
- SQL에는 쿼리를 컬럼으로, 인덱스 번호별로 데이터를 출력하는데 별도의 index번호가 없지만 함수를 통해 인덱스 번호를 주고 원하는 값만 출력할 수 있다.
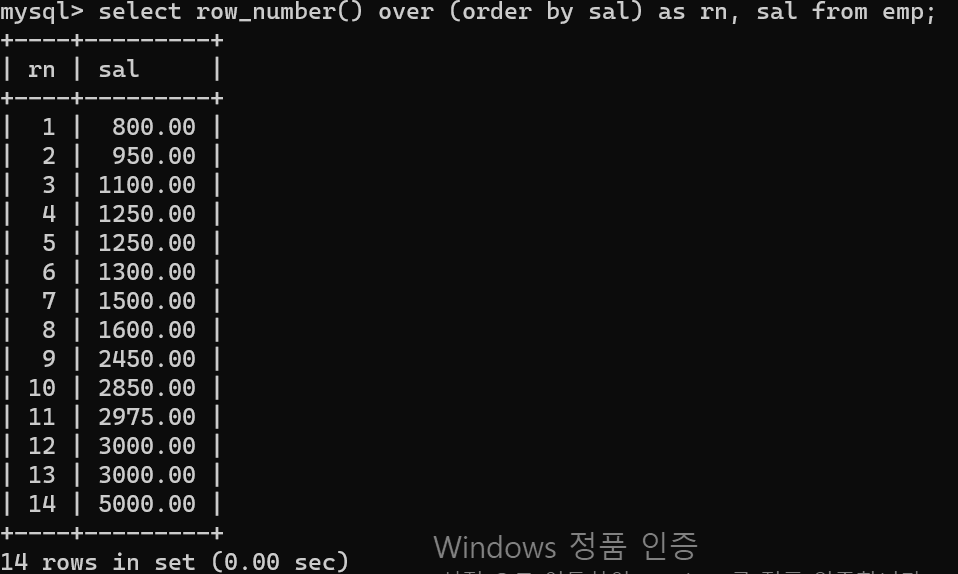
- Row_number() over(order by columns1)을 통해 기준 정렬을 설정하고, 해당 정렬 순서대로 쿼리의 row번호를 준다.
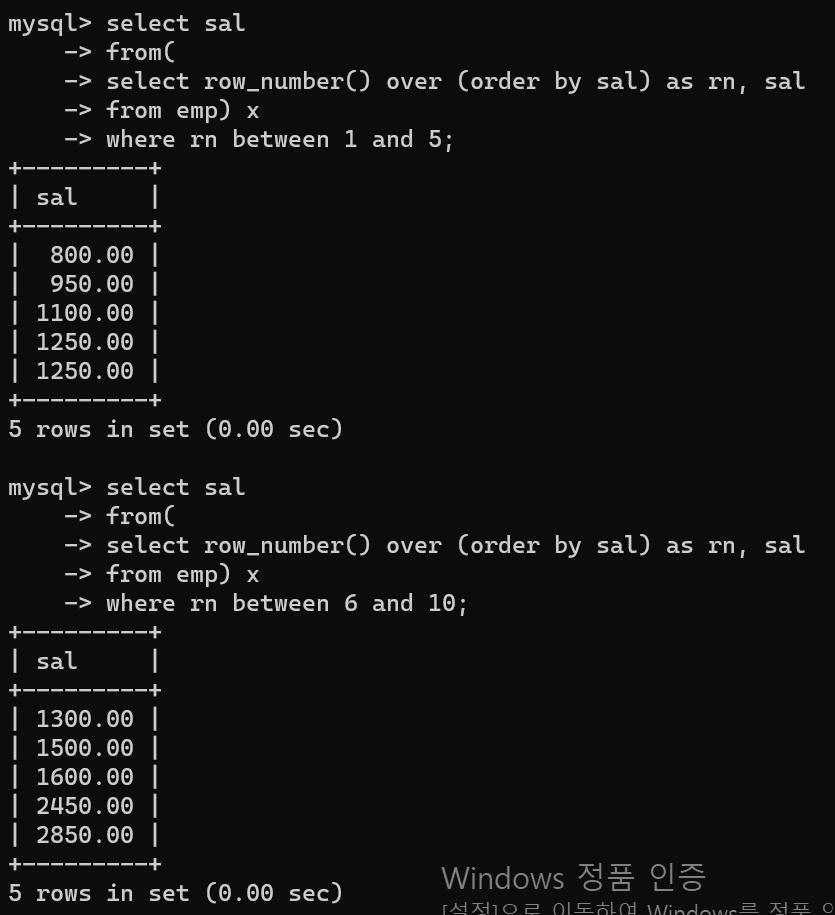
- 부여한 번호를 하나의 쿼리로 사용해서 where조건문을 통해 원하는 부분의 데이터를 뽑을 수 있다.

- 위 문제와 연결되는 문제로서 index에서 원하는 번호만 출력할 때 사용한다.
- 해당 문제에서는 홀수 번호에 해당하는 사원의 데이터만 출력한다.
- 먼저 기본적인 데이터를 14개의 행을 가진 이름을 가진 테이블이다. 여기서
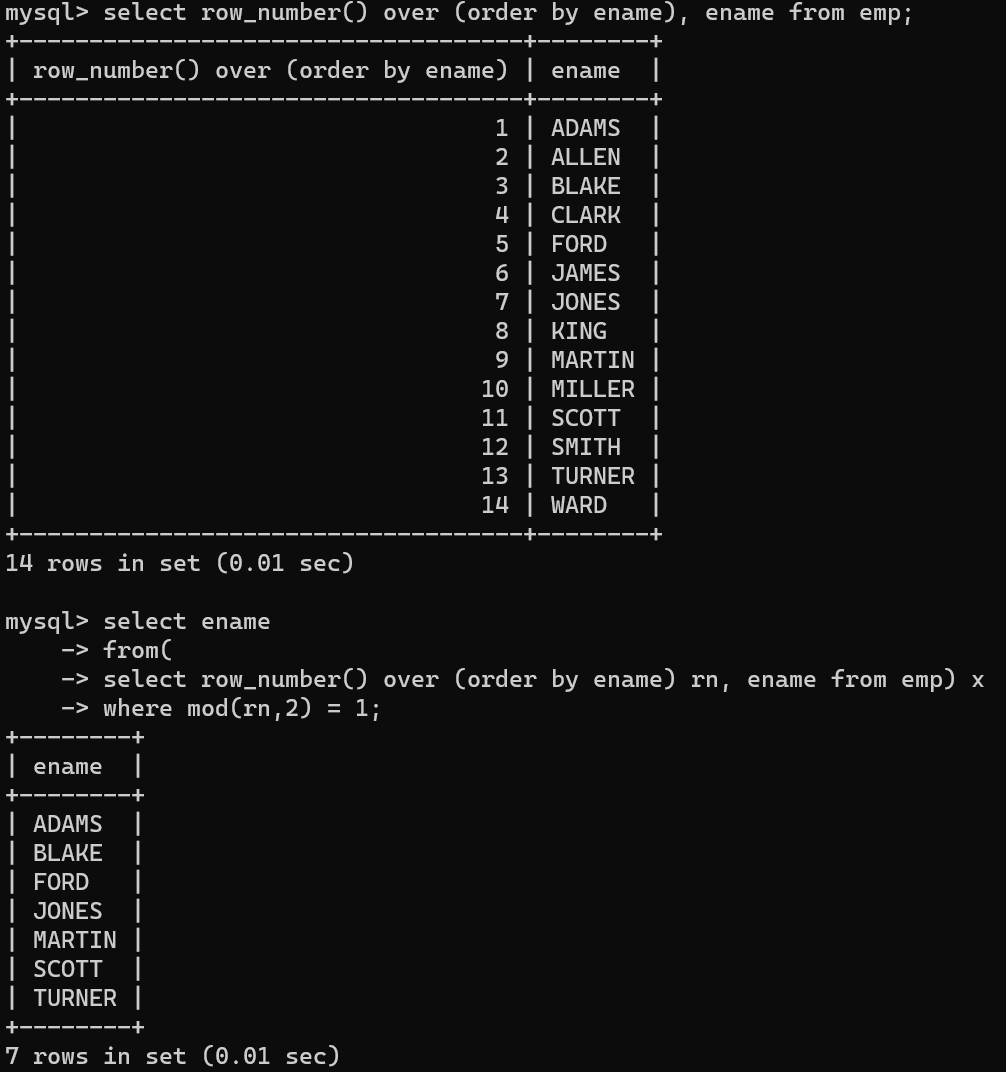
- row_number()over를 사용해서 쿼리의 번호를 넣고 메인 select절에서 where에 조건문을 넣음으로써 홀수 번호에 해당하는 사원의 이름만 출력했다.

- 조인을 사용할 때 조건문을 다양하게 쓰는 방법이다.
- 두 개의 테이블에서 detp와 emp에서 emp테이블에서는 deptno번호가 10, 20인 데이터만 뽑고, dept에서는 10~40까지의 데이터를 뽑았다.
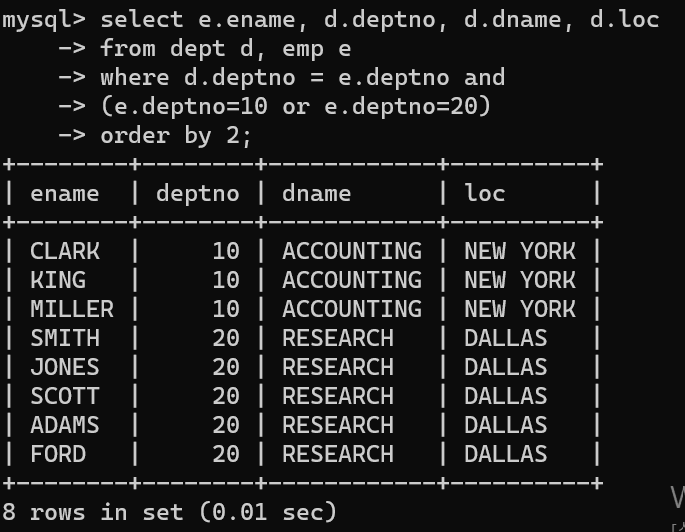
- 두 개의 테이블은 뽑아서 조건문을 넣었지만, dept테이블의 30, 40의 사무실 번호 데이터가 빠져있다.
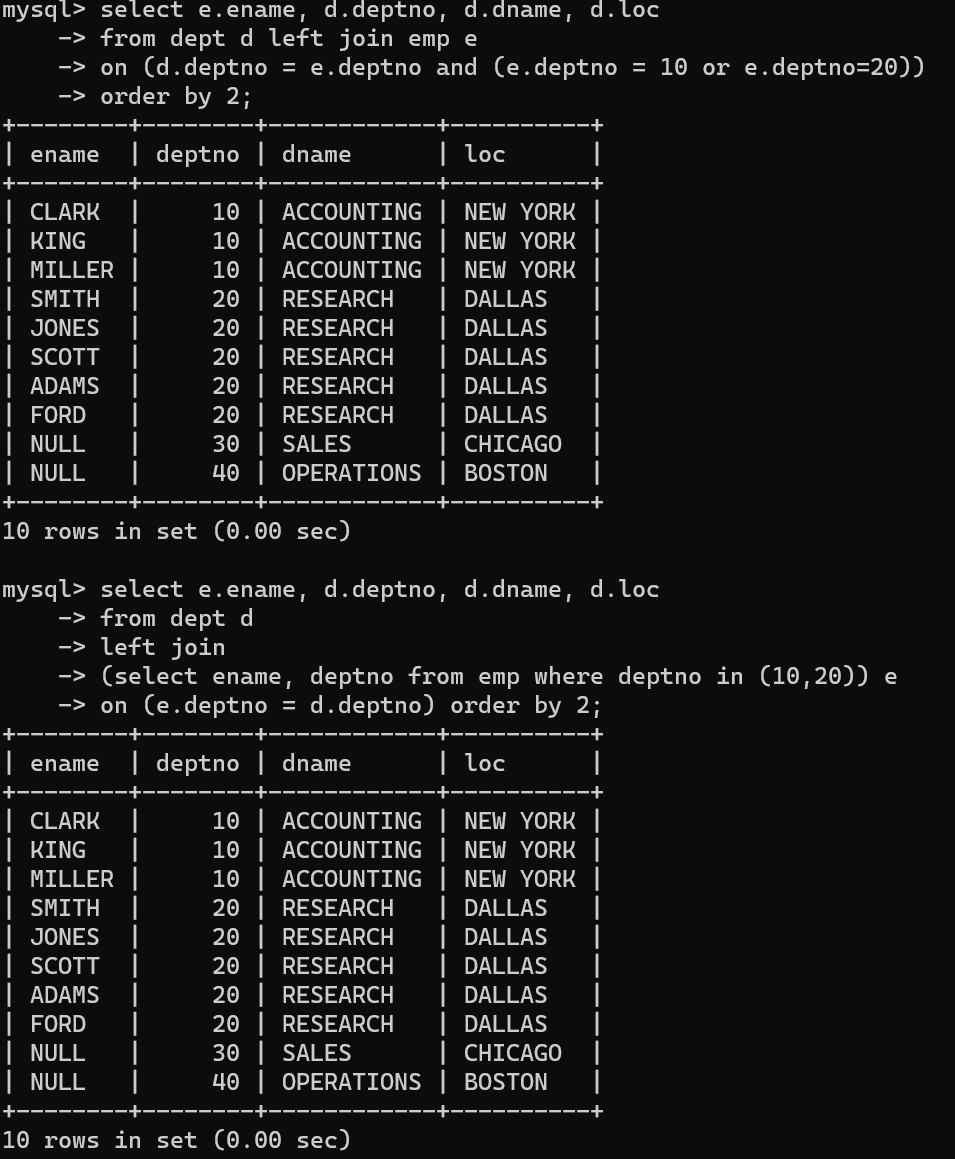
- 해당 문제를 해결하기 위한 두 가지 방법이 있다.
- 먼저 left join에서 on 조건문에 emp테이블의 사무실 번호 10과 20이라는 조건을 or로 묶거나,
- 두번째로, join할 때 select문으로 묶고 select문 안에서 조건을 넣어서 사무실 번호가 10과 20에 해당하는 데이터만 뽑아서 합치면 된다.

- 이번에는 순위를 넣고 상위 n개의 데이터만 뽑는 방법이다.
- 물론 order by와 limit함수를 사용해서도 할 수 있지만, 순위를 넣으면서 하기에 적합한 방법이다.
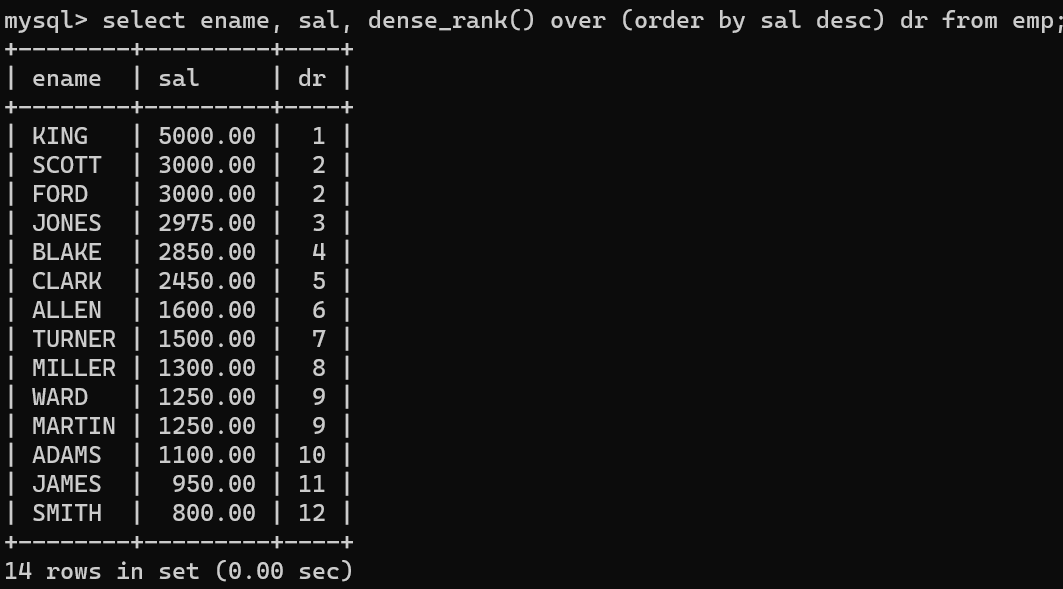
- 먼저 dense_rank 함수를 통해 기준열을 정하고 기준열에 따른 순위를 넣을 수 있다.
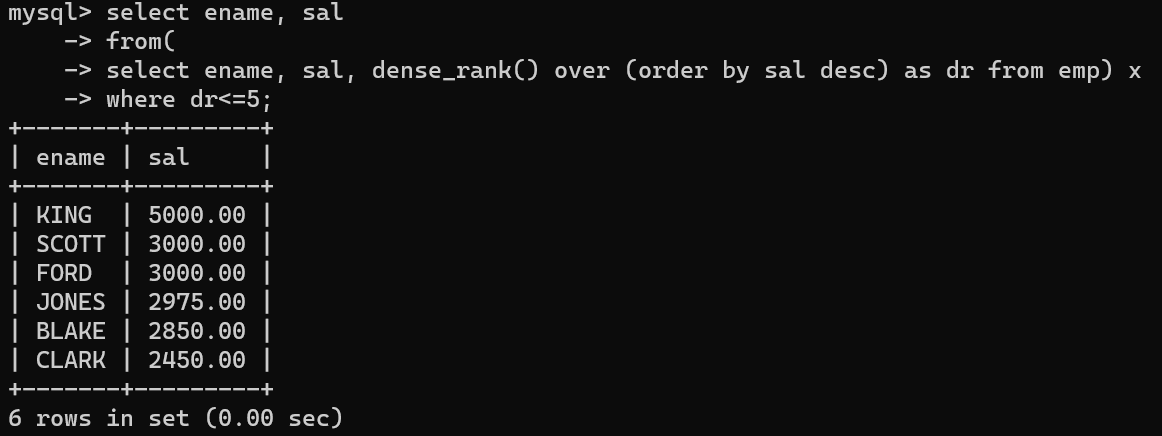
- 메인 select절에서 순위를 넣은 쿼리를 조건문으로 사용해서 상위 혹은 하위 몇개의 데이터를 뽑을 수 있다.

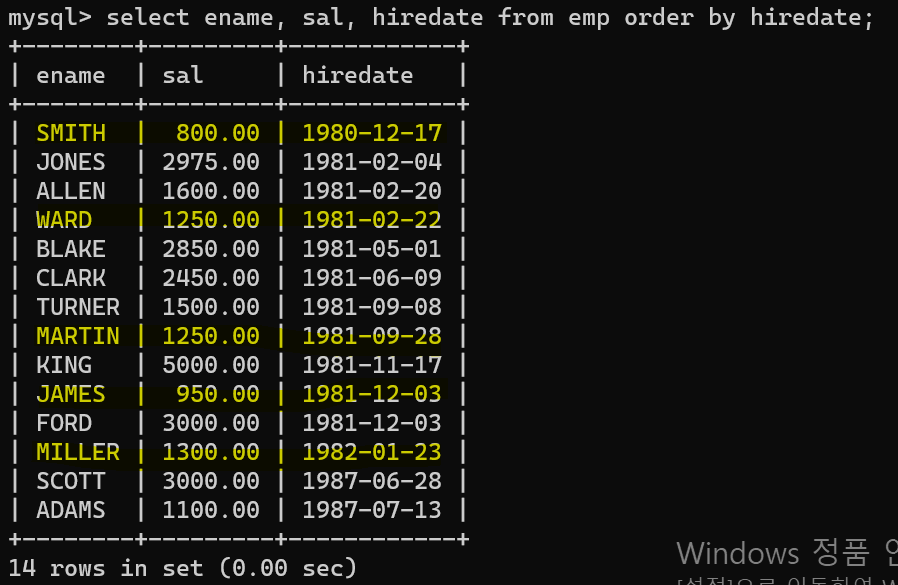
- 이번에는 행을 이전, 이후 행을 조작하는 방법을 사용했다.
- 고용된 날짜를 기준으로 이후 입사한 사람보다 월급이 낮은 데이터를 뽑았다.
- 해당 데이터 기준으로 Smith, Ward, Martin, James, Miller 5명이 이후 입사한 사원보다 봉급이 낮다.
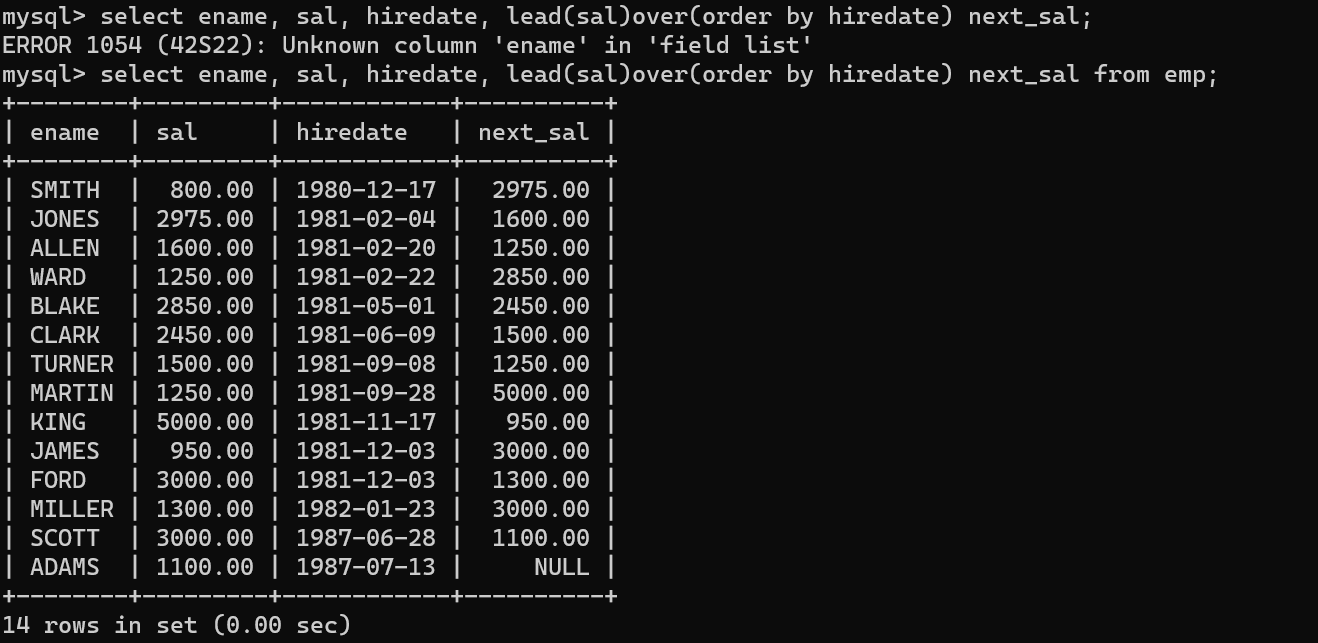
- 해당 문제를 해결하기 위해서 Lead(column1) over (order by column2) 문법을 사용했다.
- 해당 문법은 over문에서 정렬한 데이터 리스트에서 lead문 안에 데이터의 다음 행 데이터를 불러오는 함수이다. lead(column, 2)식으로 두번 째 이후 데이터도 뽑을 수 있다.
- 위와 같이 데이터를 뽑고
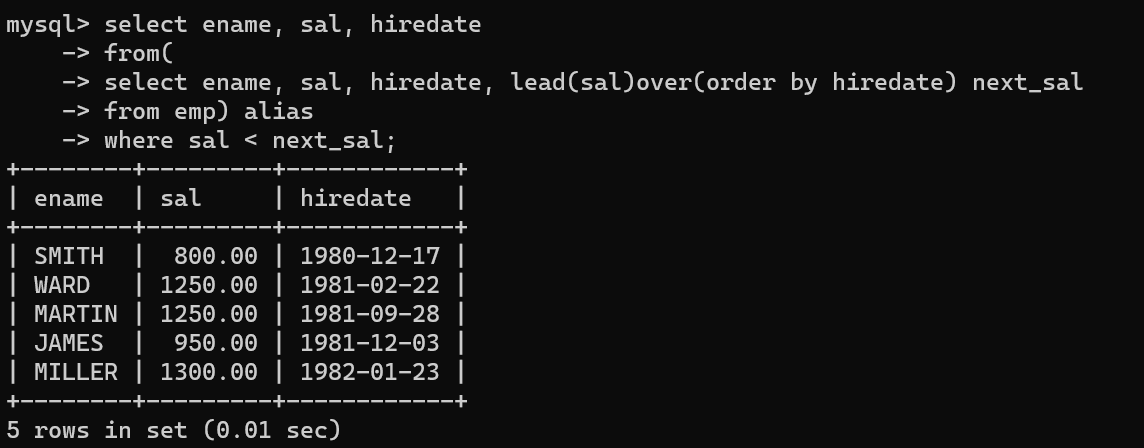
- sal과 이후 봉급을 조건을 통해 5명의 사람에 대한 데이터를 뽑을 수 있다.
- 이번에는 현재 행을 기준으로 특정 쿼리의 앞뒤 행을 출력하는 SQL문을 작성했다.
- 문제에서는 사원을 기준으로 자신보다 다음으로 높은 급여, 낮은 급여를 출력하는 데이터를 출력해야했다.
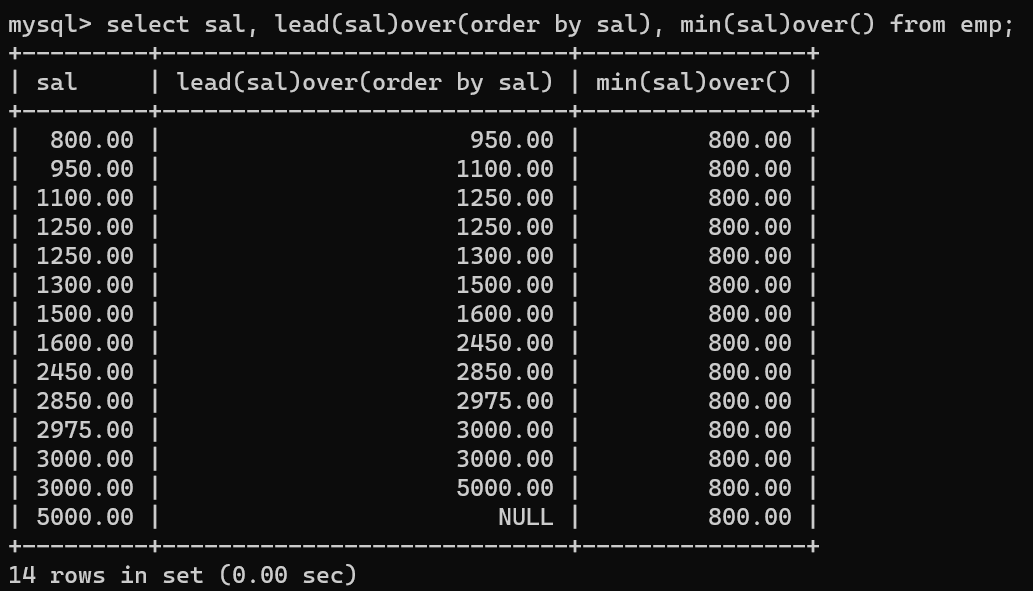
- 먼저 lead(sal)over(order by sal)을 통해 자신의 급여보다 높은 즉 다음 행을 뽑는 쿼리를 만드는데, 마지막 행의 경우 Null값이 나온다.
- 이후 coalesce문을 통해 Null값을 대체하기 위해 최소값을 출력하는 min(sal)over()도 추가한다.
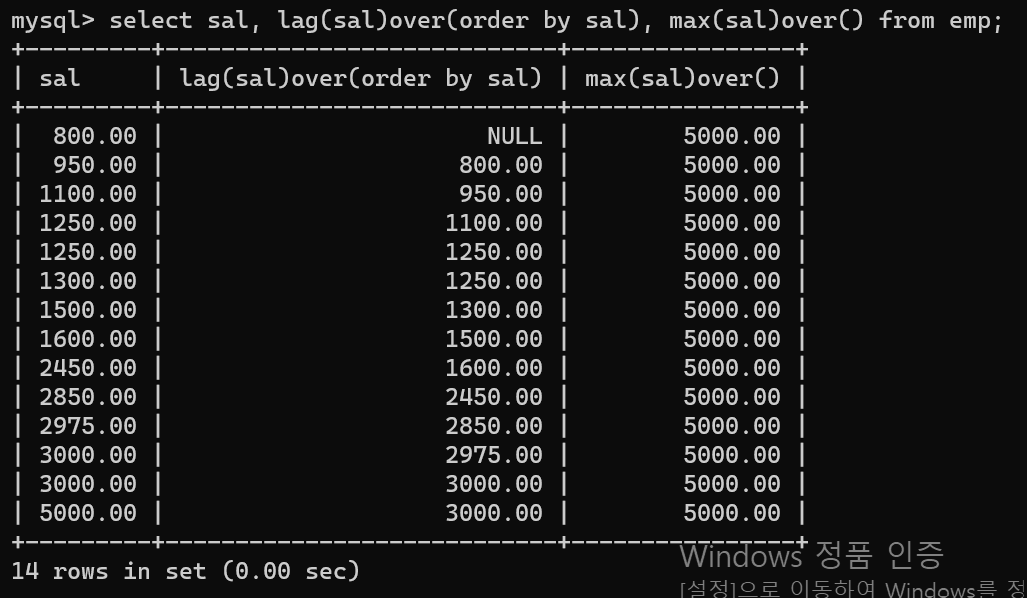
- 그리고 다음으로 이전 행 즉 자신보다 낮은 급여를 출력하는 쿼리를 lag(sal)over(order by sal)를 통해 출력하고, 처음 값이 Null값이기 때문에 최대값을 출력하는 max(sal)over()도 같이 출력한다.
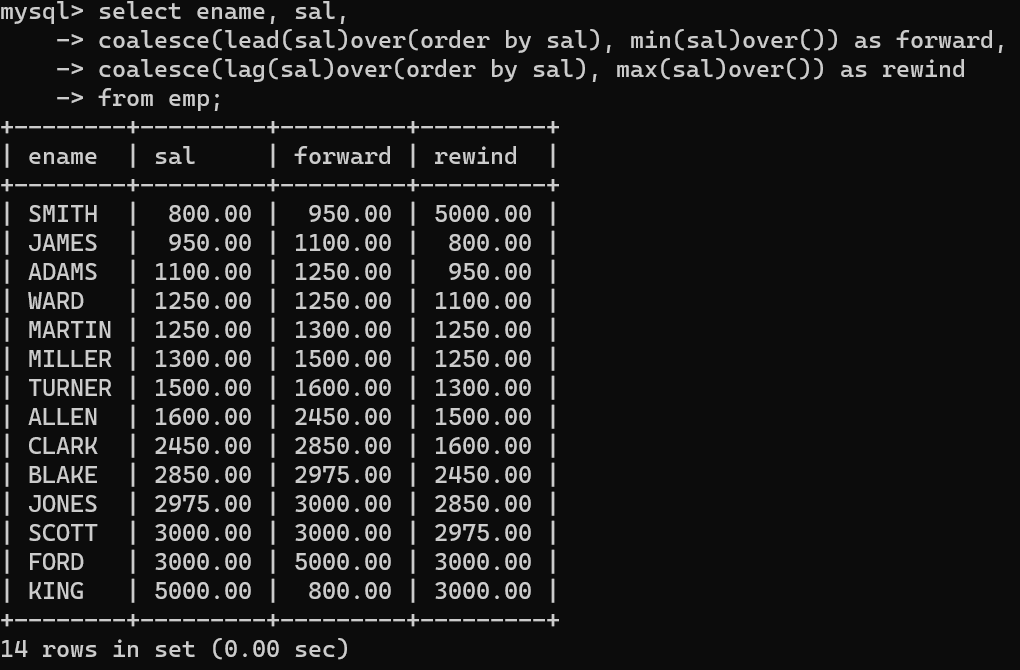
- 그리고 뽑은 4개의 컬럼을 coalesce를 통해 null값을 바꾸는 형태로 두 개의 컬럼으로 뽑아주면 자신의 급여와 함께 낮고 높은 급여를 확인할 수 있다.

- 그리고 순위를 매기는 sql문을 작성했다.
- 해당 방법은 매우 간단하다.
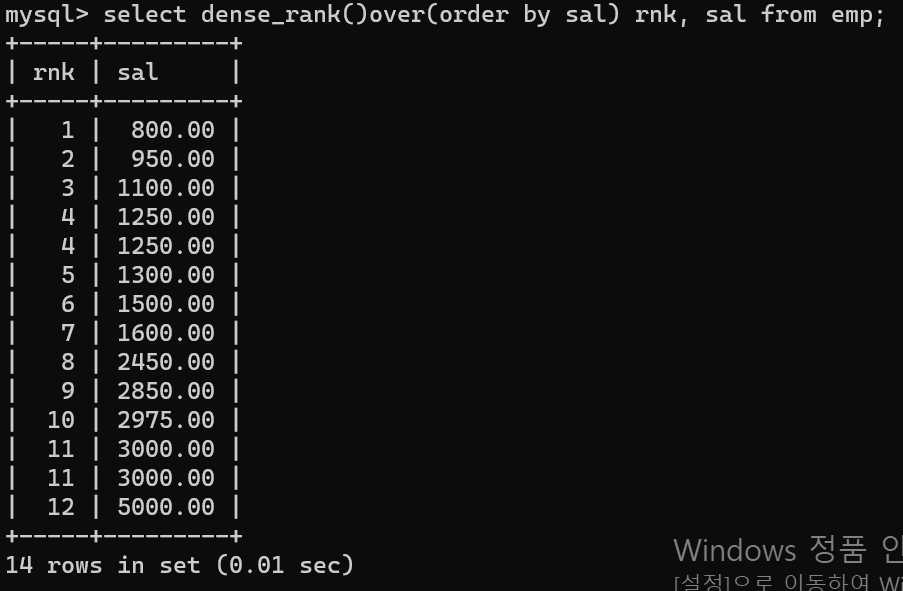
- dense_rank()over(order by column1)을 통해 간단하게 만들 수 있다.

- 이번에는 중복을 방지하는 방법이다.
- distinct를 통해 간단하게 할 수 있지만, 다른 방법으로도 가능하다.
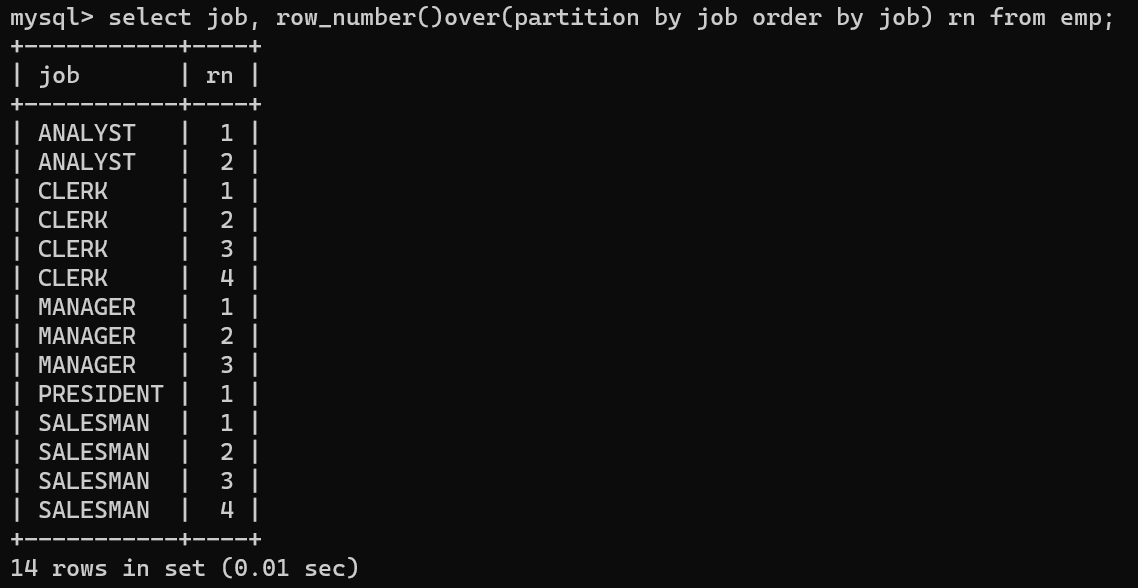
- row_number()over(partition by column order by column)을 통해 group by형태로 값들의 중복값을 행마다 번호를 넣어주고
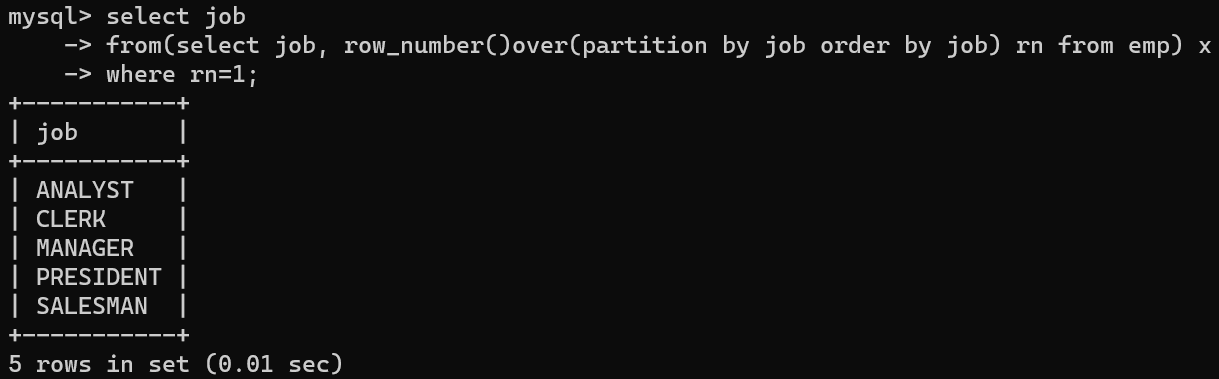
- 해당 값의 첫번 째행에 대한 조건을 걸어두면 고유한 값만 출력할 수 있다.

상황을 바꿀 수 없다면, 나를 바꾸자