- 이제 문자열 다음으로 숫자열에 대한 데이터 처리를 Mysql를 통해 해보자
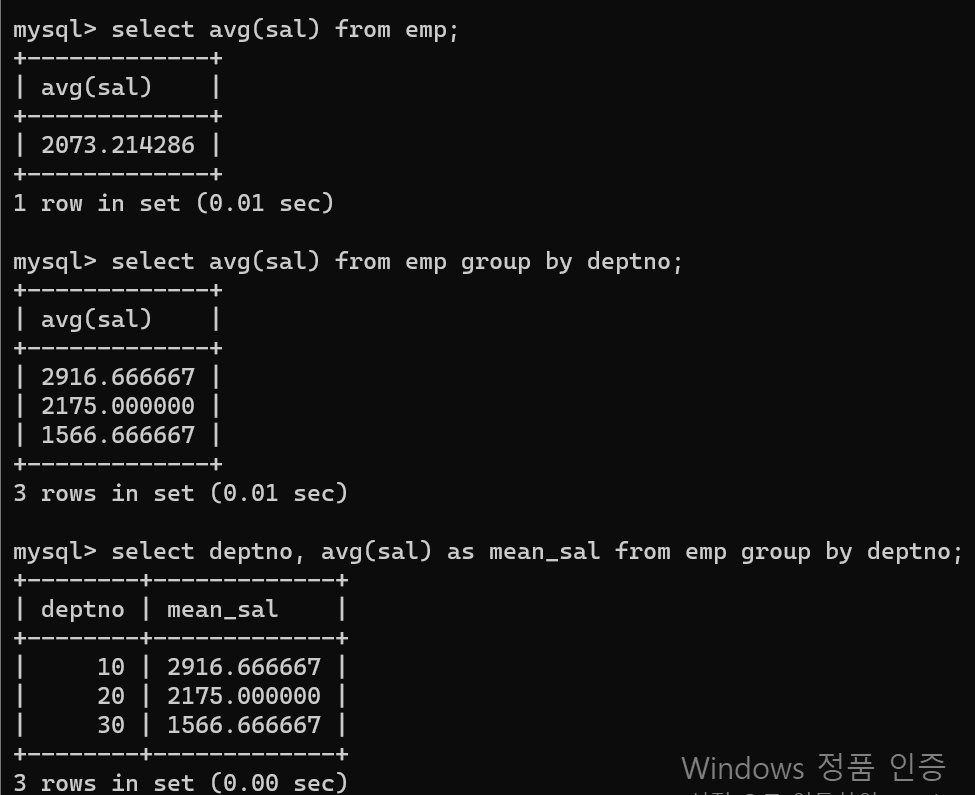
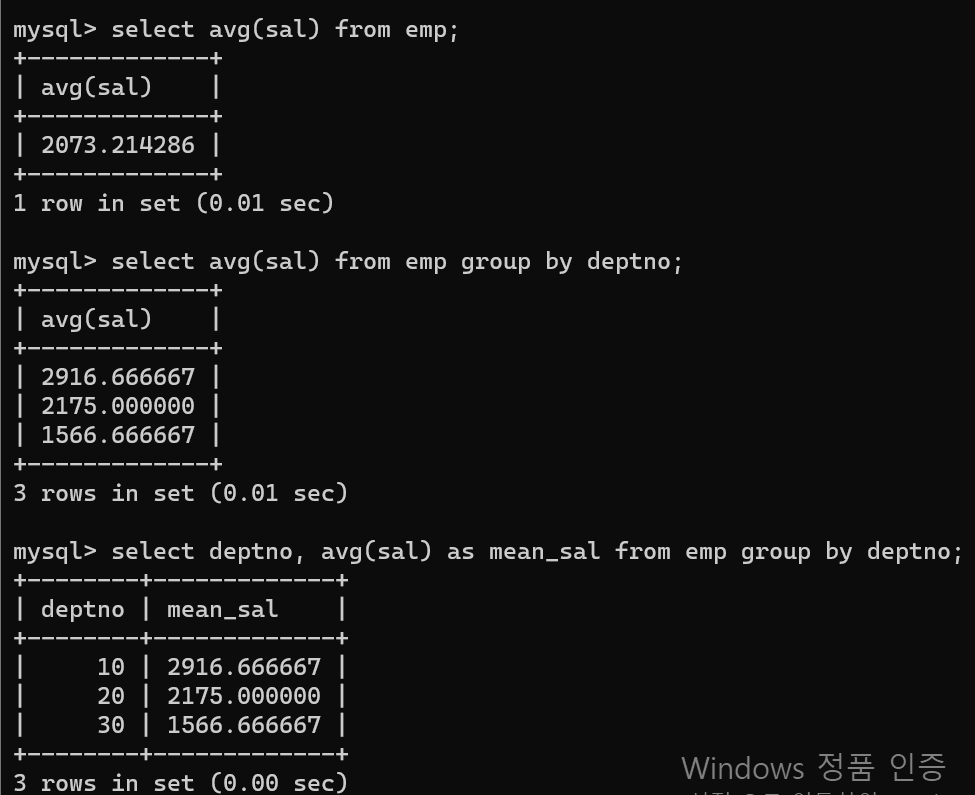
- 가장 먼저 기본 기능을 통해 평균값을 구할 수 있다.
- avg([column1])으로 코드를 쓰면서 해당 컬럼의 평균값을 구할 수 있다.
- group by와 함께 사용할 경우 그룹별 집계 함수 기능이 사용된다.
- 가독성을 높이기 위해 맨 아래와 같이 group by를 사용할 시 그룹시킨 컬럼도 같이 넣어주는 것이 좋으나, 필수는 아니다.
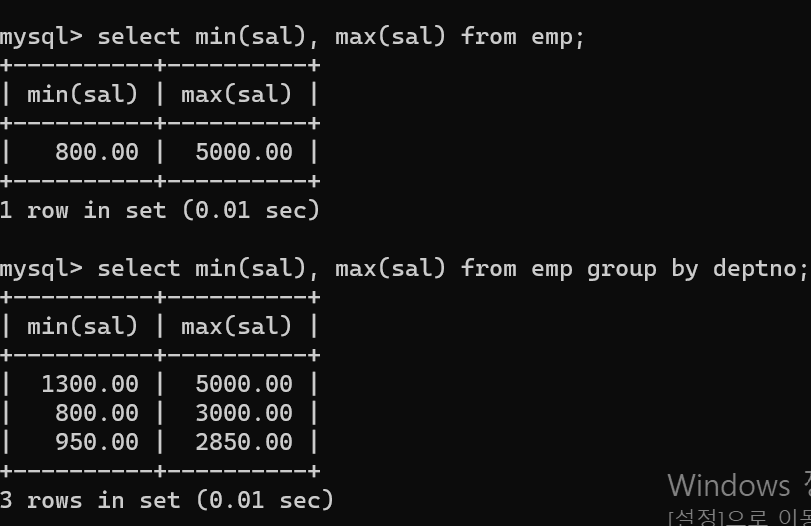
- 최소값을 찾기 위해서는 min값을 쓸 수 있다.
- 집계 함수는 group by와 함께 자주 쓰이는데 데이터 속에서 각 고유값들의 평균, 최소, 최대 등 값들을 살펴볼 수 있다.
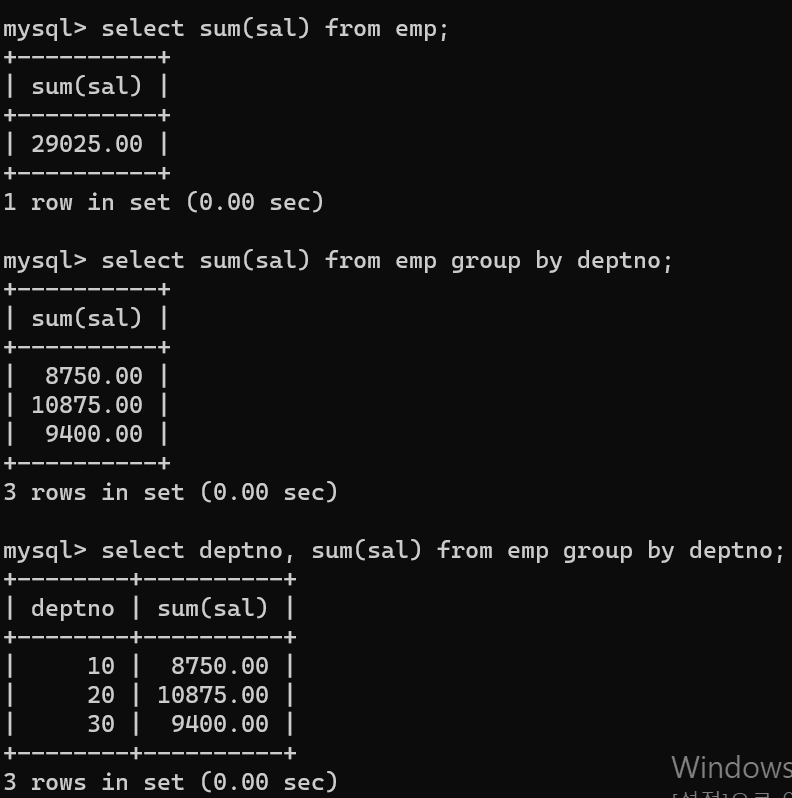
- sum은 합계를 구할 수 있는 집계 함수다.
- 숫자 part는 함수의 기능을 알고 있냐, 모르냐가 큰 차이를 보일 것 같다.
- 기본적인 함수 기능은 알고 있었지만, 나중에 나오는 lag, sum over 등은 잘 모르던 기능인데 제대로 알 수 있게 됐다.
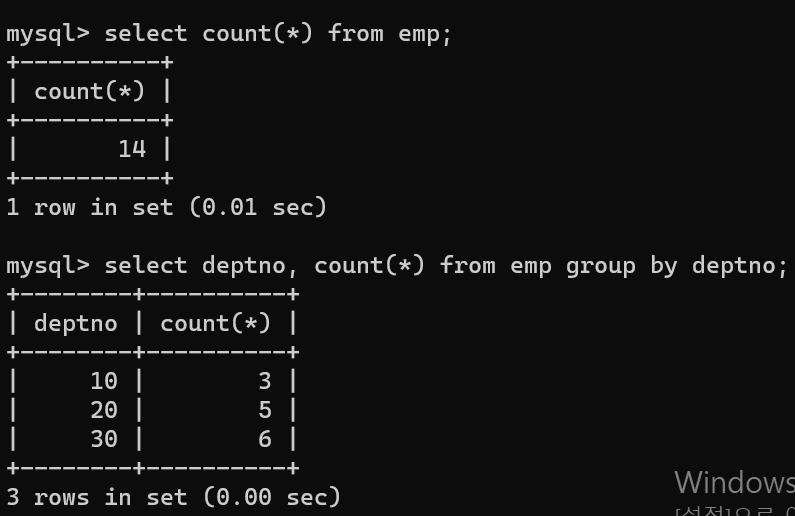
- count는 자주 사용되는 함수인데, 개수를 카운트해준다.
- 맨 밑의 코드의 경우 deptno이 10인 데이터는 3개, 20은 5개, 30은 6개가 존재한다.
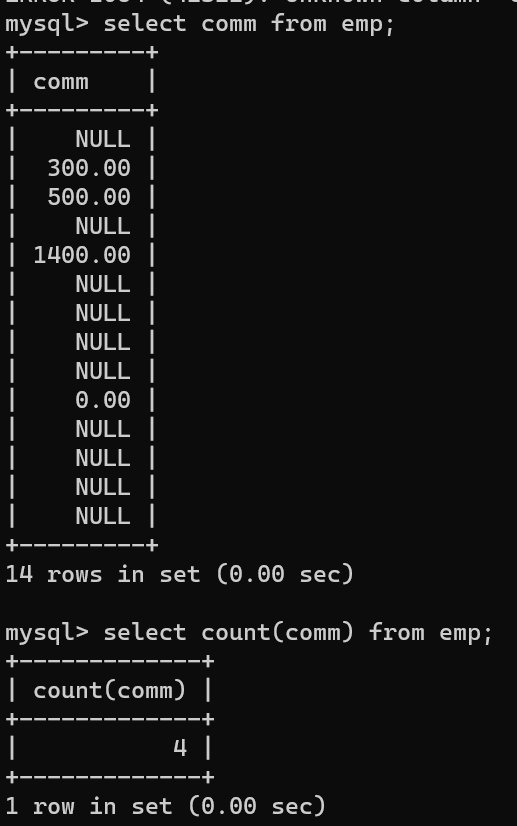
- 중요한 점은 집계 함수를 사용할 때 Null값은 제외하고 계산된다는 것이다.
- 위에 데이터는 Null를 포함해 많은 데이터가 있지만, 밑에 집계된 것은 4개밖에 없다.
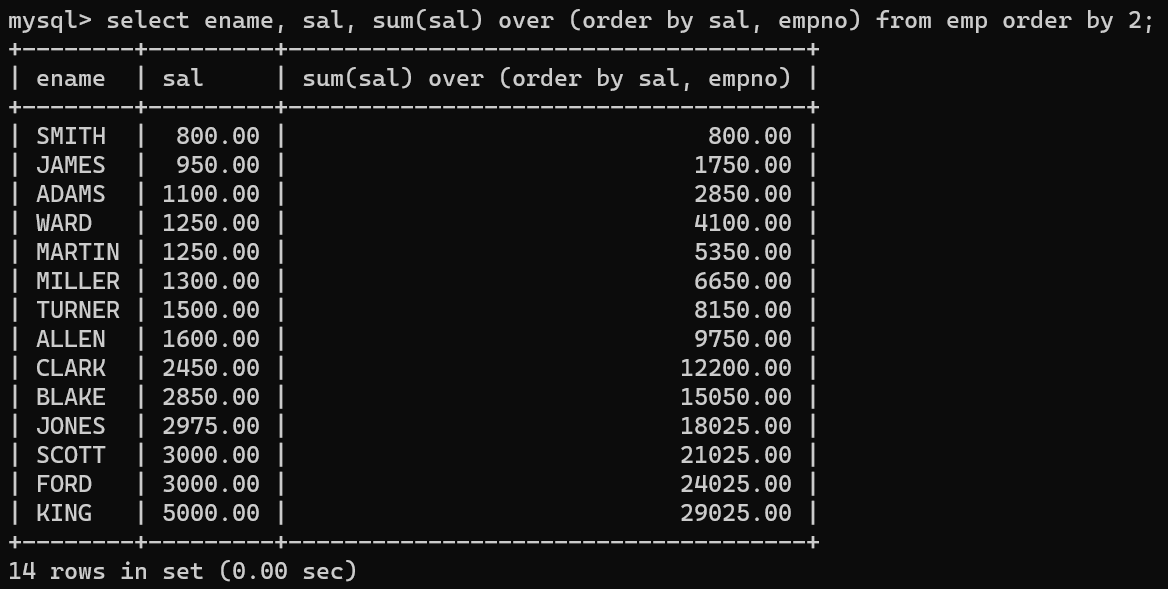
- sum() over () 함수는 누적 합계를 구할 수 있는 기능이다.
- over ()안에 order by 컬럼들을 넣음으로써 정렬할 컬럼을 넣고, 해당 기준에 따라 sum에 넣은 수치를 누적해서 더한다.
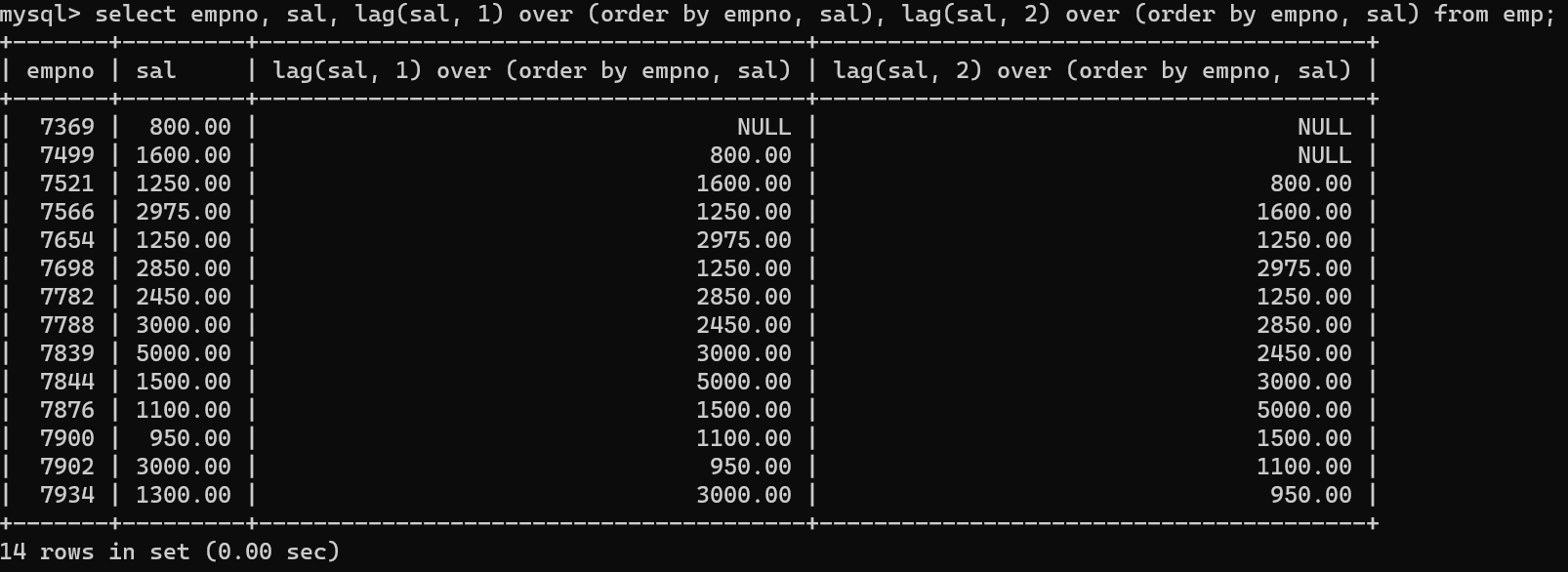
- lag는 이전 인덱스의 데이터를 출력한다. lag(컬럼, 숫자) 이런식으로 이전 인덱스의 데이터를 출력하는데
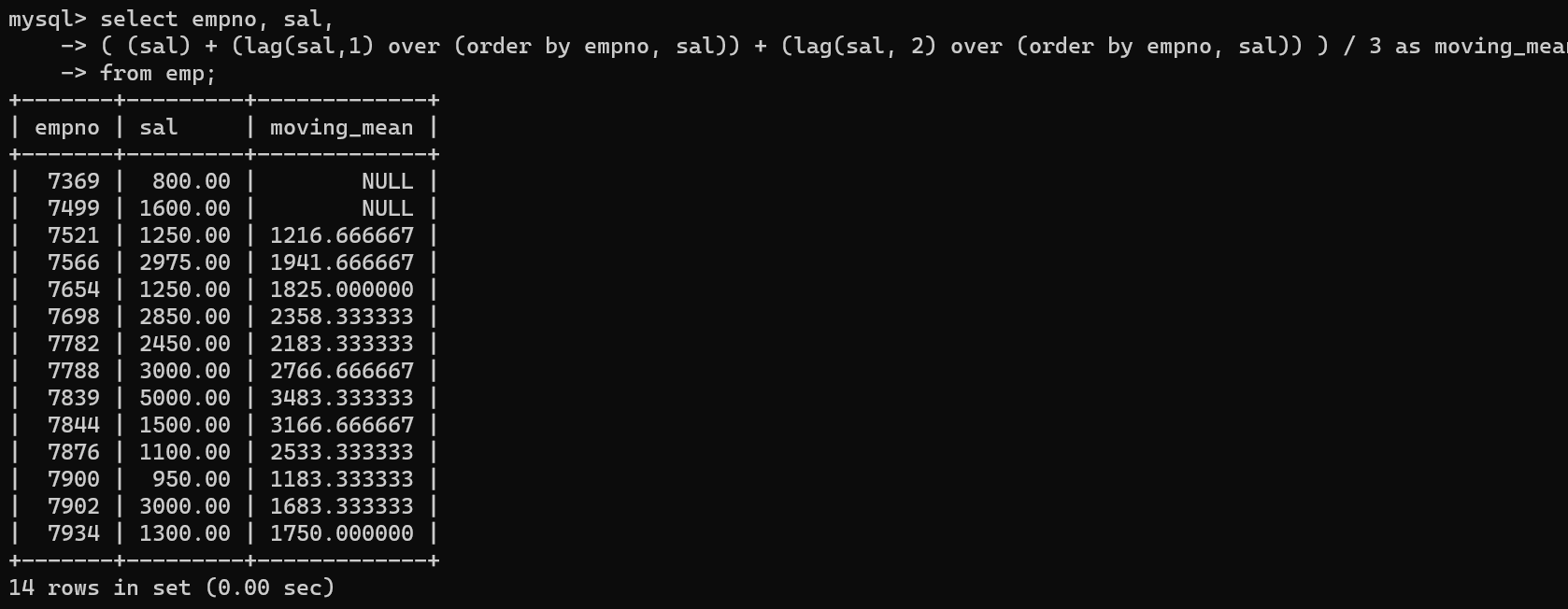
- 이런식으로 값1, 값2, 값3 등을 더해서 나눔으로써 평균이동수치를 구할 수도 있다.
- 시계열 데이터를 분석할 때 사용하기 좋은 함수이다.
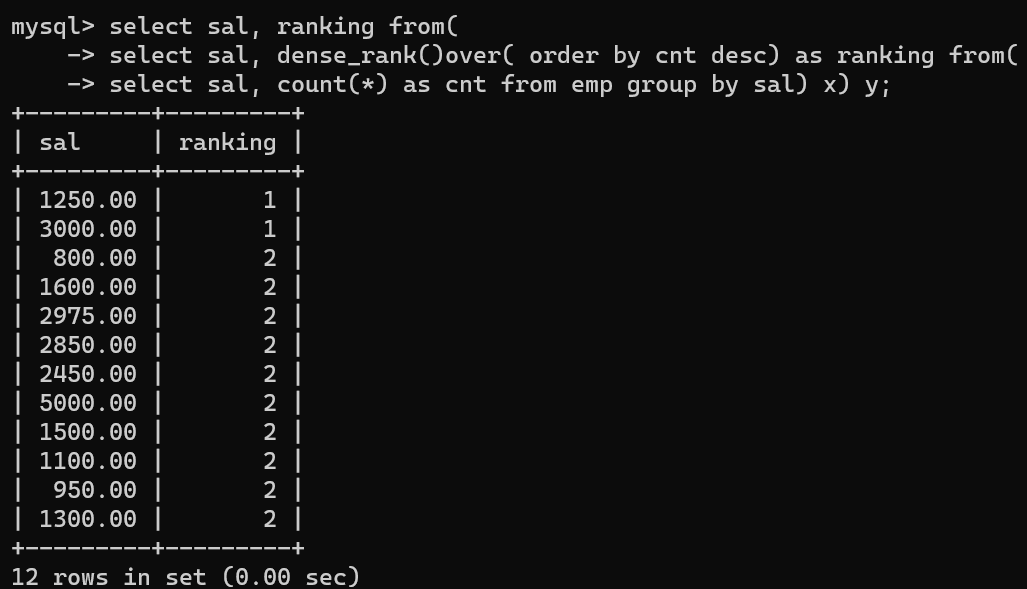
- dense_rank()over() 기능과 count를 합쳐 최빈값을 구할 수도 있다.
- 메인 select절에 2개의 from이 묶여있는데
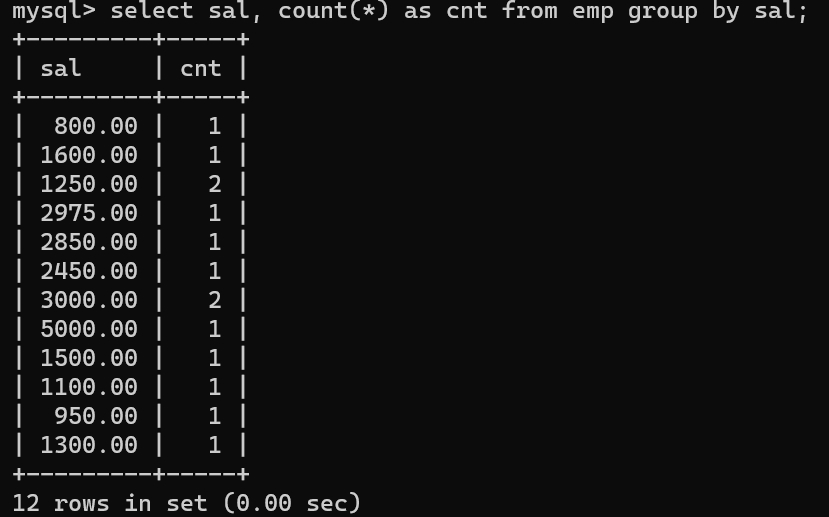
- 맨 안쪽 select절은 급여에 따른 count를 cnt라고 alies를 붙이고 출력했다.
- 해당 select절을
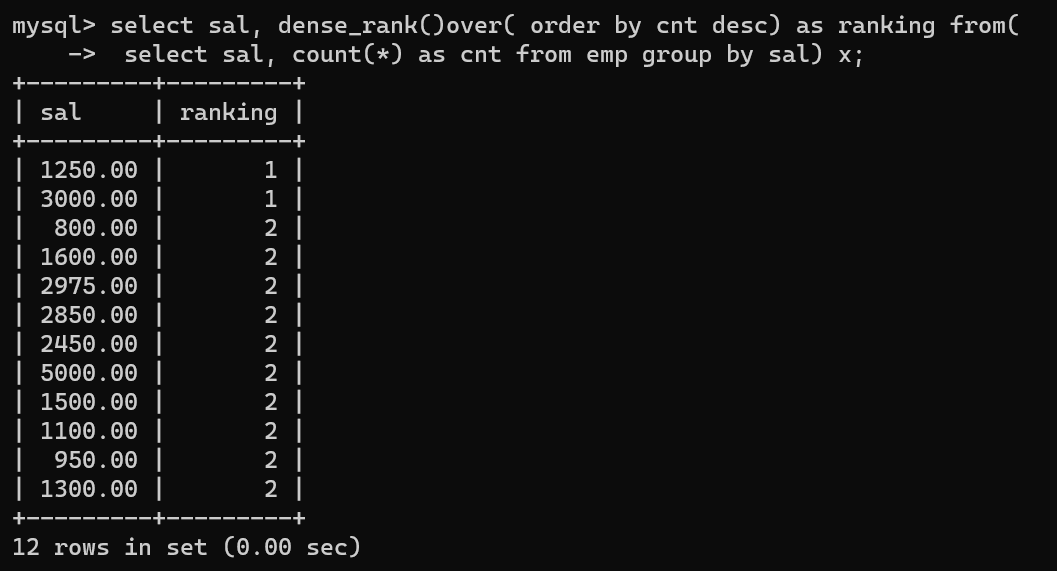
- dense_rank로 묶어버리면 count숫자에 따라 순위를 만들어준다.
- dense_rank()over 기능과 count를 통해 쉽게 최빈값을 구할 수 있다.
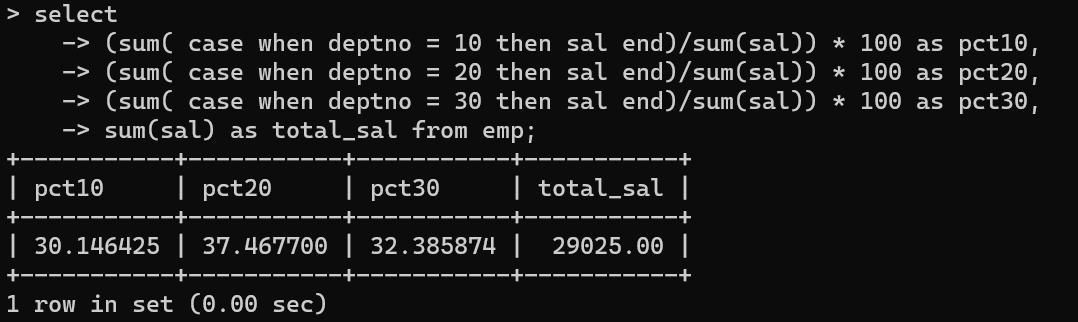
- 위 코드는 sql에서 백분위수를 나타내는 방법이다.
- 가장 자주 쓰이는 백분위수인데, 코드는 아주 심플하다.
- 연속형 자료를 포함한 컬럼을 분모에 sum()함수를 사용해서 나누고, 위에는 case when condition_컬럼1 = condition1 then target_column end로 마무리해주면 된다.
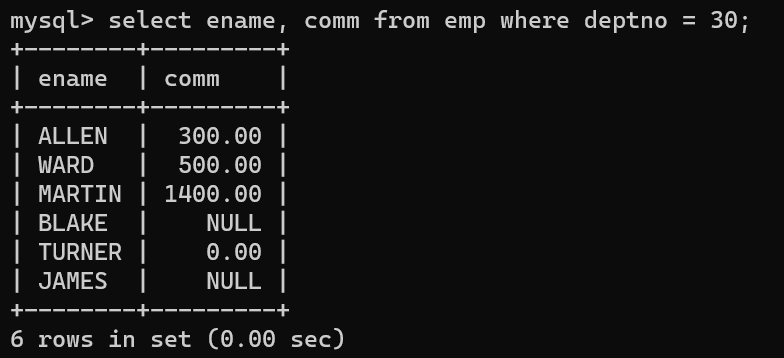
- 이번에는 평균을 구할 때 Null값이 포함된 경우 null값을 포함해서 평균을 구하는 방법이다.

- 이렇게 집계해보면 결과값에 null값은 빠진 상태로 집계된 것을 확인할 수 있다.
- 위에는 null값포함 count가 6개인데, 밑에는 4개만 집계된다.
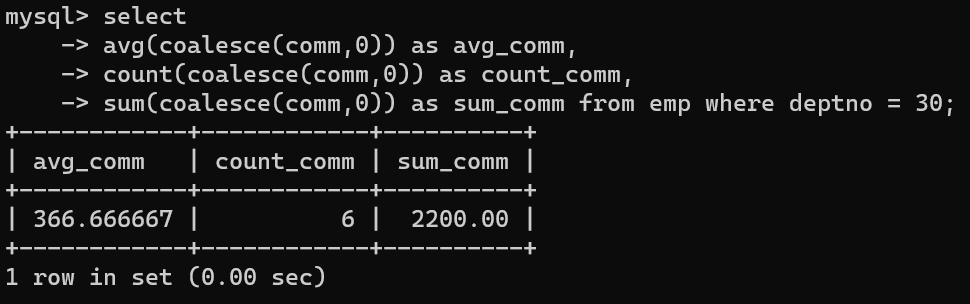
- 그렇기 때문에 coalesce함수를 사용해 null값이 경운 0을 넣어서 계산하면 평균을 계산할 때 정상적으로 null값도 포함해서 출력할 수 있다.
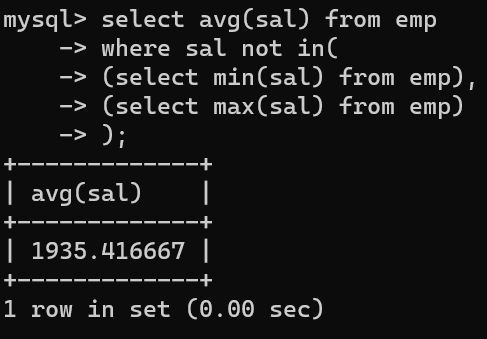
- 이번에는 절사평균을 구하는 방법이다.
- 산술평균의 경우 이상치 데이터에 영향을 크게 받기 때문에 중앙값을 사용하거나, 위와 같이 max, min값을 제외해서 평균을 낸다.
- 방법은 심플하다. 먼저 where조건절에 max값과 min값을 넣어 not in 함수를 사용해서 제외하면 된다.
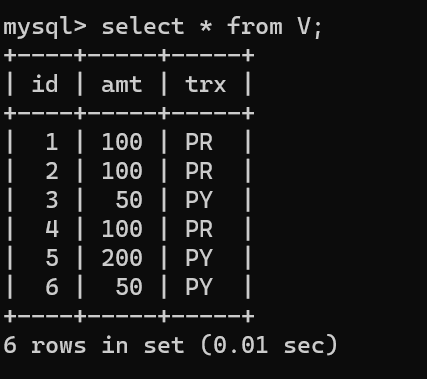
- 이번에는 조건에 따른 누적합계 코드이다.
- 보통 데이터 누적 계산 시 조건에 따라 더하거나, 빼는 경우가 있는데 위에 trx가 PR일 경우 Purchase로 더하고, PY일 경우 Payment로서 뺴야한다.
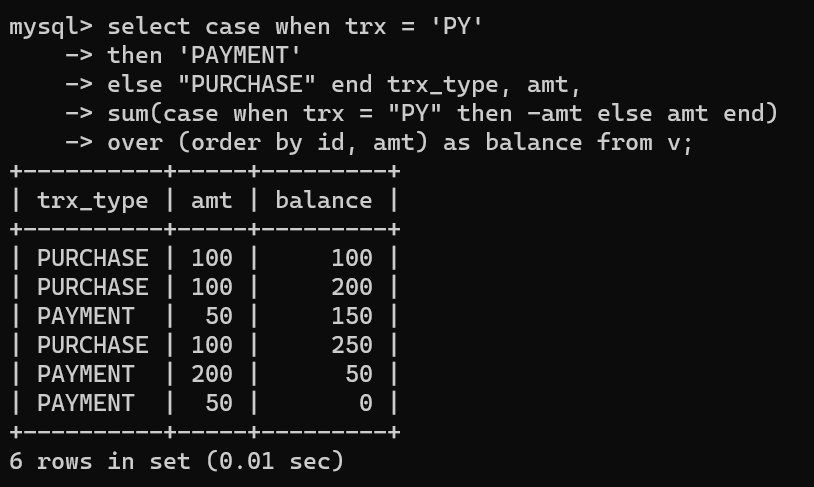
- 위 코드와 같이 sum()over()함수를 사용하는데, sum ( )안에 case 조건문을 넣는다.
- trx="PY"일 경우 amt를 -(minus)값으로 넣고, 나머지는 그대로 넣는다.
- 그리고 id와 amt별로 누적 합계를 구해준다. id와 amt 두 컬럼의 order by를 한 이유는 amt의 경우 중복값이 있기 때문에 구분을 하기 위해서 두 개의 값을 모두 넣어줬다.

상황을 바꿀 수 없다면, 나를 바꾸자