3-1. 들어가며
딥러닝 모델을 학습 시키기 위해서는 대량의 데이터를 확보하는 건 기본!! 대표적인 이미지 데이터셋인 이미지넷(ImageNet)은 약 1400만 장이나 되는 이미지를 갖고 있고, 분류 대상 클래스가 10개라 상대적으로 간단해 보이는 CIFAR-10도 몇 만장의 데이터를 갖고 있다.
미리 공개되어 있는 데이터셋 외에도 우리가 원하는 문제를 풀 때는 이에 맞는 데이터가 추가로 필요하다. 하지만 이러한 데이터는 몇 만장씩 구축하는 데는 많은 비용과 시간이 필요하다. 이 때, 제한된 데이터셋을 최대한 활용하기 위해서 augmentation이라는 방법을 사용할 수 있다. 그렇다면 augmentation은 어떻게 사용하는 것이며 우리에게 어떤 효과를 줄 수 있을까??
클라우드 쉘(터미널)을 열고 개인 실습환경에 맞춰 경로를 변경하고, 일부 실습에 필요한 디렉토리를 먼저 만들어 준다.
! mkdir -p ~/aiffel/data_augmentation/images3-2. 데이터셋의 현실
1) 대량의 데이터셋
앞서 이야기했듯, 이미지넷은 1400만장의 이미지를 보유하고 있으며, 우리가 자주 사용해왔던 CIFAR-10만 하더라도 학습용 데이터셋이 5만 장이나 되었다.
이런 규모의 데이터셋을 만드는 데 얼마나 큰 비용이 들지... 라벨 데이터를 포함해 장당 10원에 불과하다고 하더라도 이미지넷과 같은 데이터셋을 구축하기 위해서는 1억이라는 어마무시한 비용이 들어간다. 물론 실제로 이러한 데이터셋을 직접 구축하려면 이보다 훨씬 비싼 가격이 들어간다.
[출처 : https://www.robots.ox.ac.uk/~vgg/software/via/images/via_demo_screenshot2_via-2.0.2.jpg]
2) 직접 구축하는 데이터셋
사진을 보고 시내의 유명한 카페를 분류하는 모델을 만들어야 하는 프로젝트가 있다고 가정해 보자. 그러면 우리는 어떻게 데이터셋을 모을 수 있을까?
강남의 카페를 조사하기 위해 인스타그램을 크롤링 해 20여개의 카페 사진 약 2,500장을 얻을 수 있다고 상상해 보라. 처음 크롤링 할 때는 많았으나 내부 인테리어 사진으로 카페를 구분하기 위해서 음식 사진, 사람 사진을 제외하고 나니 많은 수가 줄어들었다. 이처럼 직접 데이터를 수집한다면 만 장 단위로 데이터셋을 모으기가 쉽지 않다는 것을 금방 알 수 있다.
[우리가 현실의 문제를 해결하기 위해 맞닥뜨려야 하는 데이터들은 충분히 모으기도 쉽지 않지만 고품질로 정제하는 과정도 만만치 않습니다.]
3-3. Data Augmentation이란? - (1) 개요
그럼 열심히 모은 데이터셋을 어떻게 활용할 방법을 없는 걸까?
이를 위해 Data augmentation을 활용하게 될 텐데, 이는 갖고 있는 데이터셋을 여러 가지 방법으로 증강시켜(augment), 실질적인 학습 데이터셋의 규모를 키울 수 있는 기법이다. 일반적으로 하드디스크에 저장딘 이미지 데이터를 메모리에 로드한 후, 학습시킬 때 변형을 가하는 방법을 사용한다. 이를 통해 1장의 이미지를 더 다양하게 쓸 수 있다.
아래의 비디오를 보고 data augmentation의 개념을 익히면 좋을 듯 하다.
데이터가 많아진다는 것은 과적합(overfitting)을 줄일 수 있다는 것을 의미한다. 또한 우리가 가지고 있는 데이터셋이 실제 상황에서의 입력값과 다를 경우, augmentation을 통해서 실제 입력값과 비슷한 데이터 분포를 만들어 낼 수 있다. 예를 들어, 우리가 학습한 데이터는 노이즈가 많이 없는 사진이지만 테스트 이미지는 다양한 노이즈가 있는 경우 테스트에서 좋은 성능을 내기 위해서는 이러한 노이즈의 분포를 예측하고 학습 데이터에 노이즈를 삽입해 모델이 이런 노이즈에 잘 대응할 수 있도록 해야 한다. 이렇게 data augmentation은 데이터를 늘릴 뿐만 아니라 모델이 실제 테스트 환경에서 잘 동작할 수 있도록 도와주기도 한다.
이미지 데이터 augmentation
이미지 데이터의 augmentation은 포토샵, SNS의 사진 필터, 각종 카메라 앱에서 흔히 발견할 수 있는 기능들과 유사하다. 쉬운 예로는 모델이 다양한 색상의 사진을 학습하게 하기 위해서 우리가 인스타그램에 업로드할 때 쓰는 색상 필터들을 적용해 볼 수 있다. 또 좌우 대칭이나 상하 반전과 같이 이미지의 공간적 배치를 조작할 수도 있다.
3-4.Data Augmentation이란? - (2) 다양한 Image Augmentation 방법
그렇다면 image augmentation 기법에는 구체적으로 어떤 것들이 있는지 본격적으로 살펴볼 시간이다. 먼저 텐서플로우 튜토리얼에 소개된 image augmentation 예제들로부터 시작한다. 아래 텐서플러우 페이지에서는 텐서플로우 API를 사용해 바로 적용할 수 있는 image augmentationm 기법들을 소개하고 있다.
[링크텍스트](Tensorflow : Data augmentation)https://www.tensorflow.org/tutorials/images/data_augmentation
1) Flipping
이 기능은 이미지의 대칭 이동과 같은 경우를 말한다. 우리가 거울을 보면 반전이 디듯이 상하 또는 좌우로 이미지를 반전시킨다. 분류 문제에서는 문제가 없을 수도 있지만 물체 탐지(detertion),세그멘테이션(segmentation) 문제 등 정확한 정답 영역이 존재하는 문제에 적용할 때는 라벨도 같이 좌우 반전을 해줘야 한다.
만약 숫자나 알파벳 문자를 인식(recognition)하는 경우에는 적용시킬 때도 주의해야 한다. 상하나 좌우가 반전될 경우 다른 글자가 될 가능성이 있기 때문이다. 예컨대 6을 9로 잘못 인식 한다든지, 소문자 b를 d로 인식한다든지 하는 이런 문제 말이다.

https://www.tensorflow.org/tutorials/images/data_augmentation
2) Gray scale
Gray scale은 3가지 채널(channel)을 가지는 RGB 이미지를 하나의 채널만을 가지도록 해 준다. 아래의 시각화 예제처럼 gray scale이라고 해서 꼭 흑백 이 아니라 다른 색상으로 이미지로 표현하기도 한다. 텐서플로우에서 어떻게 구현이 되었는지는 아래 코드를 확인 바란다. RGB 각각의 채널마다 가중치(weight)를 주어 가중합(weighted sum)을 했다. 사용된 가중치의 경우 합이 1이 되는 특징이 있다.

https://www.tensorflow.org/tutorials/images/data_augmentation
3) Saturation
Saturation은 RGB 이미지를 HSV, 즉 Hue(색조), Saturation(채도), Value(명도)의 3가지 성분으로 색을 표현하는 것을 통해 이미지로 변경하고 S(Saturation) 채널에 오프셋(offset)을 적용, 조금 더 이미지를 선명하게 만들어 준다. 이후 다시 우리가 사용하는 RGB 색상 모델로 변경을 한다.
색상 모델(gray, RGB, HSV, YCBCr) 에 대해서 보통 이미지, 영상 관련 처리를 할 때 상황에 맞는 색상 모델을 정해야 합니다.이러한 색상 모델에는 여러 가지 종류가 있습니다.간단하게 색상 모델에 대한 특징을 정리해보겠습니다.
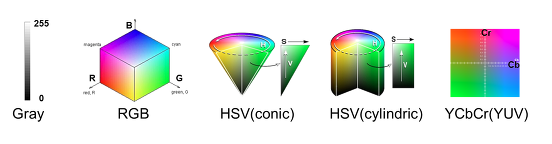
[출처: https://darkpgmr.tistory.com/66]
Gray 모델 : 색(Color) 정보를 사용하지 않고, 밝기 정보만으로 영상을 표혀하는 것. 검정(0)부터 흰색(255) 까지 총 256단계의 밝기 값(Intersity)으로 영상 픽셀 값을 표현한다.
RGB 모델 : 가장 기본적인 색상 모델로, 색을 Red, Green, Blue의 3가지 성분의 조합으로 생각하는 것을 말한다. RGB 모델에서는 색상에 관하여 다음과 같이 픽셀값을 가지므로 참고 바란다.
- 검은색은 R,G,B의 값이 모두 0 -> (0,0,0)
- 흰색은 R,G,B의 값이 모두 255 -> (255,255,255)
- 빨간색은 R이 255, 나머지 G,B가 0 -> (255,0,0)
- 초록색은 G가 255, 나머지 R,B가 0 -> (0,255,0)
- 파란색은 B가 255, 나머지 R,G가 0 -> (0,0,255)
- 노란색은 R과 G가 255, B=0 -> (255,255,0)
여기서 R=G=B일 경우는 무채색인 Gray 색상을 따르게 된다. R, G, B가 각각 0~255 사이의 값을 가질 수 있으므로, RGB 색상 모델을 사용하면 총 256 X 256 X 256 = 16,777,216 가지의 색을 표현할 수 있다.HSV 모델 : Hue(색조), Saturation(채도), Value(명도)의 3가지 성분으로 색을 표현한다. Hue의 색조란 해당 색이 붉은색 계열인지 푸른색 계열인지를 나타내고, Saturation의 채도란 해당 색이 얼마나 선명하고 순수한 색인지, Value의 명도란 밝기(Intensity)를 나타낸다. HSV 모델은 우리가 색을 가장 직관적으로 표현할 수 있는 모델이고, 머릿속에서 상상하는 색을 가장 쉽게 만들어낼 수 있는 모델이다. 영상처리 / 이미지 처리에서 HSV 모델을 사용할 때, H, S, V 각각은 0~255 사이의 값으로 표현된다. H 값은 색의 종류를 나타내기에 크기가 의미가 없이 단순 인덱스를 나타내는 것이며, S 값은 0이면 무채색(gray색), 255면 가장 선명한(순수한) 색임을 나타낸다. V 값은 작을수록 어둡고, 클수록 밝은 색임을 나타낸다. HSV 색상 모델은 그림과 같이 원뿔(conic) 형태, 원기둥(cylindric) 형태가 있다.
YCbCr 모델 : RGB 색에서 밝기 성분과 색차 정보를 분리하여 표현하는 색상 모델이다. 디지털 영상에서 Y, Cb, Cr은 각각 0~255 사이의 값을 가지며, Y가 커지면 그림이 전체적으로 밝아지고, Y가 작아지면 전체적으로 어두워진다. YCCr 모델은 mpeg에서 사용되는 색상모델로써, 인간의 눈이 밝기 차에는 민감하지만, 색차에는 상대적으로 둔감하다는 점을 이용해서 Y에서 많은 비트수(해상도)를 할당하고, Cb, Cr에는 낮은 비트 수를 할당하는 방식으로 비디오를 압축한다. 따라서 비디오 데이터를 처리할 경우에 YCbCr 모델을 사용하면 별도의 색상 변한을 하지 않아도 되는 장점이 있다. 참고로 YCbCr 모델은 YUV 모델로도 불린다.

https://www.tensorflow.org/tutorials/images/data_augmentation
4) Brightness
밝기를 조절할 수도 있다. 우리가 주로 사용하는 RGB에서 (255,255,255)는 흰색을, (0,0,0)은 검은색을 의미한다고 했었는데, 이 RGB 채널에서 값을 더해주면 밝아지고, 빼주면 어두워지는 원리를 이용한다. 이를 통해 밝기(Brightness)를 변경할 수 있다.
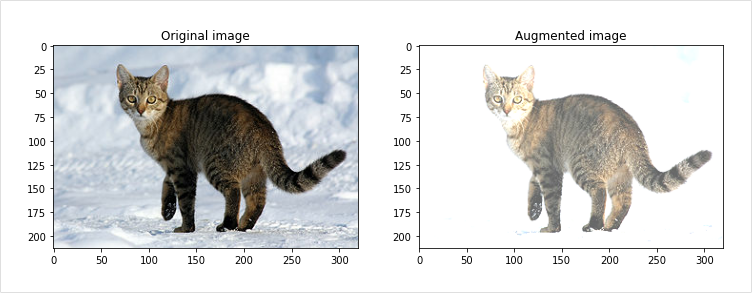
https://www.tensorflow.org/tutorials/images/data_augmentation
5) Rotation
Rotation은 이미지의 각도를 변환해 준다. 90도의 경우 직사각형 형태가 유지되기 때문에 이미지의 크기만 조절해 주면 바로 사용할 수 있다. 하지만 90도 단위로 돌리지 않는 경우 직사각형 형태에서 기존 이미지로 채우지 못하는 영역을 어떻게 처리해야 할지 유의해야 한다.

https://www.tensorflow.org/tutorials/images/data_augmentation
6) Center Crop
Center crop은 이미지의 중앙을 기준으로 확대하는 방법이다. 너무 작게 center crop을 할 경우 본래 가진 라벨과 맞지 않게 되는 상황이 발생할 수 있으니 주의가 필요하다. 예를 들어 고양이 라벨의 이미지를 확대해 한 장 더 만들어내려면, 이미지 내에 고양이의 형상을 유지해야 하고 털만 보이는 이미지를 만들어서는 안 된다.

https://www.tensorflow.org/tutorials/images/data_augmentation
7) 정리
위의 기본적인 방법들 외에도 다양한 augmentation 방법론이 있다. 이들 방법을 사용하면 아래 이미지처럼 라벨은 유지한 채 다양한 이미지를 학습 데이터로 사용할 수 있게 된다.

https://github.com/aleju/imgaug
이 뒤부터는 이미지를 들고 와서 직접 실습해보는 시간을 가진다. 직접 코랩에 작성 후 Github에 공유했으니 과정이 궁금하다면 한 번 돌아봐도 괜찮을 듯 싶다.
텐서플로우를 사용한 Image Augmentation 실습
※ 주의 : 용량이 제법 큰 편(대략 14MB 정도)이라서 해당 Github 주소로의 접속이 한번씩 안 될 수도 있습니다. 그럴 경우에는 colab에서 작성한 것도 공유했으니 이걸로 봐도 될 거 같습니다.
