
프로젝트 개요
- Hana路 Digital 교육을 듣는 과정에서 마음이 맞는 3명의 교육생과 함께 문화체육관광부 주최의 문화데이터분석 공모전에 참석했다.
- 우리의 공모전 프로젝트 목표는 서울시 스마트도서관의 이용률 현황파악 및 이용률 증가를 위한 데이터분석으로 잡았다.
- 먼저 서울시 공공도서관의 데이터를 수집 및 분석 후 KDC기준 책 종류, 인구, 토지 목적 등 다양한 도서, 인구통계 데이터를 분석하고 분석한 데이터를 기반으로 스마트도서관의 소장 도서에 적용해 역별 스마트도서관의 커스텀마이징을 목표로 했다.
데이터 수집 및 전처리

- 데이터는 공공데이터포털, 문화빅데이터플랫폼 및 국민정보공개청구 등 3가지 경로를 통해 스마트도서관, 국립도서관 및 인구통계데이터를 수집했다.
- 우리팀은 2022년를 기준으로 데이터를 수집했다.
- 먼저 서울시 도서관 데이터를 가져왔다.
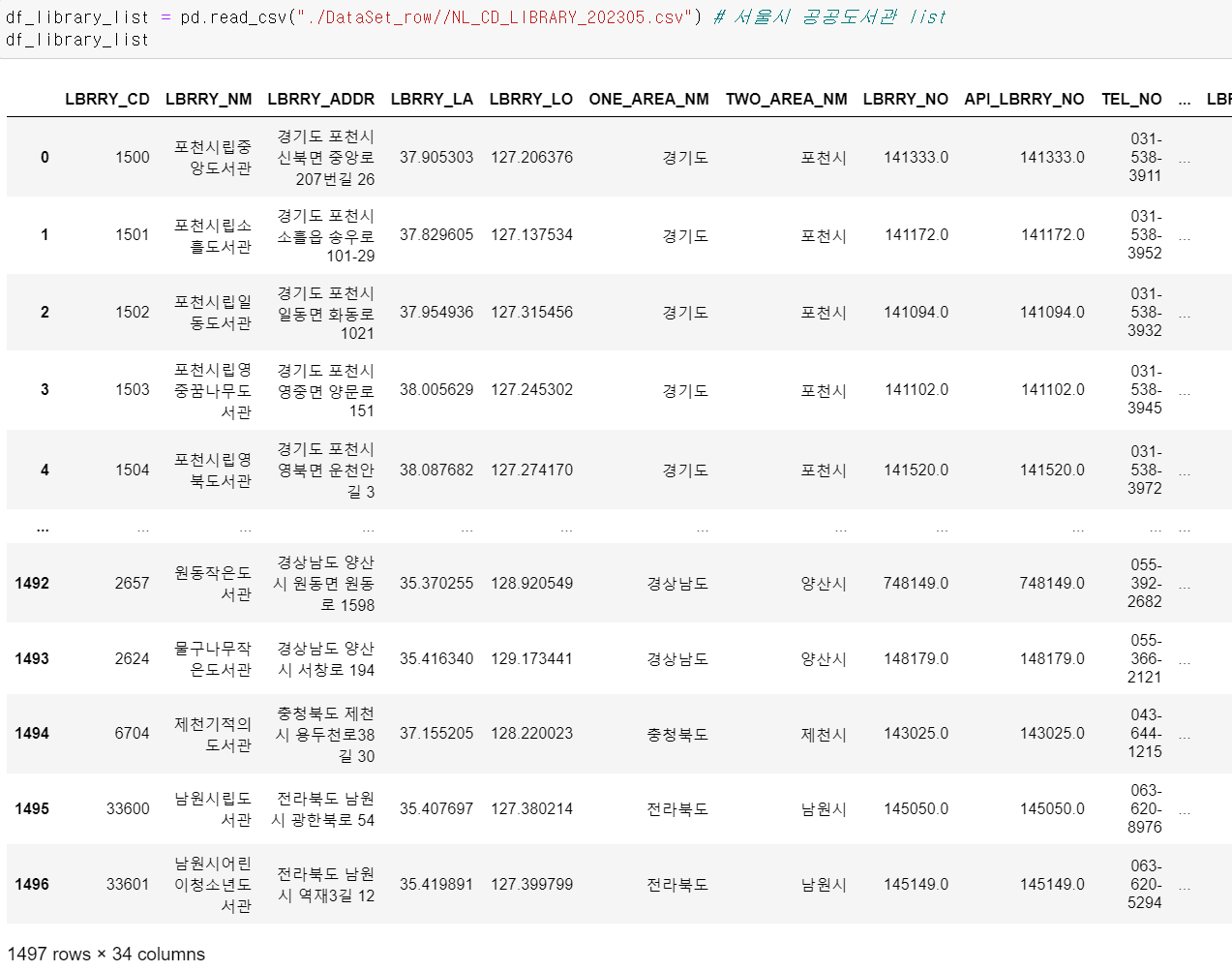
- csv데이터를 불러와 데이터프레임으로 만든 후
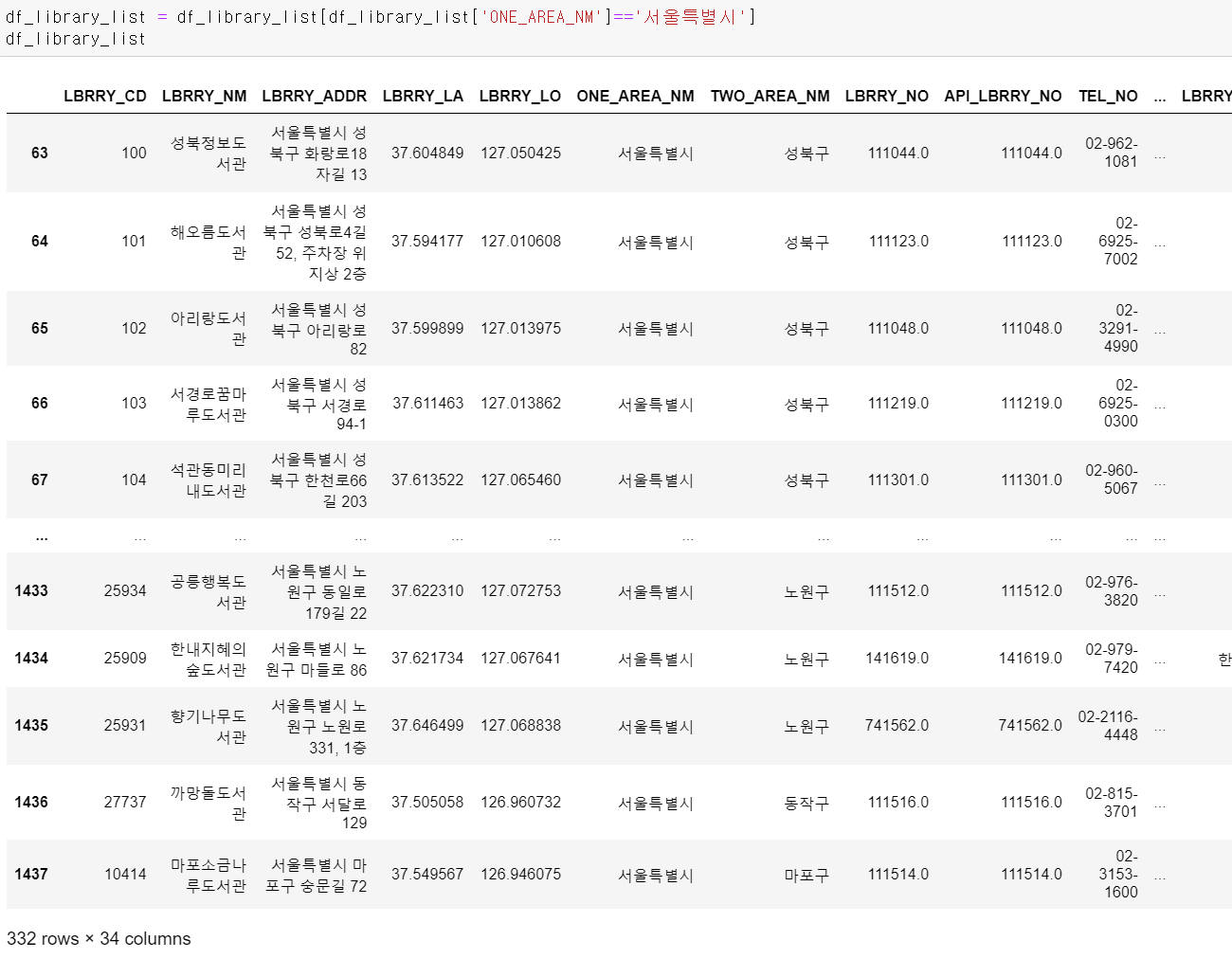
- 필요한 서울시 도서관만 조건을 걸어 뽑았다.
- 뽑은 데이터를 확인해보니 서울시의 국공립 도서관이 332개 존재한다.
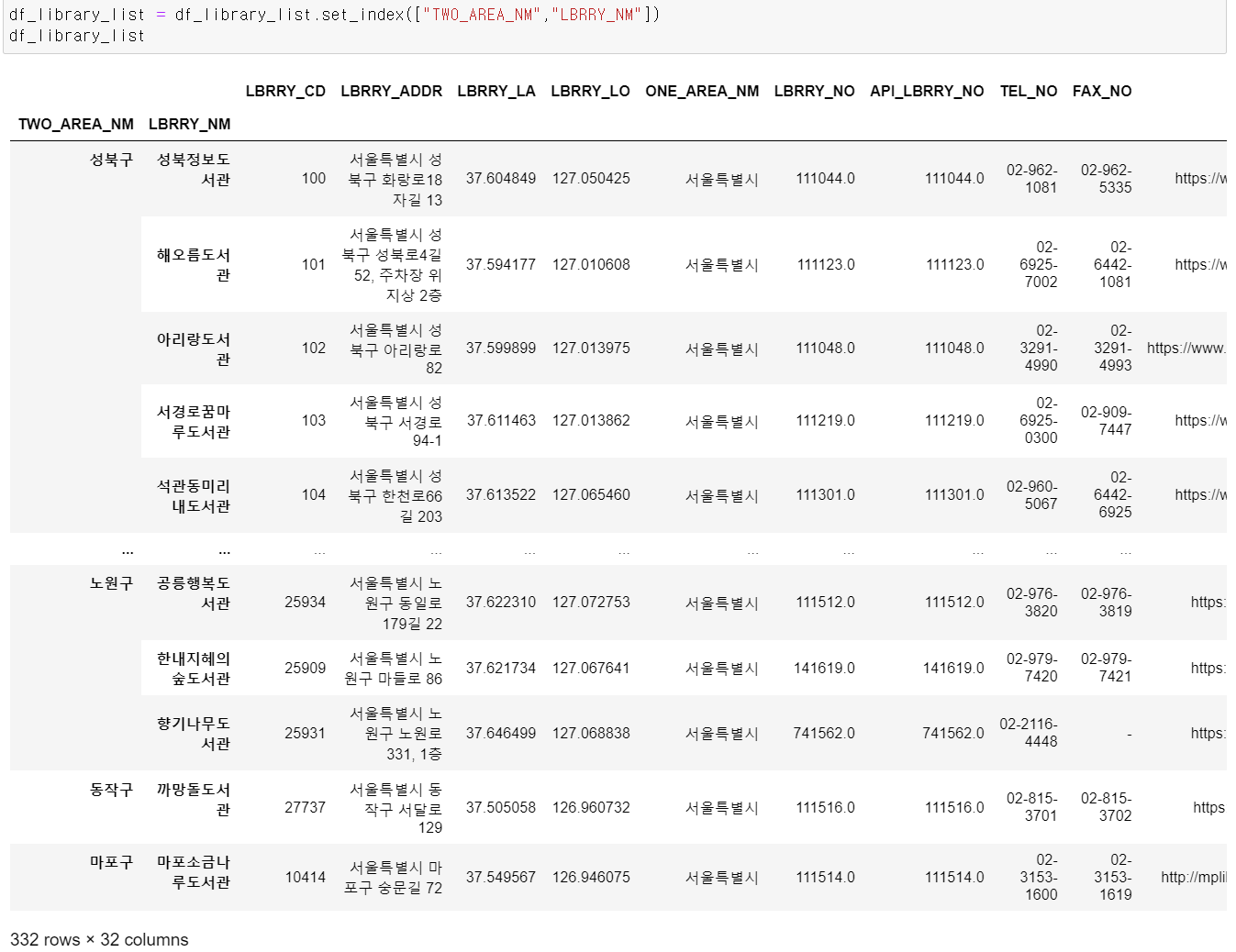
- 그리고 조건을 통해 뽑은 데이터에서 구와 도서관을 인덱스로 설정해 구별 도서관별로 데이터를 정리했다.
- 다음으로는 도서관 대출정보 데이터를 불러왔다.
- 월마다 데이터의 양이 많아 여러 csv파일로 쪼개져 있어서
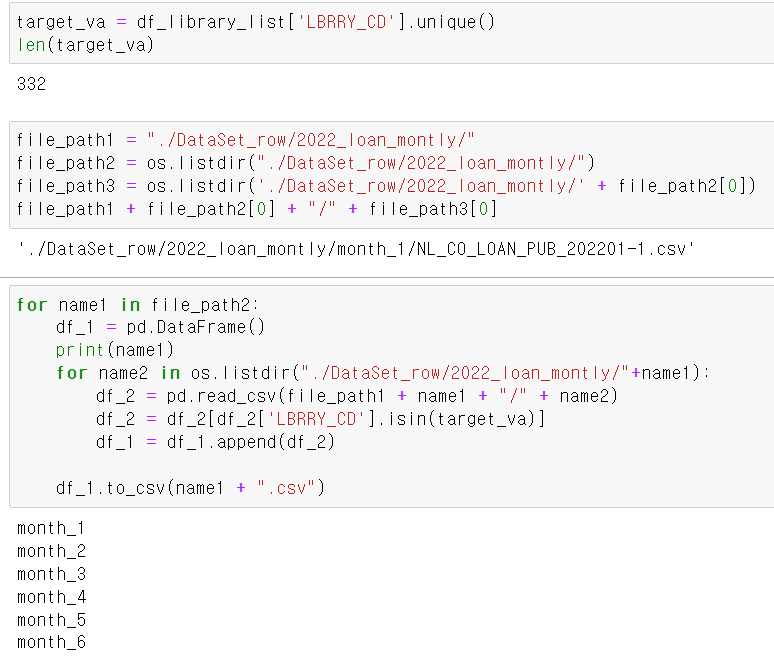
- 각 파일 안에 월별로 여러 데이터를 넣어두고, 위 코드와 같이 file경로를 여러 단계로 구분해 for문을 통해 월별 서울시 도서관 대출 정보 데이터를 정리하려고 시도했다.
- 먼저 도서관 정보(332)의 도서관 코드 고유값을 리스트로 리스트로 저장하고,
- for문을 통해 대출정보 데이터를 뽑을 때 서울시 도서관 코드에 해당하는 데이터만 뽑히도록 설정을 추가하고, 월별로 데이터를 csv파일로 정리했다.

- 파일 확인 결과 정상적으로 상반기 6개 데이터가 출력됐다. 하반기는 다른 팀원이 진행하고 나중에 합치기로 했다.

- 나중에 대출정보의 도서번호와 다른 데이터셋 중 도서 정보가 있기 때문에 join과 FK기능을 사용하기 위해 해당 데이터들을 mysql로 저장했다.
- sqlalchemy의 create_engine라이브러리를 사용하면 데이터프레임을 그대로 sql에 저장할 수 있다.
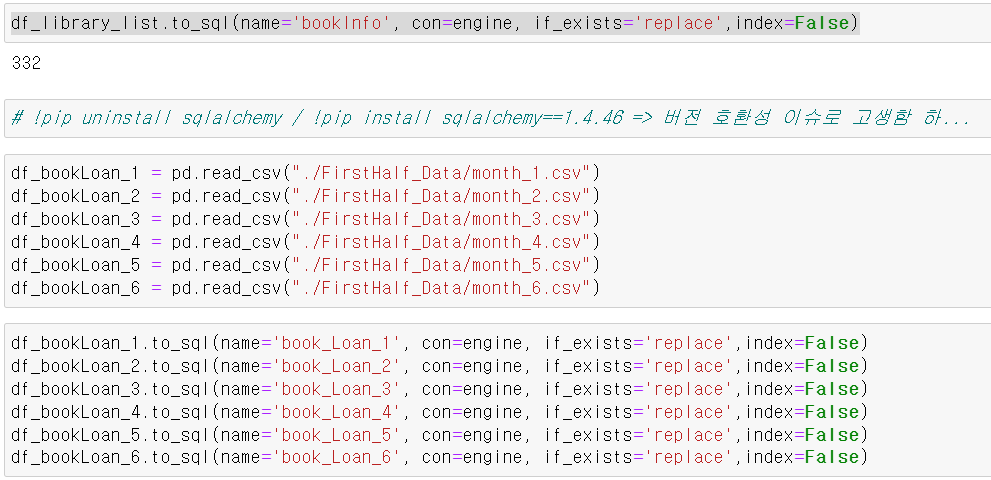
- 먼저 도서관 정보 데이터를 리셋인덱스 후 필요한 컬럼만 저장하고
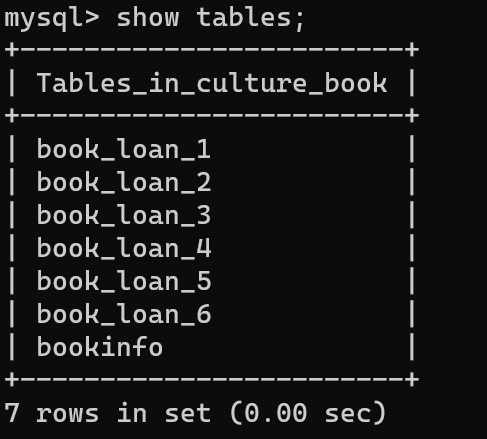
- sql에 던진 후 월별 6개의 월 서울시 대출정보 데이터를 sql에 저장했다.
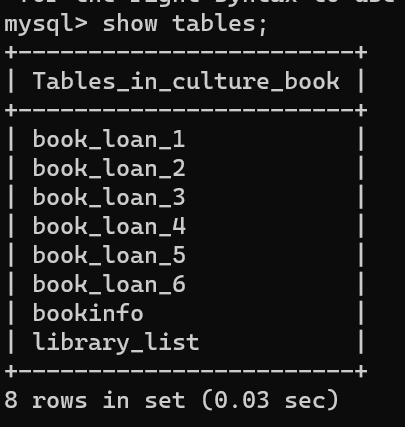
- 확인 결과 총 8개의 테이블이 만들어졌다
- 월별 대출 기록, 도서 정보, 도서관 목록 등 다른 팀원의 테이블과 2022년 최종 테이블만 만들면 된다.
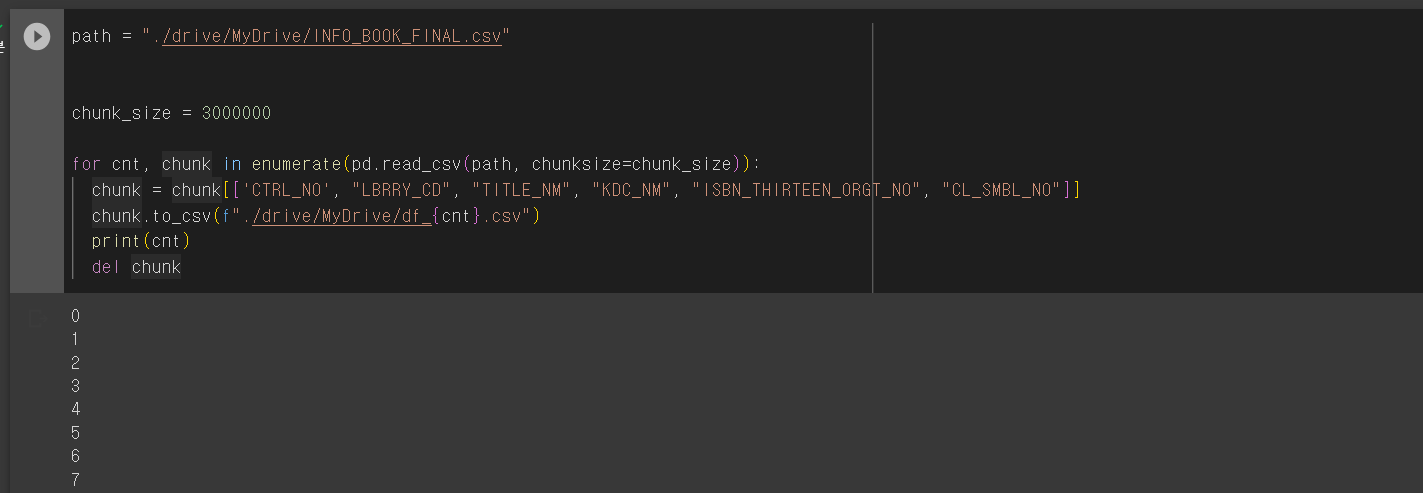
- 도서 목록 개수가 20,000,000개가 넘으면서 너무 큰 대용량 데이터로 인해 구글 드라이브에 데이터를 저장하고, colab에서 쪼개서 csv파일로 부르고 local환경에서 판다스 -> sql로 넘기며 대용량 데이터로 인해 큰 어려움을 겪었다.
프로젝트 방향성 수정
- KDC별로 데이터 수집 및 전처리를 하고 모든 도서관에서 KDC별 도서 데이터의 비중이 비슷한 양상을 보였다.
- 원래의 목적은 공공도서관의 도서 데이터, 지역, 인구통계 데이터를 분석하고 해당 인사이트를 근처 스마트도서관에 적용해 위치별 스마트도서관의 커스텀마이징을 의도했지만, 도서관별로 비슷한 양상을 보여 기존의 방향성을 접고 새로운 방향성을 잡았다.
- 새로운 방향성은 "스마트도서관 비치 도서 추천 시스템"구축이었다.
- 해당 프로젝트는 1월의 A라는 스마트도서관의 대출기록의 책제목 데이터를 2022년 서울시 332개의 공공도서관에서 대출기록에서 추천 도서 리스트를 만드는 것이다. 추천 알고리즘은 다음과 같다.
- KDC별 도서 군집화 형성
- 군집 안에서 스마트도서관의 책제목을 기준으로 공공도서관의 대출기록이 남은 책제목 유사도 분석 결과 상위 20개 리스트 추출
- 상위 20개 리스트 중 공공도서관의 책제목별 대출 횟수를 기준으로 상위 5~10개를 추천 리스트로 만들어 총 50개의 추천 목록 생성
- 위 과정을 통해 추천 리스트를 만드는 프로젝트로 방향을 잡았다.
데이터 수집 및 전처리
- 기존에 수집한 데이터와 정보공개 청구를 통해 서울시 332개의 서울시 공공도서관 리스트, 공공도서관의 대출기록, 스마트도서관의 대출기록 크게 3개의 데이터를 수집 및 전처리 작업을 가졌다.
- 데이터 수집에서 정말 많이 힘들었다. 각 구별로 양식도 다르고 컬럼도 다르고 한해를 집계해서 보내는 경우도 있었다
- 그래도 각 팀원과 구를 나눠서 각자 맡은 구에서 스마트도서관의 데이터를 얻을 수 있었다.
- 몇몇 구의 경우 책제목과 KDC번호를 함께 주어서 차후 테스트 데이터로도 사용했다.
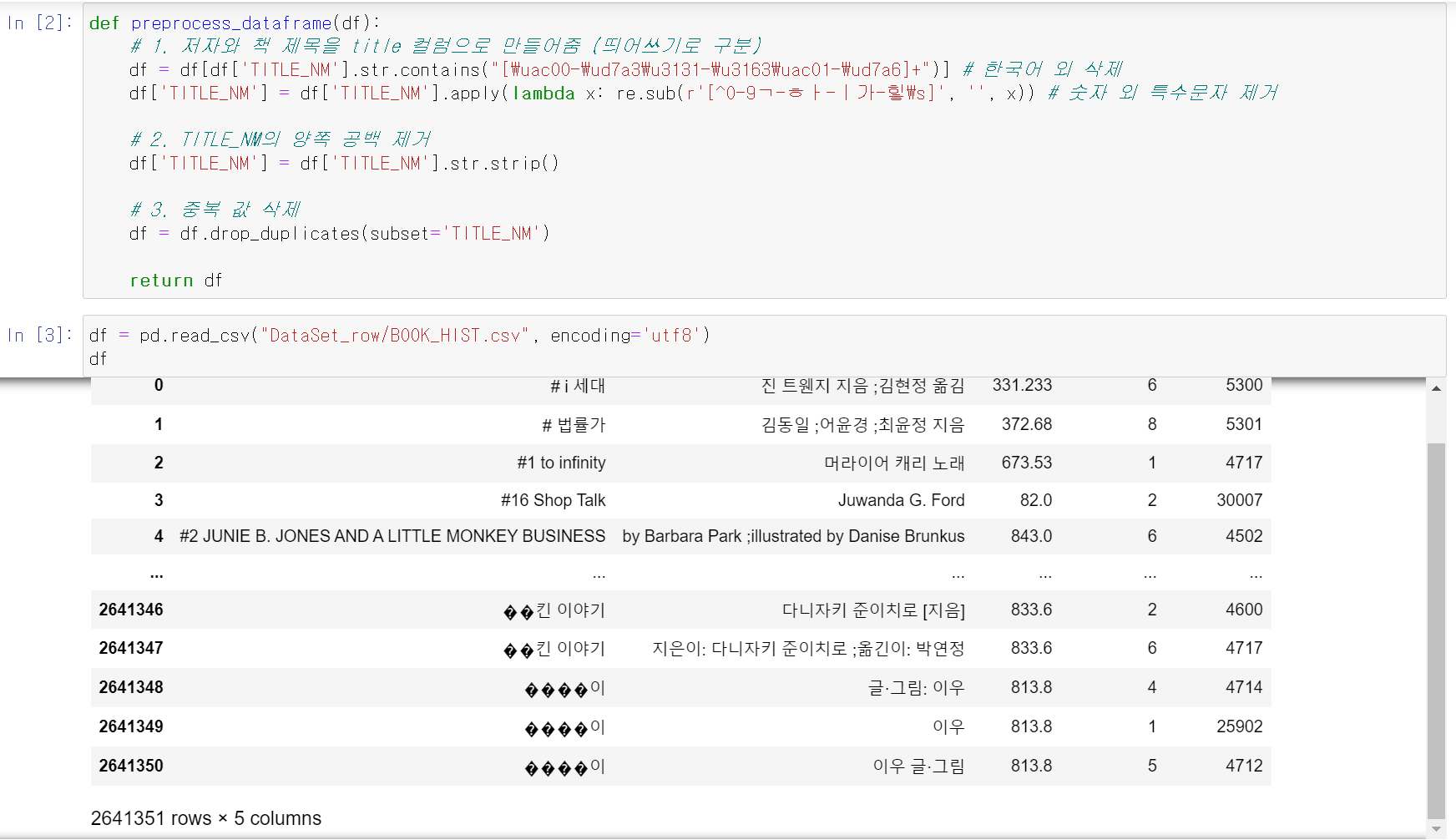
- 그리고 기존에 수집했던 공공도서관의 대출기록을 분석 결과 제목에 특수문자가 많으며, 제목의 유사도 분석 과정에서 한국어를 제외한 외국어가 있는 책이 존재했다.
- 그래서 함수를 통해 책제목의 숫자를 제외한 모든 특스문자를 제거하고, 외국어가 있을 경우 해당 책은 데이터에서 drop했다.
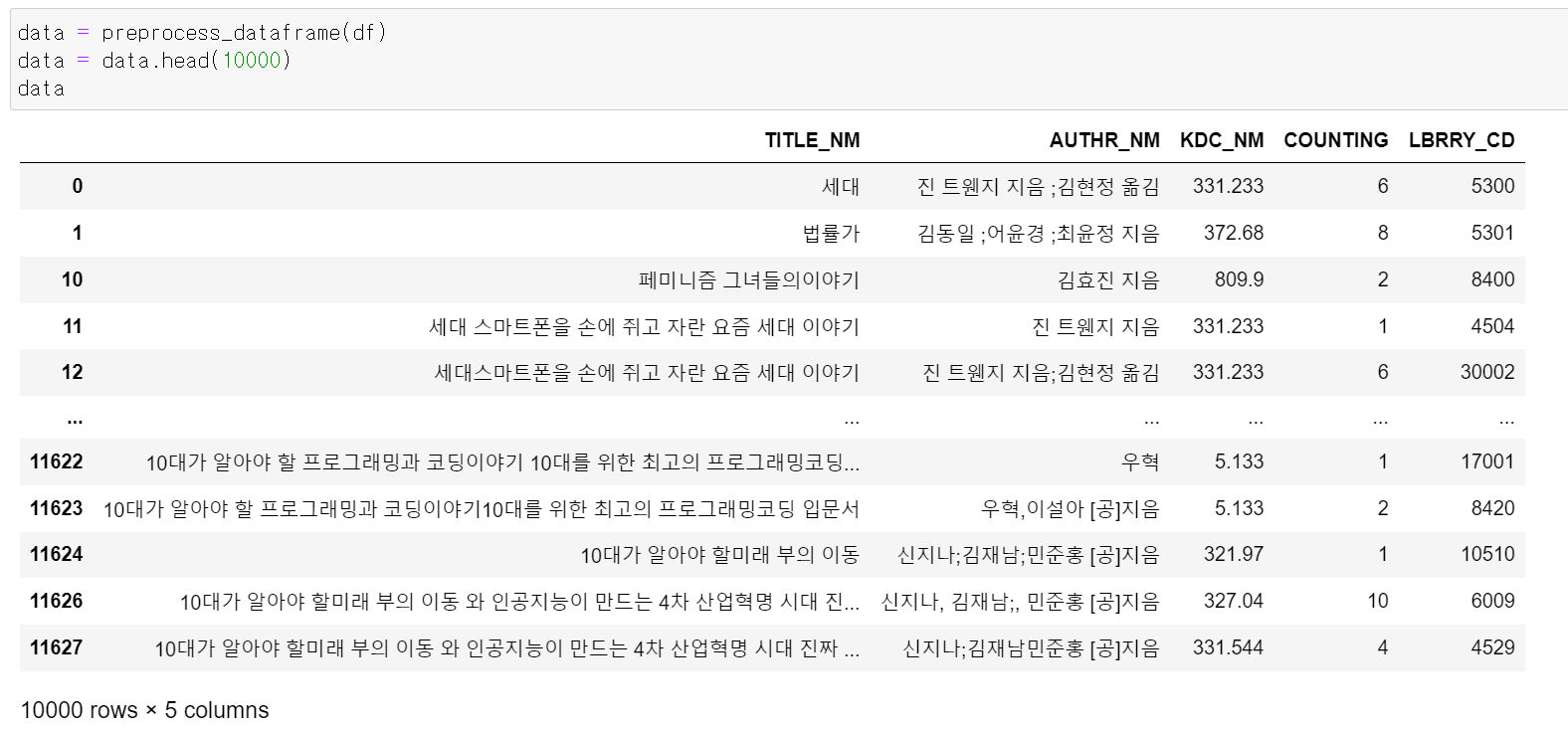
- 전처리 결과 제목이 정상적으로 나왔다.
- 공공도서관의 최종적인 데이터는 [첵제목, 저자, KDC, 대출 횟수, 도서관 코드] 이렇게 나왔다.
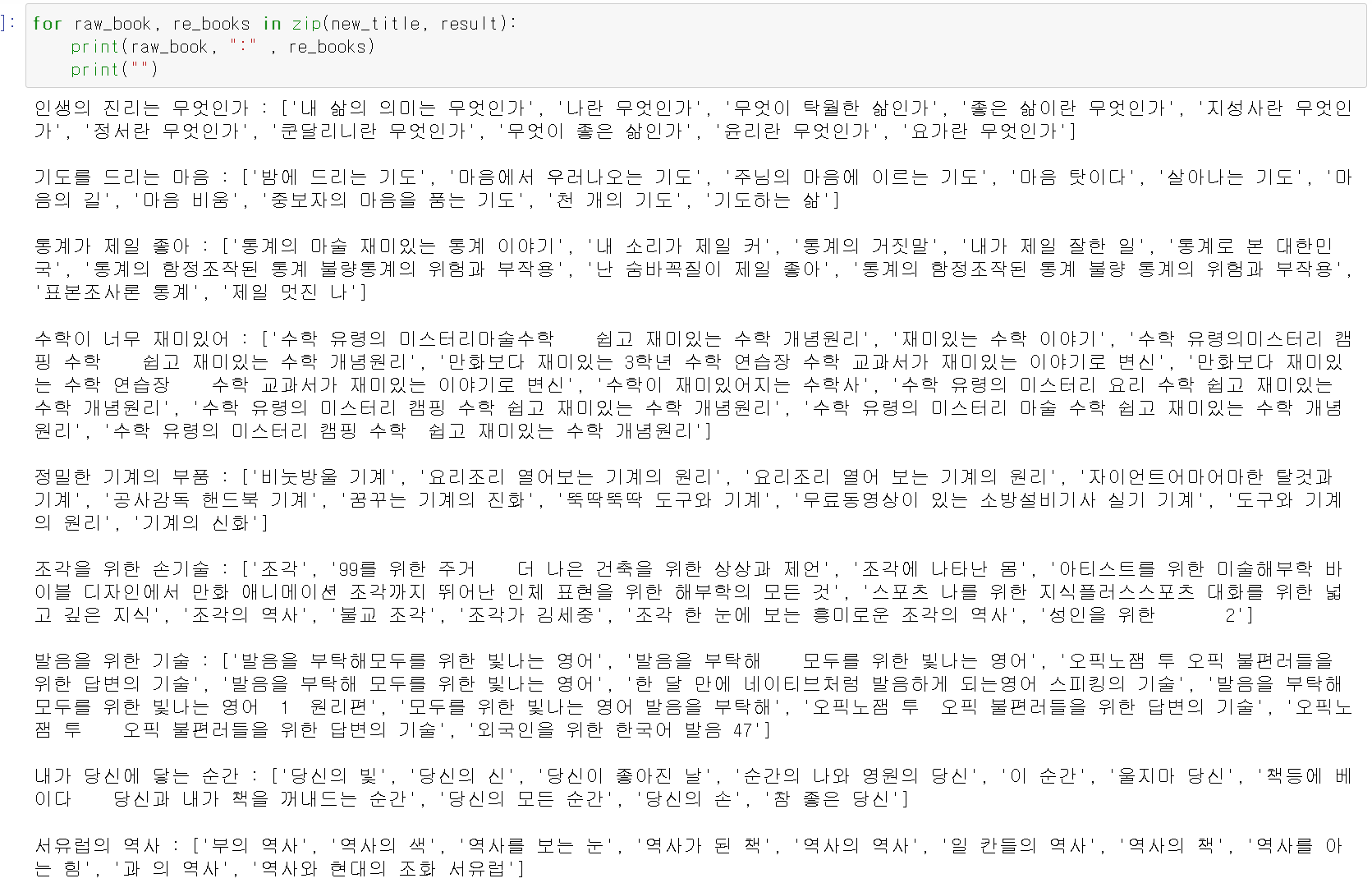
- 임의로 제목을 넣고 유사도 및 카운팅을 기준으로 결과를 보니 유사도가 높으면서 대출 횟수가 많은 책들이 뽑혀나왔다.
모델 구축
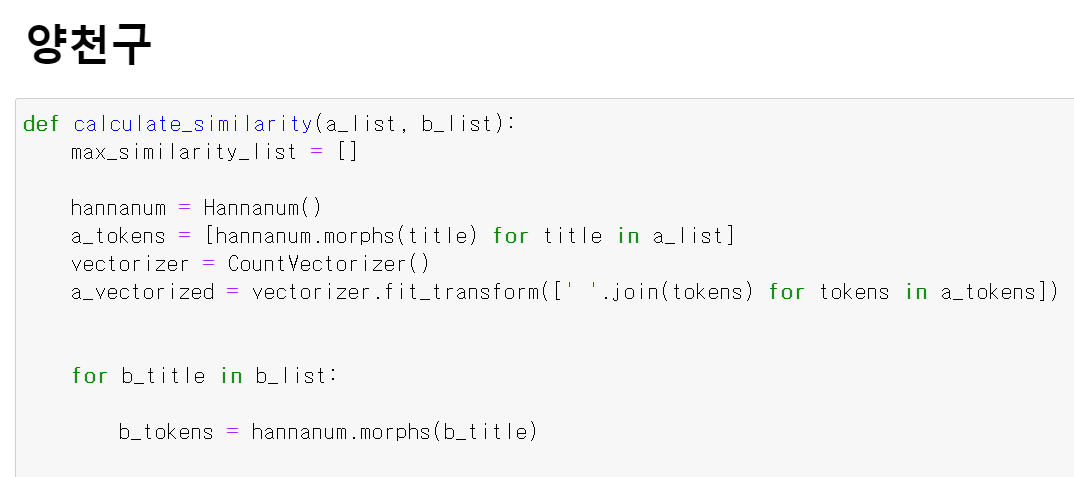
def calculate_similarity(a_list, b_list):
max_similarity_list = []
hannanum = Hannanum()
a_tokens = [hannanum.morphs(title) for title in a_list]
vectorizer = CountVectorizer()
a_vectorized = vectorizer.fit_transform([' '.join(tokens) for tokens in a_tokens])
for b_title in b_list:
b_tokens = hannanum.morphs(b_title)
b_vectorized = vectorizer.transform([' '.join(b_tokens)])
similarity = cosine_similarity(a_vectorized, b_vectorized).max()
max_similarity_list.append(similarity)
average_similarity = sum(max_similarity_list) / len(max_similarity_list)
return average_similarity
def maek_score(data, test_data, n = 20):
data["KDC_NM"] = data["KDC_NM"].astype("str")
test_data['LOAN_DATE'] = pd.to_datetime(test_data['LOAN_DATE'])
test_data['LOAN_DATE'] = test_data['LOAN_DATE'].dt.strftime('%m')
test_data['LOAN_DATE'] = test_data['LOAN_DATE'].astype('int')
test_data['TITLE_NM'] = test_data['TITLE_NM'].apply(lambda x: re.sub(r'[^0-9ㄱ-ㅎㅏ-ㅣ가-힣\s]', '', x))
test_data['TITLE_NM'] = test_data['TITLE_NM'].str.strip()
data_1 = data[data["KDC_NM"].str[0] == "1"]
data_1 = data_1.sort_values("COUNTING", ascending=False)
data_2 = data[data["KDC_NM"].str[0] == "2"]
data_2 = data_2.sort_values("COUNTING", ascending=False)
data_3 = data[data["KDC_NM"].str[0] == "3"]
data_3 = data_3.sort_values("COUNTING", ascending=False)
data_4 = data[data["KDC_NM"].str[0] == "4"]
data_4 = data_4.sort_values("COUNTING", ascending=False)
data_5 = data[data["KDC_NM"].str[0] == "5"]
data_5 = data_5.sort_values("COUNTING", ascending=False)
data_6 = data[data["KDC_NM"].str[0] == "6"]
data_6 = data_6.sort_values("COUNTING", ascending=False)
data_7 = data[data["KDC_NM"].str[0] == "7"]
data_7 = data_7.sort_values("COUNTING", ascending=False)
data_8 = data[data["KDC_NM"].str[0] == "8"]
data_8 = data_8.sort_values("COUNTING", ascending=False)
data_9 = data[data["KDC_NM"].str[0] == "9"]
data_9 = data_9.sort_values("COUNTING", ascending=False)
hannanum = Hannanum()
tokens1 = [hannanum.morphs(datum) for datum in data_1["TITLE_NM"]]
tokens2 = [hannanum.morphs(datum) for datum in data_2["TITLE_NM"]]
tokens3 = [hannanum.morphs(datum) for datum in data_3["TITLE_NM"]]
tokens4 = [hannanum.morphs(datum) for datum in data_4["TITLE_NM"]]
tokens5 = [hannanum.morphs(datum) for datum in data_5["TITLE_NM"]]
tokens6 = [hannanum.morphs(datum) for datum in data_6["TITLE_NM"]]
tokens7 = [hannanum.morphs(datum) for datum in data_7["TITLE_NM"]]
tokens8 = [hannanum.morphs(datum) for datum in data_8["TITLE_NM"]]
tokens9 = [hannanum.morphs(datum) for datum in data_9["TITLE_NM"]]
vectorizer1 = CountVectorizer()
vectorized_data1 = vectorizer1.fit_transform([' '.join(token) for token in tokens1])
vectorizer2 = CountVectorizer()
vectorized_data2 = vectorizer2.fit_transform([' '.join(token) for token in tokens2])
vectorizer3 = CountVectorizer()
vectorized_data3 = vectorizer3.fit_transform([' '.join(token) for token in tokens3])
vectorizer4 = CountVectorizer()
vectorized_data4 = vectorizer4.fit_transform([' '.join(token) for token in tokens4])
vectorizer5 = CountVectorizer()
vectorized_data5 = vectorizer5.fit_transform([' '.join(token) for token in tokens5])
vectorizer6 = CountVectorizer()
vectorized_data6 = vectorizer6.fit_transform([' '.join(token) for token in tokens6])
vectorizer7 = CountVectorizer()
vectorized_data7 = vectorizer7.fit_transform([' '.join(token) for token in tokens7])
vectorizer8 = CountVectorizer()
vectorized_data8 = vectorizer8.fit_transform([' '.join(token) for token in tokens8])
vectorizer9 = CountVectorizer()
vectorized_data9 = vectorizer9.fit_transform([' '.join(token) for token in tokens9])
score_list = []
for num in range(1, 12):
similar_titles_list = []
month_data = test_data[test_data['LOAN_DATE']==num]
new_title_list = list(month_data['TITLE_NM'])
kdc_list = list(month_data['KDC_NM'].str[0])
for kdc, new_title in zip(kdc_list, new_title_list):
if kdc == "1":
new_title = new_title
new_title_tokenized = hannanum.morphs(new_title)
new_title_vectorized = vectorizer1.transform([' '.join(new_title_tokenized)]).toarray()
similarities = cosine_similarity(vectorized_data1, new_title_vectorized)
similar_indices = similarities.flatten().argsort()[-n:][::-1]
similar_books = data_1.iloc[similar_indices]
similar_books = similar_books.sort_values("COUNTING", ascending=False).head(5)
similar_titles = similar_books["TITLE_NM"].tolist()
similar_titles_list.append(similar_titles)
elif kdc == "2":
new_title = new_title
new_title_tokenized = hannanum.morphs(new_title)
new_title_vectorized = vectorizer2.transform([' '.join(new_title_tokenized)]).toarray()
similarities = cosine_similarity(vectorized_data2, new_title_vectorized)
similar_indices = similarities.flatten().argsort()[-n:][::-1]
similar_books = data_2.iloc[similar_indices]
similar_books = similar_books.sort_values("COUNTING", ascending=False).head(5)
similar_titles = similar_books["TITLE_NM"].tolist()
similar_titles_list.append(similar_titles)
elif kdc == "3":
new_title = new_title
new_title_tokenized = hannanum.morphs(new_title)
new_title_vectorized = vectorizer3.transform([' '.join(new_title_tokenized)]).toarray()
similarities = cosine_similarity(vectorized_data3, new_title_vectorized)
similar_indices = similarities.flatten().argsort()[-n:][::-1]
similar_books = data_3.iloc[similar_indices]
similar_books = similar_books.sort_values("COUNTING", ascending=False).head(5)
similar_titles = similar_books["TITLE_NM"].tolist()
similar_titles_list.append(similar_titles)
elif kdc == "4":
new_title = new_title
new_title_tokenized = hannanum.morphs(new_title)
new_title_vectorized = vectorizer4.transform([' '.join(new_title_tokenized)]).toarray()
similarities = cosine_similarity(vectorized_data4, new_title_vectorized)
similar_indices = similarities.flatten().argsort()[-n:][::-1]
similar_books = data_4.iloc[similar_indices]
similar_books = similar_books.sort_values("COUNTING", ascending=False).head(5)
similar_titles = similar_books["TITLE_NM"].tolist()
similar_titles_list.append(similar_titles)
elif kdc == "5":
new_title = new_title
new_title_tokenized = hannanum.morphs(new_title)
new_title_vectorized = vectorizer5.transform([' '.join(new_title_tokenized)]).toarray()
similarities = cosine_similarity(vectorized_data5, new_title_vectorized)
similar_indices = similarities.flatten().argsort()[-n:][::-1]
similar_books = data_5.iloc[similar_indices]
similar_books = similar_books.sort_values("COUNTING", ascending=False).head(5)
similar_titles = similar_books["TITLE_NM"].tolist()
similar_titles_list.append(similar_titles)
elif kdc == "6":
new_title = new_title
new_title_tokenized = hannanum.morphs(new_title)
new_title_vectorized = vectorizer6.transform([' '.join(new_title_tokenized)]).toarray()
similarities = cosine_similarity(vectorized_data6, new_title_vectorized)
similar_indices = similarities.flatten().argsort()[-n:][::-1]
similar_books = data_6.iloc[similar_indices]
similar_books = similar_books.sort_values("COUNTING", ascending=False).head(5)
similar_titles = similar_books["TITLE_NM"].tolist()
similar_titles_list.append(similar_titles)
elif kdc == "7":
new_title = new_title
new_title_tokenized = hannanum.morphs(new_title)
new_title_vectorized = vectorizer7.transform([' '.join(new_title_tokenized)]).toarray()
similarities = cosine_similarity(vectorized_data7, new_title_vectorized)
similar_indices = similarities.flatten().argsort()[-n:][::-1]
similar_books = data_7.iloc[similar_indices]
similar_books = similar_books.sort_values("COUNTING", ascending=False).head(5)
similar_titles = similar_books["TITLE_NM"].tolist()
similar_titles_list.append(similar_titles)
elif kdc == "8":
new_title = new_title
new_title_tokenized = hannanum.morphs(new_title)
new_title_vectorized = vectorizer8.transform([' '.join(new_title_tokenized)]).toarray()
similarities = cosine_similarity(vectorized_data8, new_title_vectorized)
similar_indices = similarities.flatten().argsort()[-n:][::-1]
similar_books = data_8.iloc[similar_indices]
similar_books = similar_books.sort_values("COUNTING", ascending=False).head(10)
similar_titles = similar_books["TITLE_NM"].tolist()
similar_titles_list.append(similar_titles)
elif kdc == "9":
new_title = new_title
new_title_tokenized = hannanum.morphs(new_title)
new_title_vectorized = vectorizer9.transform([' '.join(new_title_tokenized)]).toarray()
similarities = cosine_similarity(vectorized_data9, new_title_vectorized)
similar_indices = similarities.flatten().argsort()[-n:][::-1]
similar_books = data_9.iloc[similar_indices]
similar_books = similar_books.sort_values("COUNTING", ascending=False).head(5)
similar_titles = similar_books["TITLE_NM"].tolist()
similar_titles_list.append(similar_titles)
else:
pass
after_book = list(test_data[test_data['LOAN_DATE']==num+1]['TITLE_NM'])
similar_titles_list = [item for sublist in similar_titles_list for item in sublist]
result = calculate_similarity(after_book, similar_titles_list)
print(f"{num+1}월 : {result}")
score_list.append(result)
return score_list- 위 해당 함수를 통해 스마트도서관의 대출기록을 공공도서관의 대출기록과 비교해 KDC군집, 유사도 분석, 대출 횟수 기준 추천 도서 추천 등 3개의 단계를 거치는 모델을 구축했다.
- 먼저 유사도 분석의 경우 먼저 konlpy를 통해 책제목을 형태소 단위로 구분하고, CountVectorizer를 통해 형태소 별로 구분한 단어를 벡터화시켰다. 그리고 벡터화 시킨 데이터를 코사인 유사도 분석을 통해 책제목의 유사도를 분석했다.
- 위 방법을 사용한 이유는 책제목의 경우 문맥적 의미보다 단어에 함축적인 의미를 많이 사용하고 의미가 없는 단어를 사용하는 경우가 적기 때문에 형태소별로 구분하고 해당 형태소의 빈도를 통해 유사도를 분석했다.
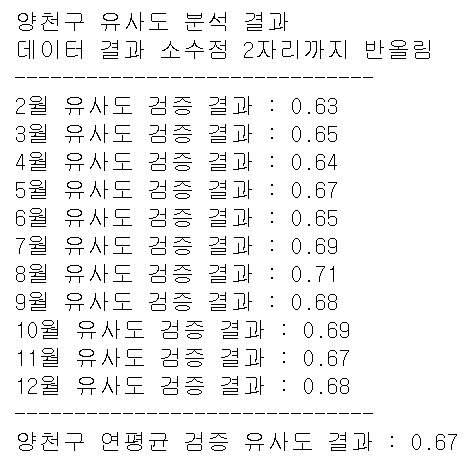
- 이제 특정 구에 대한 스마트도서관의 대출기록과 구축한 모델에 돌려 성능을 테스트한 결과 유사도의 연평균 기준 0.67이 나왔다.
- 마지막에 프로젝트의 방향성을 바꾸며 급하게 끝냈지만, 그래도 유사도 분석 결과가 만족스럽게 나왔다.

상황을 바꿀 수 없다면, 나를 바꾸자