1. Dlib 얼굴 인식의 문제점
Face detection, 얼마나 작고 빨라질 수 있을까?
Dlib 라이브러리를 이용해 Face Landmark를 찾아내서 이미지 속의 얼굴을 빠르고 정확히 인식하는 방법을 고안해 봤었지만 그것만으로는 충분치 않았었죠.
Dlib 라이브러리를 이용했을 때는 얼굴을 잘 못 찾는다든지, 각도를 달리하거나 하는 등 의 변화에 취약했다는는 단점이 있었죠.
왜 작아지고 빨라지는 게 중요할까요?
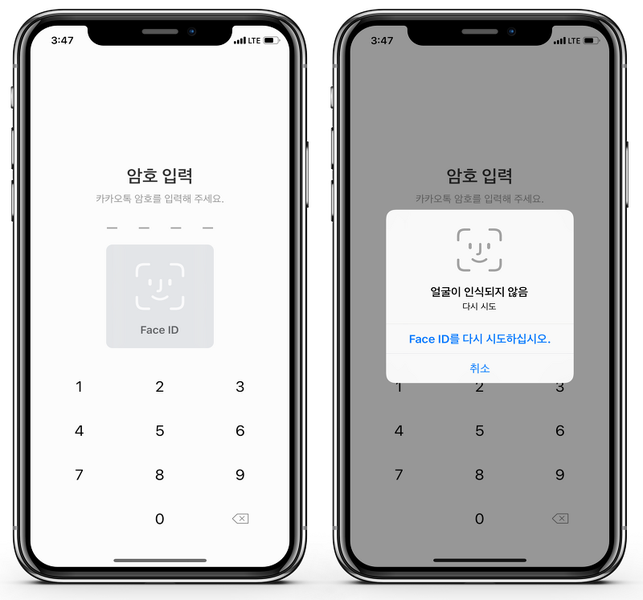
우선 비대면 인증수단으로 얼굴인식이 보편적으로 사용되기 시작했다는 점을 들 수 있습니다. 얼굴 인식을 위해 딥러닝 서버 구동이 필요한 모델을 활용할 수 있을까요?
서버로 이미지를 보낸 후 처리하는 방식은 네트워크 비용 + 서버 비용 + 인터넷 속도의 영향을 고려하지 않을 수 없습니다. 따라서 네트워크 상황과 무관하게 항상 동작해야 하는 핸드폰 인증 수단으로는 적합하지 않습니다. 그렇다면 edge device(=핸드폰)를 바로 이용하려면 어떻게 해야 할까요?
핸드폰 모델을 올리려면 weight가 작은 모델이 관리에 유리합니다. 하지만 일반적으로 작은 모델은 성능이 떨어지기 때문에 어떻게 보완할 수 있을지 고민이 시작됩니다.
국내 IT 대기업들도 관련 연구를 활발히 진행하고 있습니다.
어떻게 빠르게 만들 수 있을까?
Face detection에서 많은 시간이 드는 요소는 Sliding window입니다. 그러므로 Sliding window를 버려야 빨라집니다. 따라서 2-stage 방식의 detection은 좋은 선택이 아닙니다.
또 연산의 병렬화가 가능해야 합니다. 컴퓨터의 GPU에서는 병렬화가 가능하지만 핸드폰에서도 병렬화가 가능할까요?
크게는 안드로이드와 아이폰의 경우로 나누어 생각해 볼 수 있습니다. 안드로이드에서는 MLKit, 아이폰에서는 CoreML이라는 라이브러리를 통해 병렬화를 할 수 있습니다. 하지만 제한이 많기 때문에 TFLite라는 도구를 이용하여 훈련된 모델을 이용하기도 합니다.
위 방법으로도 해결이 안 된다면 어렵더라도 다른 방법을 생각해봐야 합니다. 우선 직접 병렬프로그래밍 라이브러리를 만들어 볼 수 있겠네요~! 하지만 그 난이도는 어마어마하겠죠? 비교적 쉬운 방법으로는 병렬화 도구를 사용하는 방법이 있습니다. 하지만 무엇보다도 적은 파라미터 수로도 정확한 성능을 가지는 모델을 설계하는 게 중요하겠죠?
2. Single Stage Object Detection
2-Stage Detector은 정확도는 높지만 실행속도(FPS)가 느리다는 단점이 있었죠?
다시 정리하자면, 2-Stage Detector는 물체가 존재하는 bounding box를 먼저 찾은 후에 bounding box를 분류하는 두 가지 과정을 순차적으로 거쳤기 때문에, 속도가 느렸습니다.
하지만 이전 스텝에서 살펴본 것처럼, 얼굴 인식과 같이 딥러닝 모델이 가벼워야 하는 task는 1-Stage 기반을 사용하는 것이 유리합니다. 1-Stage Detector는 localization과 classification을 동시에 수행합니다. 따라서 2단계를 거치는 2-Stage Detector보다는 속도가 빠릅니다. 하지만 정확도가 낮다는 단점도 있습니다.
아래의 그림에서 2-Stage Detector와 1-Stage Detector에 해당하는 모델이 어떤 것이 있는지 볼 수 있습니다.
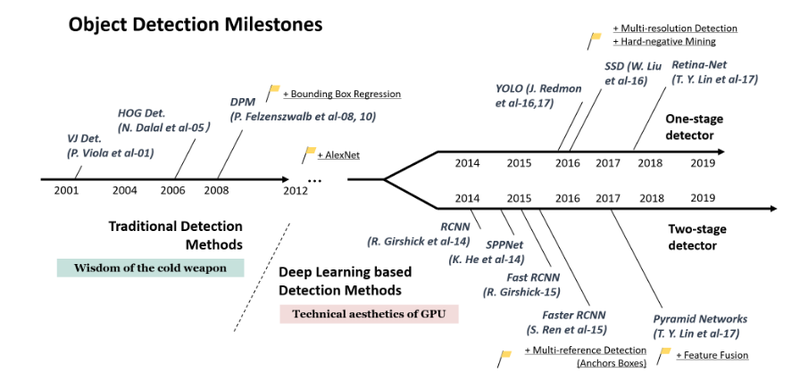
혹시 이전에 공부했던 Object Detection과 관련해서 복습이 필요하다면 아래 참고자료를 활용해 주세요.
이후 스텝에서 우리는 1-stage(Single stage) Object detection 모델을 위주로 하여 Face detection에 적합한 딥러닝 모델들에 대해 탐색해 보겠습니다. YOLO, SSD, RetinaNet 등 이 분야의 모델들의 발전사는 딥러닝 분야에서도 매우 흥미진진한 이력을 가지고 있으니, 함께 살펴봅시다.
3. YOLOv1
3.1. YOLOv1의 등장
YOLO : You Only Look Once
YOLO라는 모델의 네이밍 센스는 과연 어디서 왔을까요? YOLO라는 유명한 모델을 언급하려면 절대 빼놓을 수 없는 사람이 있습니다. 바로 Joseph Redmon, 즉 YOLO 논문의 1 저자이자 C로 구현된 오픈소스 뉴럴 네트워크 Darknet의 제작자입니다.
YOLOv1, big wave의 시작
YOLO의 출현은 당시 전 세계 computer vision 학계와 업계에 충격적일 정도의 기술 진보를 보여줬습니다. 우선 "You Only Look Once:Unified, Real-Time Object Detection"이라는 제목의 영상을 소개하겠습니다.
CVPR 2016...!
무려 2016년도에 CVPR oral session에서 실시간 데모를 해버립니다. 지금은 자연스러워 보일 수도 있지만, 당시 기술 수준을 생각하면 충격과 공포 그 자체였거든요.
"아니 detection이 실시간으로 돌아간다고?? 초대형 서버도 아니고 학회장에서??"
실제로 YOLO를 실행했을 때의 결과는 아래의 그림과 같습니다. 아래 줄 두 번째에 있는 사람을 비행기로 인식한 것 외에는 꽤 잘 detection하는 것 같죠?

"You Only Look Once:Unified, Real-Time Object Detection"는 CVF 채널에서 유튜브 조회 수 1위 동영상입니다. 참고로 2위는 2 stage detector 기반인 Mask-R-NN이에요. Detection이 사람들이 얼마나 관심이 많은지 알 수 있는 대목입니다.
3.2. YOLOv1의 원리
이제부터 YOLO v1의 원리에 대해 알아보죠. YOLO를 설명한 논문은 You Only Look Once:Unified, Real-Time Object Detection입니다. 이전 스텝에서 영상을 보았지만 논문을 통해 YOLO v1의 자세한 원리를 알아보는 것도 좋을 것입니다.
YOLO의 특징
YOLO의 특징은 논문 제목에 잘 드러나 있습니다. 주요 특징은 다음과 같습니다.
-
YOu Only Look Once
전체 이미지를 보는 횟수가 1회라는 걸 의미합니다. YOLO 클래스에 대한 정보와 주변 정보까지 한번에 학습하고 처리합니다. 따라서 배경 오류가 적고 일반화 성능이 좋습니다. -
Unified
Localization과 Classification을 동시에 수행합니다. YOLO는 이미지를 신경망에 넣어주기만 하면 바로 detection이 가능합니다. -
Real-Time
기본적인 YOLO 모델로는 45FPS(초당 프레임수), 빠른 버전은 150FPS까지의 성능을 보입니다.(참고로 Fast R-CNN은 0.5FPS, DPM은 30FPS 정도의 성능입니다.) 따라서 스트리밍 비디오에서도 실시간으로 객체를 detection할 수 있습니다.
그 외에도 Object detection을 회귀 문제로 관점을 전환했고, 여러 도메인에서 object detection이 가능하다는 특징이 있습니다.
RCNN과 YOLO
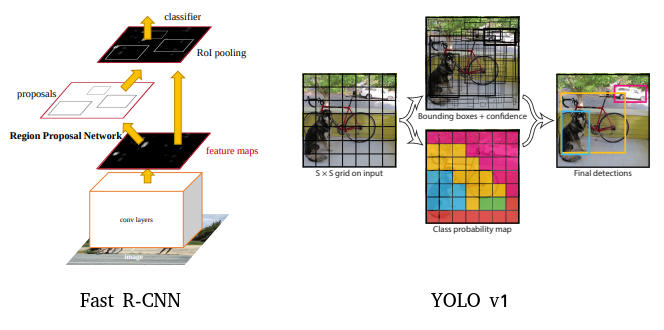
대표적인 2-stage detector인 RCNN과 1-stage detector인 YOLO 모델은 아래와 같이 기본 가정이 차이 납니다.
-
RCNN 계열의 가정 :
"객체가 존재할 것 같은 곳을 backbone network로 표현할 수 있다." → Region Proposal Network(RPN) -
YOLOv1의 가정 :
"이미지 내의 작은 영역을 나누면 그곳에 객체가 있을 수 있다." → grid 내에 객체가 존재한다.
따라서 YOLO v1에서 grid는 고정되고, 각 grid 안에 객체가 있을 확률이 중요하게 됩니다.
YOLO의 grid cell
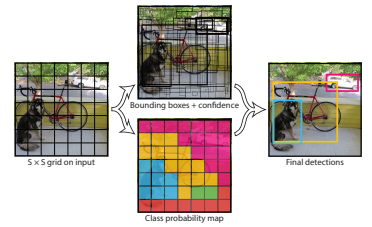
YOLO는 이미지를 SxS grid로 나누고, box regression 단계와 각 클래스마다 probability map을 구하는 단계가 동시에 병렬적으로 수행됩니다.
논문에서는 입력 이미지를 7x7 grid로 나누고, 각 grid cell마다 예측하는 bounding box(bbox)를 2개, 총 클래스의 수는 20으로 정했습니다.
각 grid cell은 bounding box와 C개의 class 확률을 예측합니다.
각 bounding Box(bbox, B)는 x, y, w, h, confidence score를 예측합니다. x,y는 bbox의 중심 좌표이고 w, h는 너비와 높이입니다. 주의할 점은 w, h는 입력 이미지를 bbox의 너비와 높이를 나눠서 normalize한 값으로, 0과 1 사이의 값을 가집니다.
confidence score는 box가 객체를 포함하고 있는지를 모델이 얼마나 자신 있는지, 그리고 박스가 예측하는 것이 얼마나 정확한지를 보여줍니다. 이를 식으로 나타내면 아래와 같습니다.
만약 grid cell이 객체를 포함하지 않으면 P(Object)가 0이므로 confidence score는 0입니다. grid cell이 객체를 정확히 포함하고 있다면 P(Object)는 1이므로 결국 IoU만 남습니다. 따라서 confidence score가 예측된 box와 ground truth box 사이의 IoU와 같도록 하는 것이 좋겠죠?
C개의 조건부 클래스 확률 는 grid cell이 사물을 포함할 때 bbox 안의 객체가 i번째 클래스에 속할 확률입니다. bounding box의 개수와 상관없이 각 grid cell의 확률만 예측합니다.
위의 내용을 정리하면 하나의 grid cell에 대해 아래와 같은 tensor가 나옵니다.

위의 이미지에서 보면 자전거를 포함하는 grid가 많습니다. 이런 경우는 해당 grid의 bbox가 모두 자전거라고 예측할까요? 학습이 잘된 경우는 해당 grid들이 모두 비슷한 크기로 자전거의 bbox를 잡습니다. 여기서 동일한 객체를 잡는 bbox가 많아진다는 문제가 생깁니다.
이때는 NMS(Non-Maximum Suppression) 와 같은 기법을 이용합니다. 비-최대 억제라고도 불리는 NMS 기법은 object detector가 예측한 여러 개의 bounding box 중 정확한 bounding box만을 선택하는 기법입니다.
NMS의 알고리즘은 아래와 같습니다.
-
하나의 클래스에 대한 높은 confidence score 순서대로 bbox를 정렬합니다. confidence score가 특정 threshold를 넘지 않는 것은 제거합니다.
-
가장 높은 Confidence Score의 bbox와 겹치는 다른 bbox를 비교하여 IoU가 threshold보다 높으면 겹치는 bbox를 목록에서 제거합니다. 두 bbox의 IoU가 높다는 것은 같은 객체를 detect하고 있다는 의미이기 때문입니다.
-
1과 2의 과정을 반복해 마지막으로 남은 bbox를 반환합니다.
-
각 클래스에 대해 위의 과정을 반복합니다.
NMS 알고리즘을 적용하면 아래 그림과 같이 겹쳐 있는 bounding box 중 정확한 bounding box 하나만 표시됩니다.

YOLO의 목표는 grid에 포함되는 객체를 잘 잡아내는 것입니다. 즉 grid cell에 속하는 객체를 검출할 책임이 있는 거죠. 따라서 1개 grid에 귀속된 bbox 정보 (x, y, w, h)의 학습 목표는 bbox의 ground truth와 최대한 동일하도록 학습되는 것입니다. 학습 목표가 제대로 이루어졌는지를 확인하려면 객체 인식 모델의 성능 평가 도구인 IoU(Intersection over Union)를 사용하면 되겠죠?
YOLO의 네트워크 구조
YOLO 네트워크 구조는 아래 그림과 같이 24개의 Conv 레이어와 2개의 Fully connected 레이어로 이루어져 있습니다.
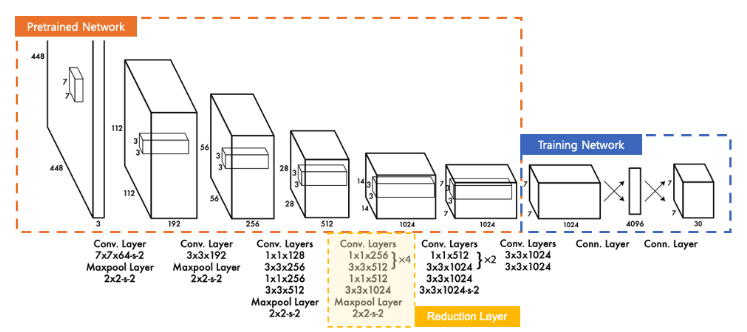
모델 구조의 앞부분(Pretrained)은 ImageNet의 1000개 클래스 데이터셋을 가지고 사전학습한 GoogleNet 모델입니다. 사전학습을 위해 20개의 Conv 레이어와 average pooling 레이어와 fully-connected 레이어를 사용했습니다. 그러나GoogleNet의 Inception 모듈 대신 1x1 reduction 레이어를 사용해 연산량을 감소시켰습니다.
detection을 위해 사전학습된 모델에 4개의 Conv 레이어와 2개의 FC 레이어를 추가했고, PASCAL VOC 데이터셋으로 fine-tuning을 했습니다. fine-grained 이미지를 얻기 위해 원래의 224x224 이미지의 2배인 448x448의 이미지를 사용했다고 합니다.
마지막 레이어는 Class 확률과 bbox 좌표를 학습하고 예측하여 SxSx(B * 5 + C) 크기의 텐서로 예측값이 출력됩니다.
YOLO의 Inference 과정
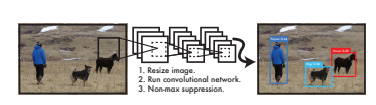
Inference를 할 때는 조건부 클래스 확률 를 각 box의 confidence 예측값과 곱해 각 box의 클래스별 confidence score(class-spercific confidence score)를 얻을 수 있습니다. 각 score는 box의 클래스의 확률과 예측된 box가 사물을 얼마나 잘 예측하는지를 보여줍니다.
이 과정을 모든 bbox에서 시행하면 한 이미지에서 예측한 클래스별 confidence score의 개수는 7 7 2 = 98개입니다. 이 98개의 클래스별 confidence score에 대해 20개의 class를 기준으로 NMS를 하여 object에 대한 class와 bounding box location을 결정할 수 있습니다.
3.3 YOLOv1의 성능
YOLOv1의 loss 함수
YOLO의 loss는 bbox의 위치 예측과 관련된 localization loss와 클래스 예측과 관련된 classification loss가 있으며, 두 loss 모두 SSE(sum-squared error)를 기반으로 합니다. 그런데 SSE는 이 두 loss에 동일하게 가중치를 줍니다. 이런 상황은 이상적인 상황이 아니죠? 뿐만 아니라 이미지 내 대부분의 grid cell에 객체가 없을 경우가 일반적인데, 이런 경우에는 confidence score가 0에 가깝게 됩니다. 이는 모델의 불균형을 초래합니다.
이런 문제를 해결하기 위해 bbox의 좌표에 대한 loss를 증가시키고, 객체가 없는 box의 confidence 예측값의 loss는 감소시켰습니다. 이를 위해 와 라는 두 개의 하이퍼파라미터를 사용했습니다.
뿐만 아니라 SSE는 큰 bbox와 작은 bbox의 loss를 모두 동일한 가중치로 계산합니다. 그러나 작은 bbox가 큰 bbox보다 조그마한 위치 변화에도 더 민감하죠. 이를 개선하기 위해 bbox의 너비와 높이에 square root를 취해주었습니다.
YOLO의 loss 함수는 아래와 같습니다.
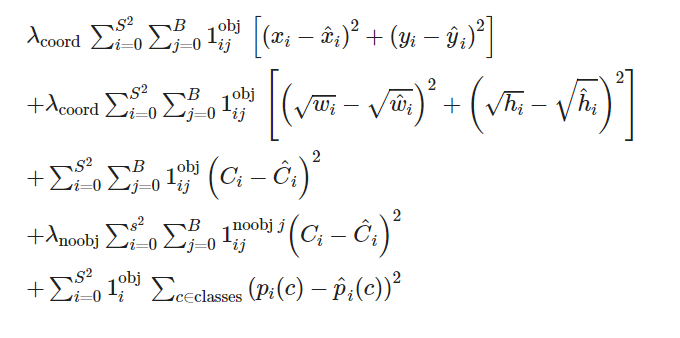
-
는 grid cell i 안에 객체가 있는지 여부를 나타냅니다. 객체가 grid cell 안에 존재하면 1, 없으면 0을 출력합니다.
-
는 객체가 존재하는 grid cell i의 j번째 bbox predictor이고, i번째 cell에 객체가 있고, j번째 predictor의 값이 다른 predictor보다 높으면 1, 그렇지 않으면 0으로 출력합니다.
-
는 객체가 존재하지 않는 grid cell의 j번째 bbox predictior를 의미합니다.
loss 함수를 하나씩 살펴보면 아래와 같습니다.
-
첫번째 항 ~ 세번째 항 : 객체가 존재하는 grid cell i의 bbox predictor j에 대해
1. 첫번째 항: x와 y의 loss 계산 2. 두번째 항: 너비와 높이의 loss 계산(제곱근을 취한 SSE) 3. 세번째 항: confidence score의 loss 계산 -
네번째 항 : 객체가 존재하지 않는 grid cell i의 bbox predictor j에 대해 confidence score의 loss 계산(객체가 없을 때의 패널티)
-
다섯번째 항: 객체가 존재하는 grid cell i에 대해 조건부 클래스 확률의 loss 계산
YOLO의 성능
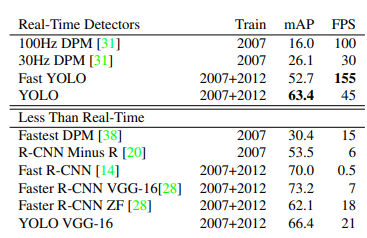
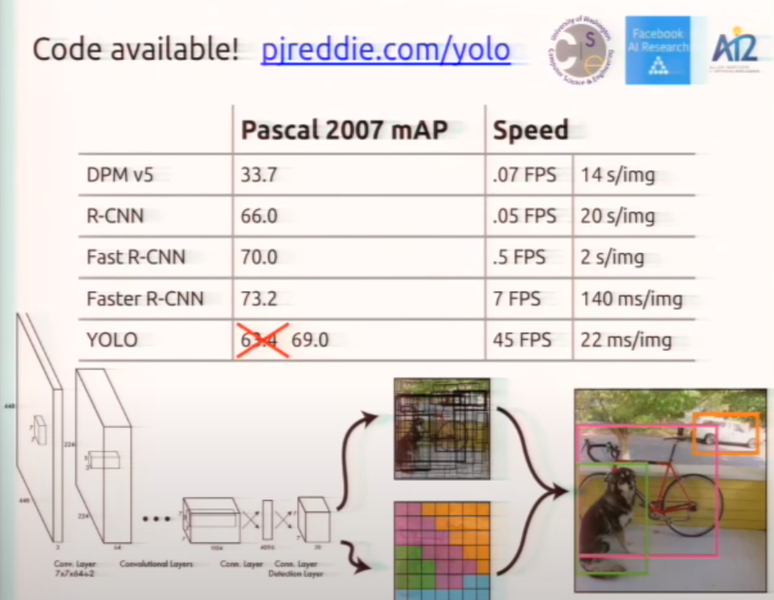
arXiv 논문 발표에서는 mAP가 63.4였지만 CVPR 2016 발표때는 69.0으로 모델의 성능을 향상되어 발표되었습니다. 즉 YOLO v1은 Faster R-CNN과 성능에 큰 차이가 나지 않으면서 속도는 6배 이상인 혁신적인 연구였습니다.
YOLOv1의 단점
획기적이었던 YOLOv1에도 단점이 있었습니다. 우선 각각 grid cell이 2개의 box와 하나의 클래스만 예측 가능하므로 가까이에 있는 여러 개의 객체를 예측하기 어려웠습니다. 특히 새떼와 같이 그룹으로 나타나는 작은 object에 대해 예측을 제대로 하지 못했습니다.
또한 bbox 형태가 training data를 통해 학습되었기 때문에 bbox 분산이 너무 넓어 새로운 형태의 bbox 예측이 잘 안되기도 했습니다. 모델 구조상 backbone만 거친 feature map을 대상으로 bbox 정보를 예측하기 때문에 localization이 다소 부정확했습니다.
마지막으로 loss 함수가 작은 bbox와 큰 bbox의 loss를 같게 다루기 때문에 큰 box의 작은 loss보다 작은 box의 작은 loss가 IoU에 더 큰 영향을 미쳤습니다. 그래서 2017년 YOLOv2가 나오게 됩니다.
4. YOLOv2

Object Detection에 혁신을 가져온 Redmon은 1년 뒤인 CVPR 2017에 YOLO를 v2로 발전시켜 가지고 나옵니다. 위의 이미지는 실제 발표 자료에 포함된 것이었습니다. Joseph Redmon의 발표자료에서 intro에서 YOLO 자체로 좋긴 좋았는데 정확도가 아쉬웠다고 언급합니다.
CVPR 2016에서 데모 중에 Redmon이 잠깐 사라진 적이 있는데, YOLO가 뒷문을 화장실로 인식해버리는 사고였어요. Redmon은 CVPR 2017에서 이때 장면을 캡쳐해서 가지고 나왔습니다. 즉 YOLO의 정확도가 낮다는 것을 보여준 예였죠.

YOLOv2의 목적

YOLO의 목적은 아래와 같습니다.
- Make it better
- Do it faster
- Makes us stronger
간단히 요약하자면 recall을 올리고 localization을 잘 해보자! 입니다.
1)Make it better
Better는 정확도를 올리기 위한 방법입니다. YOLOv2에서는 이전 모델에서 낮은 성능으로 보였던 localization과 recall을 높이면서도 여전히 모델을 단순하게 만들고 속도도 빠르게 하려고 하였습니다.
이를 위해 Batch Normalization, High Resolution Classifier, Convolutional with Anchor boxes, Dimension Clusters, Direct Location prediction, Fine-Grained Features, Multi-Scale Training 등의 방법을 사용했습니다. 각 방법을 사용했을 때의 결과는아래의 표로 정리되어 있습니다.

정확도를 높이기 위해 사용했던 각각의 방법을 간단히 정리하면 아래와 같습니다.
Batch Normalization
모든 conv 레이어에 batch normalizaion을 사용하였고, dropout은 제거하였습니다. 이로써 mAP에서 2% 이상의 성능 개선을 하였습니다.
High Resolution Classifier
YOLO v1에서 ImageNet의 224 x 224 이미지를 학습하고, detection에서 448 x 448 이미지를 사용했던 것과 달리 YOLO v2에서는 처음부터 448 x 448의 해상도로 학습하였습니다. 이로써 mAP에서 4% 정도의 성능 개선을 이루었습니다.
Convolutional With Anchor Boxes
bounding box를 예측하기 위해 YOLO v1의 Fully connected 레이어를 제거한 후 Fully Convolutional Network를 사용하였고, anchor box들을 사용해 bounding box를 예측하였습니다.
또한 1개의 중앙점을 갖는 13 x 13(홀수 x 홀수)의 출력 feature map을 만들도록 입력 이미지의 크기를 448 x 448에서 416 x 416로 줄였습니다. 이는 대부분의 객체가 이미지의 중앙에 있는데, 중앙에 위치한 객체의 경우는 중앙점이 하나일 경우에 더 잘 예측할 것이라는 예상 때문이었습니다.
따라서 YOLO v2는 13 13 5개의 bounding box를 예측합니다.
그 결과 mAP는 69.5에서 69.2로 떨어지지만 recall은 81%에서 88%로 증가였습니다.
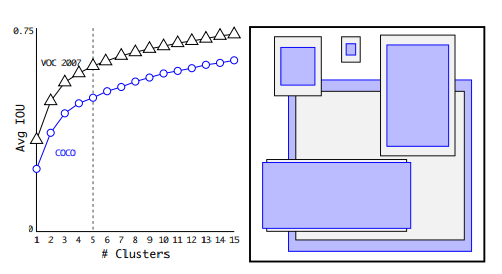
Dimension Cluster
Fast R-CNN에서는 anchor box의 크기와 비율을 사전에 정해주고, 학습을 통해 세부 조정을 했습니다. 그러나 YOLOv2는 k-means clustering을 적용해 최적의 anchor box를 결정했습니다.
하지만 유클리드 거리를 사용하는 일반적인 k-means clustering과 달리 IoU 개념을 distance metric으로 사용해 더 좋은 anchor box를 얻을 수 있었어요. 그 이유는 ground truth box와 유사한, 즉 IoU가 높은 anchor box를 찾기 위해서였습니다.
클러스터링 개수를 늘리면 정확도가 높아지지만 속도가 느려지므로 YOLOv2는 최종적으로 5개의 anchor box를 사용했습니다.
Direct location prediction
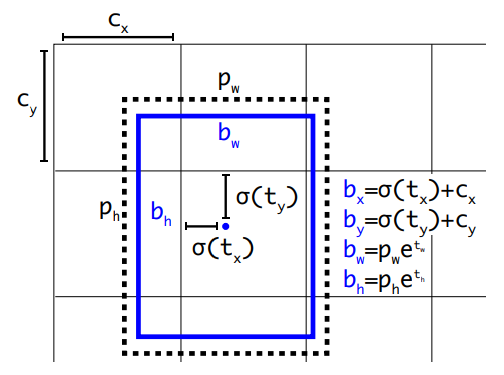
YOLOv2는 결정한 anchor box에 따라서 하나의 셀에서 5차원의 벡터로 이루어진 bounding box를 아래와 같은 방식으로 조정하여 예측했습니다. 학습 초반에 random initialization으로 인한 학습의 불안정을 예방하기 위해 bounding box가 grid cell을 벗어나지 않도록 제약을 둔거죠. 주의할 점은 YOLOv1이 grid cell의 중앙점을 예측했다면 YOLOv2는 좌상단으로부터 얼마나 이동했는지를 예측한다는 것입니다.
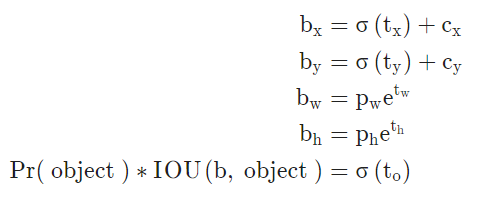
- , : 앵커 박스 사이즈
- , , , : 모델의 예측 offset 값
- , , , : 예측 bounding box의 좌표, 너비, 높이
Dimension Cluster와 Direct location prediction을 사용해 약 5%의 성능 향상을 얻어냈습니다.
Fine-Grained Features
13×13의 feature map은 작은 물체 검출을 잘 하지 못한다는 단점이 있었기 때문에 YOLO v2는 passingthrough 레이어라는 것을 사용했습니다. passingthrough 레이어는 이전 레이어의 26×26 feature map과 13×13의 feature map을 concatenate합니다. 이렇게 하는 이유는 26x26의 feature map에 Fine-Grained Features(고해상도 피처)가 담겨 있기 때문입니다.
그러나 두 feature map의 크기가 다르기 때문에 26 × 26 × 512 feature map을 13×13×2048 feature map으로 변환한 후 concatenate하였습니다.
이로써 약 1%의 성능 향상을 보였습니다.
Multi-Scale Training
모델이 다양한 입력 사이즈에도 예측을 잘 할 수 있도록 매 10개의 batch마다 입력 이미지의 크기를 바꿔가면서 모델 학습을 하였습니다. 모델이 32 간격으로 downsample 되므로 입력 이미지는 32의 배수가 될 수 있습니다. 그래서 입력 이미지의 크기는 {320, 352, ... 608} 중 하나가 사용됩니다.
2) Do it faster
faster는 detection 속도를 향상시키기 위한 방법이었습니다.
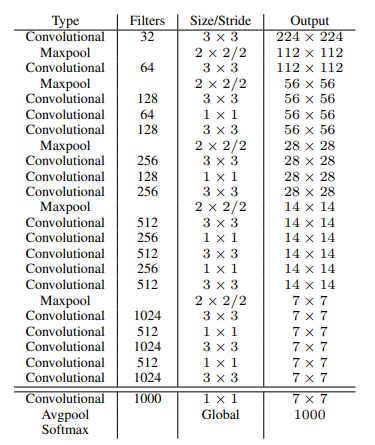
Darknet-19
YOLO v2에서는 Fully Connected 레이어를 제거하고 global average pooling을 하여 가중치 파라미터 수를 크게 줄였습니다. 이렇게 해서 만든 최종 모델은 Darknet-19이라고 불리는데, 19개의 convolutional 레이어와 5개의 maxpooling 레이어로 이루어져 있습니다.
DarkNet-19를 통과한 YOLO v2의 최종 출력은 13x13x125이에요. 위에서 feature map이 13x13이라고 하였고, 5개의 bounding box를 예측하기 때문에 5 * (5+20)이므로 13x13x125이 됩니다. 이전 스텝에서 하나의 bounding box가 x, y, w, h, confidence를 예측하고, 클래스의 개수가 20개라고 했던 것 기억하시죠?
3) Makes us stronger
stronger는 더 많은 범위의 class를 예측하기 위한 방법이었습니다. YOLO v1는 PASCAL VOC 데이터셋에서 제공되는 20개의 클래스를 기준으로 학습해서 20개의 클래스만 detection하였습니다. 그러나 YOLO v2에서는 9천개의 클래스에서 detection할 수 있도록 하고, 그 모델을 YOLO9000이라고 불렀습니다. 그래서인지 YOLO v2는 YOLO9000: Better, Faster, Stronger이라는 논문 이름으로 발표되었죠.
YOLO 9000은 YOLO v2와 모델 구조가 같고 detection하는 라벨을 늘렸기 때문에 자세히 설명하지는 않겠습니다. 간단히 설명하자면 9천개의 클래스에 대해 분류를 하기 위해 계층적으로 분류 작업(Hierachical Classification)을 수행하여 기존의 WordNet 기반의 데이터를 트리 구조인 WordTree를 생성하였습니다.
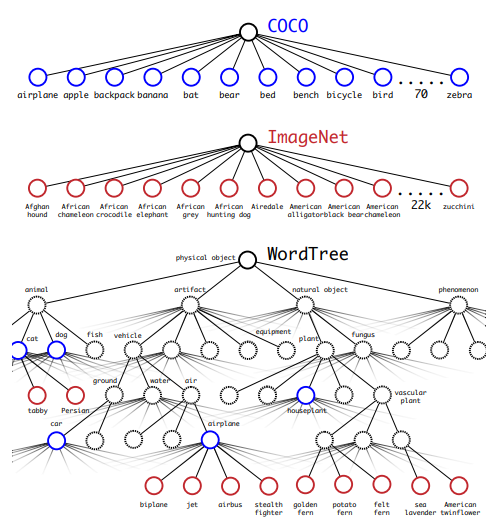
ImageNet + COCO 데이터셋 + ImageNet Detection을 합쳐 9천개의 클래스 라벨을 생성했습니다. 그 후 Detection과 Classification을 합쳐서 학습을 하는데, Detection 데이터셋과 Classification 데이터셋의 개수가 차이가 크기 때문에 oversampling하여 Detection과 Classification 비율을 4:1로 맞췄습니다. Detection 데이터셋은 classification과 bbox에 대한 loss를 역전파하였지만 Classification 데이터셋은 classfication loss만 역전파하여 학습하였습니다. 이로 인해 9천개의 클래스를 detection할 수 있었죠. 이에 대한 자세한 내용은 논문을 통해 알아보시기 바랍니다.
YOLOv2 의 성능비교
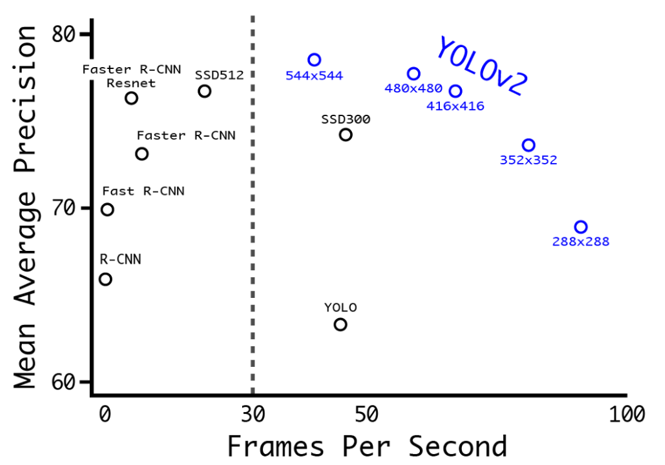
YOLOv2의 성능은 위의 그래프에서도 볼 수 있듯이 mAP가 상승하고 FPS도 개선되었다는 것을 알 수 있습니다. 그러나 여전히 mAP와 FPS간의 trade-off가 존재하였죠.
YOLOv2 발표 당시 SSD, R-FCN 등이 이미 발표된 상황이었습니다. 특히 SSD와 YOLO는 같은 single stage 방법을 지향하고 있었기 때문에 경쟁 모델이 되었고, YOLOv2 입장에서는 SSD와의 성능 차이를 부각시키는게 중요한 과제였습니다.
이후 YOLOv3가 등장하는데 이건 다음 시간에 계속~~
