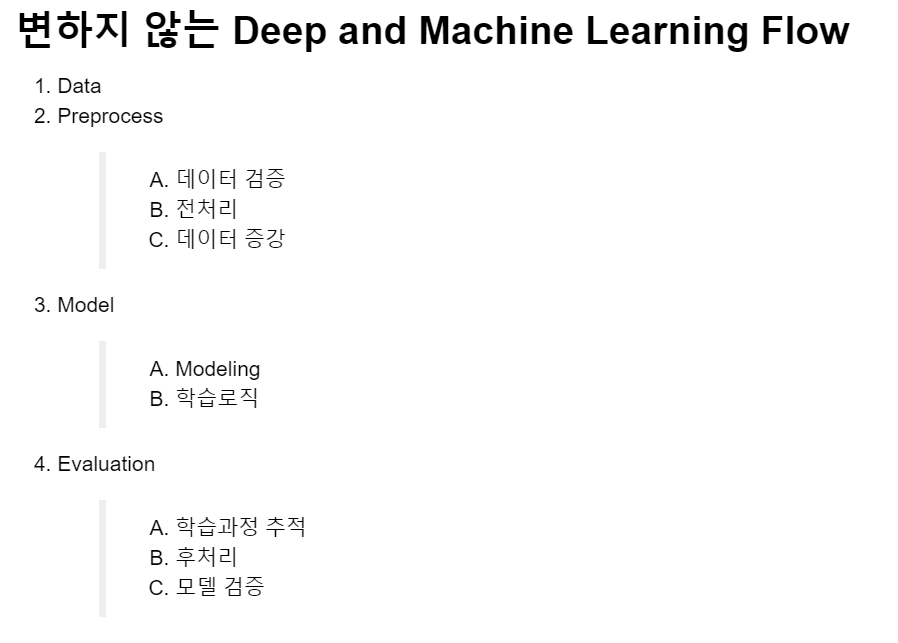
- tensorflow에서 딥러닝을 통해 학습시키기 위해서는 위 4가지 단계를 통해 진행이 필요하다
- Data : 분석 및 모델에 사용할 데이터를 불러온다.
- Preprocess
ㄱ. 데이터 검증 : 불러온 데이터의 결측값 등의 유무 파악
ㄴ. 전처리 : Scale, 단위 등을 조정
ㄷ. 데이터의 양을 증가 및 감소 - Model : 딥러닝을 학습시키기 위한 모델을 구축
- Evaluation : 학습 과정을 추척하며, 모델의 성능을 검증
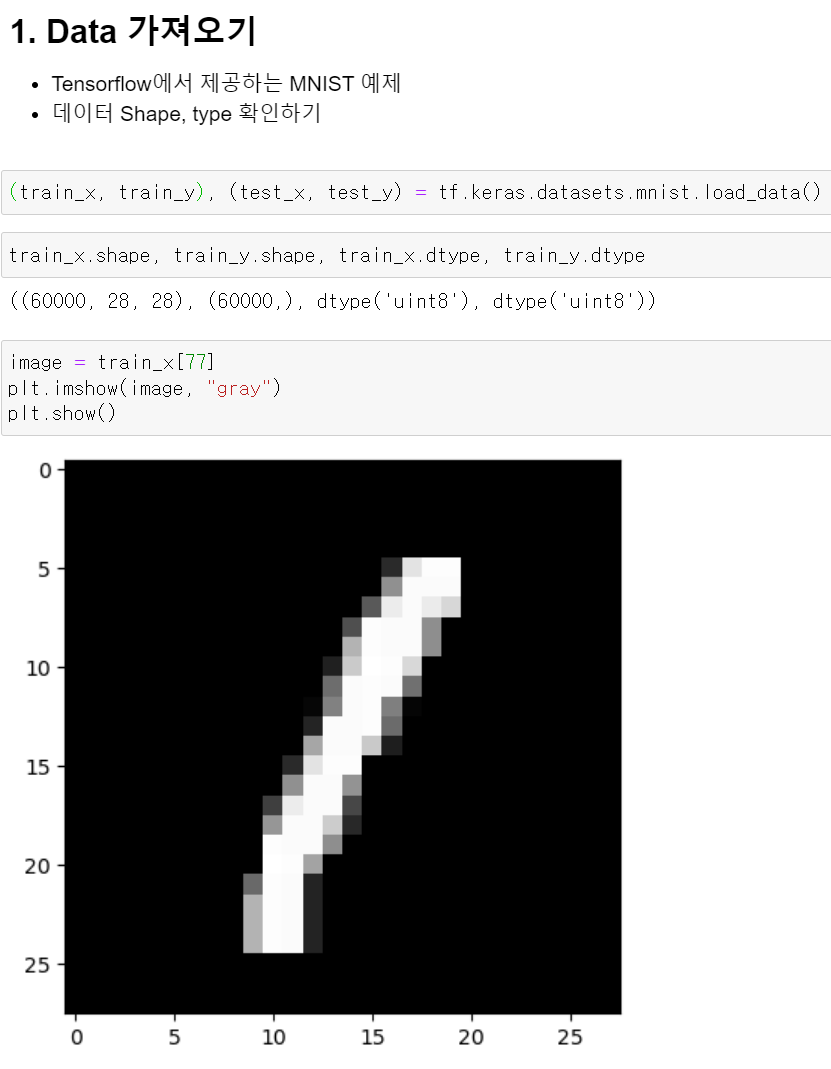
- 일단 가장 먼저 기본적인 tensorflow에서 제공하는 MNIST데이터를 불러온다
- train데이트의 shape를 확인해보니 정상적으로 나왔다.
- 그리고 임의의 하나의 데이터를 뽑아서 matplotlib를 통해 확인해보니 1인 것 같은 데이터가 나왔다.
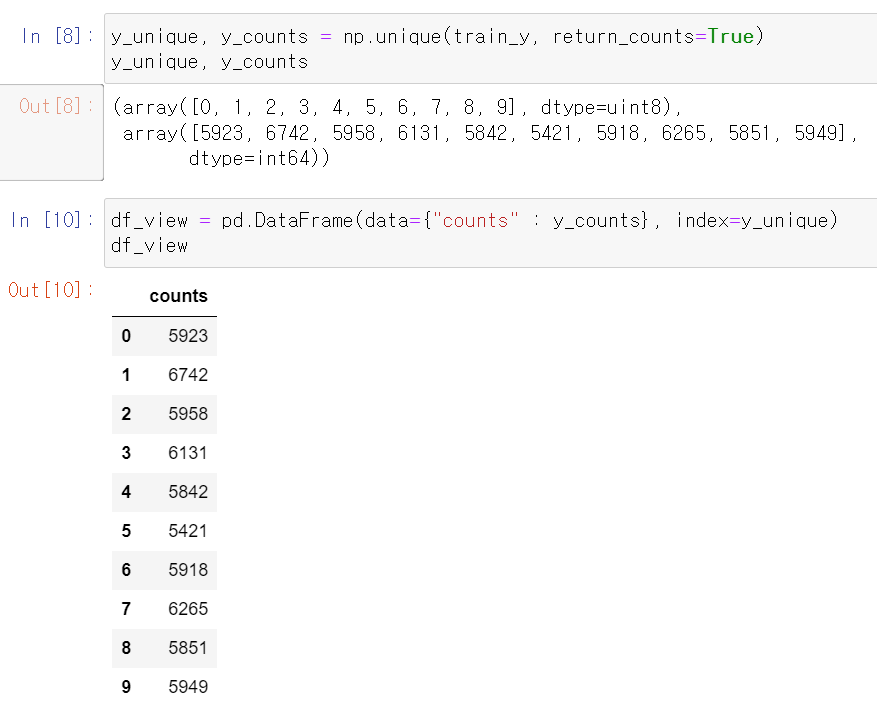
- 이제 Label값의 고유값과 각 고유값의 count를 확인해봤다.
- 프레임 형태로 확인해보니 각 고유값의 큰 차이가 있는 것 같지는 않다.
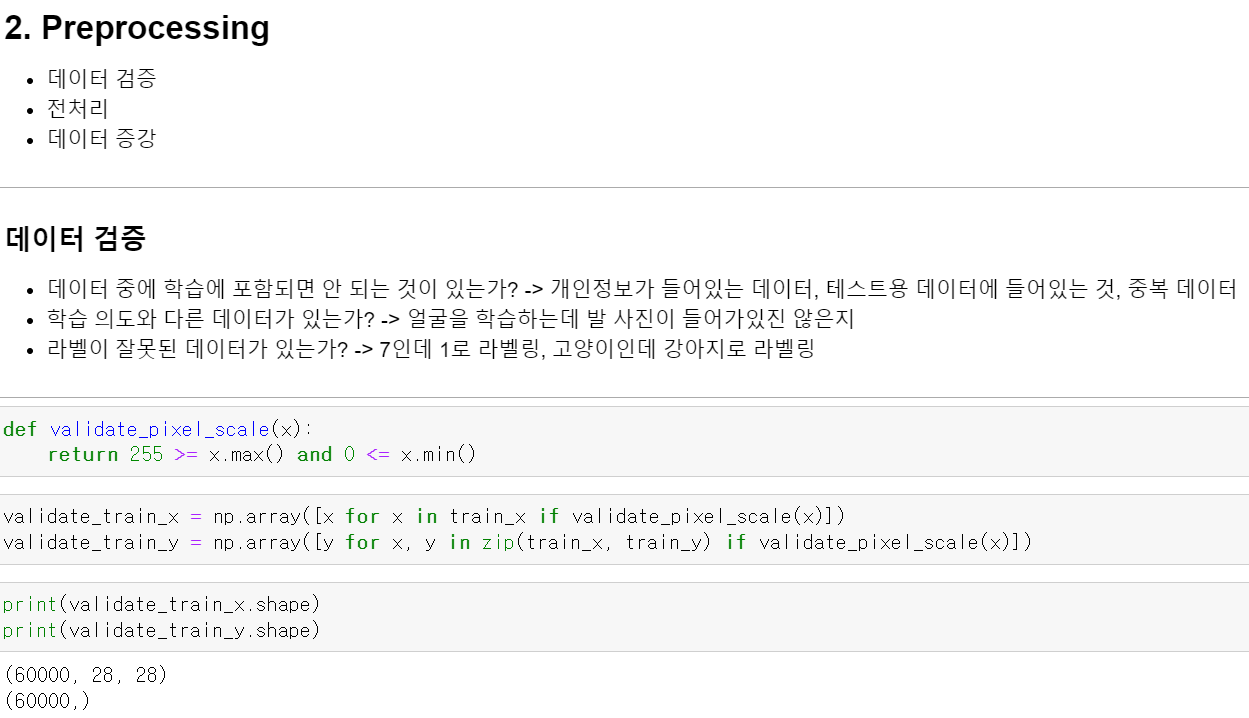
- 이제 해당 데이터의 전처리 과정을 진행했다.
- 픽셀값의 이상치를 확인하기 위해 0~255사이에 있는지 x와 y에 함수를 돌려줘서 shape를 확인해본 결과 다 정상적으로 출력됐다.
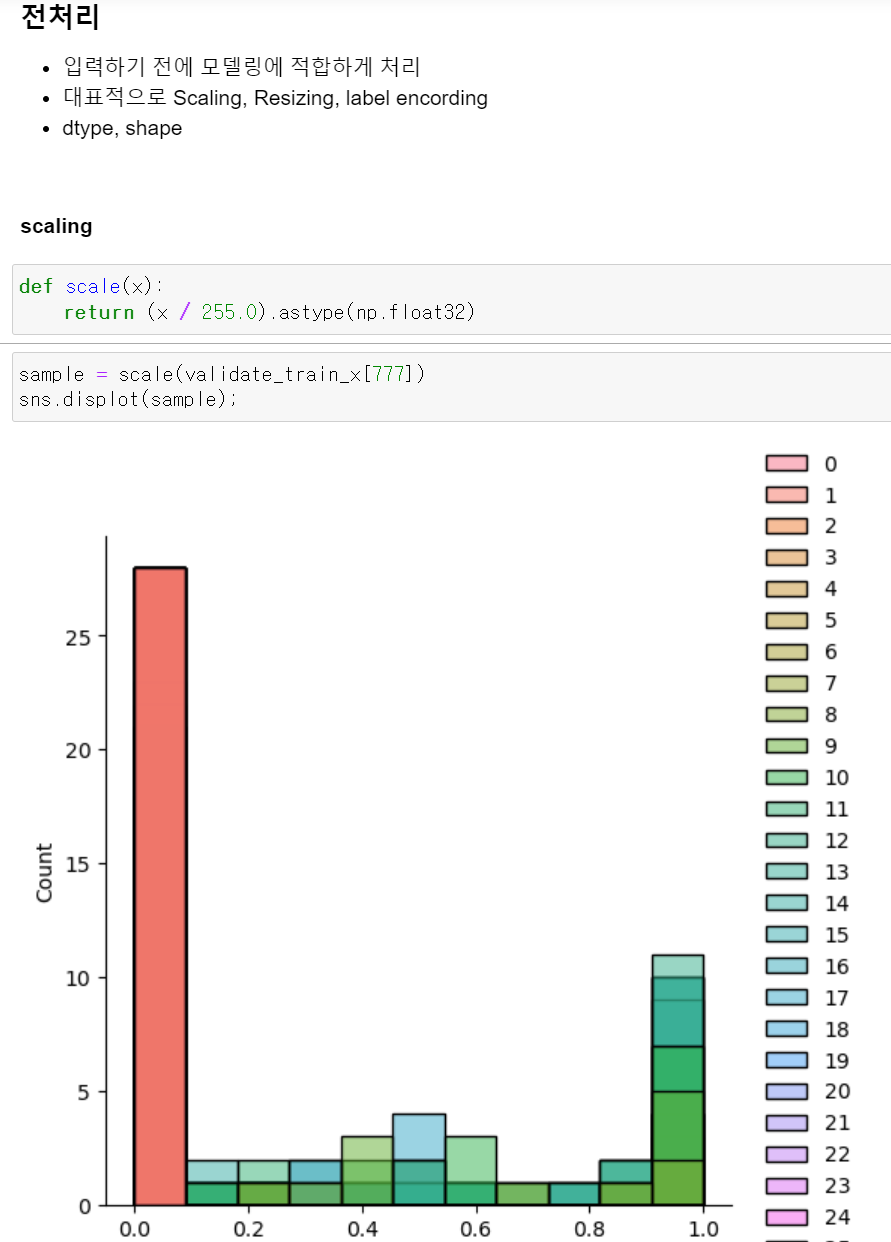
- 이제 스케일의 max값 255를 나눠서 0~1사이에 값으로 변환했다.
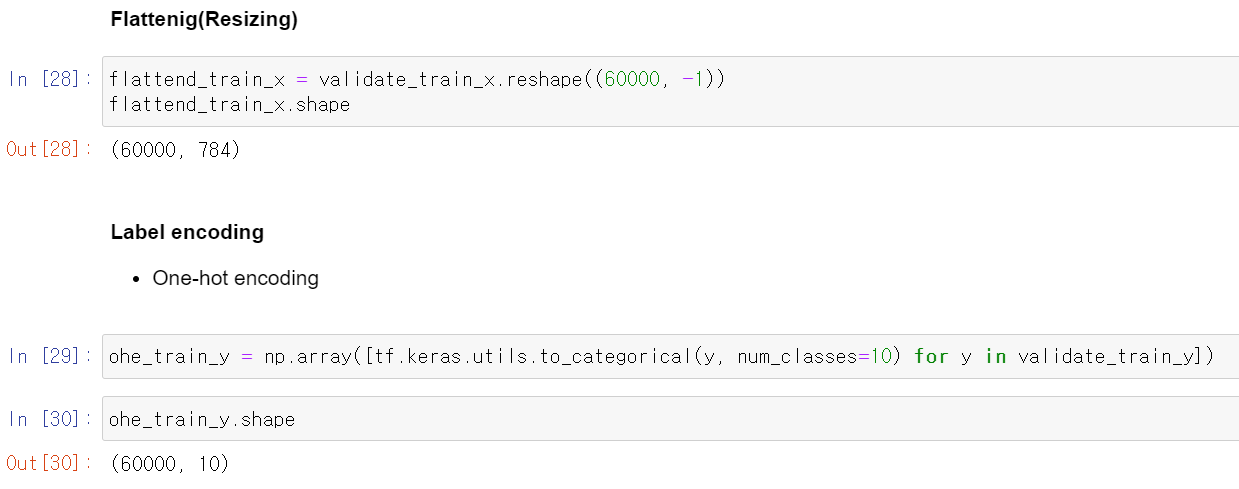
- 그리고 형태의 데이터 픽셀을 하나의 열로 변환하고,
- 10개의 Label값을 One_hot_encorder로 만들어줬다.

- 위 과정을 하나의 class로 만들어 간편하게 작업을 수행할 수 있도록 했다.
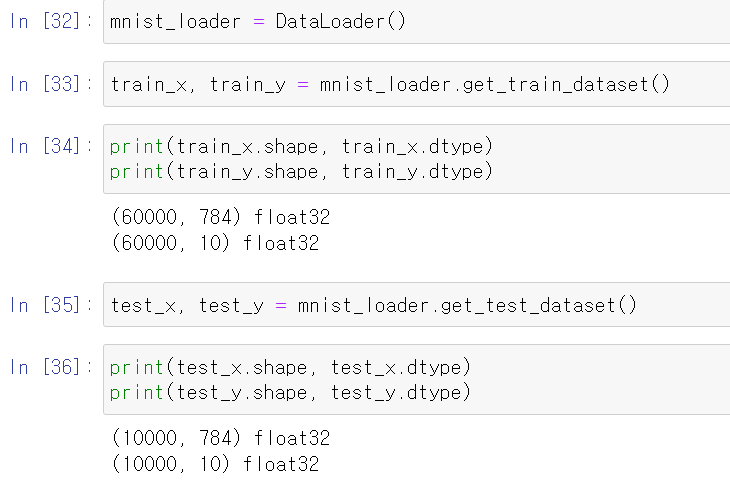
- 클래스로 불러온 데이터를 shape로 확인 결과 정상적으로 나왔다.
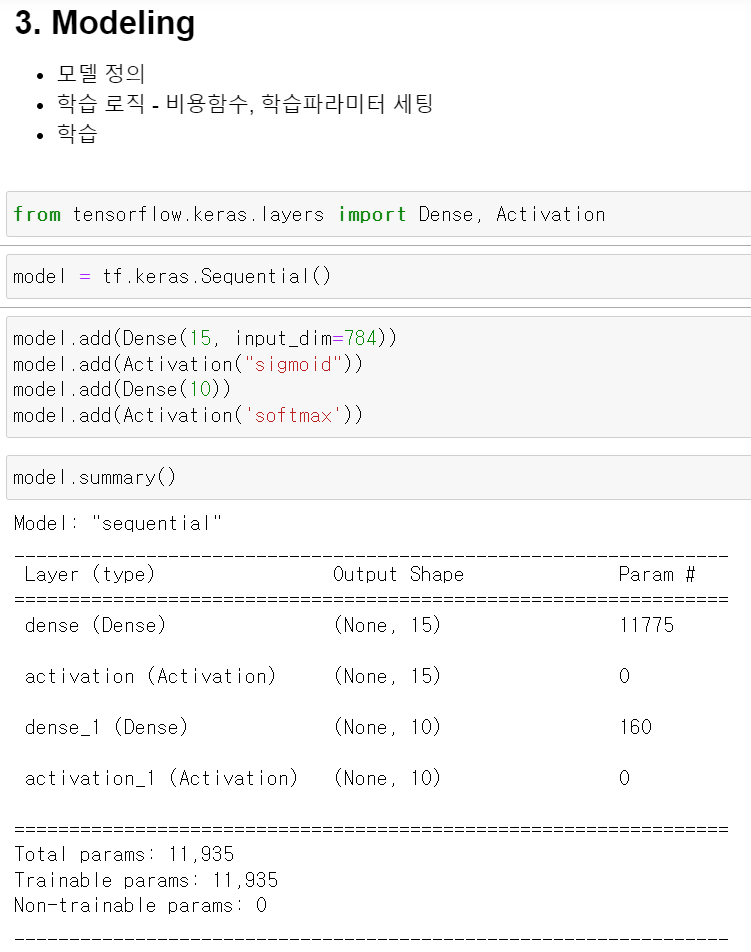
- 이제 불러온 데이터를 교육시키기 위한 모델링을 구축해야한다.
- 모델 구축 중 Sequential이 가장 간단하지만, 조정의 폭이 좁다.
- model.add를 통해 모델링을 구축하고
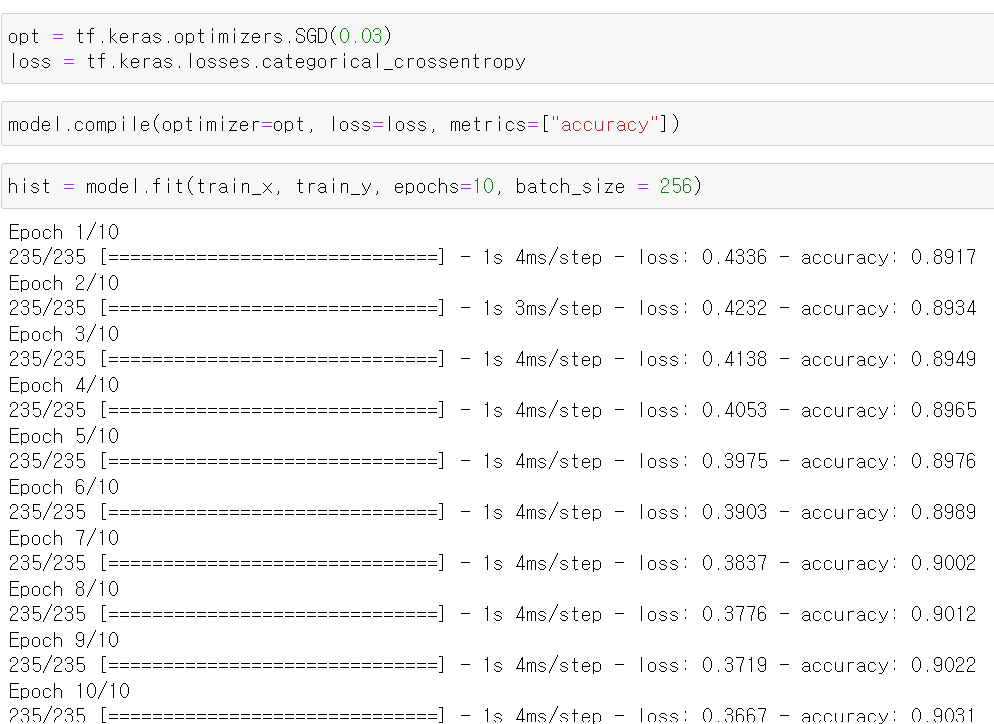
- 최적화는 SGD에 learning rate0.03을 주고 loss값은 categorical 계열로 줬다.
- 이제 model의 학습과정을 compile하고 model을 fit해서 교육시키면 되는데, 반환값을 hist에 먼저 담아뒀다.
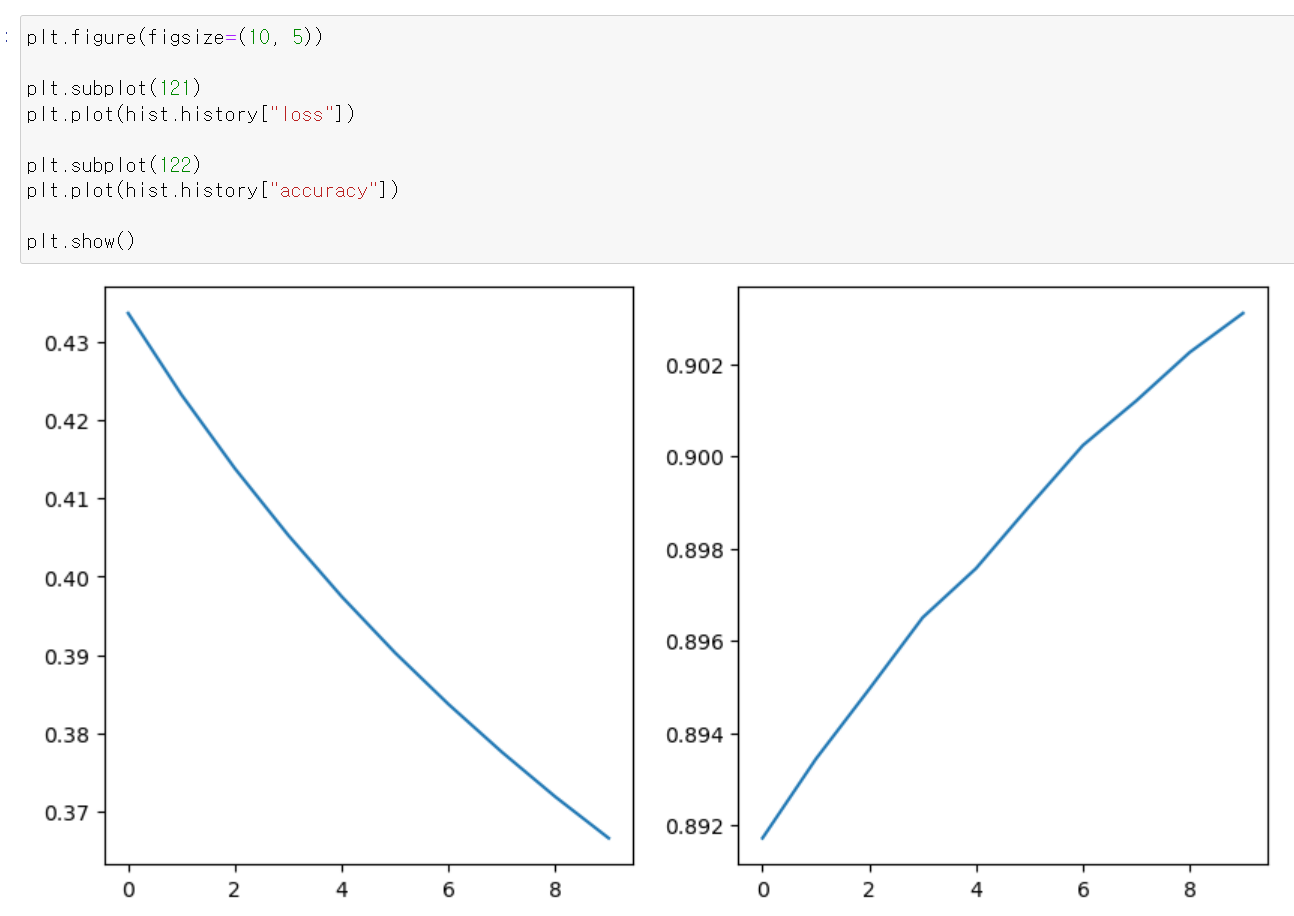
- fit의 반환값은 학습과정에서 나온 결과로 출력하기 때문에 시각화로 학습 과정에서 성능의 개선을 볼 수 있다.
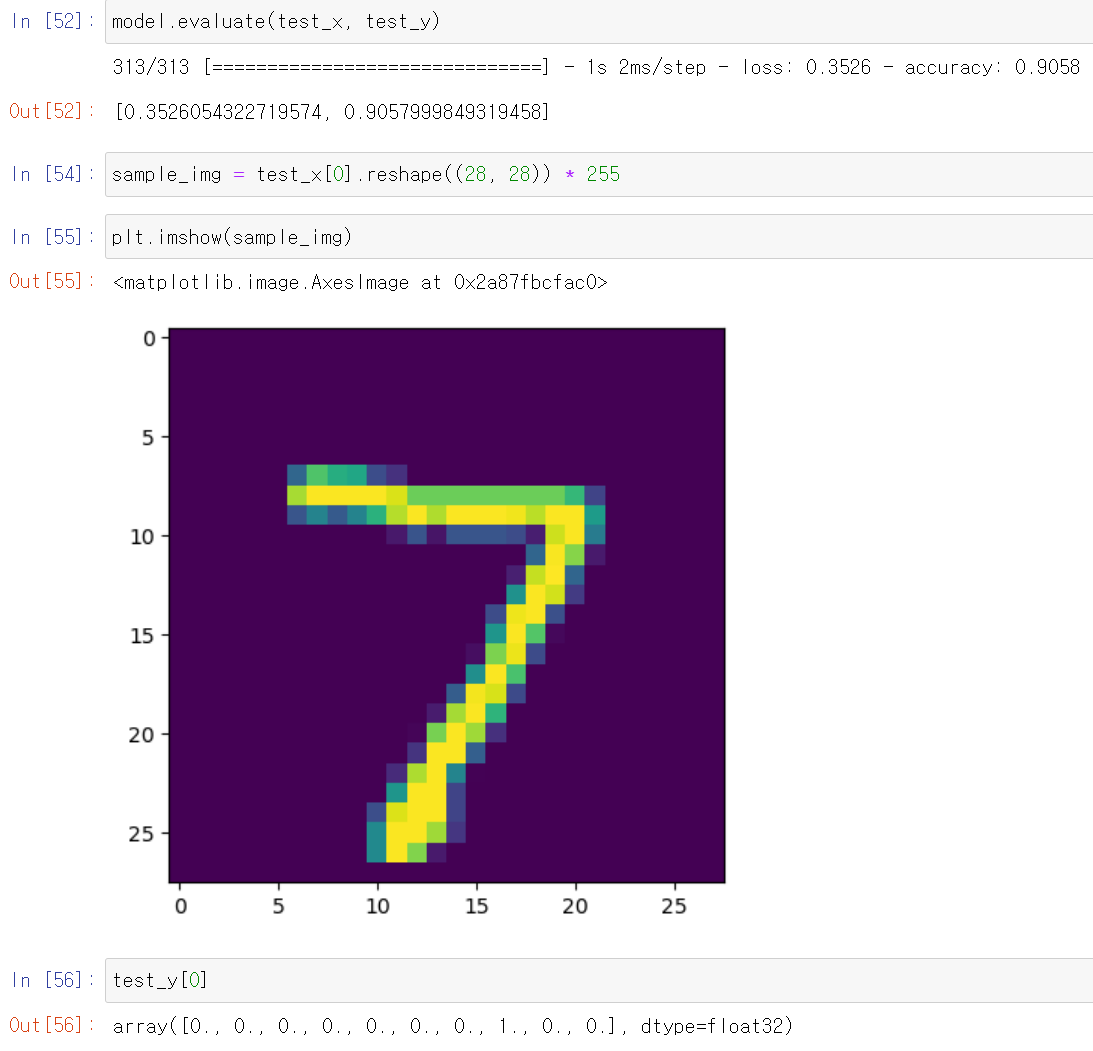
- 이제 학습한 모델의 성능을 보기 위해서 test해본 결과 7이라는 숫자에 one_hot_encorder 7 결과값이 나왔다.

상황을 바꿀 수 없다면, 나를 바꾸자