
WWDC 2020에서 Detect Body and Hand Pose with Vision 이라는 세션을 정리하였습니다.
Vision이란?
공식문서를 찾아보면
Vision은 얼굴, 텍스트 감지, 바코드 인식, 이미지 등록등을 수행하는 프레임 워크입니다.
Vision Framework가 처음 소개되었을 때는 딥 러닝 기술을 기반으로 한 얼굴감지였습니다.
이후 WWDC2020을 통해서 Hand Pose와 Body Pose를 감지하는 기능을 발표했습니다.
먼저 Hand Pose에 대해서 알아보겠습니다.
Hand Pose

Vision FrameWork의 Hand Pose는 위 사진 처럼 손의 위치나 자세를 인식해 줍니다.
영상에서 소개하는 Vision FrameWork의 Hand Pose를 이용한 몇가지 예시를 살펴보겠습니다.

사진을 찍는 제스처를 만들어 터치없이 사진을 찍을 수 있습니다.

Hand Pose와 일치하는 이모지를 손위에 덧씌울 수 있습니다.
다음은 사용 방법입니다.
Vision Framework의 Hand Pose를 사용하는 방법

-
request handler를 만들기
image request handler를 사용합니다.VNImageRequestHandler: 이미지로부터 얼굴정보나 텍스트를 찾는 등 이미지 분석을 처리
-
request를 만들기
VNDetectHumanHandPoseRequest를 사용합니다. -
performRequests호출을 통해 handler에게 요청을 제공
이 작업이 완료되면 requests result property에observations를 가집니다.(VNRecognizedPointsObservations가 리턴)

observations에는 발견된 모든 손의 랜드마크 위치가 포함되어 있습니다.
사용 중인 알고리즘이 위치만 반환하는 경우 VNPoint가 부여됩니다.
VNPoint에는 CGPoint 타입의 location이 포함되어 있으며, 원하는 경우 해당 위치의 X 및 Y 좌표에도 직접 액세스할 수 있습니다.
사용 중인 알고리즘에 confidence(신뢰성)가 있는 경우 VNDetectedPoint 객체를 가져옵니다.
VNDetectedPoint : 이미지에 정규화된 지점을 confidence value 와 함께 나타내는 객체
open class VNDetectedPoint : VNPoint {
open var confidence: VNConfidence { get }
}마지막으로 알고리즘이 point를 labelling 하면 VNDetectedPoint 객체를 가져옵니다. (Hand Pose의 경우 VNRecognizedPoint 객체가 리턴)
Hand landmarks

Vision에서는 손에 대한 landmark(인식 지점)를 총 21개(손가락 마다 4개 + 손목에 1개) 제공합니다. 각 landmark 마다 키값을 가지고 있고 이를 이용해서 해당 포인트에 접근할 수 있습니다.
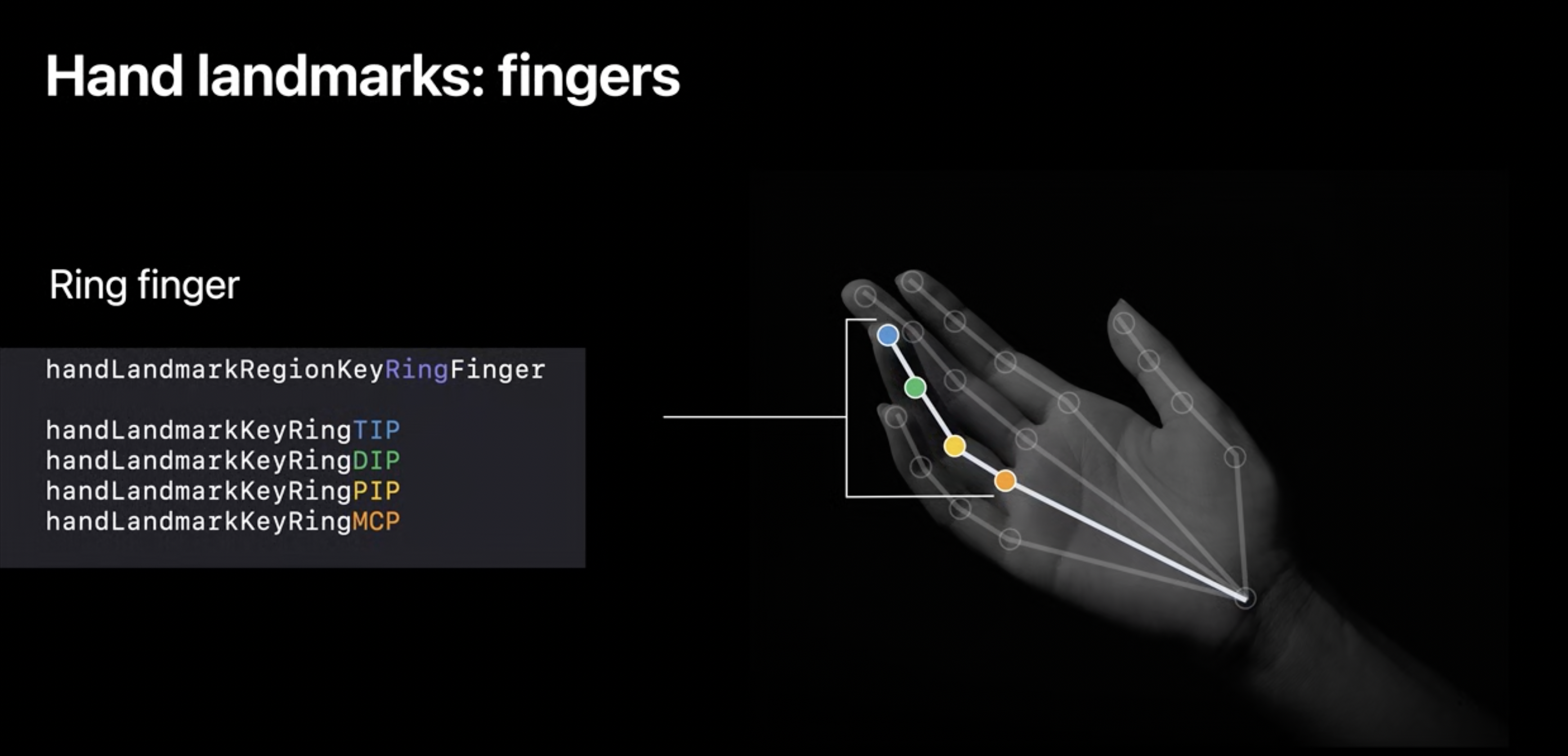
손가락에서는 랜드마크를 구별하기 위해 약어를 사용하고 검지(Index), 중지(Middle), 약지(Ring), 소지(Little) 4개의 패턴은 동일합니다.
Ring finger(약지) VNRecognizedPointGroupKey(약지의 모든 landmark를 담고있는 그룹키값) : handLandmarkRegionKeyRingFinger
Ring finger의 VNRecognizedPointKey (약지그룹 안에 있는 각각의 landmark에 접근할 수 있는 키값)
handLandmarkKeyRingTIP(Tip of finger) // 끝에서 부터handLandmarkKeyRingDIP(Distal interphalangeal joint)handLandmarkKeyRingPIP(Proximal interphalangeal joint)handLandmarkKeyRingMCP(Metacarpophalangeal joint)
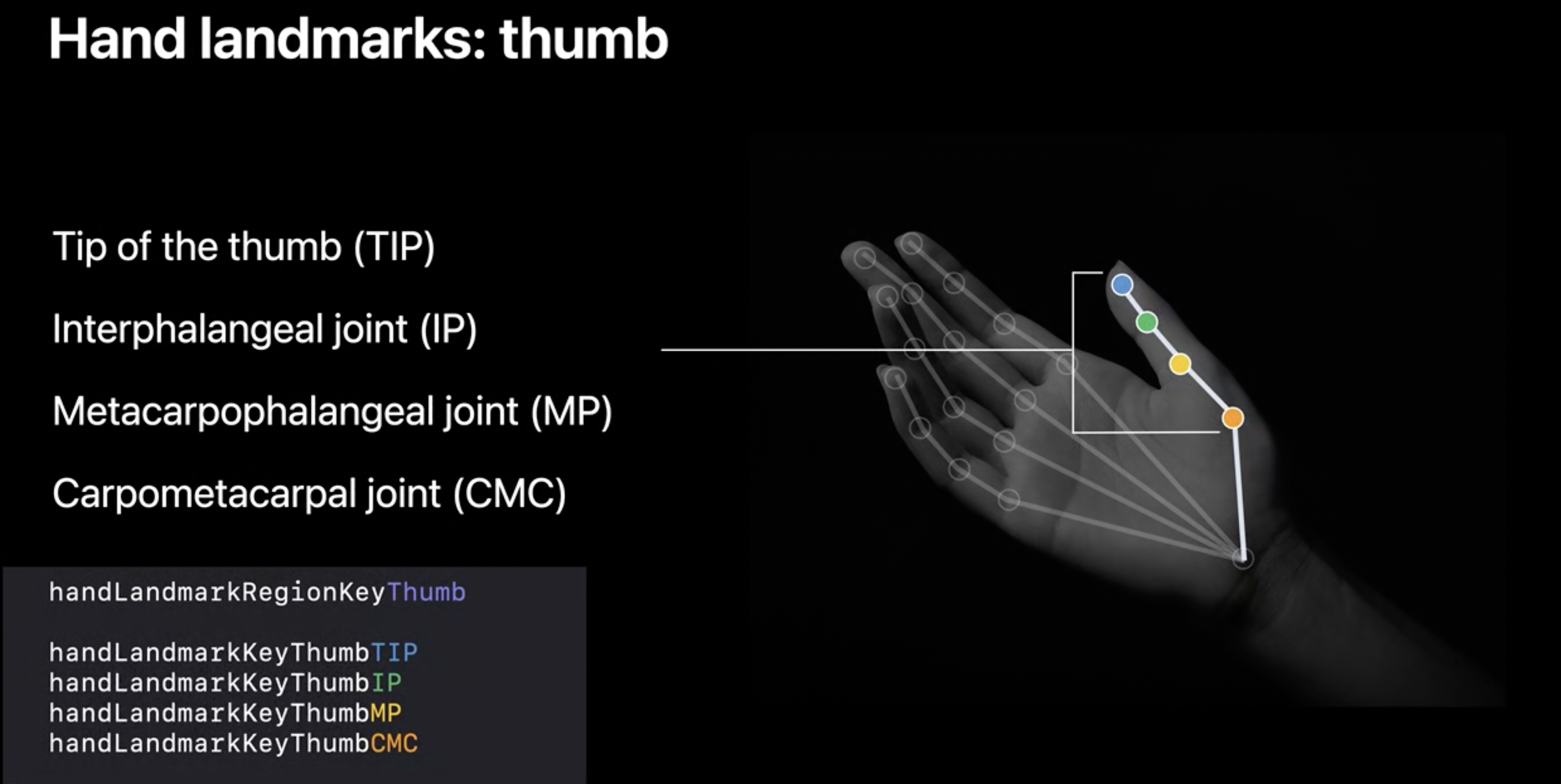
엄지는 조금 나머지 4개의 손가락과 약어의 구성이 조금 다릅니다.
Thumb의 VNRecognizedPointGroupKey :
handLandmarkRegionKeyThum
Thumb의 VNRecognizedPointKey
handLandmarkKeyThumbTIP(Tip of the thump) // 끝에서 부터handLandmarkKeyThumbIP(Interphalangeal joint)handLandmarkKeyThumbMP(Metacarpophalangeal joint)handLandmarkKeyThumbCMC(Carpometacarpal joint)
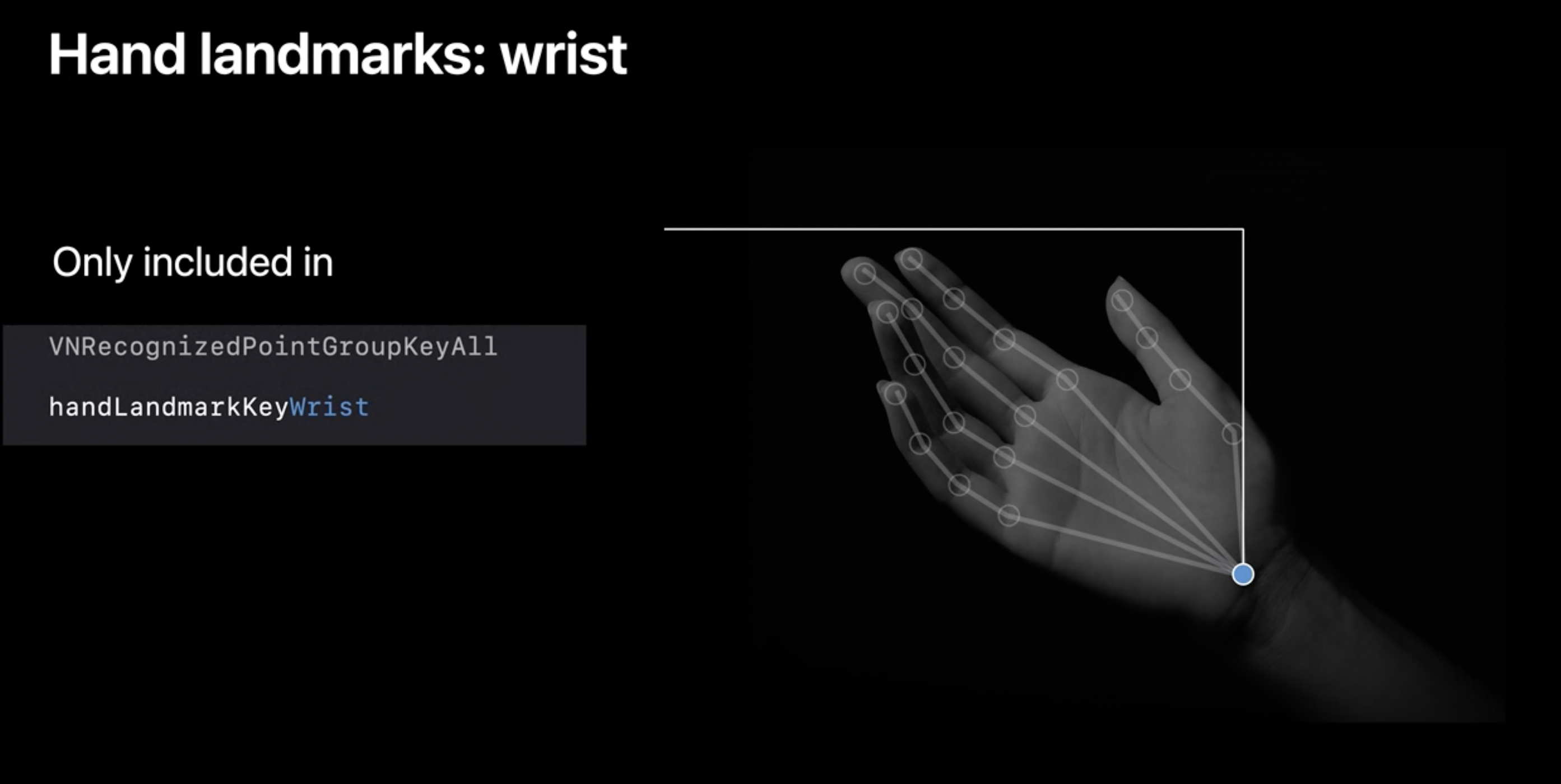
마지막으로 손목입니다.
Wrist landmark 는 손목의 중앙에 위치하며 전체 그룹에만 속합니다.
이제 observation으로 부터 위의 landmark들에 접근하는 방법입니다.
observation으로 부터 landmark에 접근하는 방법
먼저 observation에 .recognizedPoints(forGroupKey: 를 호출하여 랜드마크의 dictionary를 요청합니다.
[VNHumanHandPoseObservation.JointName : VNRecognizedPoint]모든 포인트를 원하는 경우
let allPoints = handPoseObservation.recognizedPoints(forGroupKey: VNRecognizedPointGroupKeyAll)
// 손에 있는 landmark 전부검지손가락의 포인트만 원할 경우
let indexFingerPoints = handPoseObservation.recognizedPoints(forGroupKey: VNRecognizedPointGroupKey.handLandmarkRegionKeyIndexFinger)
// 검지손가락에 있는 landmark 전부검지 손가락의 특정 부분의 포인트만 원할 경우
let indexTipPoint = indexFingerPoints[VNRecognizedPointKey.handLandmarkKeyIndexTip]
// 검지 손가락의 끝 부분Vision의 Hand Pose에서 알아야 할 몇 가지 추가 사항
- request에서 maximumHandCount를 조정하여 포착하는 손의 개수를 조절해야 합니다. (기본값은 2)
handPoseRequest.maximumHandCount = 1- Vision에서 hand poes를 사용하는 동안 VNTrackObjectRequest를 활용할 수 있습니다.
VNTrackObjectRequest : An image analysis request that tracks the movement of a previously identified object across multiple images or video frames. (식별된 객체의 이동을 추적하는 이미지 분석 요청)
-
VNTrackObjectRequest을 활용하는 이유 두 가지
-
손의 위치를 추적하고 자세를 신경 쓰지 않는다면, 손을 찾은 다음 VNTrackObjectRequest를 사용하여 손이 움직이는 위치를 알 수 있다. (손의 위치만 필요하면 효율 적이라는 뜻)
-
어느쪽 손인지 추적하기 더 좋음
-
- Vision을 사용할 때 정확성을 위해 고려해야할 주의사항
-
화면 가장자리 근처의 손은 부분적으로 가려져서 제대로 작동하지 않는다. (Near edges of the screen)
-
손이 카메라의 시야 방향과 평행하면 제대로 작동안한다.
-
장갑으로 덮인 손은 인식이잘안된다.
-
발을 손으로 감지할 때도 있다.
Body Pose

WWDC2020에 Hand Pose와 같이 공개된 여러 사람의 신체포즈를 한 번에 분석할 수 있는 기능입니다.
Vision Framework의 Body Pose를 사용하는 방법

Vision의 Hand Pose를 사용하는 방법과 동일합니다.
Request handler를 만들고 VNDetectHumanBodyPoseRequest를 만든 다음 request handler를 사용하여 요청을 수행 (hand 대신 body를 사용)
observation에서 랜드마크 포인트를 엑세스하는 패턴도 hand pose와 같습니다.
let allPoints = bodyPoseObservarion.recognizedPoints(forGroupKey: VNRecognizedPointGroupKeyAll)
// 모든 랜드마크 포인트
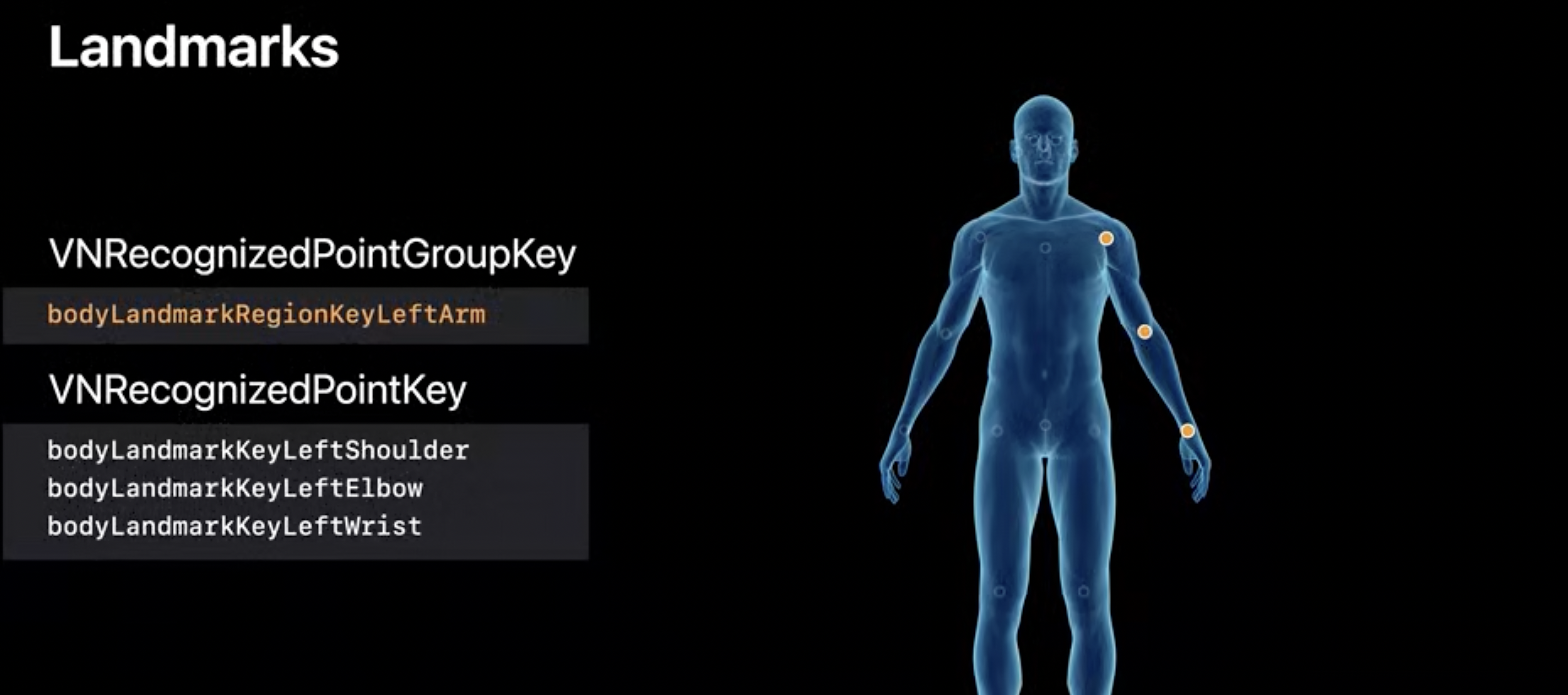
let leftArmPoints = bodyPoseObservarion.recognizedPoints(forGroupKey: VNRecognizedPointGroupKey.bodyLandmarkRegionKeyLeftArm)
// 특정 그룹의 랜드마크 포인트
let leftWristPoint = leftArmPoints[VNRecognizedPointKey.bodyLandmarkKeyLeftWrist]
// 특정 그룹안에 특정 부분 랜드마크 포인트Body landmarks
-
Landmarks: Face
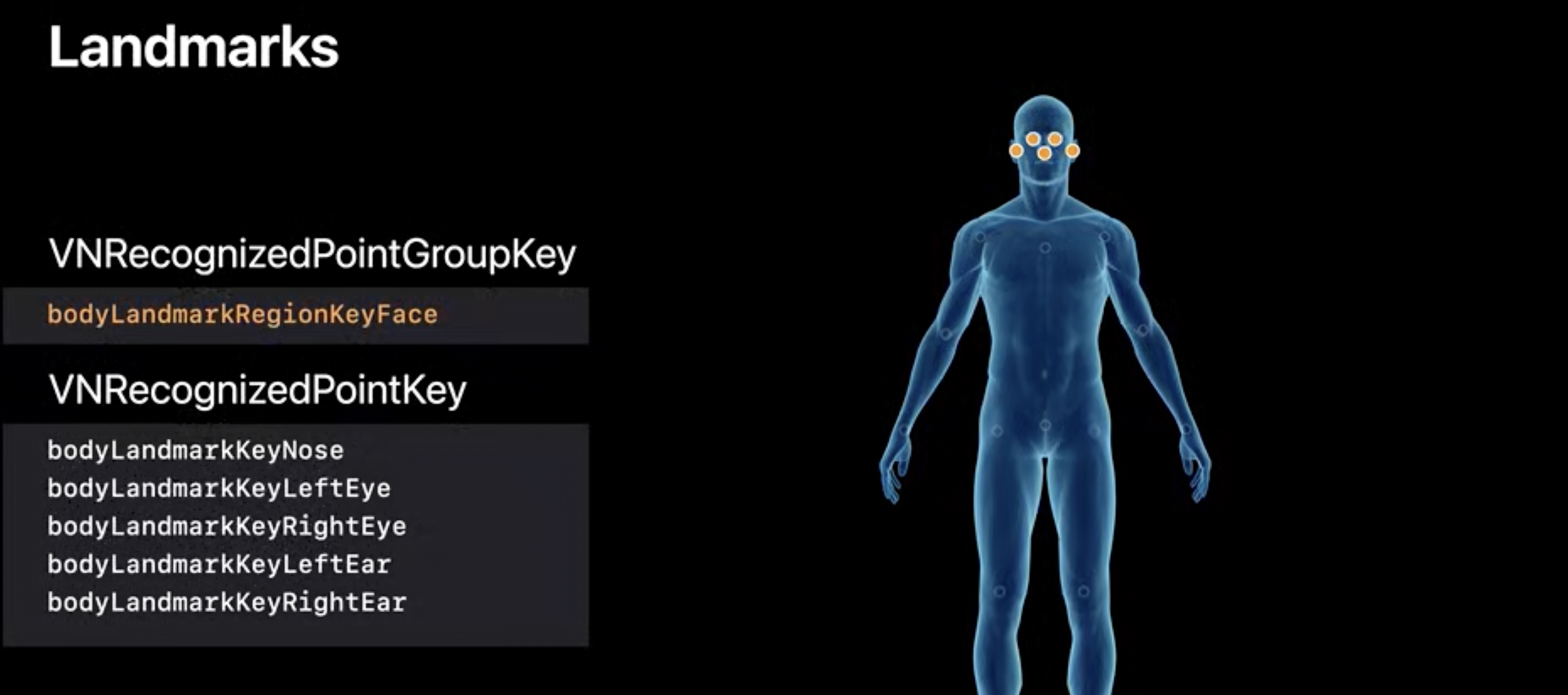
-
Landmarks: LeftArm
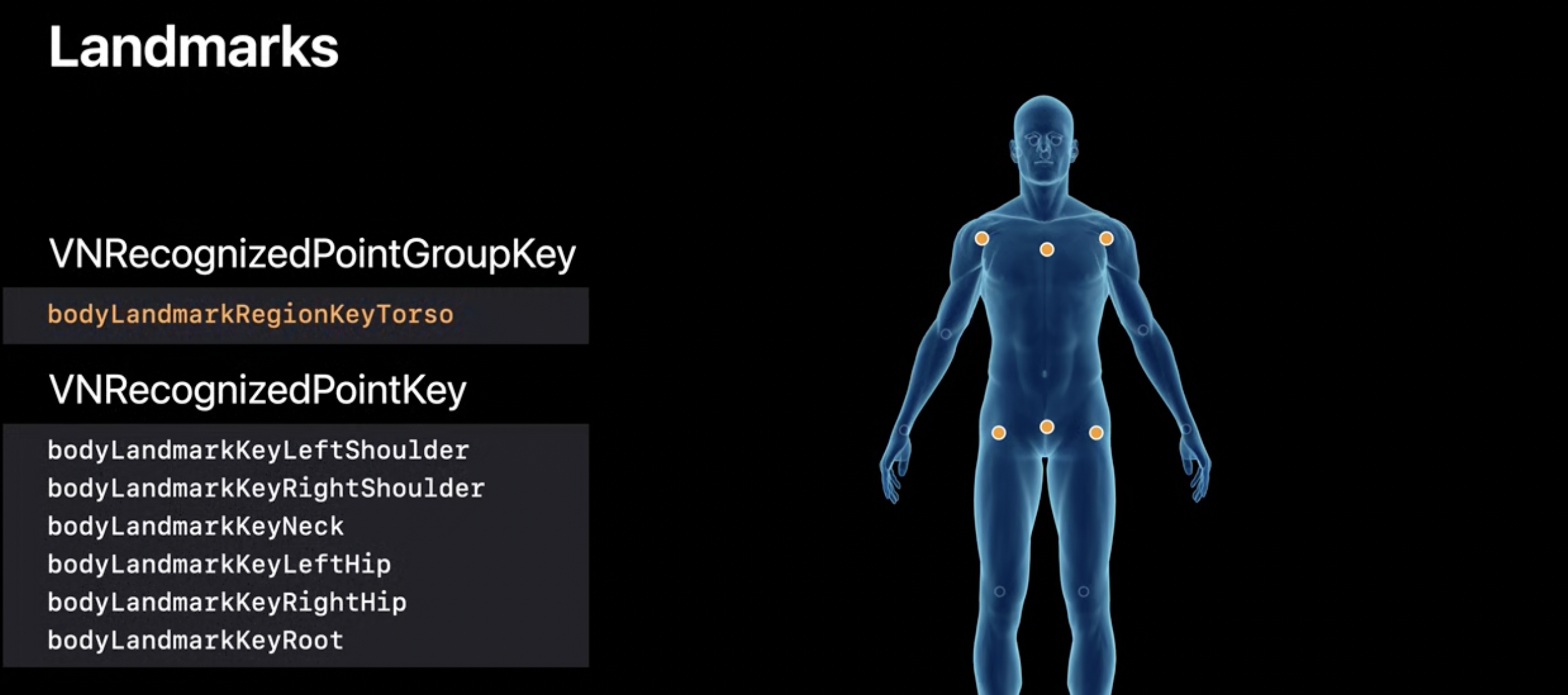
Landmarks: Torso
Landmarks: RightLeg
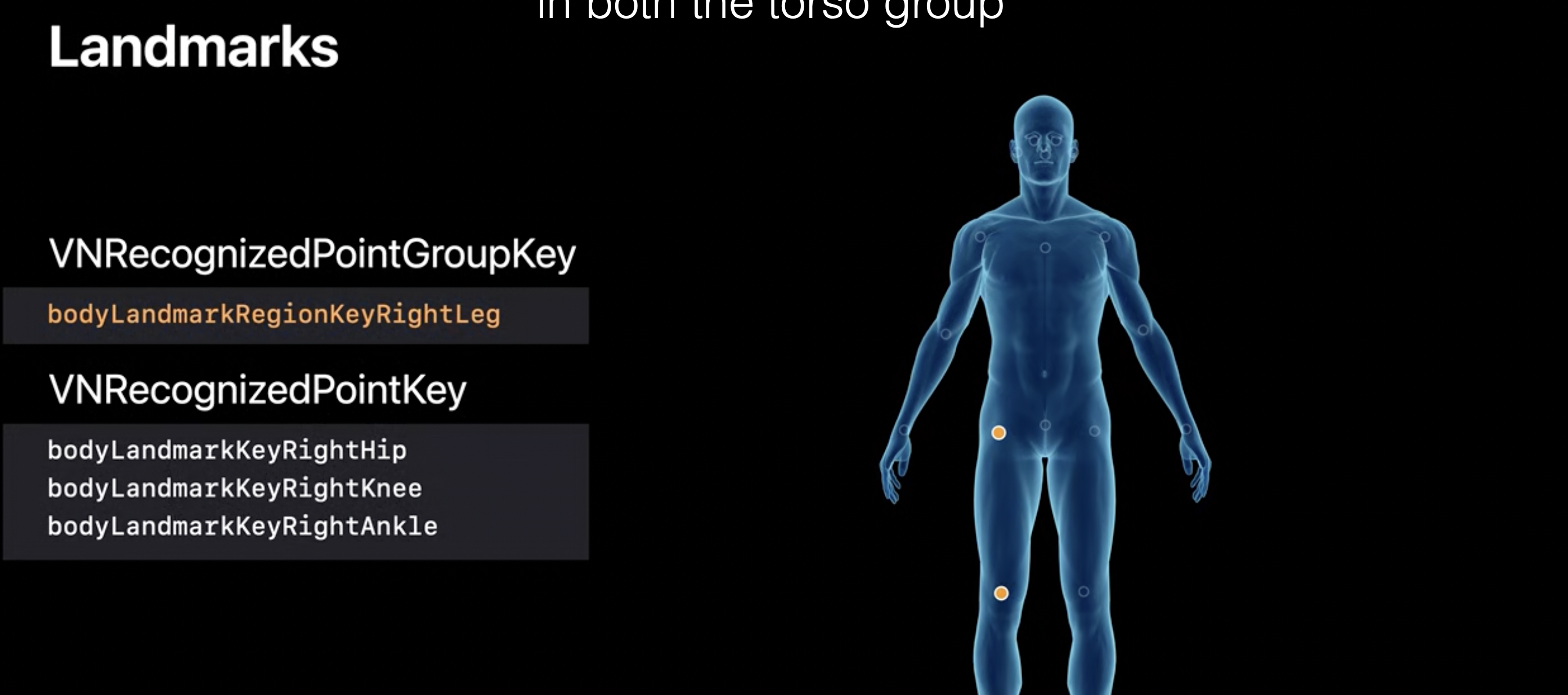
각 그룹마다 겹치는 포인트가 있습니다.
ex) 몸통이랑 팔에 어깨가 겹친다.
Vision vs ARKit
ARKit에서도 Body Pose분석을 제공합니다.
다음은 Vision과 ARkit에서 제공하는 Body Pose의 차이점 입니다.

-
둘다 동일한 랜드마크를 제공하지만 Vision은 신뢰 값(confidencd value)을 제공한다.
-
ARKit은 라이브 모션 캡쳐 앱을 위해 설계됨, 후면 카메라, ARSession을 지원하는 장치에서만
-
Vision의 body pose는 오프라인(이미지를 얘기하는 것 같음), 실시간 분석을 목적으로 합니다.
이상 WWDC2020 Detect Body and Hand Pose with Vision 세션 요약끝입니다!!
실제 코드로 Vision구현하기는 다음 포스트입니다.
영상 링크
