머신러닝 교과서
1.3장 분류모델(1) Logistic Regression
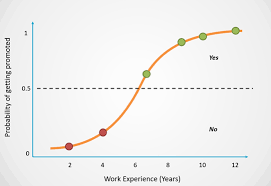
1. Logistic Regression regression이지만 회귀가 아니라 분류 모델이다. logistic regression은 간단하지만 선형모델에서 강력한 성능을 보여주낟. Odd Ratio $odds\,\,ratio = \frac{P}{1-P}$ (P
2.3장 분류모델(2) SVM(Support Vector Machine)
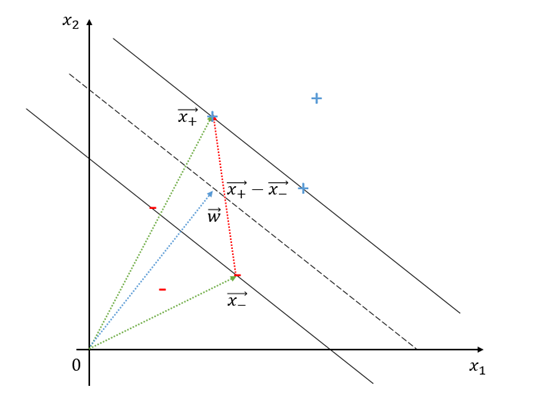
Support Vector Machine? support vector machine, SVM은 가장 기본적인 deepleanrning 모델중 하나인 퍼셉트론의 확장형 모델이다. 차이점은 단순히 분류를 위해 초평면을 찾는것 뿐만 아니라 margin을 최대화하느것이 목표
3.3장 분류모델(3) Decision Tree(결정 트리)
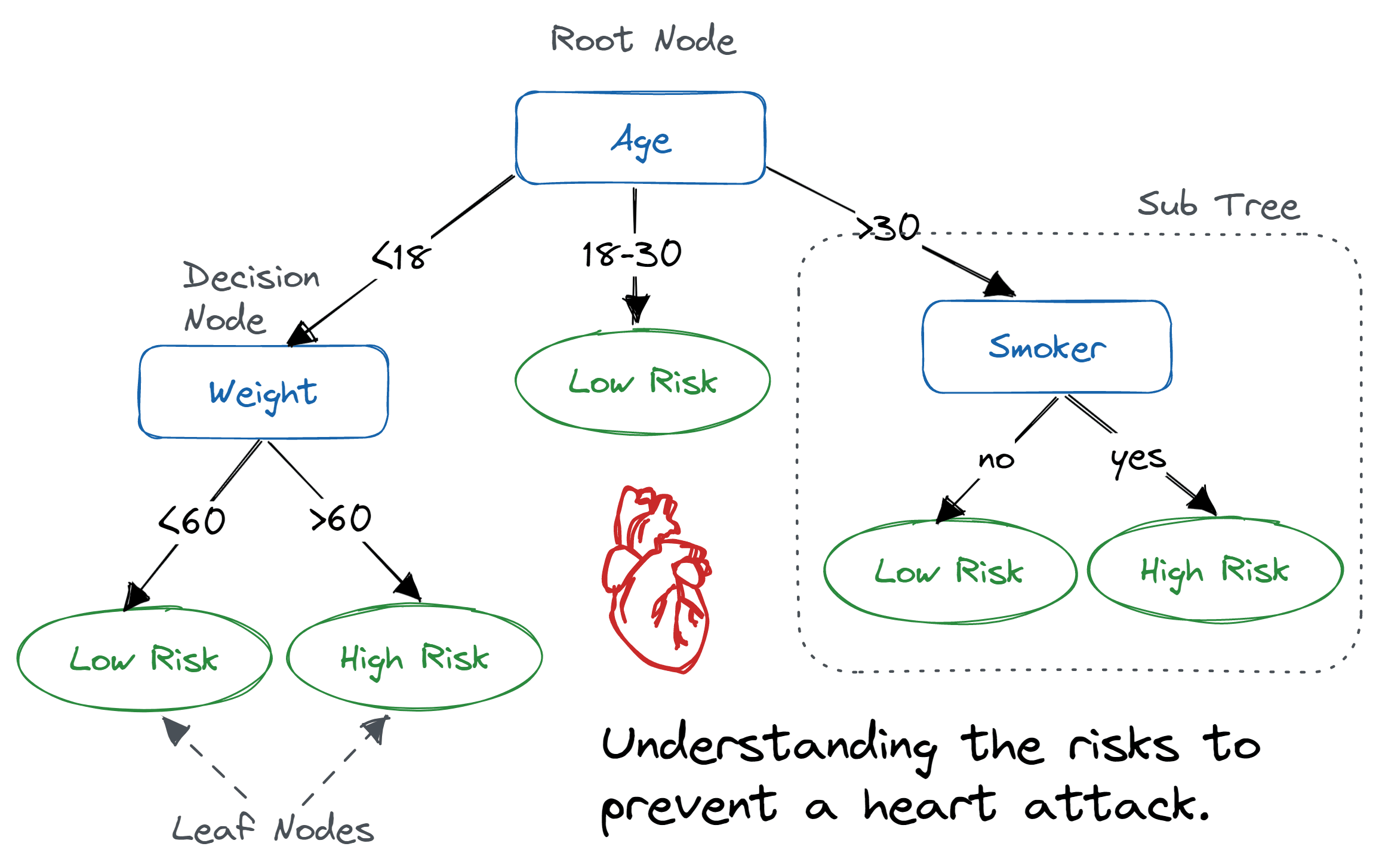
Decision Tree, 결정 트리 feature를 기반으로 클래스의 lable을 cnwjd 범주형/연속형 데이터 모두 가능 tree root부터 시작하여 information Gain(정보이득)이 최대가 되는 특성으로 데이터를 나눈다. 과적합을 막기 위해 tree
4.3장 분류모델(4) KNN, K-Nearest Neighborhood
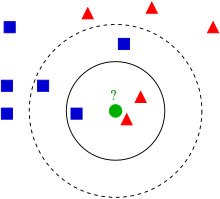
KNN 알고리즘은 분류알고리즘 중 가장 직관적인 알고리즘이다.또한 KNN알고리즘은 전형적인 lazy learner(게으른 학습모델)이다. parameter를 학습하여 저장하는 모델(parametic model)과 달리 훈련세트 자체를 전부 저장하는 방식으로 작동하는 모
5.4장 데이터 전처리 (1)

누락 데이터 삭제 -> 해당 row나 column을 삭제보간법을 사용하여 누락값 대체평균(혹은 중앙값, 최빈값 등)으로 대체 가능중요한 점은 훈련 세트와 테스트 세트의 변환 방법을 동일하게 가져가야 한다는 점이다. 연속형이 아닌 A, B, C와 같이 범주로 묶여있는 데
6.4장 데이터 전처리 (2)
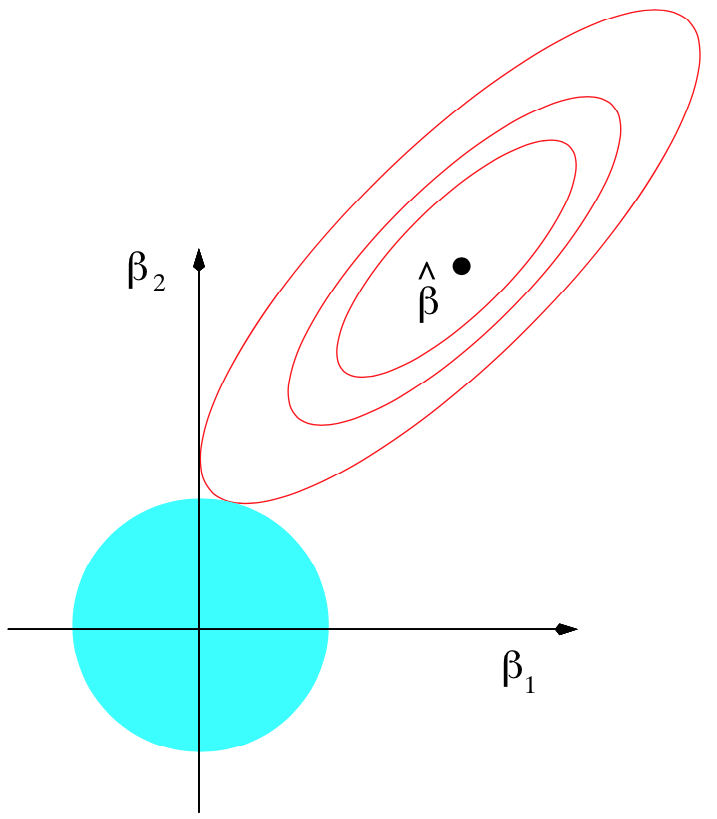
과대적합(overfitting) : 훈련 세트에 너무 가깝게 맞춰진 샘플 과대적합을 벗어나는 방법은 대표적으로 아래와 같은 방법들이 있다. 더 많은 훈련 세트를 준비 규제(regularization)를 활용해 복잡도 제한더 간단한 모델 사용차원 축소 $L1 : ||\\
7.5장 차원 축소를 사용한 데이터 압축-PCA (1)
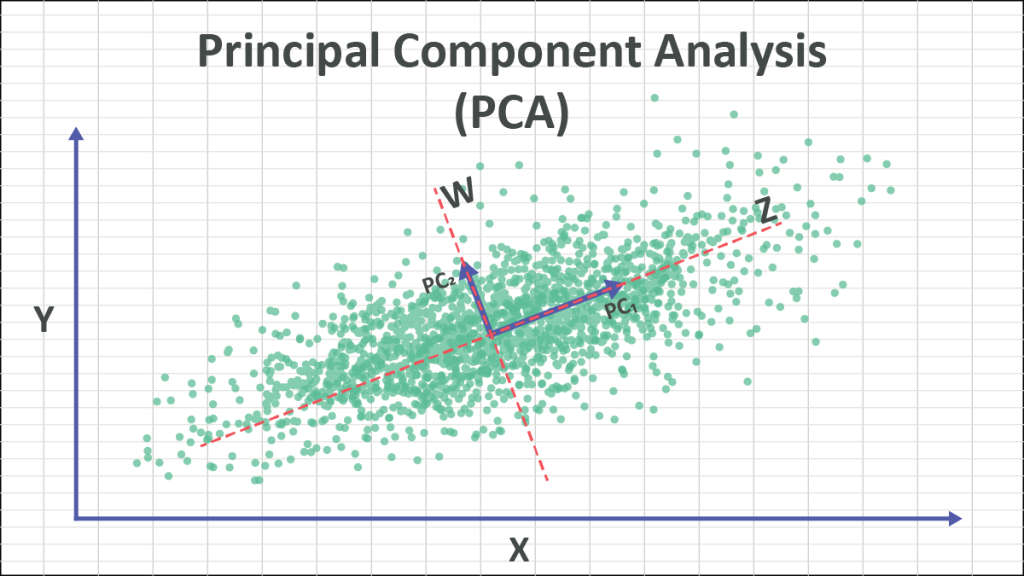
EDA, Denoising 등에서 활용가능한 차원 축소 방법pca는 상관관계 기반 패턴 찾기 방법이다. => 분산이 가장 큰 방향을 찾는다. \-> 구분이 잘 되는 방향을 찾는다. \-> 설명력이 높은 방향을 찾는다. 위 그림을 바탕으로 설명하기에 앞서 분산에 대해서
8.5장 차원 축소를 사용한 데이터 압축-LDA (2)
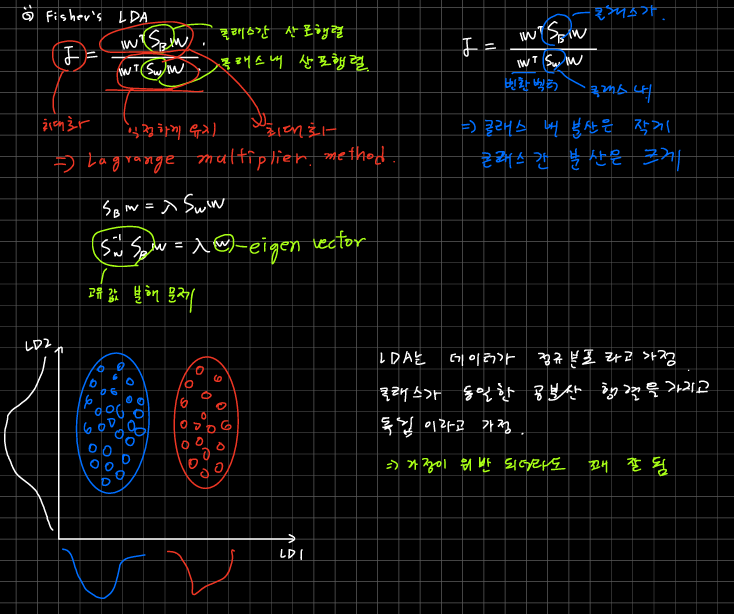
선형 판별 분석 (Linear Discriminant Analysis)차원의 저주로 인한 과대적합 해결기본적으로 PCA 유사 일반적으로 LDA가 지도학습이라 더 좋다고 생각할 수 있음But 클래스별 샘플이 몇 개 안될 때 오히려 PCA가 좋을 수 있음 쉽게 말해서 LD
9.6장 K-겹 교차 검증 (1)
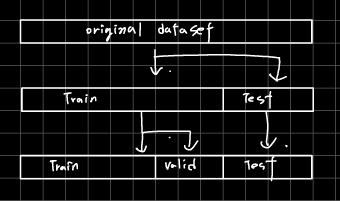
머신러닝 모델 구축의 핵심 중 하나는 새로움 데이터에 대한 test과정을 구축하는 것이다. 방법에는 크게 두 가지가 있다. Holdout cross-validation K-fold cross-validation홀드아웃 방법은 가장 흔하게 사용되는 train, valid
10.6장 학습 곡선과 검증곡선을 사용한 알고리즘 디버깅 (2)
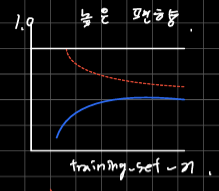
학습곡선검증곡선데이터에 비해 모델이 너무 복잡하면 과대적합 가능성이 높음너무 복잡하다 : 모델의 자유도나 파라미터가 너무 많으면. 딥러닝의 경우 너무 깊으면=> sample을 더 모으면 좋아질 수 있음훈련세트의 크기 함수로 그래프를 그려보면 모델의 분산이 높은게 문제인