
- 이번에는 Training과정을 알아보는데, 그전에 먼저 필요한 데이터 불러오기 class를 불러왔다.
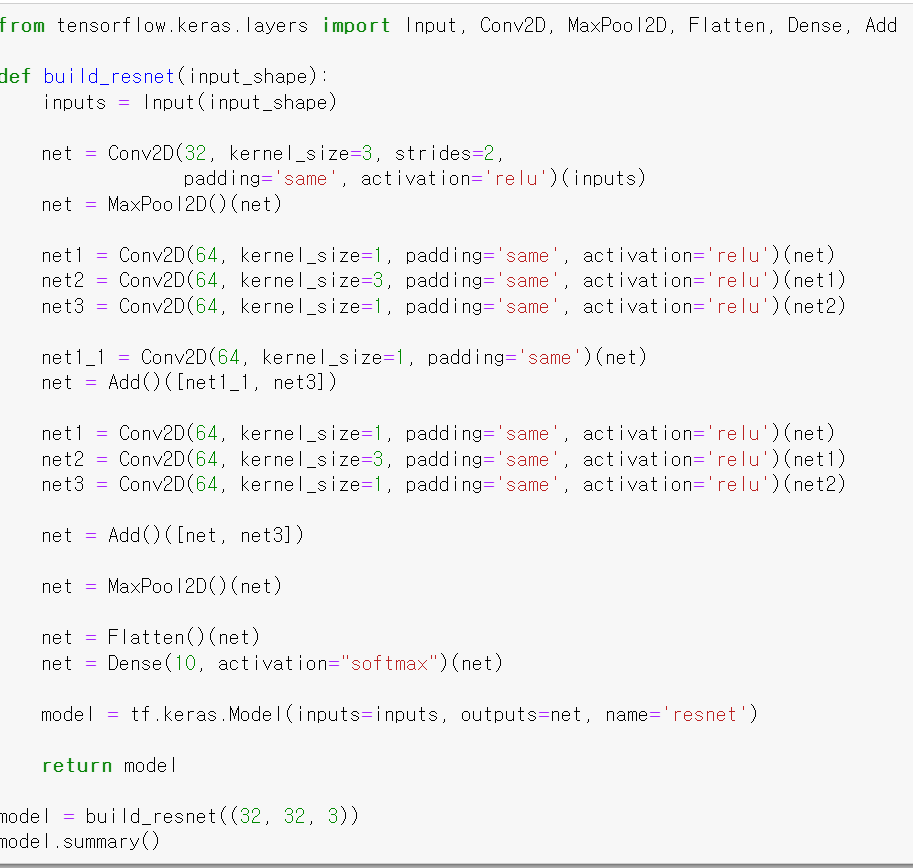
- 그리고 모델 구축 과정을 한 번에 해결할 수 있는 함수를 불러왔다.
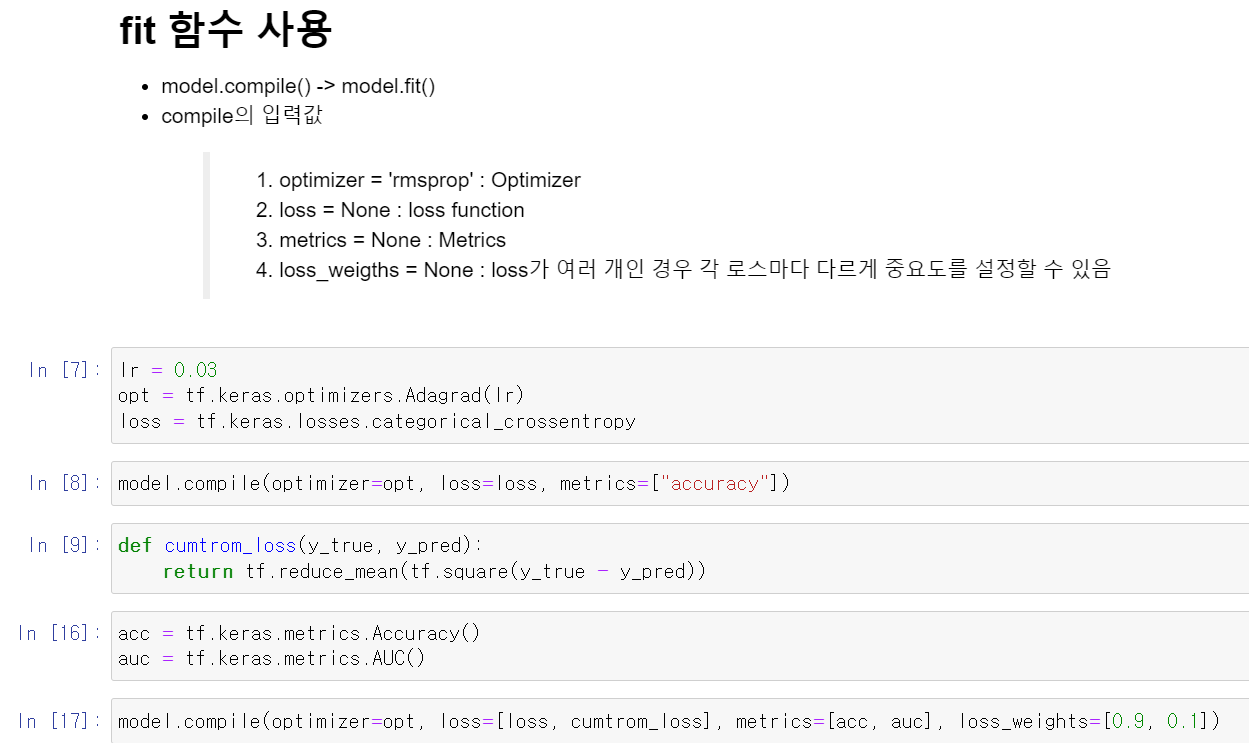
- 모델을 compile할 때 조정하는 대표적인 값들로는 optimizer(최적화), loss(비용 함수), metrics(결과값), loss_weigth(가중치) 등 4개이다.
- 먼저 learning_rate를 0.03으로 주고, 최적화는 Adagrad로 줬다.
- 그 상태로 model에 fit하고,
- 비용 함수를 구하는 함수를 만들었다. 그리고 결과값에 출력할 accuracy와 auc 변수를 만들어서 compile에 위와는 다른 방식으로 저장했다.
- 첫번째 compile처럼 각 값을 넣을 수도 있지만, 두번 째처럼 변수를 만들고 list형태로도 넣을 수 있다.
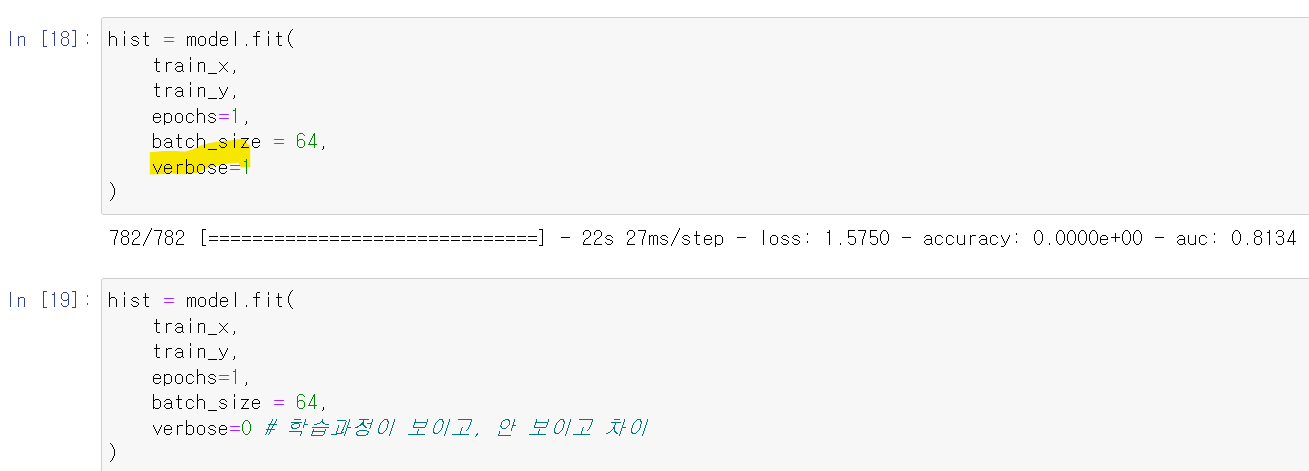
- 그리고 fit 과정에서 verbose는 학습 과정을 출력하지 안 할지 선택하는 기능이 있다.

- callback함수의 경우 함수를 생성해 fit에 넣음으로써 기능을 수행하는데, 학습 과정에서 조건에 따라 학습 조건을 바꿔줄 수 있다.
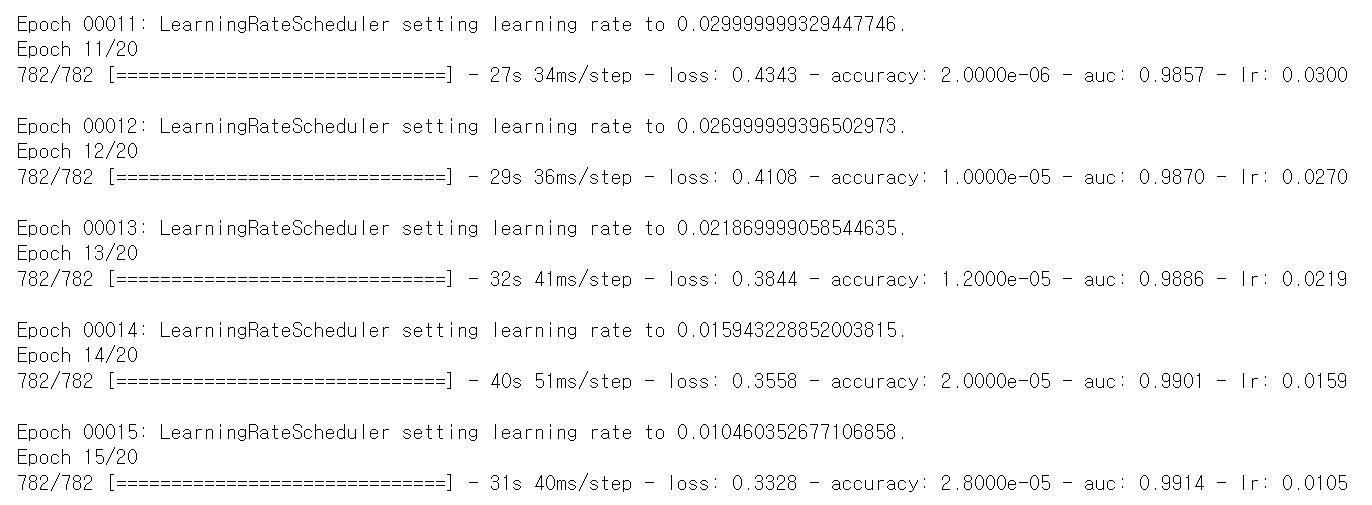
- epoch가 11에서부터 learning rate가 점점 떨어지면서 학습 과정에서 learning_rate의 조건을 바꿨다.

- fit 과정에서 자주 사용하는 입력값들이다.
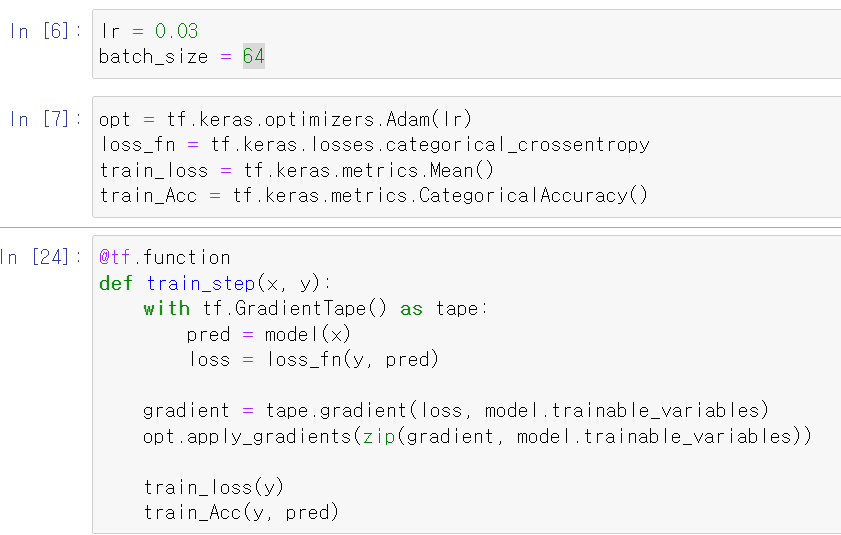
- 이제 위 학습과정을 한 번 직접해보자
- 저번에 한 GradientTape를 이용해 최적화 과정을 수행하면서 과정을 수행할 수 있다.
- model에 x값을 넣어 예측값을 구하고 실제값과 예측값의 비용 함수를 구한다.
- 비용 함수에 대한 각 변수의 값에 대한 편미분을 진행해 편미분 값을 구한 후 편미분한 값을 바탕으로 기존의 변수를 최적화시킨다.
- 그리고 결과값과 예측값을 비교하면 된다.
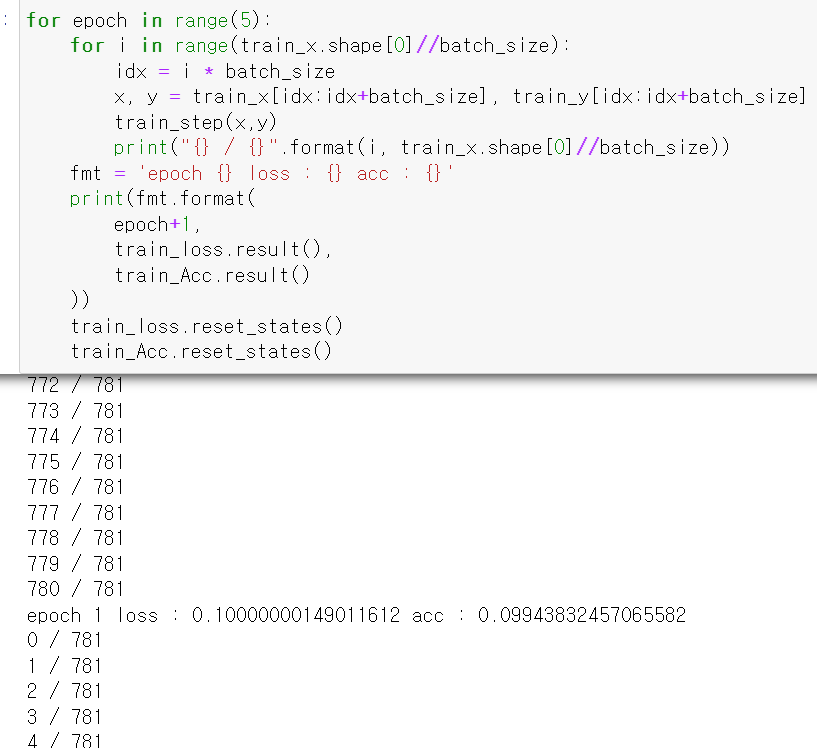
- 위 과정을 for반복문을 통해 epoch를 설정해서 돌려주면 된다.
- batch_size를 설정하기 위해 이중 for문을 사용하고, i:i+batch_size만큼 이동하면서 교육을 진행한다.

상황을 바꿀 수 없다면, 나를 바꾸자