6.3 학습 곡선과 검증곡선을 사용한 알고리즘 디버깅
학습곡선
검증곡선
6.3.1 학습곡선으로 편향과 분산으로 문제 분석
과대적합
데이터에 비해 모델이 너무 복잡하면 과대적합 가능성이 높음
- 너무 복잡하다 : 모델의 자유도나 파라미터가 너무 많으면. 딥러닝의 경우 너무 깊으면
=> sample을 더 모으면 좋아질 수 있음
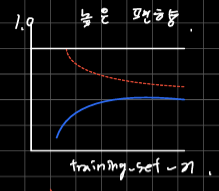
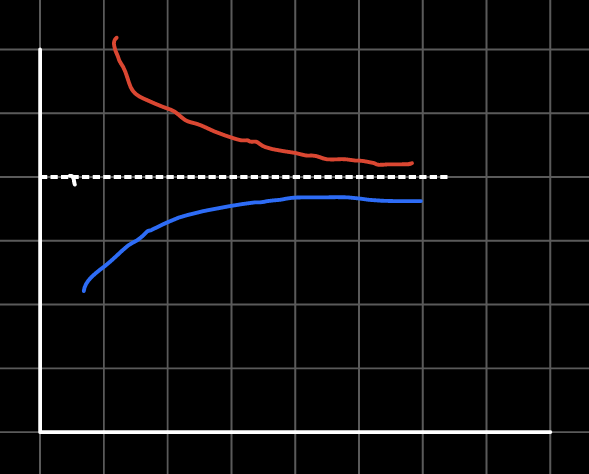
훈련세트의 크기 함수로 그래프를 그려보면 모델의 분산이 높은게 문제인지 편향이 문제인지 판단 가능하다.
훈련 정확도와 검증 정확도가 모두 낮다.
-> 규제 강도를 줄여서 해결할 수 있다.
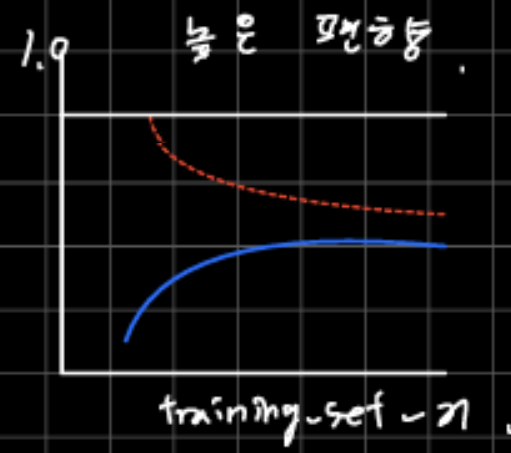
훈련 정확도는 높은데 검증 정확도가 그에 미치지 못한다.
-> 과대적합이라고 한다.
-> 모델 복잡도를 낮추거나 규제를 통해 해결할 수 있다.
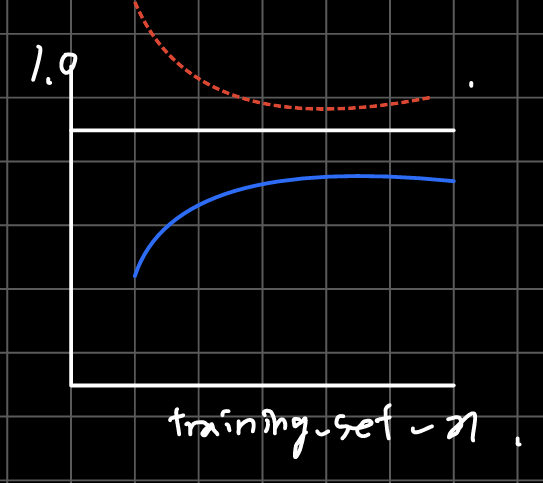
이런 경우는 둘 다 좋은 경우라 최선의 케이스이다.
6.5 여러가지 성능지표
6.5.1 오차 행렬 confusion metrix
TP, TN, FP, FN
앞쪽의 T, F는 예측의 성공했는지(True) 실패했는지(False)를 나타낸다.
뒤쪽의 P, N은 긍정예측인지(Positive), 부정 예측인지(Negative)인지를 나타낸다.
ex) TN : N으로 예측했는데 맞았다.
6.5.2 분류모델의 정밀도(Precision)와 재현(Recall)율 최적화
precision은 정밀도라고한다. 한국어로 누가 번역을 만들었는지 모르겠지만 정말 직관적이지 않은 이름이라고 생각한다.
쉽게 이진분류를 기준으로 설명하면 내가 1이라고 고른것중에 진짜 1인 경우가 몇 퍼센트인가를 뜻한다. 즉, 내가 얼마나 엄한걸 고르지 않고 정확하게 골랐는가를 나타낸다.
Recall은 재현율이라고 한다.
앞서 설명처럼 이진분류를 기준으로 설명하면 실제 1인것 중에 내가 몇개나 맞췄는가이다. recall은 내가 찾고싶은걸 얼마나 잘 찾을 수 있는가를 나타낸다.
Precision과 Recall의 조화평균이다.
두 지표의 의미를 적당히 조합한 지표이다.

AI 엔지니어 김태종입니다. 추천시스템, 이상탐지, LLM에 관심이 있습니다. 블로그에는 공부한 기술, 논문 혹은 개인적인 경험을 올리고 있습니다.