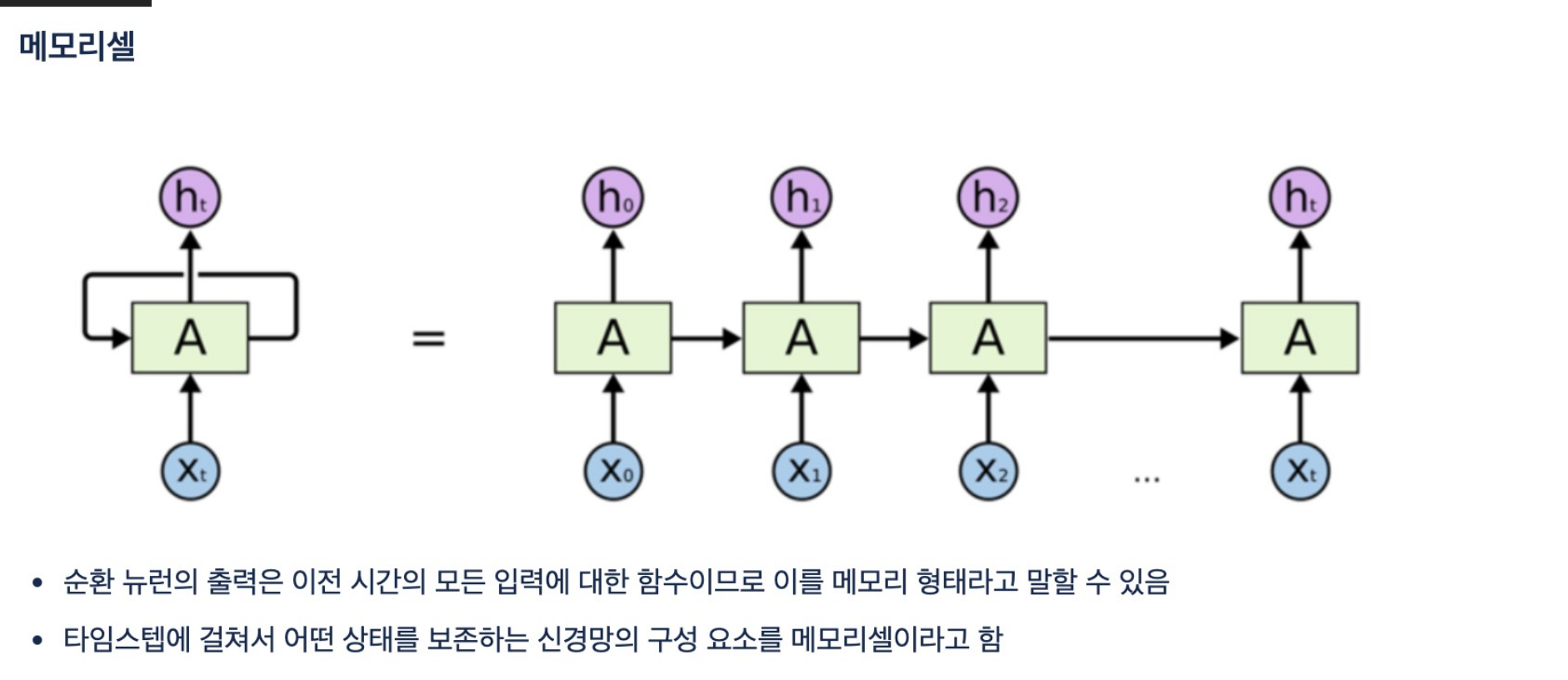
- RNN은 메모리셀 기반의 딥러닝 모델로서 자연어 처리 및 시계열 데이터 처리에 유용하다
- RNN의 특징으로 $ y = f(Xt, u1)$ 즉 이전 데이터와 입력값을 모두 받아 출력값을 만든다는 것이다.
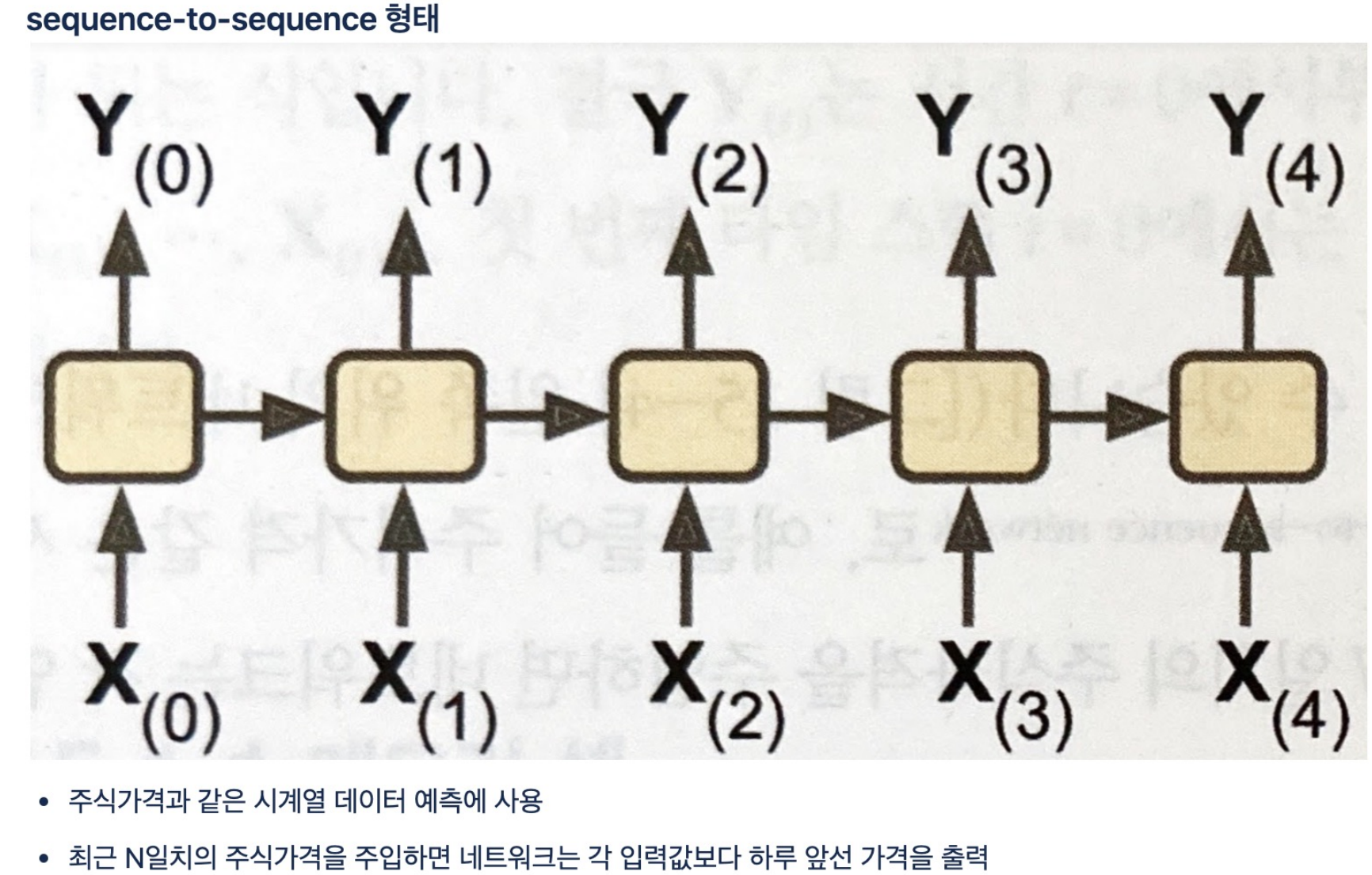
- 구체적인 flow로서 이전의 시계열 데이터와 입력값을 통해 학습하고 출력값을 산출한다.
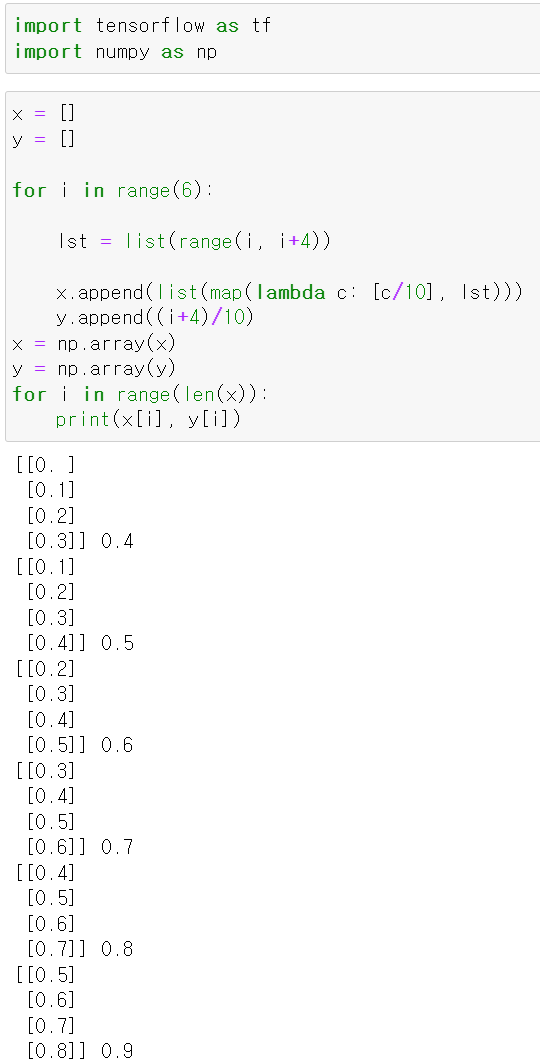
- 간단한 예시로 4개의 데이터와 4개의 라벨을 통해 모델을 학습시켰다.
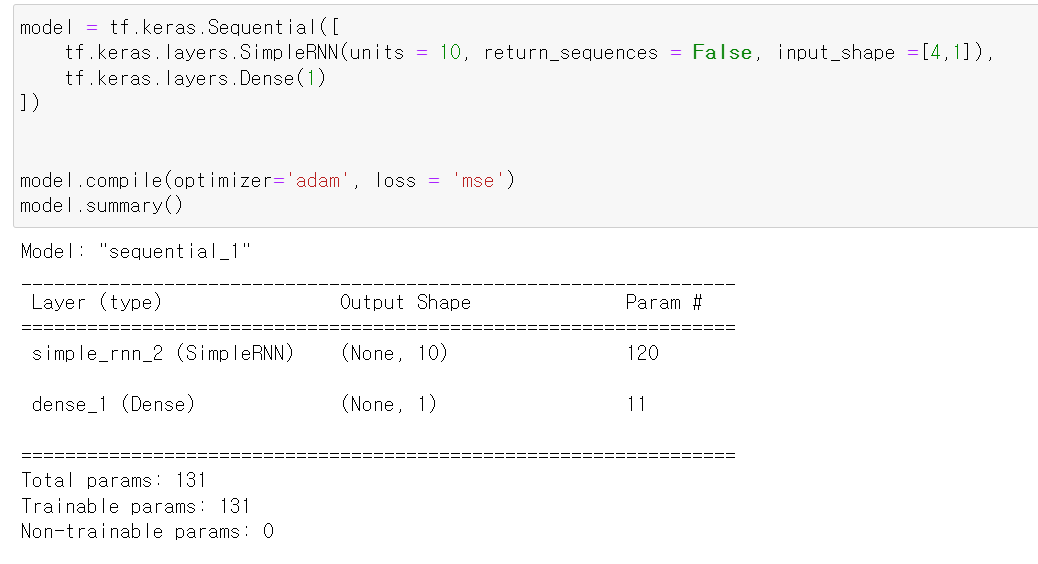
- 모델은 아주 심플한 RNN모델을 구축했으며, 각 입력값의 설명은 아래와 같다.

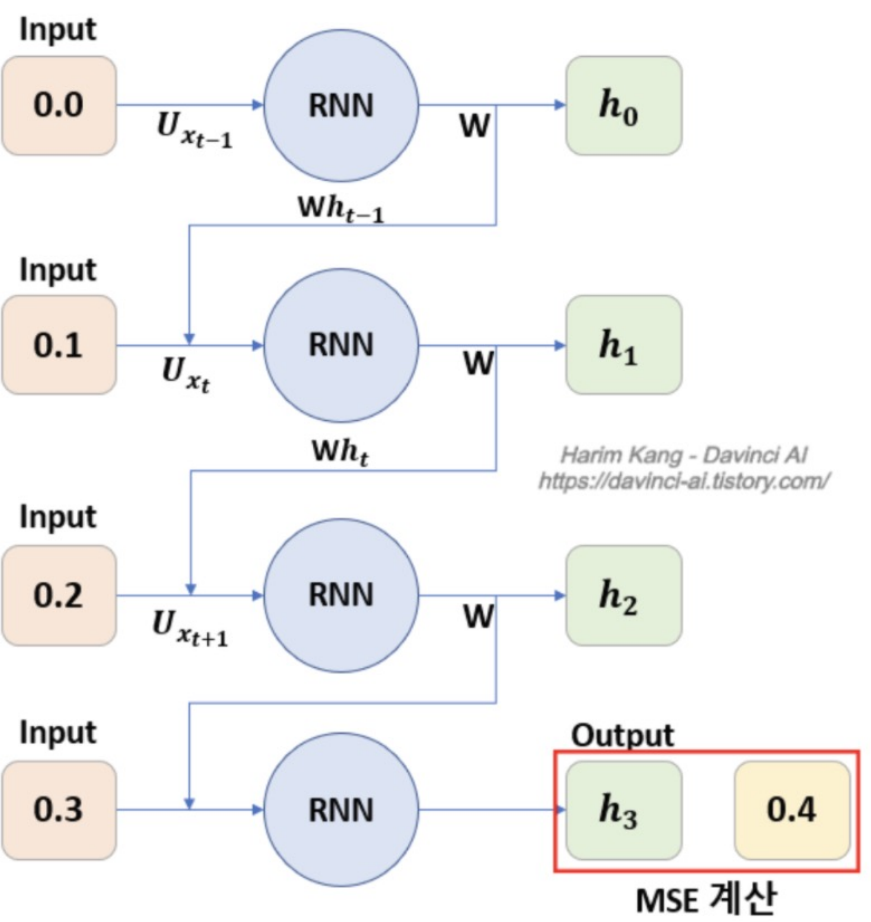
- 위 모델의 모양은 그림고 같이 구현된다.
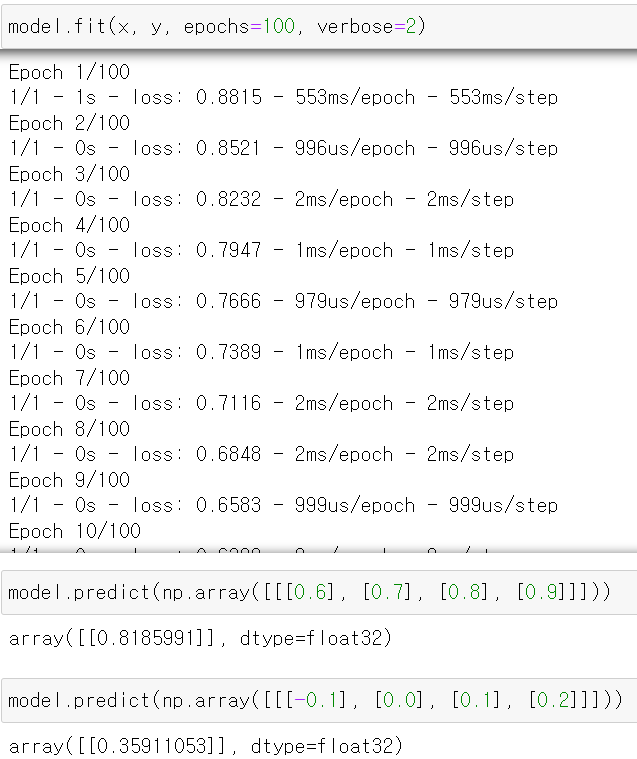
- 그리고 구축한 모델을 통해 예시로 만든 데이터를 교육시키고, 새로운 데이터를 넣어 예측값을 만들어봤다.
- 1과 0.2가 나와야하는데 제대로 예측이 되지 않았다.

- 그 이유는 RNN의 경우 입력 데이터가 길어지면 초기의 데이터가 뒤로 갈수록 영향을 적게 받아서 제대로된 예측이 어렵다.
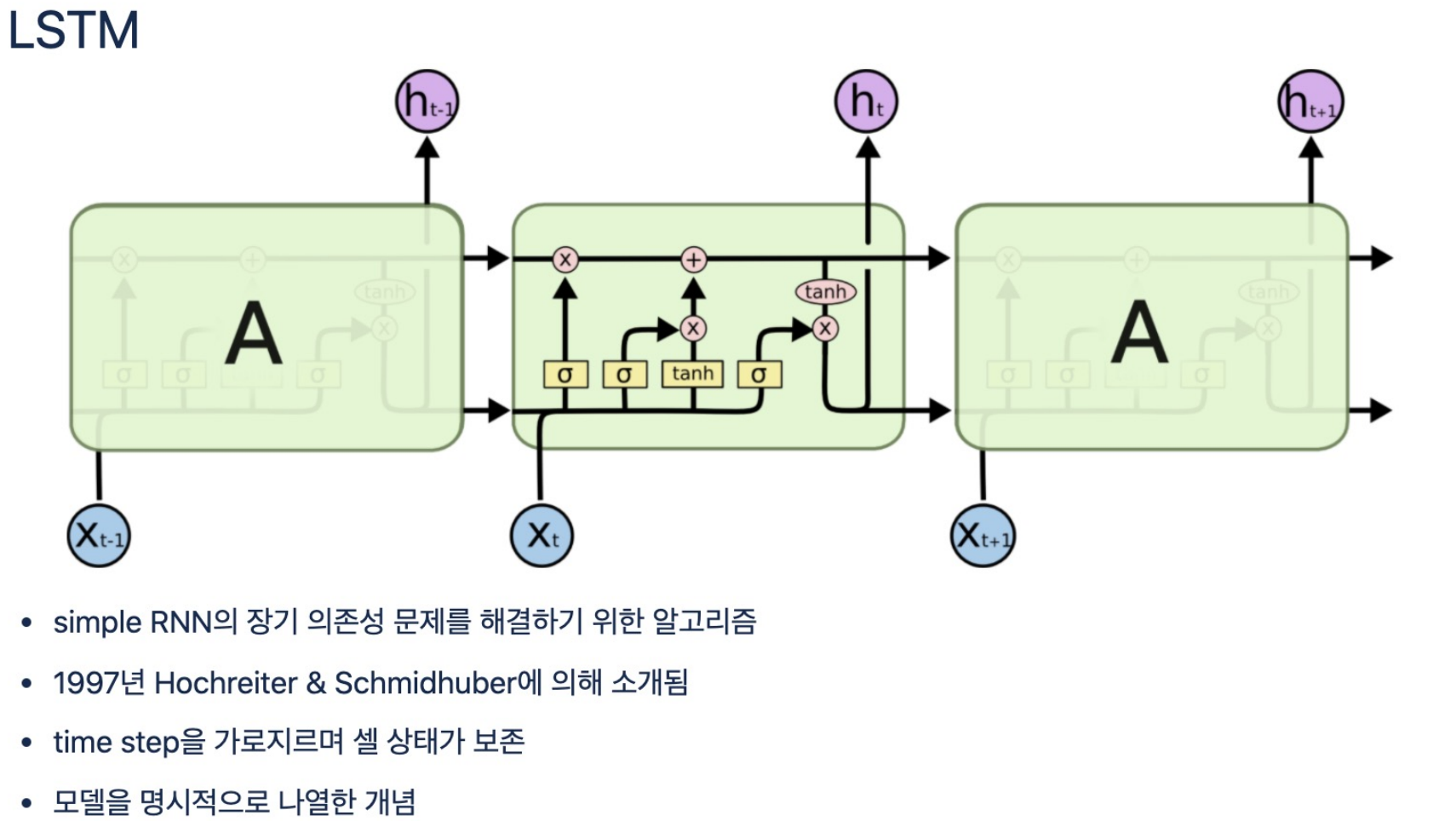
- RNN의 단점을 극복하기 위해 만들어진 모델인 LSTM이다.
- 해당 모델을 두 개의 파이프를 통해 RNN을 그대로 수행하는 파이프와 초기 데이터를 유지하는 파이프 두 개가 존재한다.
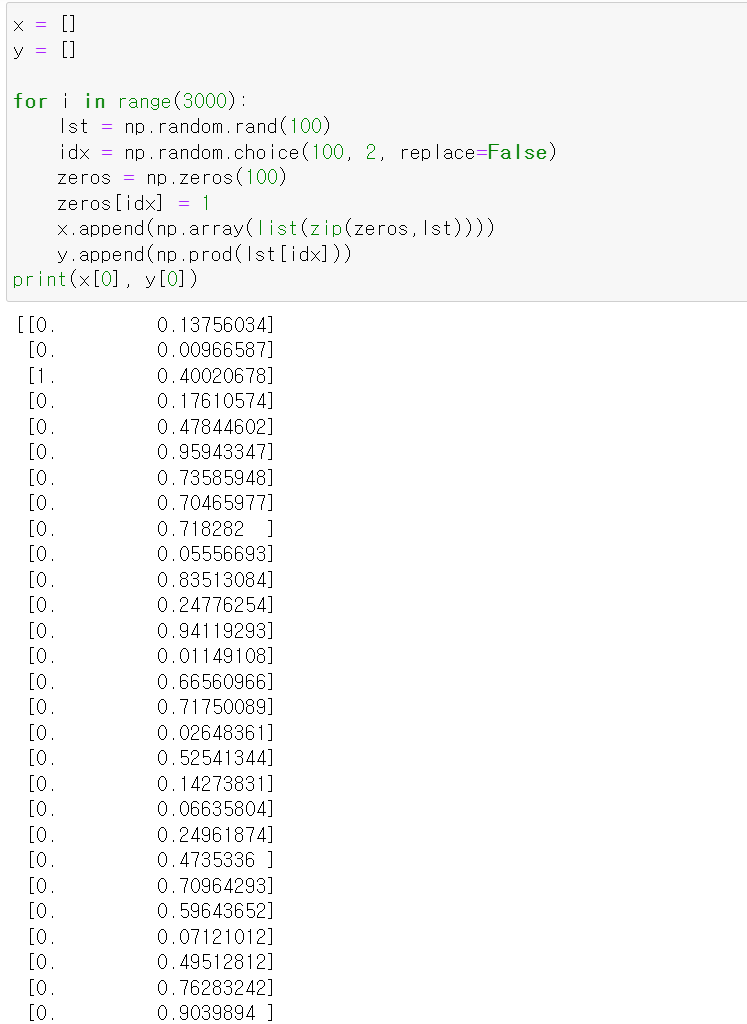
- 이번에는 numpy의 random를 통해 불규칙한 데이터셋을 구성하고
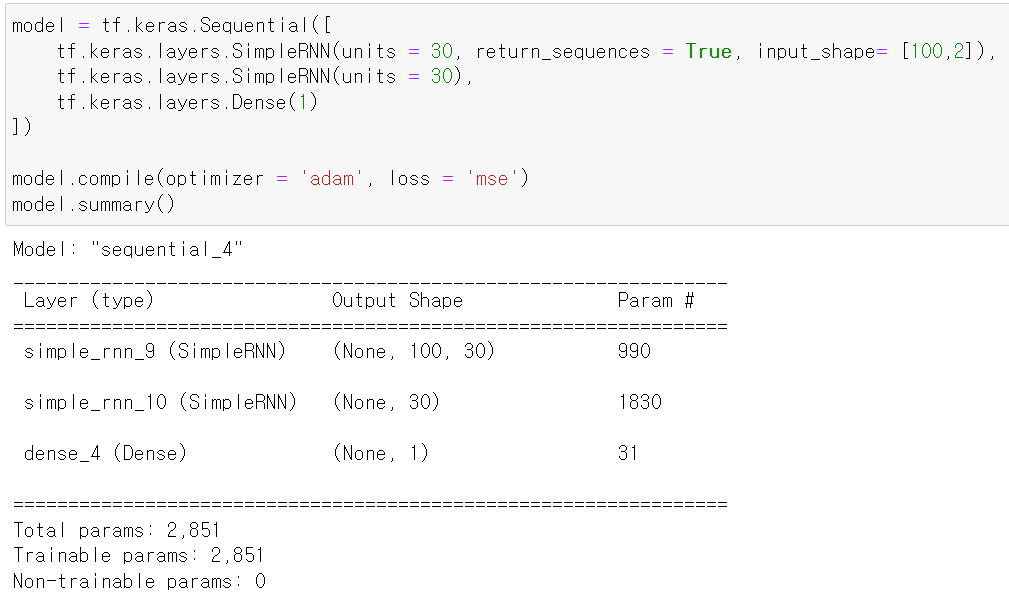
- 해당 데이터를 위에 구축한 모델에 넣어 RNN으로 model을 compile했다.

- random으로 구성한 데이터를 교육시킨 후
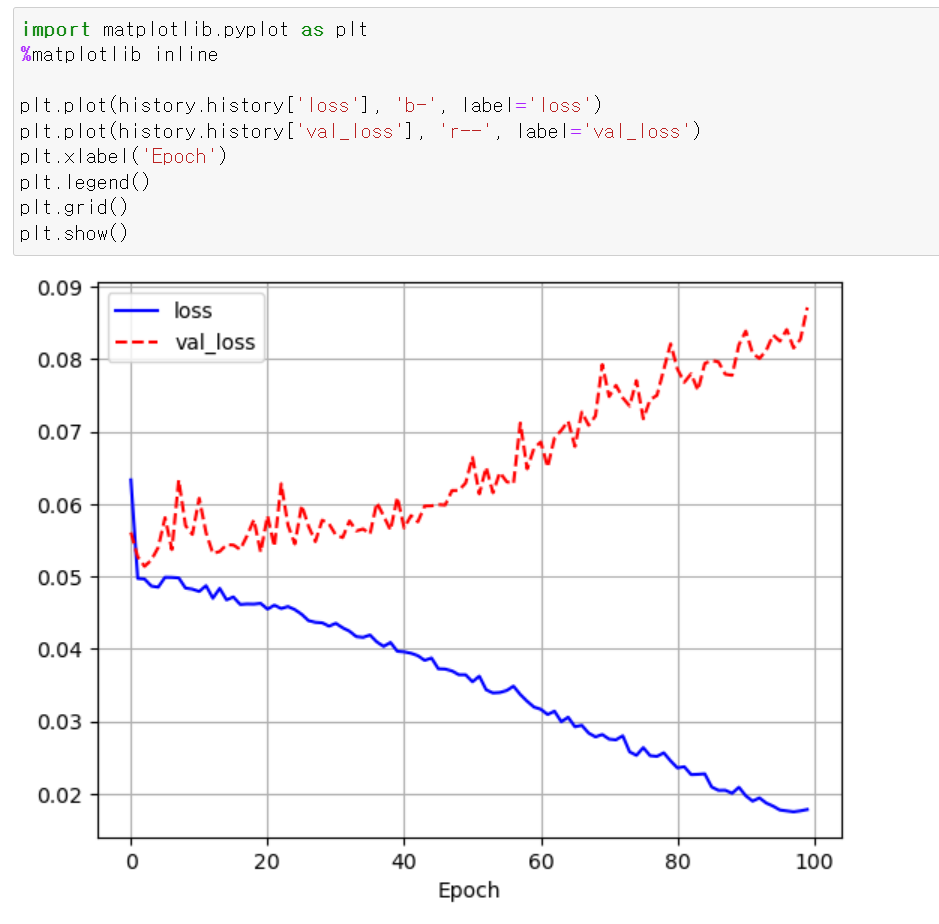
- loss값에 대한 성능을 테스트해보니, validation_data에 대한 loss값이 점점 올라감으로써 제대로된 학습이 진행되지 않는다.
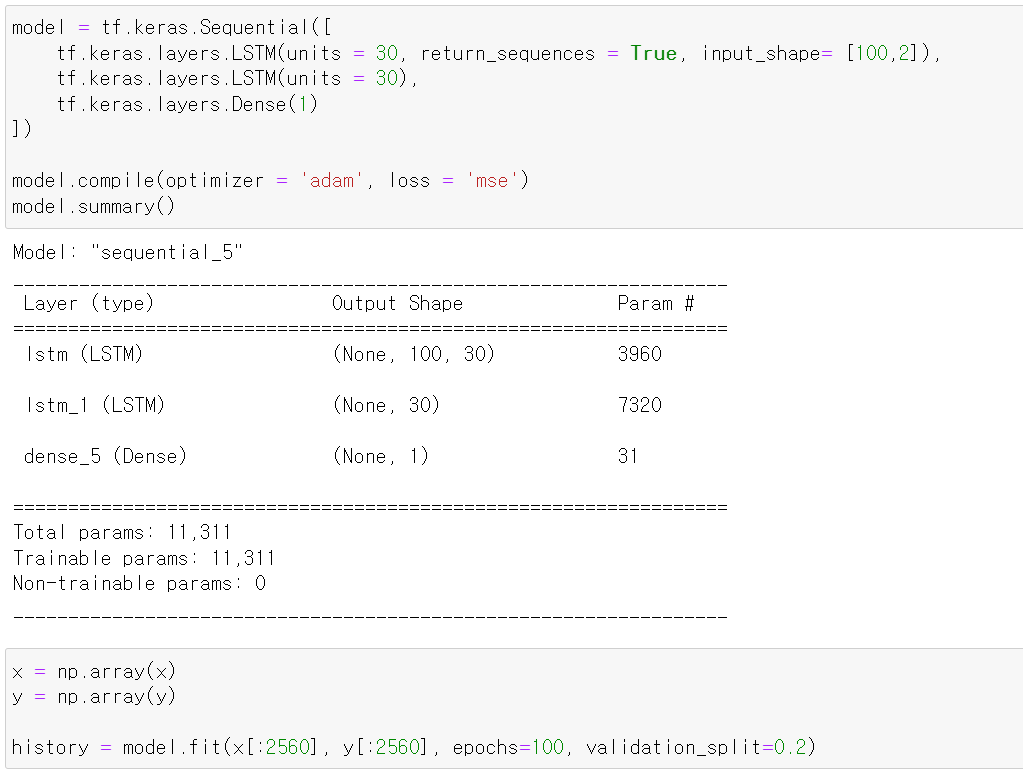
- 이번에는 RNN의 단점을 극복한 LSTM으로 똑같이 모델을 구성하고
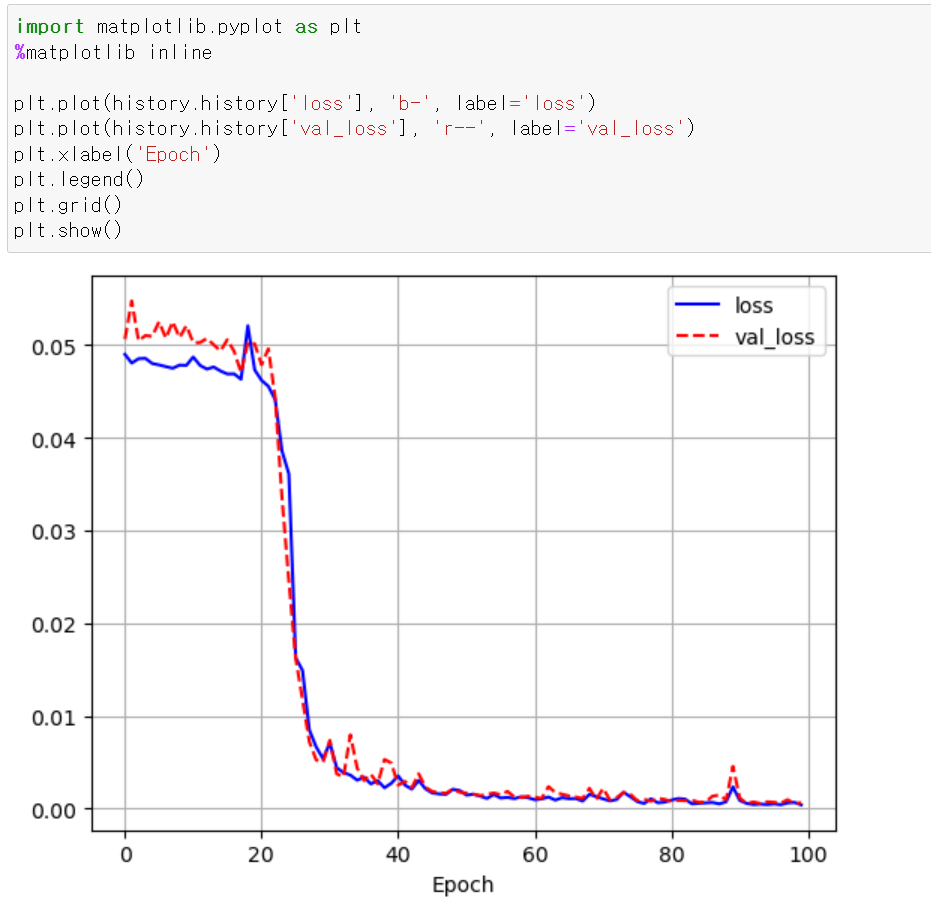
- fit시킨 후 성능을 확인해보니 RNN과 다르게 Validation_data에 대한 loss값이 지속적으로 떨어지면 성능이 개선되는 것이 보인다.

- 이번에는 LSTM을 통해 감성 분석을 진행해봤다.
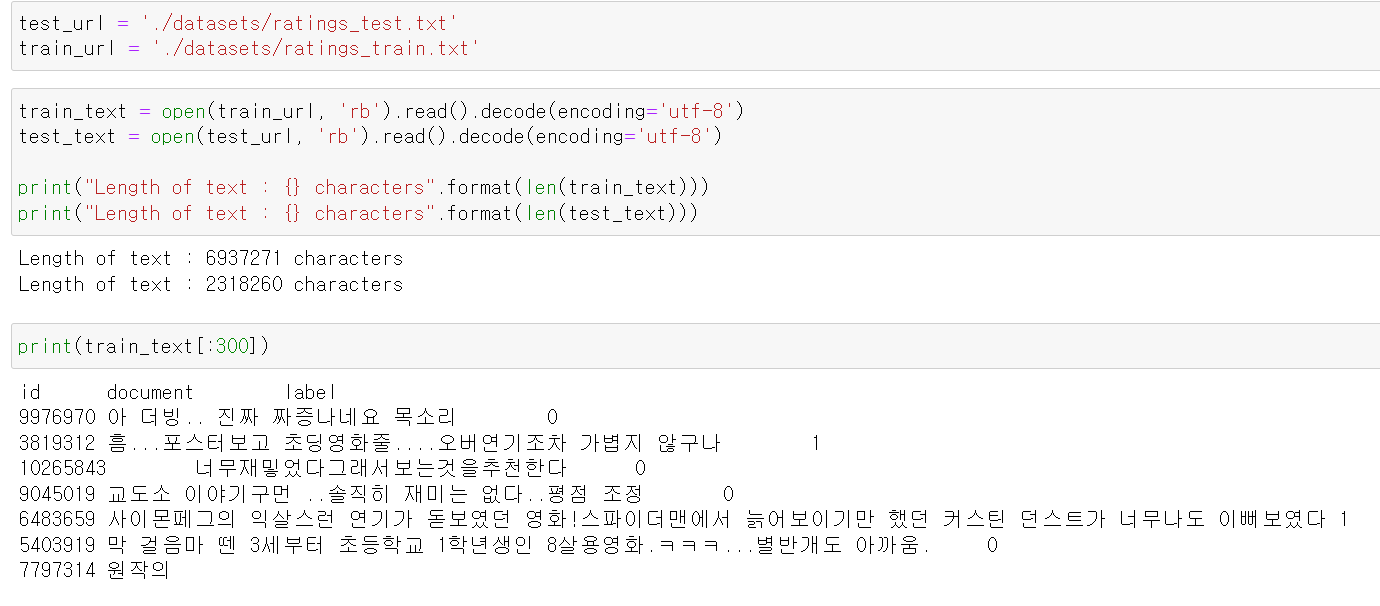
- 먼저 데이터셋을 불러오고, 해당 데이터들의 글자 개수를 확인했다.
- 그리고 일정 부분을 확인해보니 정리가 되지 않아서 글자와 label값이 구분되어 있지 않다.

- 이제 구분을 위해 split을 통해 나눠주고, label값만 별도로 0과 1로 구분해서 저장했다.

- 이제 자연어 분석을 하기 전에 중요한 개념이 tokenization과 cleaning이다.
- tokenization은 문장을 형태소 혹은 띄어쓰기 등 기준을 정하고 말뭉치를 나누는 기준이다.
- cleaning은 문장 해석 시 불필요한 단어 혹은 말뭉치를 없애는 과정이다.
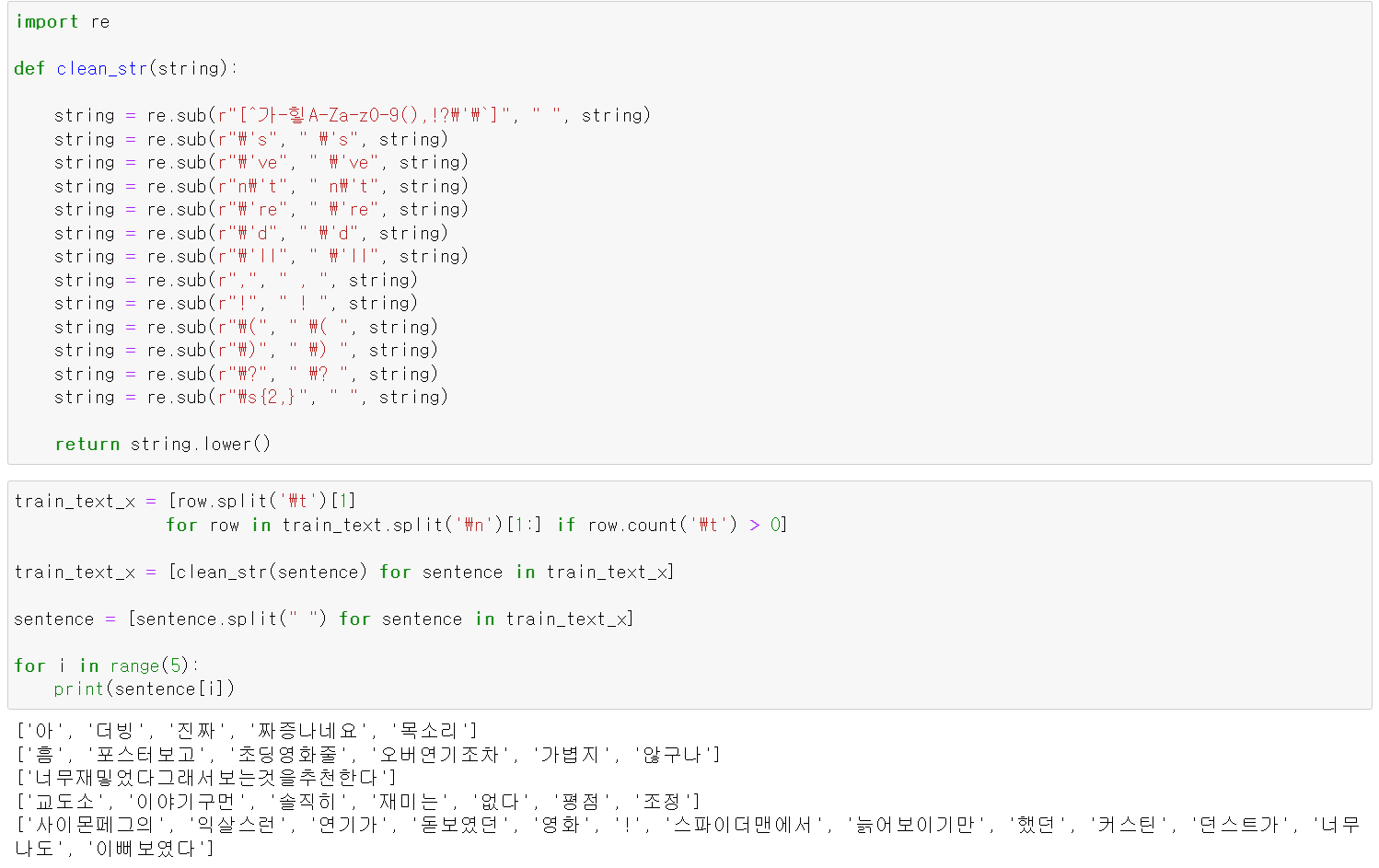
- 먼저 clean과정을 위해 re모듈을 통해 불필요한 단어들을 없애고, 띄어쓰기를 기준을 tokenization을 진행했다.
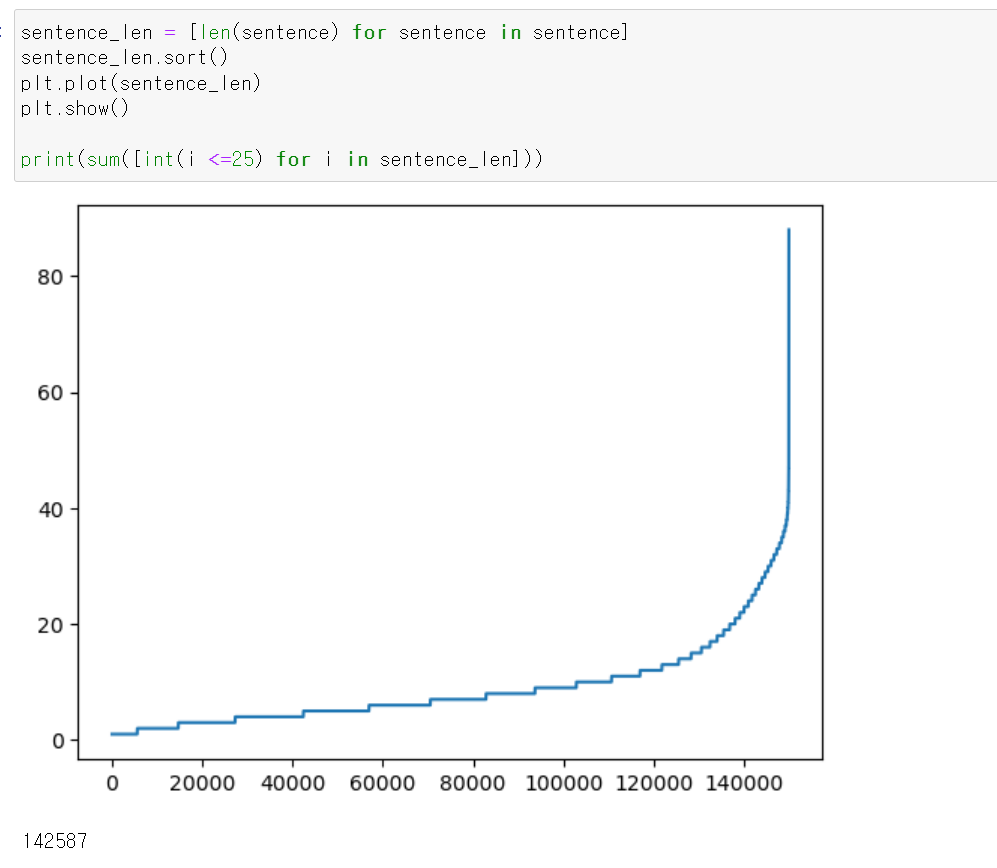
- 또한, 중요한 점이 데이터를 모델에 교육시키기 위해 말뭉치의 수가 같아야하기 때문에 시각화를 통해 확인해보니 25개까지 말뭉치만 사용해서 분석하면 될 것 같다.
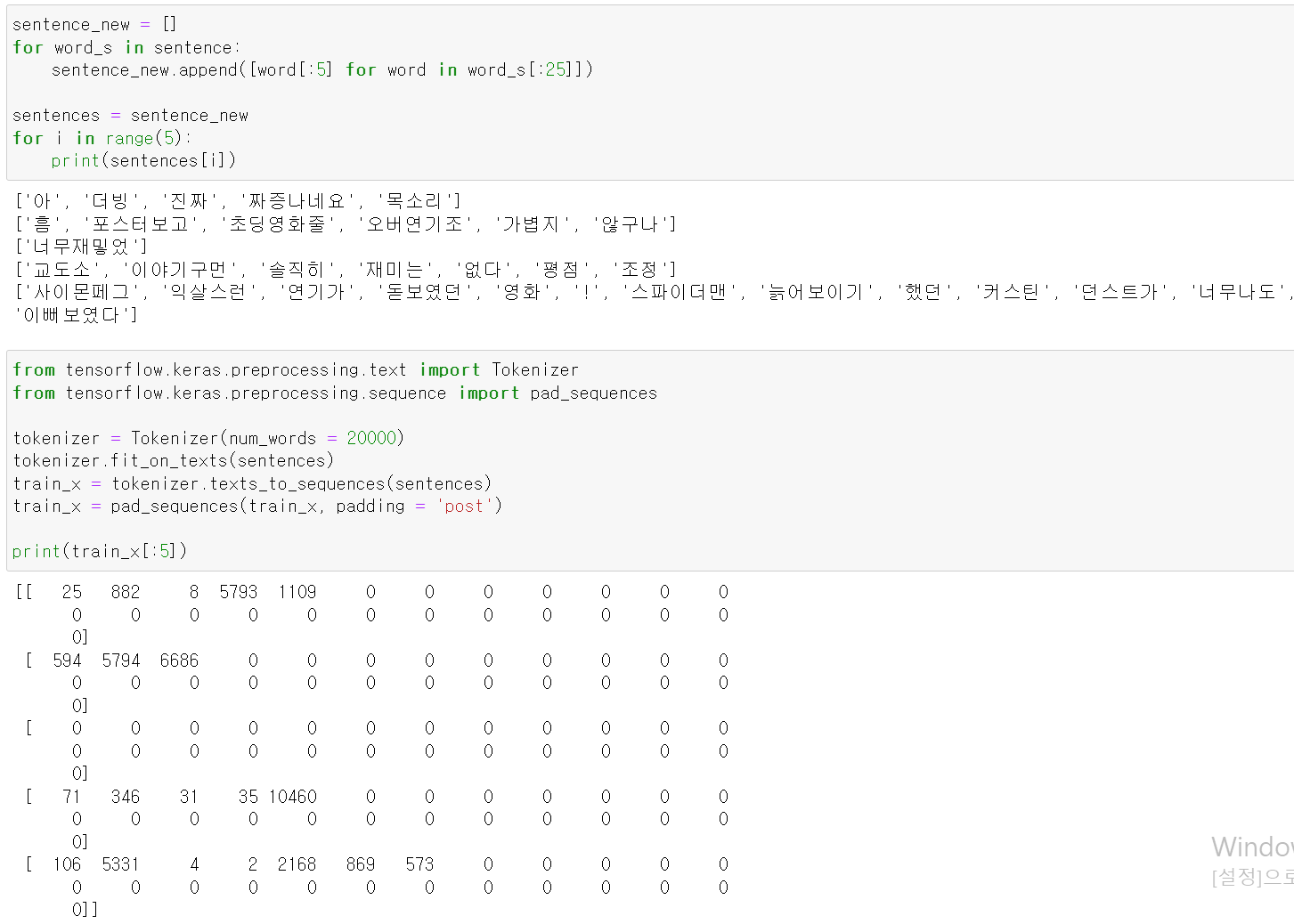
- 하지만, 25개의 말뭉치가 되지 않는 문장도 있기 때문에 pad_sequence를 통해 빈값을 0으로 넣어줬다.
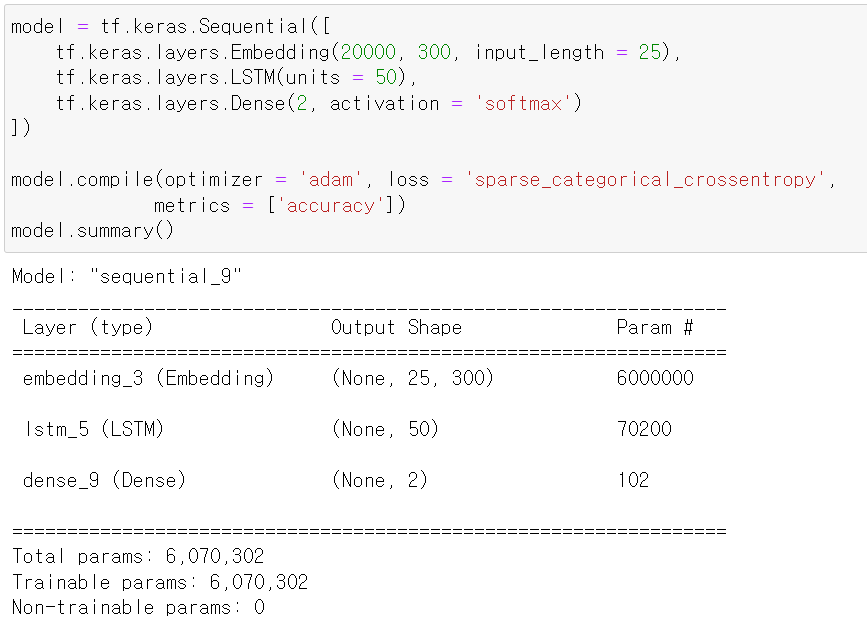
- 그리고 모델을 구축했다.

- 여기서 Enbedding은 자연어 처리 과정에서 전처리 과정을 수행해주는 모델이다.
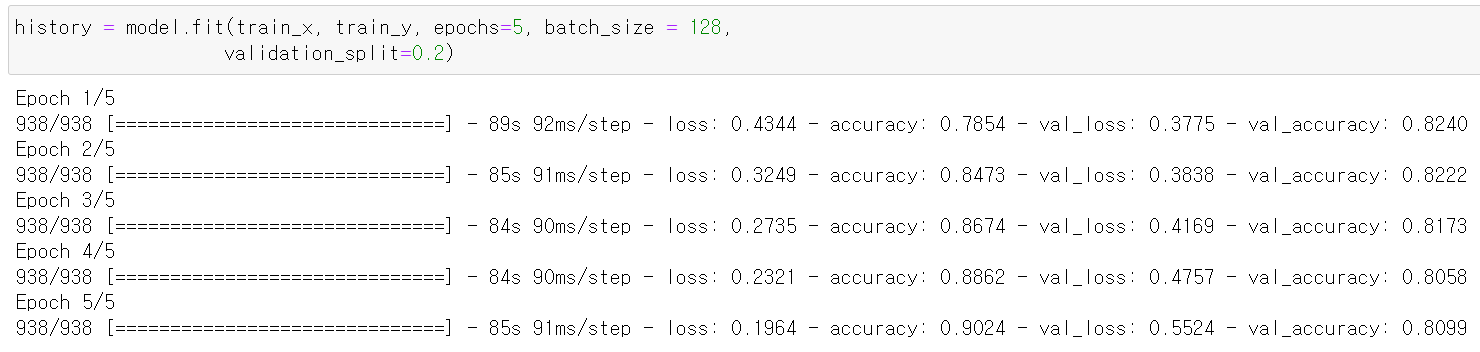
- 이제 구축한 모델에 데이터를 교육시킨 후
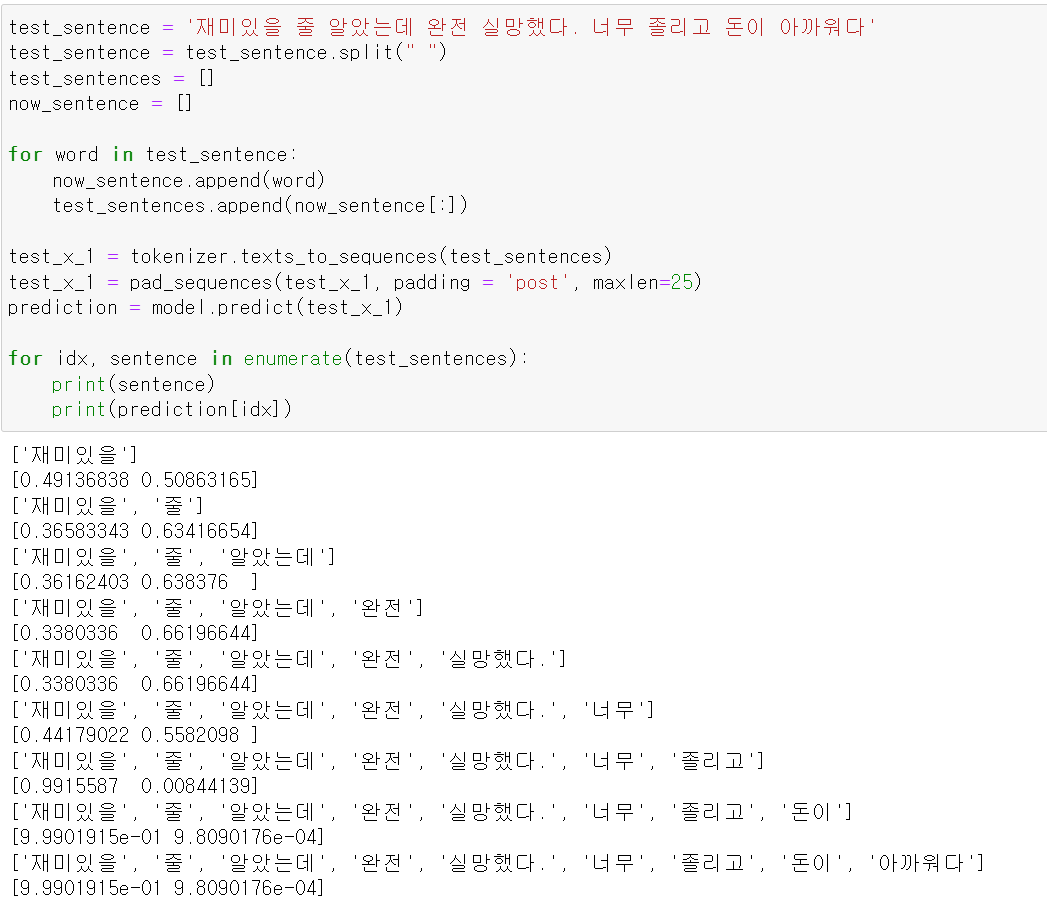
- 단계적으로 분석해보니 재미, 완전 등이 나왔을 때 애매하지만, 뒤로 나와서 졸리다, 실망 등이 나왔을 때 부정적인 문장으로 인식한다.

상황을 바꿀 수 없다면, 나를 바꾸자