
- 이번 프로젝트는 CNN모델을 기반으로 재활용품 사진을 통해 어떤 재활용품인지 분류하는 프로젝트를 진행했다.
- Git_hub : 링크
1. 데이터 수집 및 전처리
- 데이터는 AiHub의 생활폐기물 데이터를 바탕으로 딥러닝 프로젝트를 진행했다.
- 재활용 선별장, 실내형 분류기, 어플리케이션 3개의 항목에 따라 구분되어 있다.

- 먼저 하나의 사진을 불러오고, 데이터가 너무 크기 때문에 이미지의 size를 줄였다.
- 여기서 중요한 점은 OpenCv를 사용할 때 경로에 한글이 있으면 오류가 발생하니 조심해야한다.

- 원본 데이터와 새로운 데이터를 살펴보니 확살히 용량이 많이 줄었다.

- 하지만 문제는 하나의 사진에 여러 쓰레기가 묶여있다는 것이다.
- 각 쓰레기에 따라 Label을 줘야했는데
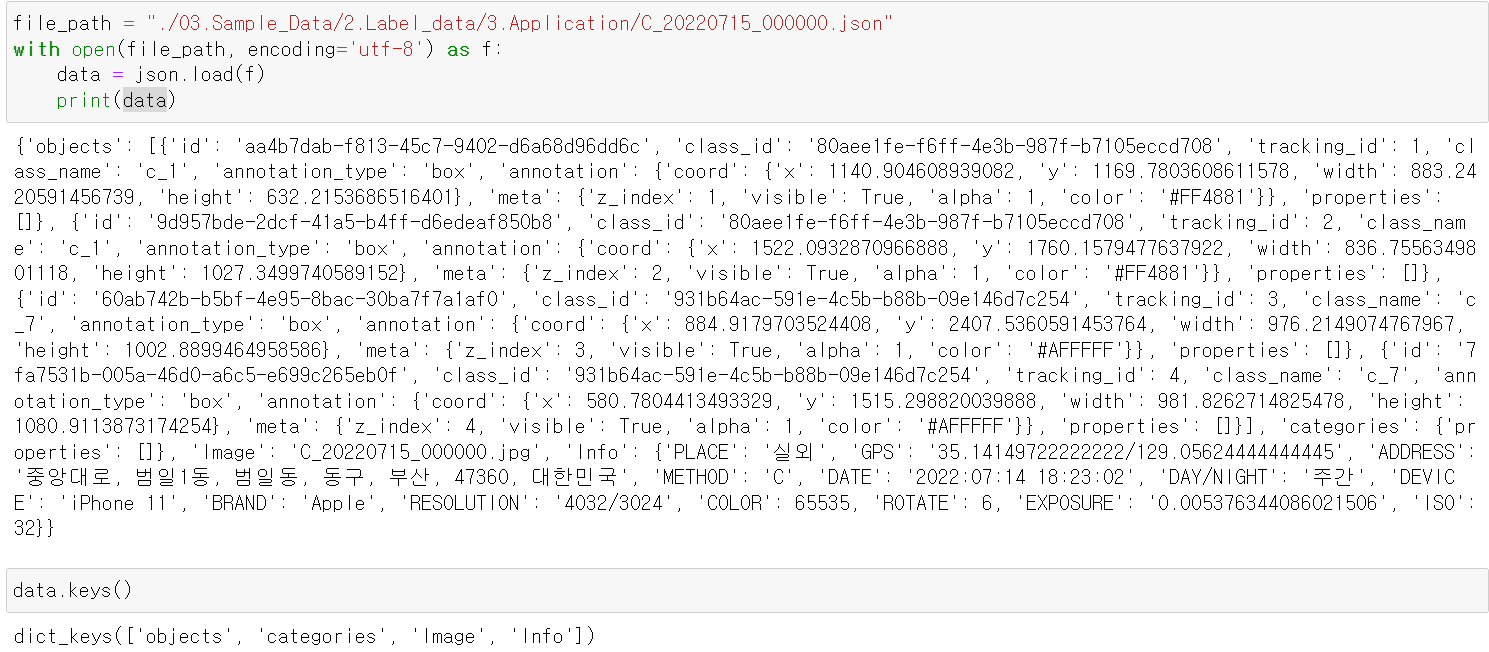
- 다행히 Json파일을 확인해보니 각 데이터의 Label값과 이미지의 위치가 저장되어 있다.
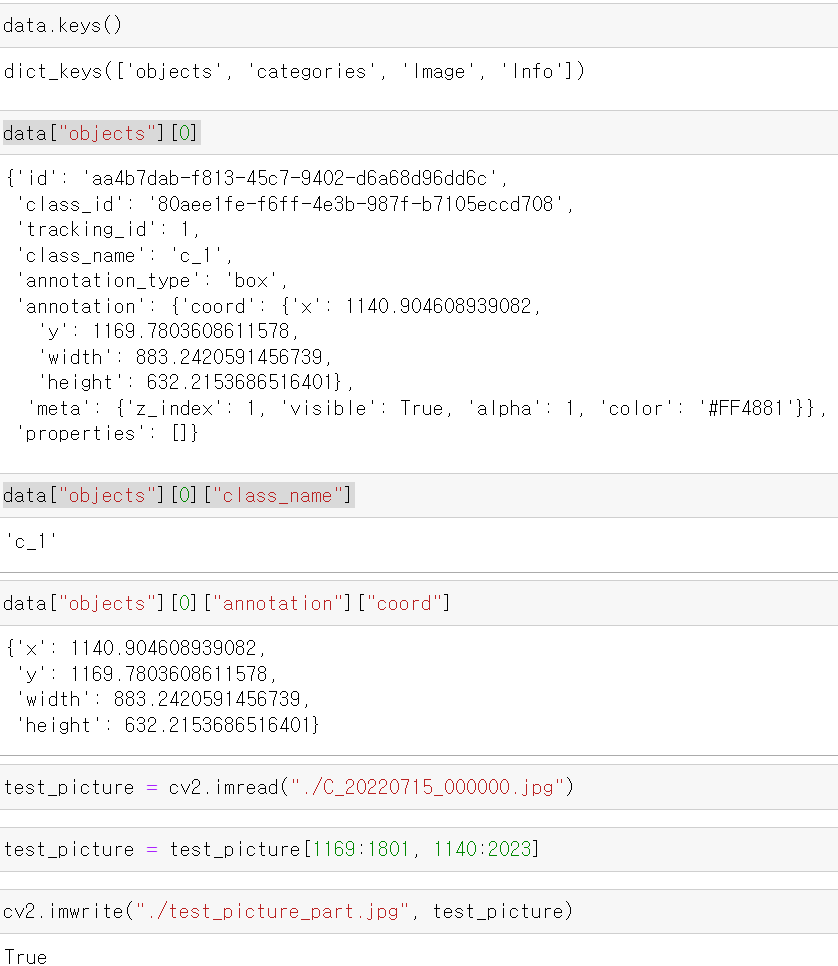
- Json파일의 형태를 확인 후 Label의 여부를 파악하고, 이후 해당 Label값의 사진 위치를 뽑았다.

- 위치를 잘라 확인해보니 정상적으로 이미지가 짤려서 나왔다.
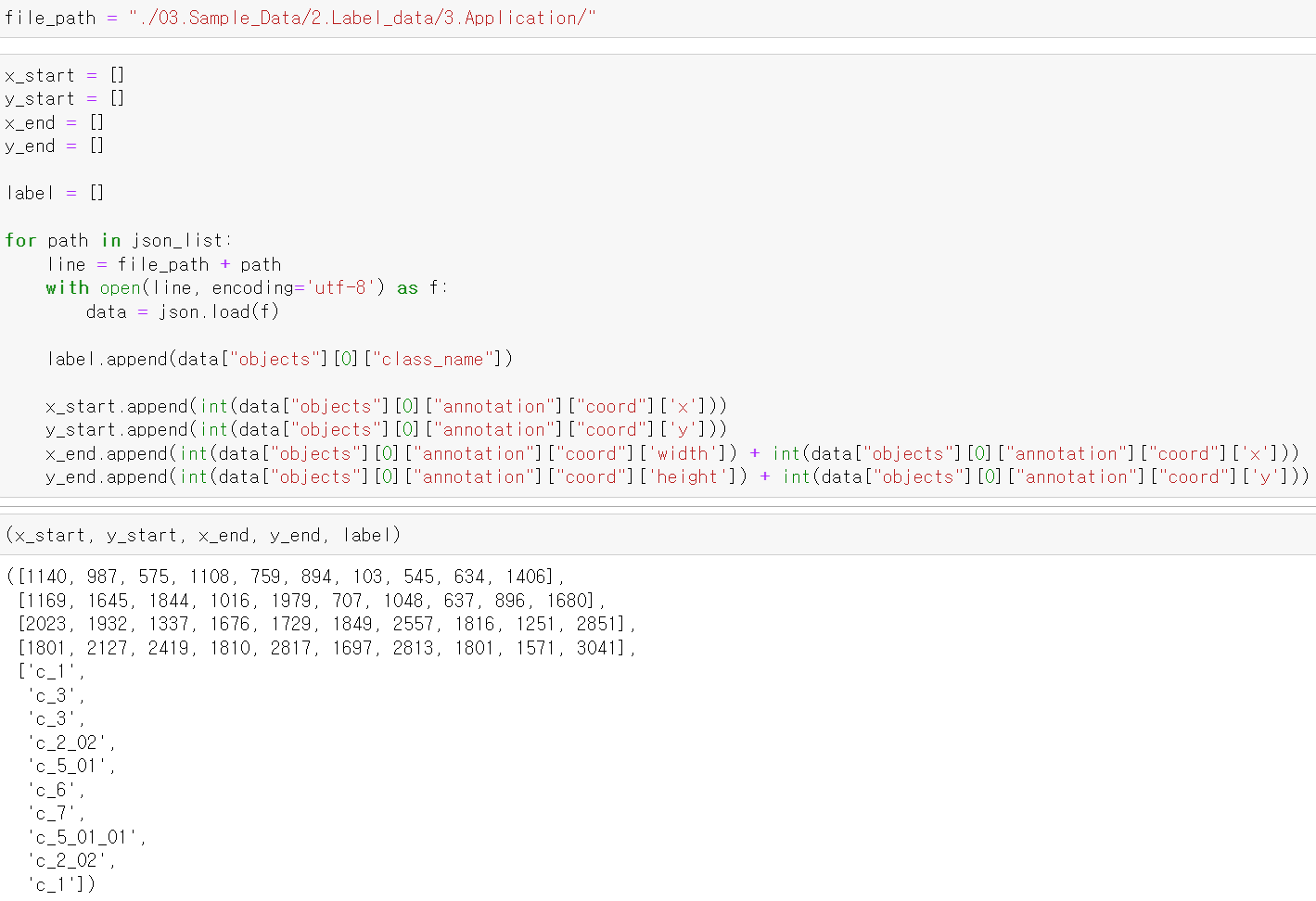
- for반복문과 os를 이용해 각 데이터의 경로를 저장하고, 해당 경로의 json파일에서 필요한 위치 데이터와 라벨값을 가져왔다.
- 실내형 분류기의 경우 파일의 깊이가 하나 더 늘어났다.
- 파일의 깊이가 하나 더 있기 때문에 이중 for을 통해 필요한 Label값과 사진의 위치를 저장했다.
- 재활용 선별장의 데이터도 같은 구조이기 때문에 똑같은 방법으로 진행했다.
- 하지만 문제가 하나의 사진에 여러 쓰레기가 있고, 각 데이터를 별도로 저장해야하는데 위치 데이터만 뽑는다고 끝나는 것이 아니었다.
- 그래서 json파일과 이미지 데이터를 한 번에 뽑아서 각 리스트에 저장해야겠다고 생각함.

- 먼저 이미지 size를 정하고, 위와 비슷한 방법으로 이미지와 json파일을 한 번에 불러와 각 Label값에 맞는 사진 데이터만 추출했다.
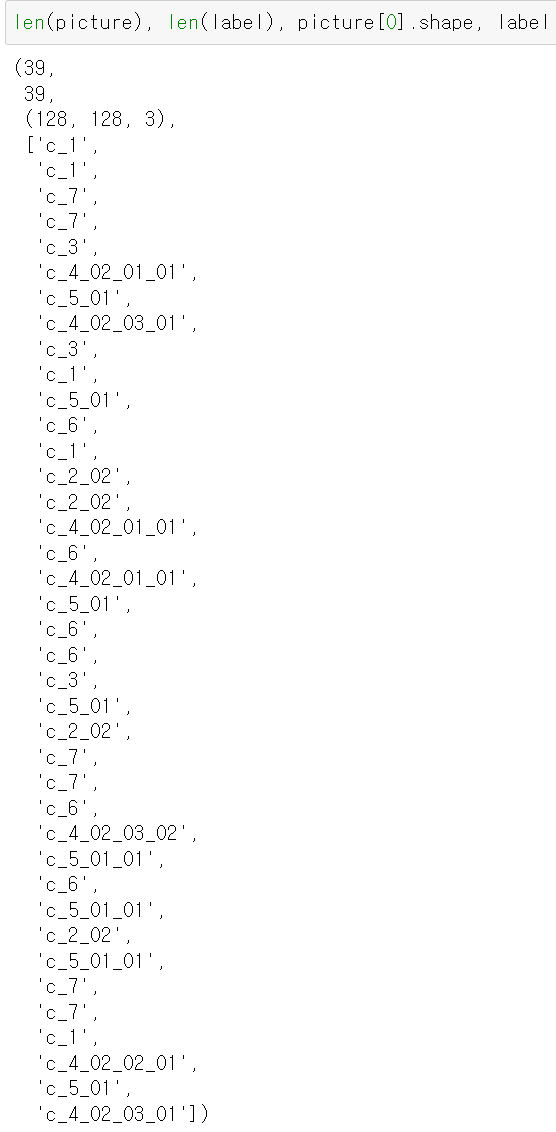
- 추출한 데이터를 확인해보니 정상적으로 39개의 사진과 각 라벨값이 출력됐다.
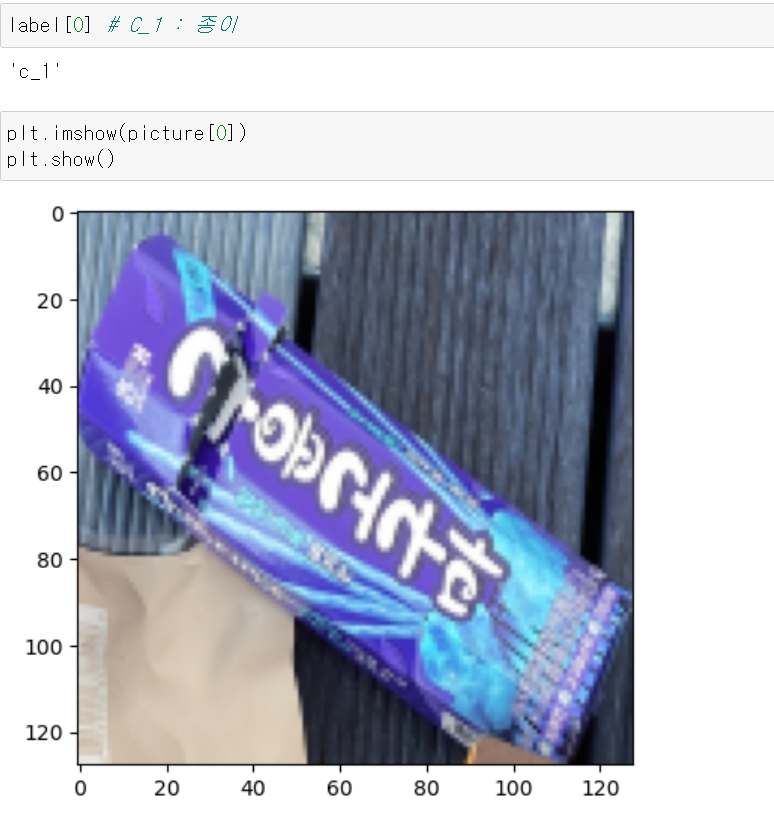
- OpenCV와 matplotlib의 rgb배열이 다르기 때문에 색감이 조금 이상하게 나오나, 리스트의 같은 위치에 라벨값과 사진 numpy배열이 제대로 입력됐다.

- 다시 확인해봐도 잘 뽑혔다.
- 다음으로 실내형 분류기 데이터를 위와 같은 방법으로 뽑고
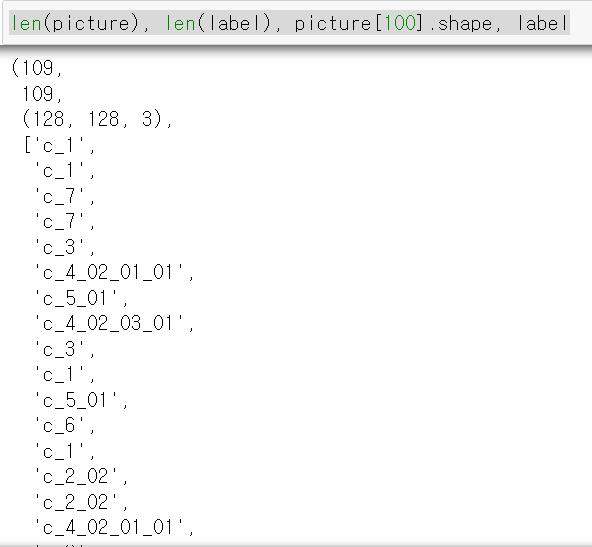
- 데이터의 길이와 라벨값이 정상적으로 저장됐다.
- 페트에 다중포장재가 Label값에 맞는 페트병이 나왔다.

- 마지막으로 재활용 선별장에서 뽑은 데이터도 추출 후 확인해보니 정상적으로 Label값과 사진이 일치한다.
- *위 과정의 데이터는 SampleData로 해당 방법을 원본 데이터에 적용했다.
- 데이터 전처리 이후 팀원들과 데이터를 공유하기 위해 picture_array데이터와 라벨값을 데이터프레임으로 만들어 공유하고자 먼저 사진 데이터를 flatten하고 다시 reshape으로 제대로 되는지 확인했다.
- 결과적으로 정상적으로 나왔다.
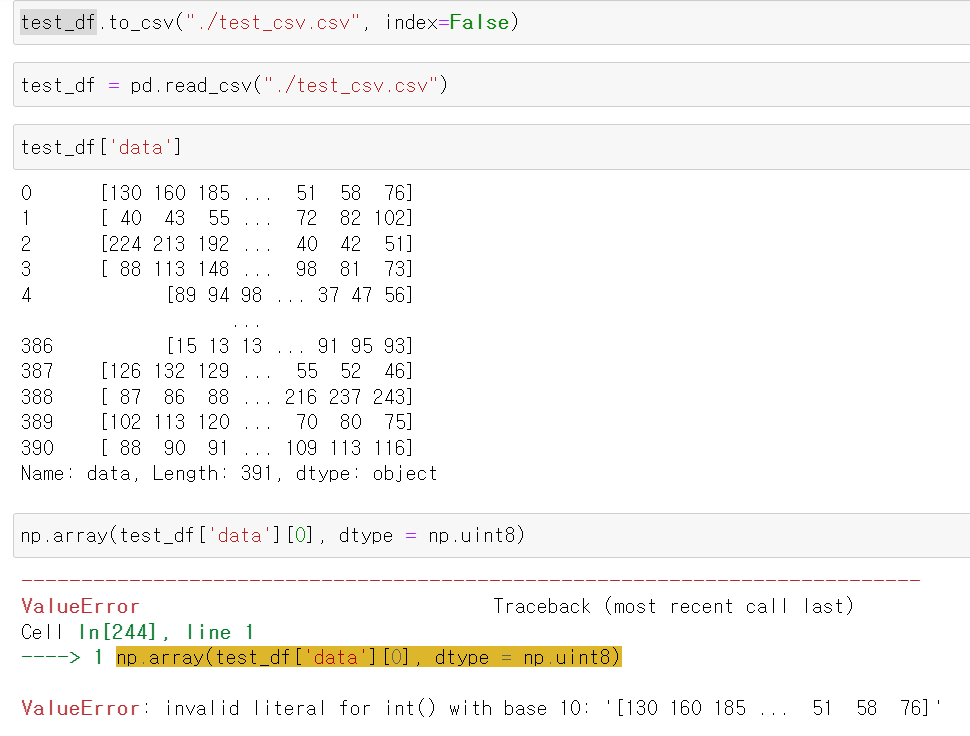
- 하지만 데이터프레임 데이터를 csv로 변환 후 다시 불러올 때 picture데이터가 string형태로 저장되어서 numpy에서 데이터 변환이 정상적으로 되지 않은 문제가 발생했다.
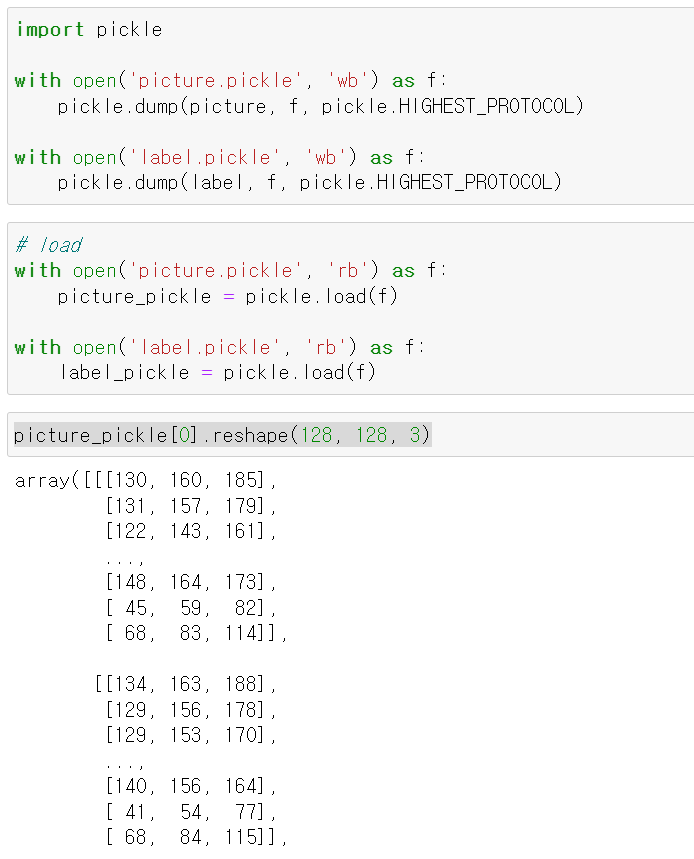
- 그래서 해당 문제를 해결하기 위해 아예 picture리스트 데이터 자체를 pickle로 Label값과 함께 저장 후
- 사이즈를 맞춘 뒤 이미지를 그려보니
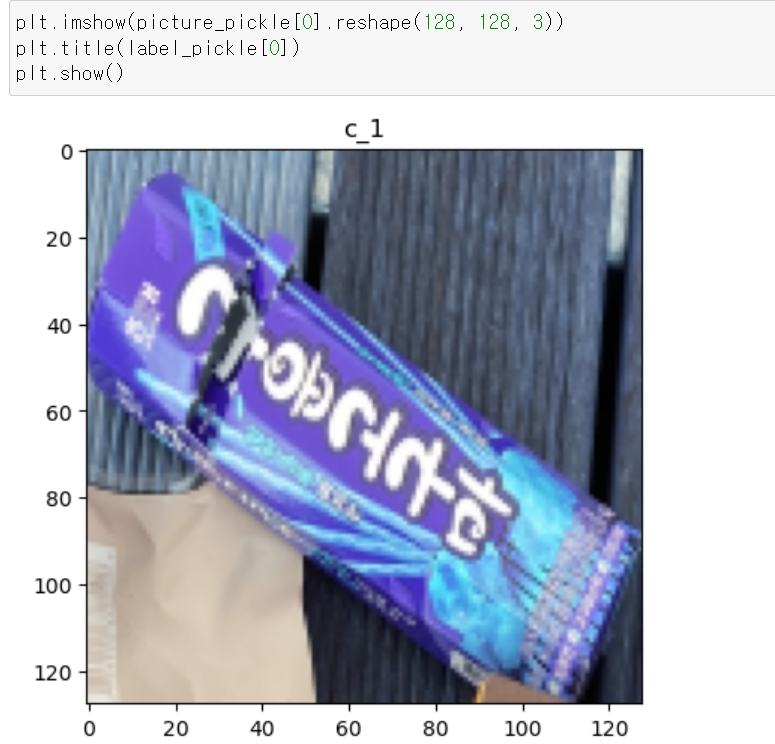
- 정상적으로 사진이 그려진다.

- 개인 노트북에서는 600GB의 원본 데이터를 처리할 수 없어, 친형집에서 4TB 데스크탑을 통해 14시간 동안 뽑은 데이터를 구글 드라이브에 Pickle타입으로 저장 후 원래 노트북에 load했다.

- load한 데이터에 이상이 없는지 확인하기 위해 먼저 이미지 데이터의 차원을 다시 128, 128, 3으로 돌려주고
- matplot를 통해 이미지 차원을 맞춰준 뒤 확인해보니

- 라벨값과 사진의 이미지가 정상적으로 매칭된다.
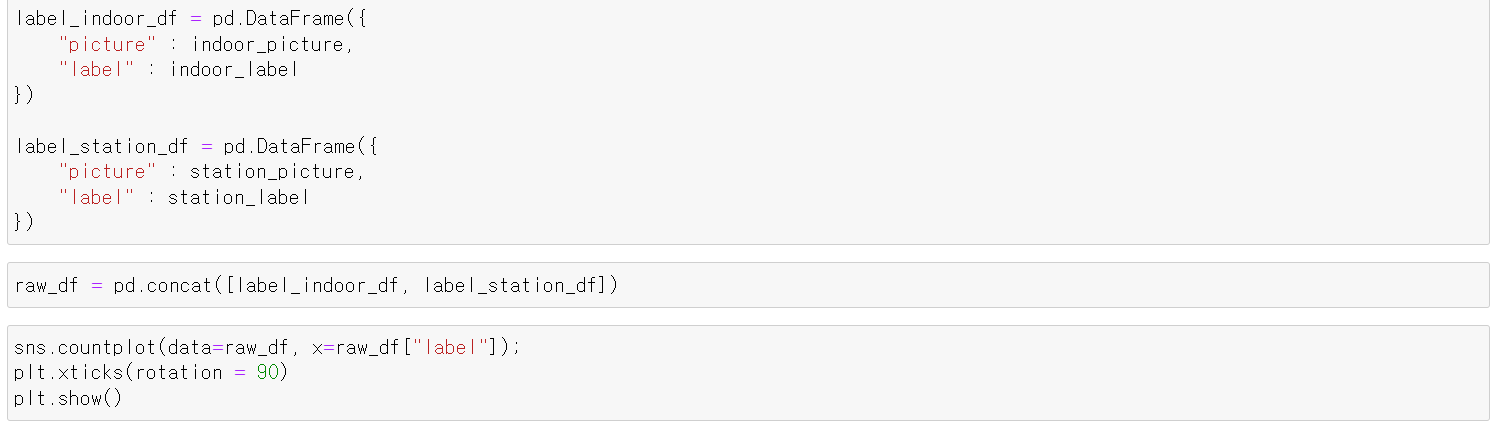
- 이제 두 장소에서 모은 데이터를 하나씩 데이터프레임으로 만들고, 하나의 프레임으로 만들어 raw_df변수에 저장했다.
- 이후 Label의 분포를 확인했다.
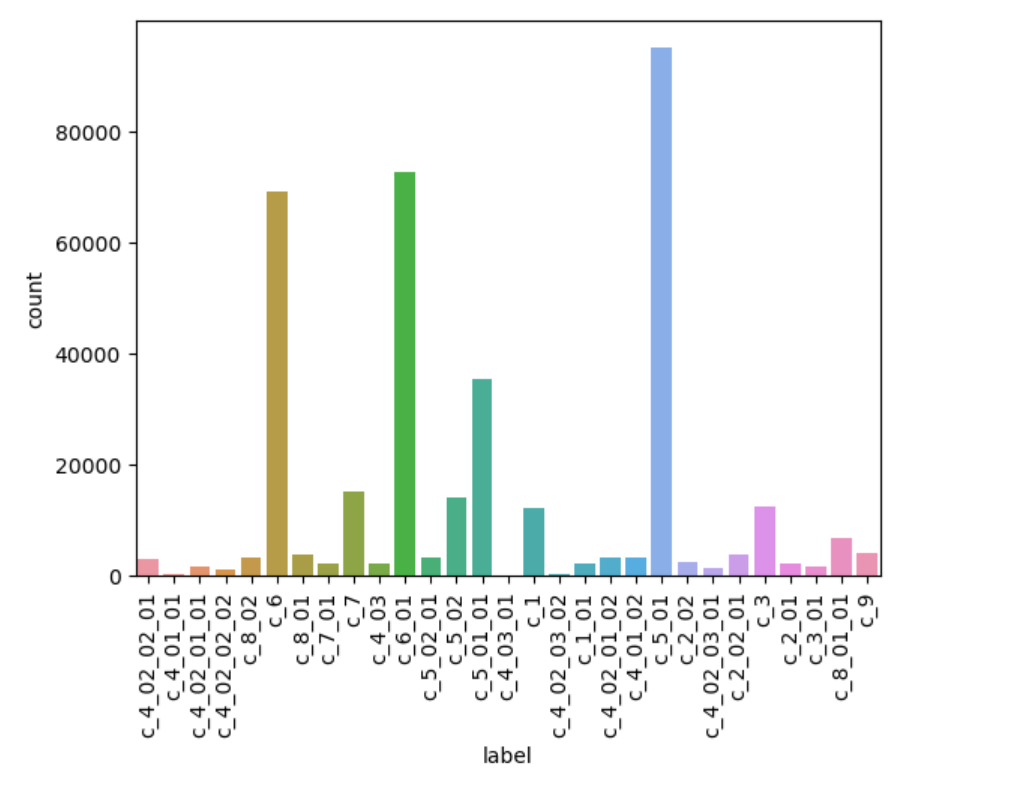
- C_4 재활용 쓰레기의 경우 녹색 유리병, 갈색 유리병 등 색을 구분한 유리병이기 때문에 데이터가 적으며, 비교적 수가 많은 플라스틱, 종이 등이 있다.
- 그리고 pickle로 불렀지만, 37만장의 사진이 담겨있기에 무거운 리스트 데이터를 지우고 하나로 묶은 raw_df를 9:1 비율로 train, test로 나눴다.
- 이후 난수의 설정을 13으로 고정하고 라벨값에 따라 분포의 비율을 일정하게 설정했다.
- 그리고 만든 train, test 데이터를 프레임 형태로 구분 후 reset_index로 인덱스를 재설정했다.
- 그리고 두 데이터프레임에서 재활용 쓰레기의 세분화된 Label값을 대분류별로 9개로 구분했다.
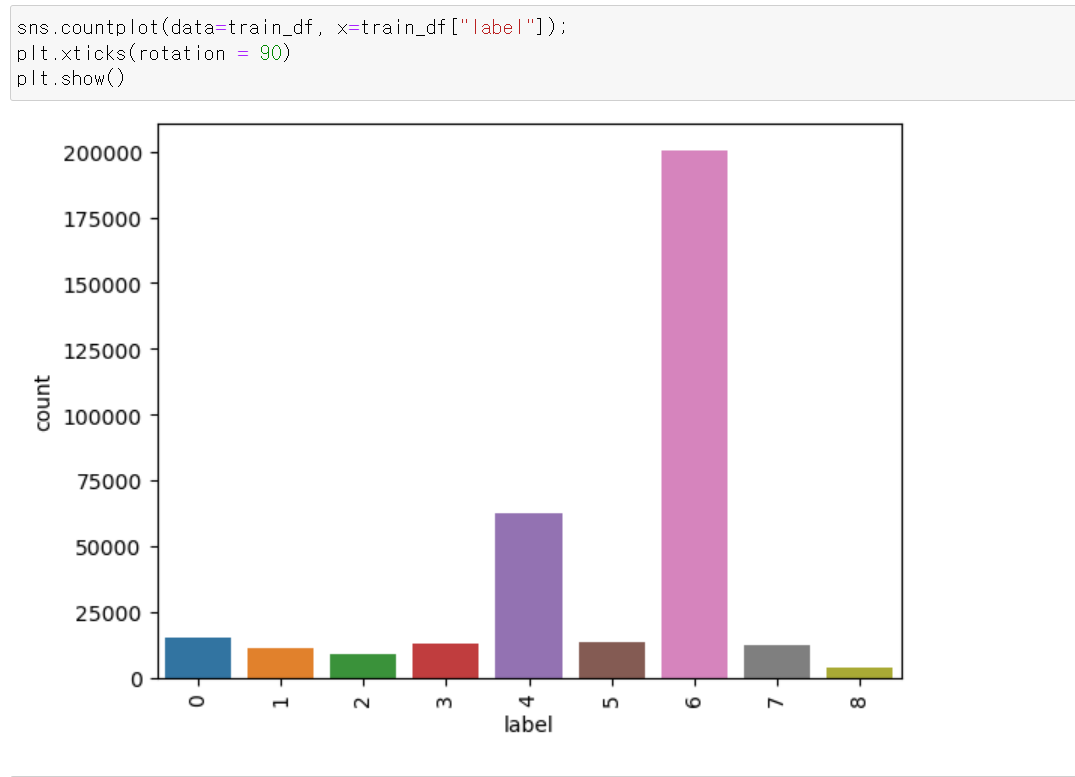
- 세분화된 Label값의 분포의 경우 플라스틱과 일반쓰레기의 비율이 많다.
- 일반쓰레기는 이물질이 묻은 플라스틱, 스티로폼 등 재활용이 불가능한 제품의 묶음이다.
2. Model_Train

- 프로젝트에서 가장 힘들었던 부분이다.
- train데이터의 경우 34만장의 사진이 데이터프레임으로 묵여있는데, 해당 데이터를 Tensor로 변환하는 순간 램의 용량이 버티지 못하고 자꾸 커널이 죽었다.
- 해당 문제를 해결하기 위해
- Tensorflow의 Dataset.make_CSV
- ImageGenerator
- Tensor_from_slice 등 많은 방법을 통해 시도했지만, 이미지 데이터 특성상 줄 구분이 많고, 무거워서 모든 방법이 에러가 발생했다.
- 그래서 해당 문제를 해결하기 위해 프레임으로 저장한 데이터에서 만 장씩 불러온 뒤 Label의 고유값이 9개 즉 모든 Label 추출되서 모델의 아웃풋값과 일치할 경우 Tensor로 변환했다.
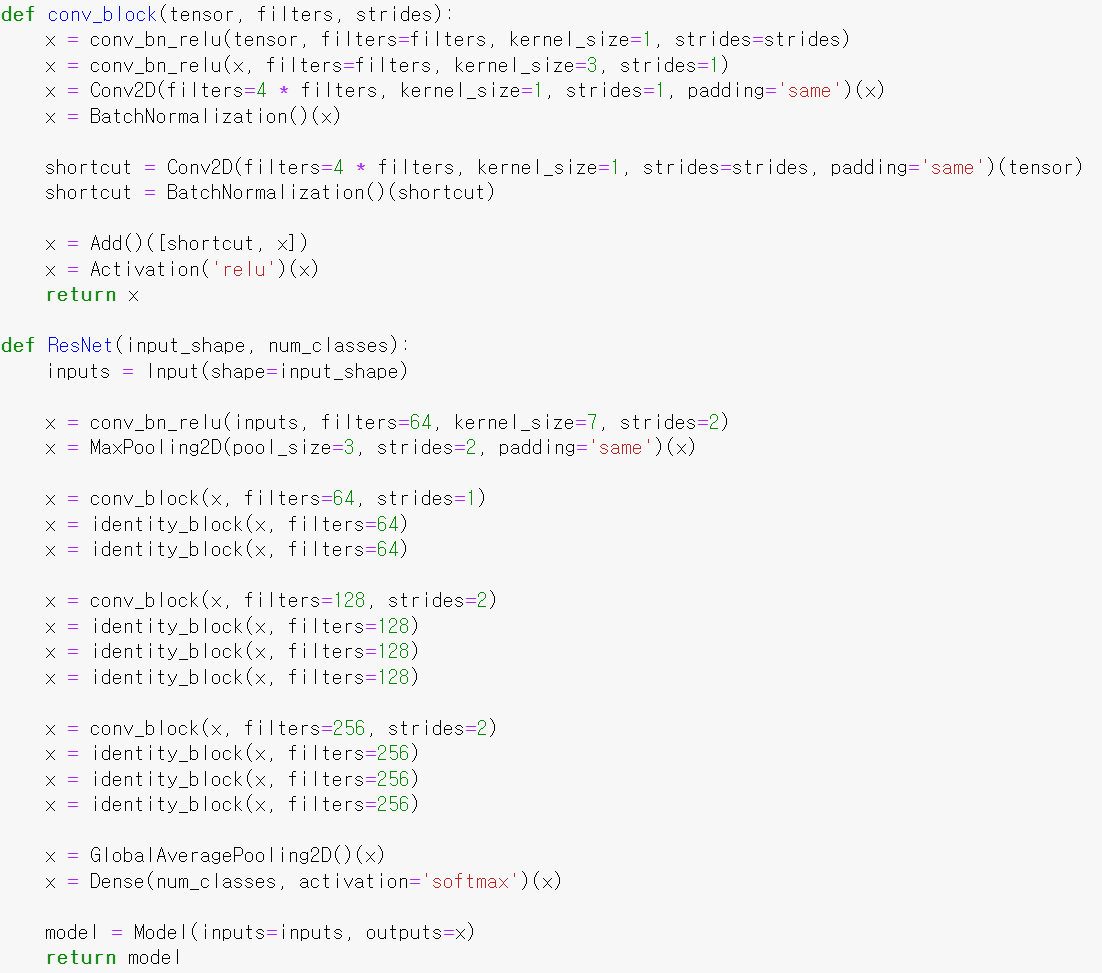
- 그리고 딥러닝 모델은 ResNet50으로 구축했다.
- 처음에는 VGGNet으로 시도했으나, 2만장까지 학습하는 과정에서 accuracy의 변환가 너무 미미해 모델을 바꿨다.
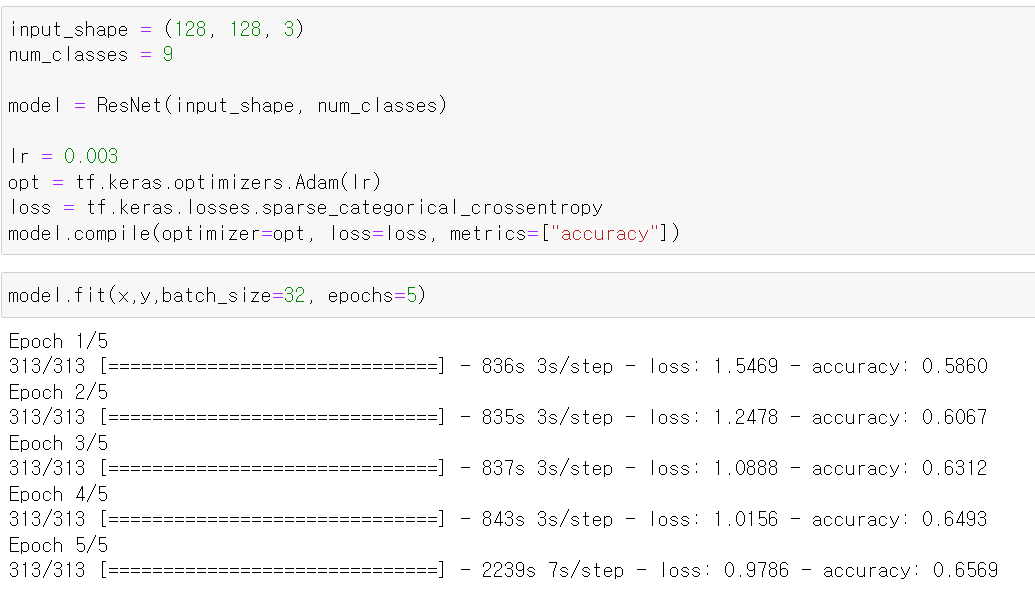
- 사진의 이미지와 차원을 저장하고, class 개수를 저정한 뒤
- 모델을 변수에 선언하고 learningrate는 0.03으로 준 뒤 adam과 원핫인코딩 효과를 내기 위해 sparse카테고리 loss를 사용했다.
- 이후 batch_size는 32, epoch는 5로 지정 후 모델을 학습시켰다.
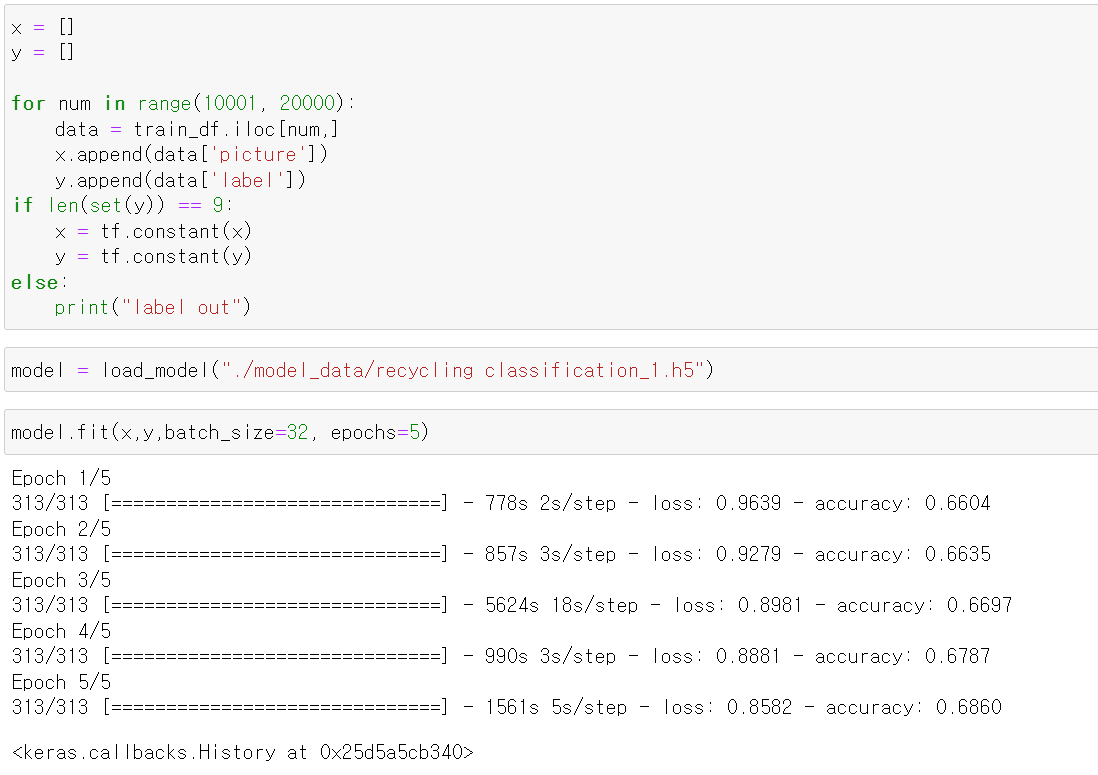
- 그리고 10001장부터 20000까지의 만장 사진을 뽑은 뒤 다시 교육하니 점점 accuracy가 높아졌다.
#Pickle 데이터 불러오기
with open('./data/train_label_indoor.pickle', 'rb') as f:
indoor_label = pickle.load(f)
with open('./data/train_picture_indoor.pickle', 'rb') as f:
indoor_picture = pickle.load(f)
with open('./data/train_label_station.pickle', 'rb') as f:
station_label = pickle.load(f)
with open('./data/train_picture_station.pickle', 'rb') as f:
station_picture = pickle.load(f)
for num in range(len(indoor_picture)):
indoor_picture[num] = indoor_picture[num].reshape(128, 128, 3)
for num in range(len(station_picture)):
station_picture[num] = station_picture[num].reshape(128, 128, 3)
label_indoor_df = pd.DataFrame({
"picture" : indoor_picture,
"label" : indoor_label
})
label_station_df = pd.DataFrame({
"picture" : station_picture,
"label" : station_label
})
raw_df = pd.concat([label_indoor_df, label_station_df])
del indoor_label
del indoor_picture
del station_label
del station_picture
x_train, x_val, y_train, y_val = train_test_split(raw_df['picture'], raw_df['label'], test_size=0.1, stratify=raw_df['label'],
random_state=13)
del raw_df
train_df = pd.DataFrame({
"picture" : x_train,
"label" : y_train
})
val_df = pd.DataFrame({
"picture" : x_val,
"label" : y_val
})
train_df = train_df.reset_index(drop=True)
val_df = val_df.reset_index(drop=True)
train_df.replace(['c_1', 'c_2_01', 'c_2_02'], [0,0,0], inplace=True)
train_df.replace('c_3', 1, inplace=True)
train_df.replace(['c_4_01_02','c_4_02_01_02','c_4_02_02_02','c_4_02_03_02','c_4_03'], [2,2,2,2,2], inplace=True)
train_df.replace("c_5_02", 3, inplace=True)
train_df.replace('c_6', 4, inplace=True)
train_df.replace('c_7', 5, inplace=True)
train_df.replace(["c_1_01","c_2_02_01","c_3_01","c_4_03_01","c_5_01_01","c_5_02_01","c_6_01","c_7_01","c_4_01_01","c_4_02_01_01","c_4_02_02_01","c_4_02_03_01","c_5_01"], [6,6,6,6,6,6,6,6,6,6,6,6,6], inplace=True)
train_df.replace(['c_8_01', 'c_8_02', 'c_8_01_01'], [7,7,7], inplace=True)
train_df.replace('c_9', 8, inplace=True)
val_df.replace(['c_1', 'c_2_01', 'c_2_02'], [0,0,0], inplace=True)
val_df.replace('c_3', 1, inplace=True)
val_df.replace(['c_4_01_02','c_4_02_01_02','c_4_02_02_02','c_4_02_03_02','c_4_03'], [2,2,2,2,2], inplace=True)
val_df.replace("c_5_02", 3, inplace=True)
val_df.replace('c_6', 4, inplace=True)
val_df.replace('c_7', 5, inplace=True)
val_df.replace(["c_1_01","c_2_02_01","c_3_01","c_4_03_01","c_5_01_01","c_5_02_01","c_6_01","c_7_01","c_4_01_01","c_4_02_01_01","c_4_02_02_01","c_4_02_03_01","c_5_01"], [6,6,6,6,6,6,6,6,6,6,6,6,6], inplace=True)
val_df.replace(['c_8_01', 'c_8_02', 'c_8_01_01'], [7,7,7], inplace=True)
val_df.replace('c_9', 8, inplace=True)
x = []
y = []
for num in range(60000, 70000):
data = train_df.iloc[num,]
x.append(data['picture'])
y.append(data['label'])
if len(set(y)) == 9:
x = tf.constant(x)
y = tf.constant(y)
else:
print("label out")
model = load_model("./model_data/recycling classification_6.h5")
model.fit(x,y,batch_size=32, epochs=5)
model.save("./model_data/recycling classification_7.h5")- 위 코드를 바탕으로 만 장씩 데이터를 모델에 전이학습을 진행했다.
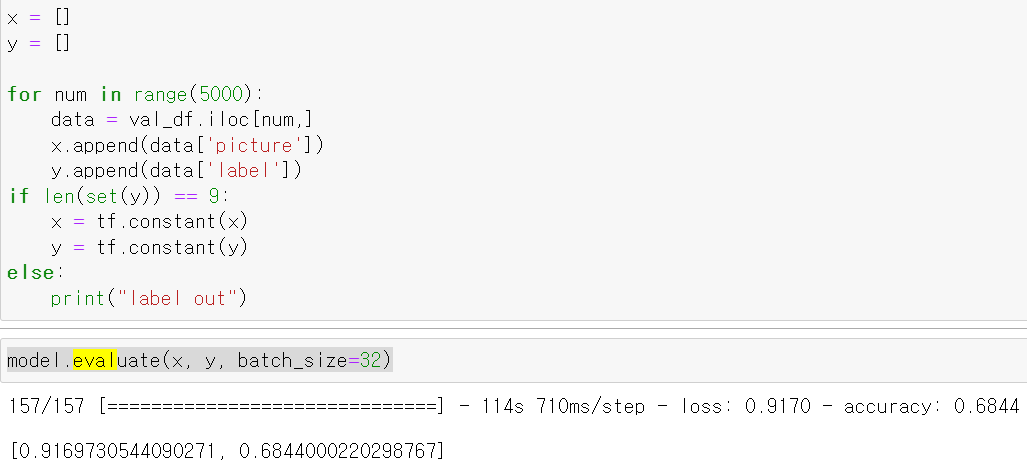
- 5만장까지 데이터를 학습 시킨 후 해당 모델을 통해 test데이터의 5000장을 tensor로 변환 후 모델의 성능을 테스트한 결과 68%의 정확도가 나왔다.
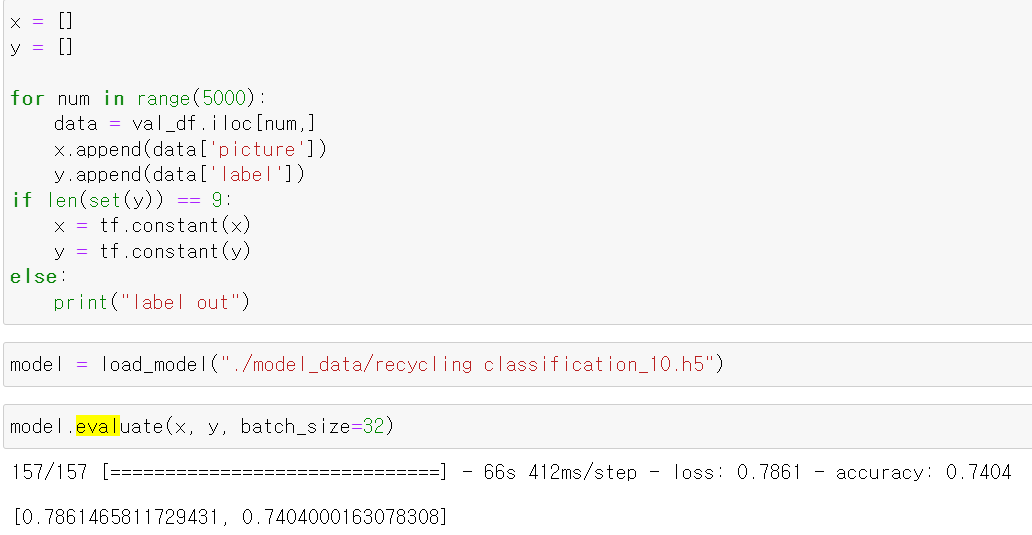
- 이후 10만장의 사진을 학습시킨 후 똑같은 test데이터를 바탕으로 모델의 성능을 테스트해보니 이전보다 6%가 올랐다.
- 10만장까지는 학습을 통해 성능이 개선되는 것이 확인된다.
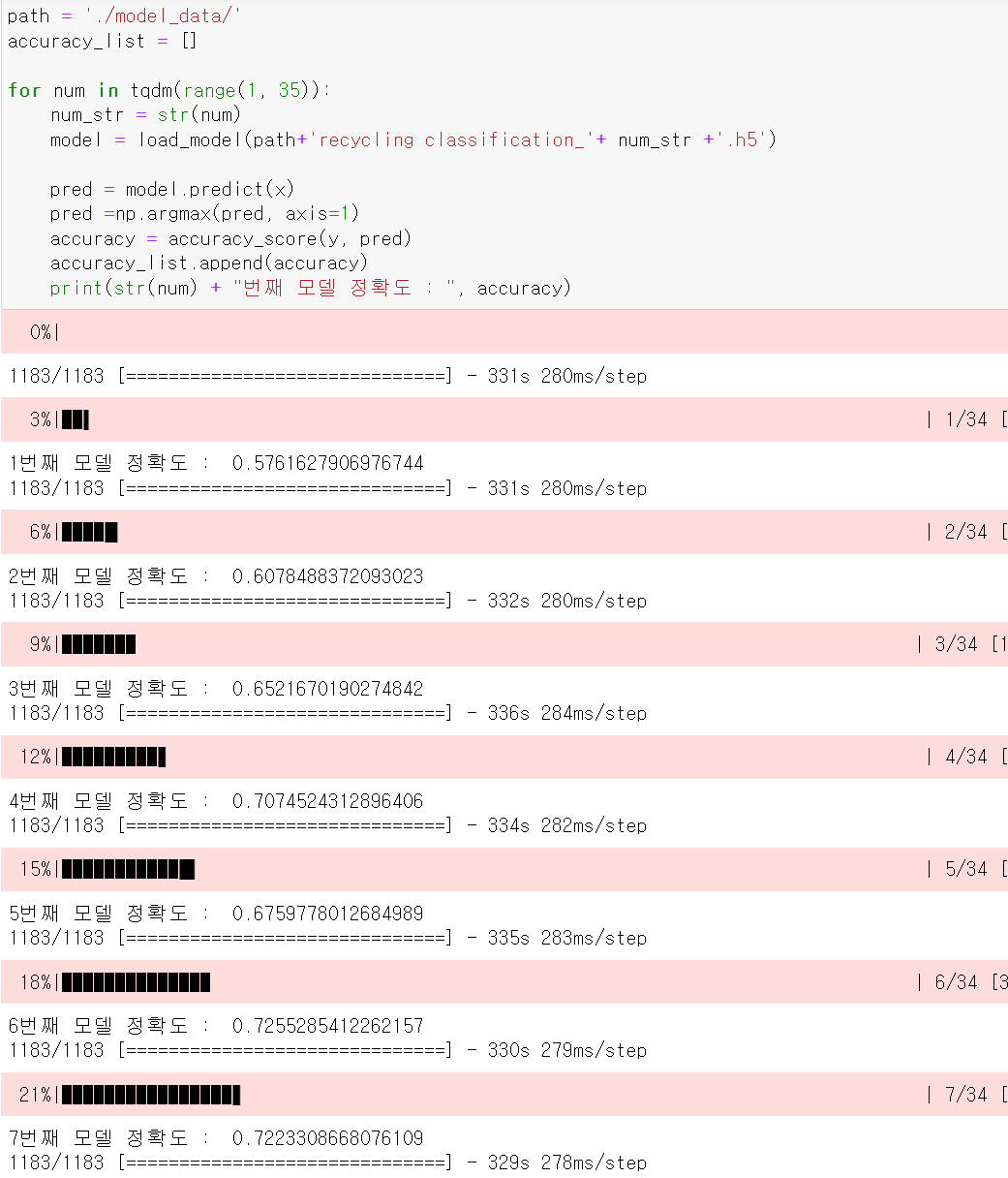
- 10,000장씩 전이학습한 모델 34개를 for문을 통해 37,000장의 test데이터에 정확도를 측정했다.
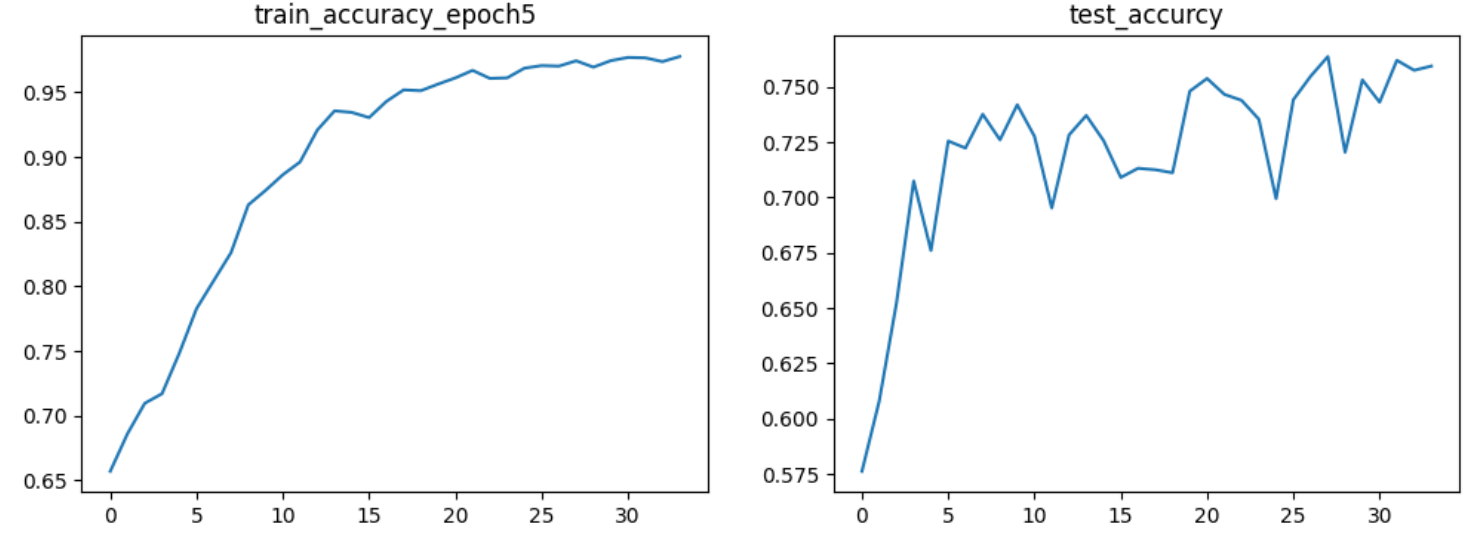
- 34만장의 train데이터를 학습시킬 때는 epoch5기준 accuracy가 상승곡선을 보였으나,
- test데이터에 accuracy를 측정한 결과 accuracy가 초반 단계에서는 상승했으나, 뒤로 갈수록 상승곡선을 보이지 않고 수치가 위아래로 튀었다.

- 학습시킨 모델 중 가장 성능이 좋은 모델인 28만장을 학습시킨 모델을 토대로 test데이터에 성능을 테스트한 결과 accuracy 76%가 나왔다.
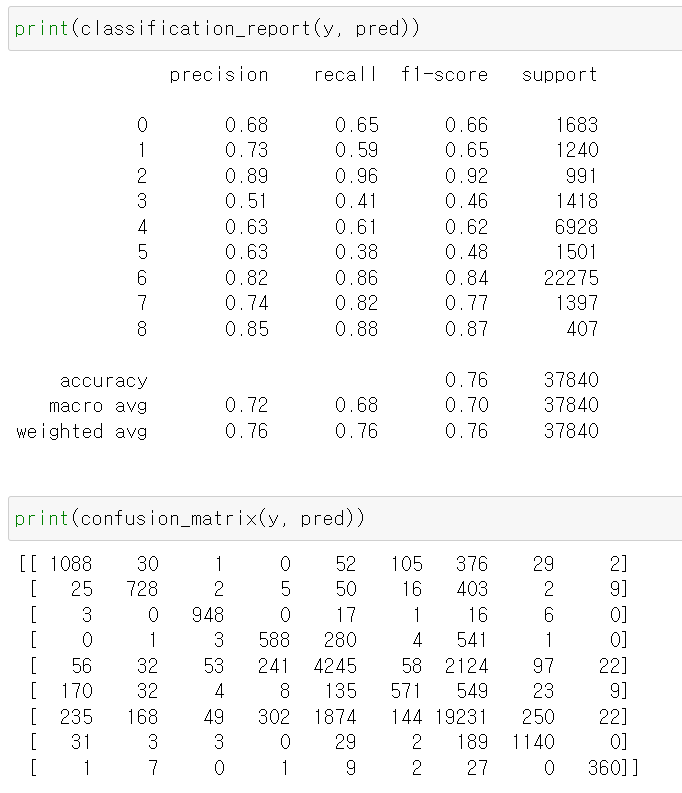
- 결과에 대한 분석을 한 결과 3번 label 즉 pet에 대한 f1-score가 낮다.
- 여기서 주목해야하는 부분으로 5번 즉 비닐 재활용의 경우 recall값이 현저히 낮으며 precision이 상대적으로 높으나 다른 재활용품을 다 비닐로 예측해 실제 비닐을 비닐로 예측한 recall값이 많이 낮다.
- 밑에 매트릭스표를 본 결과 비늘을 종이, 플라스틱, 일반쓰레기 등 다른 다양한 재활용품으로 잘못 예측했다.
- 그리고 다음으로 주목할만한 부분은 일반쓰레기에 대한 오답예측이다. 이물질이 묻을 경우 일반쓰레기로 분류하는데, 이물질이 묻은 여부를 정확히 예측하지 못하고 있다.
- 10,000장씩 전이학습을 통해 여러 모델을 구축했기 때문에 더 좋은 성능 개선을 생각한 결과 기존의 앙상블은 다른 모델을 보팅, 배깅, 부스팅 등의 방법으로 사용하지만, 전이학습을 통해 10,000장씩 나눈 모델 다수로 앙상블을 돌리면 어떨까? 생각했다.
- 모델 중 높은 성능을 보인 4개의 모델 28, 32, 33, 34 모델을 각각 예측값을 뽑고, 해당 예측값의 평균을 통해 하나의 예측을 했다.

- 기존에 문제가 있었던 비닐의 recall값이 0.1이 높아졌으며, 일반쓰레기에 대한 잘못 예측한 데이터의 수가 131개 줄었다.
- 또한, 성능이 4% 정도 오르며 반올림 기준 80%의 정확도를 보인다.

상황을 바꿀 수 없다면, 나를 바꾸자