- 데이터 분석 관련 첫번 째 프로젝트를 진행했다.
- 처음에는 솔직히...Kaggle데이터 줘서 아쉬움이 컸지만(다른 수강생 역시 아쉬움을 표현했다.), 막상 해보니 정말 치열하고 이 데이터로 이런 인사이트를 발견할 수 있구나? 싶었다
- 나는 넌 내게 빠조의 조장으로서 역할을 수행했다.
- 우리조는 연령을 중심으로 특성을 분석하고 AI모델을 구축했다.
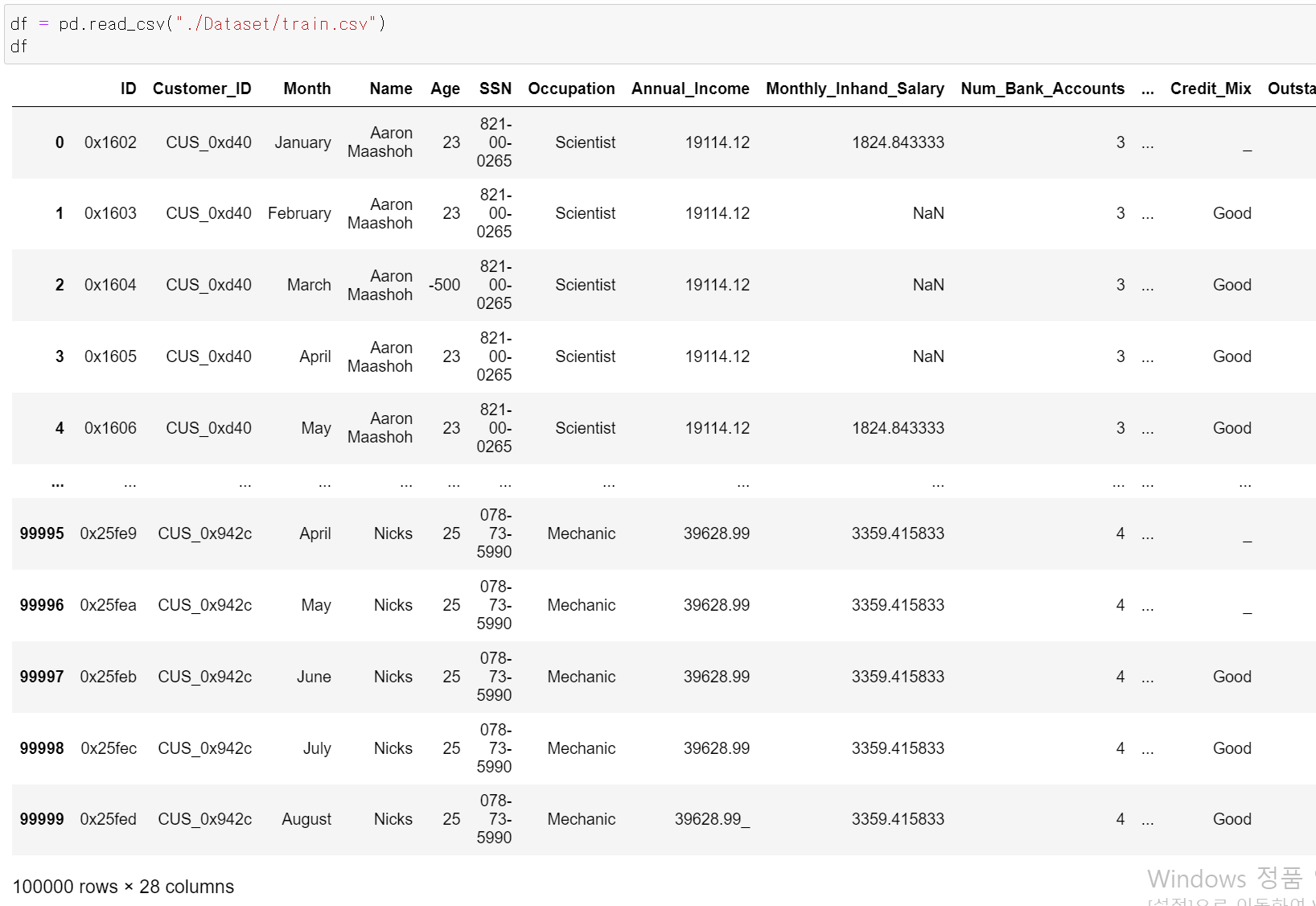
- 먼저 데이터는 28개의 칼럼과 10만개의 데이터세트를 통해 분석을 진행했다.
- 해당 데이터의 가장 큰 특징은 한 명의 고객에 대한 8달의 데이터가 쌓여있다는 것이다.

- 칼럼의 가독성을 높이기 위해 먼저 영어 칼럼을 한국어로 바꿨다.
데이터 전처리
- 데이터 전처리 작업에 많은 시간을 투자했다.
- 금액과 관련된 데이터가 많기에 모델의 성능을 향상을 중점으로 전처리 작업을 시작했다.
- 데이터 전처리의 경우 각 칼럼을 팀원과 나누고 각자 한 작업을 내가 모아서 데이터세트에 적용 후 csv파일로 공유했다.

- 먼저 '월'이 영어로 되어 있어 숫자로 데이터를 전처리했다.

- 이후 나이 데이터에서 문자형을 삭제하고, int형으로 바꾸며 57세 이상의 경우 value_counts확인 결과 1~3개 즉, 8개의 이하 데이터로서(한 명의 고객이 8개 데이터가 있기에 최소 8개가 있어야한다.) 이상치로 판단하고 -1로 변환 후 고객 ID별(8개의 데이터에 대한 Key값) 최빈값으로 변환했다.

- 다음은 연체 지불횟수 데이터의 전처리이다.
- 먼저 문자열을 삭제하고, 빈값은 -1로 채운 후 int형으로 데이터를 바꿨다.
- 또한 전체 데이터의 1~3%에 해당하는 25이상의 연체 지불횟수는 -1로 변환 후 고객 ID별 최빈값으로 변환했다.
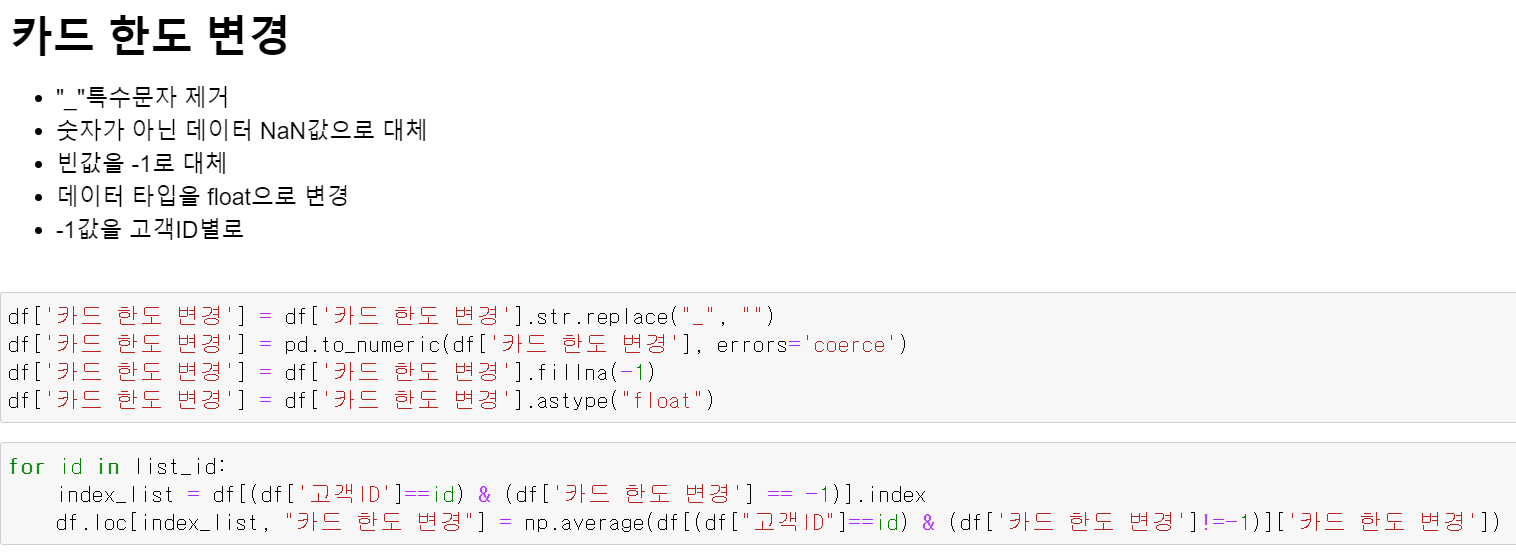
- 카드 한도 변경의 경우 특수 문자를 제거하고, 숫자가 아닌 경우 Nan값으로 대체하고 빈값은 -1로 다시 바꿨다. 이후 float타입으로 변환 후 고객 ID별 최빈값으로 변환했다.
- 소수 데이터로서 월마다 데이터의 값이 다르기 때문에 최빈값이 아닌 평균값으로 변환했다.

- 월별 투자금액의 경우 문자형을 삭제하고, 전체 데이터의 1~3%에 해당하는 데이터를 이상치로 판단 후 고객 ID별 중앙값으로 대체했다.
- 다른 데이터 또한 비슷한 방법으로 전체 데이터의 1~3%에 해당하며 이상치로 판단 후 고객 ID별 중앙값, 최빈값, 평균값으로 전처리를 작업했다.

- 대출 종류의 경우 string형태로 총 10개의 고유값이 있는 칼럼인데, 예를 들어 자동차 할부, 자동차 할부, 주택 담보 대출 3개의 대출 종류가 있으면 각 칼럼을 만들어 카운터를 세는 원핫인코딩 방식으로 전처리 작업을 했다.
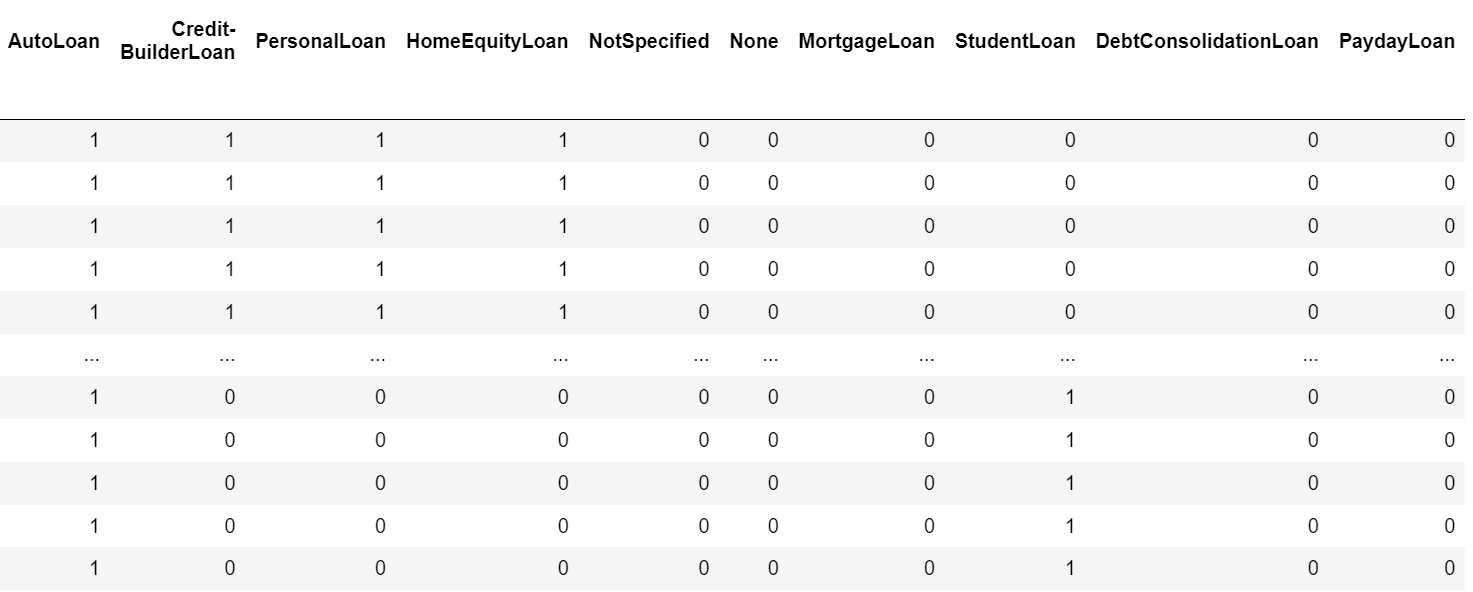
- 위 이미지를 참고하면 이해하기에 쉬울 것 같다.
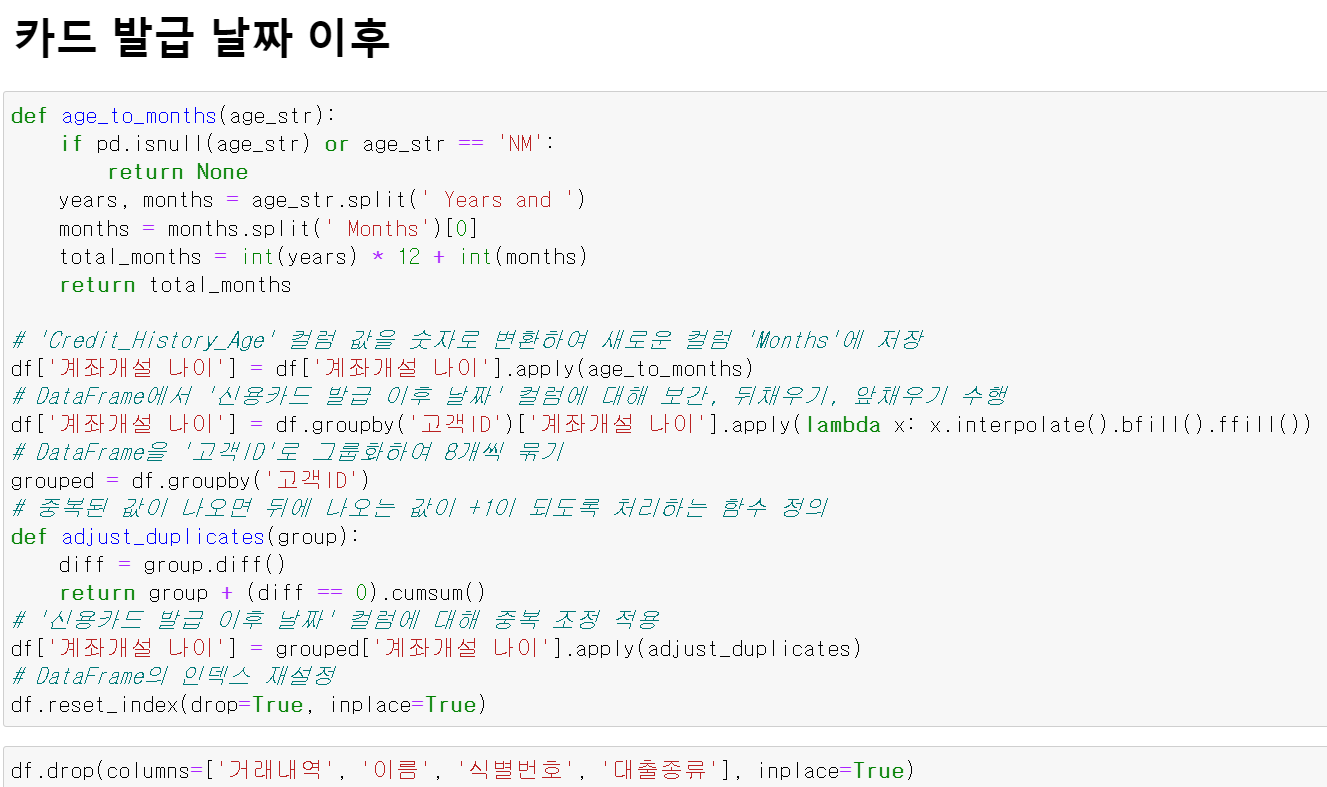
- 카드 발급 날짜 이후의 경우 시계열 데이터 성격으로 중간에 NaN값이 있는 경우 이전 혹은 이후 데이터에 -1 or +1하는 방식으로 데이터를 전처리했다.
모델 평가 및 EDA
st = StandardScaler()
knn_model = joblib.load("./model/knn_best_model.h5")
df_model = pd.read_csv("./Dataset/train_preprocessing.csv")
df_model.drop(columns="Unnamed: 0", inplace=True)
x = df_model.drop(columns=["신용점수"])
y = df_model['신용점수']
x_train, x_valid, y_train, y_valid = train_test_split(x, y, test_size=0.2, random_state=13)
x_valid_drop = x_valid.drop(columns="고객ID")
x_valid_drop.shape
le = LabelEncoder()
y_valid_le = le.fit_transform(y_valid)
x_valid_drop_scale = st.fit_transform(x_valid_drop)
y_pred = knn_model.predict(x_valid_drop_scale)
print(accuracy_score(y_valid, y_pred))
print(confusion_matrix(y_valid, y_pred))
print(classification_report(y_valid, y_pred))- autoML를 통한 성능 확인 결과 knn모델이 가장 높은 성능을 보였기에 optuna를 통해 구축한 model성능을 평가했다.
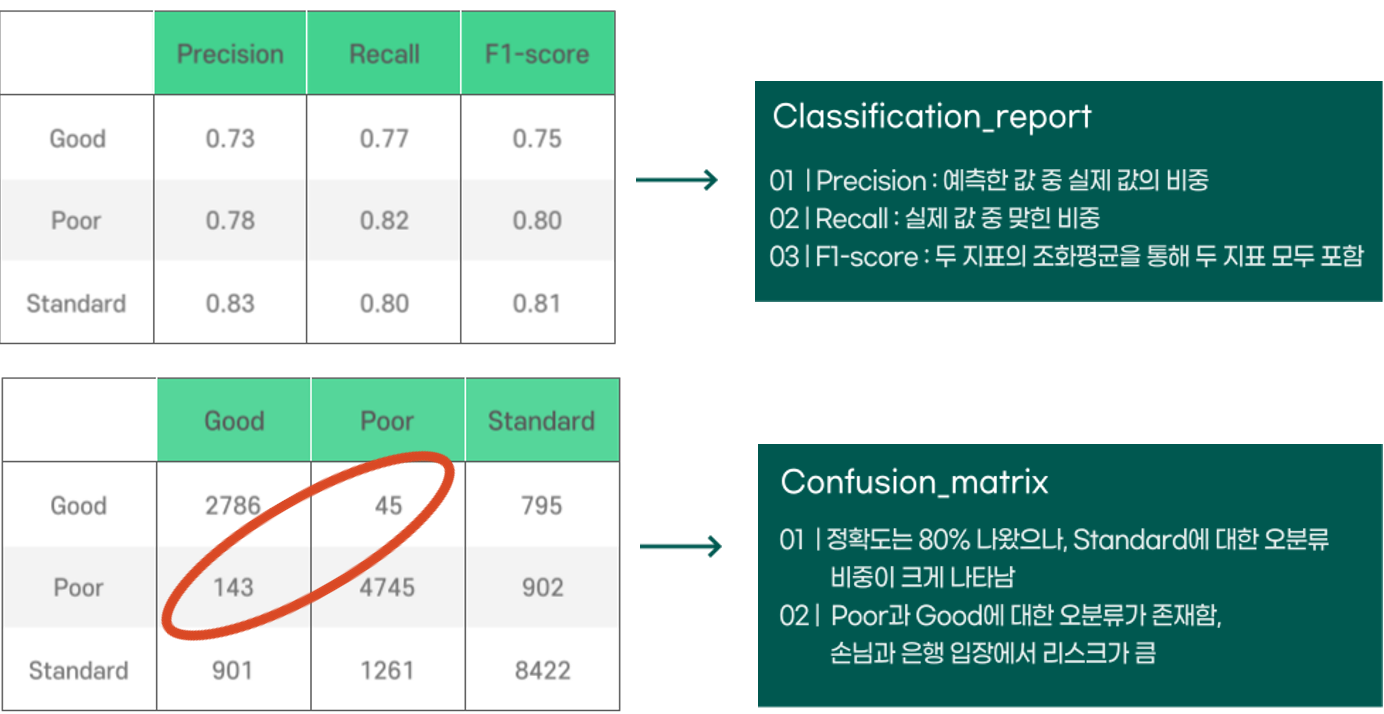
- 결과에 EDA를 진행한 결과 Good과 Poor에 대한 오분류가 적지 않다.
- 고객의 입장에서 Good의 신용등급인데 Poor이라고 오분류 받으면 은행에 대한 신뢰를 잃고
- 은행의 입장에서 Poor인 고객을 Good으로 오분류한다면 리스크에 대한 부담이 커지게 된다.
- 그렇기 때문에 우리팀은 Good과 Poor에 대한 오분류를 낮추는 것을 목표로 EDA진행했다.
- 중점적으로 데이터의 복잡도를 낮추기 위한 파생변수 생성 및 파생변수의 신뢰성 및 통계적 유의성 검증을 작업했다.
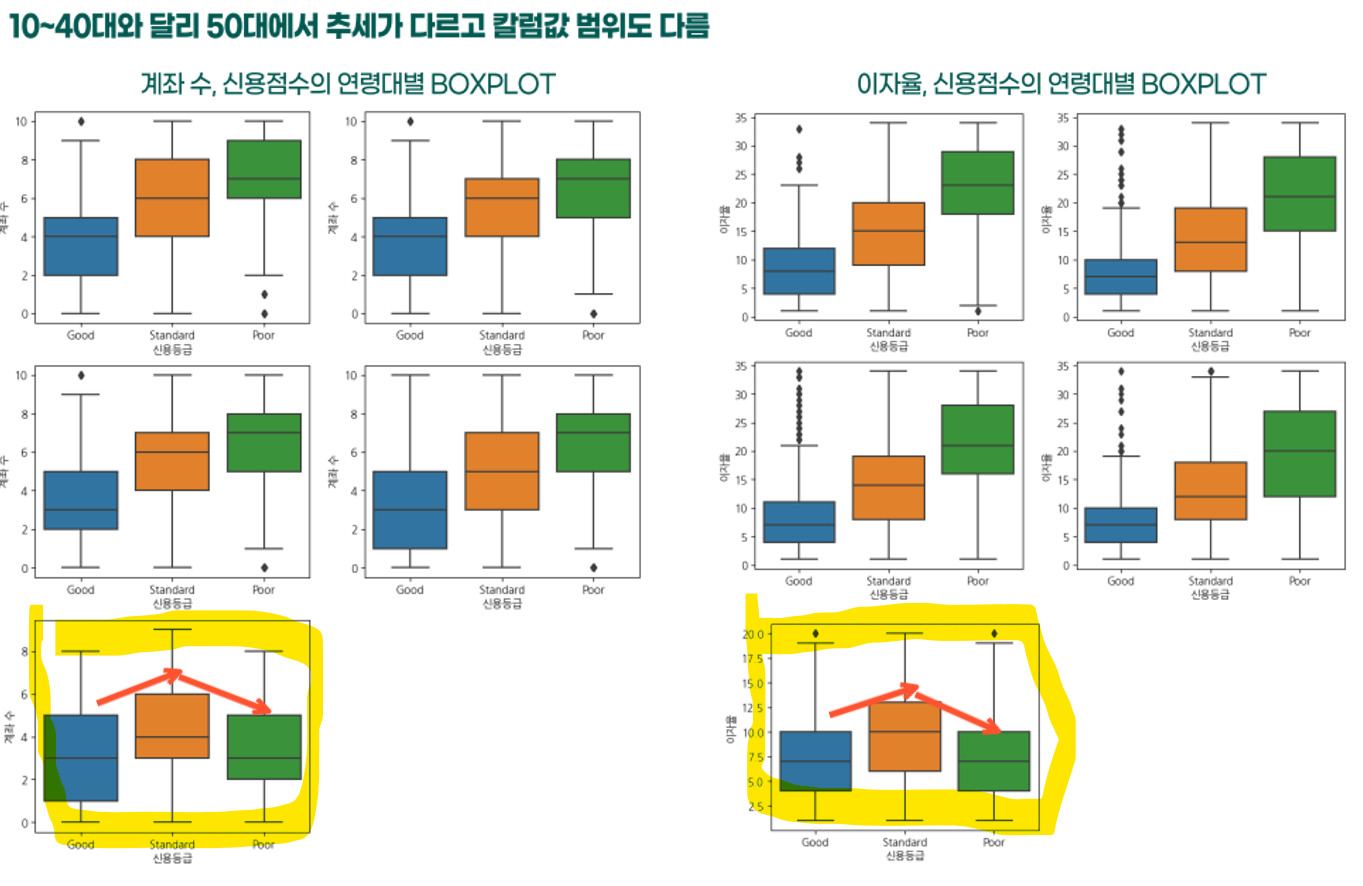
- 먼저 연령대에 따른 칼럼의 추세를 분석했다.
- 여기서 50대에서만 다른 추세를 보인다는 것을 발견했다.
- 이 인사이트를 발굴하기 위해...힘들었다 정말...
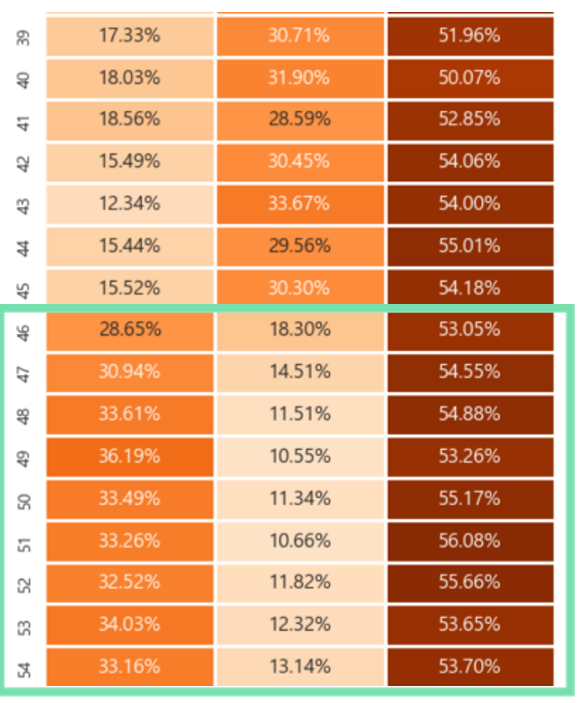
- 이제 나이에 대한 구체적인 heatmap을 그려본 결과 46세를 기준으로 Label값인 신용등급의 분포가 달라지는 것을 확인할 수 있다.
- 그래서 우리팀은 46세를 기준으로 다른 모델을 구축 후 학습 및 테스트한다면 어떨까?라는 생각을 했다.
- 단순히 모델만 따로 구축하는 것이 아니라 파생변수 생성을 통해서 변수를 줄이고 모델의 복잡도를 낮추고자 노력했다.
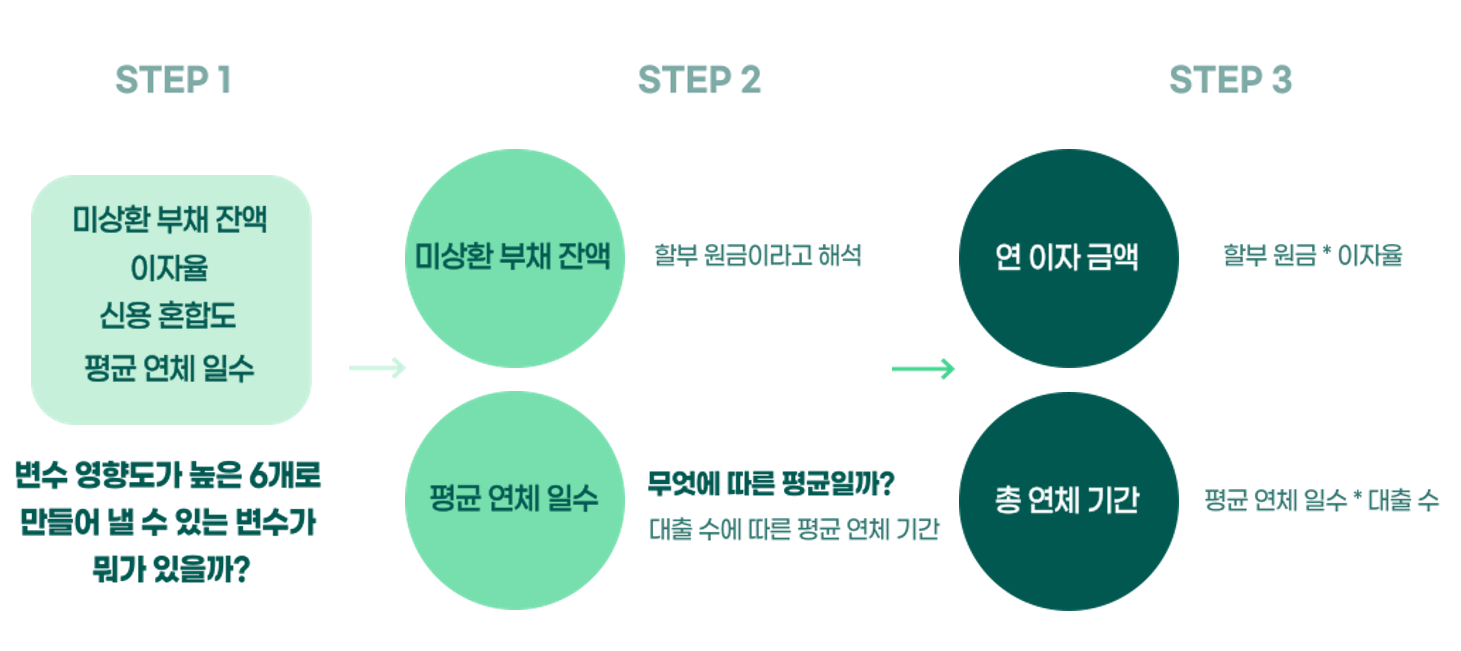
- 먼저 연이자금액 및 총 연체기간이라는 파생변수를 만들었다.
- 기존의 모델에서 feature_importance를 확인한 결과 영향력이 높은 6개의 변수에 대해서 여러 조합을 생각한 결과 두 파생변수를 만들었다.
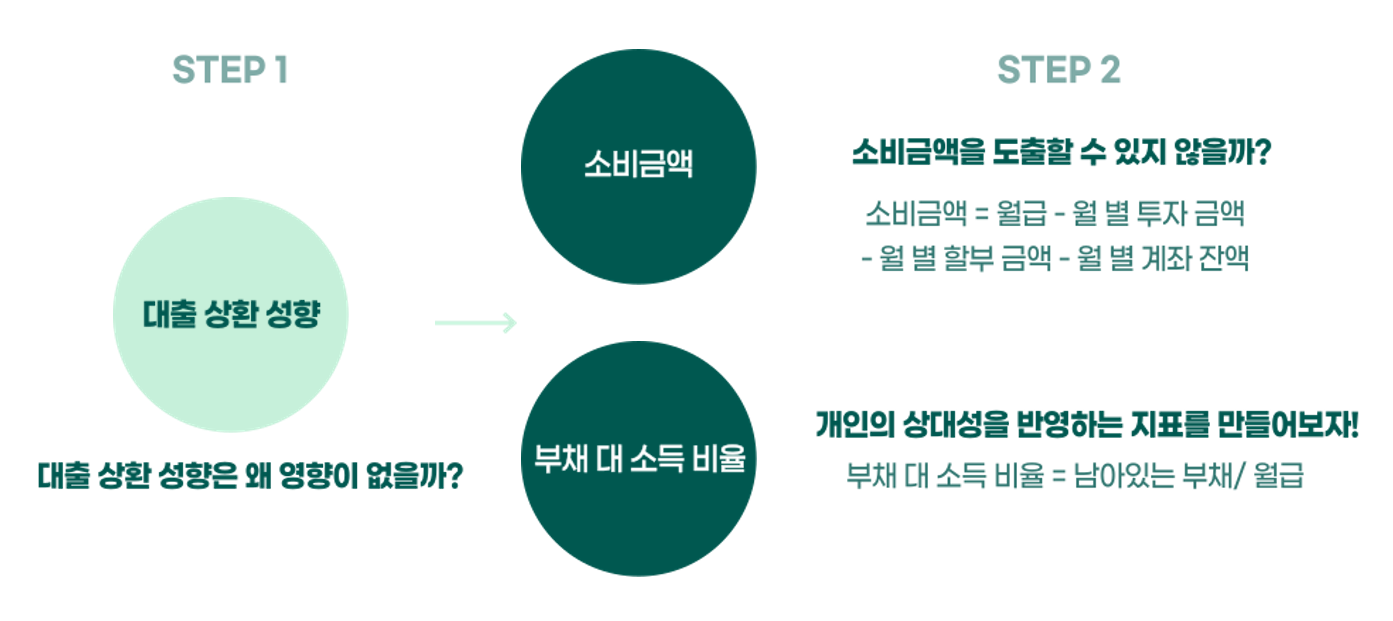
- 그리고 개인의 상대적인 지표인 대출 상환 의지에 대한 데이터를 만들고자 노력했다.
- 소비금액과 부채 대 소득 비율이라는 두 칼럼을 만들었다.
- 부채 대 소득 비율은 내가 숨만 쉬고 월급을 부채 상환에 사용할 때 몇달이 걸릴지에 대한 지표이다.
- 소비금액은 크면서 부채 대 소득 비율은 높다면, 상대적으로 부채 상환에 대한 의지가 적으며, 반대의 경우 높다고 볼 수 있다.
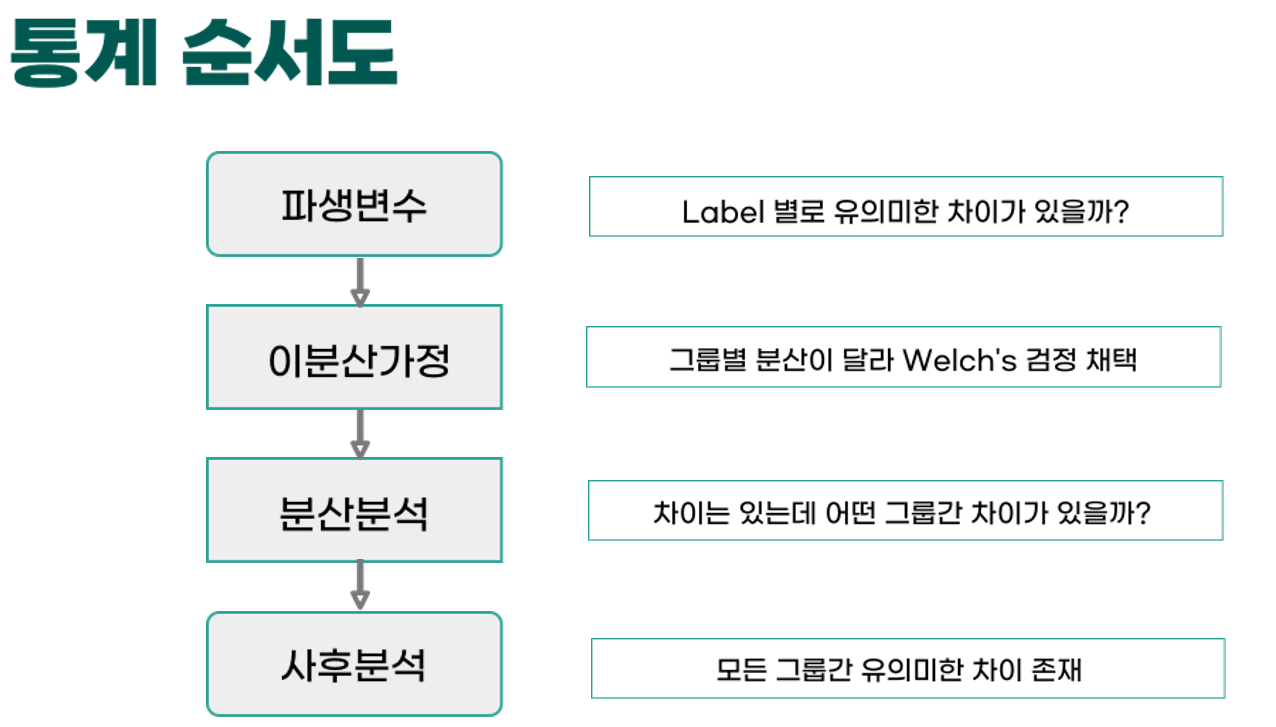
- 그리고 만든 파생변수를 각 Label범주별로 통계적의 ANOVA분석 결과 유의미한 차이, 즉 P-Value가 0.05보다 낮다는 결과를 확인했다.
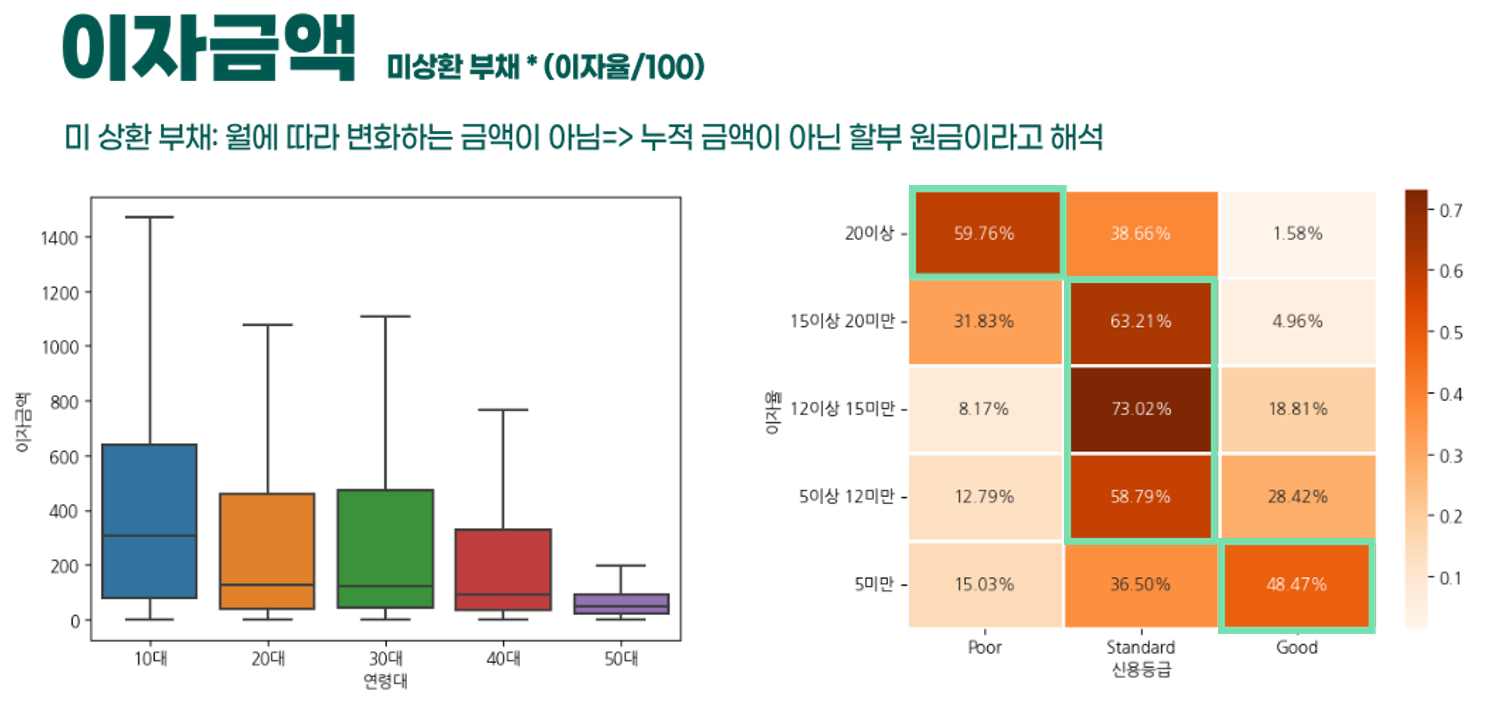
- 이후 만든 파생변수와 다른 칼럼과의 상관성을 분석함으로써 논리적으로 해당 칼럼의 신뢰성을 확인했다.
- 신용등급이 높은 연령일수록 이자금액이 낮으며, 이자율이 낮을수록 신용등급이 낮다는 것을 확인할 수 있다.
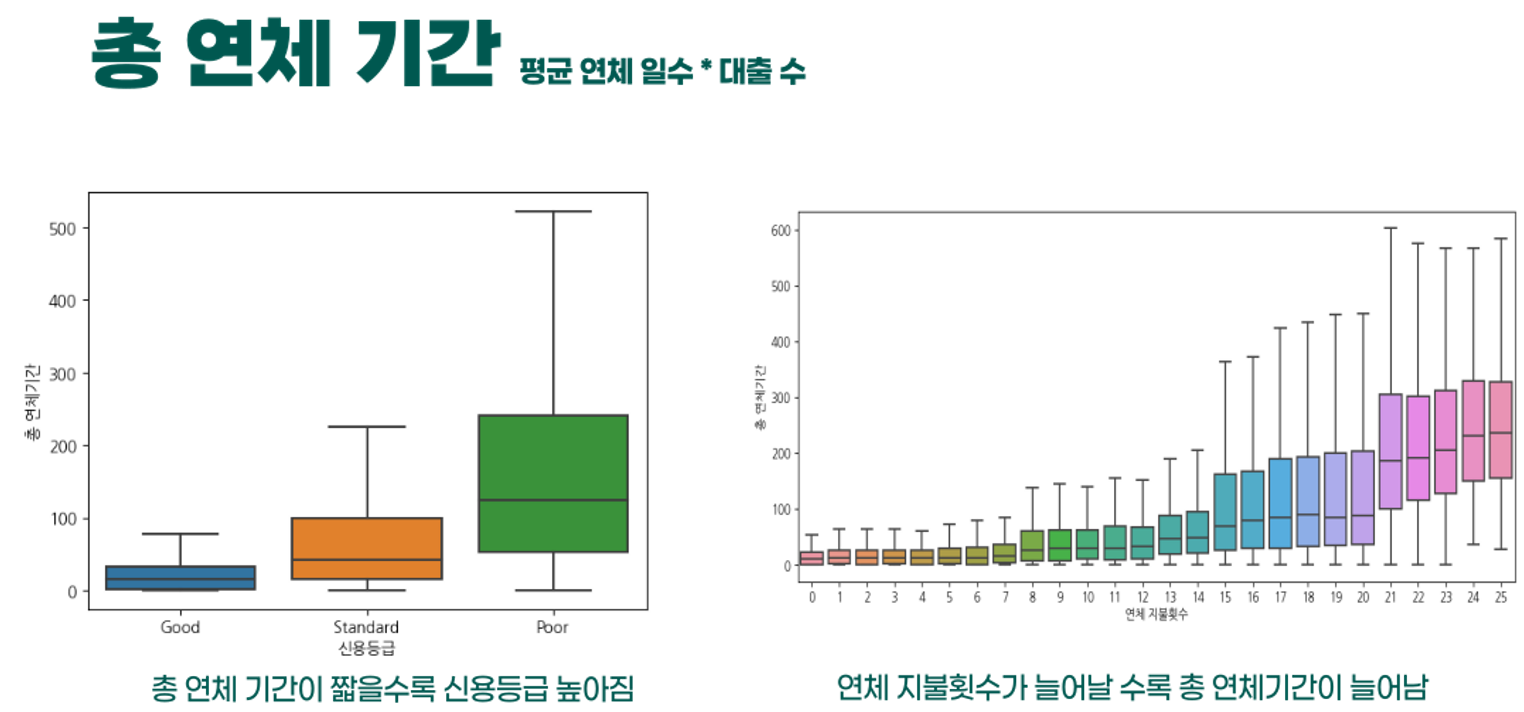
- 다음은 총 연체 기간이다. 신용등급이 좋을수록 총 연체 기간이 낮으며, 연체 지불횟수가 늘어날수록 연체기간이 늘어나는 것을 확인하며 해당 파생변수의 신뢰성을 검증했다.
- 파생변수를 만드는 데 사용하지 않은 변수와 상관성을 시각화 결과 논리적인 결과가 나온다면 신뢰성이 있다고 판단했다.
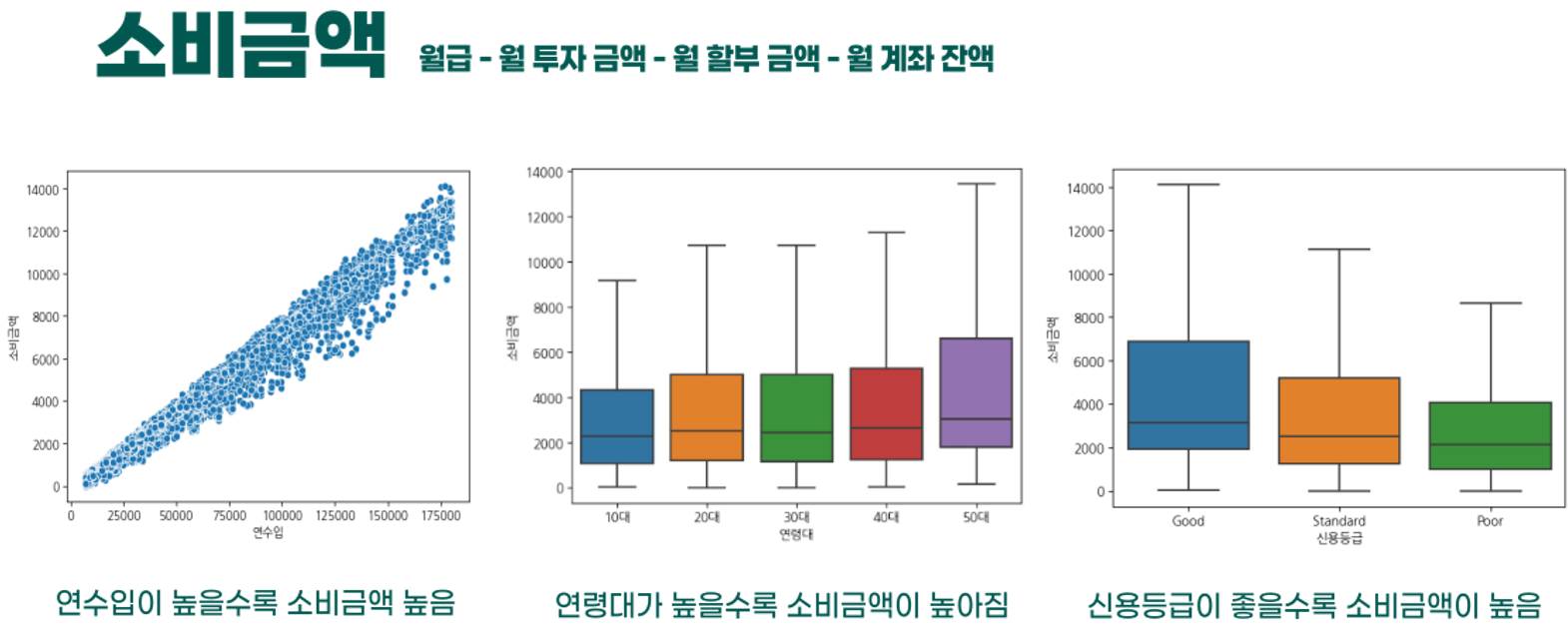
- 소비금액과 다른 칼럼과 상관성을 분석한 결과 연수입이 커질수록 소비금액 커지며, 신용등급이 낮을수록 소비금액이 낮다는 것을 확인할 수 있다.
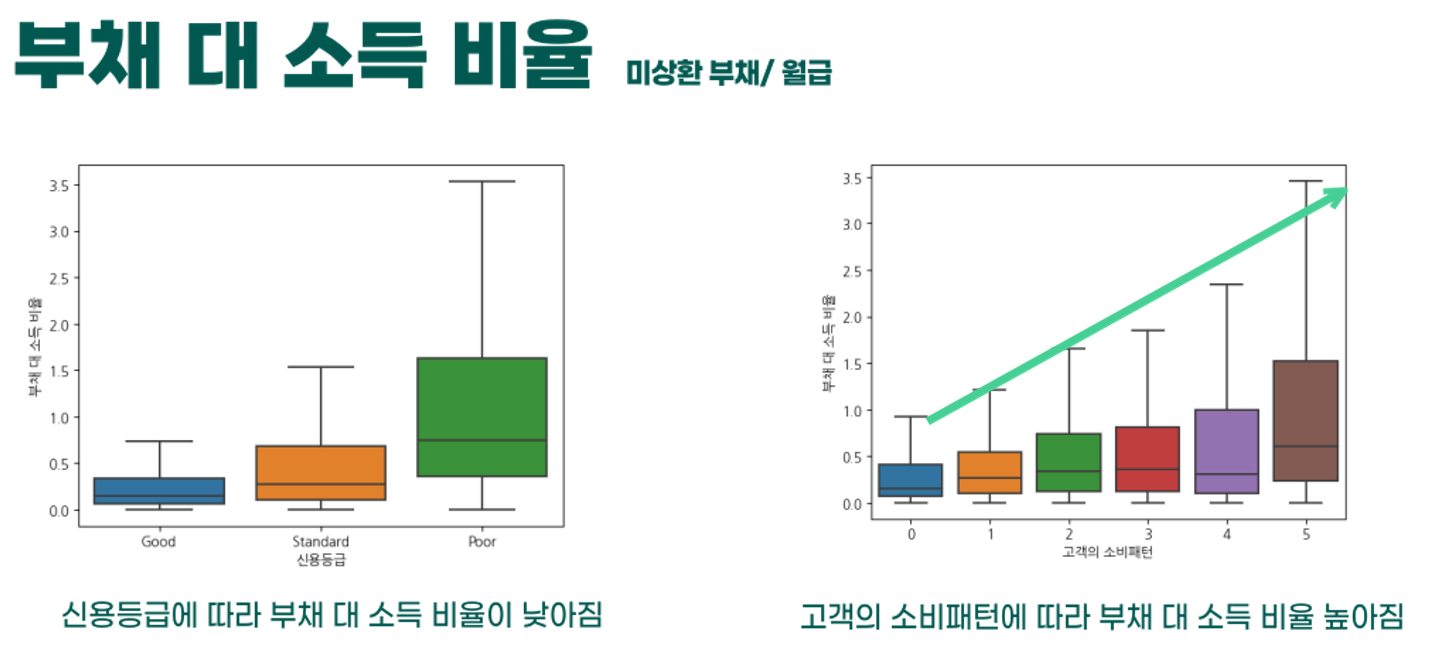
- 마지막으로 부채 대 소득 비율 역시 상관성을 보이는데
- 0~5는 0은 High_spent이며 5로 갈수록 Low_spent이다.
- 소비가 클수록 부채 대 소득이 낮을수록 높다는 것을 확인할 수 있다.
cat_model = joblib.load("./model_list/cat_best_model_for.h5")
rf_model = joblib.load("./model_list/rf_best_model_46re_under.h5")
lg_model = joblib.load("./model_list/lgbm_best_model_under46.h5")
df_model = pd.read_csv("./Dataset/df_for.csv")
x = df_model.drop(columns=["신용등급", '연령대'])
y = df_model['신용등급']
x_train, x_valid, y_train, y_valid = train_test_split(x, y, test_size=0.2, random_state=13)
x_valid_drop = x_valid.drop(columns="고객ID")
le = LabelEncoder()
y_valid_le = le.fit_transform(y_valid)
st = StandardScaler()
x_valid_drop_scale = st.fit_transform(x_valid_drop)
result_score = []
model_list = ["lg", " rf", "cat"]
models = [lg_model]
for model in models:
predictions = model.predict(x_valid_drop)
result = accuracy_score(y_valid_le, predictions)
result_score.append(result)
models = [rf_model]
for model in models:
predictions = model.predict(x_valid_drop)
result = accuracy_score(y_valid, predictions)
result_score.append(result)
predictions = cat_model.predict(x_valid)
result = accuracy_score(y_valid, predictions)
result_score.append(result)
for model_name, model_score in zip(model_list, result_score):
print(model_name, ":",model_score)
weights = [0.2, 0.4, 0.4]
model1_proba = lg_model.predict_proba(x_valid_drop) * weights[0]
model2_proba = rf_model.predict_proba(x_valid_drop) * weights[1]
model3_proba = cat_model.predict_proba(x_valid) * weights[2]
sum_probas = np.array(model1_proba) + np.array(model2_proba) + np.array(model3_proba)
avg_probas = sum_probas / 3
# 평균 확률이 가장 큰 라벨을 최종 예측으로 선택합니다.
final_predictions = np.argmax(avg_probas, axis=1)
print(accuracy_score(y_valid_le, final_predictions))
print(confusion_matrix(y_valid_le, final_predictions))
print(classification_report(y_valid_le, final_predictions))- 다음으로는 SoftVoting방식으로 내가 구축한 cat_boost와 다른 팀워의 모델을 사용했다.
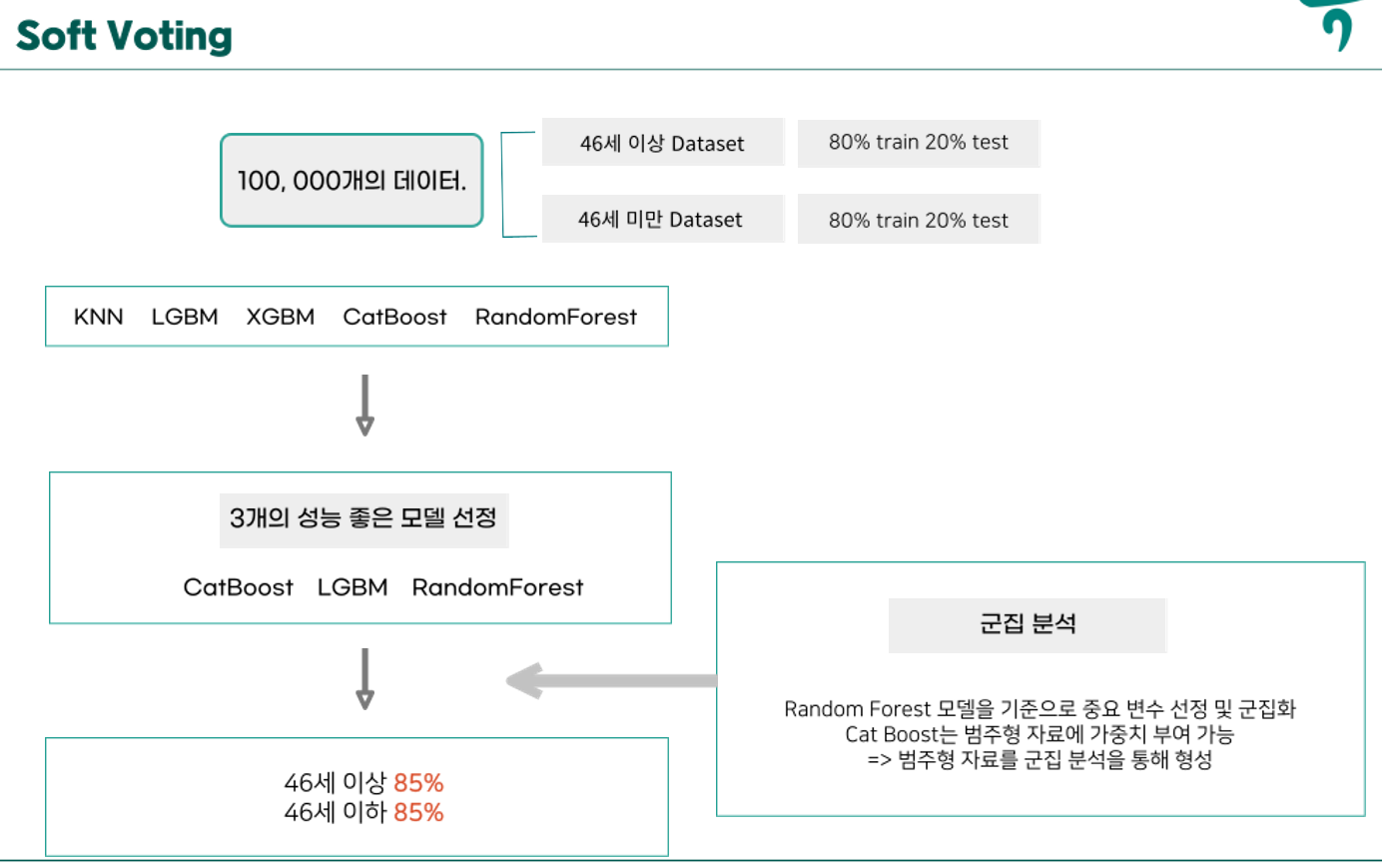
- 해당 그림을 통해 과정을 확인하면 될 것 같다.
- 중간에 군집분석 또한 사용했다.
- 정확히 말하면 군집분석이 아니라 군집 칼럼을 추가했다. CatBoost의 경우 범주형 자료에 가중치를 줄 수 있기 때문에 모델의 성능 개선을 위해 군집 칼럼을 추가했다.
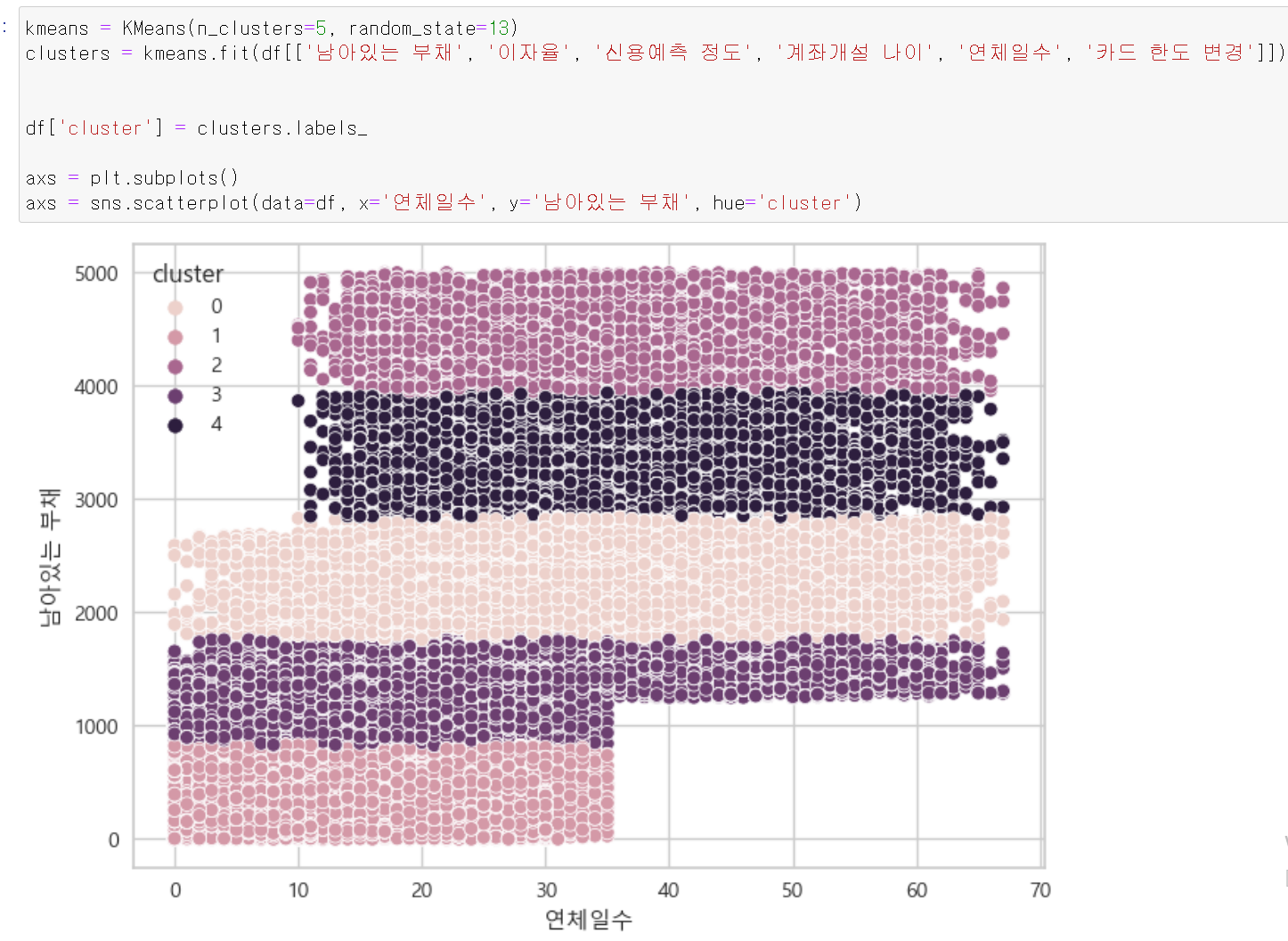
- 중요도가 높은 칼럼을 바탕으로 군집을 형성 후 군집칼럼을 추가했다.
Result
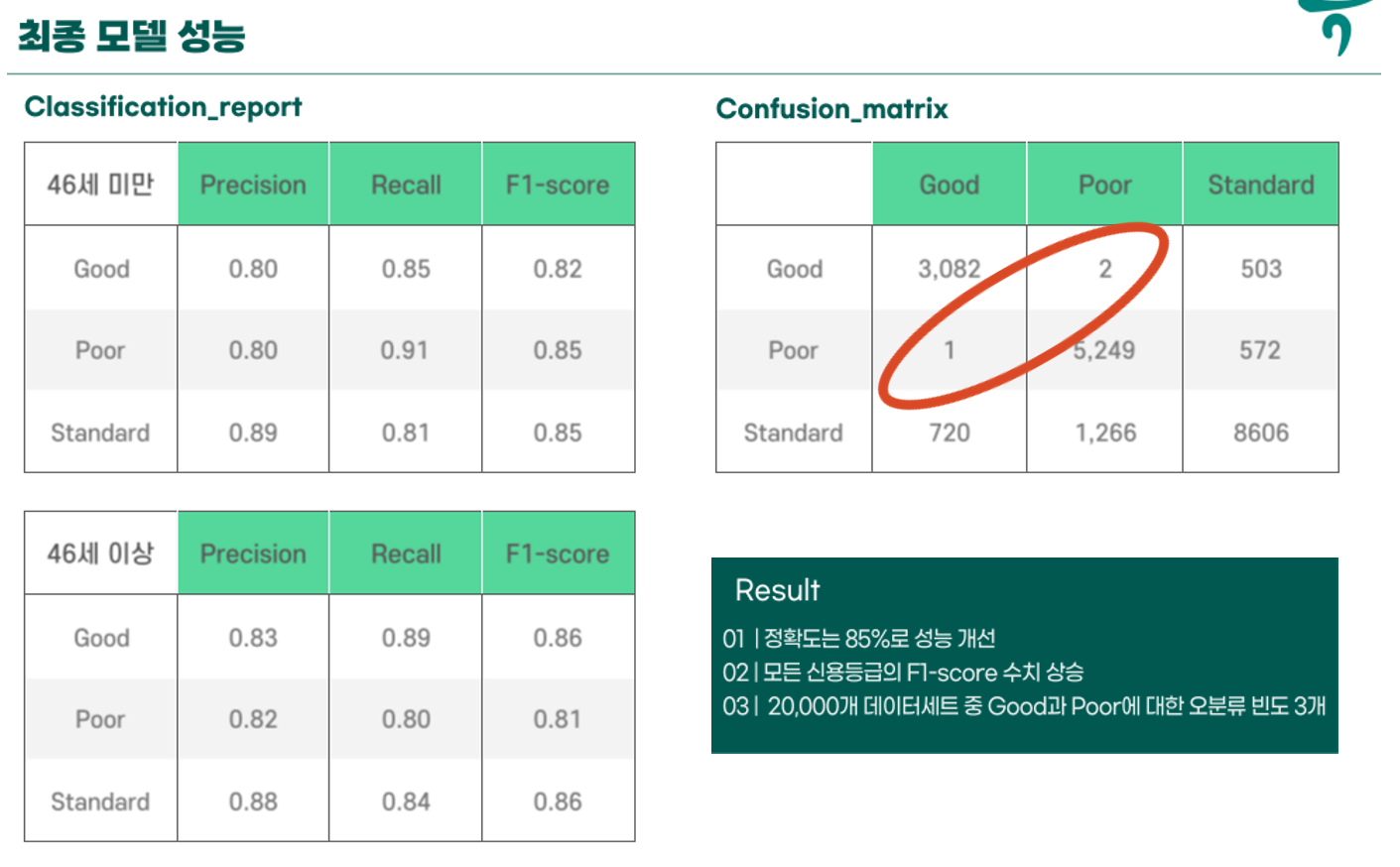
- Softvoting 후 결과 확인을 해보니 성능은 각 연령대별로 85%성능을 보이며 Confusion_matrix확인 결과 Good고 Poor에 대한 오분류가 3개로 확연히 낮다는 것을 확인할 수 있다.

- 위 3가지의 기대효과를 기대할 수 있다.
끝.

상황을 바꿀 수 없다면, 나를 바꾸자