삽입정렬
삽입 정렬(Insertion Sort)은 정렬되지 않은 부분의 데이터를 정렬된 부분에 순차적으로 삽입해가며 정렬하는 알고리즘입니다.
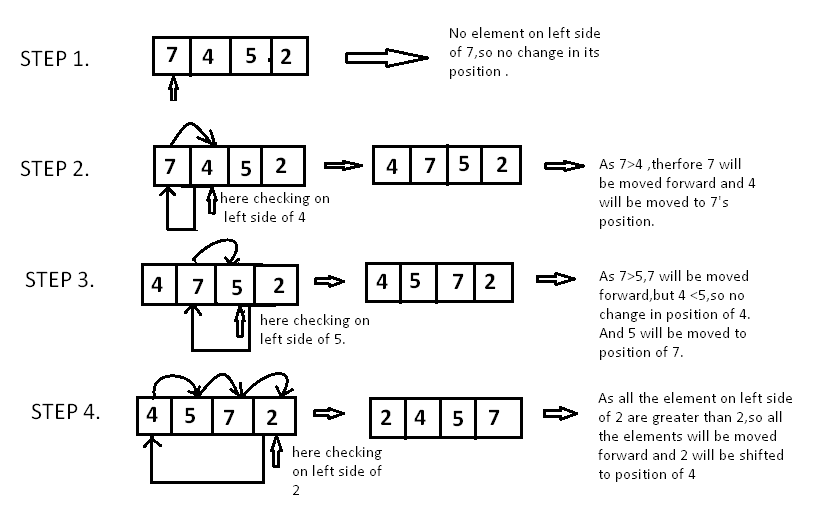
위 그림에서 삽입 정렬의 동작 과정을 시각적으로 쉽게 이해할 수 있습니다. 첫 번째와 두 번째 데이터를 비교하여 정렬 순서가 맞도록 합니다. 그다음 세 번째, 네 번째 데이터를 순차적으로 비교하면서, 정렬된 영역에 삽입하여 정렬을 이어갑니다.
정렬이 완료된 영역의 다음 위치에 있는 데이터가 그다음 정렬 대상이 됩니다. 이때, 삽입할 위치를 찾으면, 그 위치까지의 데이터를 한 칸씩 뒤로 밀면서 삽입할 수 있습니다.
삽입 정렬 시각화에서 삽입 정렬 알고리즘의 진행 과정을 확인할 수 있습니다.
구현 코드
#include <stdio.h>
void InserSort(int arr[], int n)
{
int i, j;
int insData;
for(i=1; i<n; i++)
{
insData = arr[i]; // 정렬 대상을 insData에 저장
for(j=i-1; j>=0 ; j--)
{
if(arr[j] > insData)
arr[j+1] = arr[j]; // 비교 대상 한 칸 뒤로 밀기
else
break; // 삽입 위치 찾았으니 탈출!
}
arr[j+1] = insData; // 찾은 위치에 정렬 대상 삽입!
}
}
int main(void)
{
int arr[5] = {5, 3, 2, 4, 1};
int i;
InserSort(arr, sizeof(arr)/sizeof(int));
for(i=0; i<5; i++)
printf("%d ", arr[i]);
printf("\n");
return 0;
}성능 평가
삽입 정렬의 시간 복잡도를 분석해 보면, 바깥쪽 반복문은 번 반복되며, 안쪽 반복문은 최악의 경우 -1번 반복됩니다. 이를 수식으로 표현하면:
따라서 삽입 정렬의 평균 시간 복잡도는 입니다.
장단점
장점
- 적은 데이터에 대해 매우 효율적입니다. 알고리즘 중 상대적으로 빠른 편입니다.
- 데이터가 거의 정렬된 경우 시간 복잡도가 에 가깝게 줄어듭니다.
단점
- 데이터가 클 경우 시간 복잡도가 높아 비효율적입니다.
- 다른 효율적인 정렬 알고리즘에 비해 큰 데이터셋에 적합하지 않습니다.
결론
삽입 정렬은 구현이 간단하고, 적은 양의 데이터나 거의 정렬된 데이터를 처리할 때 매우 유용한 알고리즘입니다. 하지만, 데이터 양이 많아질수록 의 시간 복잡도로 인해 성능이 저하되므로, 대규모 데이터 처리에는 다른 정렬 알고리즘이 더 적합합니다.
