
project_story
- 나의 역할 : 모델 구축 및 성능 테스트, 데이터 전처리
- 링크 : myGitHub
- 프로젝트의 진행 스토리 및 코드는 github를 통해 알 수 있습니다!
- 이번 프로젝트는 7명이 함께 금융 데이터를 바탕으로 머신러닝 모델을 구축하여 데이터를 통해 예측할 수 있게 진행했습니다.
- 해당 프로젝트는 복수의 데이터를 통해 여러 Label값(범주형, 연속형)을 예측하는 머신러닝 모델 구축을 목적으로 진행했습니다.
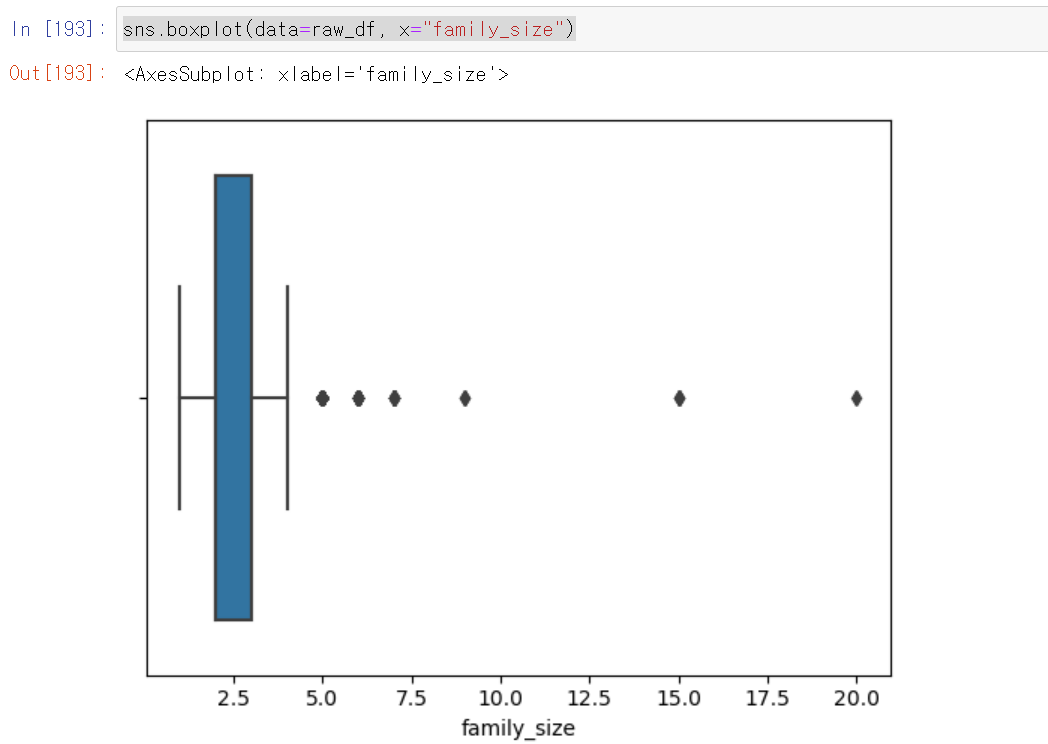
1일차, credit_data 분석 시작
- 사전 주제 선정을 위한 미팅, 화상 회의 등을 진행했지만, 본격적으로 시작한 날부터 EDA를 시작했다.
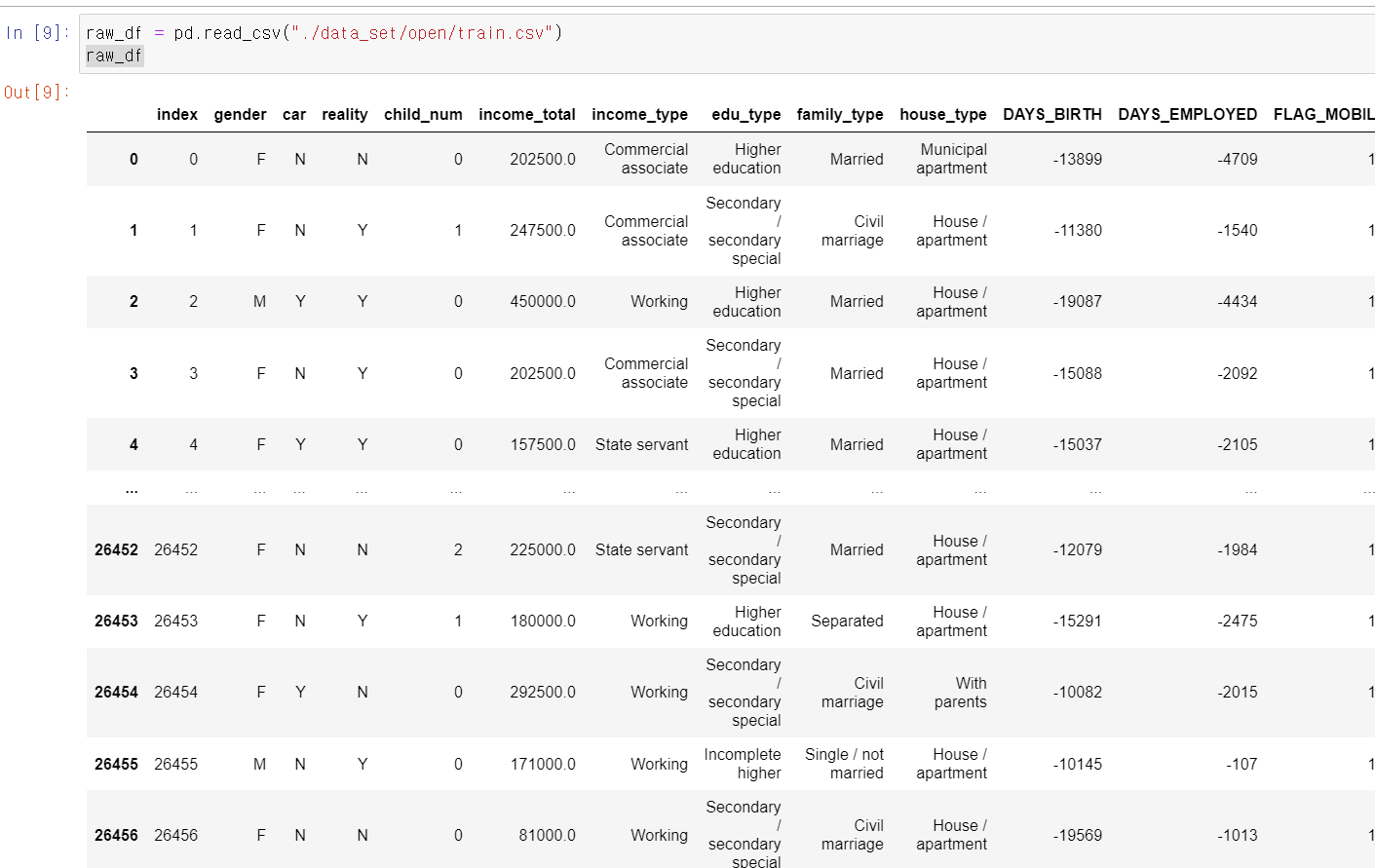
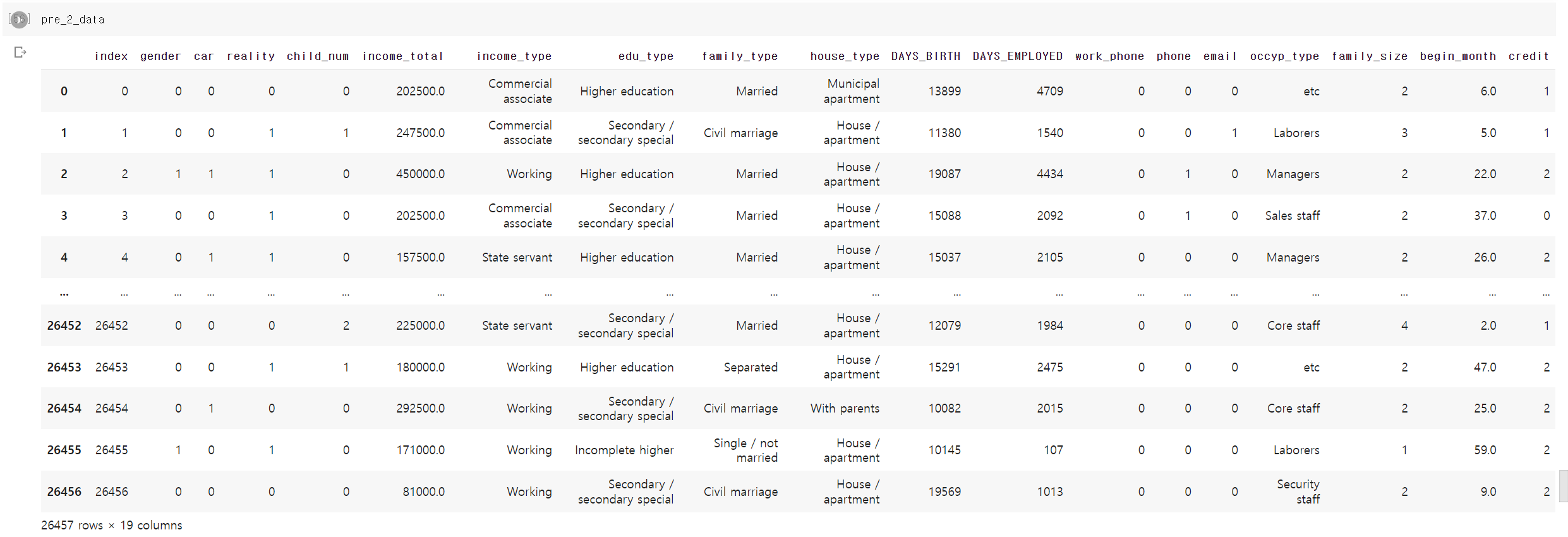
- 가장 먼저 Dacon에서 대출 연체자에 대한 신용등급 데이터셋을 불러왔다.
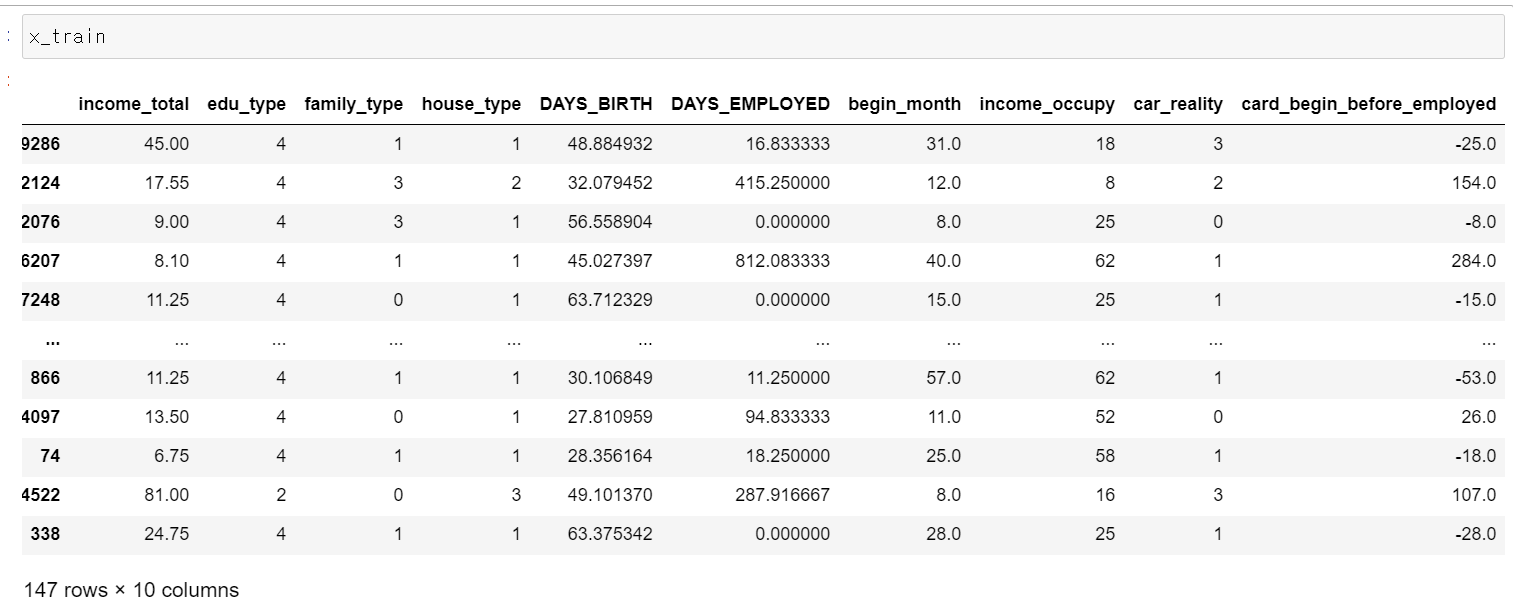
- 인덱스를 제외한 19개의 컬럼과 26457샘플링 데이터가 존재한다.
index gender: 성별
car: 차량 소유 여부
reality: 부동산 소유 여부
child_num: 자녀 수
income_total: 연간 소득
income_type: 소득 분류 ['Commercial associate', 'Working',
'State servant', 'Pensioner', 'Student']
edu_type: 교육 수준 ['Higher education' ,'Secondary / secondary
special', 'Incomplete higher', 'Lower secondary', 'Academic degree']
family_type: 결혼 여부 ['Married', 'Civil marriage',
'Separated', 'Single / not married', 'Widow']
house_type: 생활 방식 ['Municipal apartment',
'House / apartment', 'With parents', 'Co-op apartment', 'Rented
apartment', 'Office apartment']
DAYS_BIRTH: 출생일 데이터 수집 당시 (0)부터 역으로 셈, 즉,
-1은 데이터 수집일 하루 전에 태어났음을 의미
DAYS_EMPLOYED: 업무 시작일 데이터 수집 당시 (0)부터 역으로 셈, 즉,
-1은 데이터 수집일 하루 전부터 일을 시작함을 의미 양수 값은 고용되지 않은 상태를 의미함
FLAG_MOBIL: 핸드폰 소유 여부
work_phone: 업무용 전화 소유 여부
phone: 전화 소유 여부
email: 이메일 소유 여부
occyp_type: 직업 유형
family_size: 가족 규모
begin_month: 신용카드 발급 월 데이터 수집 당시 (0)부터 역으로 셈,
즉, -1은 데이터 수집일 한 달 전에 신용카드를 발급함을 의미
credit: 사용자의 신용카드 대금 연체를 기준으로 한 신용도
=> 낮을 수록 높은 신용의 신용카드 사용자를 의미함- 각 컬럼에 대한 설명
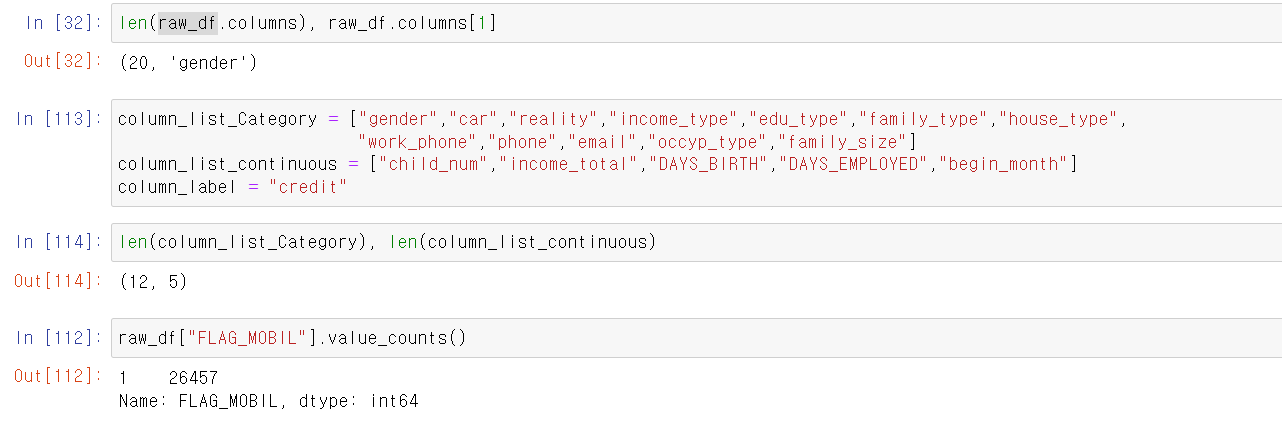
- 컬럼의 숫자를 확인하고, EDA를 위해 사전에 범주형 자료와 연속형 자료를 구분했다.
- 처음에는 DataType을 기준으로 object는 범주형, 나머지는 연속형으로 구분했는데 연속형 자료 중 1과 2 등 이진 자료가 다수 존재해 직접 데이터를 보고 구분했다.
- 그렇게 범주형 자료 12개, 연속형 자료 5개가 나왔고
- FLAG_MOBIL은 휴대폰 소지 여부인데, unuque값이 하나밖에 없어서 머신러닝 모델에 사용할 데이터로 부적합했다.

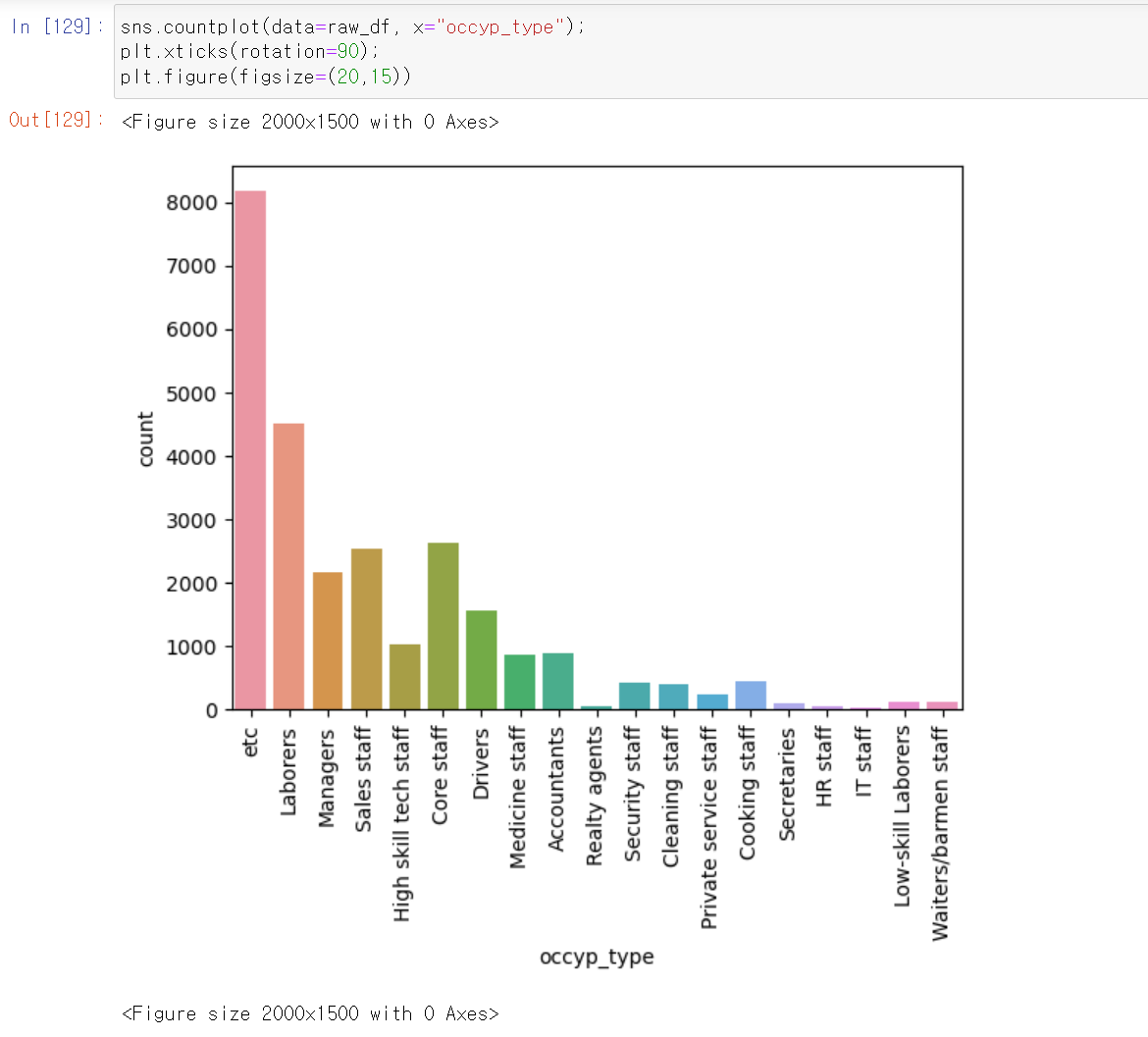
- 이제 빈도 및 분포를 확인하기 위해 범주형 자료에 대한 countplot을 그리기 위한 코드이다.
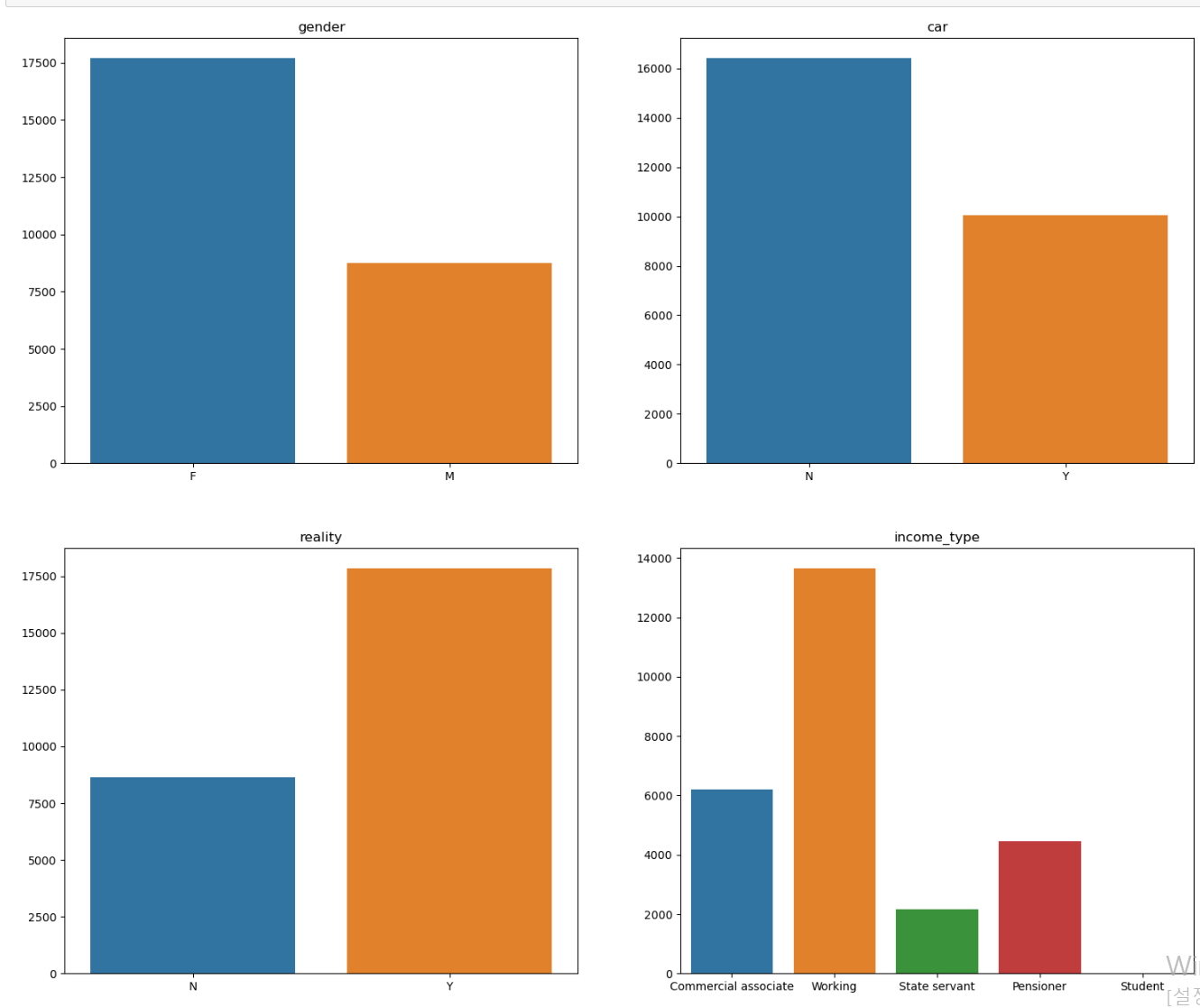
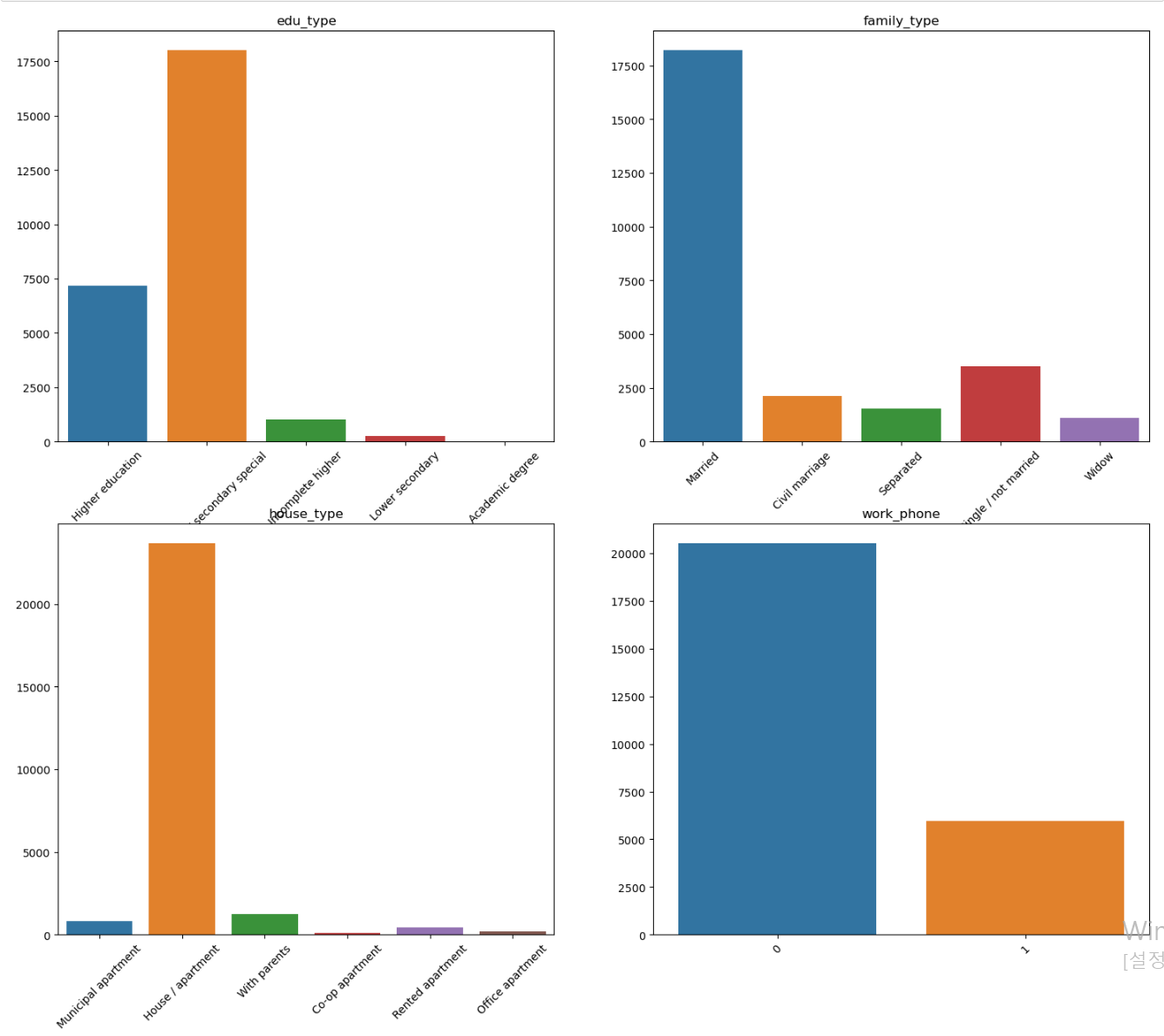
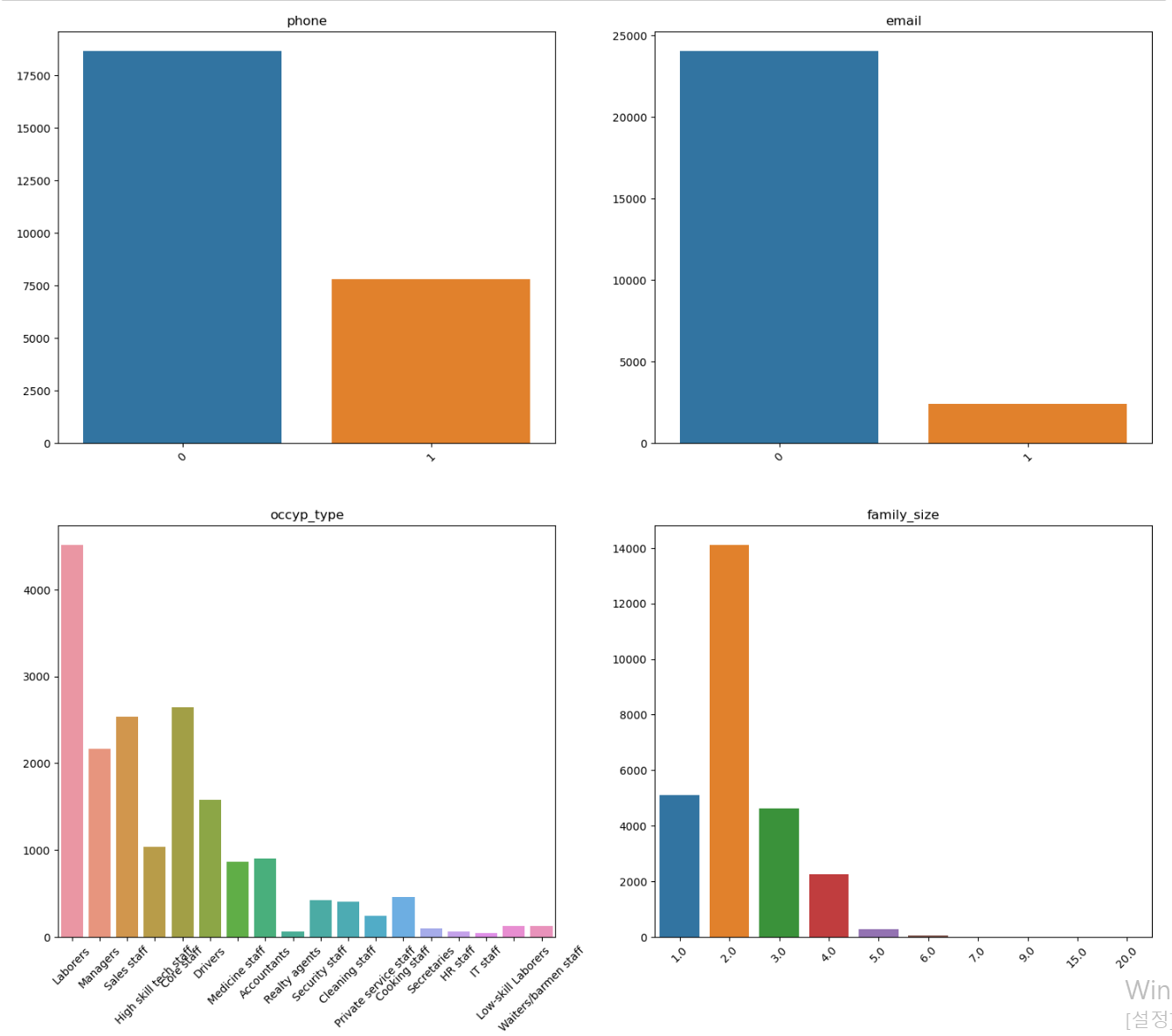
- 다양한 색깔로 그려진 것을 보니 더글로리에 전재준이 생각나네...
- 이진 자료도 다수 존재하며, 데이터 한쪽으로 쏠린 데이터 컬럼 또한 존재한다.
- 하우스 타입의 경우 거의 모든 데이터가 아파트에 몰려있다.

- 이번에는 연속형 자료를 시각화하기 위한 kdeplot 코드이다.
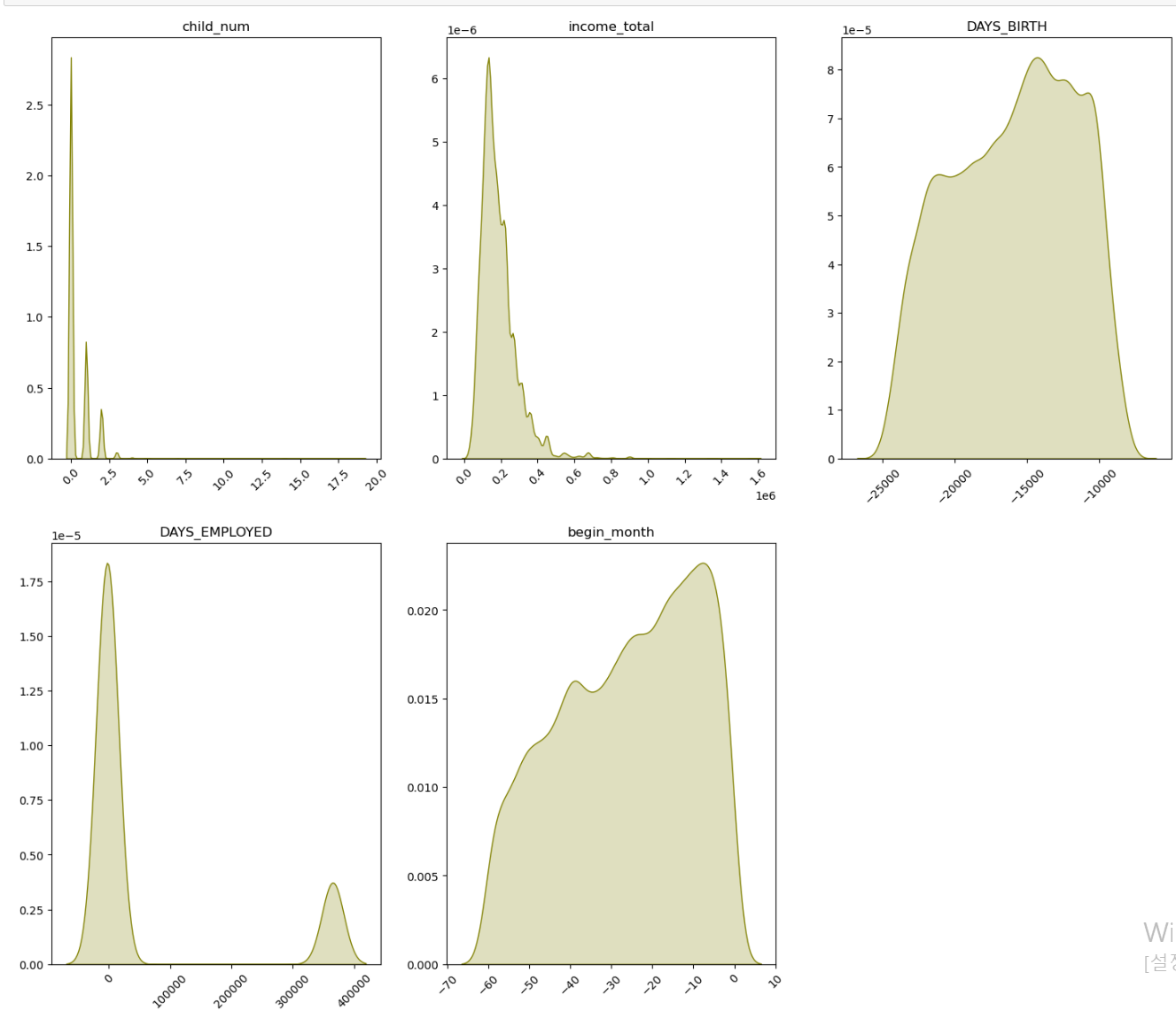
- 한 표에 다 그려져서 기분이 좋았는데. DAYS_EMPLOYED 데이터의 경우 0이면 취업을 한 경력이 없다는 의미이다
- 또한 income_total의 경우 저소득구간에 몰려 있는 데이터가 많은데 대출 연체를 한다는 것 자체가 소득의 분위가 낮을 가능성이 높다고 생각된다.
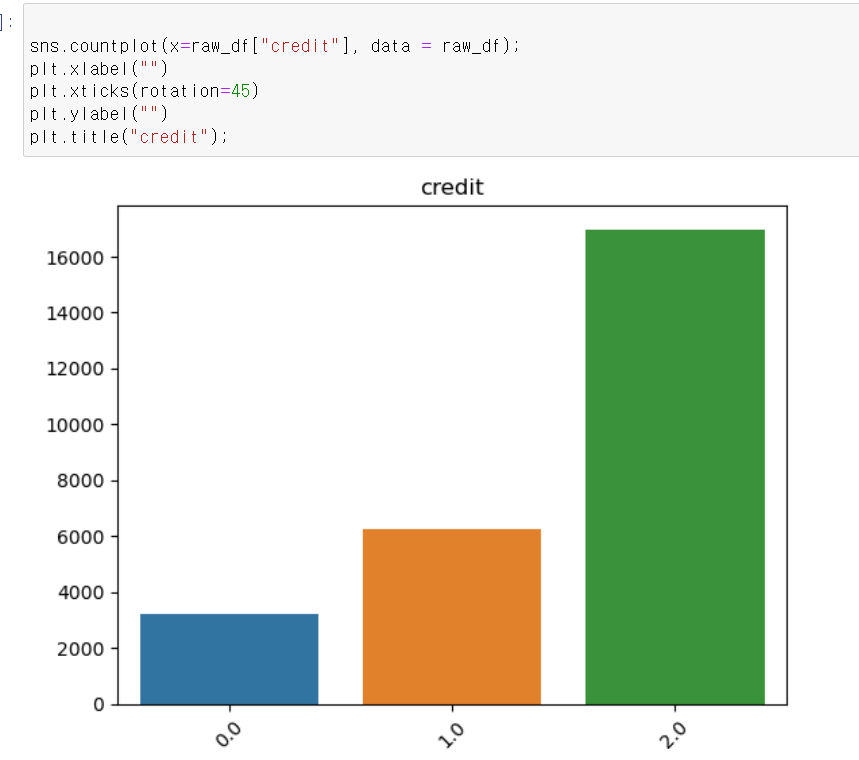
- 라벨값을 사용할 credit 데이터의 경우 2(가장 낮은 신용등급)가 가장 많으며, 0이 가장 적다.
2일차
- 이제 본격적인 분석 작업을 시작했는데, 일단 데이터 전처리 과저부터 시작했다.
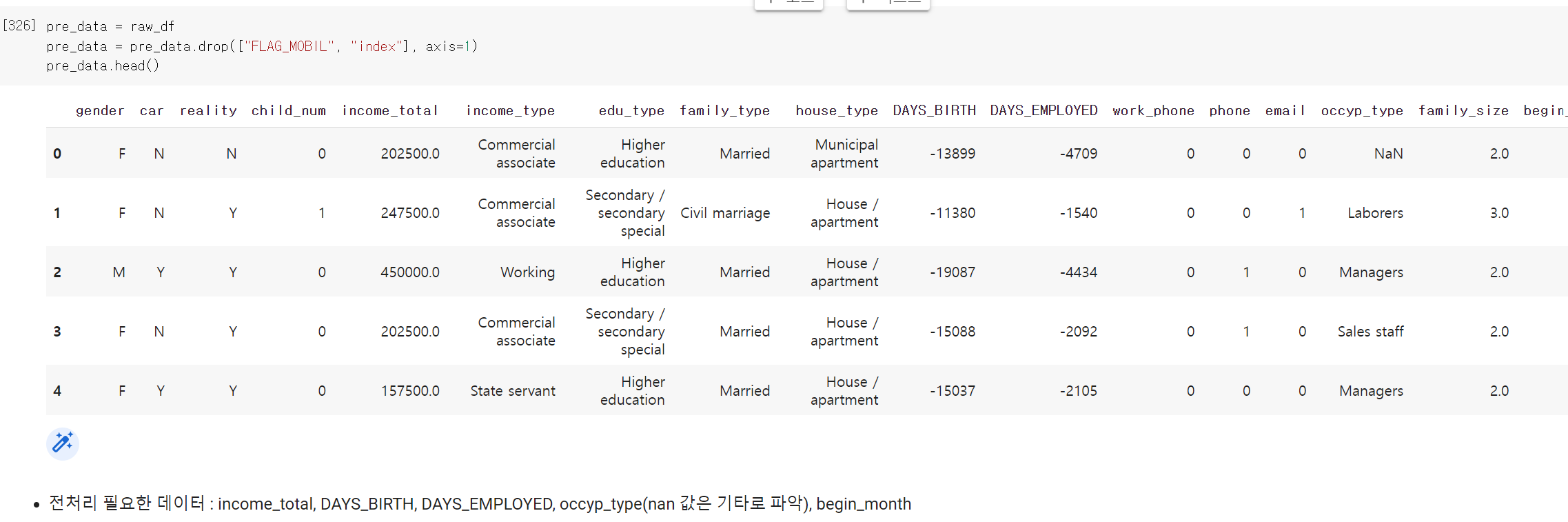
- 일단 고유값이 하나밖에 없는 휴대폰 유무 컬럼을 삭제하고, 전처리한 데이터 변수 pre_data에 저장했다.

- 컬럼의 값을 확인하고, 컬럼 중 NaN값이 있는지 확인하기 위해서 for문을 통해 각 컬럼의 NaN값을 확인했는데 occyp_type 컬럼에 NaN이 존재했다.
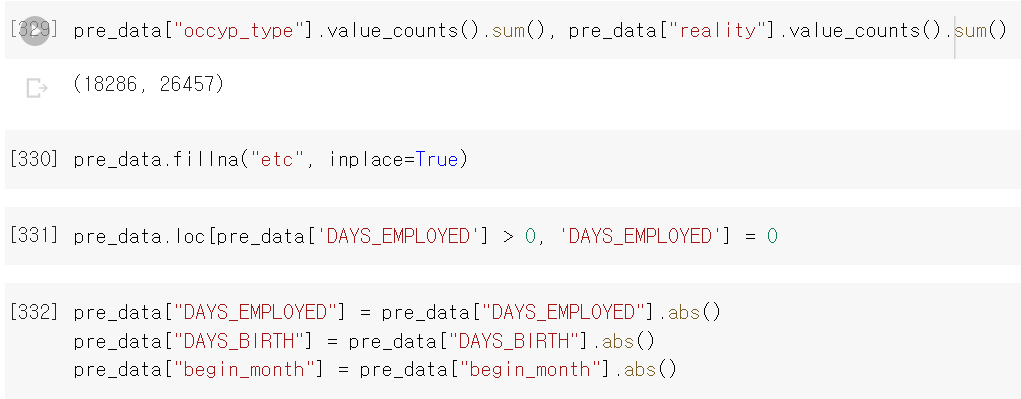
- 다른 컬럼과 Index값을 확인해보니 역시 컬럼의 총합이 다르다.
- 해당 값의 경우 직장이 없거나 직장의 분류가 확실하지 않기 때문에 발생으로 값으로 유추했기 때문에 값을 기타(etc)로 변경
- 그리고 Date 타입의 데이터는 음수값이 기준이기에 양수값으로 변경했다.
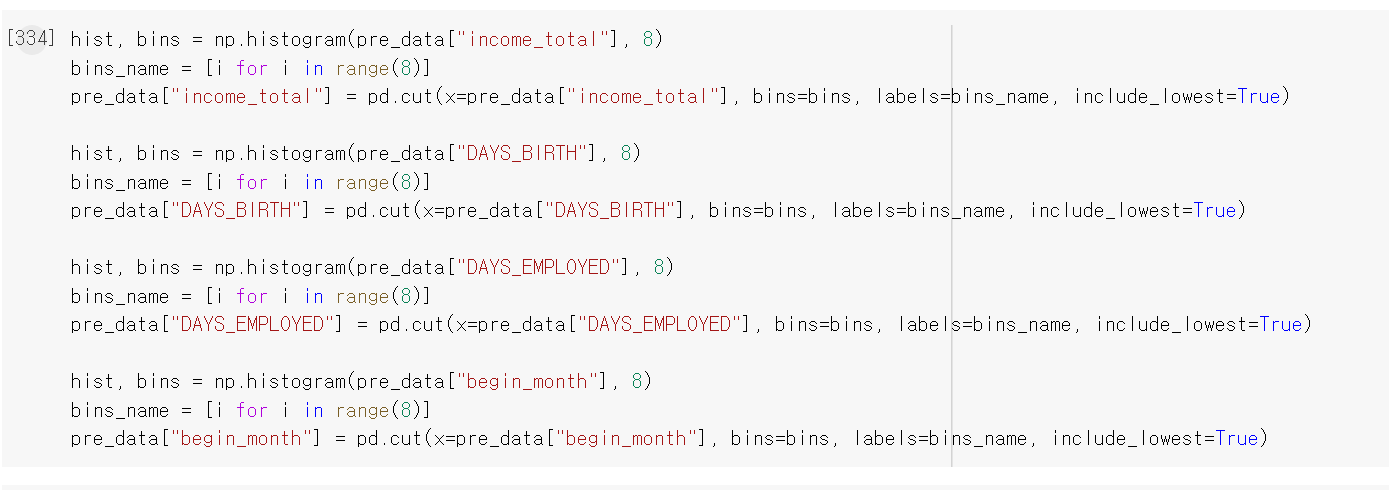
- 이제 각 연속형 자료의 구간을 정하고, 임의로 8개로 구분했다.
- 총수입, 나이(일), 근무기간(월), 카드사용기간(월) 등 4가지 자료를 구간별로 정리했다.
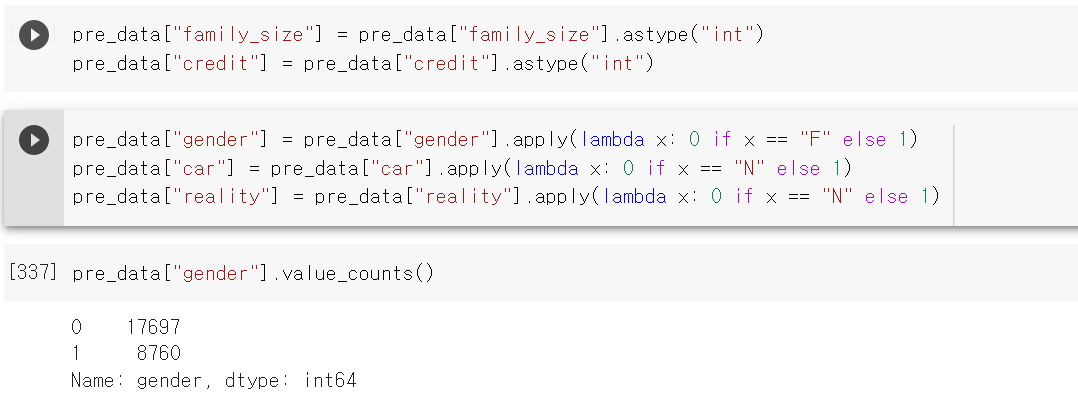
- 이후 라벨값인 credit과 가족 구성원 컬럼을 int값으로 변경 후,
- 이진 데이터인 성별, 차, 부동산 유무를 lambda를 통해 0과 1로 변경했다.

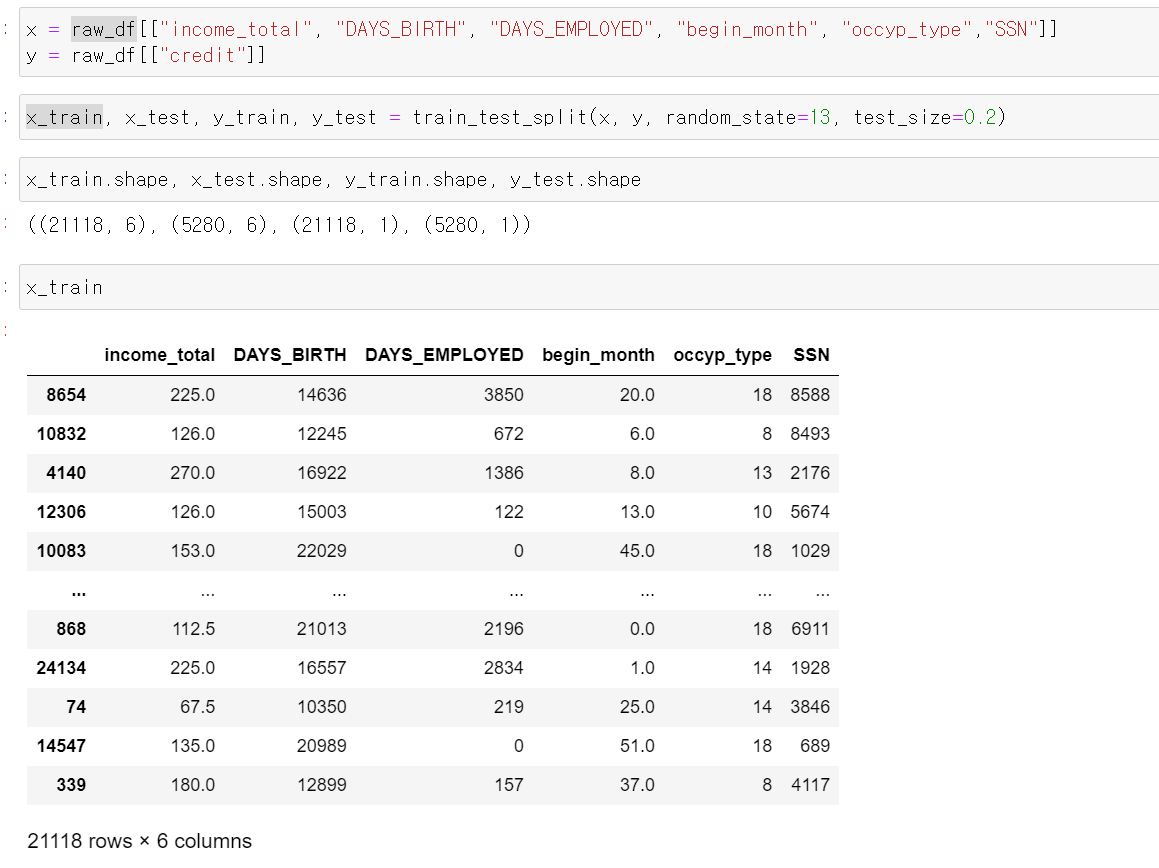
- 이제 머신러닝에 넣은 x, y값으로 구분하고 train_split sklearn으로 8:2로 x_train, x_test, y_train, y_test 4개로 구분했다.

- 그리고 등급으로 나눈 값에 라벨값을 줬다.
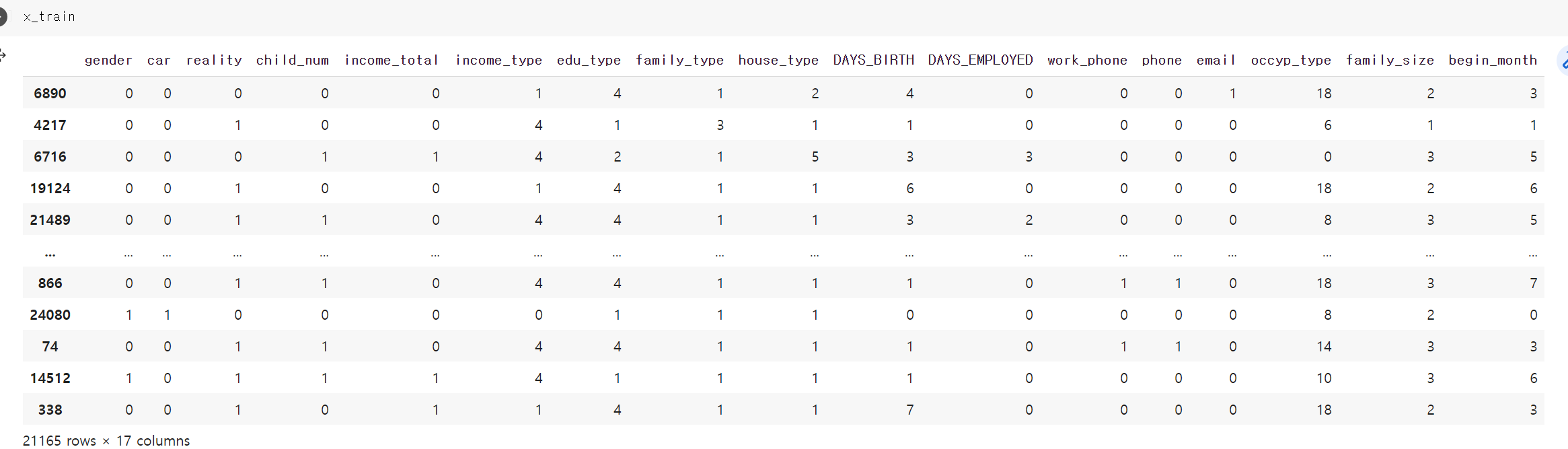
- 모든 자료의 값을 범주형 자료로 변환했다.
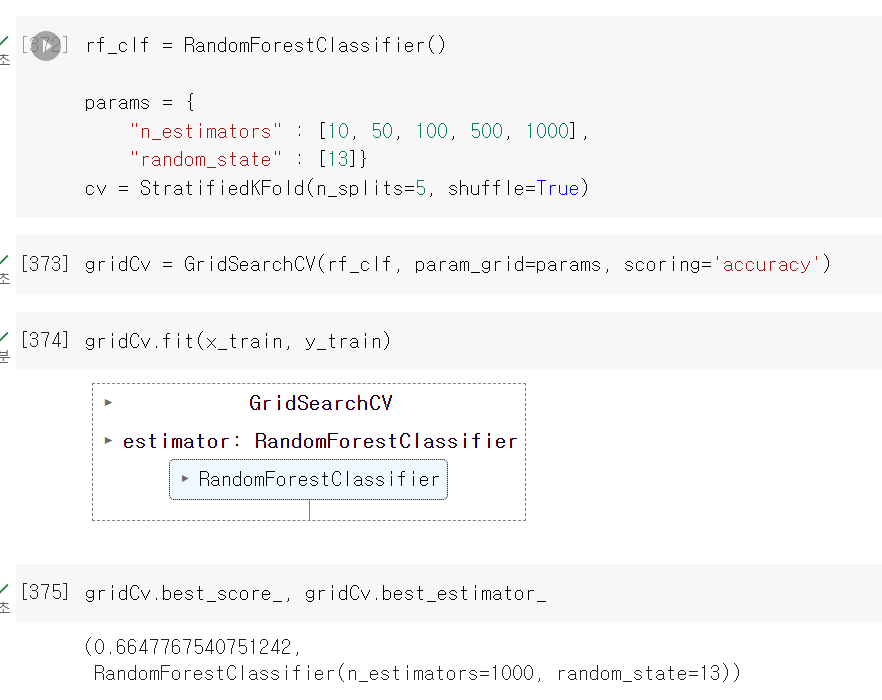
- 이제 Randomforest에 GridSearchCV로 5로 교차검증을 진행했다.
- 결과값은 처참했다. 그래도 EDA도 없고 데이터 전처리만으로 일단 모델링부터 했으니 큰 기대는 안했다.

- 그냥 시험삼아 test데이터 predict를 해서 넣어보니 역시 결과값이 낮다.

- 그러면 이제 제대로 log_loss에 GridSearchCV를 넣어서 결과값을 확인해보자
- 사실 해당 Label값이 3개의 결과값으로 출력되기 때문에 단순히 acuuracy_score로 성능을 테스트하기 어렵다.
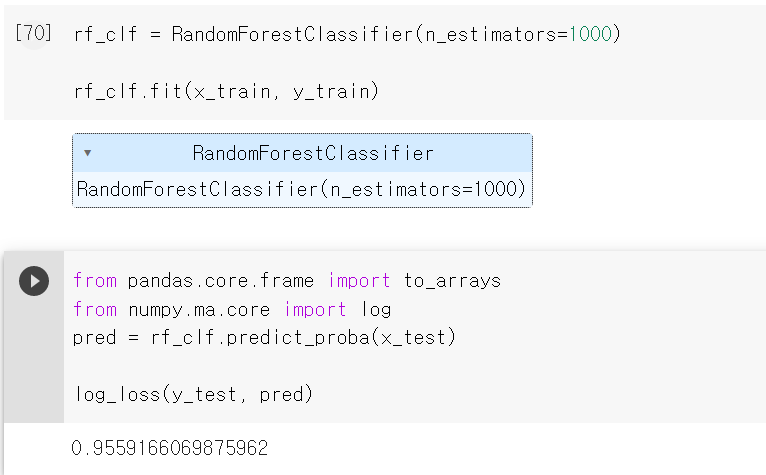
- 그래서 log_loss 모듈을 사용해 확률에 대한 정확도를 측정해보니 0.955 가까운 값이 출력됐다. 낮은 값일수록 높은 성능이기에 3일차에는 EDA를 기반으로 데이터 스케일 작업과 여러 머신러닝 기법을 통해 성능을 높여야겠다.
3일차
- 이제 다시 전처리부터 작업을 시작했다.
- 일단 무작정 머신러닝으로 돌려보고 모델 성능을 보니 처참해서 다시 처음부터 천천히 다시 봤다.
- 일단 가장 Binary type 데이터를 int형태로 바꿨줬다
- 그리고 직업 형태의 NaN값을 etc로 바꿨다. 사실 글을 쓰는 지금도 의문이다. 저 컬럼의 NaN값을 어떻게 처리할지 분명히 일을 한 적이 있는 사람인데 왜 직업의 형태는 NaN일까 그래서 일단 NaN도 결측치를 하나의 데이터로 생각했다.
- 필요없는 휴대폰 유무를 drop하고, int형태의 자료를 음수에서 양수값으로 바꿨다.
- 이제 남은 object타입의 자료와 연속형 자료만 처리하면 된다.
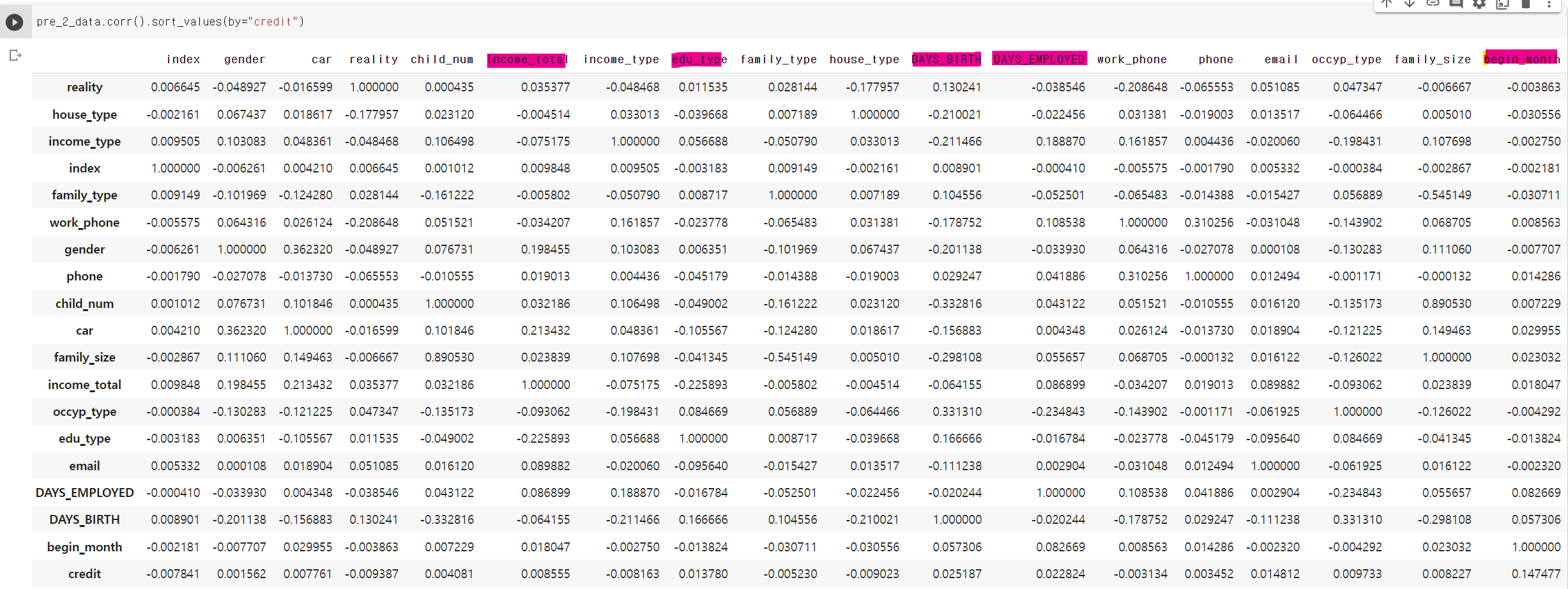
- 그전에 먼저 상관계수를 봤는데, 다시 보면서 중요한 사실을 깨달았다.
- 저기 표시한 값들이 상대적으로 높은 상관계수를 가지고 있는데 5개 중 4개 연속형 자료이다.
- 여기서 내가 멍청한 생각을 했다. 분명 라벨값이 범주형인데, 단순히 자료가 연속형이라고 다중회귀분석기법인 OLS를 돌리는 것은 어떨까? 생각한 것이다.
- 다하고 너무 바보 같아서 지워버렸는데 공식으로 cost function을 가장 낮은 회귀직선을 구하는 기법인데 왜 범주형 라벨에 사용했을까...그래도 acuuracy값은 더 높아졌다.
- 다음으로 생각한 방법은 MCA기법 다중요인분석을 통해 중요 feature값을 찾는 것이다. 하지만 KMO(Kaiser-Meyer-Olkin)값이 너무 낮게 나와서 중간에 그만뒀다. 참고로 0.6미만의 값이 나오면 다중요인분석은 쓰지 않는 것이 좋다.

- 내 생각의 흐름인데 음...아직도 참 많이 부족하다. 그래서 더 공부하고 싶다. 정말 많은 기법을 알아서 상황에 맞게 딱딱 문제를 해결할 수 있을 만큼
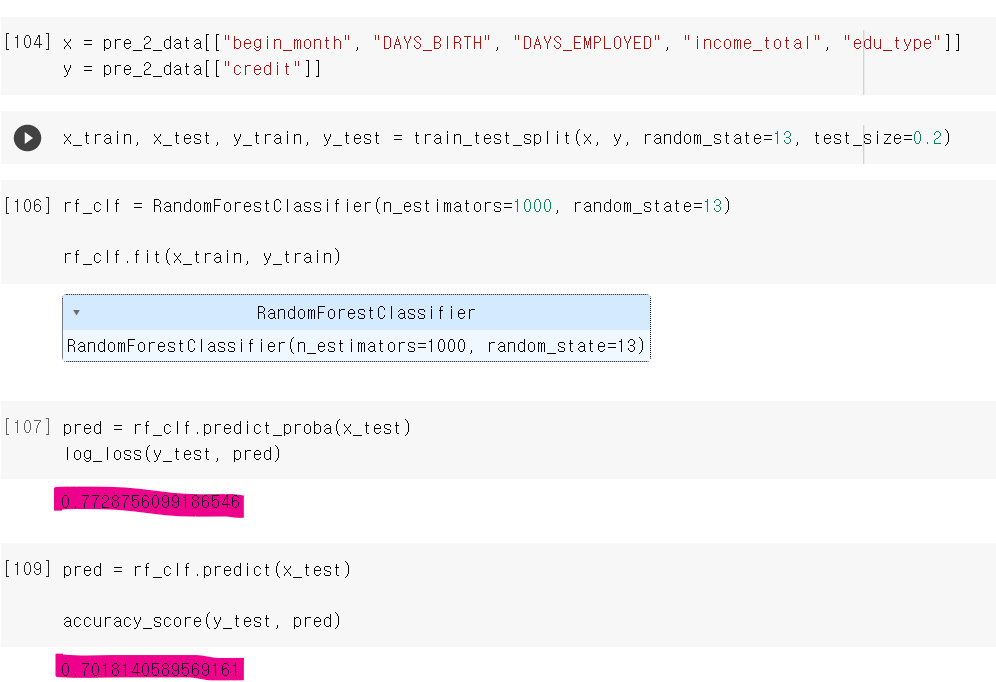
- 그래도 소득은 있었는데 저 여러 실패 과정을 통해 5개의 중요 feature값을 얻었고, 그 결과로 5개의 컬럼을 RandomForest에 돌려서 0.77의 log_los값을 얻고 70% 성능의 accuracy값을 얻었다.
- 이제 PipeLine으로 여러 모듈을 한 번에 출력하는 함수를 만들고, 데이터 분석에 중점을 둬서 여러 방면으로 분석하고 성능을 테스트해봐야겠다.
4일차, 함수 생성과 데이터 쪼개기
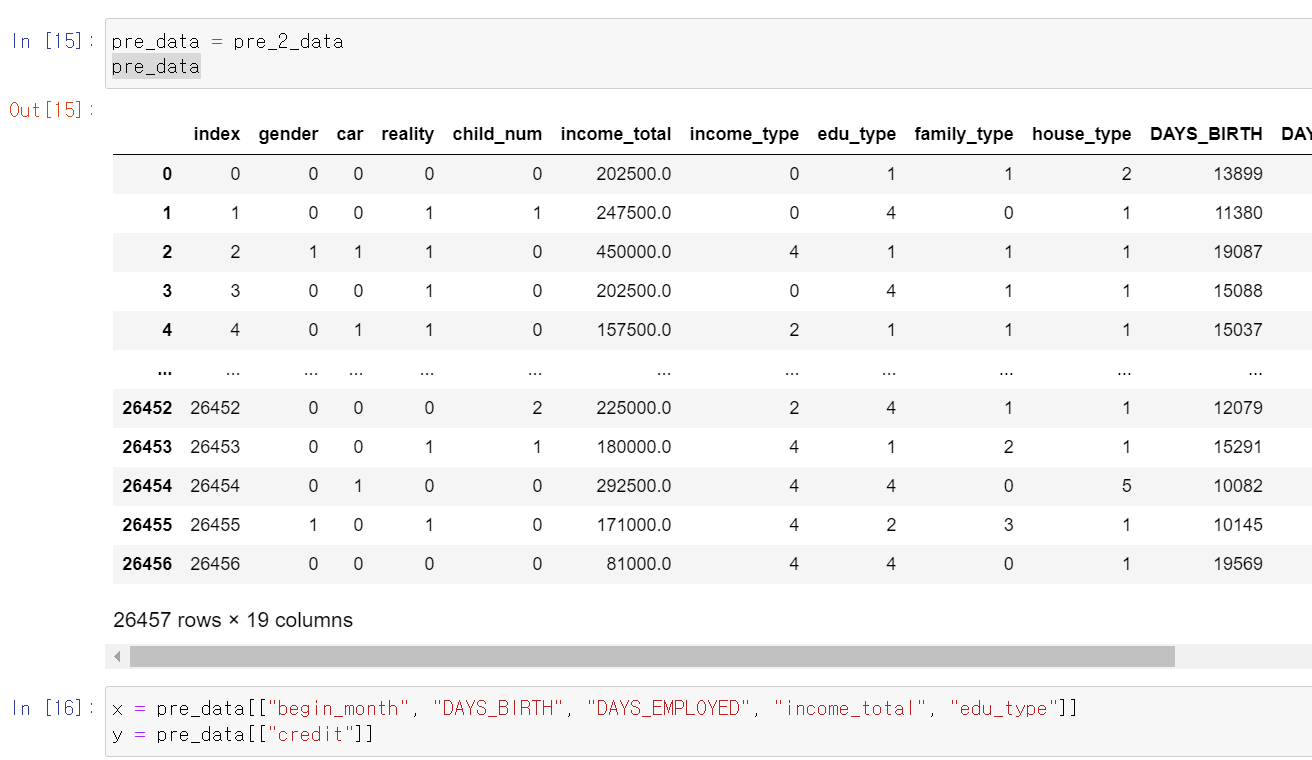
- 이제 다시 처음부터 해보는 마음으로 데이터를 다시 봤다.
- 일단 매번 모델링을 돌릴 수는 없으니까 함수를 만들기로 결심했다.
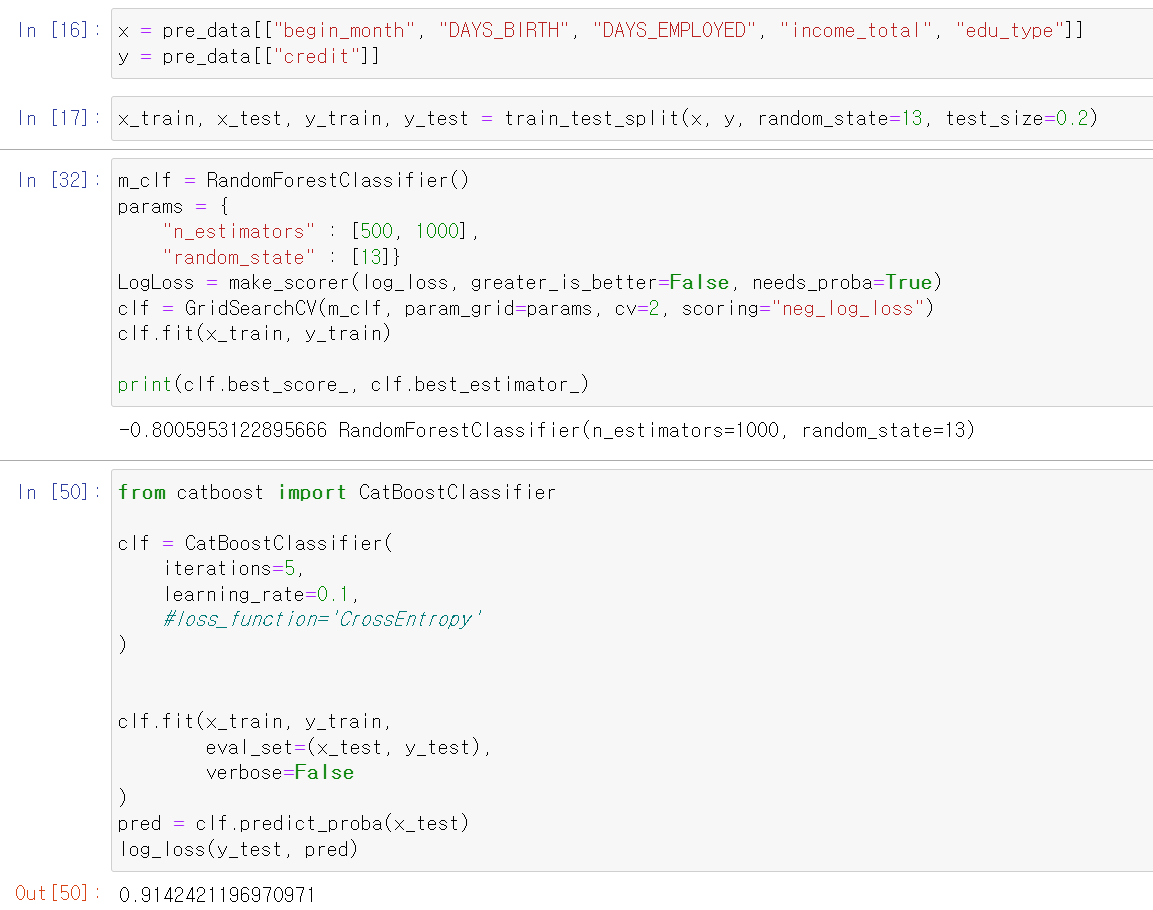
- 일단 catboost가 좋다는 구글링을 믿고 확인해봤다.
- 0.91...? 내가 잘못 돌린거겠지

- 음...일단 원래 쓰는 RandomForest와 xgbmboost를 써야겠다.

def log_loss_gridCv(x_train, y_train, x_test, y_test):
rf_clf = RandomForestClassifier()
xg = XGBClassifier()
# RandomFroest
params = {
"n_estimators" : [100, 500, 1000,2000],
"random_state" : [13]}
clf = GridSearchCV(rf_clf, param_grid=params, cv = 5, scoring="neg_log_loss")
clf.fit(x_train, y_train)
pred = clf.predict_proba(x_test)
print("RandomForest : ",clf.best_estimator_)
print("RandomForest_result : ",log_loss(y_test, pred))
print("=" * 50)
# xgbcBoost
xg = XGBClassifier()
params = {
"n_estimators" : [100, 500, 1000,2000],
"max_depth" : [3, 5, 7, 9],
"random_state" : [13]
}
clf = GridSearchCV(xg, param_grid=params, cv=2, scoring="neg_log_loss")
clf.fit(x_train, y_train)
pred = clf.predict_proba(x_test)
print("xgbm_best : ",clf.best_estimator_)
print("xgbm_result : ",log_loss(y_test, pred))- 이제 randomForest와 xgbcboost를 한 번에 gridSerchCV부터 최고 parameter로 예측까지 해주는 함수를 만들었다.
- 점점 함수의 위력을 실감한다. 진짜 너무 편하다.
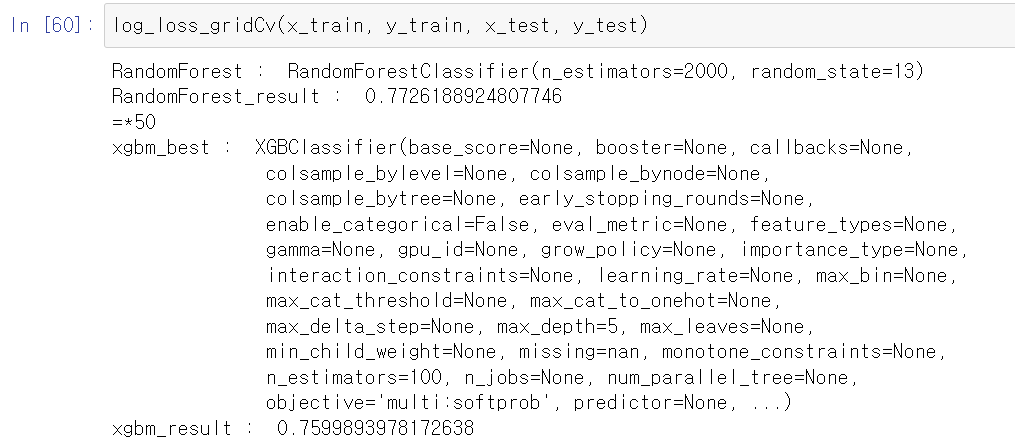
- 이제 train, test 데이터를 넣기만 하면 바로 출력된다.

- 이번에는 스케일 값을 바꿔봤다.
- 일단 MinMax값으로 바꾸고, 자동차와 부동산 소유 유무를 하나의 컬럼으로 합쳐서 확인해봤다.
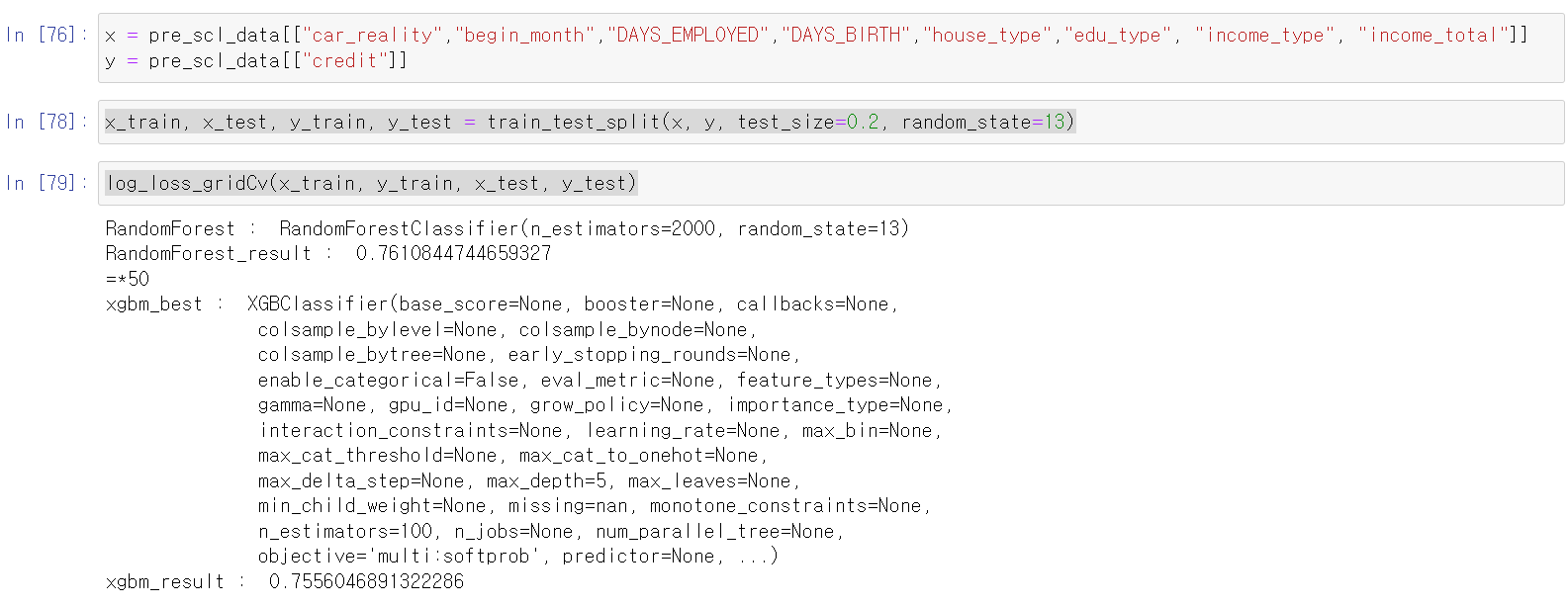
- 음 결과의 큰 변화는 없는 것 같다.
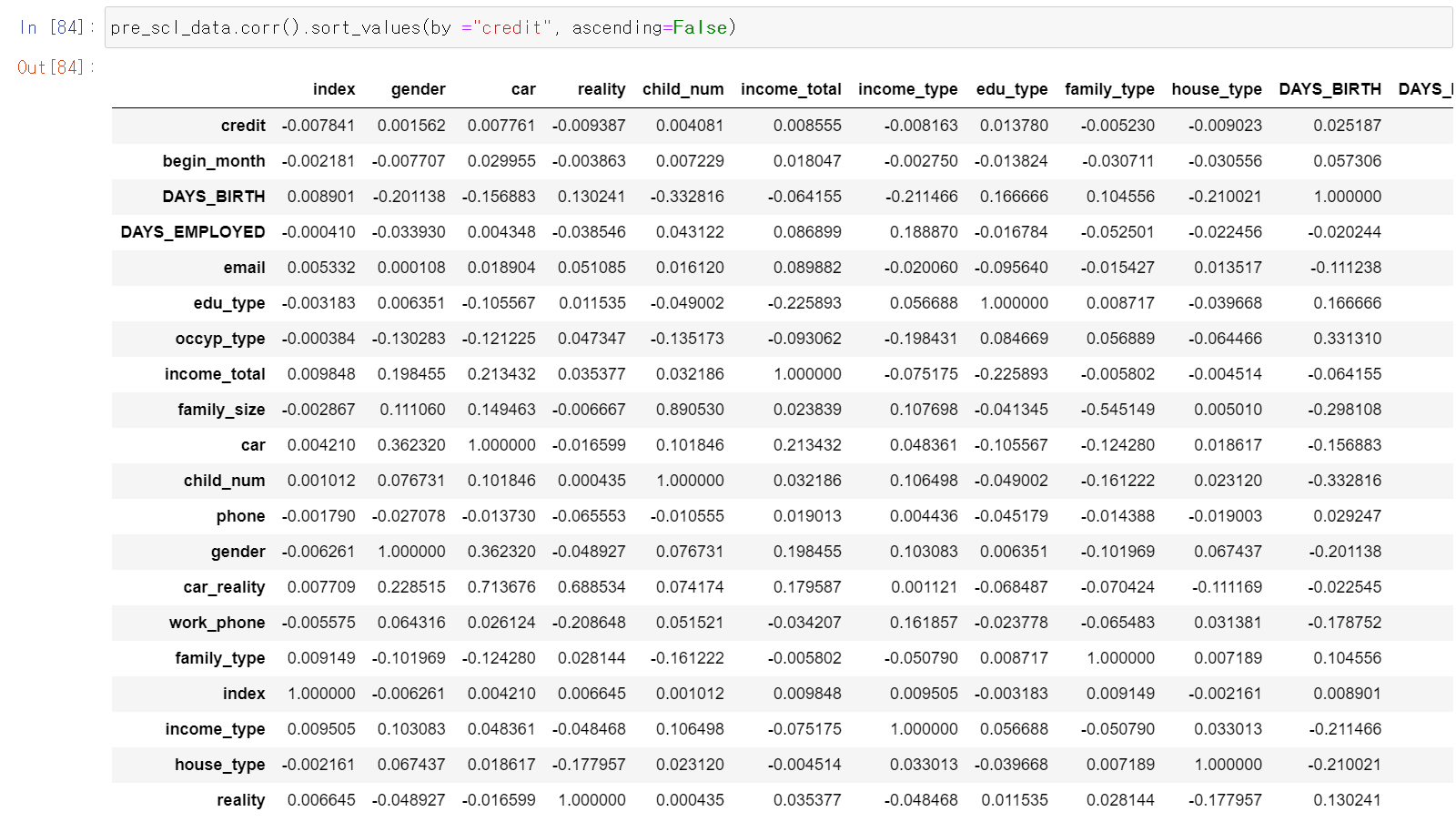
- 다시 상관계수를 확인하고, 데이터를 꼼꼼히 확인해봤다.
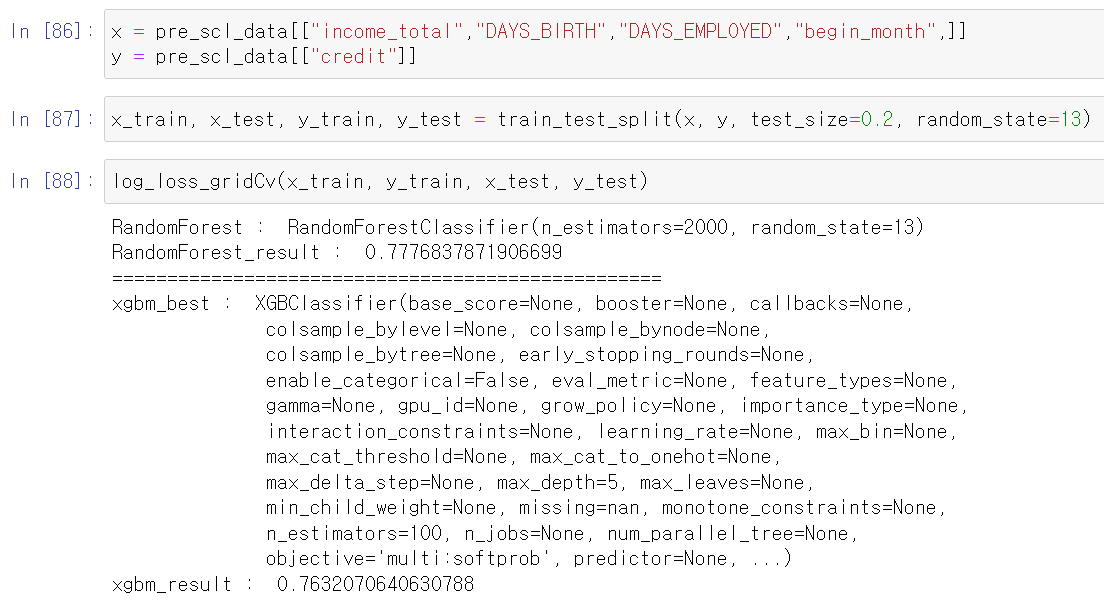
- 혹시 몰라서 연속형 변수만을 가지고 성능을 테스트해보니까 성능이 조금 더 안좋아졌다.
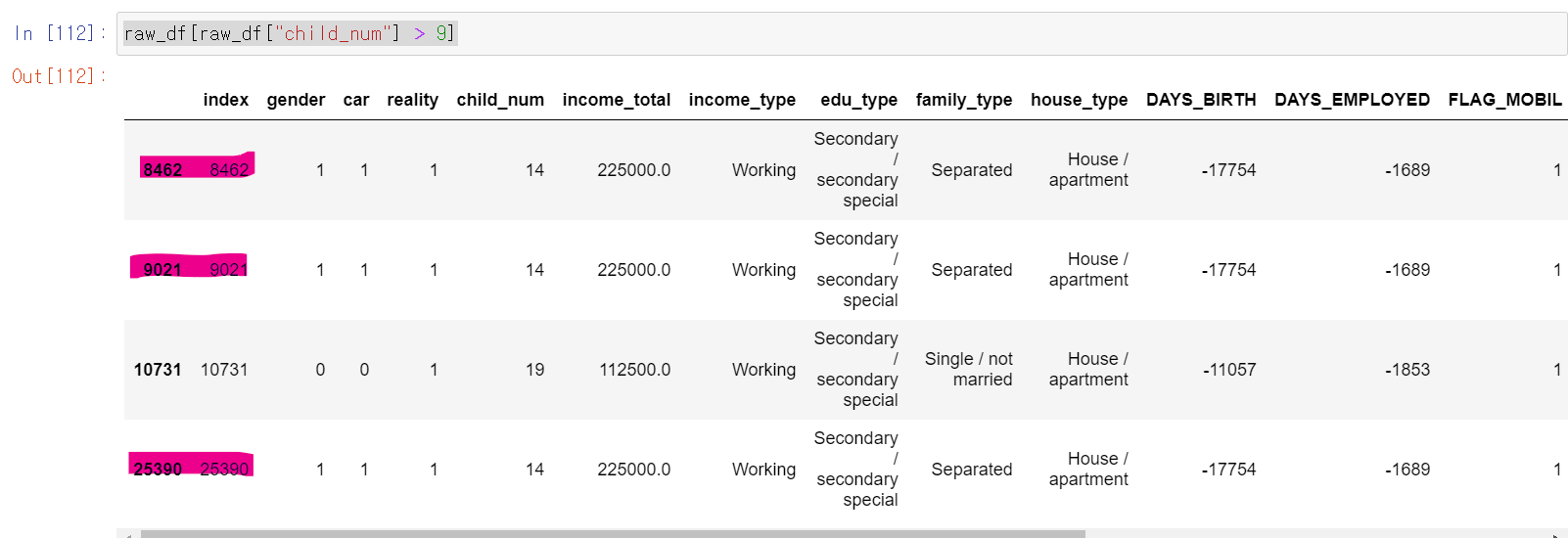
- 그때 이상치값이라도 잡아서 돌려돌까 싶어서 조건을 넣어 검색했는데, 저 3개의 인덱스가 카드를 발급 날짜만 다르고 다른 모든 값이 같았다.
- 이 말은 한 명의 사람이 여러 데이터로 축적된 것을 의미했다.
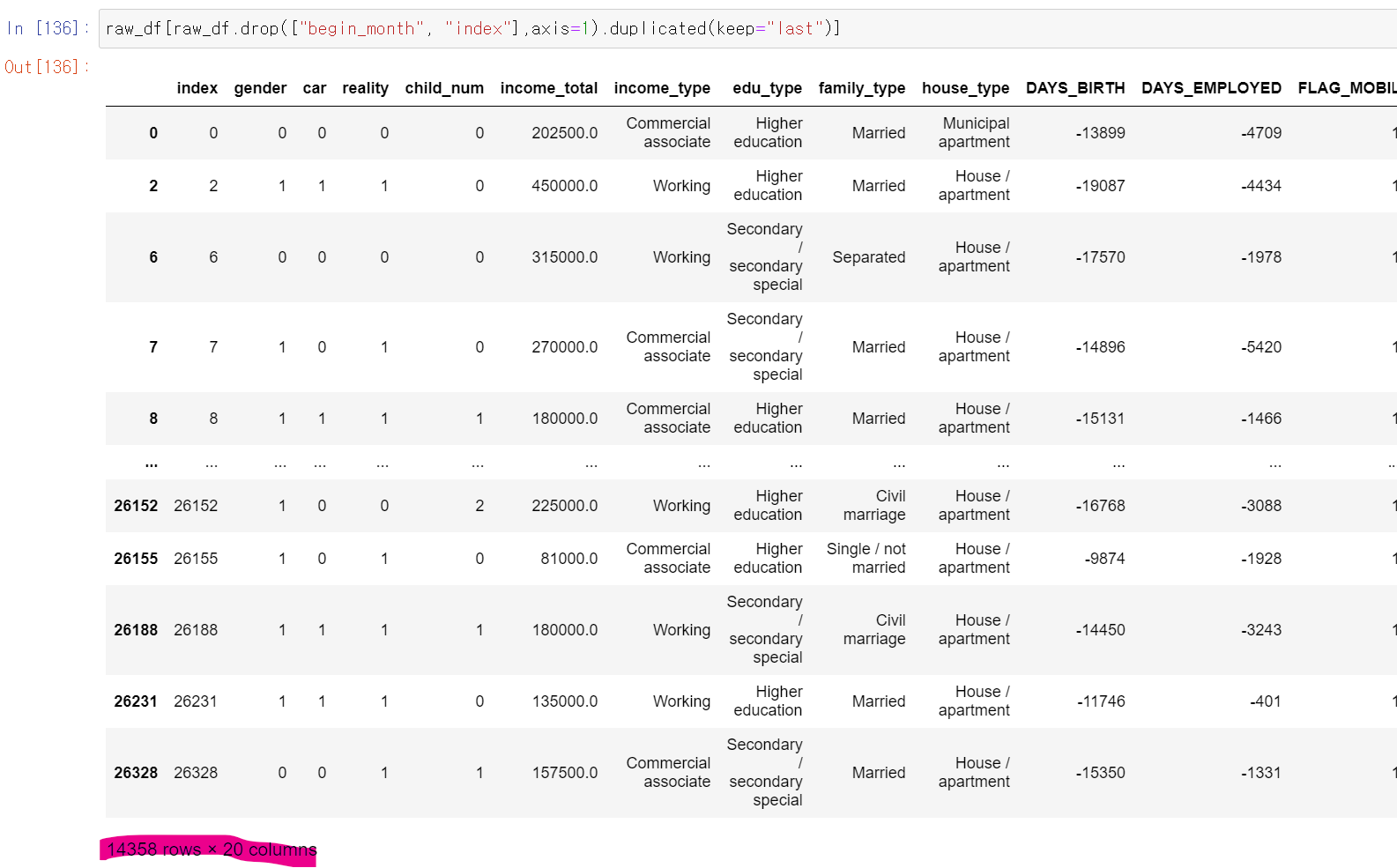
- 바로 확인해보니까 역시나 중복 데이터가 엄청 많았다.
- 그래서 든 생각이 중복값만 돌리거나, 아니면 사람마다 고유 ID를 가질 수 있는 새로운 컬럼을 만들어서 내일 다시 돌려야겠다고 생각했다.
- 머신러닝에서 통계분석을 기반으로 논리적 사고도 물론 중요하지만, 계속 해보고 성능을 테스트해보면서 최선의 분석을 찾고 성능을 높여보자
5일차, 데이터 분석과 모델링의 반복
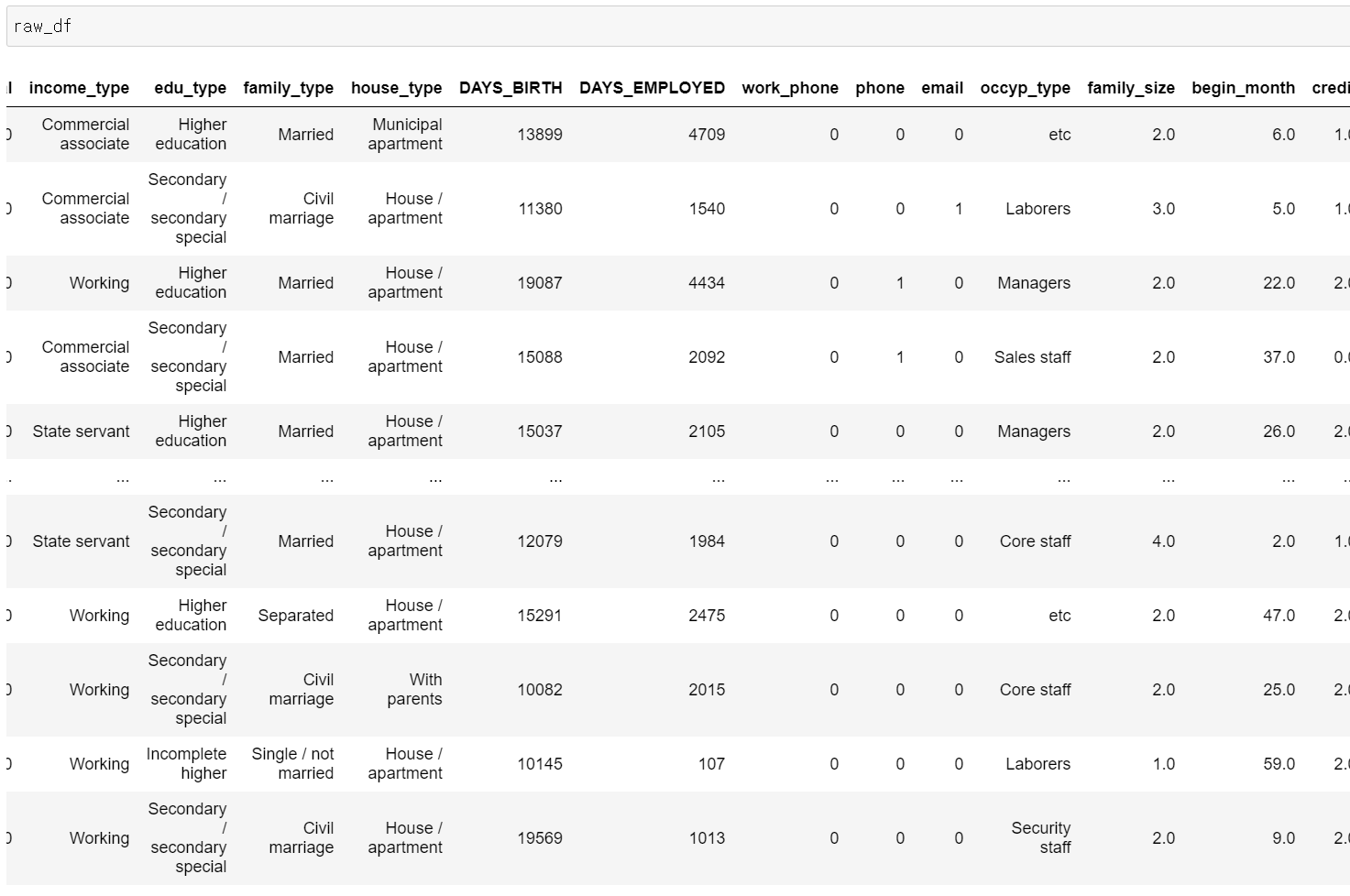
- 어제 중복값이 많다는 것을 확인하고, 데이터 분석 영역이 더 필요한 것 같아서 데이터를 더 관찰했다.
- 가장 먼저 이상치 데이터를 발견하고
- 해당 이상치 데이터를 제거하고, 필요없는 컬럼을 버렸다.
- 그리고 직장 경력이 없는 값을 0으로 통일하고, 직장의 유형이 없는 경우 etc로 바꿨다. 여기서 또 하나 관찰한 것이 직장이 없거나 유형이 없는데 총 수입이 높길래 무엇인지 보니 연금 또한 수입으로 측정된 것이었다.
- 이제 데이터 가공을 하고 다시 데이터를 관찰했다.
- 참 이 부분에서 진전없는 관찰을 많이 한 것 같다. 그냥 어떻게 하면 label를 특정할 수 있는 feature를 만들 수 있을까 생각했다.
- 그래서 다시 데이터 분석 및 시각화로 돌아갔다.
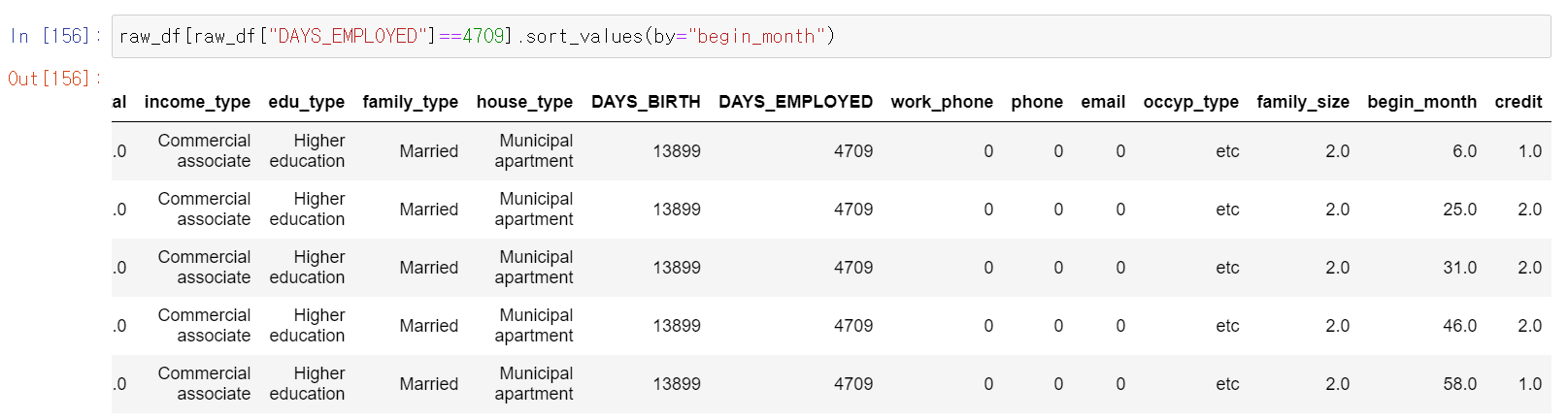
- 근무 경력을 기준으로 몇개의 중복 데이터를 찾아봤다.
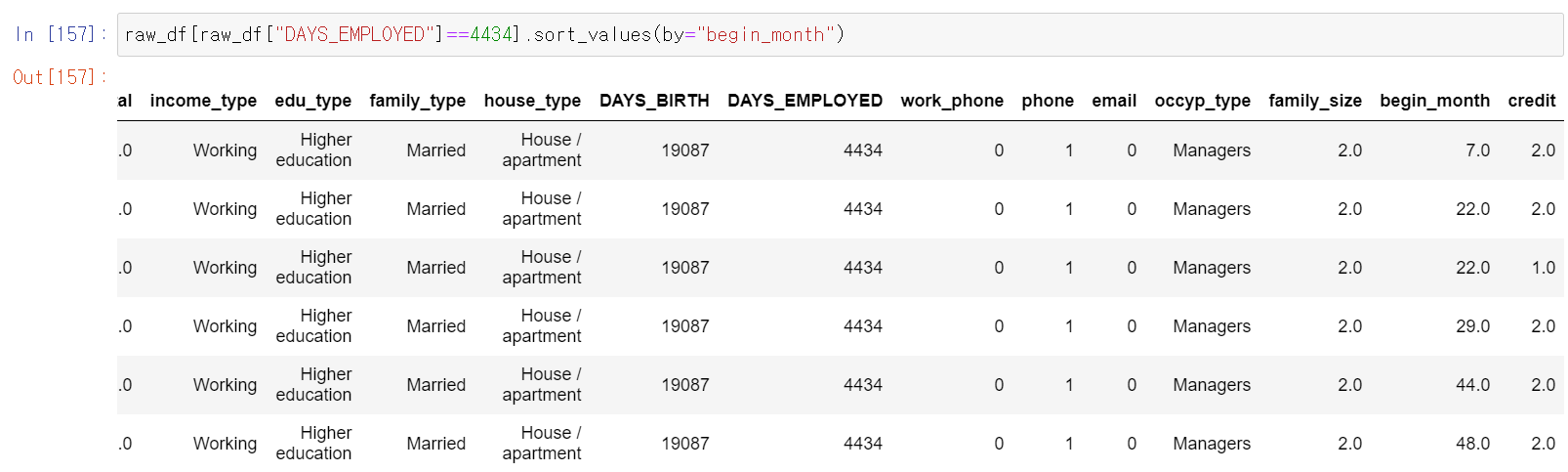
- 생각보다 한 사람의 ID값으로 많은 카드가 발급이 된 것인지, 아니면 데이터가 중복으로 축적이 되었는지는 모르겠다. 다만, begin_month를 제외한 데이터를 하나의 값으로 모으면 한 사람의 고유 값을 얻을 수 있겠다 생각했다.
- 일단 분석을 위해 반복작업을 간단하게 함수로 만드록
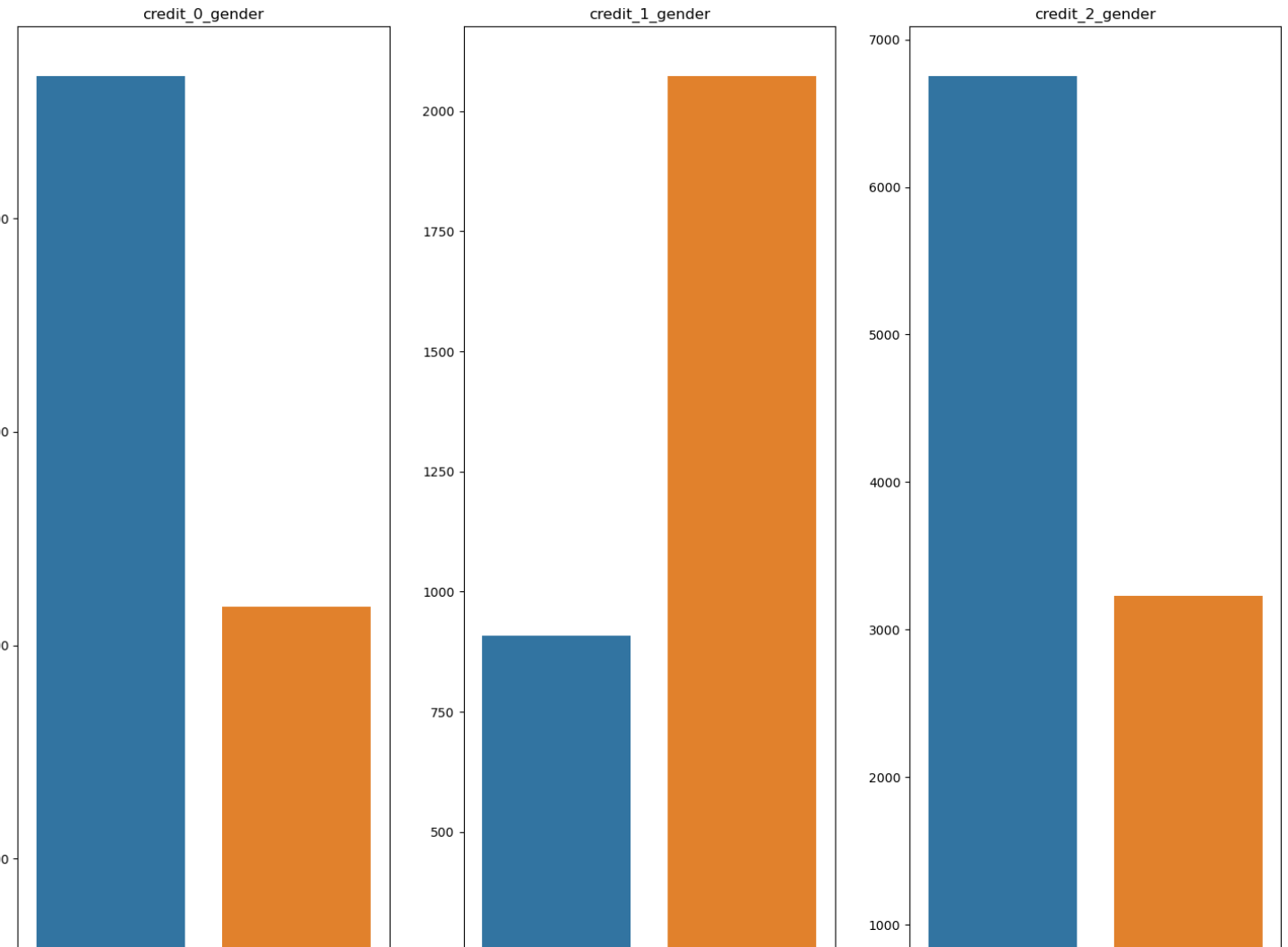
- 이번에는 credit(라벨값)에 따라 시각화를 분석했다.

- 이건 연속형 데이터 시각화를 위한 함수이다.
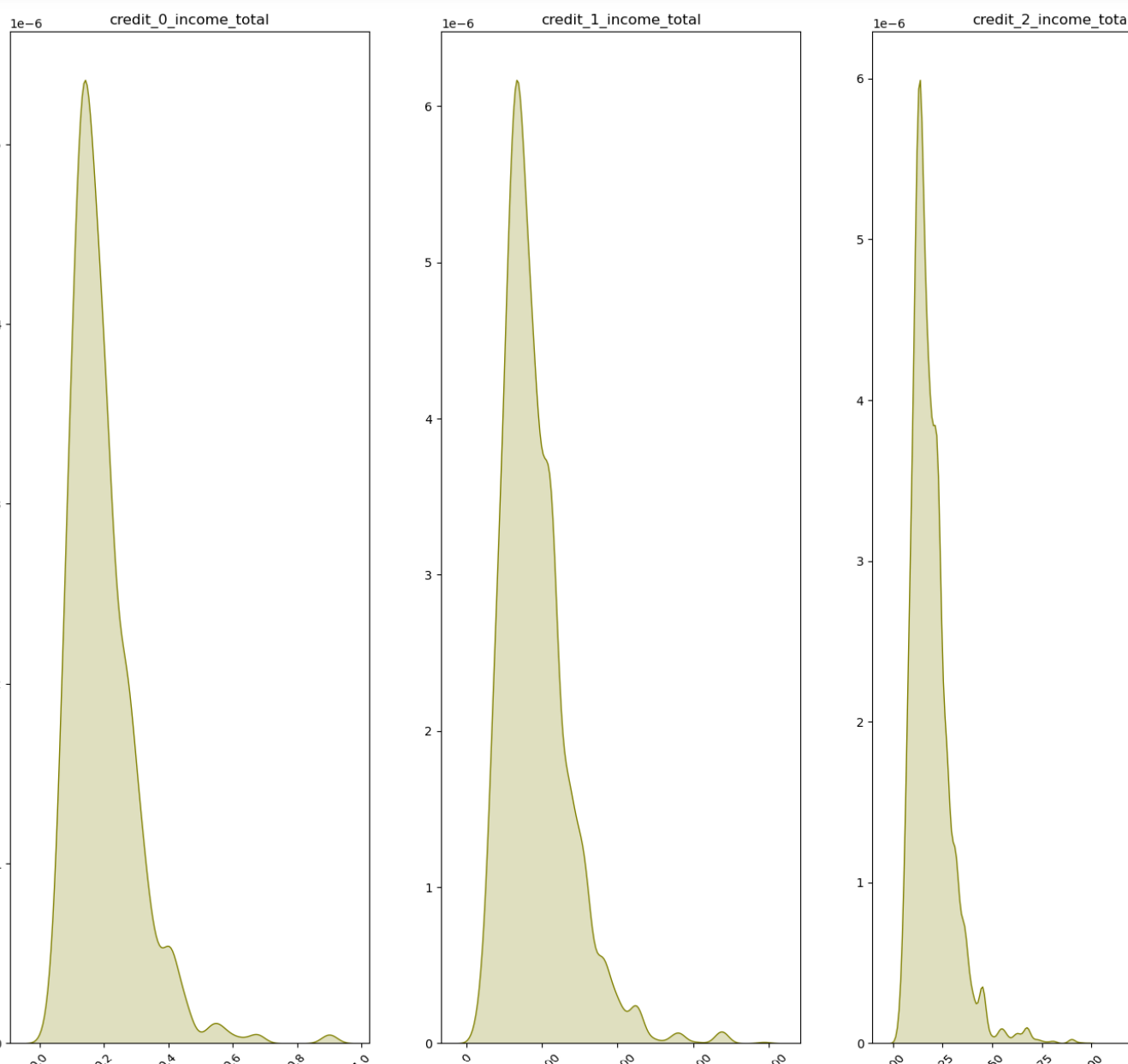
- 참 비슷하다.
- 어떻게 이 주어진 데이터로 구분을 할 수 있을까 고민한 것 같다.
- 여기서 여담으로 나는 머신러닝과 데이터 분석의 별개의 영역이라고 생각했는데, 결국 분석을 토대로 머신러닝을 돌리니 결국 하나의 세트구나 많이 생각하고, 분석의 중요성을 다시 생각했다.
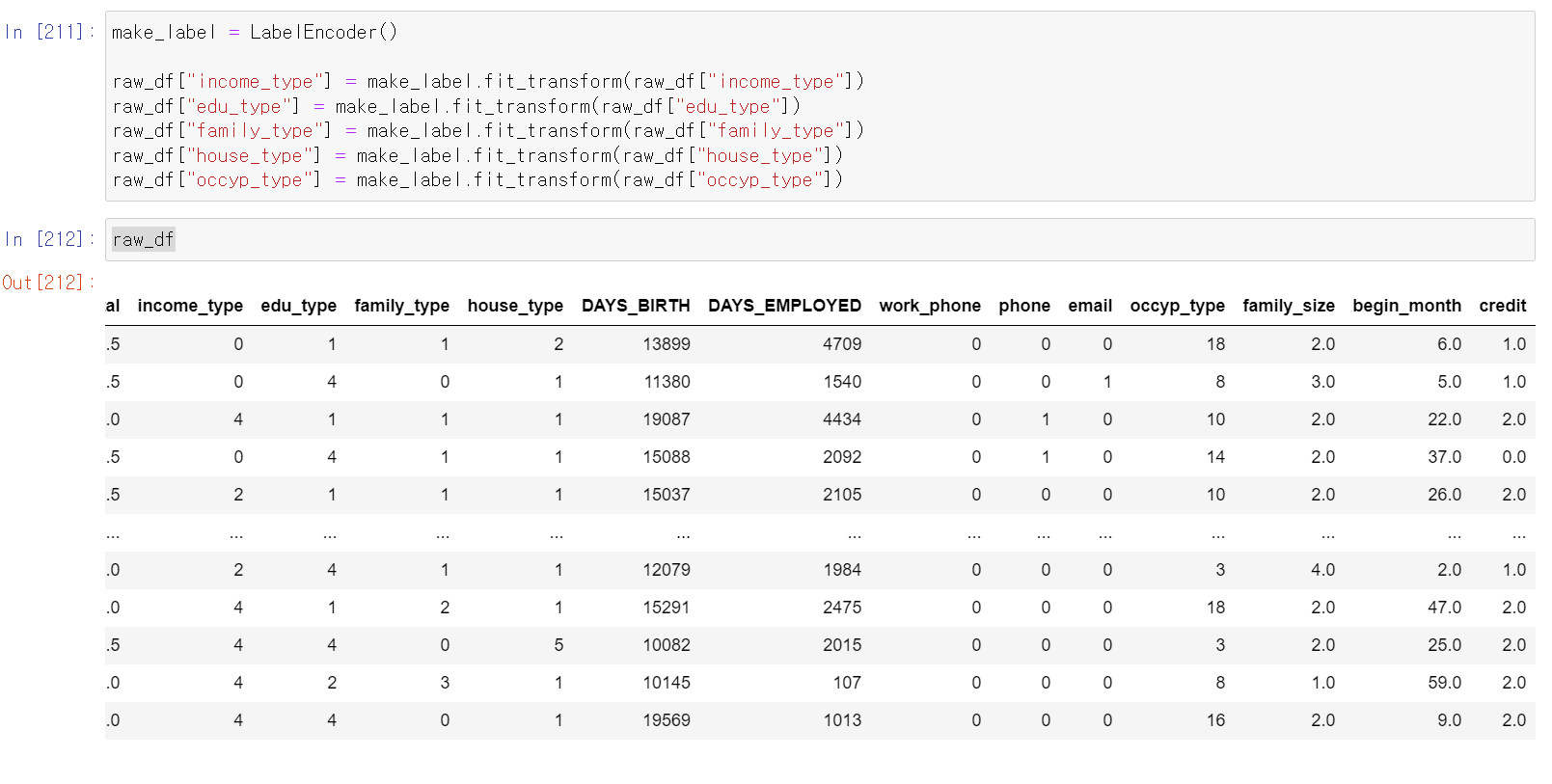
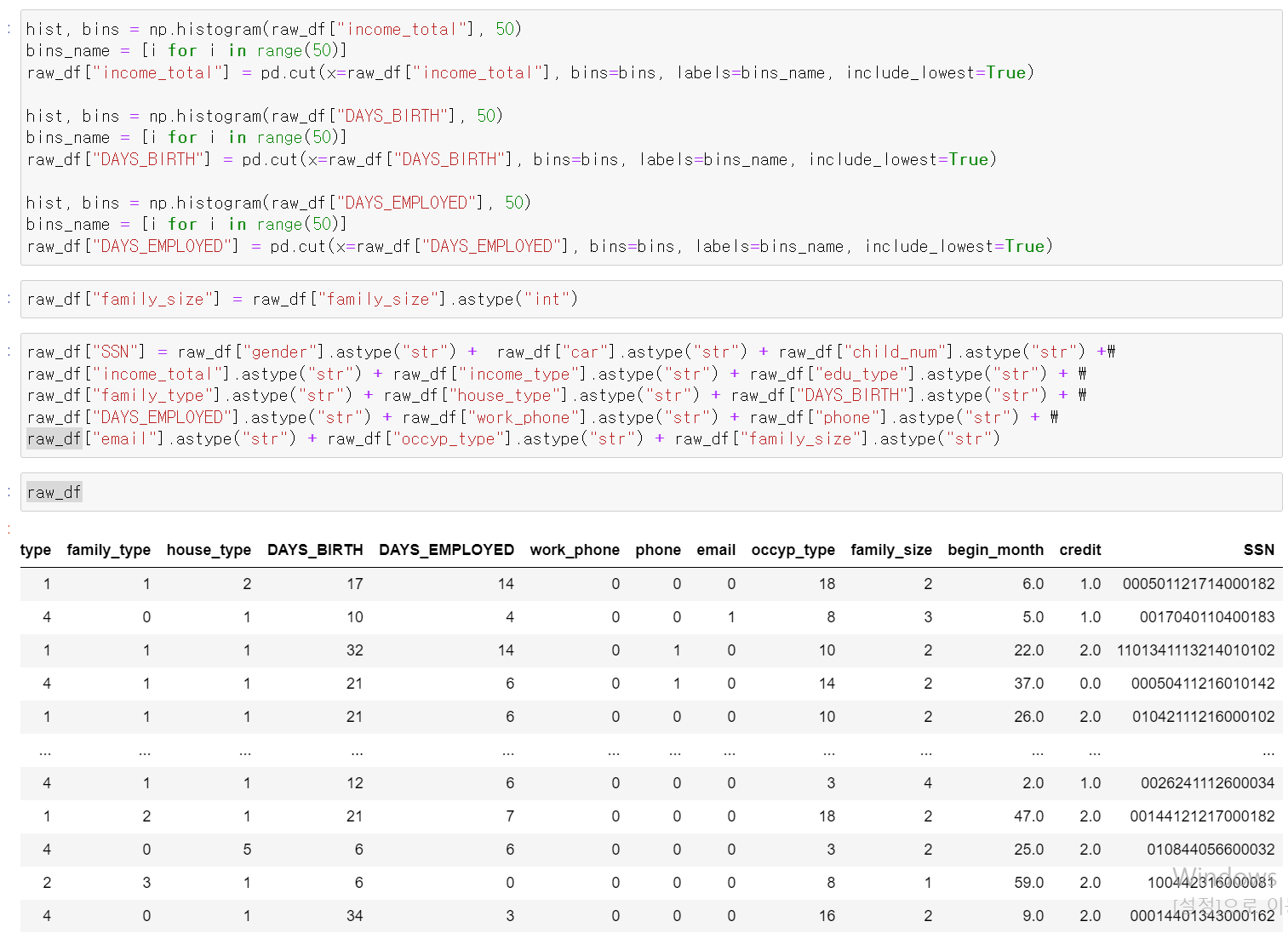
- 이제 범주형 자료를 Label로 인코딩하고
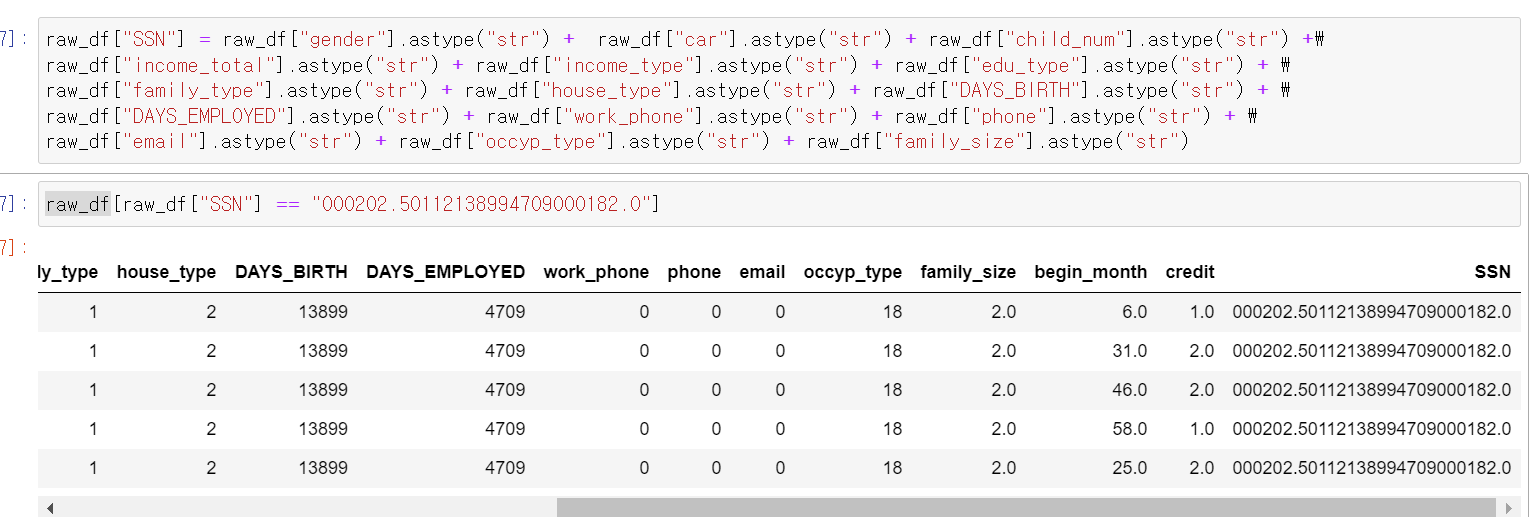
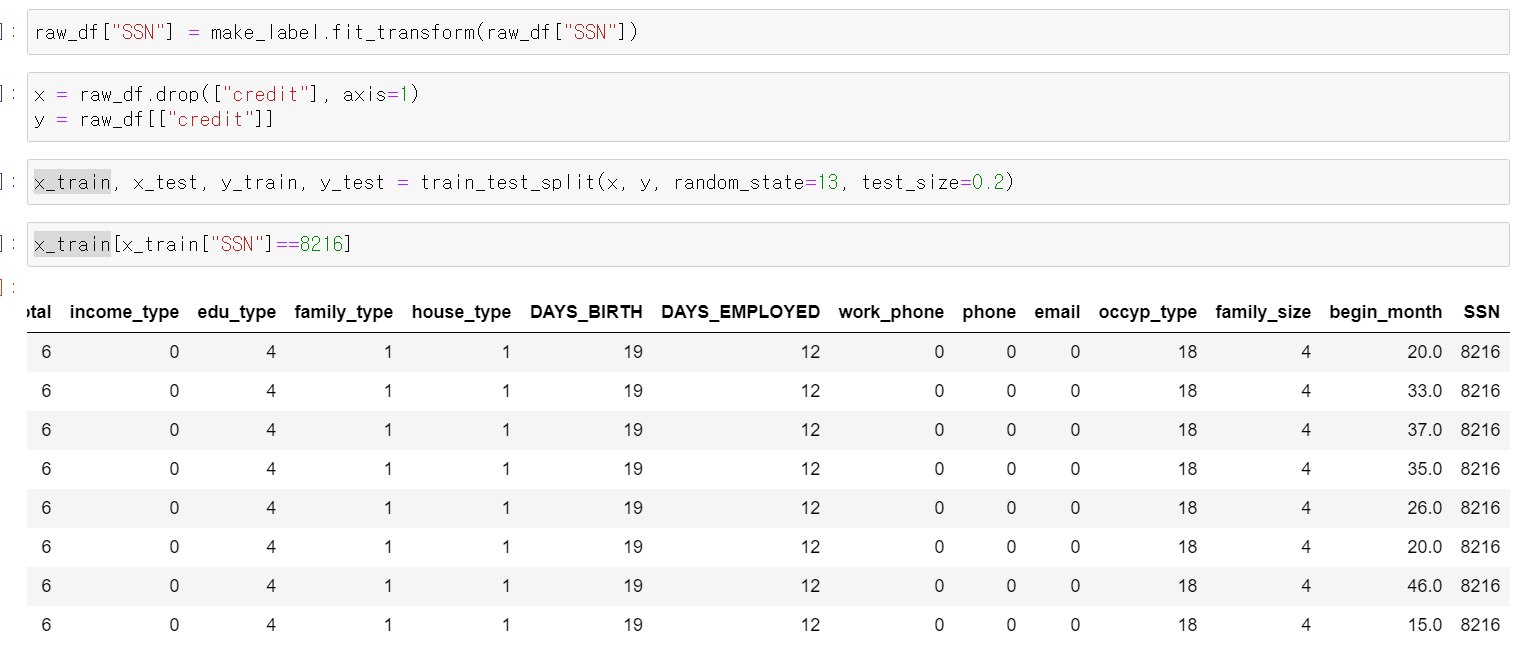
- 이제 아까 말한 개인의 고유ID 컬럼을 만들어서 관찰을 해보자
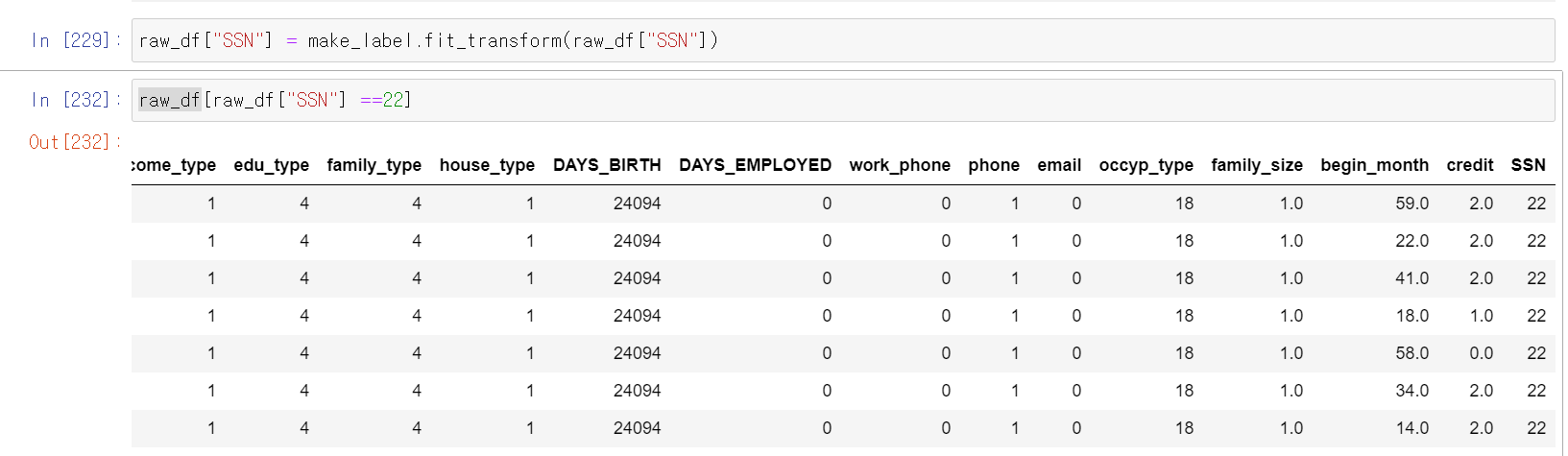
- 이제 개인 번호 22인 데이터인 사람은 credit이 2로 관찰된다.
- 이제 나눠서 분석을 해보자
- 근데 한발자국 더 나가서 다른 생각을 했다.
- 총수입, 연생, 근무경력을 연속형 자료 그대로 고유ID에 쓰면 너무 과적합한 컬럼이 아닐까?
- 여기서 머신러닝의 목적을 다시 한 번 생각해봤다. 내가 어떤 데이터로 교육시켜야 컴퓨터가 똑똑하게 label를 구분할까? 그래서 수입과 나이, 근무경력 등을 도수분포화 시켜서 고유ID(사실 이제 고유는 아니지만)값으로 넣었다.
- 이제 해당 데이터셋을 RandomForest, xgbcBoost, lgbmBoost에 돌려보자
- 돌려봤는데 에러가 뜨고 성능이 낮아졌네....내일 다시 다르게 돌려봐야겠다.
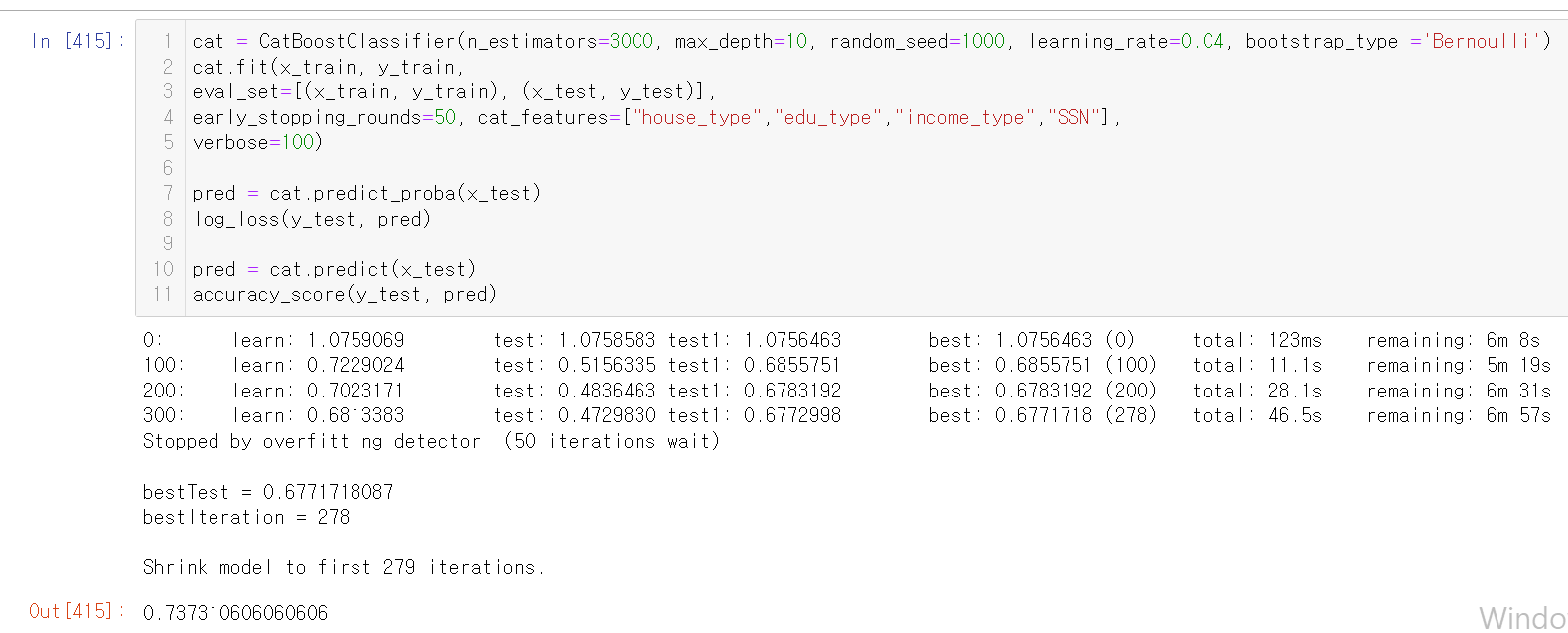
- 됐다. log_loss 값이 0.67로 엄청 낮게 나왔다.
- catBoost를 사용하니 엄청난 성능을 보였다.
- 이제 회귀분석을 사용하는 데이터를 분석해보고 싶다.
6일차, feature_analysis
- 6일차에는 feature들을 활용해 여러 방면으로 사용해봤다.
def log_loss_gridCv(x_train, y_train, x_test, y_test):
xg = XGBClassifier()
lgbm = LGBMClassifier()
# xgbcBoost
xg = XGBClassifier()
params = {
"n_estimators" : [1000, 2000],
"max_depth" : [5, 9],
"random_state" : [13]
}
clf_grid = GridSearchCV(xg, param_grid=params, cv=2, scoring="neg_log_loss")
clf_grid.fit(x_train, y_train)
df_importance = pd.DataFrame(columns=clf_grid.feature_names_in_)
pred = clf_grid.predict_proba(x_test)
print("xgbm_best : ",clf_grid.best_estimator_)
print("xgbm_result_loss: ",log_loss(y_test, pred))
pred = clf_grid.predict(x_test)
print("xgbm_result_ac : ", accuracy_score(y_test, pred))
df_importance.loc[0] = clf_grid.best_estimator_.feature_importances_.tolist()
print("=" * 50)
#lgbm
params = {
"n_estimators" : [1000, 1500, 2000],
"random_state" : [13]
}
clf_grid = GridSearchCV(lgbm, param_grid=params, cv=2, scoring="neg_log_loss")
clf_grid.fit(x_train, y_train)
pred = clf_grid.predict_proba(x_test)
print("lgbm_best : ",clf_grid.best_estimator_)
print("lgbm_result_loss : ",log_loss(y_test, pred))
pred = clf_grid.predict(x_test)
print("lgbm_result_ac : ", accuracy_score(y_test, pred))
df_importance.loc[1] = clf_grid.best_estimator_.feature_importances_.tolist()
print("=" * 50)
cat = CatBoostClassifier(n_estimators=3000, max_depth=10, random_seed=1000, learning_rate=0.04, bootstrap_type ='Bernoulli')
cat.fit(x_train, y_train,
eval_set=[(x_train, y_train), (x_test, y_test)],
early_stopping_rounds=50,
verbose=100)
pred = cat.predict_proba(x_test)
print("cat_log_loss : ",log_loss(y_test, pred))
pred = cat.predict(x_test)
print("cat_ac_score : ",accuracy_score(y_test, pred))
df_importance.loc[2] = cat.feature_importances_.tolist()
df_importance.rename(index={0 : "XGBC", 1 : "LGBMC", 2 : "Cat"})
return df_importance- 위 코드는 3개의 모델링을 학습하고, 출력하며 feature들의 중요도를 return하도록 만들었다.
- 함수의 위대함일까...정말 너무 편하다...파이썬 최고
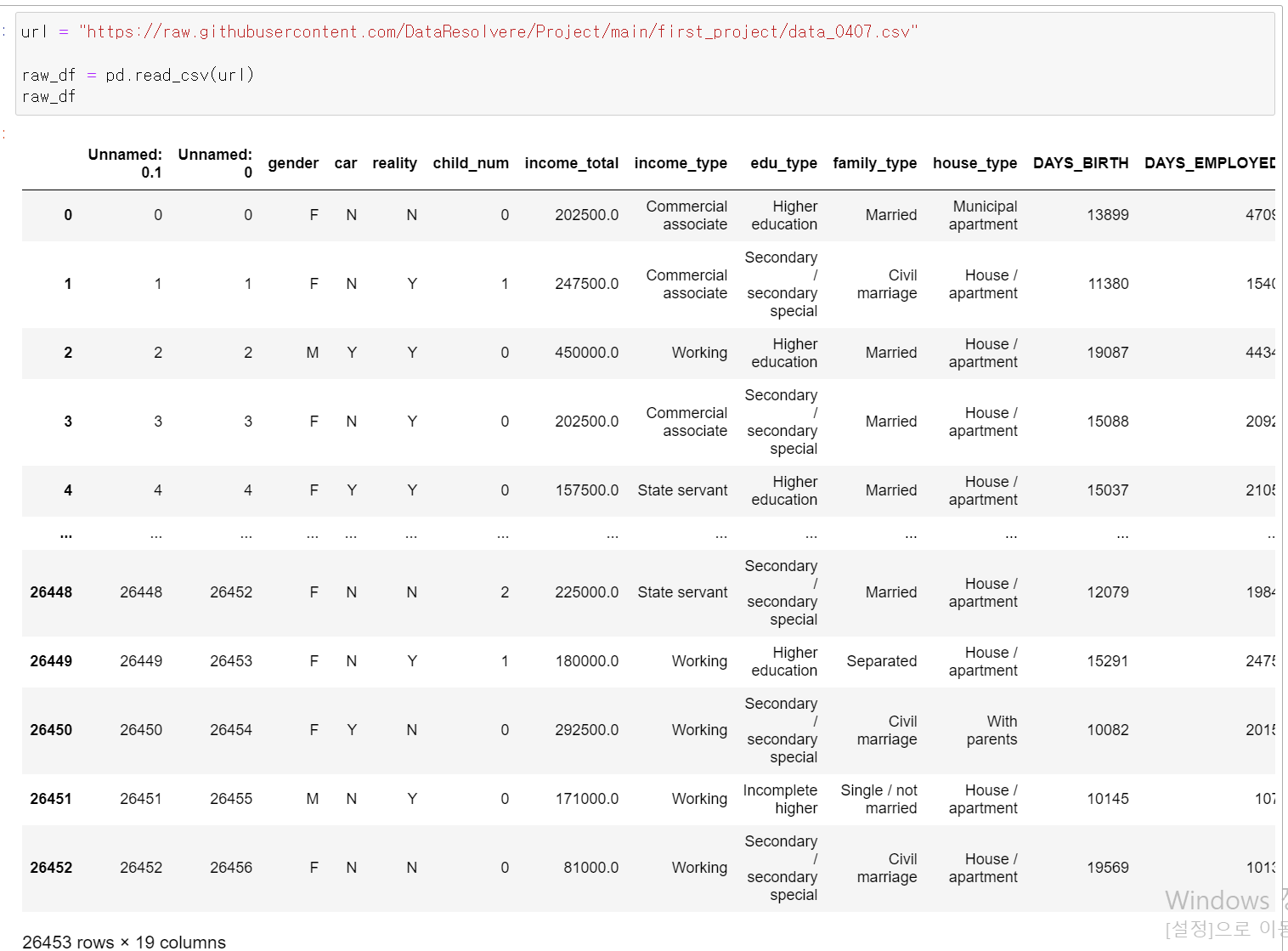
- 다시 원본 데이터를 보면서 어떻게 처리할지 고민을 해봤다.
- 이 단계가 정말 힘든 것 같다. 가정을 세우고 데이터를 전처리하고 분석하는 것은 구굴링, 기존의 알던 함수를 통해 할 수 있지만 가정을 세우고 결과를 만든다는 것은 정말 힘들다.
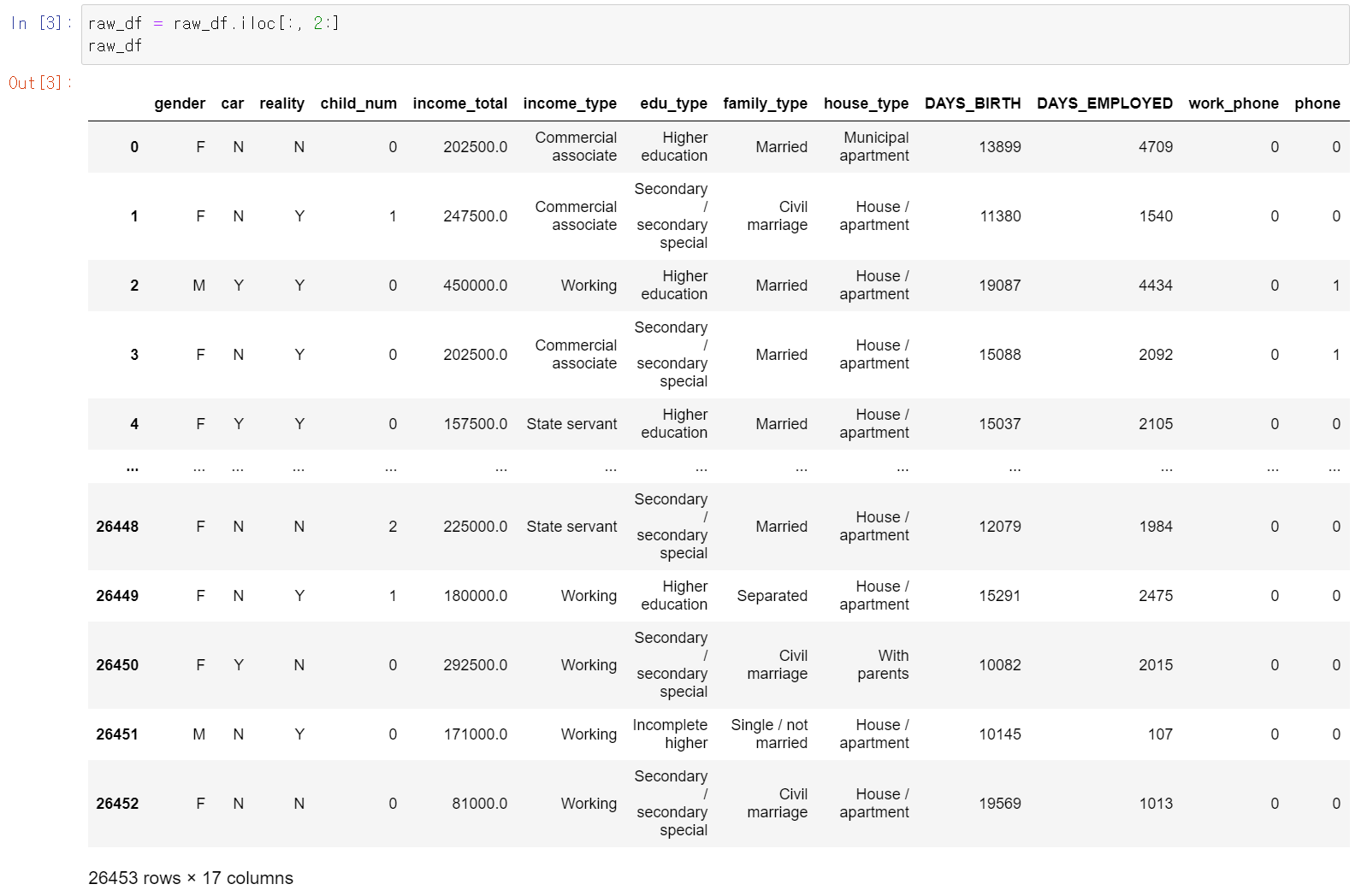
- 이제 앞에 필요없는 두 개의 컬럼을 삭제했다.

- 그리고 binary형태의 자료를 int형태로 변환했다.
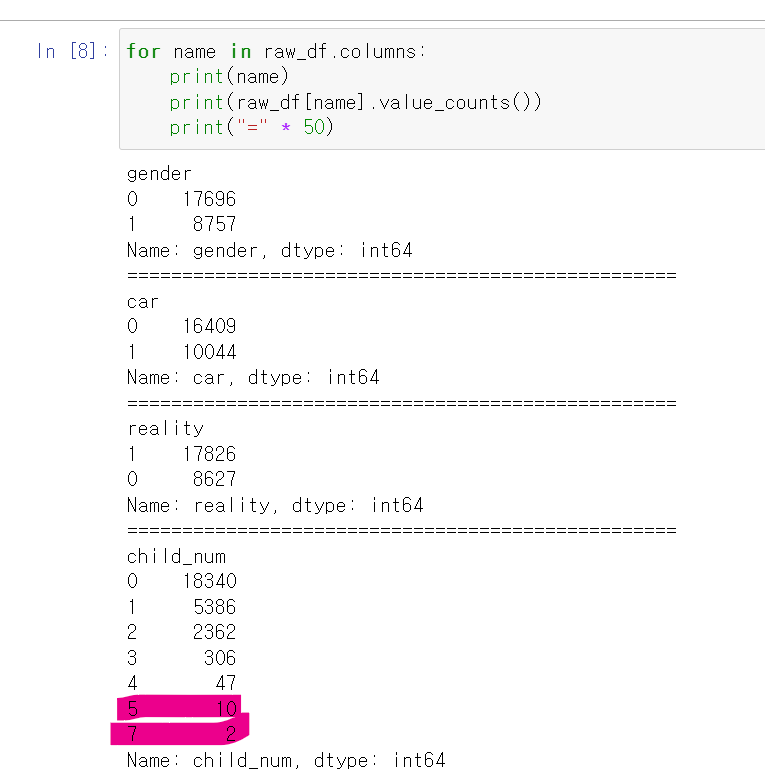
- 결측치를 찾기 위해 value_counts를 통해 각 컬럼의 결측치를 search했다.
- 연속형 자료의 경우 모든 컬럼이 feature중요도가 높게 나와서 일단 결측값을 함부로 삭제하기 애매해서 나뒀다.
- 여기서 찾은 점은 income_type에서 학생은 7개밖에 없으며, child_num도 5명 이상인 경우는 적기에 삭제했다.
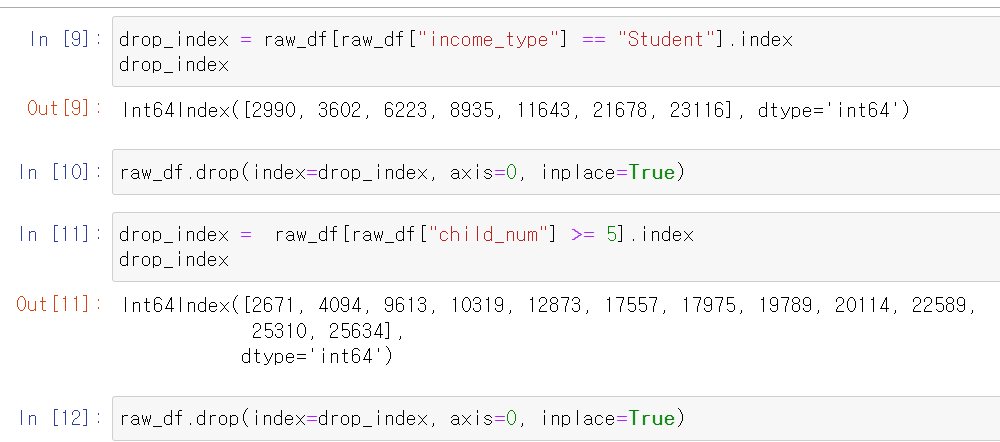
- 두 조건을 통해 index를 검색하고 해당 인덱스의 행을 삭제했다.
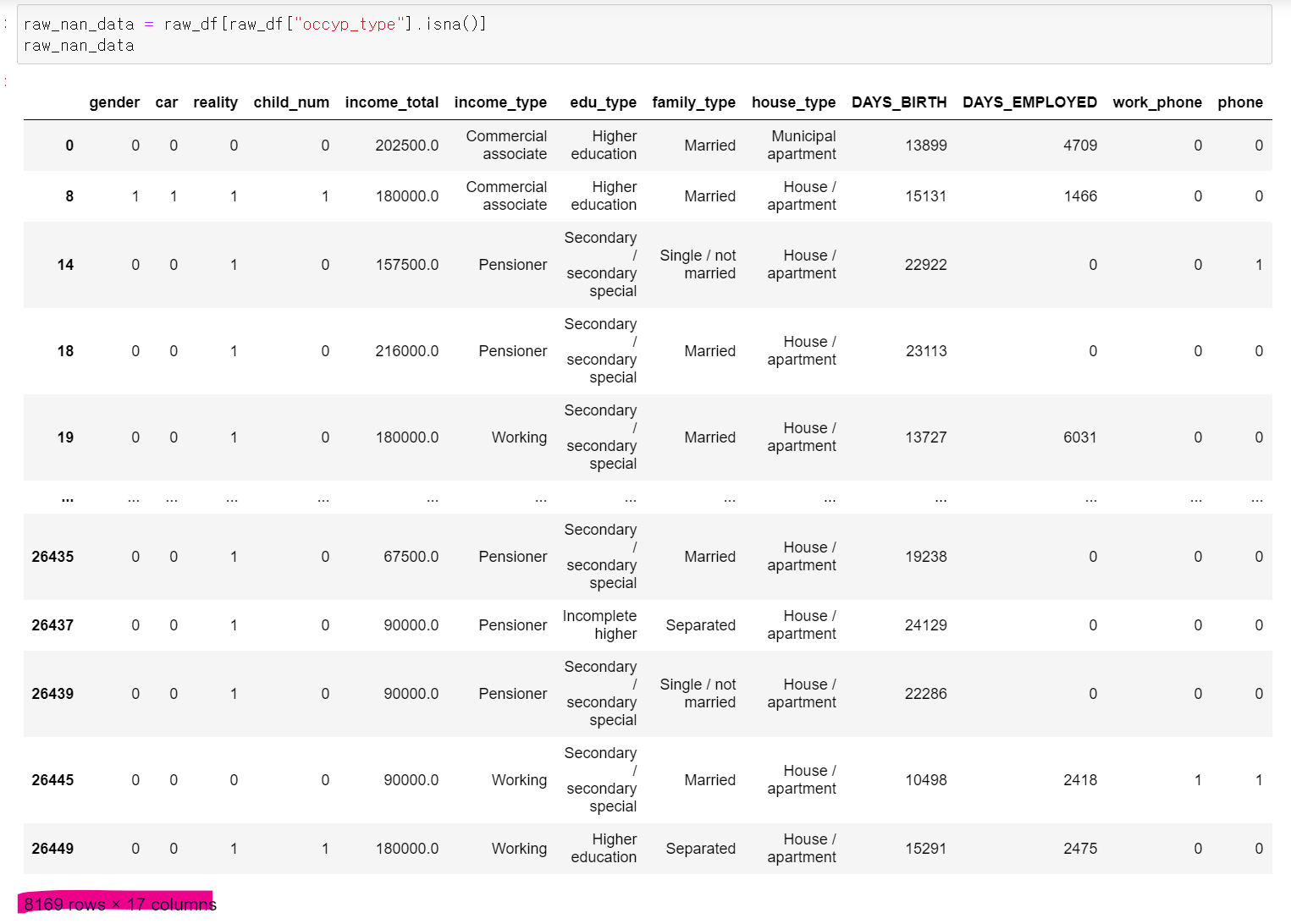
- 이제 occupy에서 Nan값인 데이터만 뽑아봤다.
- 총 8169개의 데이터가 존재하는데 저 Nan값을 어떻게 처리할까 고민을 많이 했다.
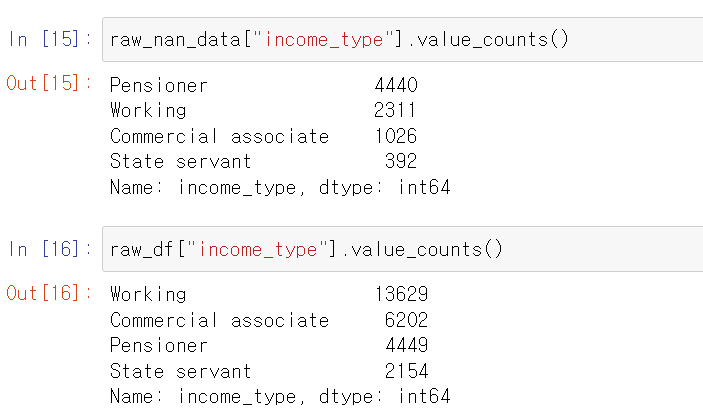
- 그래서 연관성이 높은 income_type과 살펴보니 Nan값이 있는 행의 income_type은 보통 연금수령자가 많은데, 다른 직업도 있었다.
- 그래서 생각한 가정은 공무원이지만 occupy_type이 여러 종류가 있고 분류가 애매한 경우 Nan값을 준 것이 아닐까 생각해서 두 개의 컬럼을 응용해봤다.
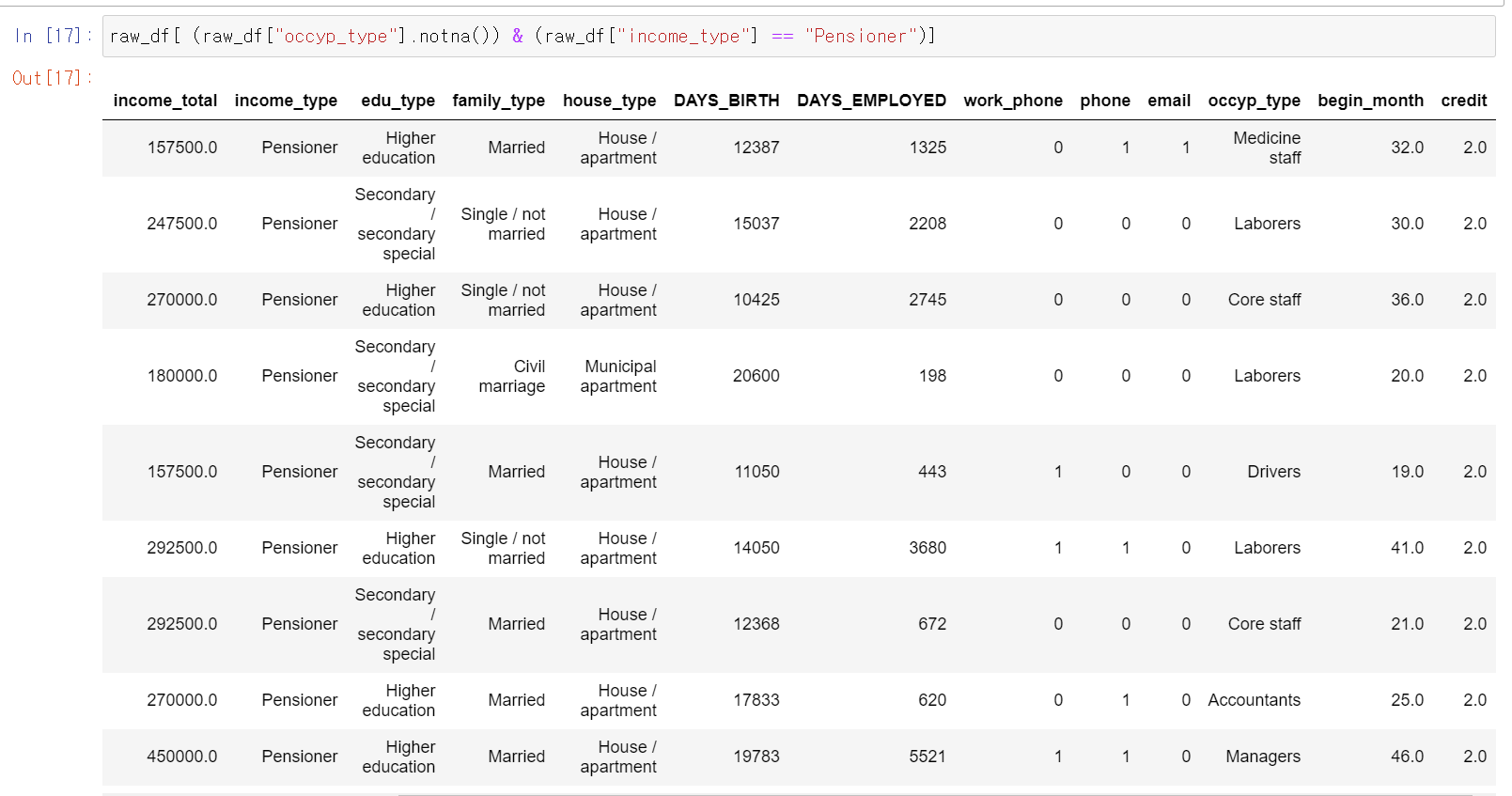
- 그리고 연금수령자면서 직업 유형이 있는 경우도 있다.
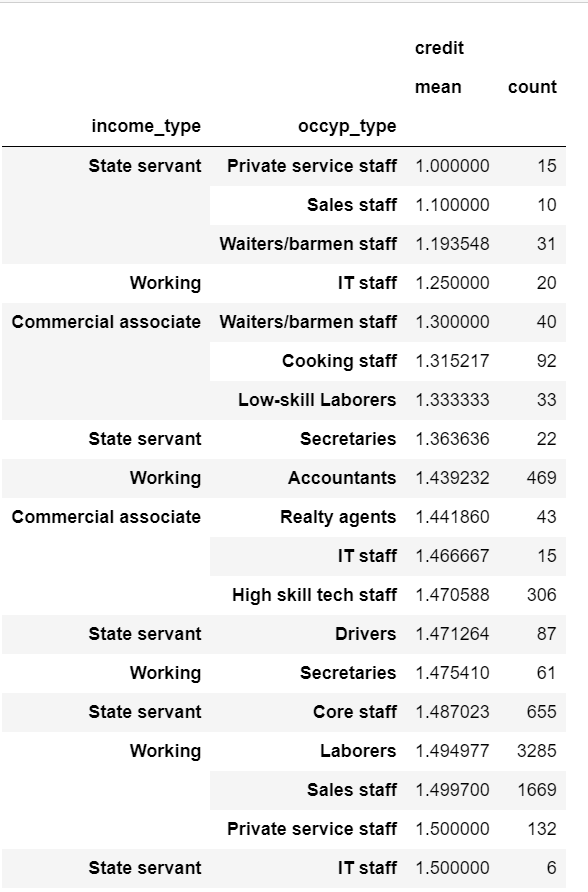
- 컬럼을 합치기 전에 두 개의 컬럼을 통해 group by로 데이터를 살펴보니 공무원 income_type의 평균 크레딧이 확실히 높았다.
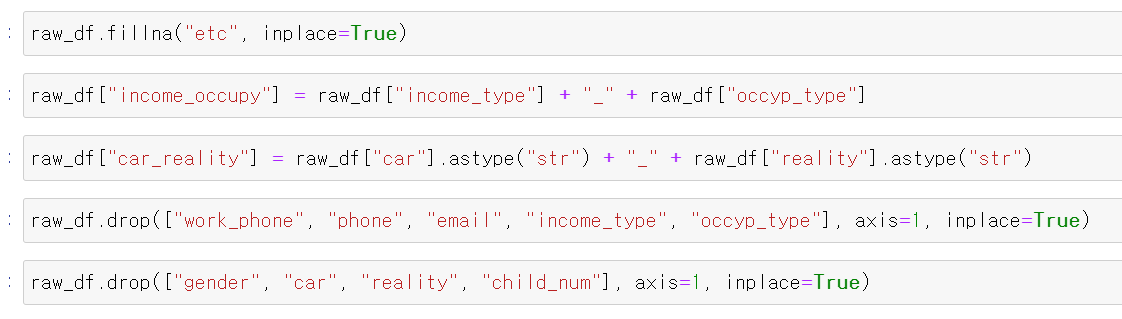
- 이제 두개의 컬럼을 합치고, 차와 부동산 유무 또한 크레딧에 영향을 미칠 것이라고 판단하여 합쳐서 두 개의 새로운 컬럼을 만들고 불필요한 binary형태의 컬럼을 drop했다.
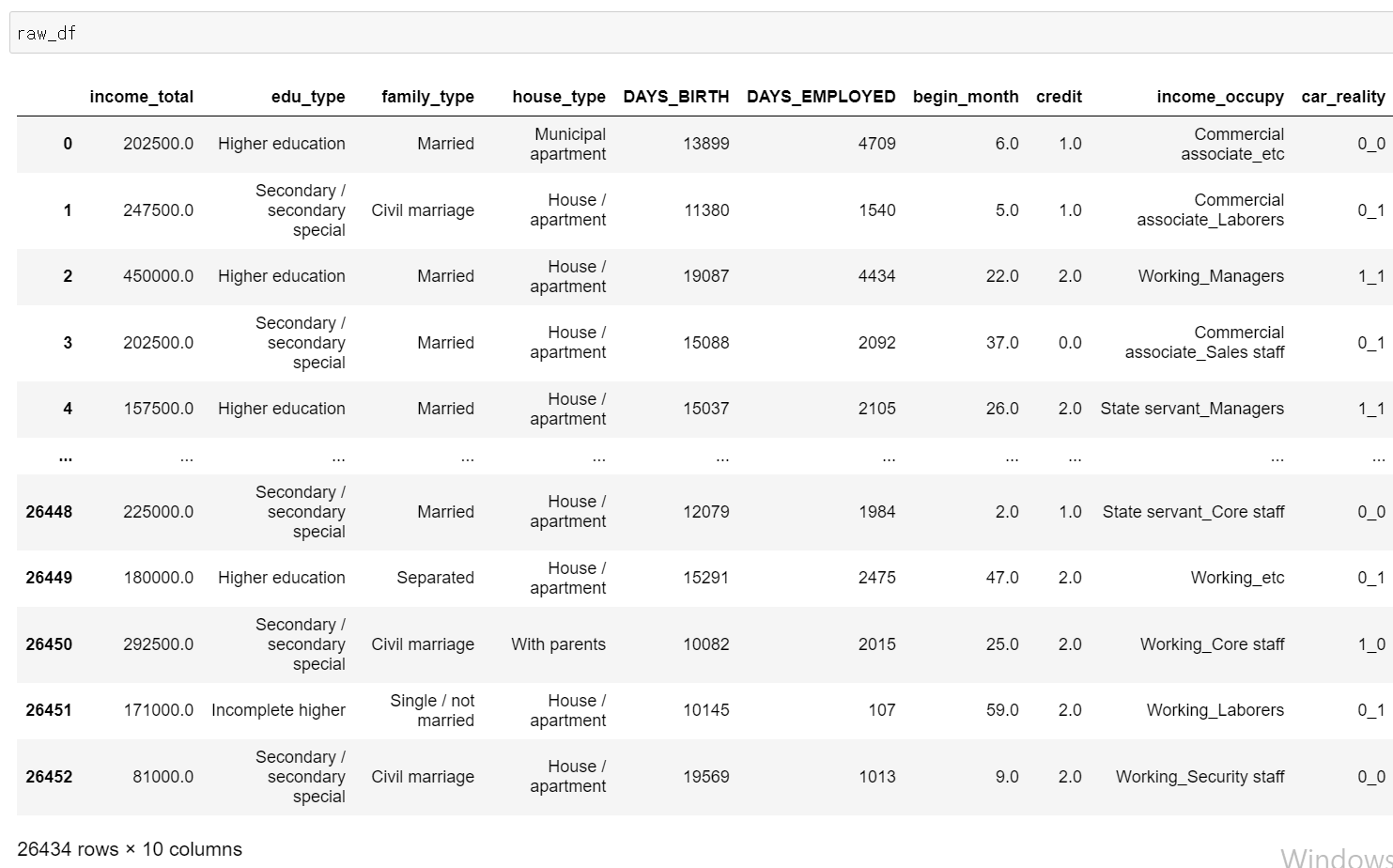
- 10개의 컬럼을 통해 새로운 데이터셋을 만들었다.
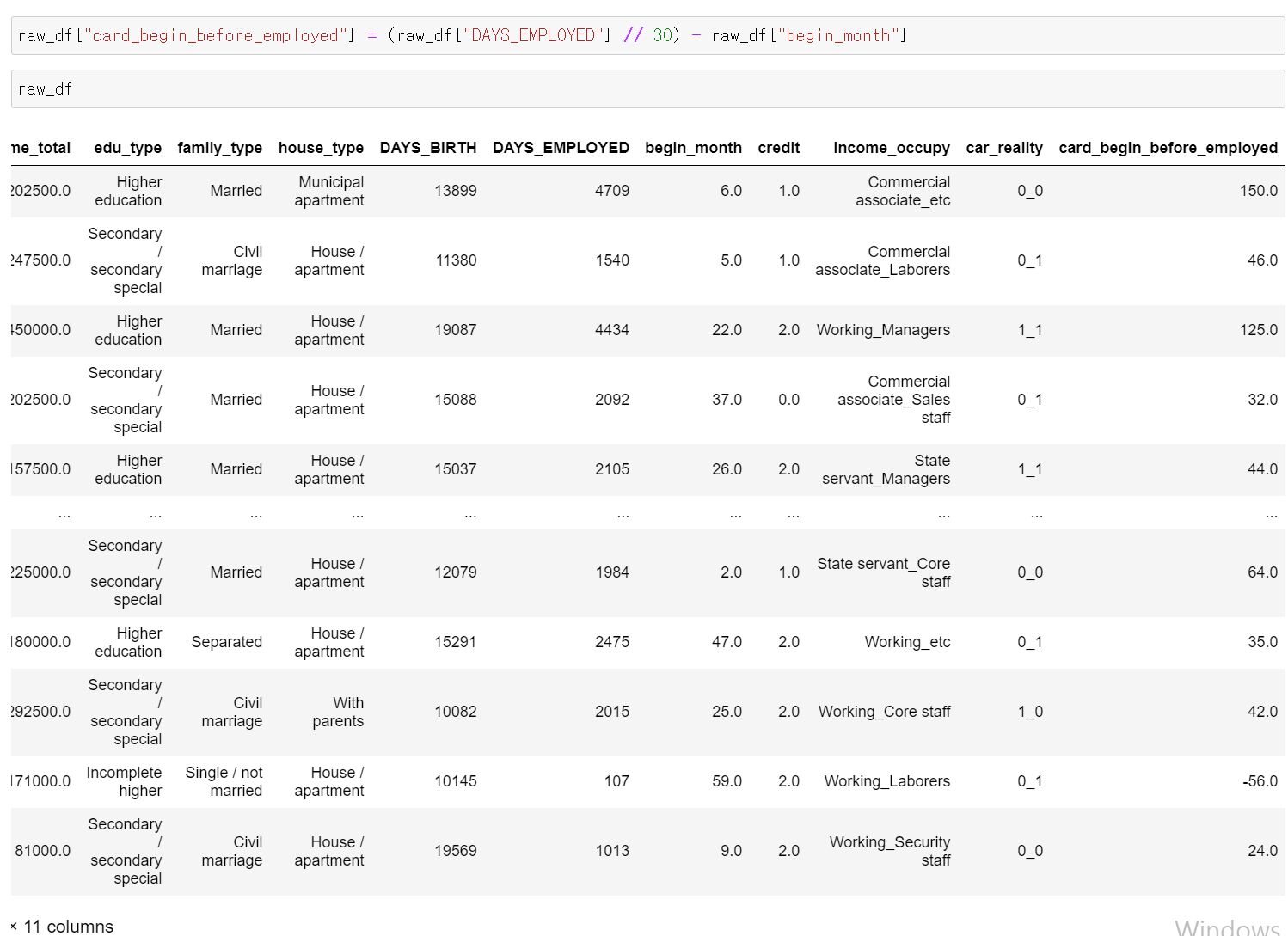
- 이번에는 일한 개월 수에 카드를 발급 받은 개월 수를 빼서 카드 발급 받은 날을 기준으로 일한 개월 수 컬럼을 추가했다. 양수일 경우 카드를 발급 받기 전부터 일했으며, 음수의 경우 카드를 발급 받고 일을 하지 않은 것이다.
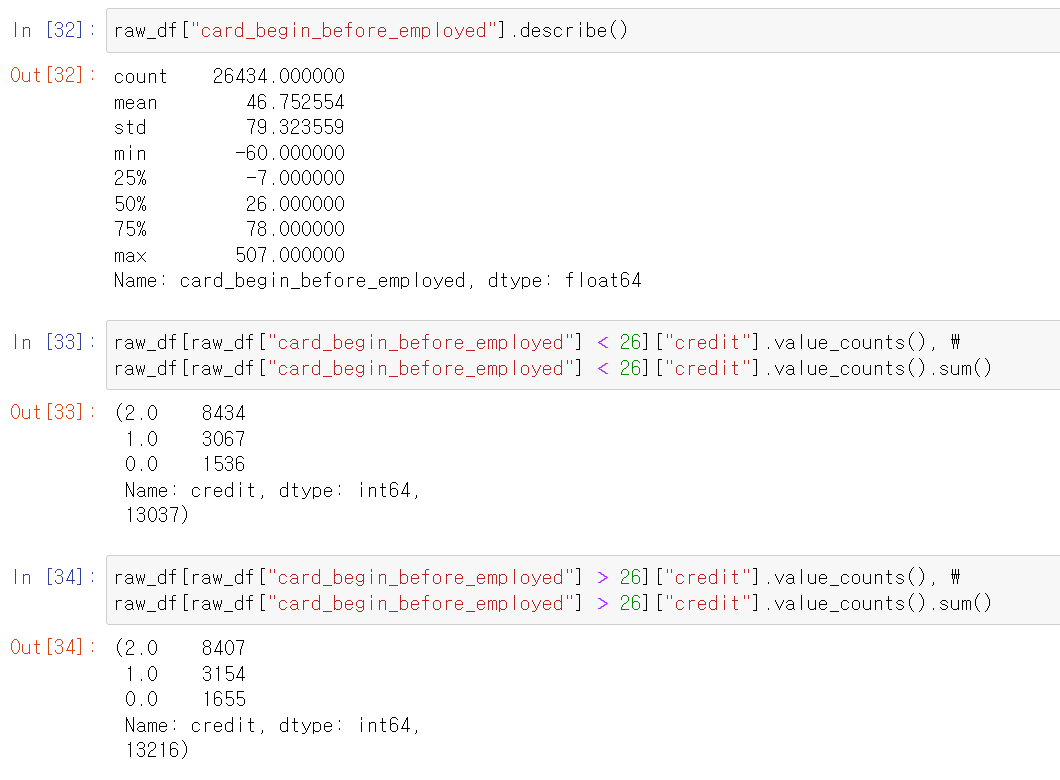
- card_begin 컬럼의 중앙값 평균 등을 찾아서 분석해봤다.
- 중앙값, 평균 등을 기준으로 구분해서 라벨값을 분석해봤으나, 뚜렷한 두 데이터의 차이점을 발견하지는 못했다.
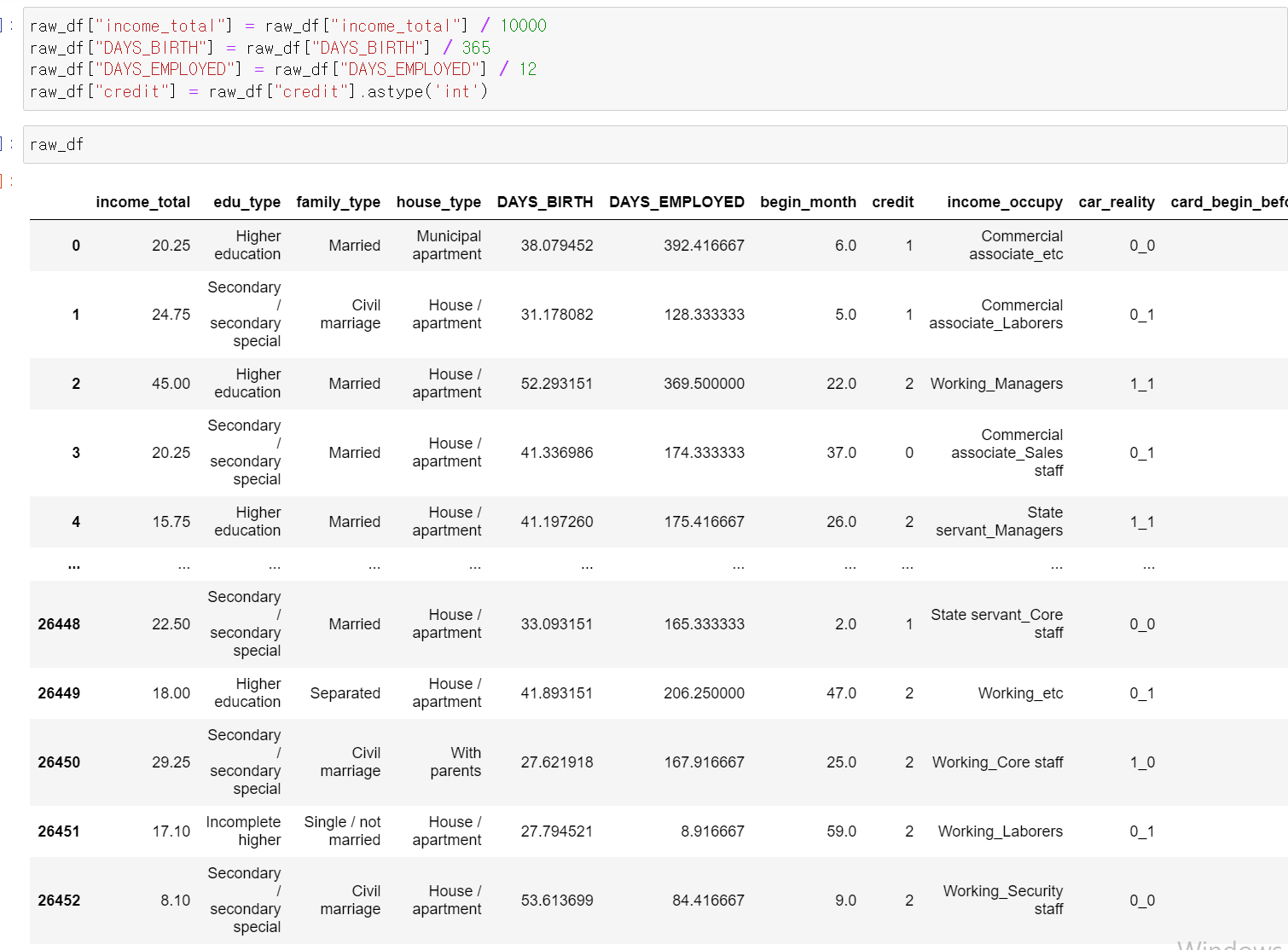
- 이제 데이터의 가독성과 단위를 위해 연속형 자료를 처리하고,
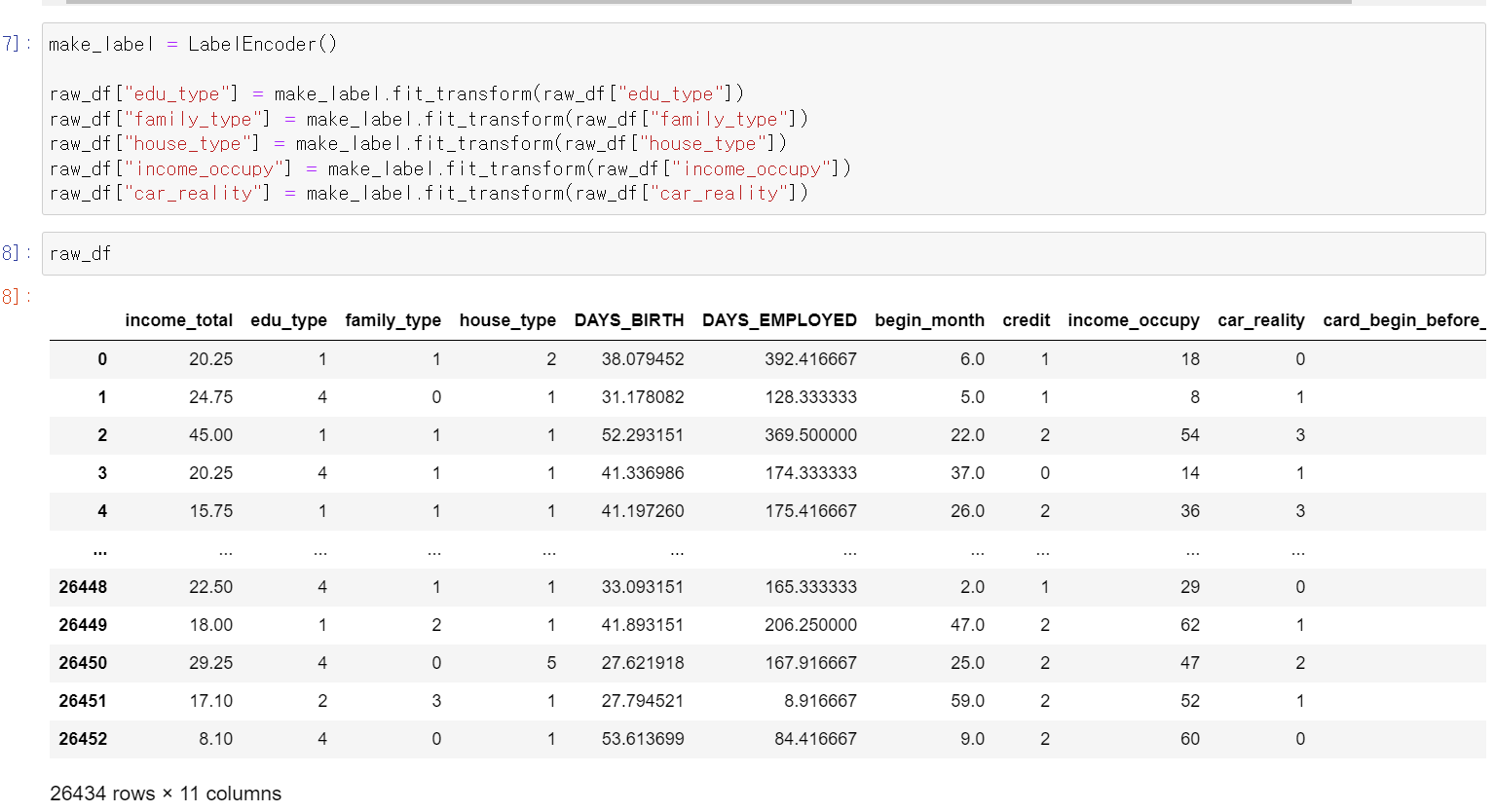
- object형 데이터는 labelEncorder작업을 했다.

- 이제 x데이터에 라벨값을 뺀 데이터를 주고, y데이터에는 라벨값을 주고 8:2로 데이터를 구분했다.
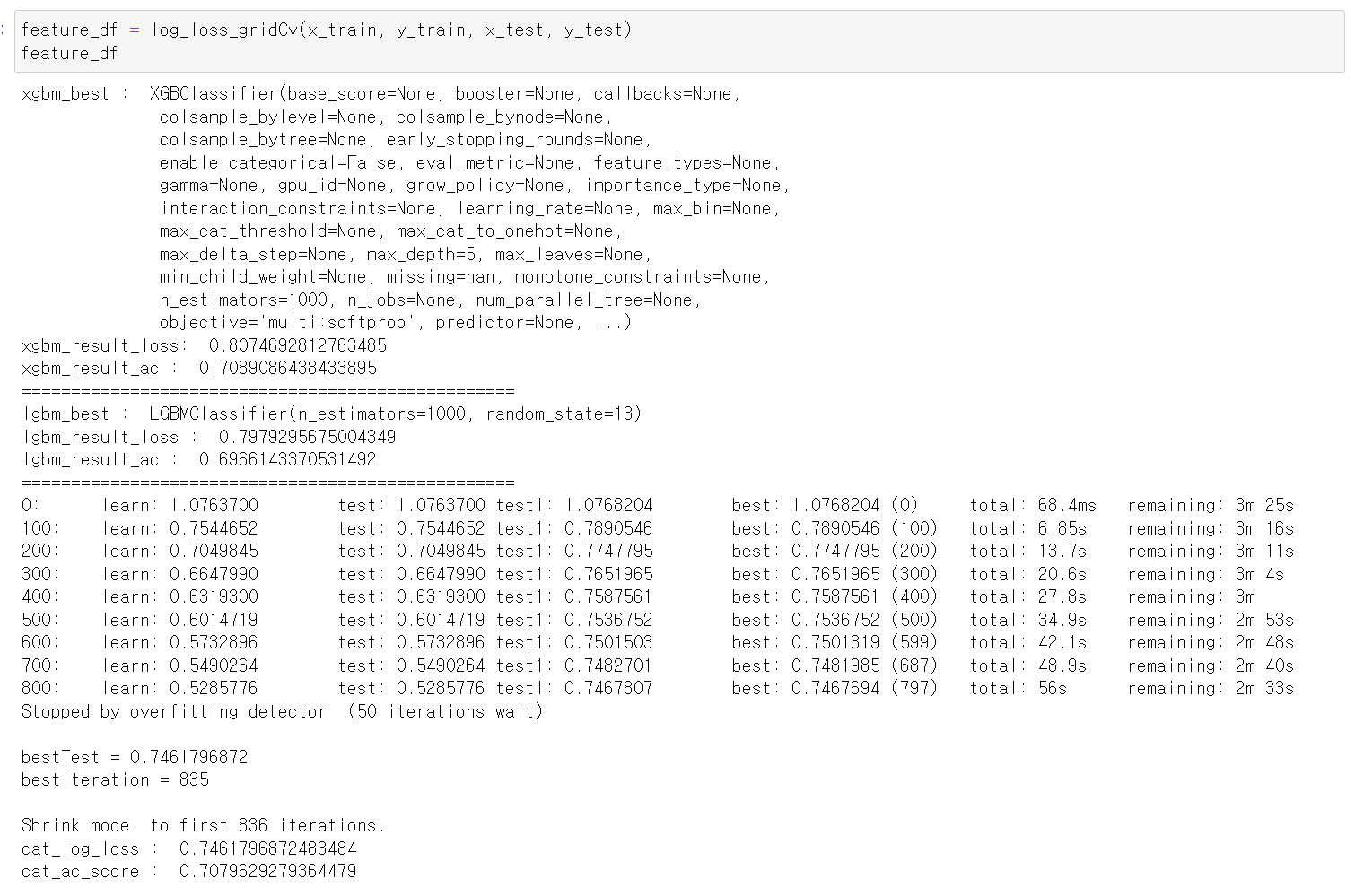
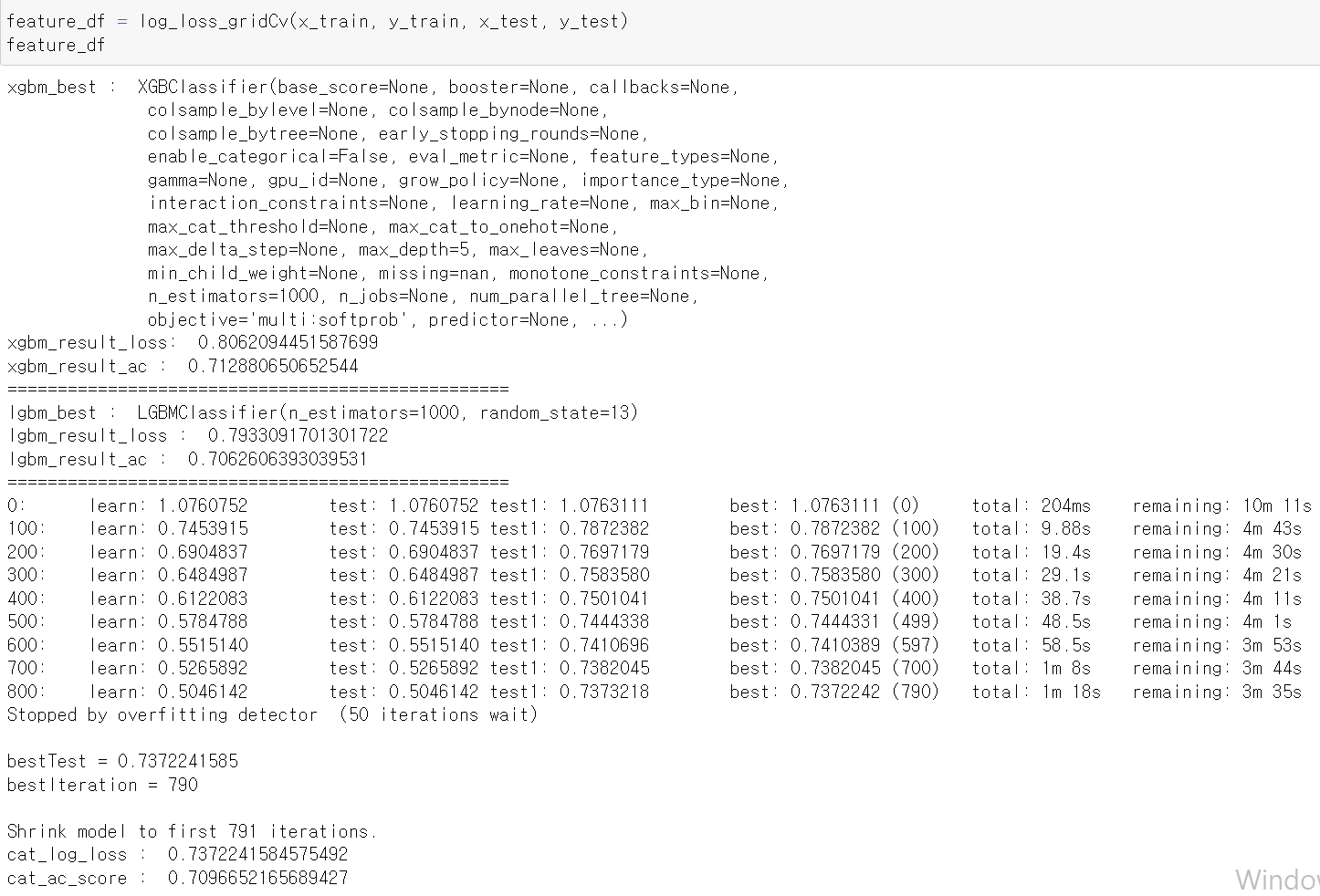
- 먼저 해당 데이터를 그대로 돌려보니 catboost가 가장 좋은 log_loss값을 출력했다.

- 그리고 feature 중요도를 프레임 변환받았는데, 연속형 자료의 중요도가 대체로 높게 나왔다.
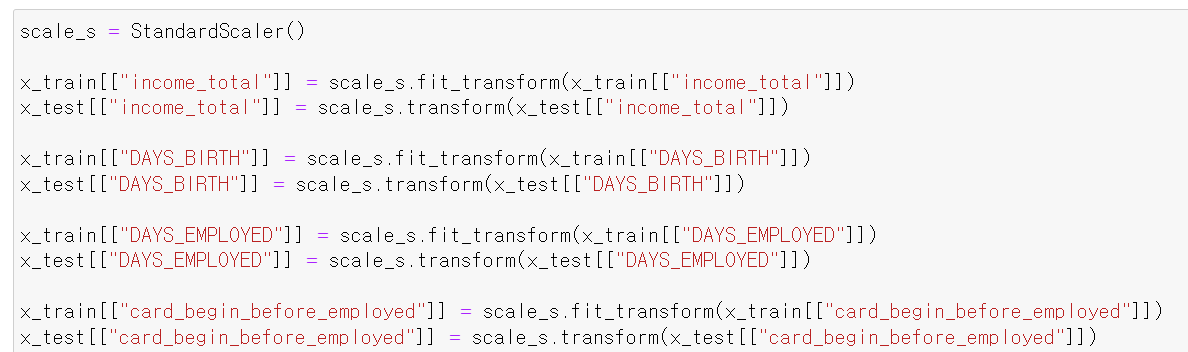
- 이번에는 scale값을 표준화하고 다시 테스트해봤다.
- 이렇게 데이터를 표준화해서 돌려보니
- 정말 큰 차이가 없다. 허탈하지만 뭐 큰 기대를 안 했다.
- 이제 다른 방식으로 feature 구분을 해보고, 분석을 해봐야겠다.
7일차, credit_data 마무리 및 새데이터 탐색
- 이제 해당 데이터를 마무리하기 위해서 두 가지 방법을 통해 머신러닝을 성능을 테스트해보고 마무리했다.
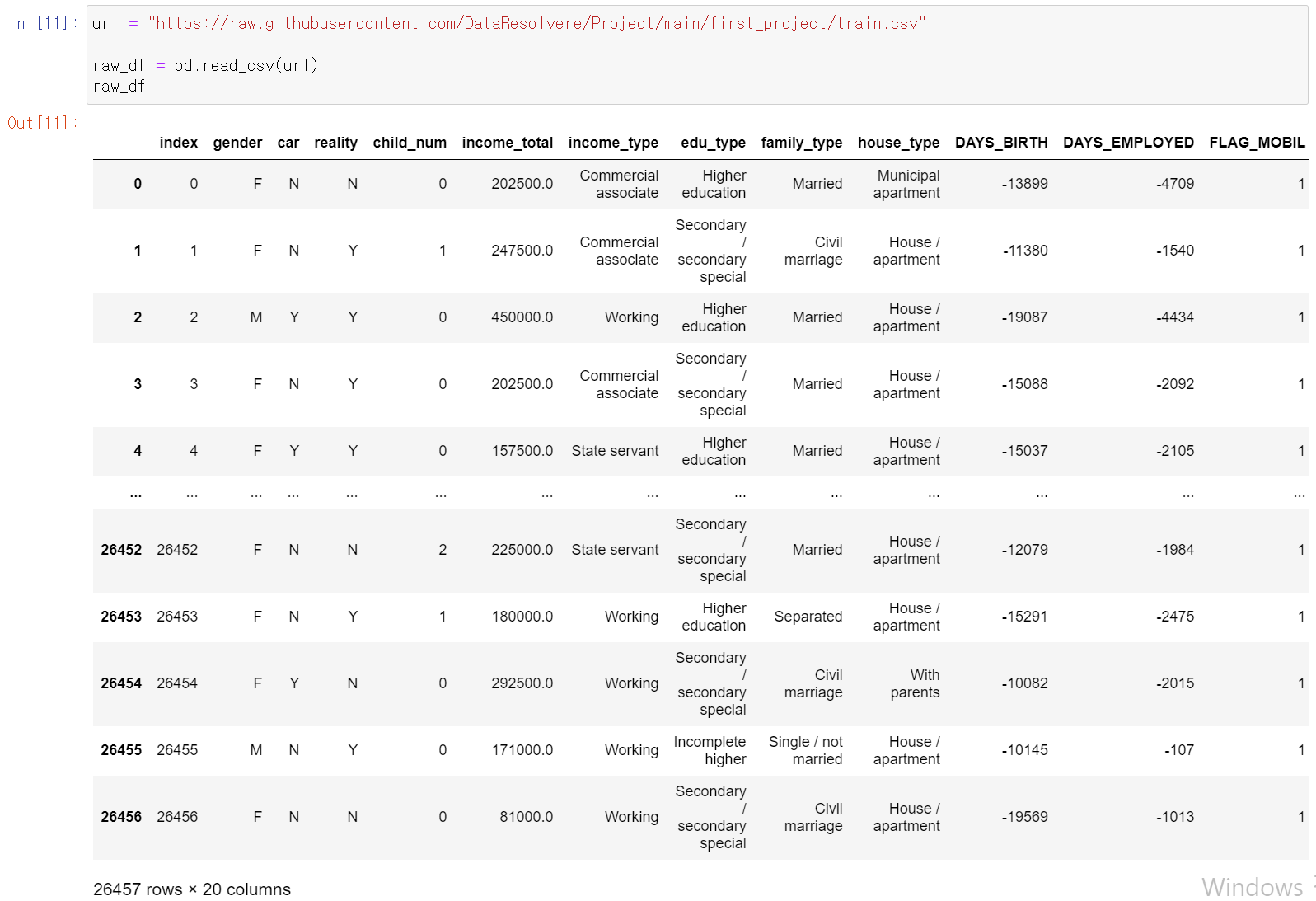
- 먼저 데이터셋을 불러왔다.

- 필요없는 column인 인덱스를 삭제하고, binary data를 int형태로 변환했다.
- 그리고 DAYS_EMPLOYED컬럼의 경우 양수는 일한 경험이 없는 데이터이기 때문에 0이상일 경우 모두 0의 값으로 바꿔주고
- 연속형 자료의 기준이 음수값이라 양수값으로 바꾸기 위해 절대값으로 변환했다.

- 그리고 데이터 분석 시 발견한 이상치 데이터를 drop했다.
- FLAG_MOBIL 컬럼의 경우 고유값이 하나이기 때문에 모델 성능에 유의미한 차이를 만들 수 없어서 drop했다.

- 이제 가공한 데이터를 통해 두 가지 방법으로 진행했다.
- 카드 발급 날짜만 다르고, 나머지 데이터 동일한 중복 데이터가 다수 발견되서 두 가지 가정을 세웠다.
- 한 사람의 데이터가 중복적으로 중첩되서 쌓였다.
- 한 사람이 자신의 정보를 토대로 복수의 신용카드를 발급했다.
- 위 문제의 가정을 해결하기 위해 두 가지 해결방안을 모색했다.
- 여러 컬럼의 조합으로 한 사람의 데이터라는 것을 식별할 수 있는 고유 ID값을 생성
- 중복 데이터를 삭제함으로써 고유 데이터만을 가지고 모델링 구축
- 위 두 가지 방법을 모두 사용해서 성능을 테스트해봤다.

- 가장 먼저 데이터 처리 과정이다.
- 카드 발급 날짜를 제외한 나머지 데이터를 모두 string형태로 조합하고, 조합한 데이터를 통해 새로운 SSN(고유식별번호) 컬럼을 만들었다.
- 두 번째는 income_type과 occupy_type을 합쳐서 수입과 발생 유형을 나타내느 새로운 컬럼과 자동차와 부동산을 합친 두 범주형 컬럼을 만들었다.
- 그리고 분석에 유의미한 차이를 만들지 못하는 feature을 drop했다.
- 카드 발급 날짜를 기준으로 일한 개월 수를 나타내는 컬럼 생성
- 연속형 데이터의 단위를 조정했다.

- 그리고 범주형 자료를 머신러닝에 돌리기 위해 LabelEncoder작업을 하고

- x변수에는 Label를 제외한 데이터를, y에는 label값을 줬다.
- 그리고 train, test 데이터로 구분하고 위에 만든 함수로 결과를 확인했다.
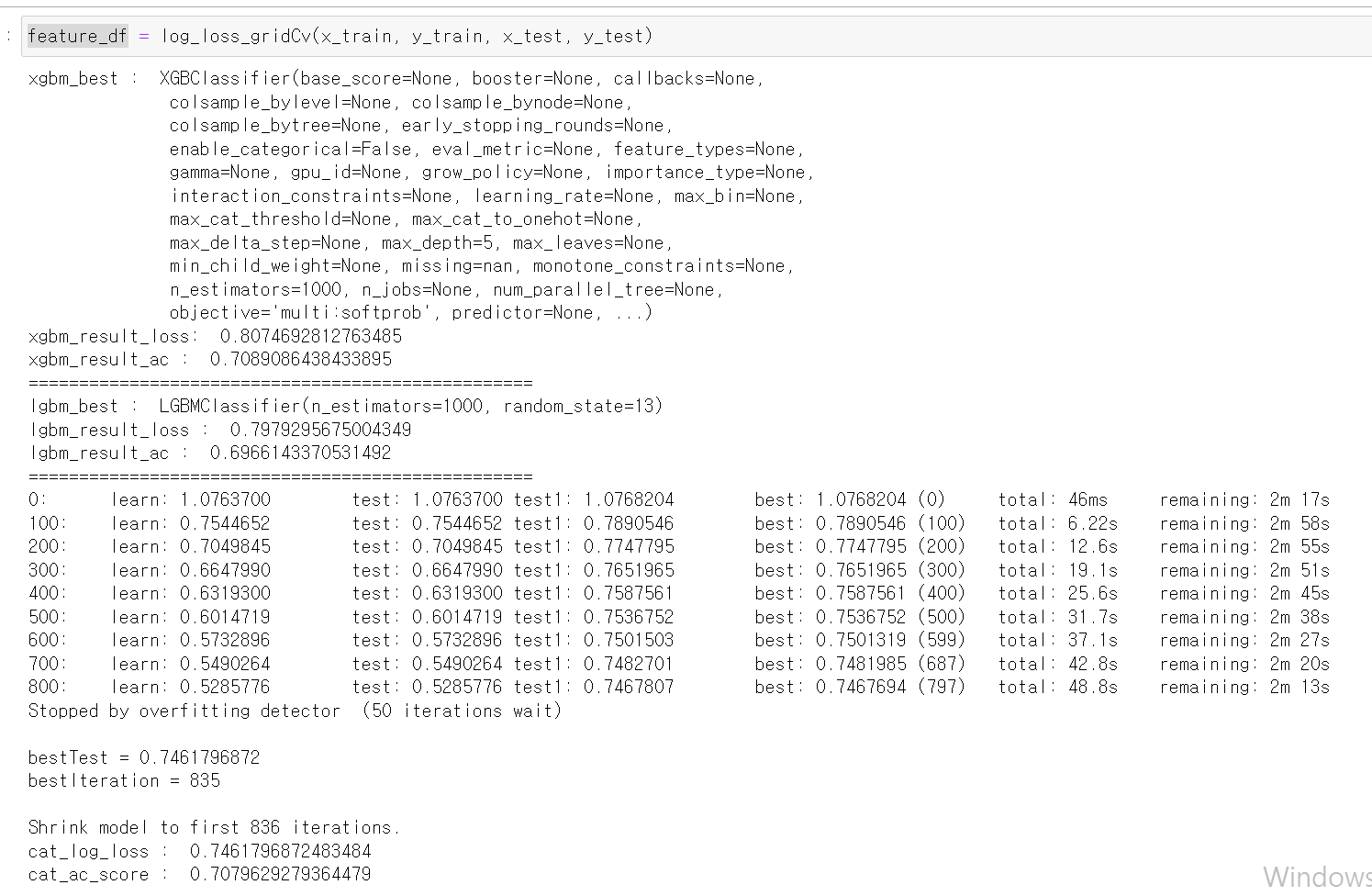
- 기대한 만큼 썩 좋은 결과는 아니지만, 그래도 catBoost의 경우 꽤 낮은 log_loss값이 나왔다.

- 각 feature의 중요도를 프레임으로 만들어서 보니 역시 연곡형 자료의 중요도가 높았다.
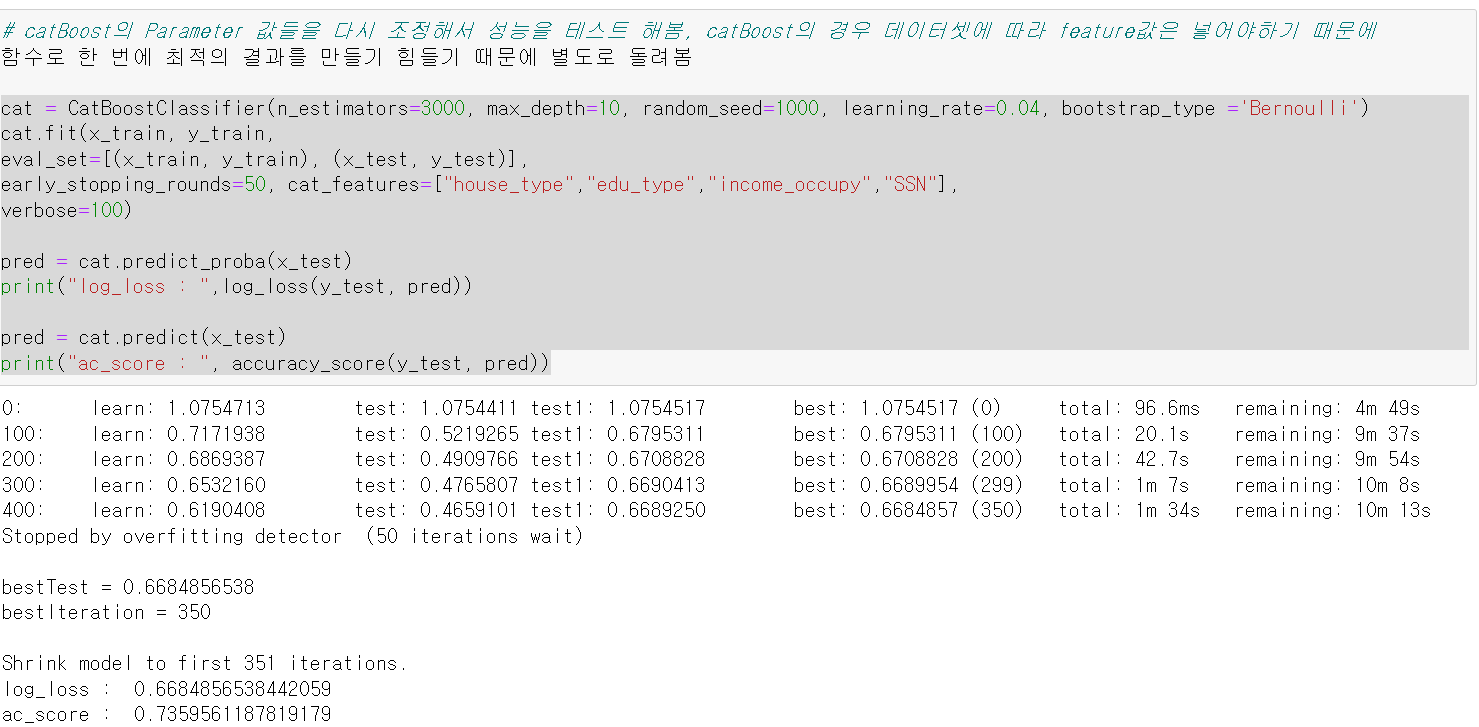
- 그리고 catBoost의 경우 데이터셋에 따라 Parameter 값을 바꿔줘야해서 따로 parameter값을 주고 다시 돌려보니 log_loss값이 0.66으로 좋은 성능이 나왔다!
xgbm_result_loss: 0.8062094451587699
xgbm_result_ac : 0.712880650652544
lgbm_result_loss : 0.7933091701301722
lgbm_result_ac : 0.7062606393039531
log_loss : 0.6684856538442059
ac_score : 0.7359561187819179
- 이번에는 위에 한 작업 중 SSN데이터 과정만 제외하고 똑같이 데이터 처리 과정을 수행했다.
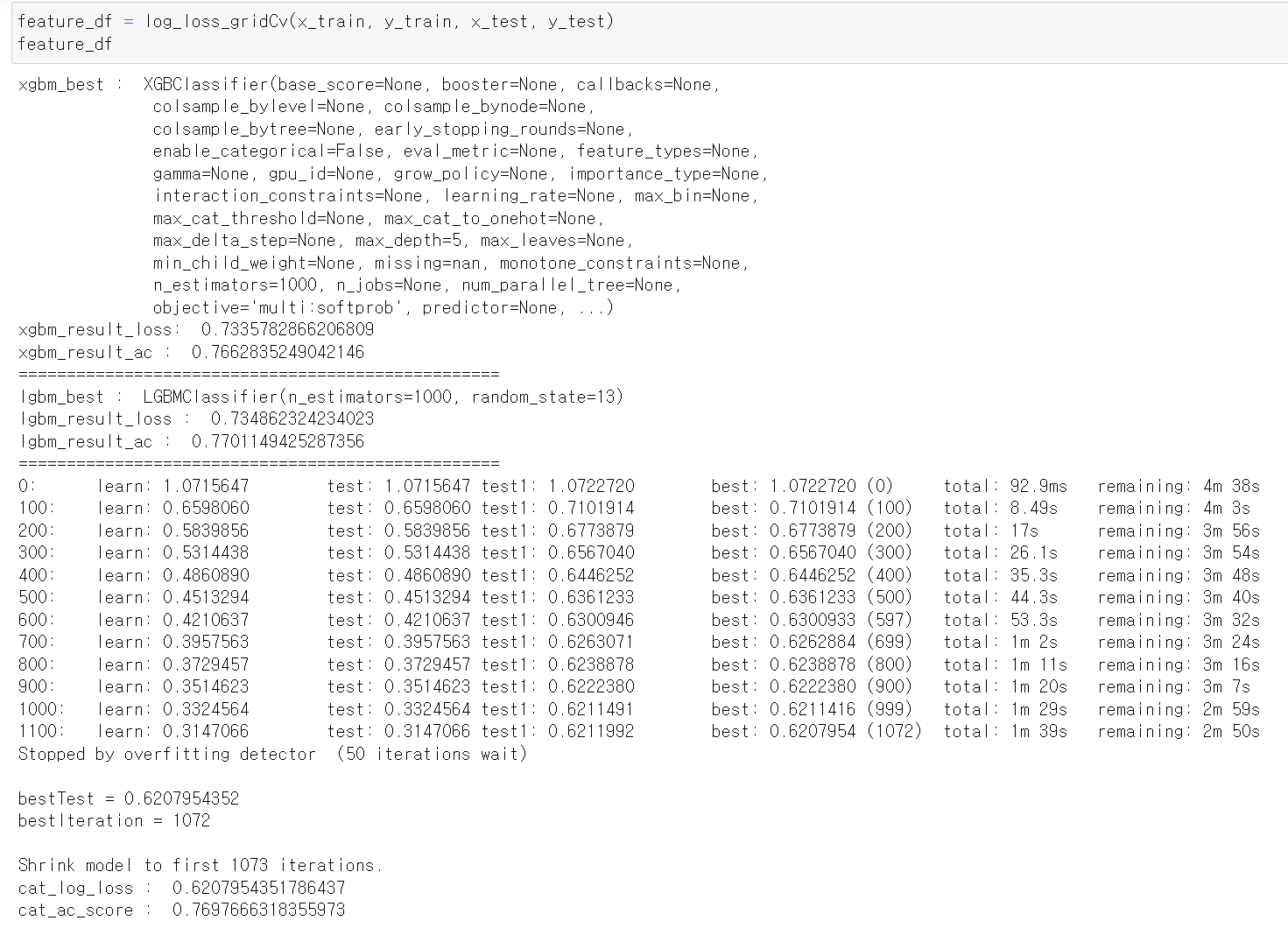
- 그리고 함수를 통해 확인해보니 확실히 중복값을 제거해서 좋은 성능이 나왔다.
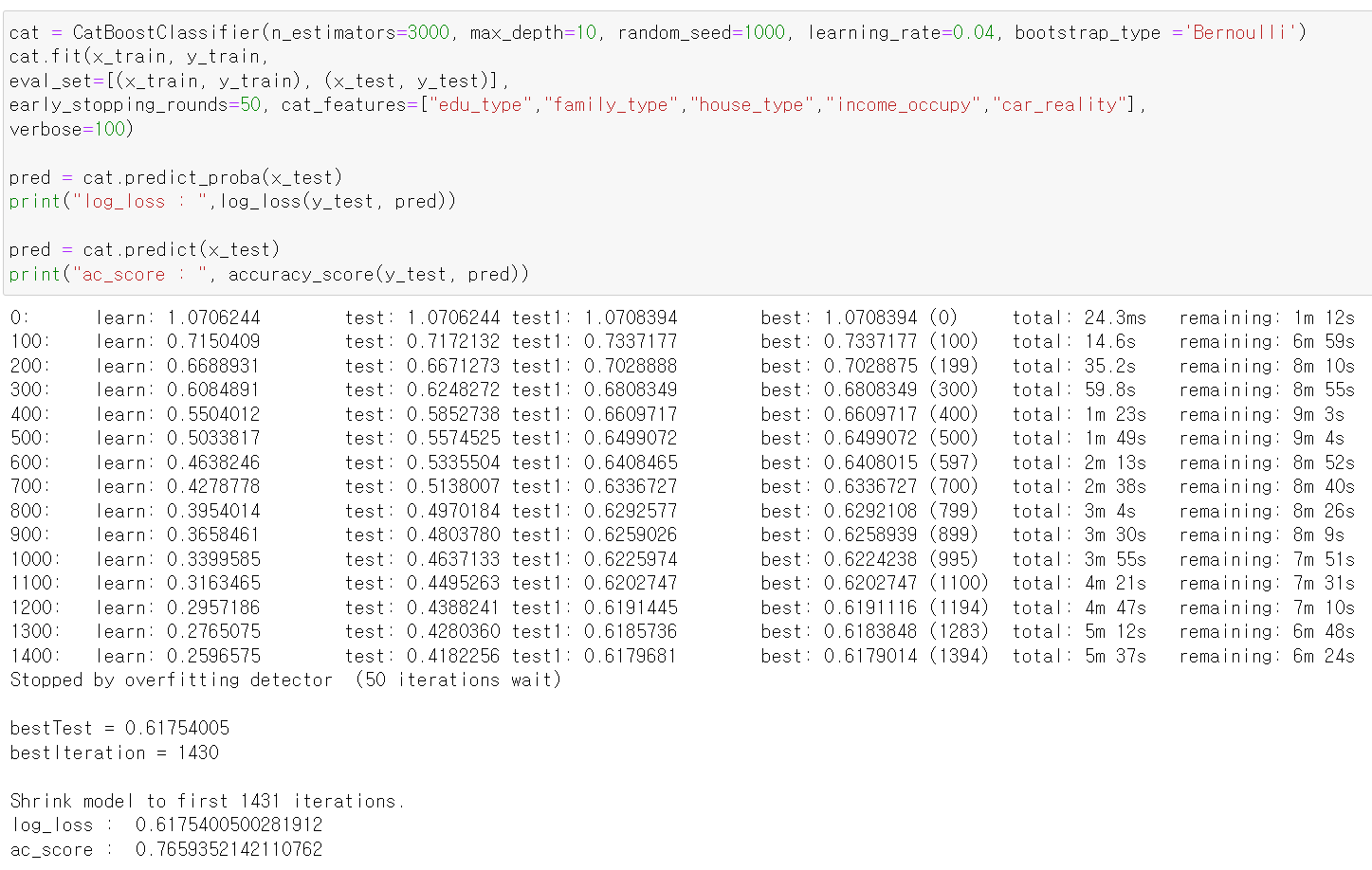
- catBoost의 Parameter 값을 바꿔서 돌려보니 가장 좋은 0.61 성능이 나왔다.
xgbm_result_loss: 0.7335782866206809
xgbm_result_ac : 0.7662835249042146
lgbm_result_loss : 0.734862324234023
lgbm_result_ac : 0.7701149425287356
log_loss : 0.6175400500281912
ac_score : 0.7659352142110762- 정확도도 77% 괜찮게 나왔고, 여기서 이 데이터를 끝냈다.
Credit_data 마무리
- 팀원과 함께 처음으로 수행한 프로젝트의 느낀점은 협업의 위대함이었다.
- 물론 소통과 커뮤니케이션 과정에서 시간과 노력 등 많은 부분을 소모해야했지만, 서로의 결과를 공유하고 매일 다른 측면의 분석이 발견됐다.
- 또한, 분석의 결과가 가장 좋은 데이터 전처리 및 모델링을 토대로 탑을 쌓는 과정처럼 층층이 노력해서 성능을 높여가면서 프로젝트의 매력을 느꼈다.
- 물론 많이 부족하지만, 해당 경험을 통해 앞으로 더 좋은 협업의 모습을 갖춰야겠다고 생각했다.
- 이제 해당 데이터를 마무리하고, 다른 금융 데이터셋을 통해 머신러닝을 돌려보자
8일차, New_Data
- 기존의 데이터를 끝내고, 새로운 데이터를 분석 및 모델링 작업을 시작했다.
- 먼저 필요한 module을 불러왔다.

- 불러온 데이터의 각 feature에 대한 설명이다.
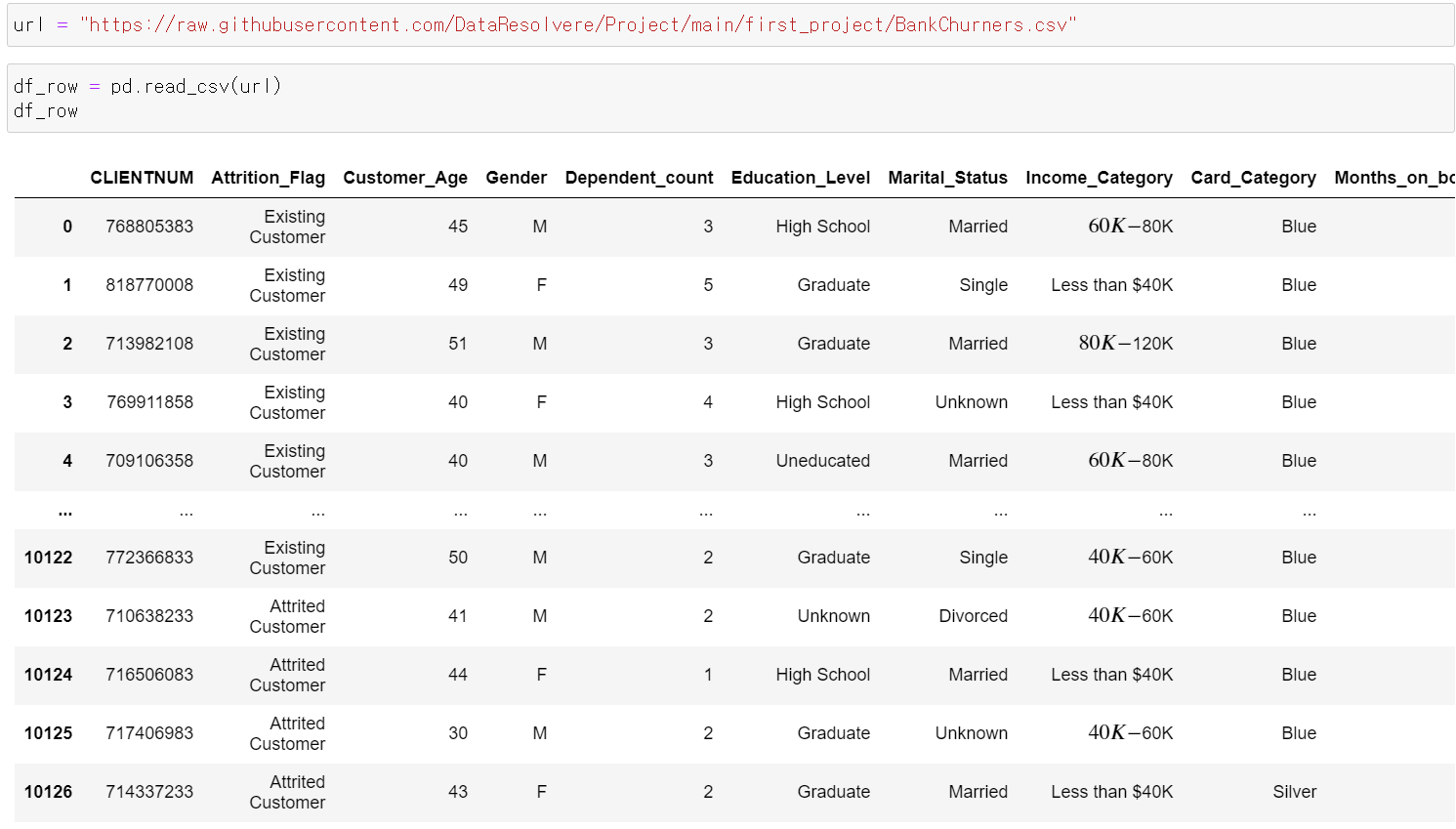
- 이제 데이터를 불러오고, 불러온 데이터를 프레임 형태로 정리했다.
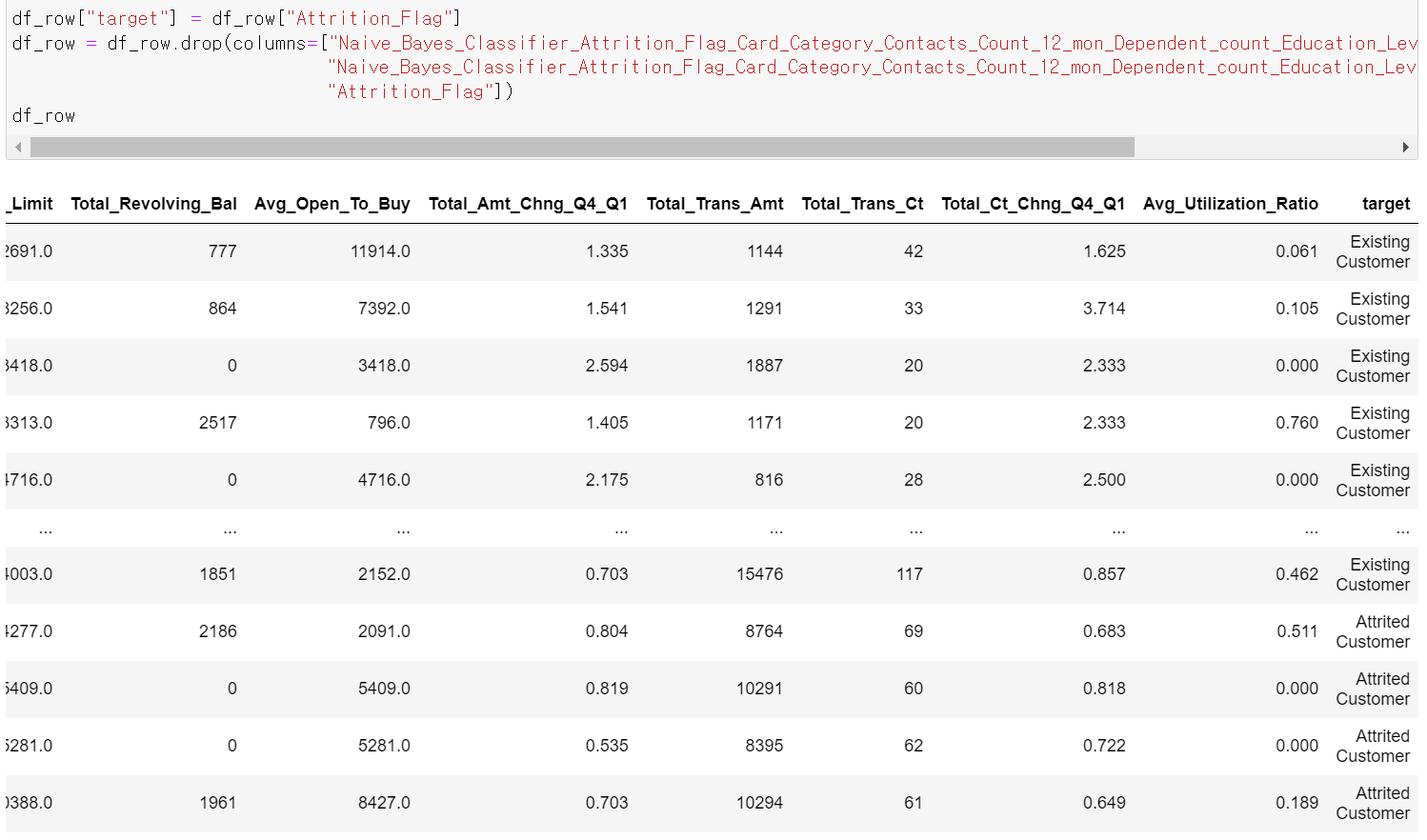
- 불필요한 feature를 drop하고, target 컬럼을 마지막에 배치했다.
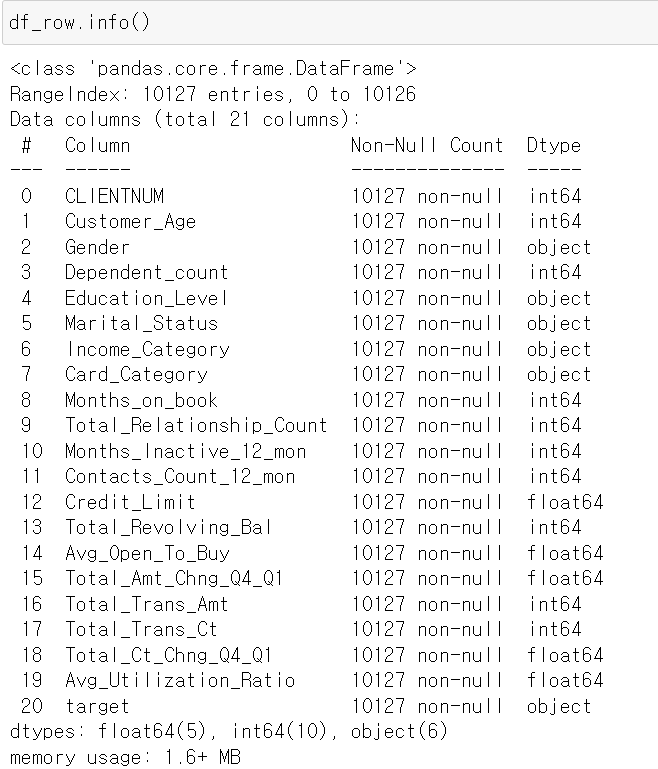
- 데이터의 정보를 살펴보니 일단 결측값 즉 Nan은 없어보인다.
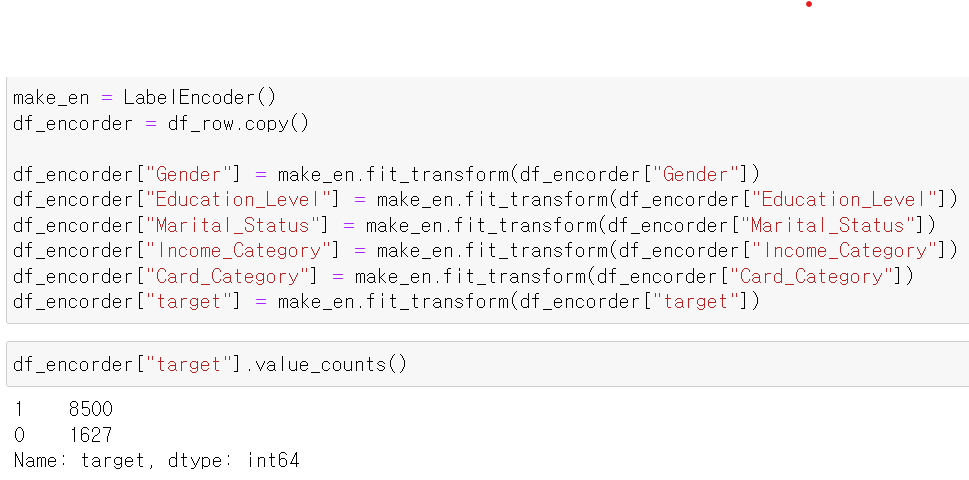
- 데이터의 분포를 확인 및 모델 테스트를 위해 범주형 자료를 LabelEncoder를 통해 int형태로 변환했다.
- 그리고 target의 분포를 확인해보니 1 즉 떠나지 않은 고객의 데이터가 많이 있었다.
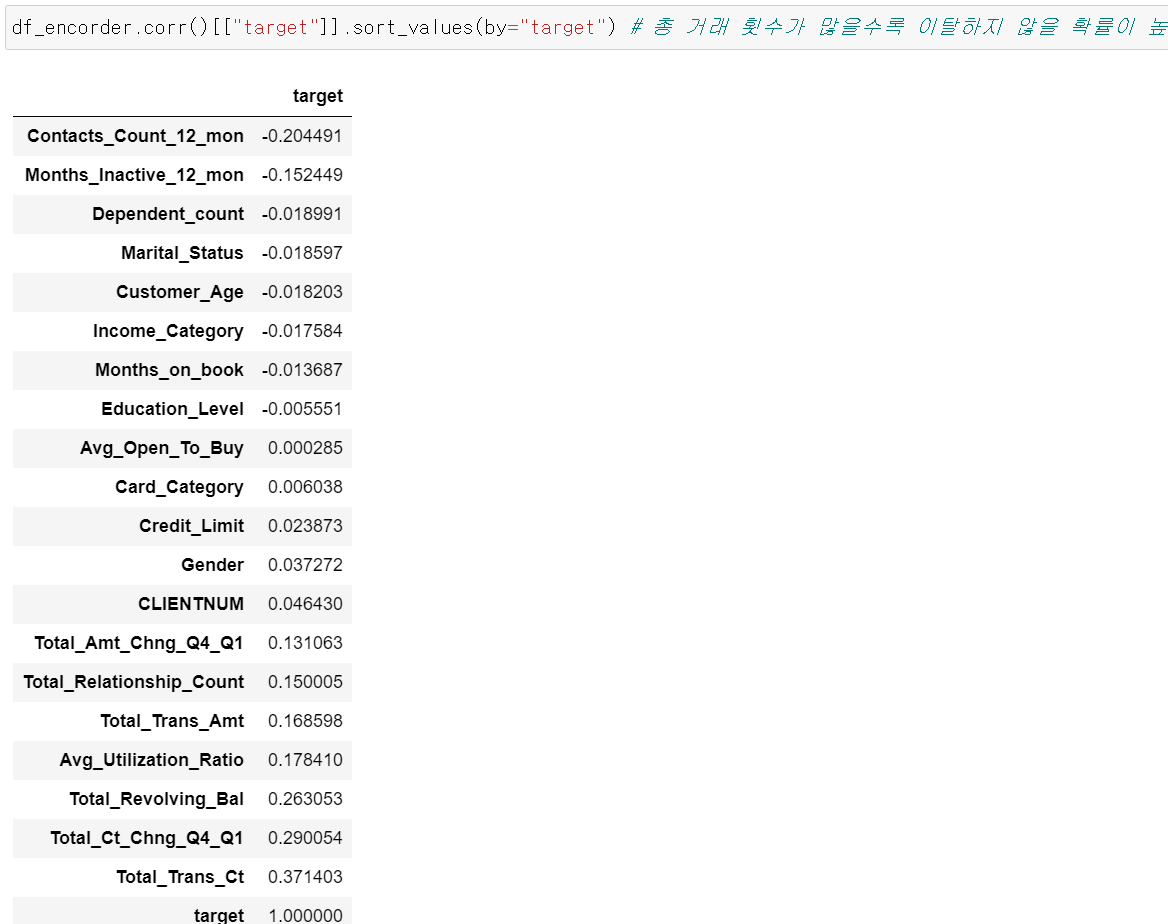
- 그리고 target값에 대해 유의미한 차이를 만드는 feature이 있는지 확인하기 위해 상관계수를 확인한 결과 12개월 내에 거래 횟수가 많은 고객의 경우 이탈하지 않을 확률이 높게 나왔다
- 그리고 각 Feature의 분포를 확인하기 위해 범주형 자료와 연속형 자료 리스트를 만들었다.
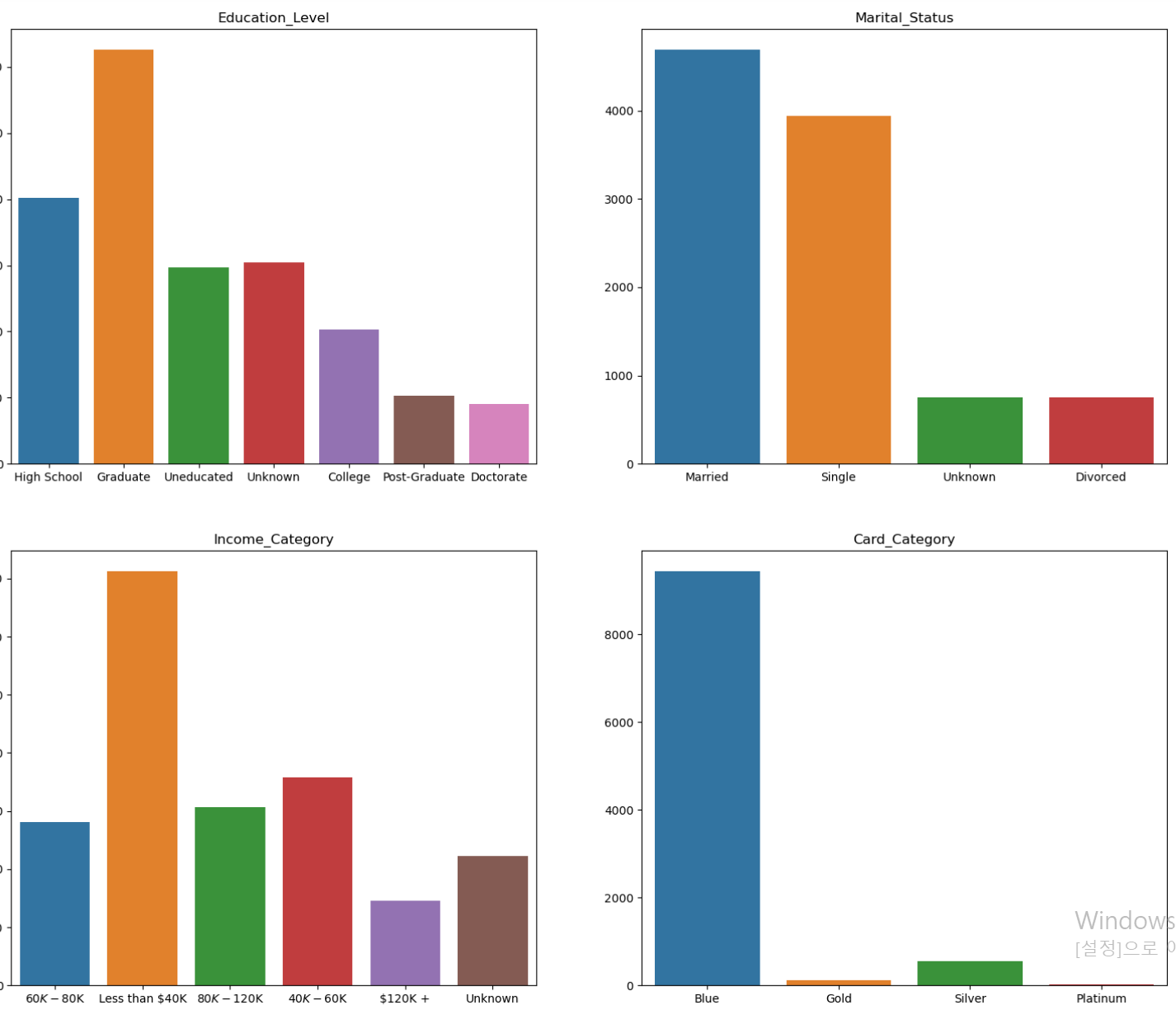
- 먼저 범주형 자료의 분포를 확인해보니 card_category데이터에서 platinum 고객의 데이터 다소 부족해보인다.
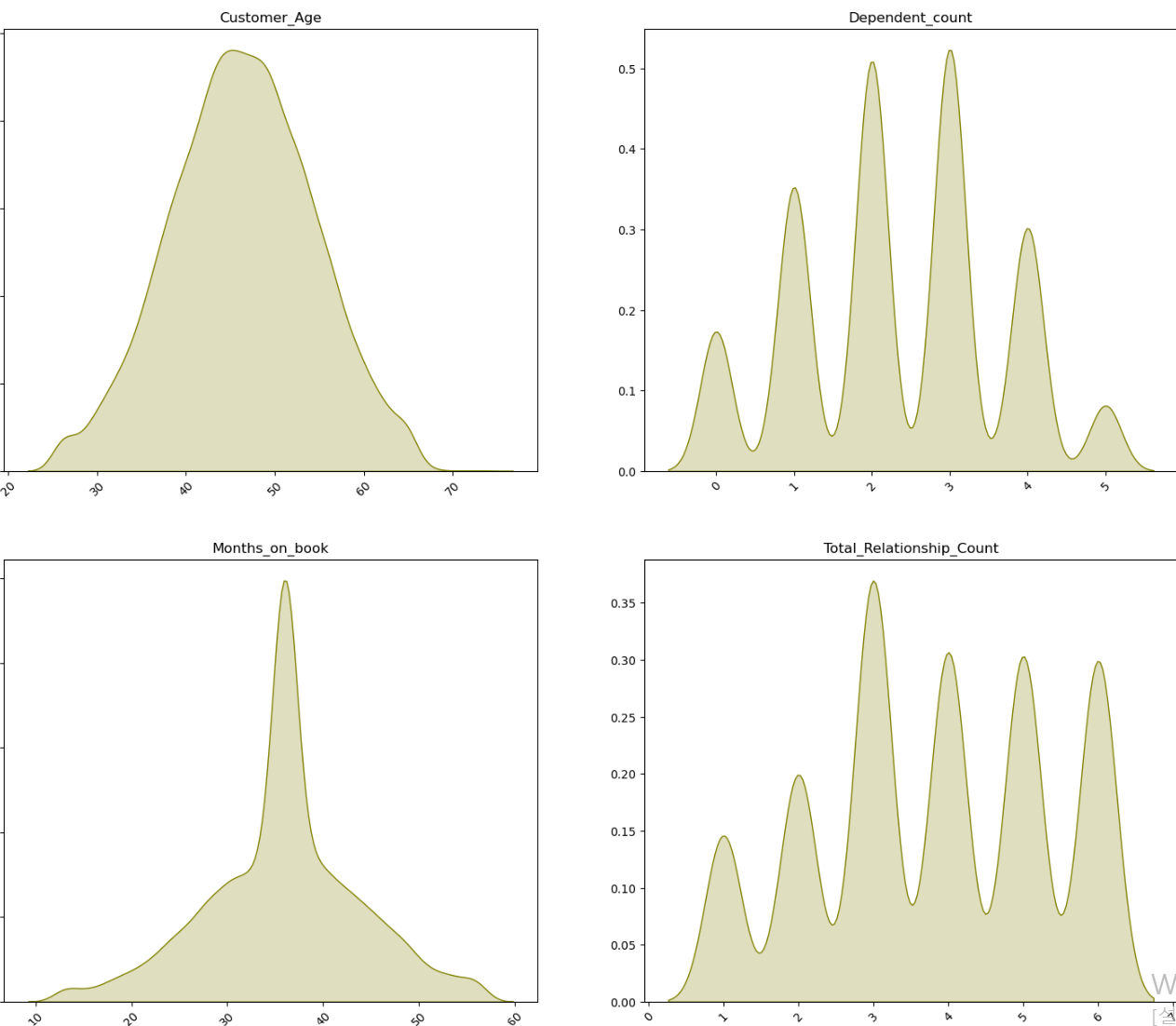
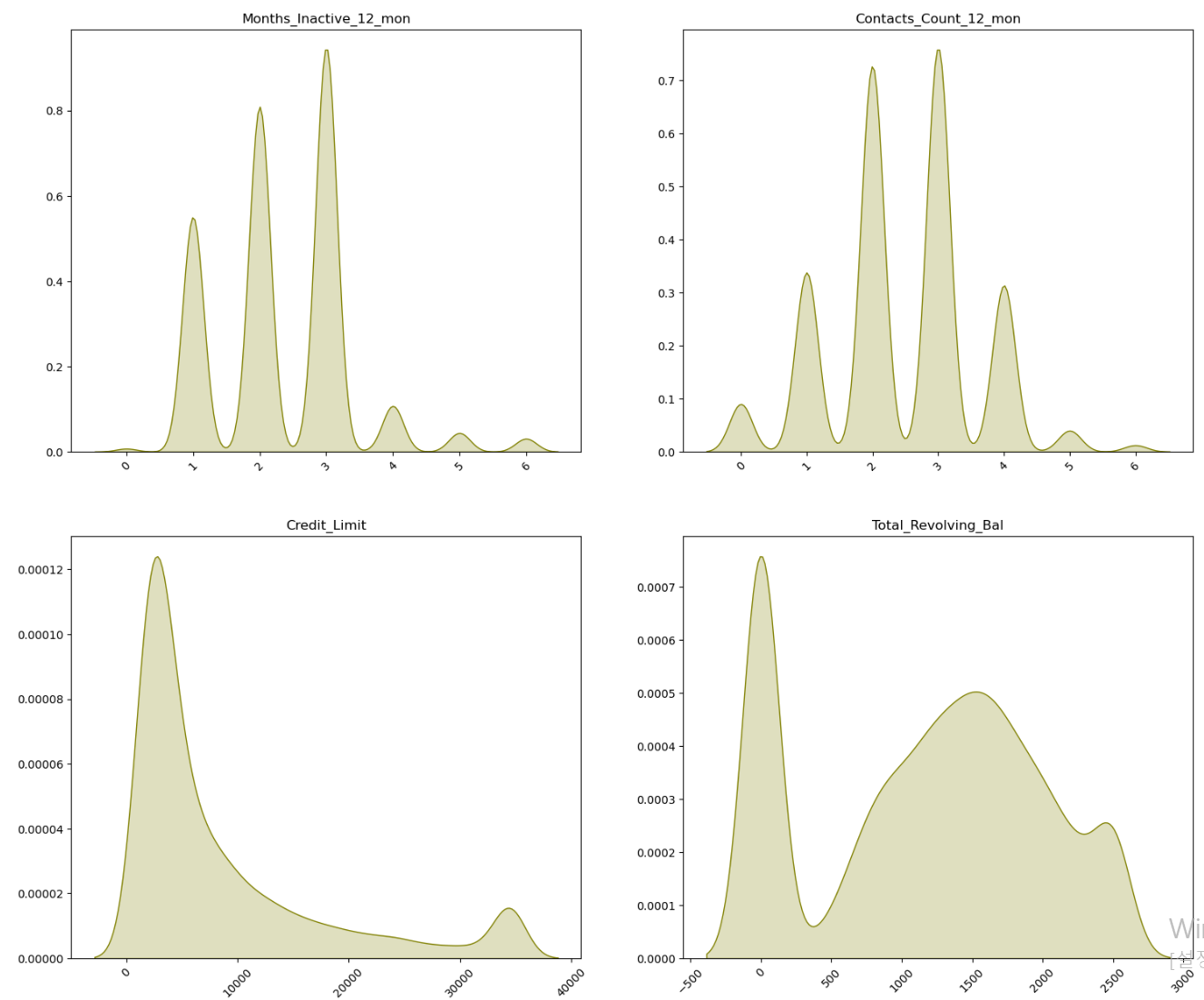
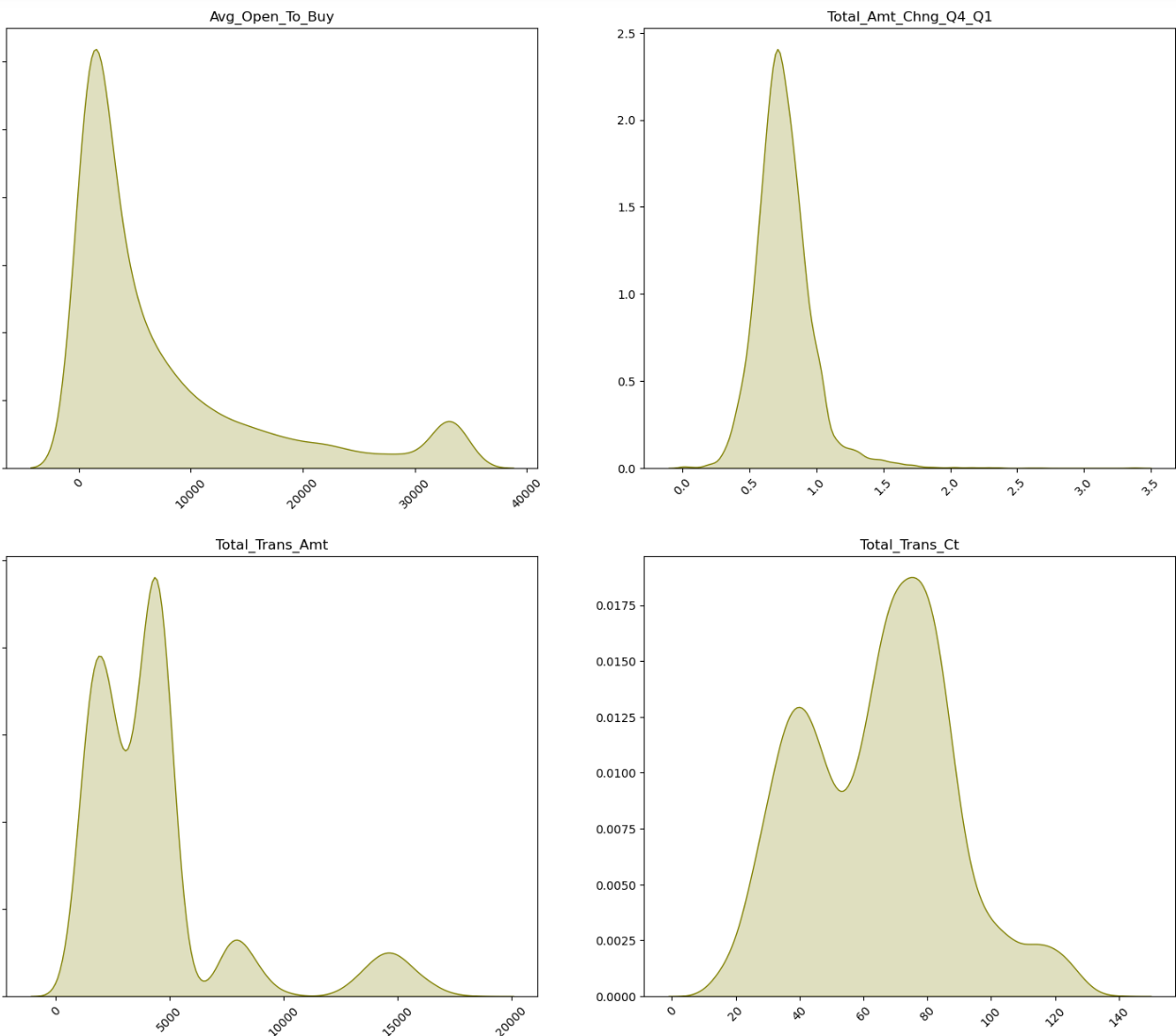
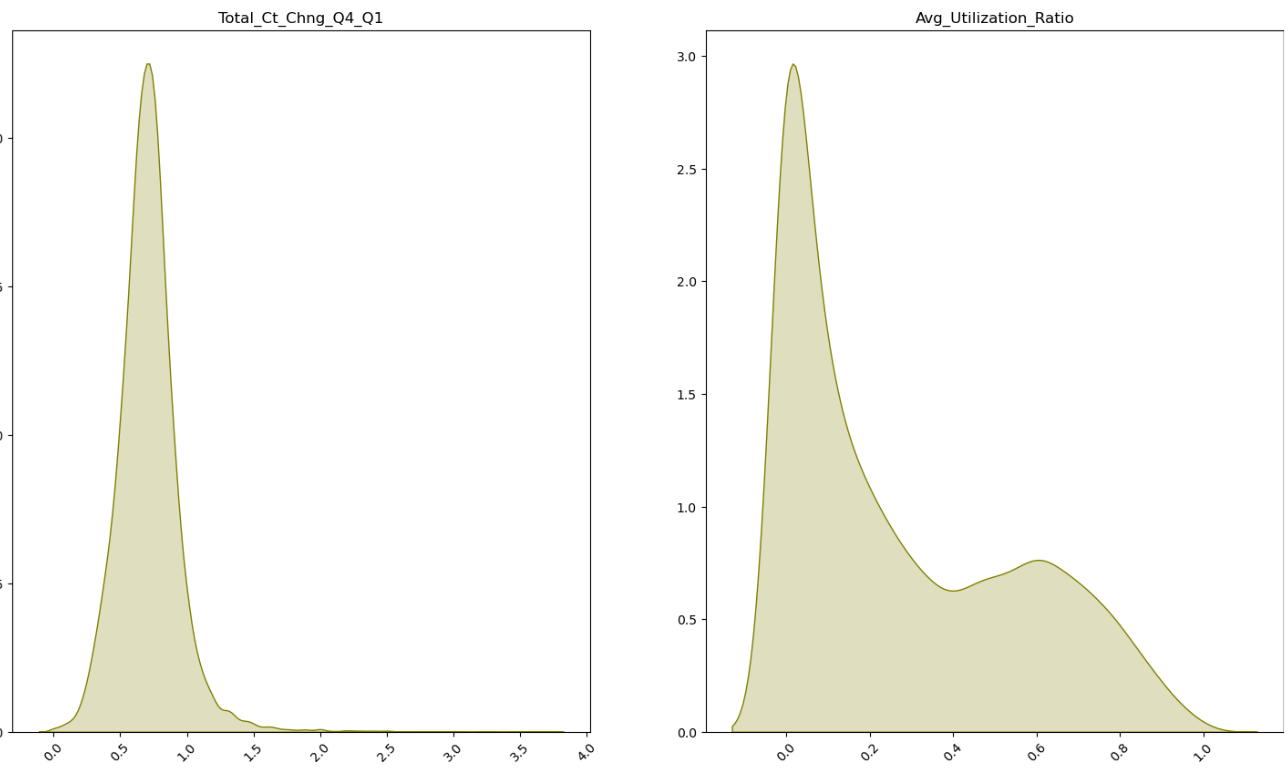
- 연속형 자료의 경우 전체적으로 이상치 데이터는 없어보이나, 12개월 내 비활성화된 횟수에서 5와 6에 해당하는 데이터의 수가 상대적으로 부족해보인다.

- 그리고 target데이터를 시각화해보니 떠난 고객의 데이터가 확실히 부족하다.
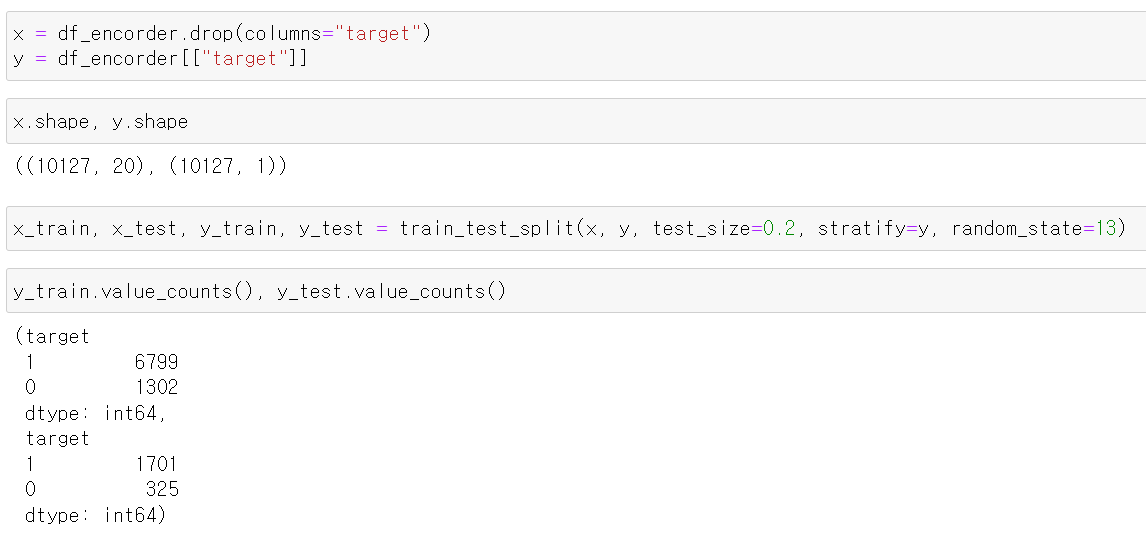
- 일단 기존의 데이터를 그대로 성능을 테스트하기 위해 train, test로 나눠주고
- 떠난 고객의 수가 부족하기 때문에 떠난 고객을 stratify 매소드를 이용해 같은 비율로 train, test에 할당했다.
- 확인해보니 정상적으로 구분되서 나뉘어졌다.

- 이제 4개의 모델 DecisionTree, RandomForest, xgbcBoost, lgbmBoost를 이용해 성능을 테스트하는 함수를 만들었다.
def print_modeling(x_train, x_test, y_train, y_test):
dc = DecisionTreeClassifier()
rf = RandomForestClassifier()
xb = XGBClassifier()
lg = LGBMClassifier()
acc = []
#DecisionTreeClassifier
params = {
"max_depth" : [3, 5, 7, 9, 11],
'random_state' : [13]
}
dc_grid_model = GridSearchCV(dc_model, param_grid=params, cv = 5, scoring='accuracy')
dc_grid_model.fit(x_train, y_train)
pred = dc_grid_model.predict(x_test)
acc.append(accuracy_score(y_test, pred))
dc_report = pd.DataFrame(classification_report(y_test, pred, output_dict=True)).transpose()
# RandomForest
params = {
"n_estimators" : [100, 500, 1000, 1500, 2000],
"max_depth" : [3, 5, 7 ,9],
"random_state" : [13]
}
rf_grid = GridSearchCV(rf, param_grid=params, cv=5, scoring="accuracy")
rf_grid.fit(x_train, y_train)
pred = rf_grid.predict(x_test)
acc.append(accuracy_score(y_test, pred))
rf_report = pd.DataFrame(classification_report(y_test, pred, output_dict=True)).transpose()
# xgbcBoost
params = {
"n_estimators" : [100, 500, 1000, 1500, 2000],
"max_depth" : [3, 5, 7 ,9],
"random_state" : [13]
}
xb_grid = GridSearchCV(xb, param_grid=params, cv=5, scoring="accuracy")
xb_grid.fit(x_train, y_train)
pred = xb_grid.predict(x_test)
acc.append(accuracy_score(y_test, pred))
xb_report = pd.DataFrame(classification_report(y_test, pred, output_dict=True)).transpose()
# lgbm
params = {
"n_estimators" : [100, 500, 1000, 1500, 2000],
'application' : ['binary'],
"max_depth" : [3, 5, 7, 9],
"random_state" : [13]
}
lg_grid = GridSearchCV(lg, param_grid=params, cv=5, scoring="accuracy")
lg_grid.fit(x_train, y_train)
pred = lg_grid.predict(x_test)
acc.append(accuracy_score(y_test, pred))
lg_report = pd.DataFrame(classification_report(y_test, pred, output_dict=True)).transpose()
df = pd.DataFrame(data={"accuracy" : acc})
df.rename(index={0 : "Decision", 1 : 'Randomforest', 2 : "XGBC", 3 : 'LGBMC'}, inplace = True)
return pd.DataFrame(data={"accuracy" : acc}), dc_report, rf_report, xb_report, lg_report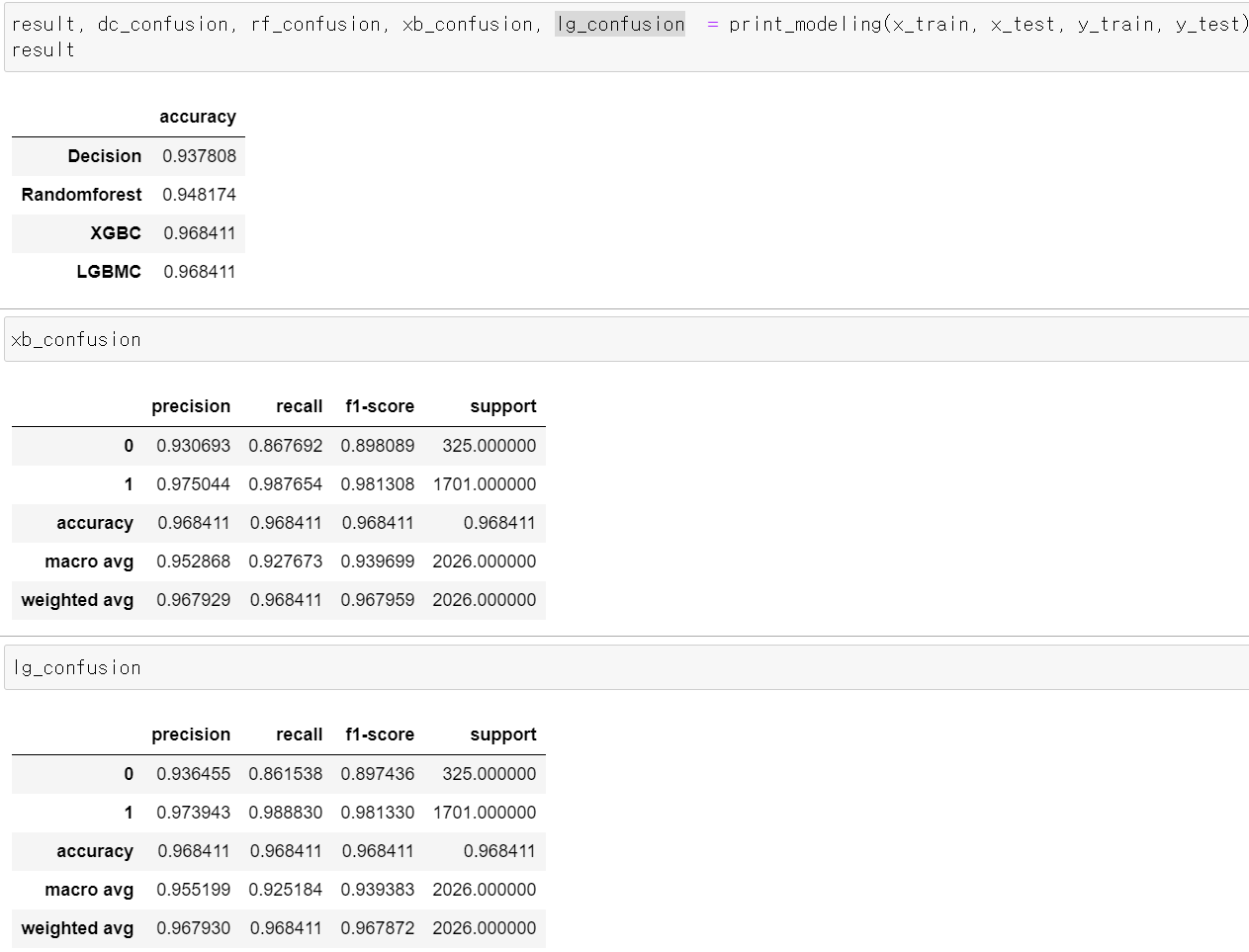
- 어라라...정확도가 왜 이렇게 좋지...0에 대한 Precision이라도 성능을 높여봐야겠다...!
9일차, 0에 대한 Recall값 개선
- 9일차에는 0에 대한 recall값을 개선하기 위해 PCA, clustering, SMOTE 세 가지 기법을 사용했다.
- 먼저 기존의 데이터는 20개의 컬럼을 가지고 있다.
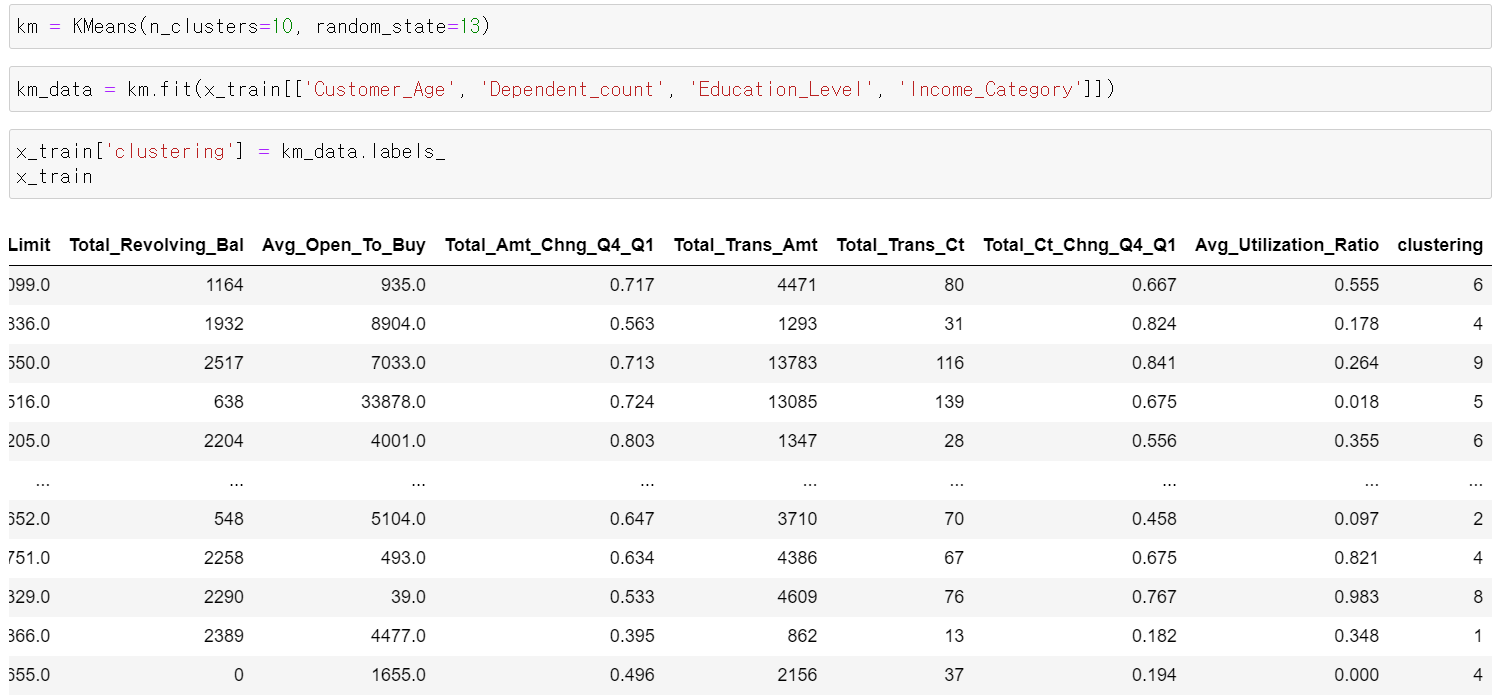
- 그리고 train데이터에 clustering을 형성하고, 학습시킨 내용을 통해 test데이터에도 군집을 형성했다.
- 일단 10개의 군집을 통해 0~9까지 군집을 만들었다.
- 군집 형성 데이터의 기준은 범주형 자료를 바탕으로 만들었다.
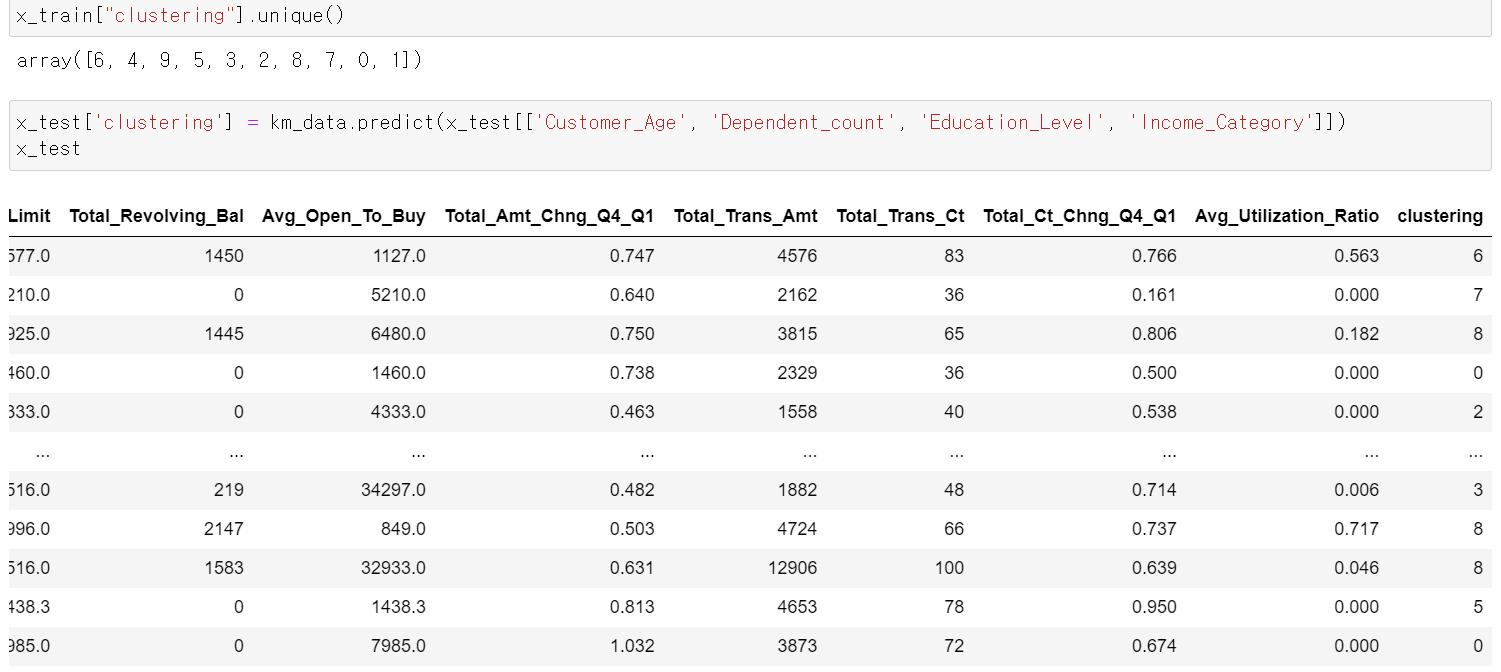
- test데이터에도 정상적으로 군집이 형성됐다.

- 이번에는 PCA기법을 통해 연속형 데이터를 바탕으로 2개의 차원으로 축소해서 새로운 Feature를 만들었다.
- 그리고 train데이터로 학습한 내용을 바탕으로 test데이터도 2개 차원으로 만들었다.
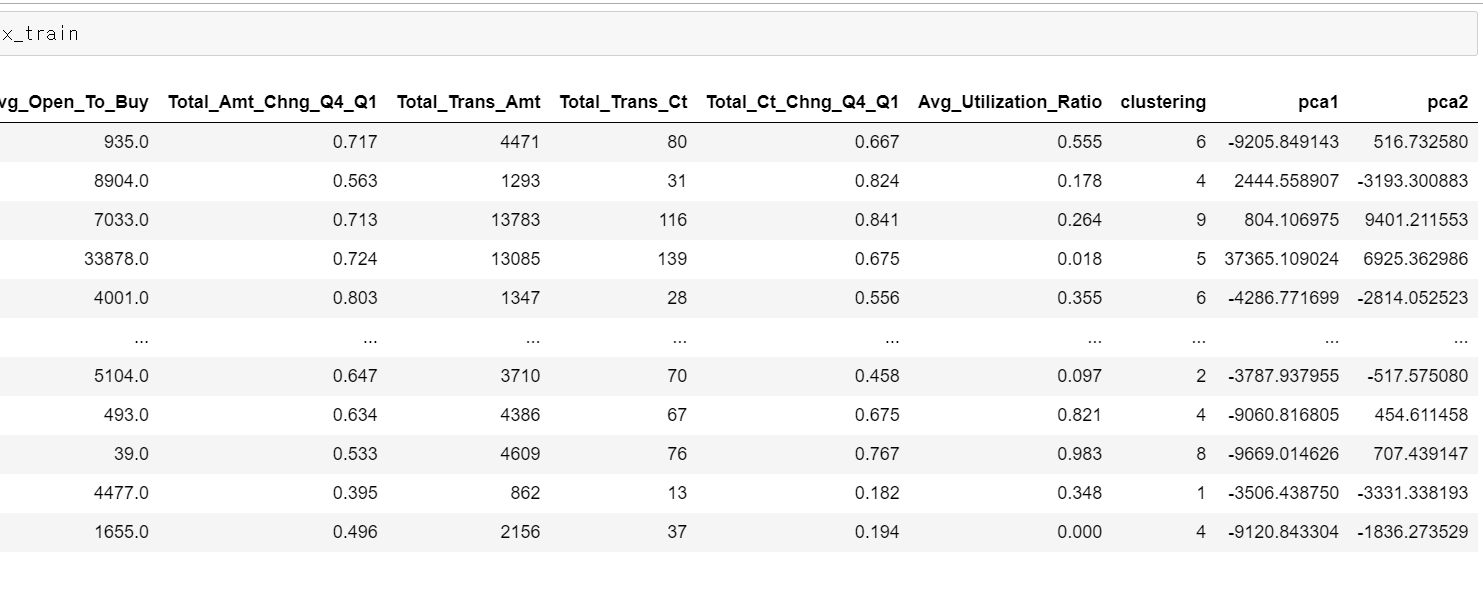
- train데이터를 확인 결과 두 개의 차원 데이터가 정상적으로 나왔고
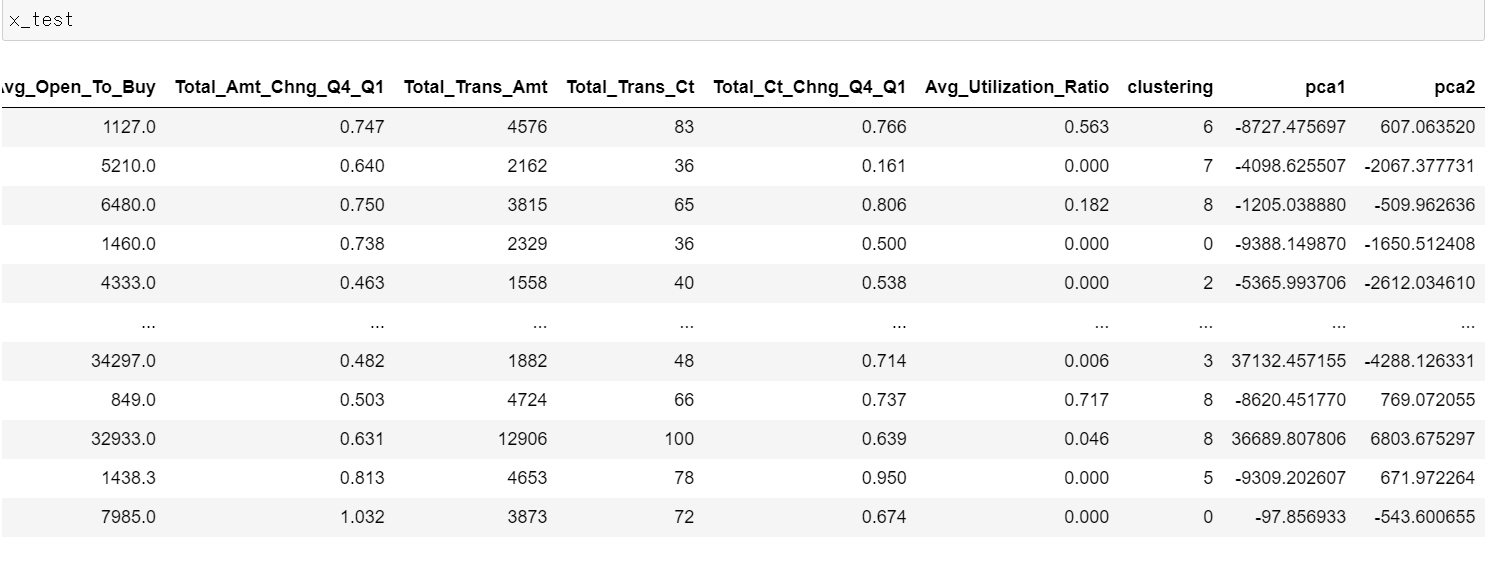
- test데이터에도 2개의 차원이 정상적으로 만들어졌다.

- 정확도를 기준으로 결과를 확인해보니 0.01정도의 accuracy가 증가했다.
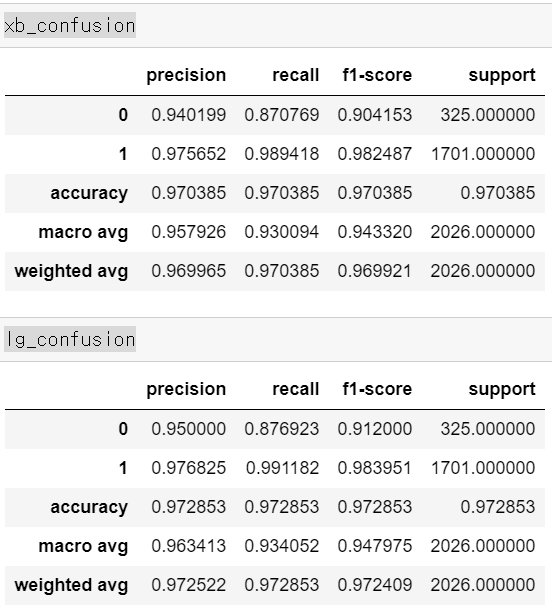
- 그리고 목적인 0에 대한 recall값은 0.01정도 올라갔으며, f1-score의 값은 0.01~0.02정도 올라갔다.
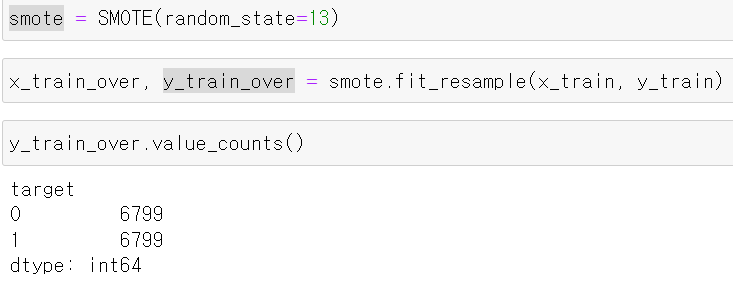
- 다음으로 0에 대한 train데이터를 SMOTE를 통해 0과 1에 대한 값을 똑같이 만들었다.

- accuracy값은 조금 떨어지고, lgbm의 결과에서 Recall값이 정말 조금 올라갔지만, 전체적인 0에 대한 Precision값이 크게 떨어짐
- 하지만, OverSampling을 통해 과적합이 해결될 수 있기 때문에 해당 Oversampling데이터로 성능 개선 시도
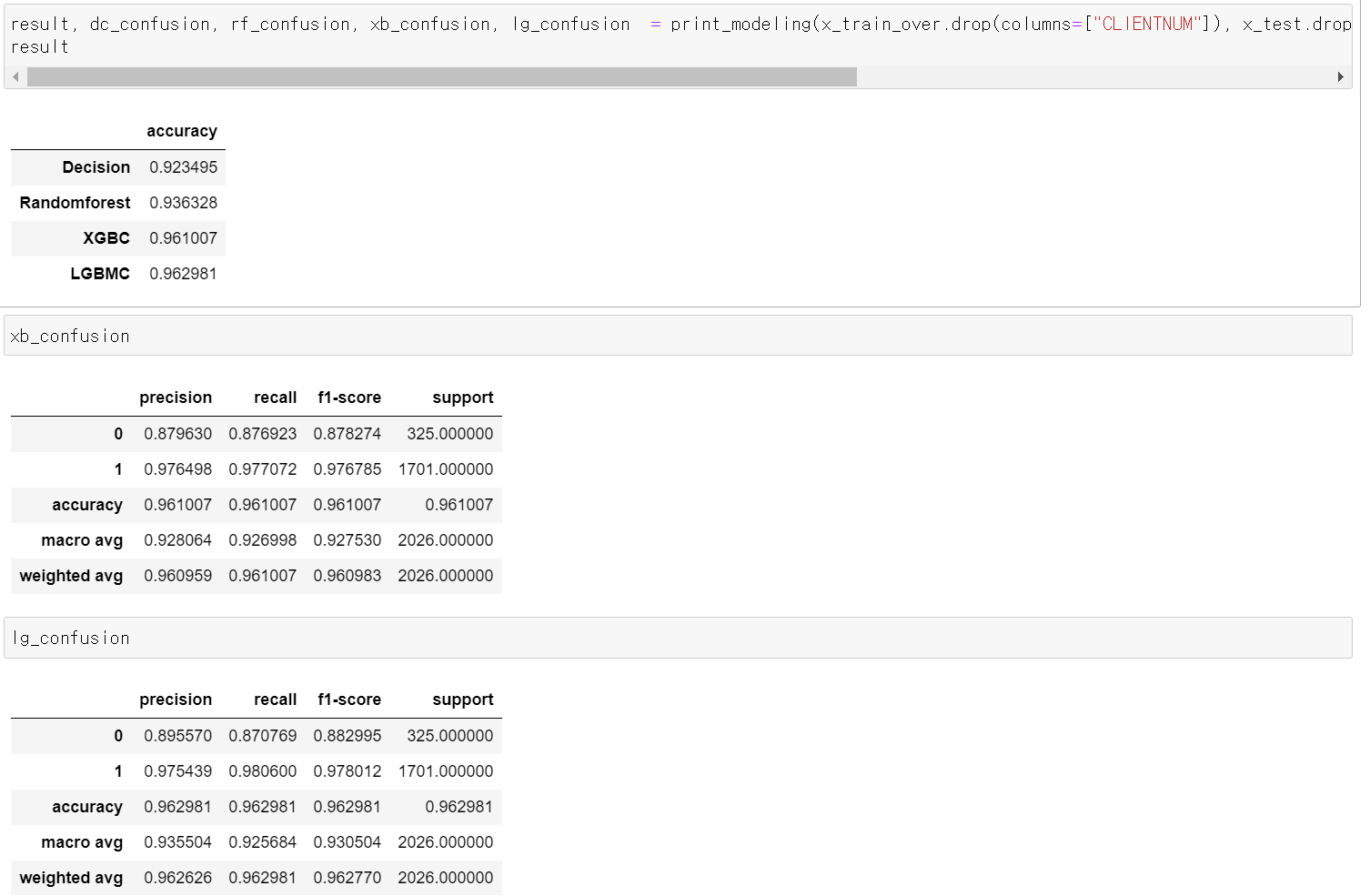
10일차, OverSampling데이터 성능 개선
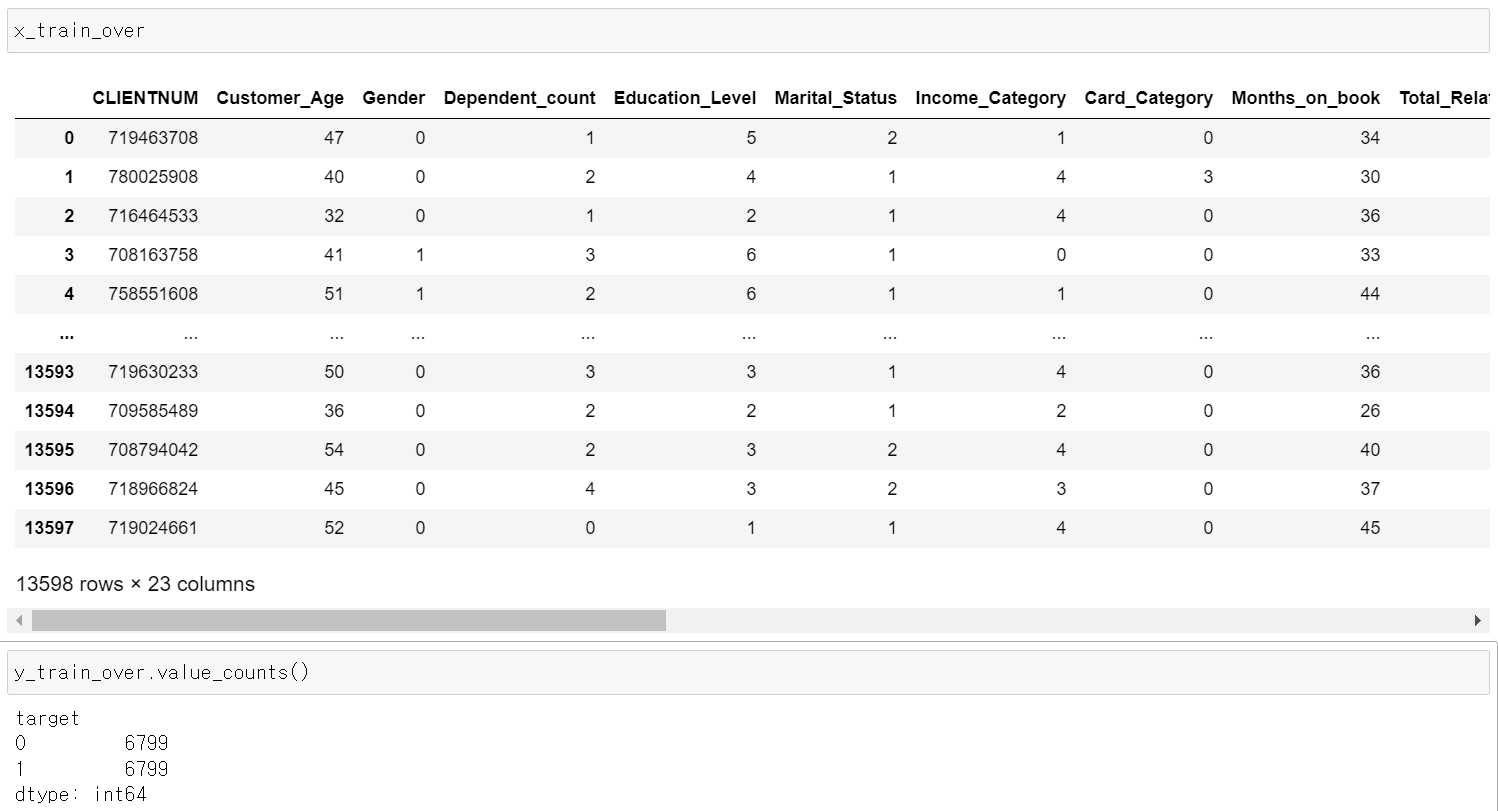
- 이전의 만든 OverSamplig 데이터를 불러와 Label값의 counts확인 결과 정상적으로 나왔다.
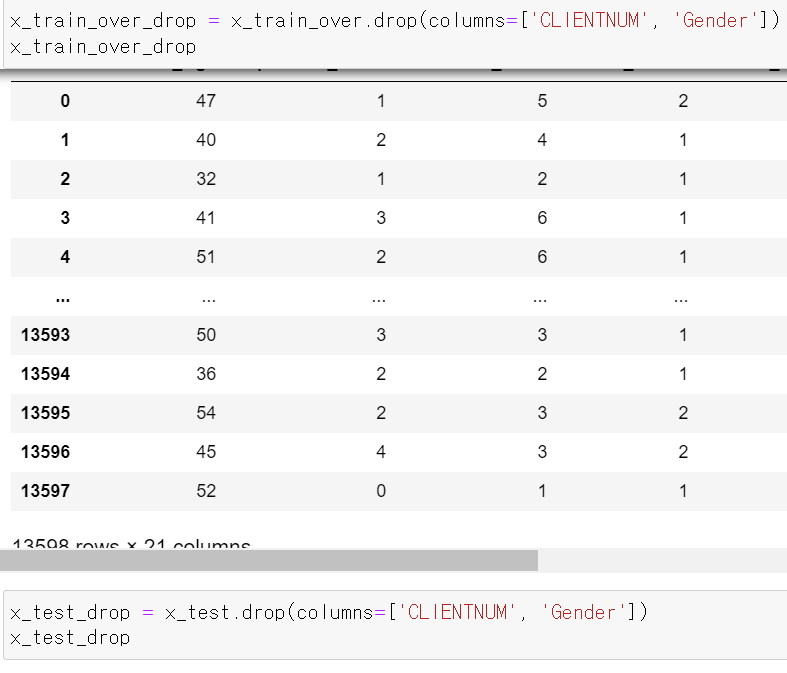
- 먼저 Feature 중 필요없는 고객번호와 Binary형태의 성별을 제거 후 성능을 테스트했다.
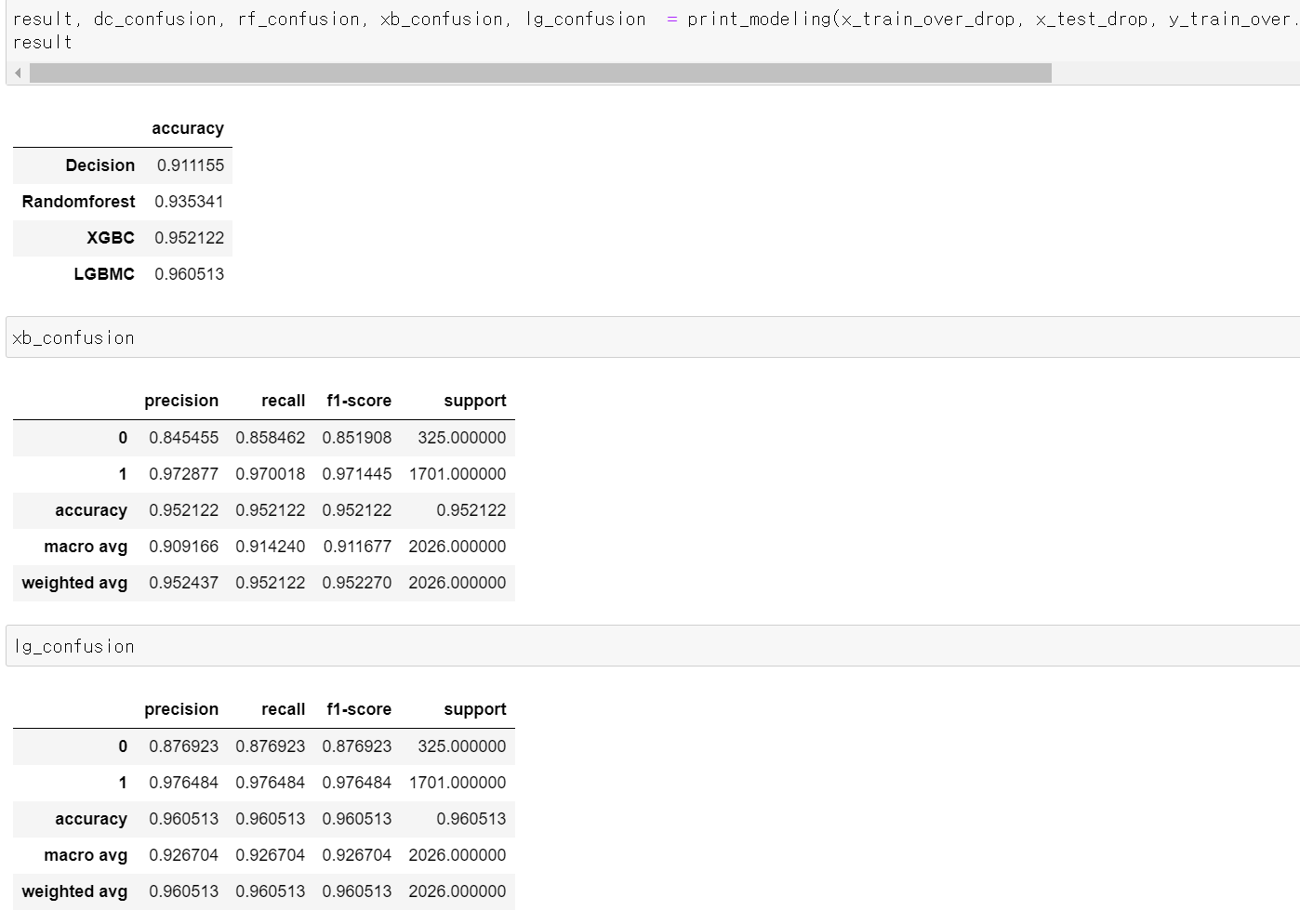
- 성능을 테스트한 결과 1%정도 떨어졌는데, 주관적인 생각에 성별이 영향을 미친 것 같다.
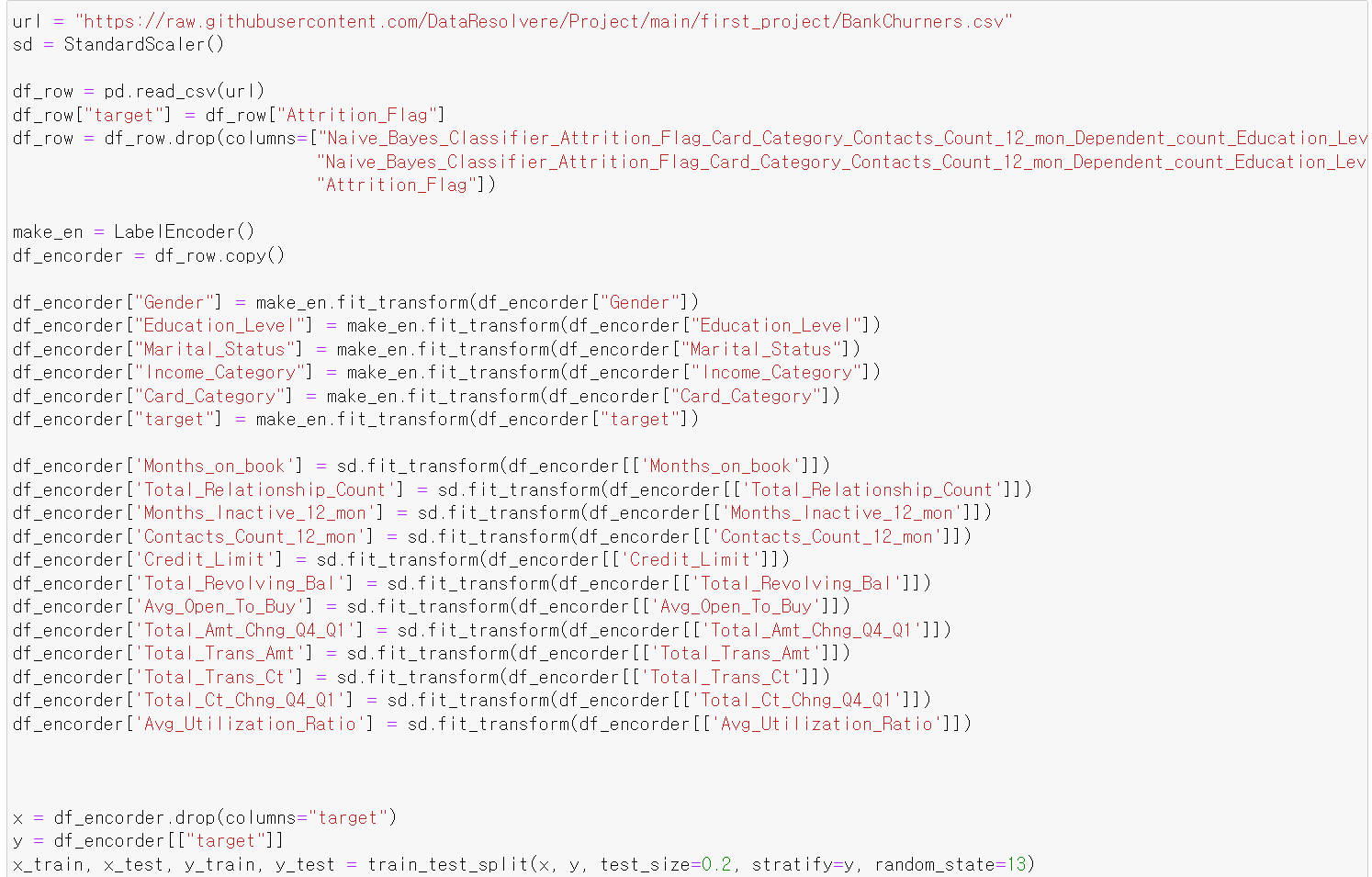
- 이제 성능을 테스트하기 전에 데이터를 불러오고, LabelEncoder작업과 Scale(Standard)작업을 진행했다.
- 그리고 train, test 데이터로 나눠주고

- 이후 위에와 같이 Clustering과 PCA작업을 진행했다.
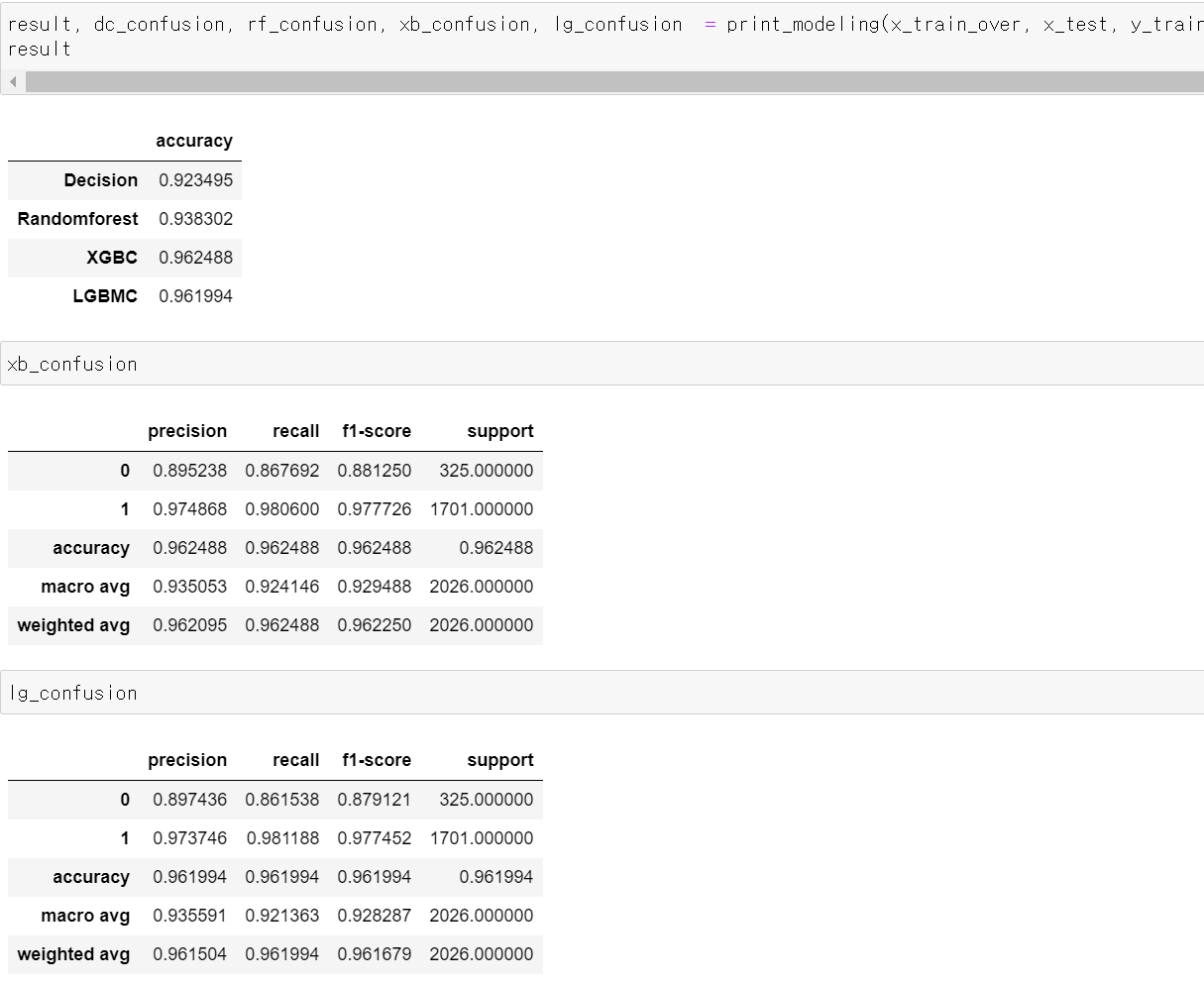
- 성능을 테스트한 결과 Scale값을 조정한다고 성능의 큰 개선이 이루어지지 않았다.
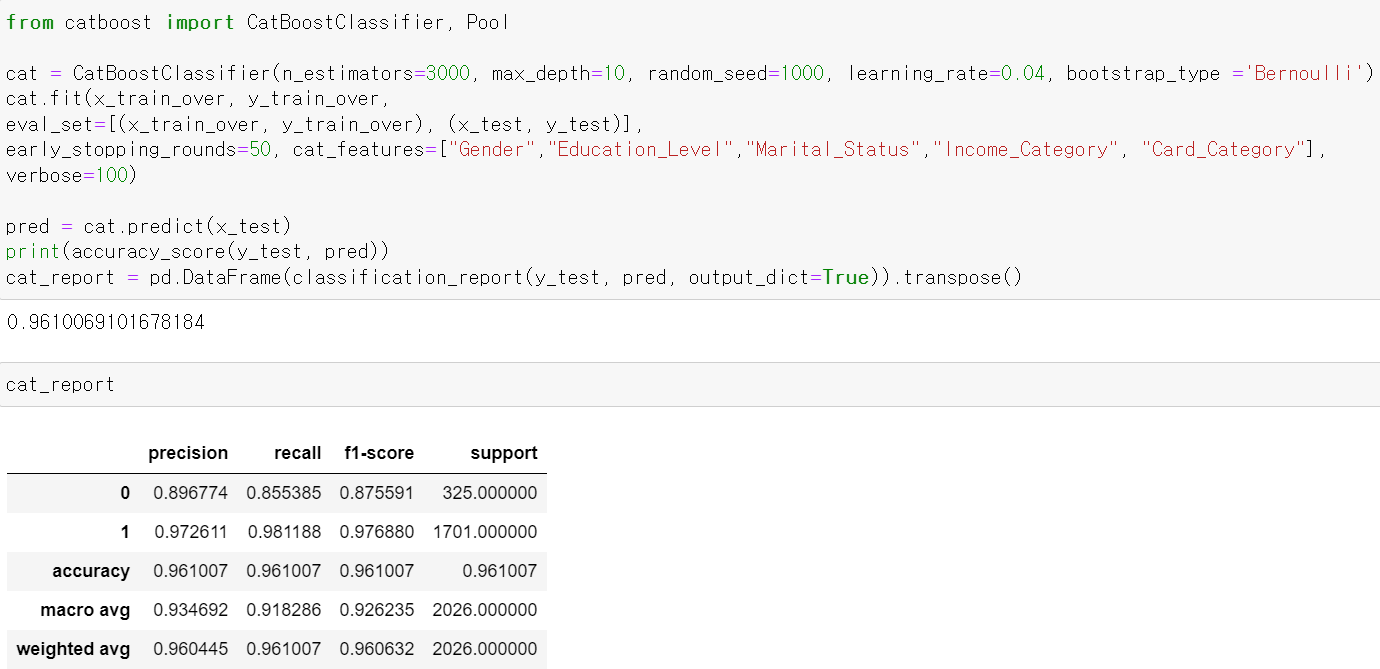
- 이번에는 cat_boost를 통해 성능을 테스트 한 후

- Feature 중요성을 확인해보니 5개의 Feature가 눈에 띄게 중요성을 보이기에 해당 5개의 Feature만 가지고 성능을 테스트해봤다.
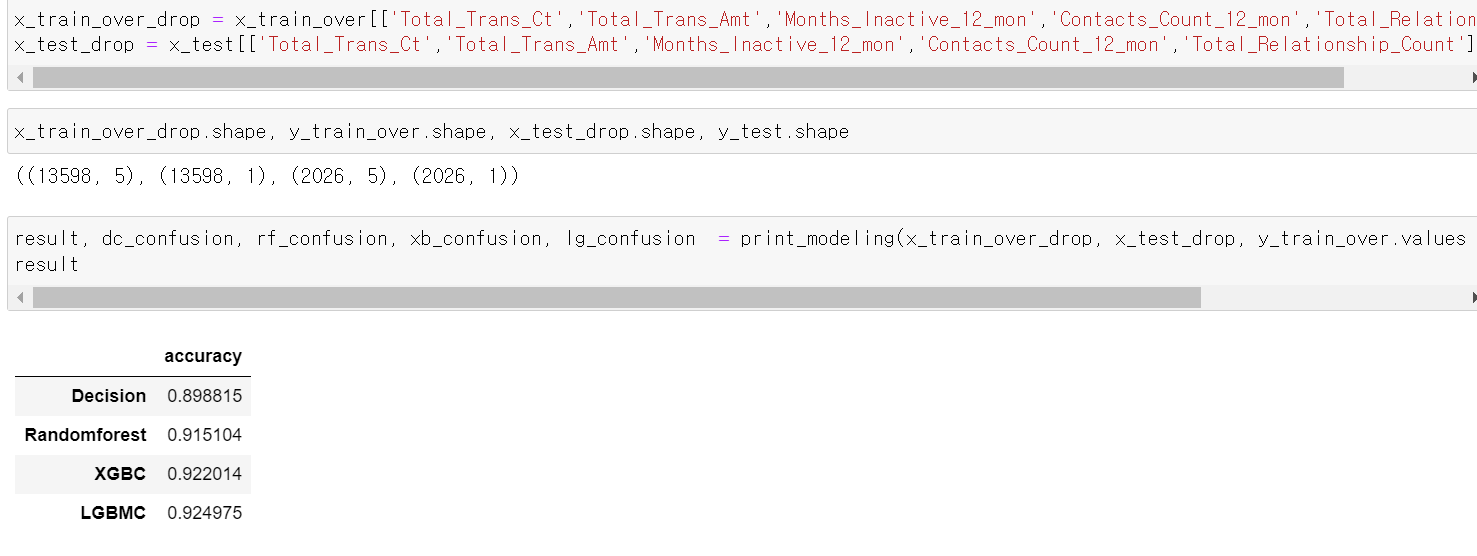
- 아무래도 Feature개수를 줄임으로써 성능이 다소 떨어졌다.
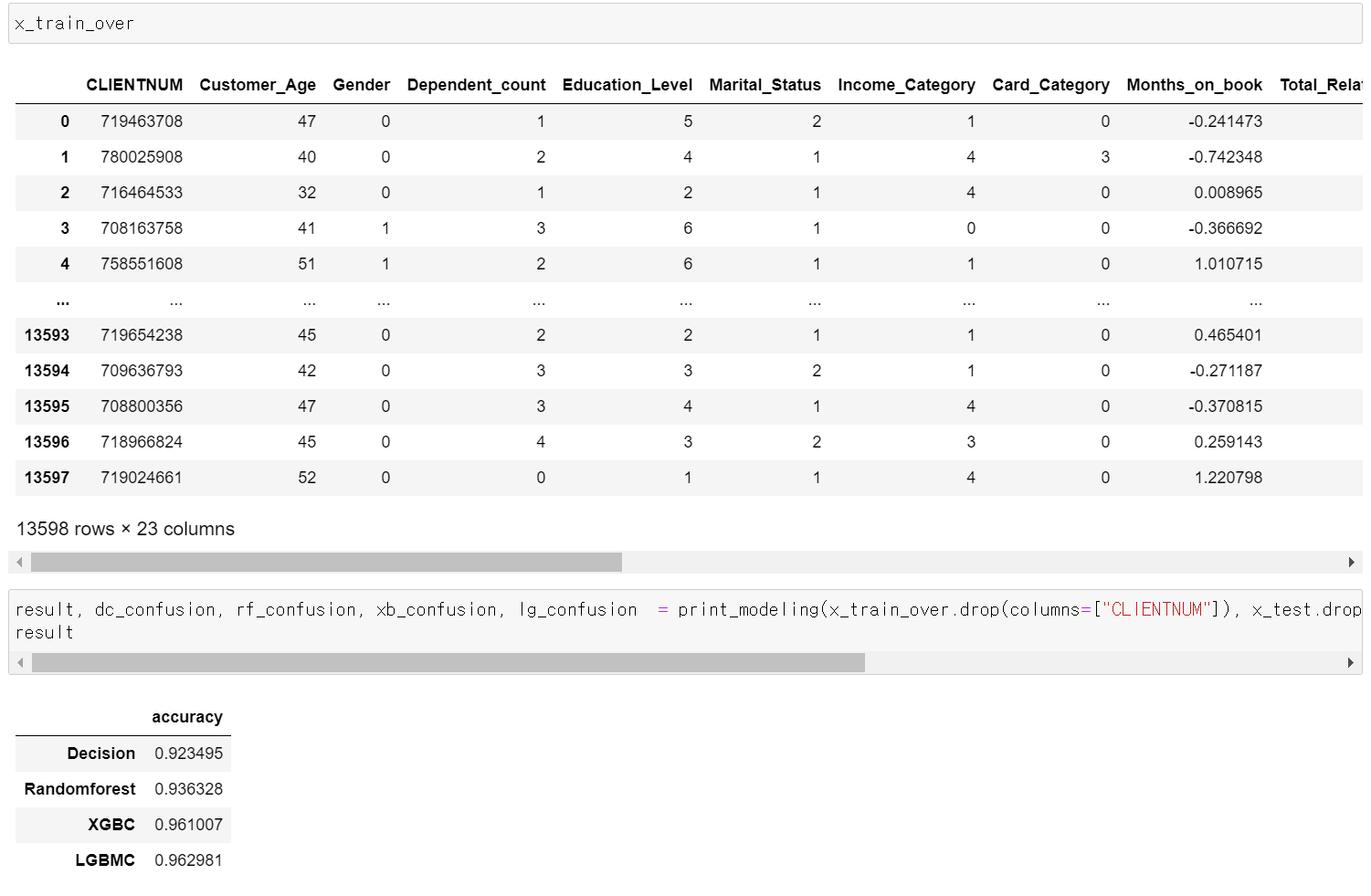
- 결과적으로 기존의 데이터는 이탈 고객의 데이터가 부족한 상태에서 accuracy가 높기 때문에 과적합이 있을 수 있다.
- 그래서 PCA, Clustering, SMOTE_overSampling 등 방법을 사용해서 데이터의 수를 늘리고 성능을 유지하면서 결과를 도출했다.

상황을 바꿀 수 없다면, 나를 바꾸자