
는 아시는 분 많을까봐 두려워서 적지는 못했습니다 ㅎㅎ
언제나 기술을 배우고 사용할 때는 사실 쓰라고 하면 사용할 수는 있습니다.
다만, 우리는 각각의 기술의 장단점들 중에서, 장점이 제일 빛나는 것을 선택하게 되죠.
왜 갑자기 이렇게 서론이 기냐고요?
... 할 말 없으니깐,,,,, 는 구라고
사실 비밀번호에 한글은 들어가도 됩니다.

팩트이긴 합니다.
다만 우리는 살면서 비밀번호로 한글을 허용하는 곳을
한번도 보지 못했기 때문,,,
하지만 우리 마음속 지적 호기심을 최대한 발동시켜보죠!
한번 브루트포스적(?) 접근을 한번 해보죠!
안든다고요?
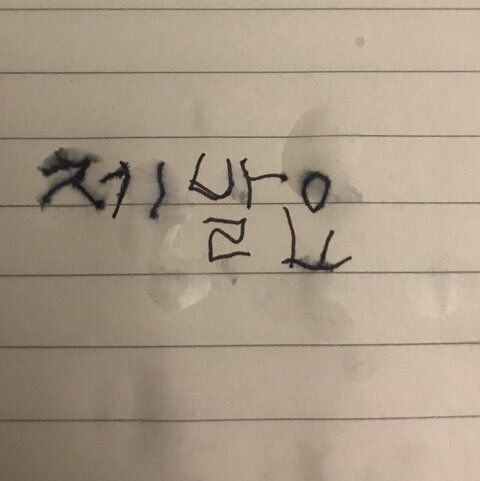
영어 + 숫자 + 한글을 사용해 비밀번호를 만든다면
더 많은 경우의 수가 나와 보안이 더 좋지 않을까요?
영어+숫자+특수문자로만 비밀번호를 만들 경우
_ _ _ _ _ _ _ _
8자리의 비밀번호를 만들어본다고 해보죠.
- 영어 알파벳: 52
- 대문자 (A-Z): 26개
- 소문자 (a-z): 26개
- 숫자: 10
- 0-9: 10개
- 특수문자: 32
- ! @ # $ % ^ & * ( ) _ + - = { } [\ ] \ | : ; " ' < > , . ? / ~ `: 32개
비밀번호 한 칸당 94 가지의 경우의 수가 가능하니,
나올 수 있는 경우의 수는 94^8 입니다.
한글을 포함해 비번을 만들 경우
_ _ _ _ _ _ _ _
8자리의 비밀번호를 만들어본다고 해보자.
- 영어 알파벳: 52
- 대문자 (A-Z): 26개
- 소문자 (a-z): 26개
- 숫자: 10
- 0-9: 10개
- 특수문자: 32
- ! @ # $ % ^ & * ( ) _ + - = { } [\ ] \ | : ; " ' < > , . ? / ~ `: 32개
- 한글 (자음+모음만) : 26
- ㄱ, ㄲ, ㄴ, ㄷ, ㄸ, ㄹ, ㅁ, ㅂ, ㅃ, ㅅ, ㅆ, ㅇ, ㅈ, ㅉ, ㅊ, ㅋ, ㅌ, ㅍ, ㅎ (자음: 19개)
- ㅏ, ㅐ, ㅑ, ㅒ, ㅓ, ㅔ, ㅕ (모음: 7개)
즉, 한칸에 들어갈 수 있는 경우의 수는 120가지입니다.
그렇다면 8자리에 나올 수 있는 비밀번호의 가지 수는 총 120^8 가지입니다.
94^8 vs 120^8? 한글 승!
한글 그냥 위대해버리네

는 무슨 ㅎㅎ
위에서 나온 결론대로 라면 비밀번호에
한국어를 사용하는 게 더 보안에 좋긴 합니다
8자리라면!
서론에서 모든 기술에는 장단점이 있고,
이 기술 중 장점이 더 빛나고 단점이 더 감춰치는 기술을
선택해야 한다는 말을 기억하시는 가요?
한국어를 비밀번호에 포함하는 선택은 장점만 가득해보이지만
장점보다는 단점이 부각되기 때문에 이 선택을 하지 않게되는 거라고 생각할 수 있습니다.
한국어를 포함하는 경우
장점
- 칸마다 다양한 경우의 수가 나온다.
단점
- 사용자가 비밀번호를 입력하는 게 귀찮다.
- 비밀번호 한 칸의 경우의 수를 늘리는 것보다,
그냥 비밀번호 길이를 늘리는 게 보안 향상이 더 쉽고, 강력하다.
단적인 예시를 한번 드려볼까요?
qpwo1489$#*)v
입력하기에 그닥 어렵지 않을 겁니다.
익숙하기도 하고, 기존의 자판에서 shift 만 더 누르면
바로바로 타이핑이 되기 때문이죠.
qㅑㅐpㅇwㅁo1489$#a*)ㄹ ->
이번에는 이걸 한번 해보신다고 생각해보죠.
영어 -> 한글 -> 영어 -> 한글 -> 영어 -> 한글
한영 변환만 5번,,, 귀찮죠?
심지어 이걸 핸드폰으로 한다고 생각하면... (어우🤮)
그래도 보안이 더 뛰어나지 않겠냐고요? 뭐 틀린 말은 아니다만,
저렇게 한글을 쓰지 않고도 보안을 더 쉽게 강력하게 만들 수 있습니다.
qpwo1489$#*)v 의 길이는 13,
qㅑㅐpㅇwㅁo1489$#a*)ㄹ 의 길이는 20 입니다.
첫 번째 비밀번호의 길이를 22까지 연장시켜 봤습니다.
`qpwo1489$#*)vppppppppp
qㅑㅐpㅇwㅁo1489$#a*)ㄹ vs qpwo1489$#*)vppppppppp
보안은 어느 쪽이 더 우세할까요?
후자입니다.
겉보기에는 전자가 더 복잡해보이니, 전자가 더 보안이 우수해 보이지만
결국 사람의 눈에만 복잡해보일 뿐이지, 공격자에게는 더 단순한 코드입니다.
위 비밀번호의 문자 하나하나를 빈칸이라고 생각해본다면
나올 수 있는 경우의 수는 각각 다음과 같습니다.
120^20 과 94^22
뭐가 더 클까요?
정답은 94^22 입니다!
120^20 = 8.9161004485...×10338.9161004485...×10^33 (대략적인 값입니다)
94^22 = 4.4405905063...×10354.4405905063...×10^35 (대략적인 값입니다)즉, 저는 한글을 안 쓰고도 2칸만 늘리면서
한글을 쓰는 불편함을 전혀 감수하지 않았습니다.
그 외에 이유
위의 이유만이 다는 아닙니다!
사실 찾아보면, 많은 사람들이 이 글의 주제와 같은 질문을 하고,
생각보다 인코딩에 대한 이야기가 많습니다.
어떤 시스템에서 (특히 레거시) 만약
ASCII (영어+숫자+특수문자) 만 사용한다면, 한글을 비밀번호로 입력한 순간 재앙이 될 것이라는 것,,,
이러한 이유도 합당한 이유이기도 하지만,
요즘 시대에 와닿지는 않는 이유이기도 해서 위에 넣지는 않았다만
인코딩 이슈도 있다! 하지만 요즘에는 그닥!
이라는 정도만 알고 넘어가시면 되겠습니다 😃
결론
뭐 사실 우리가 그 동안 비밀번호에 대해 지켜왔던,
그리고 앞으로 지킬 규칙에 대해서는 바뀔 건 없다만,
이거 하나를 배워 갈 수 있죠.
안하는 데는 이유가 있다!
쓰던 데로 쓰자!

8개의 댓글


'눈에 안 보이기 때문'도 이유로 가능할 것 같네요. 예를 들어 html의 input에 password를 넣는다고 생각해보면, 입력된 값이 모두 마스킹되므로 내가 한글로 쳤는지 영어로 쳤는지 알 수가 없습니다. 결국 사용자 경험에 있어서 재시도 횟수가 늘 수 밖에 없습니다. 입력되는 비밀번호를 계속 보이게 할 수도 없는 노릇이기도 합니다.

저는 반대로 인코딩문제가 엄청 크다고 생각합니다.
alphanumeric characters 로 제한을 두는 이유는, 모든 문자를 입력 가능한 경우엔 유니코드의 조합으로 표현되는 문자를 처리하기가 힘듭니다!
☹️ = (U+2639 + U+FE0F), 👨🏭 = (U+1F468 + U+200D + U+1F3ED), y̖̠͍̘͇͗̏̽̎͞ = (U+0079 + U+0316 + U+0320 + U+034D + U+0318 + U+0347 + U+0357 + U+030F + U+033D + U+030E + U+035E)
이런식으로, 8자리 비밀번호를 요구하는데 입력되는 문자에 제한을 두지 않게되면
DB 데이터타입이 가변길이 문자열이 되어야하고 제가 알기로 한 문자를 표현하는데 최대로 사용할 수 있는 조합의 길이에는 제한이 없는거로 알고있습니다.
글로벌 기준으로 생각하면 더 명확해지는데요, 한글은 비교적 전산화를 빨리 받아들인 국가인 덕택에 한글 자모의 모든 조합을 유니코드에 등록할 수 있었던 특혜를 누리고 있습니다.
하지만 태국어의 경우 กำ 은 'ก' (ko kai, U+0E01)과 'ำ' (am, U+0E33) 결합으로 이루어지기 때문에,
한 글자 == 하나의 유니코드 라는 연관관계가 성립하지 않습니다.
관련해서 더 찾아보고 싶으시다면, Unicode 와 l18n, extended grapheme 쪽을 찾아보시면 더 다양한 예시를 볼 수 있을꺼에요.
역시.. 언제나 한 발 더 가는 멋진 개발자시네요 한 수 배워갑니다.