static final Integer ARTICLES_EXPIRE_SECOND = 5;
/**
* Redis Cache를 사용하기 위한 cache manager 등록.<br>
* 커스텀 설정을 적용하기 위해 RedisCacheConfiguration을 먼저 생성한다.<br>
* 이후 RadisCacheManager를 생성할 때 cacheDefaults의 인자로 configuration을 주면 해당 설정이 적용된다.<br>
* RedisCacheConfiguration 설정<br>
* disableCachingNullValues - null값이 캐싱될 수 없도록 설정한다. null값 캐싱이 시도될 경우 에러를 발생시킨다.<br>
* entryTtl - 캐시의 TTL(Time To Live)를 설정한다. Duraction class로 설정할 수 있다.<br>
* serializeKeysWith - 캐시 Key를 직렬화-역직렬화 하는데 사용하는 Pair를 지정한다.<br>
* serializeValuesWith - 캐시 Value를 직렬화-역직렬화 하는데 사용하는 Pair를 지정한다. -> 가시성이 중요하지 않기 때문에 JDKSerializer 사용<br>
* Value는 다양한 자료구조가 올 수 있기 때문에 GenericJackson2JsonRedisSerializer를 사용한다.
*
* @param redisConnectionFactory Redis와의 연결을 담당한다.
* @return
*/
@Bean
public RedisCacheManager redisCacheManager(RedisConnectionFactory redisConnectionFactory,
ObjectMapper objectMapper) {
RedisCacheConfiguration configuration = RedisCacheConfiguration.defaultCacheConfig()
.disableCachingNullValues()
.entryTtl(Duration.ofSeconds(DEFAULT_EXPIRE_SECOND))
.serializeKeysWith(
RedisSerializationContext.SerializationPair
.fromSerializer(new StringRedisSerializer()));
HashMap<String, RedisCacheConfiguration> cacheConfigurations = new HashMap<>();
cacheConfigurations.put(ARTICLES_CACHE_NAME, RedisCacheConfiguration.defaultCacheConfig()
.disableCachingNullValues()
.entryTtl(Duration.ofSeconds(ARTICLES_EXPIRE_SECOND))
.serializeKeysWith(
RedisSerializationContext.SerializationPair
.fromSerializer(new StringRedisSerializer())));
return RedisCacheManager.RedisCacheManagerBuilder
.fromConnectionFactory(redisConnectionFactory)
.cacheDefaults(configuration)
.withInitialCacheConfigurations(cacheConfigurations)
.build();
}
5-2. @Cacheable
- 해당 어노테이션이 적용된 경우 먼저 key값을 가지고 cache를 조회 해본 후 캐시에 존재하지 않으면 메서드 내부 로직을(DB 조회) 실행한다.
@Cacheable(value = "articles", key = "#pageable.pageNumber + '-' + #pageable.pageSize + '-' + #pageable.sort"
+ " + '-' + #condition.anonymity + '-' + #condition.contentCategory +'-'+ #condition.isComplete")
public SliceImpl<ArticleReadResponse>readAllArticle(Pageable pageable,
ArticleSearch condition) {
Slice<Article> articleSlices = articleRepository.findSliceByCondition(pageable,
condition);5-3. Eviction Policy
https://www.alibabacloud.com/tech-news/redis/1qi-how-to-set-eviction-policy-in-redis
- redis-cli를 통해 다음 커맨드 입력 LFU 설정.
CONFIG SET maxmemory-policy allkeys-lruAWS Elasticache 에서는 CONFIG 명령이 제한된다. 따라서 AWS Console을 통해 설정해야한다.
5-4. Write-Around
수정이 발생할때 기존처럼 DB에만 쓰고 Redis캐시 내용은 수정하지 않으면 Write-Around를 만족한다.
6. 부하 테스트 실행
부하 테스트 조건은 4의 내용과(pageNumber정규분포 조회)와 이전 포스트 내용 조건과 동일
6-1. 결과
TPS, RPS
-
article 조회 api
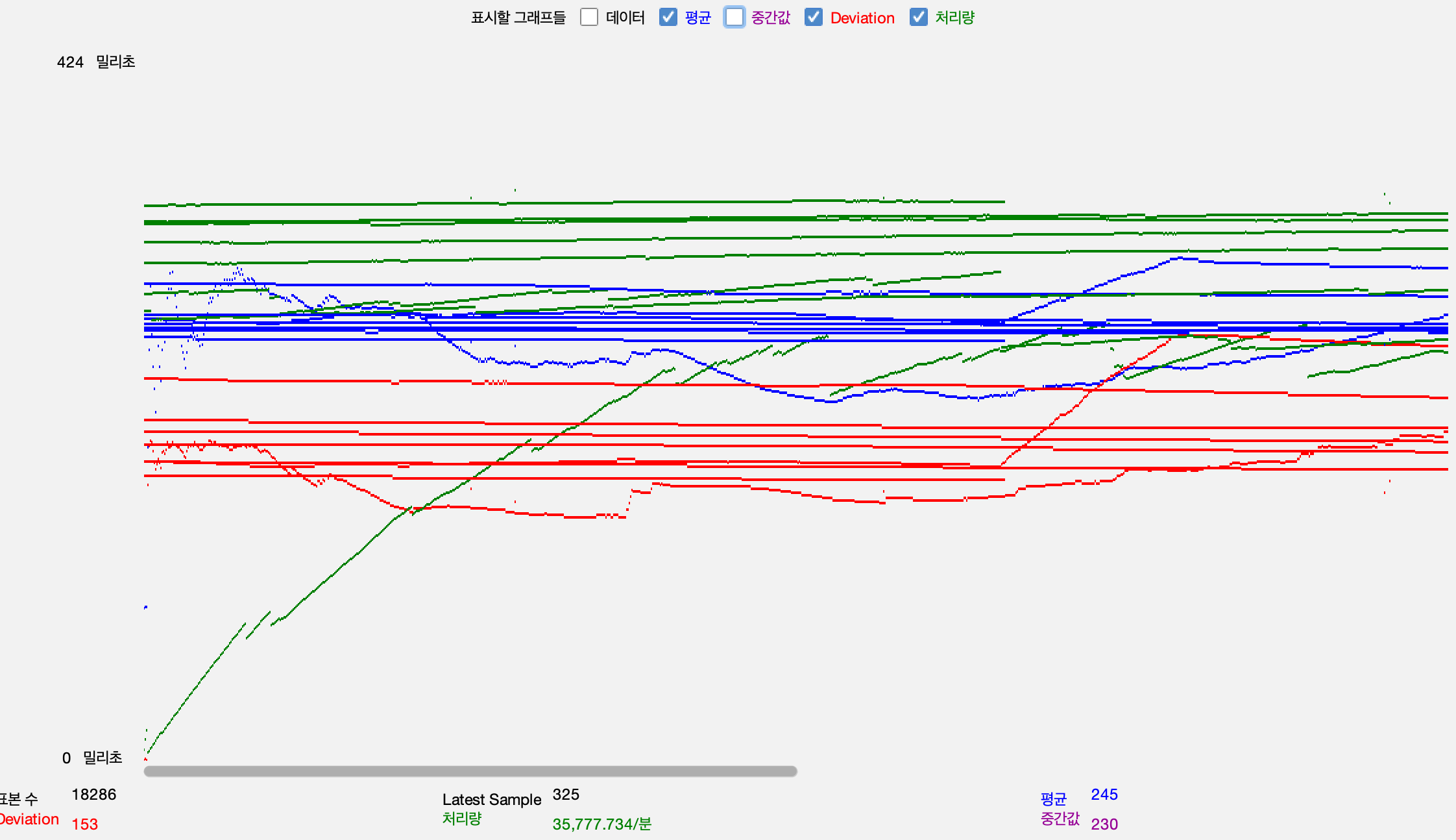
-
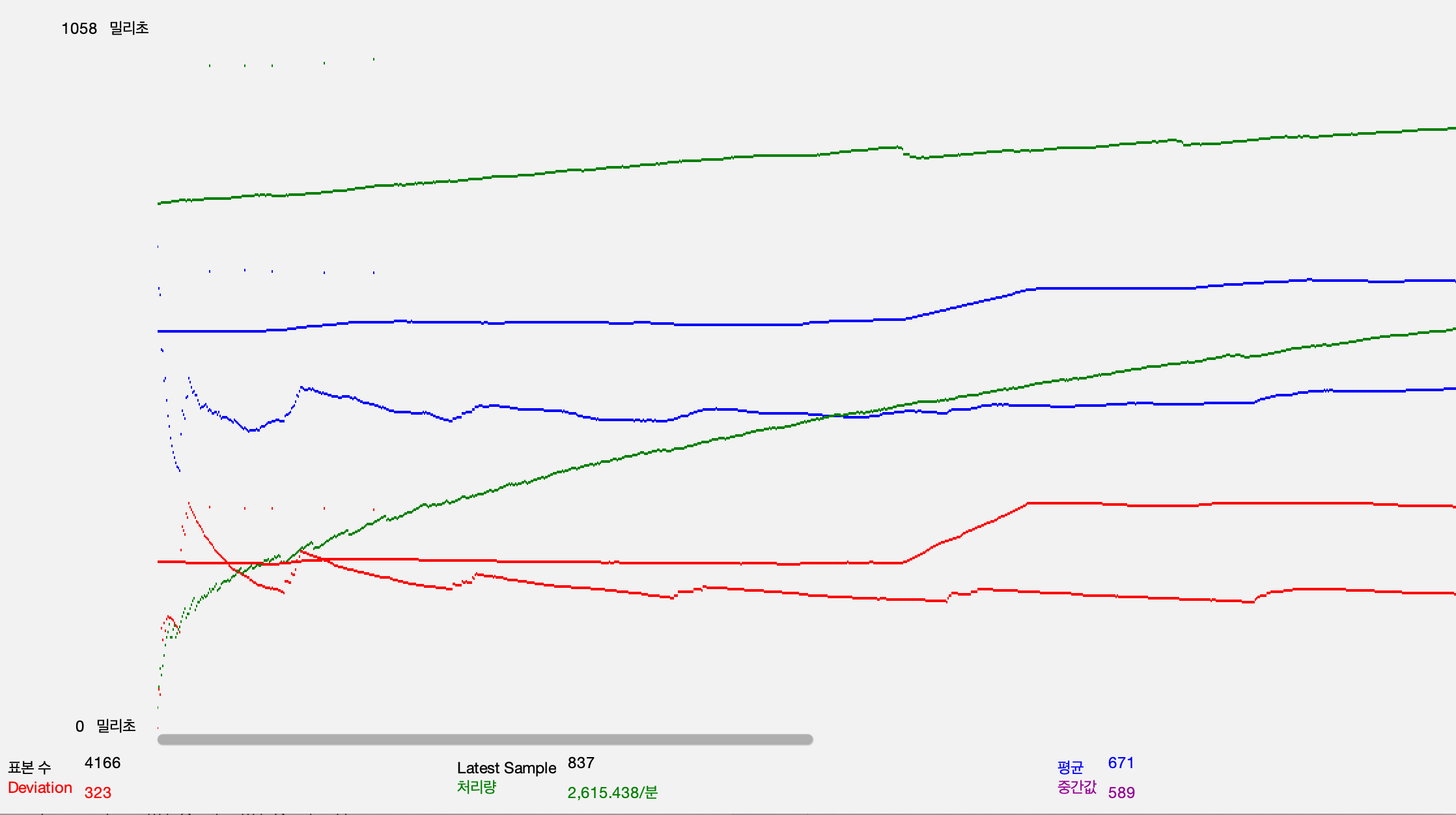
article 참여, 취소 api
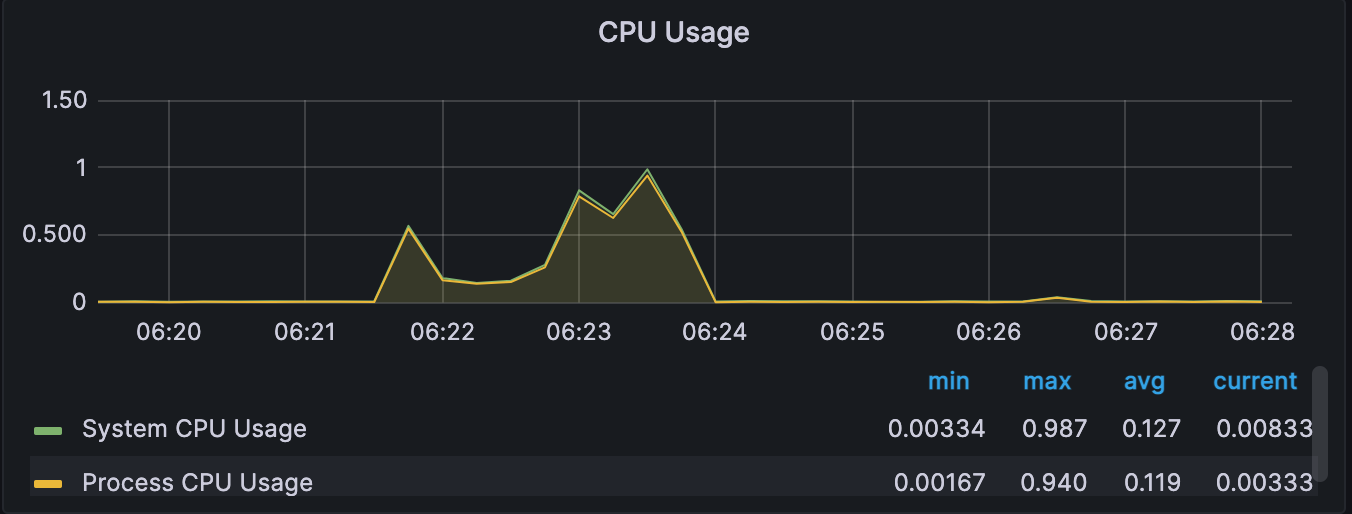
WAS
RDS

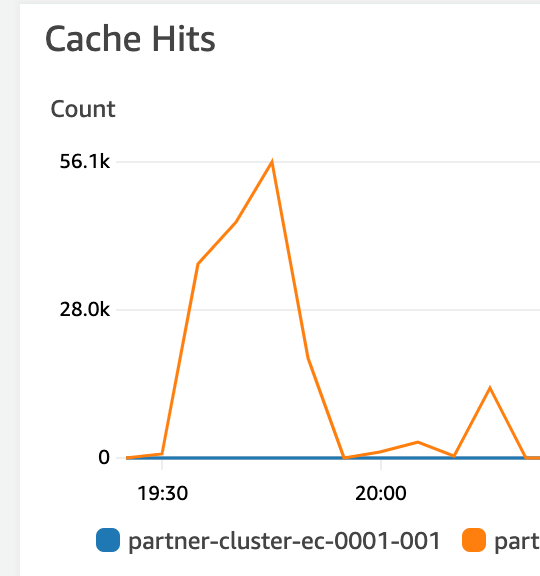
ElastiCache
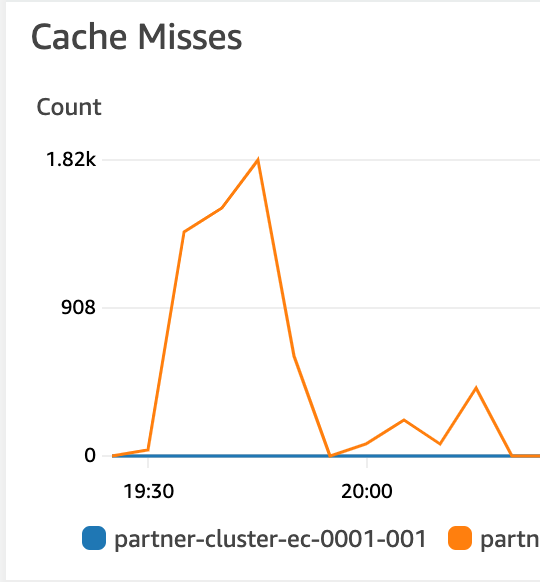
7. 결과
Article 조회 기준
1. 240 -> 600TPS 2.5배 상승
2. 응답 시간: 5.5s -> 2.5sArticle 참여, 취소 기준
1. 22 -> 48TPS 2.2배 상승
2. 응답 시간: 5.5s -> 0.8sRDS CPU사용률
100% -> 23%
