5. YOLOv2 이후의 발전사
5.1. YOLOv3
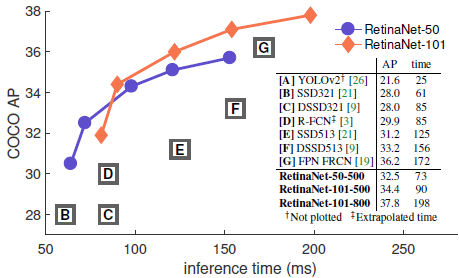
RetinaNet의 도발
아래의 RetinaNet figure를 보시면 YOLOv2를 언급하면서 보통 figure에는 그려주지도 않는 신선함을 보여줍니다. "YOLO 이제 퇴물아니야?" 란 느낌을 풍기면서 말이죠~~
실제로 retinanet 성응이 YOLOv2보다 좋기도 했습니다.
하지만 역시 CV의 힙스터 Redmon은 새로운 YOLO를 들고 RetinaNet과 정면 대결을 했습니다.
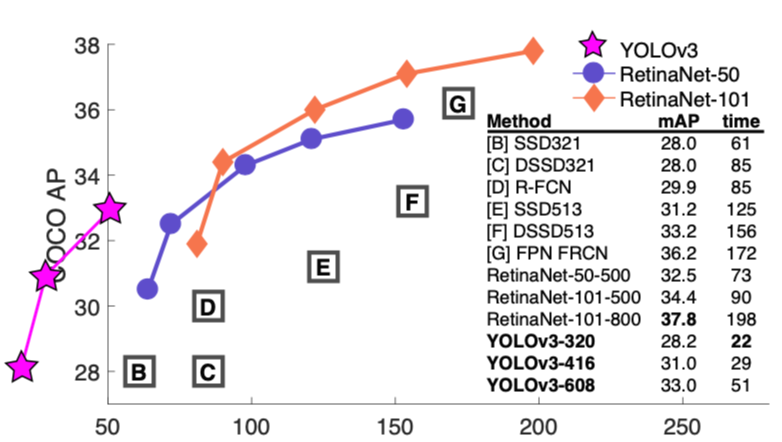
RetinaNet figure를 그대로 가지고 와서 YOLOv3 성능을 박어 넣었죠.
"graph 그릴 곳이 없어?? graph 바깥에 그리면 되잖아??"
해당 figure는 YOLO 프로젝트 페이지에도 그대로 사용됩니다.
YOLOv3 원리
YOLO v3는 YOLO v2보다는 속도는 조금 느리지만 정확도를 개선한 모델입니다. 특히 YOLO의 약점이었던 작은 물체를 detection할 때 성능을 개선하였죠.
YOLO v3는 YOLOv3: An Incremental Improvement라는 이름의 논문에 소개되었습니다. 그러나 엄밀히 말하면 논문이라기보다 Tech Report인데, 이전의 YOLO 모델과의 차이점을 간략하게 소개한 보고서입니다.
사실 YOLO v3는 YOLO v2에서 약간의 변화만 추가한 모델입니다. 따라서 YOLO v3의 원리는 YOLO v2와의 차이점을 중심으로 설명하겠습니다.
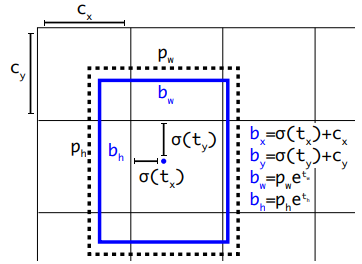
Bounding Box Prediction
Bounding Box Prediction은 YOLOv2와는 거의 차이가 없습니다. 그러나 각각의 bounding box마다 objectness score, 즉 bounding box에 물체가 있는지를 예측하는 점수를 logistic regression을 사용해 예측하였습니다. anchor box와 ground truth box의 IoU가 가장 높은 박스의 objectness score는 1로 두고 나머지는 무시하였습니다. 또한 Faster R-CNN 등의 다른 모델과 달리 각각의 ground truth에 대해 1개의 bounding box만 가지게 된다는 차이가 있었습니다.
Class prediction
YOLOv3는 하나의 이미지에 다양한 label을 붙일 수 있는 multilabel classification를 하였습니다. 예를 들어 여성의 이미지에 person과 woman이라는 두 가지의 label을 붙일 수 있는 것을 의미합니다. 이를 위해 여러 개 중 하나만 찾는 softmax classifier가 아닌 해당 label이 맞는지 아닌지를 판단하는 logistic classifier를 사용하였고, binary cross entropy를 사용해 loss를 계산하였습니다.
Predictions Across Scales
YOLO v3은 3개의 scale로 bouding box를 예측하였고, 각 scale당 3개의 bouding box를 예측하였습니다. 따라서 총 9개의 bouding box가 나오게 되며, 텐서는 N × N × {3 ∗ (4 + 1 + 80)}입니다. 여기서 3은 anchor box의 수이고, 4는 bounding box의 좌표, 너비, 높이이며, 1은 objectness score, 그리고 80의 클래스의 수입니다.
또한 feature map을 2배씩 upsampling함(13, 26, 52)으로써 더 의미 있는 semantic information을 얻고, 이전 feature map과 concatenate하여 보다 fine-grained한 정보를 얻을 수 있었다고 합니다.
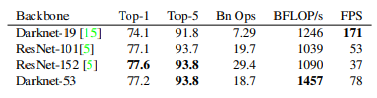
DarkNet-53
성능을 높이기 위해 YOLO v3은 53개의 레이어를 사용하였습니다. YOLO v2의 아키텍처였던 DarkNet-19에 residual network를 넣어 레이어를 53개까지 쌓을 수 있었습니다.
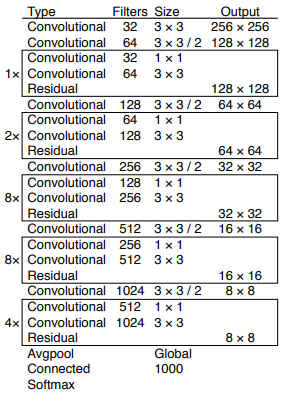
DarkNet-53은 DarkNet-19보다 정확도가 높았고, ResNet-101이나 ResNet152과 성능이 비슷하지만 연산면에서 효율적이었습니다.
전체 모델 구조는 아래의 이미지로 나타낼 수 있습니다. 입력 이미지를 DarkNet-53에 통과시켜서 downsampling하면서 feature map을 추출합니다. 이 feature map을 토대로 detection을 하고, upsampling 후 다시 detection하고 다시 upsampling을 한 후에 detection하게 됩니다. 즉 3개의 scale된 bounding box를 이용한 detection을 함으로써 여러 개의 label에 대해서도 classification을 할 수 있었습니다.
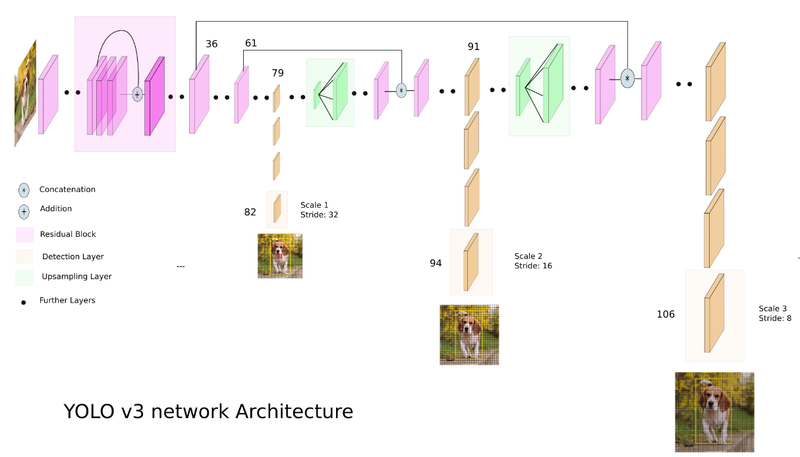
[YOLO v3의 구조]
https://towardsdatascience.com/yolo-v3-object-detection-53fb7d3bfe6b
5.2. YOLOv3 그 이후
Redmon은 Computer Vision 연구가 자신의 목적과는 다르게 군사적으로 사용되고 있는 것에 큰 회의감을 느끼고 CV 연구를 그만두겠다고 선언합니다. YOLO 등 DarkNet 프로젝트는 Alexey Bochkovskiy가 메인테이너로 이어 받게되죠. 그 이후에도 다양한 사람들에 의해 YOLO를 이용한 다양한 모델이 나왔습니다.
YOLOv4
Redmon이 빠진 후 Alexey Bochkovskiy가 2020년 4월에 YOLO v4를 발표하였습니다. 아래 그림과 같이 YOLO v3보다 AP와 FPS가 각각 10%, 12% 증가된 것을 볼 수 있죠.
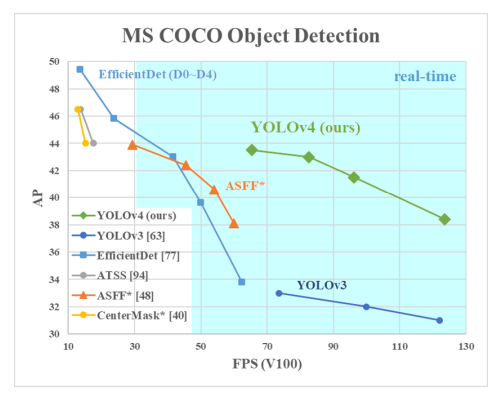
YOLOv4을 간단히 설명하자면 YOLOv3에 다양한 기법을 사용해 하나의 GPU(1080 Ti 또는 2080 Ti)로 object detection을 실시간으로 할 수 있도록 만든 모델입니다. 논문에서도 다양한 기법을 소개하고, 그 기법들을 실험한 결과를 정리하여 YOLO v4라는 모델을 만들어 냈습니다. 따라서 YOLOv4를 아래와 같이 나타낼 수 있습니다. 백본으로는 CSPDarknet53을 사용하였고, Neck(feature map 정제 및 재구성)으로는 SPP와 PAN, Head(object classification, localization)에서는 YOLOv3를 사용한 거죠.
YOLOv4 = YOLOv3+ CSPDarknet53 + SPP + PAN(Path Aggregation Network) + BoF(Bag of Freebies) + Bos(Bag of Specials)
각각의 자세한 내용은 논문을 참고해 보시기 바랍니다.
YOLOv5
YOLO v5는 2020년 6월에 YOLO v3을 PyTorch로 구현한 Glenn Jocher에 의해 발표되었습니다. 하지만 YOLO v5는 처음으로 논문과 함께 발표되지 않은 최초의 모델이자, DarkNet이 아닌 PyTorch로의 구현이므로 기존의 YOLO 모델과 많이 다르다는 이유로, YOLO v5라는 이름에 대해 논란이 있었던 모델입니다. YOLO v5의 코드는 Ultralytics LLC라는 회사의 GitHub에 공개되어 있습니다.
YOLO v4와 성능은 비슷하지만 용량이 훨씬 작고 속도도 빠릅니다.
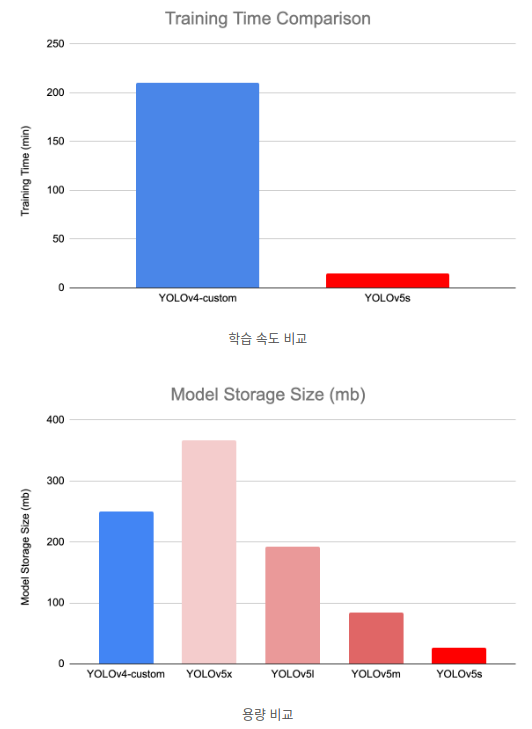
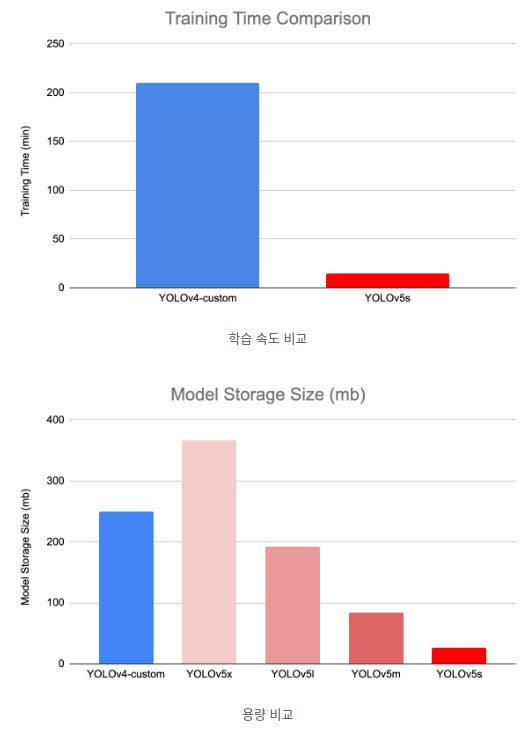
YOLOv5는 OLOv5s, YOLOv5m, YOLOv5l, YOLOv5x라는 이름의 4가지 버전이 있습니다. 각각 small, medium, large, xlarge로, 백본이나 head는 동일하지만 모델 깊이와 레이어의 채널 수가 다릅니다. YOLOv5s는 (0.33, 0.50), YOLOv5m은 (0.67, 0.75), YOLOv5l은 (1.0, 1.0), YOLOv5x는 (1.33, 1.25)의 비율이며, 그에 따른 성능은 아래와 같이 s가 가장 빠르고, 정확도는 x가 가장 높습니다.
PPYOLO
PPYOLO는 2020년 8월에 바이두에서 발표된 모델로, PP라는 것은 바이두에서 만든 오픈 소스 딥러닝 전용 프레임워크 PaddlePaddle의 약자입니다. 즉 PPYOLO는 PaddlePaddle을 이용해 구현한 YOLO 계열의 모델입니다. PPYOLO를 소개한 논문 PP-YOLO: An Effective and Efficient Implementation of Object Detector은 YOLO v4와 비슷하게, 좋다고 알려진 다양한 기법을 사용해 YOLO v3의 성능을 올린 과정을 소개한 논문이죠.
그러나 YOLO v4와 달리 백본 네트워크, Data augmentation, NAS 등은 사용하지 않았는데, 그 이유는 일반적인 방법을 사용해 YOLO v3의 성능을 올리기 위해서라고 합니다. 만약 YOLO v4에서 사용한 기법을 사용하면 PPYOLO의 성능은 더 좋아질 것이라고 하네요.
PPYOLO의 기본 구조는 YOLO v3와 거의 동일합니다. 다만 다른 것은 백본을 DarkNet-53 대신 ResNet50-vd를 사용한 것과 Inject Points 3가지가 추가로 적용된다는 것입니다.
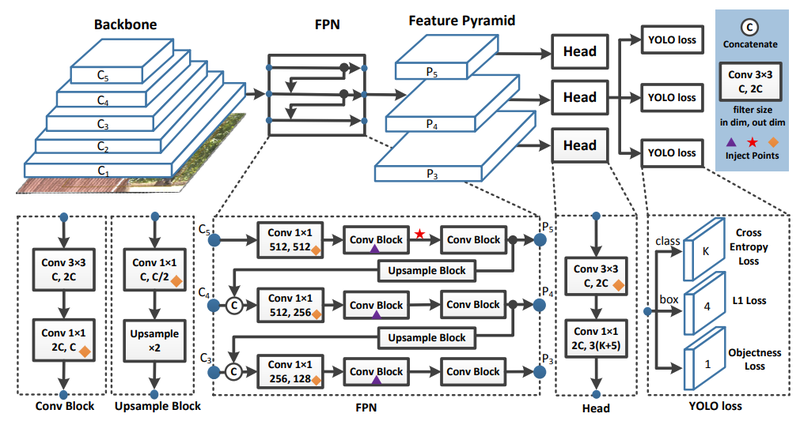
PPYOLO에서는 YOLOv4와 비슷하게 Larger Batch Size, EMA, DropBlock Regularization, SPP 등 다양한 방법을 사용해 실험을 했는데, 자세한 내용은 논문을 참고해 보세요.
PPYOLO의 성능은 YOLOv4보다 정확도와 속도가 모두 높습니다.
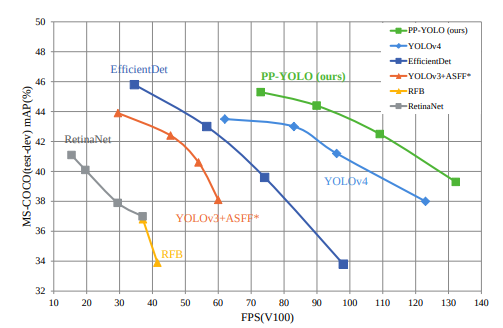
Scaled YOLO v4
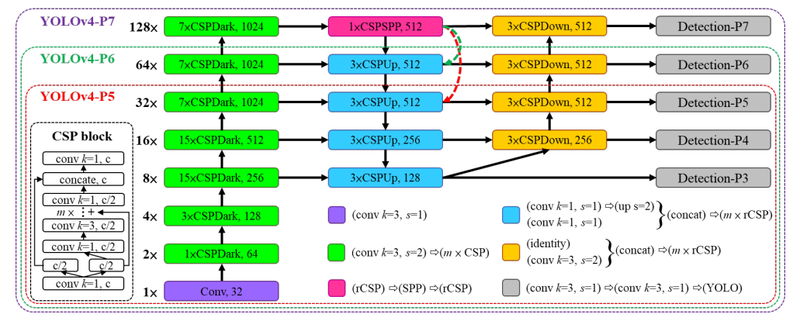
2020년 11월, YOLO v4에 scaling 기술을 적용한 Scaled YOLO v4가 공개되었습니다. Scaled YOLO v4는 다양한 디바이스 환경에서 실시간으로 객체를 탐색하면서도 높은 정확도를 갖출 수 있도록 모델에 scaling 기술을 YOLO v4에 적용하였는데요, YOLO v4 -> YOLOv4-CSP-> Scaled YOLO v4의 순서로 모델을 만들었다고 합니다. YOLO v4에 CSP를 적용한 이유는 기존 모델에 CSPNet을 적용하면 FLOPs(FLoating point Operations Per Second)을 현저히 줄일 수 있기 때문이었습니다. 또한 모델의 scaling의 상한과 하한을 정해 YOLOv4-large와 YOLOv4-tiny model을 만들었습니다.
아래의 그림은 YOLO v4-large의 아키텍처입니다. 먼저 CSP를 완전히 적용한 YOLOv4-P5를 디자인한 후, 이를 스케일링 업하여 -P6, -P7 버전을 만들었다고 하네요.
Scaled YOLO v4는 발표 당시 기존의 object detection 분야에서 가장 좋은 성능을 가지고 있었습니다. Scaled YOLO v4에 대한 자세한 내용은 논문 Scaled-YOLOv4: Scaling Cross Stage Partial Network을 참고하세요.
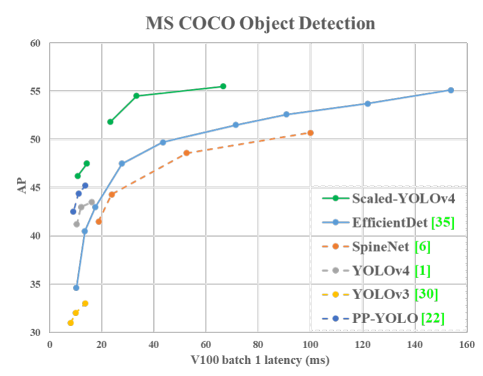
[Scaled YOLO v4 성능]
PPYOLO v2
2021년 4월 PPYOLO의 업그레이드된 모델인 PPYOLO v2가 공개되었습니다. PPYOLO v2의 성능과 정확도는 당시의 다른 모델보다 좋았다는 것을 아래의 그래프를 통해 알 수 있습니다.
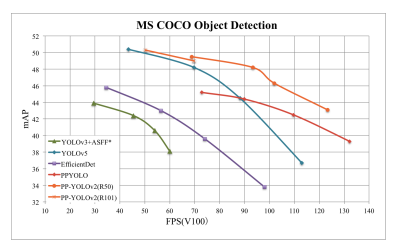
PPYOLO v2는 PPYOLO의 성능을 향상시키기 위해 mish 활성화 함수와 Path Aggregating Network 등 다양한 실험을 했다고 하는데요, 자세한 내용은 논문 PP-YOLOv2: A Practical Object Detector을 참고해 보세요.
YOLOR
2021년 5월에 YOLOR이 논문 You Only Learn One Representation: Unified Network for Multiple Tasks에서 소개되었습니다. YOLOR은 Scaled YOLO v4에서 파생된 모델로 같은 저자에 의해 쓰여졌습니다.
YOLOR은 사람이 학습할 때 명시적 지식(explicit knowlege)과 암묵적 지식(implicit knowlege)를 사용한다는 것에서 착안하여 만들어진 모델입니다. 참고로 명시적 지식은 말과 글로 표현할 수 있는 지식이고, 암묵적 지식은 문자나 언어가 아닌 경험이나 학습에 의해 체득된 지식입니다. YOLOR은 사람의 일반적인 학습 과정을 딥러닝에 적용하여 general representation을 생성하는 통합된 네트워크를 구성하였습니다. 이로써 YOLOR은 멀티 태스크를 잘 수행할 수 있었죠.
YOLOR의 아키텍처는 단순한데, YOLO v4 CSP 모델의 feature alignment, prediction refinement, multitask에 암묵적 지식을 아래와 같이 더해주는 것입니다. 암묵적 지식의 형태나 어떻게 모델에 적용되는지는 논문을 참고해 보세요.
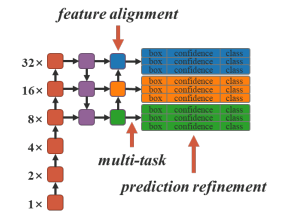
[YOLOR의 아키텍처]
YOLOX
2021년 8월에 나온 YOLOX: Exceeding YOLO Series in 2021는 Anchor-Free Detector, Advanced Label Assignment Strategy, End-to-end Detector 등의 최신 연구를 적용하여 YOLO v3 SPP의 성능을 개선하였습니다.
아래 그림은 베이스라인으로 사용한 YOLO v3과의 차이를 나타내고 있는데요, YOLOX는 특히 Decoupled Head, Strong Data Augmentation, Anchor-Free, Multi-positives를 통해 성능 향상을 꾀하고 있습니다. Decoupled Head는 prediction하고자 하는 값에 따라 Head를 나누어 학습 속도를 빠르게 했고, Detector를 End-to-End 방식으로 만들 수 있었습니다.
Anchor-Free는 ground truth box 와 생성된 bounding box 안의 cell이 겹쳐 있으면 positive, 아니면 negative로 지정하여 detection을 수행합니다. 이로 인해 연산량을 낮추고, 일반화를 시킬 수 있으며 class imbalance 문제도 해결하고, 정확도를 높일 수 있다고 하네요.
그러나 Anchor-Free 방식만으로는 Anchor 메커니즘의 정확도를 따라잡을 수 없었기 때문에 Multi-positives를 사용하였습니다. Multi-positives는 각 객체의 중심과 주변에 해당하는 cell을 positive로 할당하여 예측을 하는 방법으로, 낮은 loss를 가진 k개의 cell만 학습에 참여시키는 simOTA과 함께 사용하여 정확도를 향상시켰습니다. YOLOX에 대해 더 자세한 내용은 논문을 참고해 보세요.
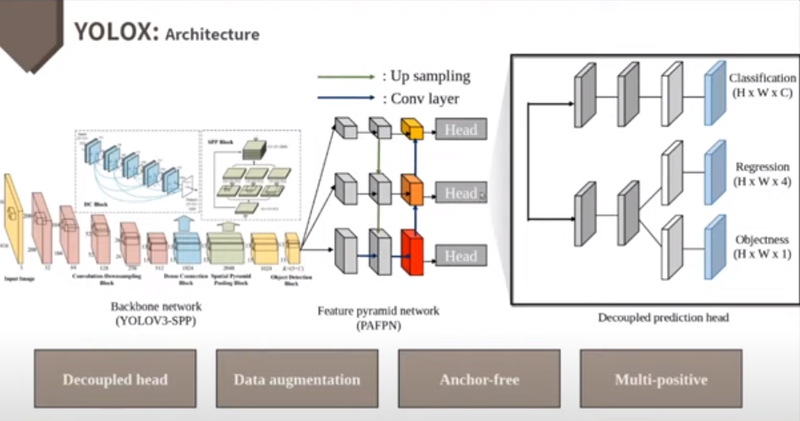
[YOLOX의 아키텍처]
YOLOS
NLP 분야에서 큰 영향을 끼치고 있는 Transformer는 CV에서도 점차 영향력을 키우고 있습니다. 이런 흐름에 맞춰 2021년 10월 You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection라는 논문에서 YOLOS라는 모델이 소개되었습니다. 즉 YOLOS는 Transformer Encoder와 NLP Heads만을 사용해 2D object detection을 수행한 모델입니다.
YOLOS의 성능은 최근에 나온 다른 YOLO 게열의 모델과 비교했을 때 아주 좋지는 않은데요, YOLO v3이나 RetinaNet와 비슷한 정도의 성능을 보이고 있습니다. 하지만 Transformer를 object detection에 적용했다는 점에서 주목해볼만 하죠?
아래의 그림은 YOLOS의 모델 구조입니다. 간단히 설명하자면 YOLOS는 Transformer와 DETR의 Bipartite Loss를 합친 모델입니다. 자세한 내용은 논문을 참고해 보세요.
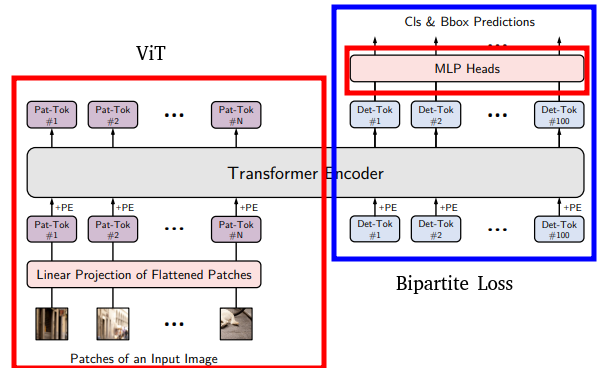
[YOLOS의 아키텍처]
6. SSD
6.1. SSD의 특징
SSD : Single Shot MultiBox Detector
YOLO가 1-stage로 object detection을 할 수 있다는 증명을 한 뒤, 1-stage detector는 수많은 발전을 이뤄왔습니다. SSD는 YOLOv1에서 grid를 사용해서 생기는 단점을 해결할 수 있는 아래와 같은 몇 가지 테그닉을 제안했죠.
- Pre-defined Anchor Box
- Image Pyramid
이제부터 SSD에 대한 자세한 내용을 논문 SSD: Single Shot MultiBox Detector를 참고로 하여 설명해 보겠습니다.
SSD의 Workflow
YOLOv1의 두번째 단점은 box 정보(x, y, w, h)를 예측하기 위한 seed 정보가 없기 때문에 bbox 분포를 모두 학습할 수 없었다는 점입니다. 이로 인한 성능 손실이 존재할 수 있었죠. 따라서 Faster R-CNN 등에서 사용하는 anchor를 적용할 필요가 있었습니다.
만약 개가 등장하는 bounding box가 존재한다면 그 bounding box만의 x, y, w, h 특성이 존재하기 때문에 pre-defined된 box의 x, y, w, h를 refinement하는 layer를 추가하는 것이 이득이었습니다. 이 anchor box를 SSD에서는 Default box라고 부릅니다.
Image Pyramid
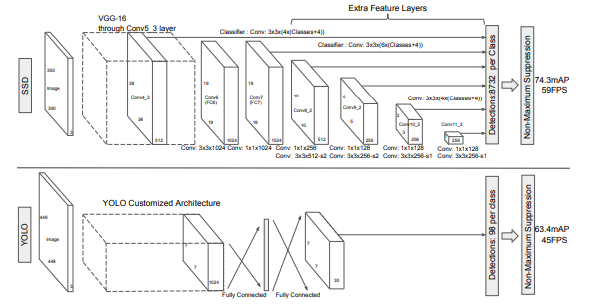
[SSD와 YOLO의 아키텍처 비교]
Image Pyramid는 ImageNet으로 사전학습된 VGG16을 사용합니다. VGG에서 pooling layer를 거친 block은 하나의 image feature로 사용 가능합니다.
YOLO에서 7x7 크기의 feature map 하나만을 사용했다면, SSD는 38 x 38, 19 x 19, 10 x 10, 5 x 5, 3 x 3, 1 x 1인 다양한 크기의 feature map을 사용하였습니다. 각 feature map은 YOLO의 관점에서 보면 원본 이미지에서 grid 크기를 다르게 하는 효과가 있었습니다. 따라서 5 x 5 크기의 feature map에서 grid가 너무 커서 작은 물체를 못찾는 문제를 38 x 38 크기의 feature map에서 찾을 수 있는 단서를 마련하였습니다.
즉 SSD는 서로 다른 크기의 feature map에서 object detection을 해서 작은 물체는 큰 feature map에서, 큰 물체는 작은 feature map에서 찾을 수 있게 한 거죠. 각 단계에서 추출된 feature map은 detector와 classifier를 통과해 object detection을 합니다.
각 feature map에는 bounding box와 클래스 정보가 담겨 있는데, 이 feature map들을 2번 convolution합니다. 위의 그림에서 보면 Classifier: Conv: ...라고 쓰여있는 부분에서 1번 더 convolution을 하게 되죠. 3 x 3 x (default box의 수 x (class의 수 + 4)의 가중치로 convolution을 하여 n x n x (default box의 수 x (class의 수+4))의 feature map을 얻게 됩니다. 여기서 class는 PASCAL VOC의 클래스 20개와 배경 클래스를 합해 21이고, + 4는 bounding box의 위치 정보 x, y, w, h의 개수를 의미합니다.
아래의 그림은 위의 그림에서 생략되었던 detector와 classifier를 포함한 아키텍처를 보여줍니다. 각각의 feature map에서 뽑아낸 6개의 classifier의 예측을 NMS를 사용해 confidence가 가장 높은 box 하나만 남겨 최종 detection을 합니다.
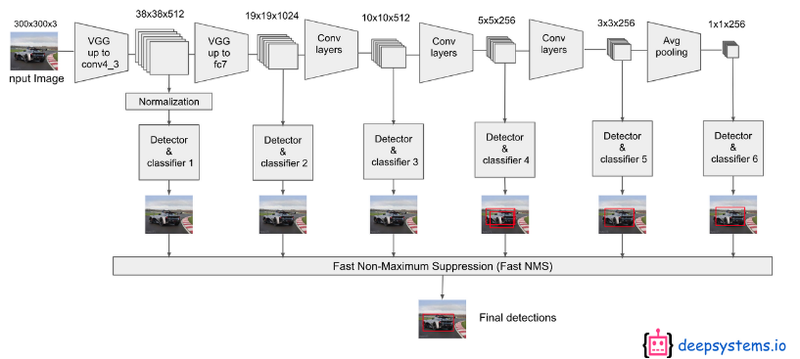
https://www.youtube.com/watch?v=P8e-G-Mhx4k
SSD의 framework
SSD는 입력 이미지와 각 객체에 대한 ground truth box만을 필요로 합니다. convolution을 할 때 비율이 다른 default box를 설정하는데, 아래의 그림은 다른 크기의 feature map에서, 각 객체마다 다른 비율의 default box를 4개씩 만들어 놓은 것을 표현한 것입니다. 각 default box에서 default box와 대응되는 bounding box regression을 적용하여 box의 (x, y, w, h)를 찾고 confidence, 즉 box 안에 물체가 있는지 없는지를 예측하는 점수를 예측합니다.
학습할 때 이 default box와 ground truth box를 비교해 ground truth box와 비슷한 default box를 선택하여 positive, 나머지는 negative로 설정합니다. 고양이는 개보다 작기 때문에 8 x 8 feature map에서는 고양이를 잡아내고, 4 x 4 feature map에서는 개를 잡아낸 것을 볼 수 있습니다.
이렇게 각 레이어에서 피쳐 맵들을 가져와 Object Detection을 수행한 결과들을 모두 합하여 localization loss와 confidence loss를 구한 다음, 전체 네트워크를 학습시키는 방식으로 1 Step end-to-end Object Detection 모델을 구성하였습니다.
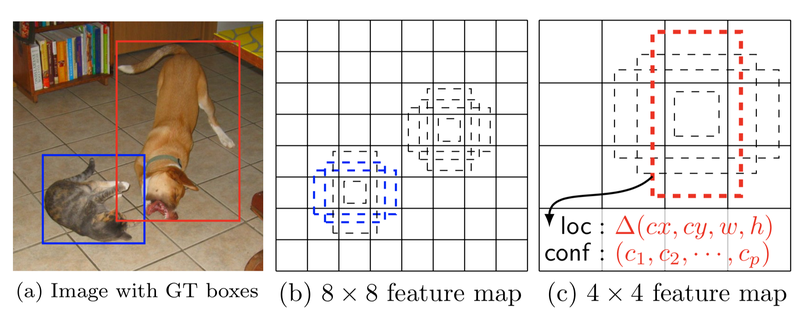
[SSD framework]
Default box를 위한 scale
다양한 크기의 Default box 생성을 위해 SSD는 아래와 같은 식을 사용합니다.
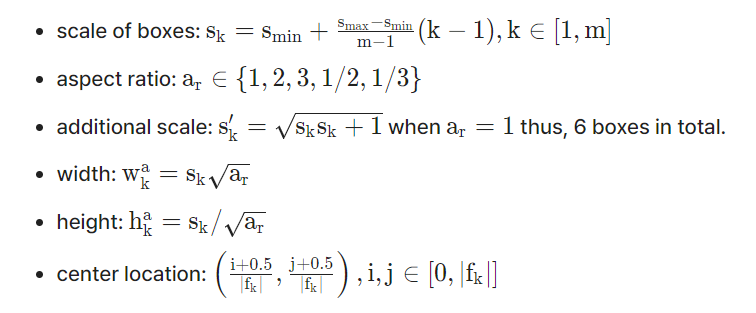
feature map의 개수를 m, 을 0.2, S를 0.9라고 하고, 위의 식에 넣으면 각 feature map당 서로 다른 6개의 s 값(scale 값) [0.2, 0.34, 0.48, 0.62, 0.76, 0.9]이 나옵니다. 이 값은 각 feature map에서 default box의 크기가 입력 이미지의 너비와 높이에 비해 얼마나 큰 지를 보여줍니다.
여기서 aspect ratio를 {1, 2, 3, 1/2, 1/3}로 설정하여 default box의 너비와 높이를 구할 수 있습니다. 예를 들어 k=3이라면 scale은 0.48이며 aspect ration가 2라면 너비는 0.68, 높이는 0.34입니다. 논문에서는 1개의 box를 더 추가해 총 6개의 default box의 너비와 높이 값을 구합니다.
입력 이미지에서 default box가 위치할 중심점(center location)의 식에서 는 k번째 feature map의 크기입니다. 대략 예측되는 상자가 정사각형이나 가로로 조금 길쭉한 상자, 세로로 조금 길쭉한 상자이기 때문에 2:3으로 임의로 정해도 학습이 잘 되지만, 특이한 경우, 즉 가로 방향으로 걸어가는 지네와 같은 경우에 위의 비율로 정하면 threshold를 0.5로 했을 때 학습이 되지 않습니다. 따라서 학습할 이미지에 따라서 aspect ration를 조정해야 합니다. 임의로 정하는 것은 비효율적이므로 KNN과 같은 알고리즘을 활용하면 좋은 결과가 나올 것입니다.
이렇게 구해준 중심점 좌표들에 원래의 입력 이미지의 크기를 곱해 중심점을 구하고, 각 중심점마다 default box를 그릴 수 있습니다. 이를 시각화하면 아래와 같습니다.
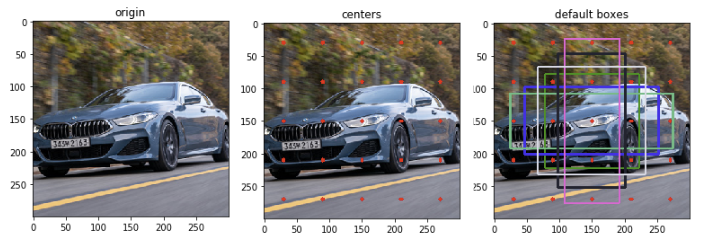
[default box 그리기]
6.2. SSD의 Loss와 성능
Matching strategy
학습 전에 ground truth와 default box의 jaccard overlay(IoU)이 0.5 이상인 것을 미리 매칭시켜 positive sample로 설정합니다. jaccard overlap이 0.5 이상인 default box를 모두 사용하면 학습 문제를 단순화시켜서 더 높은 성능을 가져올 수 있습니다.
SSD Loss function
SSD Loss function의 식은 아래와 같습니다.

우선 위의 식에서 사용된 용어를 정리하면 아래와 같습니다.
- : category p에 대한 ii번째 Default box와 jj번째 Ground Truth box의 물체 인식 지표입니다. 0.5 이상이면 1, 미만이면 0으로 정의됩니다.
- N : 매칭된 Default box의 개수, N이 0이면 loss는 0입니다.
- l : 예측된 상자(Predicted box)
- g : Ground Truth box
- d : Default bounding box
- cx, cy = 해당 box의 중점점 좌표
- w, h : 해당 box의 너비와 높이
- : 교차 검증으로 얻어진 값으로 1로 설정되어 있습니다.
Objective Loss Function
전체 로스는 각 클래스 별로 예측한 값과 실제값 사이의 차이인 와 bounding box regression 예측값과 실제값 사이의 차이인 를 더한 값입니다.
Localization Loss Function
Localization Loss Function는 예측된 박스 ll과 Ground truth box gg 파라미터 사이의 Smooth L1 loss, 즉 bounding box regression loss입니다. 는 예측해야할 bounding box의 중심점 좌표, 너비와 높이를 의미합니다. x, y 좌표 값은 절대값이므로 예측값과 실제 값 사이의 차를 default 박스의 너비 혹은 높이로 나누어 0과 1 사이로 정규화시켰습니다. 너비와 높이의 경우엔 로그를 씌워줍니다.
Confidence Loss Function
Confidence Loss Function는 여러 클래스의 confidence에 대한 softmax loss로, cross entropy loss와 비슷합니다. 매칭된(Positive) 클래스를 나타내는 값은 이고, 그 매칭된 클래스에 softmax를 취해줍니다. 매칭되지 않은(Negative) class를 예측하는 값은 이고 배경이면 1, 아니면 0의 값을 가집니다. 즉 최종 예측된 클래스 점수는 예측할 클래스 + 배경 클래스를 나타내는 지표가 됩니다.
Hard negative mining
대부분의 Default box가 배경이기 때문에 이 0인 경우가 많습니다. 따라서 마지막 class의 loss 부분에서는 default box를 high confidence 순으로 정렬해 상위만 가져다 써서 positive:negative 비율을 1:3으로 정해 출력합니다. 이로써 최적화 속도가 빨라지고 안정적으로 학습된다고 하네요.
SSD의 성능
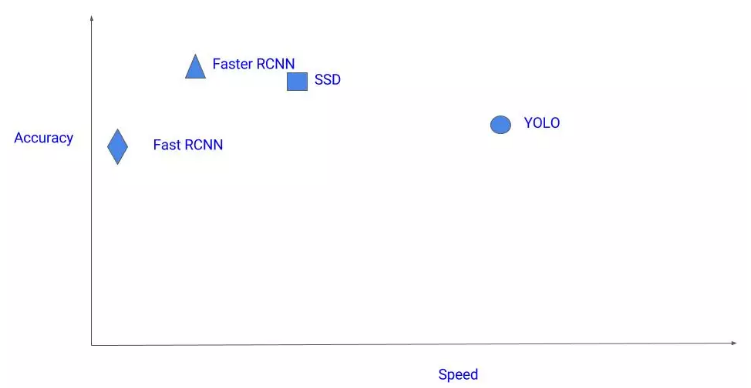
[SSD와 기타 object detection 모델의 정확도와 속도 비교]
YOLO가 작은 물체를 잘 찾아내지 못했던 것 역시 SSD에서는 어느 정도 해결한 것 같습니다. 심지어 YOLO v2보다 성능이 더 좋다는 것을 알 수 있습니다.
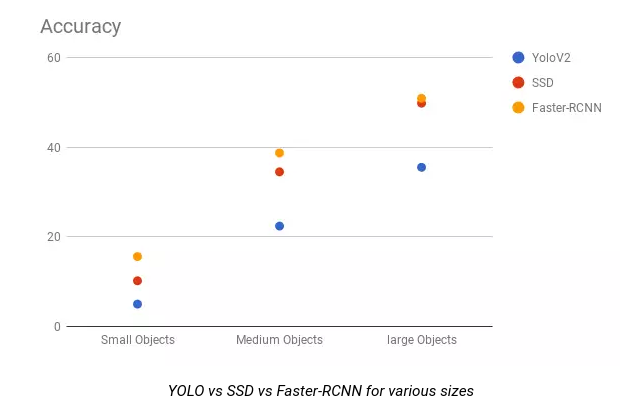
FCOS
FCOS:Fully Convolutional One-Stage Object Detectionan는 기존의 anchor box기반에서 벗어나 pixelwise로 예측하는 FCOS를 제안했습니다. Anchor box를 사용하면서 생기는 부작용(예: 학습 계산량, 하이퍼파라미터에 민감한 성능 등)을 해결하면서도 좋은 성능을 보입니다.
자세한 내용은 아래의 자료를 참고하세요.
7. Face Detection을 위한 모델들
지금까지 One-Stage Detection의 가장 대표적인 두가지 모델인 YOLO와 SSD에 대해 살펴보았습니다. 다음 실습에서는 SSD를 활용한 Face Detection을 실제로 구현해 보는 과정을 통해 더욱 깊이있게 알아보게 될 것입니다.
SSD 이후로 특히 Face Detection 모델이 지속적으로 발표되었습니다. papers with code에서 검색하면 Face Detection에 대한 다양한 모델을 살펴볼 수 있습니다.
그럼 SOTA Face Detection 모델을 중심으로 간단히 살펴볼까요?
TinaFace
논문 TinaFace: Strong but Simple Baseline for Face Detection에서는 Face Detection과 Object Detection이 다르지 않다는 점을 지적하면서, Object Detection에서 사용했던 기법을 사용해 단순하지만 좋은 성능을 보이는 모델인 TinaFace를 소개합니다. TinaFace는 백본으로 ResNet50을 사용했고 기존에 존재했던 모듈(Feature Pyramid Network, Inception block, FCN 등)을 활용해 만들어졌습니다. 자세한 내용은 논문을 참고해 보세요.
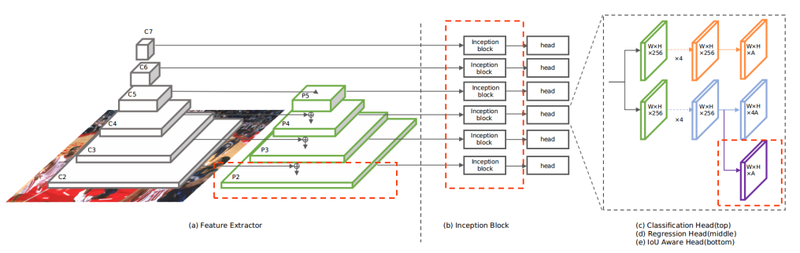
[TinaFace 모델 아키텍처]
RetinaFace
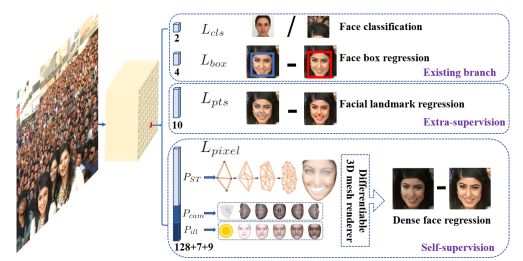
RetinaFace는 1-Stage face detector로서, 다양한 얼굴 크기에 대해 pixel-wise face localization을 수행했습니다. 이를 위해 기존의 box classification과 regression 브랜치와 함께 extra-supervised and self-supervised multi-task learning을 하였다고 합니다. 그 결과는 아래의 그림에 나와 있듯 face score, face box, 5개의 얼굴 랜드마크, 3D face vertices(정점)라고 하네요. 자세한 내용은 논문 RetinaFace: Single-stage Dense Face Localisation in the Wild을 참고해 보세요.
DSFD
DSFD는 Feature Enhance Module(FEM), Progressive Anchor Loss(PAL), Improved Anchor Matching (IAM)라는 기법을 사용해 성능을 높인 모델인데요, 언급한 세 기법이 two-stream으로 디자인되어 있어서 Dual Shot Face Detector라는 이름이 붙었다고 합니다. 자세한 내용은 논문 DSFD: Dual Shot Face Detector을 참고해 보세요.
S3FD
S3FD는 하나의 deep neural network를 사용해 다양한 얼굴 크기에 대해 face detection을 수행하며, 특히 작은 얼굴을 잘 찾는 모델입니다. 다양한 크기의 얼굴을 잘 찾기 위해 layer의 넓은 범위에 anchor를 바둑판 형식으로 배열하였고, anchor 크기도 새롭게 디자인했다고 합니다. 그 외에도 작은 얼굴을 잘 찾기 위해 다양한 기법을 사용했다고 하는데요, 자세한 내용은 논문 S3FD: Single Shot Scale-invariant Face Detector을 참고해 보세요.
