mysql_cook_book
1.SQL_03_17

이제 내 스스로 공부하는 시간이다. 데이터 분석 및 사이언티스트에게 가장 중요한 것은 무엇일까?모델링? EDA? 다 중요하다. 하지만 가장 중요한 것은 Data관리다. 그렇기에 데이터 가공, 전처리 등의 역량을 위한 SQL 공부를 시작하자해당 책의 내용을 공부하기 위해
2.SQL_03_18
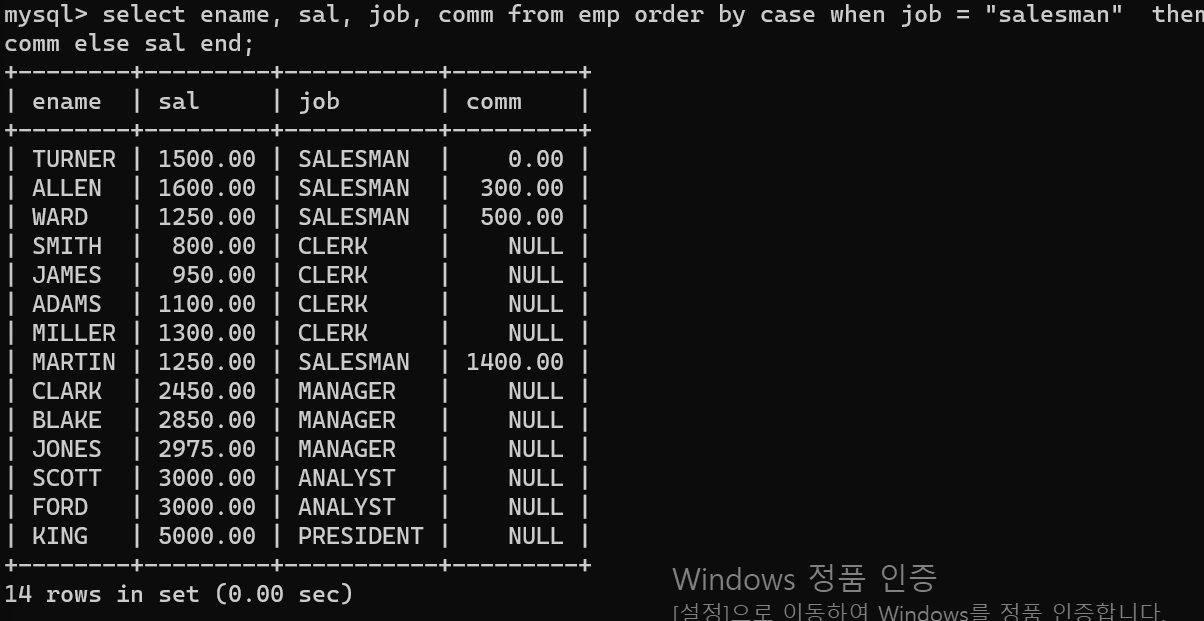
위 코드는 order by절에 case문구를 넣음으로써 조건에 따른 정렬을 수행할 수 있다.job 쿼리의 조건에 해당할 경우 먼저 comm으로 정렬을 하고, 해당하지 않을 경우 sal쿼리를 기준으로 정렬을 한다.이번에는 union (all) 조인 기능이다.union a
3.SQL_03_19
오늘 첫번 쨰 코드는 두 테이블의 자료 비교이다.먼저 비교할 첫번 째 테이블의 자료이며,두번 째 테이블이다.두 테이블의 앞에 테이블에는 ename이 중복되는 값이 없고 deptno이 10인 자료가 존재하지만, 두번 째 테이블의 경우 ename이 WARD인 값이 2개 존
4.Chapter4. 레코드 작업
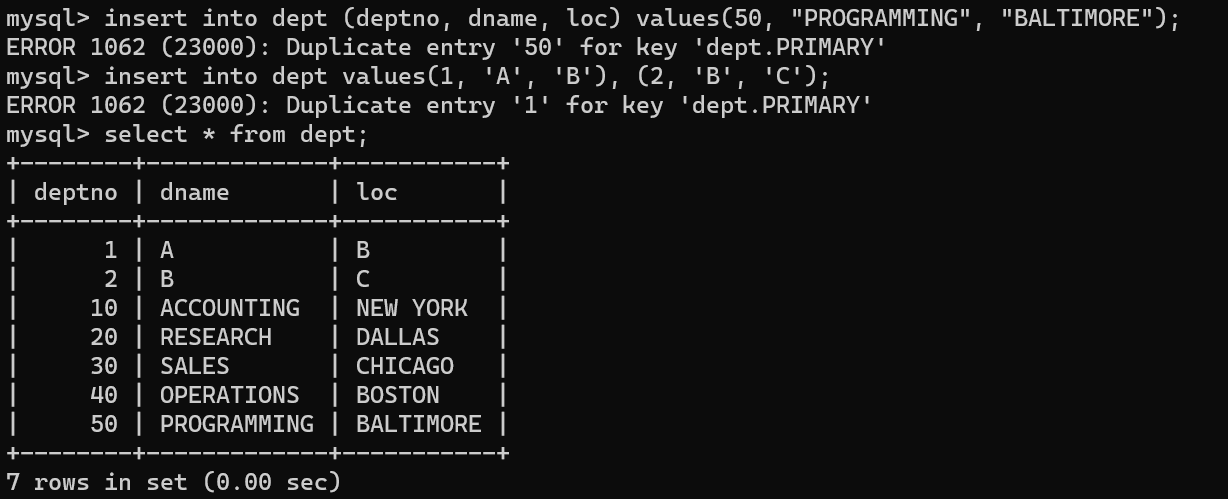
테이블에 데이터를 넣을 때 처음 문법 처럼 처음 코드는 하나의 데이터 셋을 넣는 방식이고, 두번 째는 여러 데이터를 넣을 때 튜플 형태로 여러 데이터를 넣을 수 있다. 또한, column부분의 경우 테이블의 column의 수와 동일한 데이터셋을 넣는다면 넣지 않아도 괜
5.Chapter6. 문자열 작업
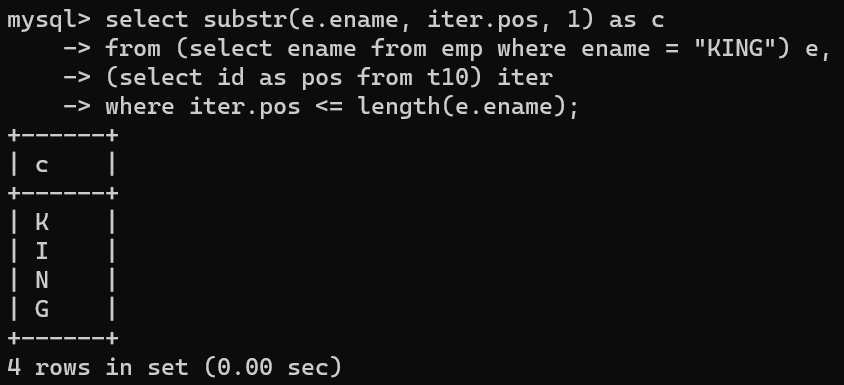
sql의 단점 중 하나는 문자열 처리가 용이하지 않다는 점이다. 그렇기 때문에 여러 방법을 통해 문자열을 작업해야하는 경우가 있다.먼저 하나의 단어를 인덱스별로 출력을 해야하는 경우 위 코드를 사용할 수 있다.substr함수는 3개의 매소드를 통해 사용할 수 있는데,
6.Chapter7. 숫자열 작업
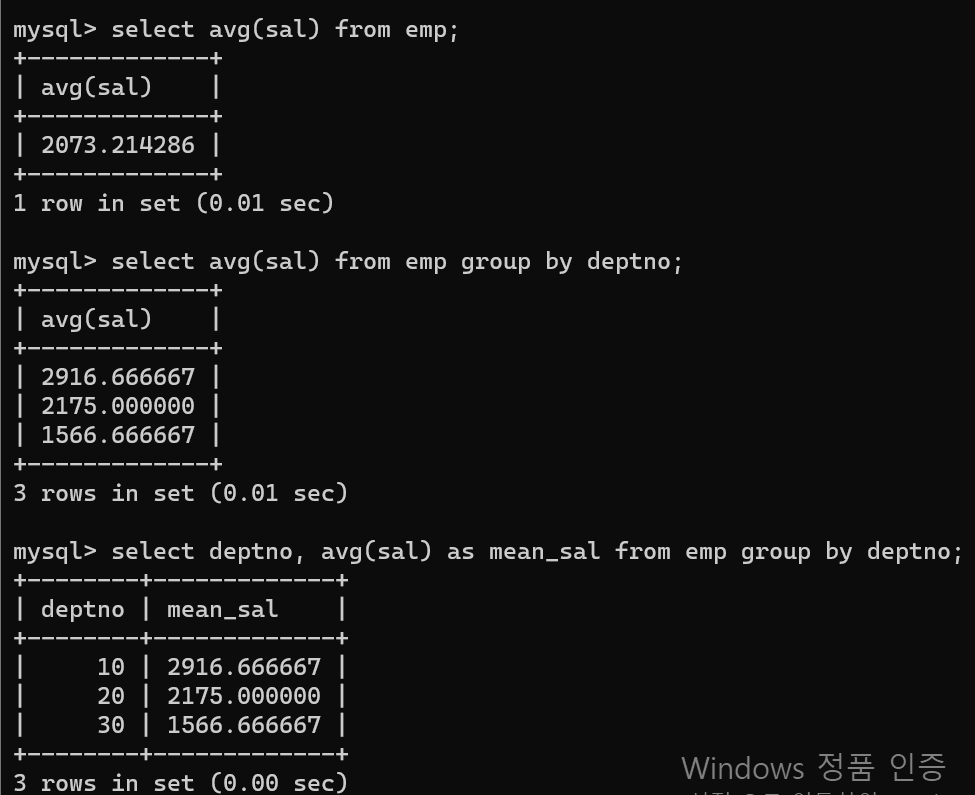
이제 문자열 다음으로 숫자열에 대한 데이터 처리를 Mysql를 통해 해보자가장 먼저 기본 기능을 통해 평균값을 구할 수 있다.avg(column1)으로 코드를 쓰면서 해당 컬럼의 평균값을 구할 수 있다.group by와 함께 사용할 경우 그룹별 집계 함수 기능이 사용된
7.Chapter8. 날짜 작업
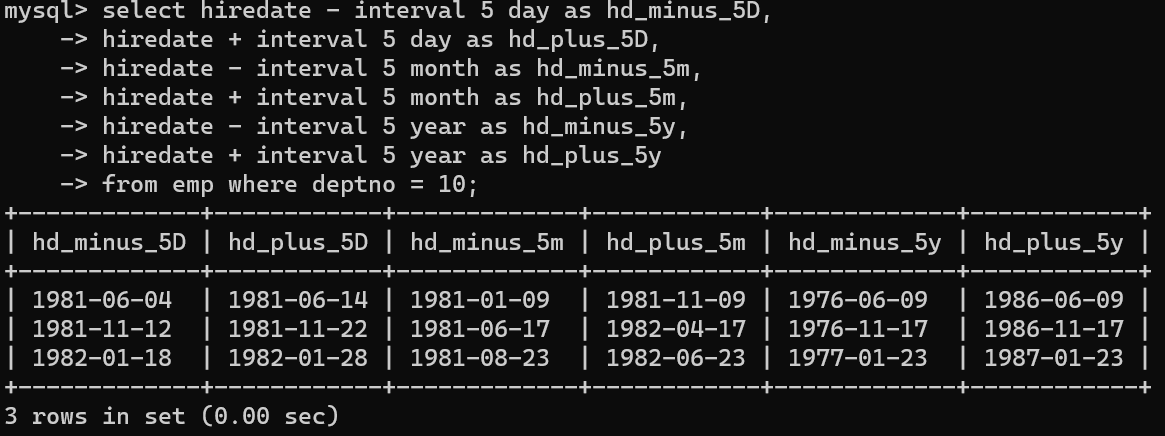
이번 Chapter에서는 날짜 데이터를 다뤄봤다.일단 가장 단순히 입력된 날짜 데이터를 day, month, year를 기준으로 더하거나 뺏다.위와 같이 date날짜에 연산을 넣고 숫자와 형식을 넣어주면 계산이 된다.이번에는 두 날짜의 차이를 계산해봤다.위 두 사람의
8.Chapter 09. 날짜 조작 기법

이번에는 날짜를 계산하는 것을 넘어, 다양한 형태로 변환하는 과정을 가졌다.윤년은 4년에 한 번씩 2월에 29일이 생기는 연도로서 날짜를 데이터로 사용할 때 신경써야하는 부분인데, 해당 연도가 윤년인지 확인하는 작업을 가졌다.먼저 해당 연도에서 현재 날짜까지의 일수를
9.Chapter 11. 고급검색

SQL에는 쿼리를 컬럼으로, 인덱스 번호별로 데이터를 출력하는데 별도의 index번호가 없지만 함수를 통해 인덱스 번호를 주고 원하는 값만 출력할 수 있다.Row_number() over(order by columns1)을 통해 기준 정렬을 설정하고, 해당 정렬 순서대