4-1. 들어가며
오늘은 augmentation 기법을 적용해 ResNet-50을 학습시켜 보는 시간이다. 텐서플로우의 랜덤 augmentation API를 사용해보고, 최신 augmentation 기법을 익힌 뒤, 훈련 데이터셋의 augmentation 적용 여부에 따라 모델의 성능이 달라지는지 비교해 보자.
실습 목표
- Augmentation을 모델 학습에 적용하기
- Augmentation의 적용을 통한 학습 효과 확인하기
- 최신 data augmentation 기법 구현 및 활용하기
학습 내용
- Augmentation 적용 (1) 데이터 불러오기
- Augmentation 적용 (2) Augmentation 적용하기
- Augmentation 적용 (3) 비교 실험하기
- 심화 기법 (1) Cutmix Augmentation
- 심화 기법 (2) Mixup Augmentation
- 프로젝트 : CutMix 또는 Mixup 비교 실험하기
준비물
~/aiffel/data_augmentation 폴더가 필요한데. 아직 디렉토리가 없다면 터미널을 열고 개인 실습환경에 맞추어 경로를 변경, 디렉토리를 생성해 야 한다. 본인은 이미 디렉토리 생성 완료~~
4-2. Augmentation 적용 - (1) 데이터 불러오기
이번 노드에서는 augmentation을 텐서플로우 모델 학습에 어떻게 적용할 수 있는지를 공부한다. 지금까지 모델을 훈련시키기 전, 데이터를 전처리해 입력값으로 사용해 왔다. Augmentation도 이처럼 입력 이미지의 데이터를 변경해 주는 과정이므로 일반적인 이미지 데이터 전처리 방법과 활용방법이 동일하다. 먼저 필요한 라이브러리들을 불러온다.
# TensorFlow and tf.keras
import tensorflow as tf
from tensorflow import keras
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
import tensorflow_datasets as tfds학습 전에는 항상 GPU 환경을 확인한다. 특히 코랩에서 할 경우!!
tf.config.list_physical_devices('GPU')[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
그리고 사용할 데이터셋을 불러온다. 이번 시간에는 stanford_dogs 데이터셋을 사용할 것이다. stanford_dogs 데이터셋에는 120개 견종의 이미지가 포함되어 있으며, 총 20,580장이다. 그 중 12,000장은 학습용 데이터셋, 나머지 8,580장은 평가용 데이터셋이다.
데이터를 처음 사용한다면 다운로드를 해야 되서 시간이 다소 오래 걸린다. 최소 10분 이상 걸릴 수도 있으니 리플레쉬~~ 해당 데이터셋은 다른 프로젝트에서도 사용할 수 있으니, 프로젝트 디렉토리가 아닌 TensorFlow Datasets 기본 디렉토리에 저장하는 게 좋다.
(ds_train, ds_test), ds_info = tfds.load(
'stanford_dogs',
split=['train', 'test'],
shuffle_files=True,
with_info=True,
)# 다운로드한 데이터 확인
tfds.show_examples(ds_train, ds_info)4-3. Augmentation 적용 - (2) 실제 적용하기
텐서플로우 Random Augmentation API 사용하기
많은 augmentation 기법들이 있었지만 그중에서 텐서플로우 API로 바로 사용할 수 있는 방법들을 먼저 적용해 본다. 먼저 이미지셋에 대해서 랜덤한 확률로 바로 적용할 수 있는 augmentation 함수들은 아래와 같다.
random_brightness()random_contrast()random_crop()random_flip_left_right()random_flip_up_down()random_hue()random_jpeg_quality()random_saturation()
Augmentation을 적용하기에 앞서 기본적인 전처리 함수를 만든다.
def normalize_and_resize_img(image, label):
# Normalizes images: `uint8` -> `float32`
image = tf.image.resize(image, [224, 224])
return tf.cast(image, tf.float32) / 255., label이미지 변환하는 전처리 함수는 대략 다음과 같은 형태를 가지게 된다.
def 전처리_함수(image, label): # 변환할 이미지와 라벨
# 이미지 변환 로직 적용
new_image = 이미지_변환(image)
return new_image, label이렇게 되면 이미지 변환의 결과로 리턴 받은 이미지를 그다음 전처리 함수의 입력으로 연거푸 재사용할 수 있는 구조가 되어 매우 편리하다. 위에서 만든 기본적인 전처리 함수도 위와 같은 구조를 가지고 있다. 이 함수는 입력받은 이미지를 0~1 사이의 float32로 normalize하고, (224,224) 사이즈로 resize한다. 이 함수는 훈련용과 테스트용으로 사용될 모든 이미지에 적용이 될 것이다.
맨 위에서 언급한 random augmentation들 중에서 우선 random_flip_left_right()와 random_brightness()를 활용해 보도록 하겠다. 'flip'의 경우 좌우 대칭을 시켜주는 "flip"의 경우 좌우 대칭을 해줬었다. 예컨대 이미지 분류 문제에서 개 이미지는 좌우를 대칭하더라도 문제가 생기지 않는다. 따라서 좌우대칭의 적용을 통해 데이터를 늘릴 수 있도록 해야 한다. 여기서 상하 대칭은 테스트 데이터셋의 이미지를 생각해 볼 때 위아래가 뒤집힌 사진이 없으므로 도움이 되지 않을 것이라 적용하지 않는다. 또 "brightness"를 조절하여 다양한 환경에서 얻어진 이미지에 대응할 수 있도록 한다.
def augment(image,label):
image = tf.image.random_flip_left_right(image)
image = tf.image.random_brightness(image, max_delta=0.2)
image = tf.clip_by_value(image, 0, 1)
return image, label오늘의 Augmentation을 통해 원본 데이터셋에 다양한 형태의 가공한 새로운 데이터셋을 얻게 되는 모든 과정을 구현한 메인 함수를apply_normalize_on_dataset()으로 정의한다. 여기서는 apply_normalize_on_dataset()을 통해서 일반적인 전처리 과정, 즉 normalize, resize, augmentation과 shuffle을 적용하도록 하낟. 이 때 주의점은 shuffle이나 augmentation은 테스트 데이터셋에는 적용하지 않아야 한다는 점이다.
여러 결과를 조합하기 위한 앙상블(ensemble) 방법 중 하나로 테스트 데이터셋에 augmentation을 적용하는 test-time augmentation이라는 방법이 있다. 이는 캐글 등의 경쟁 머신러닝에 많이 사용되지만, 지금은 개념만 알아도 된다. 아래 링크에서 test-time augmentation에 관한 설명을 참고하면 된다.
코드에서는 이후에 수행할 비교실험을 위해서 with_aug 매개변수를 통해 augmentation의 적용여부를 결정할 수 있도록 했다.
# 데이터셋(ds)을 가공하는 메인함수
def apply_normalize_on_dataset(ds, is_test=False, batch_size=16, with_aug=False):
ds = ds.map(
normalize_and_resize_img, # 기본적인 전처리 함수 적용
num_parallel_calls=2
)
if not is_test and with_aug:
ds = ds.map(
augment, # augment 함수 적용
num_parallel_calls=2
)
ds = ds.batch(batch_size)
if not is_test:
ds = ds.repeat()
ds = ds.shuffle(200)
ds = ds.prefetch(tf.data.experimental.AUTOTUNE)
return ds
Random Augmentation 직접 구현하기
위에서는 미리 구현된 random augmentation을 적용하도록 augment() 함수를 작성했었다. 이번에는 tf.image의 다양한 함수들을 이용해서 직접 다양한 augmentation 기법을 랜덤하게 적용하는 augment2() 함수를 작성해보세요.
# make random augment function
def augment2(image,label):
image = tf.image.central_crop(image, np.random.uniform(0.50, 1.00))
image = tf.image.resize(image, [224, 224])
return image, label4-4. Augmentation 적용 - (3) 비교실험
이제 비교 실험을 해보도록 할 것이다. 우리가 비교해야 하는 것은 augmentation을 적용한 데이터를 학습시킨 모델과 적용하지 않은 데이터를 학습시킨 모델의 성능이다. 새로운 augmentation이 떠올랐다면 새로운 함수로 augmentation한 데이터와 아닌 데이터를 학습시켜서 어떤 효과가 있는지 실험을 통해 알아볼 수 있다.
아래 코드는 텐서플로우 케라스의 ResNet50 중 imagenet으로 훈련된 모델을 불러온다. includ_top은 마지막 fully connected layer를 포함할지의 여부이다. 해당 레이어를 포함하지 않고 생성하면 특성 추출기(feature extractor) 부분만 불러와 우리의 필요에 맞게 수정된 fully connected layer를 붙여서 활용할 수 있다. 이렇게 하는 이유는 이미지넷(ImageNet)과 우리의 테스트셋이 서로 다른 클래스를 가지므로, 마지막에 추가해야 하는 fully connected layer의 구조(뉴런의 개수) 또한 다르기 때문이다.
num_classes = ds_info.features["label"].num_classes
resnet50 = keras.models.Sequential([
keras.applications.resnet.ResNet50(
include_top=False,
weights='imagenet',
input_shape=(224,224,3),
pooling='avg',
),
keras.layers.Dense(num_classes, activation='softmax')
])Augmentation을 적용한 데이터셋으로 학습시킬 ResNet을 하나 더 만든다.
aug_resnet50 = keras.models.Sequential([
keras.applications.resnet.ResNet50(
include_top=False,
weights='imagenet',
input_shape=(224,224,3),
pooling='avg',
),
keras.layers.Dense(num_classes, activation='softmax')
])텐서플로우 데이터셋에서 불러온 데이터에 하나는 apply_normalize_on_dataset()에서 with_aug를 False로 주어 augmentation이 적용되지 않도록 하고, 다른 하나는 True로 주어 augmentation이 적용되도록 한다.
(ds_train, ds_test), ds_info = tfds.load(
'stanford_dogs',
split=['train', 'test'],
as_supervised=True,
shuffle_files=True,
with_info=True,
)
ds_train_no_aug = apply_normalize_on_dataset(ds_train, with_aug=False)
ds_train_aug = apply_normalize_on_dataset(ds_train, with_aug=True)
ds_test = apply_normalize_on_dataset(ds_test, is_test=True)이제 두 개 모델에 각각 augmentation이 적용된 데이터셋과 적용되지 않은 데이터셋을 학습시키고, 검증을 진행한다.
아래 학습은 EPOCH=20으로 진행시 GPU 기반으로 3~4시간 가량의 시간이 소요됩니다. Augmentation 적용 효과를 명확히 검증하기 위해서는 최소 이정도의 학습이 진행되어야 하지만, 원활한 학습 진행을 위해서 EPOCH=3 정도로 진행해 보기를 권합니다. 하지만 실제 프로젝트 단계에서는 꼭 충분한 학습이 진행되어야 합니다.
#EPOCH = 20 # Augentation 적용 효과를 확인하기 위해 필요한 epoch 수
EPOCH = 3
resnet50.compile(
loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.SGD(lr=0.01),
metrics=['accuracy'],
)
history_resnet50_no_aug = resnet50.fit(
ds_train_no_aug, # augmentation 적용하지 않은 데이터셋 사용
steps_per_epoch=int(ds_info.splits['train'].num_examples/16),
validation_steps=int(ds_info.splits['test'].num_examples/16),
epochs=EPOCH,
validation_data=ds_test,
verbose=1,
use_multiprocessing=True,
)aug_resnet50.compile(
loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.SGD(lr=0.01),
metrics=['accuracy'],
)
history_resnet50_aug = aug_resnet50.fit(
ds_train_aug, # augmentation 적용한 데이터셋 사용
steps_per_epoch=int(ds_info.splits['train'].num_examples/16),
validation_steps=int(ds_info.splits['test'].num_examples/16),
epochs=EPOCH,
validation_data=ds_test,
verbose=1,
use_multiprocessing=True,
)훈련 과정을 시각화 해봅시다.
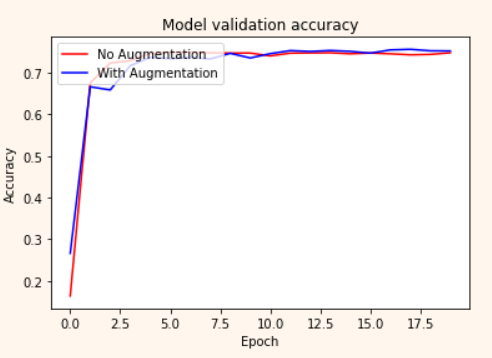
plt.plot(history_resnet50_no_aug.history['val_accuracy'], 'r')
plt.plot(history_resnet50_aug.history['val_accuracy'], 'b')
plt.title('Model validation accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['No Augmentation', 'With Augmentation'], loc='upper left')
plt.show()확대 기능을 활용하여 조금 더 확대
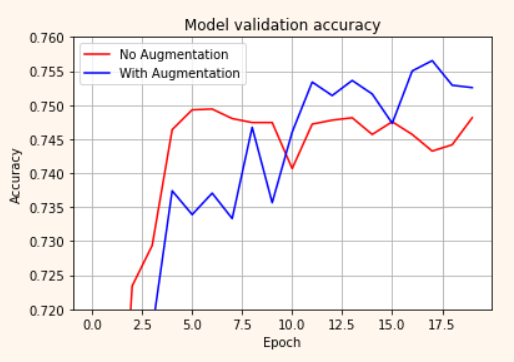
plt.plot(history_resnet50_no_aug.history['val_accuracy'], 'r')
plt.plot(history_resnet50_aug.history['val_accuracy'], 'b')
plt.title('Model validation accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['No Augmentation', 'With Augmentation'], loc='upper left')
plt.grid(True)
plt.ylim(0.50, 0.80) # 출력하고자 하는 Accuracy 범위를 지정해 주세요.
#plt.ylim(0.72, 0.76) # EPOCH=20으로 진행한다면 이 범위가 적당합니다.
plt.show()참고로, EPOCH=20으로 수행해 본 두 모델의 훈련 과정 시각화한 내용은 아래 그림과 같다. Augmentation 적용한 경우가 보다 천천히 학습되지만, EPOCH 10을 전후해서 aug_resnet50의 accuracy가 더 높게 형성되는 것을 확인할 수 있다.
4-5. 심화 기법 - (1) CutMix Augmentation
지금부터는 조금 더 복잡한 augmentation 방법을 알아볼 텐데, 그 첫 번째는 CutMix augmentation 이다.
CutMix는 네이버 클로바(CLOVA)에서 발표한 CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features 에서 제안된 방법이다. 이름인 CutMix를 보고 유추할 수 있듯이 이미지 데이터를 자르고 섞는다고 생각할 수 있다.
아래 표에서 ResNet-50 컬럼은 우리가 일반적으로 사용해왔던 방식을 나타낸다. Mixup 은 특정 비율로 픽셀별 값을 섞는 방식이고, Cutout 은 이미지를 잘라내는 방식이다. CutMix는 Mixup과 비슷하지만 일정 영역을 잘라서 붙여주는 방법이다. 차에 비유하면 블렌딩 같은 방법인 셈이다.
두 번째 링크인 Chris Deotte's CutMix and MixUp on GPU/TPU에서는 캐글 그랜드마스터인 Chris Deotte가 구현한 CutMix와 Mixup을 확인할 수 있다. 남은 스텝에서 CutMix와 Mixup을 구현하면서 참고하면 된다. 참고로 캐글에서 직ㅁ 참가하고 있는 대회와 비슷한 태스크의 경진대회가 있는 경우, 다른 사람들이 적용한 방법들을 찾아보는 것도 인사이트를 얻는 데 유용하다.
CutMix는 이미지를 섞는 부분과 섞은 이미지에 맞추어 라벨을 섞는 부분을 포함한다. 이제 한 부분씩 구현해 보겠다.
1) 이미지 섞기
가장 먼저 두 개의 이미지를 섞어주는 것부터 생각해 봐야 한다. 배치 내의 이미지를 두 개 골라서 섞어준다. 이때 이미지에서 잘라서 섞어주는 영역을 바운딩 박스(bounding box)라고 부른다.
예시를 위해 훈련데이터셋에서 이미지 2개를 가져와 보았다.
아래 코드 블록은 바운딩 박스의 위치를 랜덤하게 뽑고 이를 잘라내서 두 개의 이미지를 섞어주는 함수를 만드는 과정을 나타냈다. 이미지를 텐서로 만들어 텐서플로우 연산을 사용해 보자. 이때 이미지는 tfds에서 한 장을 뽑아서 사용하면 된다.
import matplotlib.pyplot as plt
# 데이터셋에서 이미지 2개를 가져온다.
for i, (image, label) in enumerate(ds_train_no_aug.take(1)):
if i == 0:
image_a = image[0]
image_b = image[1]
label_a = label[0]
label_b = label[1]
break
plt.subplot(1,2,1)
plt.imshow(image_a)
plt.subplot(1,2,2)
plt.imshow(image_b)
plt.show()두 개의 이미지를 얻었다. 이 중 첫번째 이미지 a를 바탕 이미지로 하고 거기에 삽입할 두번째 이미지 b가 있을 때, a에 삽입될 영역의 바운딩 박스의 위치를 결정하는 함수를 먼저 구현한다.
이번 노드에서는 이미지 a, b가 모두 (224,224)로 resize되어 두 이미지의 width, height가 같은 경우이지만, CutMix의 공식 repo에서는 width, height가 다르더라도 가변적으로 적용할 수 있도록 구현되어 있기 때문에, 임의의 이미지 사이즈에 대해서도 유연하게 대응이 가능하도록 구현을 시키는 게 좋다.
def get_clip_box(image_a, image_b):
# image.shape = (height, width, channel)
image_size_x = image_a.shape[1]
image_size_y = image_a.shape[0]
# get center of box
x = tf.cast(tf.random.uniform([], 0, image_size_x), tf.int32)
y = tf.cast(tf.random.uniform([], 0, image_size_y), tf.int32)
# get width, height of box
width = tf.cast(image_size_x*tf.math.sqrt(1-tf.random.uniform([], 0, 1)), tf.int32)
height = tf.cast(image_size_y*tf.math.sqrt(1-tf.random.uniform([], 0, 1)), tf.int32)
# clip box in image and get minmax bbox
x_min = tf.math.maximum(0, x-width//2)
y_min = tf.math.maximum(0, y-height//2)
x_max = tf.math.minimum(image_size_x, x+width//2)
y_max = tf.math.minimum(image_size_y, y+width//2)
return x_min, y_min, x_max, y_max
x_min, y_min, x_max, y_max = get_clip_box(image_a, image_b)
print('x : ', x_min, x_max)
print('y : ', y_min, y_max)바탕이미지 image_a에서 바운딩 박스 바깥쪽 영역을, 다른 이미지 image_b에서 바운딩 박스 안쪽 영역을 가져와서 합치는 함수를 구현하는 과정이다.
# mix two images
def mix_2_images(image_a, image_b, x_min, y_min, x_max, y_max):
image_size_x = image_a.shape[1]
image_size_y = image_a.shape[0]
middle_left = image_a[y_min:y_max, 0:x_min, :] # image_b의 왼쪽 바깥 영역
middle_center = image_b[y_min:y_max, x_min:x_max, :] # image_b의 안쪽 영역
middle_right = image_a[y_min:y_max, x_max:image_size_x, :] # image_b의 오른쪽 바깥 영역
middle = tf.concat([middle_left, middle_center, middle_right], axis=1)
top = image_a[0:y_min, :, :]
bottom = image_a[y_max:image_size_y, :, :]
mixed_img = tf.concat([top, middle, bottom], axis=0)
return mixed_img
mixed_img = mix_2_images(image_a, image_b, x_min, y_min, x_max, y_max)
plt.imshow(mixed_img.numpy())
plt.show()2) 라벨 섞기
이미지를 섞었다면 라벨도 이에 맞게 섞어 줘야 한다. 그림에서 볼 수 있듯이, 우리가 강아지와 고양이의 이미지를 섞었다면 라벨 또한 적절한 비율로 섞어야 함을 알 수 있다.
CutMix에서는 면적에 비례해서 라벨을 섞어준다. 섞인 이미지의 전체 이미지 대비 비율을 계산해서 두 가지 라벨의 비율로 더해준다. 예를 들어 A 클래스를 가진 원래 이미지 image_a와 B 클래스를 가진 이미지 image_b를 섞을 때, image_a를 0.4만큼 섞었을 경우, 0.4만큼의 클래스 A, 0.6만큼의 클래스 B를 가지도록 해준다. 이 때 라벨 벡터는 보통 클래스를 표시하듯 클래스 1개만 1의 값을 가지는 원-핫 인코딩이 아니라 A와 B 클래스에 해당하는 인덱스에 각각 0.4, 0.6을 배분하는 방식을 사용한다.
위에서 섞인 이미지 두 가지에 대해서 라벨을 만들 때 적절한 비율로 라벨을 합쳐주는 함수를 구현해 보자.
# mix two labels
def mix_2_labels(label_a, label_b, x_min, y_min, x_max, y_max, num_classes=120):
image_size_x = image_a.shape[1]
image_size_y = image_a.shape[0]
mixed_area = (x_max - x_min)*(y_max - y_min)
total_area = image_size_x*image_size_y
ratio = tf.cast(mixed_area/total_area, tf.float32)
if len(label_a.shape)==0:
label_a = tf.one_hot(label_a, num_classes)
if len(label_b.shape)==0:
label_b = tf.one_hot(label_b, num_classes)
mixed_label = (1-ratio)*label_a + ratio*label_b
return mixed_label
mixed_label = mix_2_labels(label_a, label_b, x_min, y_min, x_max, y_max)
mixed_label이제 거의 다 준비되었다!! 위에서 구현한 두 함수 mix_2_images()와 mix_2_label()을 활용하여 배치 단위의 cutmix() 함수를 구현하면 된다.
def cutmix(image, label, prob=1.0, batch_size=16, img_size=224, num_classes=120):
mixed_imgs = []
mixed_labels = []
for i in range(batch_size):
image_a = image[i]
label_a = label[i]
j = tf.cast(tf.random.uniform([],0, batch_size),tf.int32)
image_b = image[j]
label_b = label[j]
x_min, y_min, x_max, y_max = get_clip_box(image_a, image_b)
mixed_imgs.append(mix_2_images(image_a, image_b, x_min, y_min, x_max, y_max))
mixed_labels.append(mix_2_labels(label_a, label_b, x_min, y_min, x_max, y_max))
mixed_imgs = tf.reshape(tf.stack(mixed_imgs), (batch_size, img_size, img_size, 3))
mixed_labels = tf.reshape(tf.stack(mixed_labels), (batch_size, num_classes))
return mixed_imgs, mixed_labels4-6. 심화 기법 - (2) Mixup Augmentation
Mixup은 앞에서 보여드린 CutMix보다 간단하게 이미지와 라벨을 섞어준다. 아래 참고자료는 앞에서 본 CutMix 비교표에서 "Mixup"이라는 방법이 제안된 논문이다. 두 개 이미지의 픽셀별 값을 비율에 따라 섞어주는 방식으로 CutMix보다 구현이 간단하다고 볼 수 있다.
두 이미지 쌍을 섞을 비율은 일정한 범위 내에서 랜덤하게 뽑고, 해당 비율 값에 따라 두 이미지의 픽셀별 값과 라벨을 섞어주면 된다.
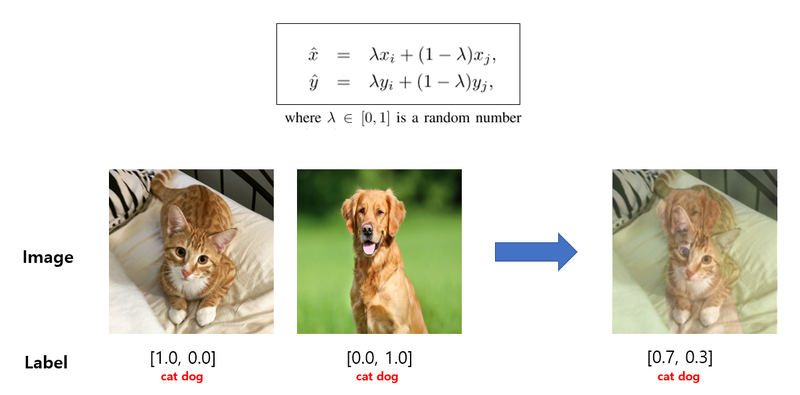
# function for mixup
def mixup_2_images(image_a, image_b, label_a, label_b):
ratio = tf.random.uniform([], 0, 1)
if len(label_a.shape) == 0:
label_a = tf.one_hot(label_a, num_classes)
if len(label_b.shape) == 0:
label_b = tf.one_hot(label_b, num_classes)
mixed_image = (1-ratio)*image_a + ratio*image_b
mixed_label = (1-ratio)*label_b + ratio*label_b
return mixed_image, mixed_image
mixed_img, mixed_label = mixup_2_images(image_a, image_b, label_a, label_b)
plt.imshow(mixed_img.numpy())
plt.show()
print(mixed_label)그러면 위에서 구현한 함수를 활용하여 배치 단위의 mixup() 함수를 구현해 보자.
def mixup(image, label, prob=1.0, batch_size=16, img_size=224, num_classes=120):
mixed_imgs = []
mixed_labels = []
for i in range(batch_size):
image_a = image[i]
label_a = label[i]
j = tf.cast(tf.random.uniform([],0,batch_size), tf.int32)
image_b = image[j]
label_b = label[j]
mixed_img, mixed_label = mixup_2_images(image_a, image_b, label_a, label_b)
mixed_imgs.append(mixed_img)
mixed_labels.append(mixed_label)
mixed_imgs = tf.reshape(tf.satac(mixed_imgs), (batch_size, img_size, img_size, 3))
mixed_labels = tf.reshape(tf.stack(mixed_labels), (batch_size, num_classes))
return mixed_imgs, mixed_labels이로써 Going Deeper에 나와 있는 Image Augmentation에 대한 내용을 모두 정리해 보았다. 이제 남은 건 프로젝트~~
