Optuna
Optuna는 TPE(Tree-structured Parzen Estimator) 알고리즘을 적용하여 이전의 평가 결과를 기반으로 하이퍼파라미터의 새로운 조합을 제안하는 효율적인 하이퍼파라미터 최적화 프레임워크
- 기존의 랜덤 또는 격자(grid) 검색 방법보다 효율적으로 탐색 공간을 탐색
- 모델의 성능을 가장 잘 향상시킬 것으로 예상되는 하이퍼파라미터 조합에 더 많은 자원을 할당
- Optuna는 이러한 과정을 자동화하는 내부 wrapper class를 지원한다는 점에서 편리
여러 모델 튜닝용 코드
# !pip install optunaimport optuna
import lightgbm as lgb
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from xgboost import XGBClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, recall_score, roc_auc_score
from sklearn.model_selection import train_test_split
def objective(trial):
# 최적화할 모델 목록
classifier_name = trial.suggest_categorical("classifier", ["Random Forest", "XGBoost", "LightGBM"])
# Define hyperparameter search space based on the chosen model
if classifier_name == "Random Forest":
param = {
'n_estimators': trial.suggest_int('n_estimators', 50, 300),
'max_depth': trial.suggest_int('max_depth', 3, 20),
'min_samples_split': trial.suggest_int('min_samples_split', 2, 20),
'min_samples_leaf': trial.suggest_int('min_samples_leaf', 1, 10),
'random_state': 42
}
model = RandomForestClassifier(**param)
elif classifier_name == "XGBoost":
param = {
'objective': 'binary:logistic',
'eval_metric': 'logloss',
'n_estimators': trial.suggest_int('n_estimators', 50, 300),
'learning_rate': trial.suggest_loguniform('learning_rate', 1e-4, 1e-1),
'max_depth': trial.suggest_int('max_depth', 3, 9),
'subsample': trial.suggest_uniform('subsample', 0.4, 1.0),
'colsample_bytree': trial.suggest_uniform('colsample_bytree', 0.4, 1.0),
'random_state': 42,
'use_label_encoder': False
}
model = XGBClassifier(**param)
elif classifier_name == "LightGBM":
param = {
'objective': 'binary',
'metric': 'binary_logloss',
'verbosity': -1,
'boosting_type': 'gbdt',
'num_leaves': trial.suggest_int('num_leaves', 20, 100),
'max_depth': trial.suggest_int('max_depth', 3, 9),
'learning_rate': trial.suggest_loguniform('learning_rate', 1e-4, 1e-1),
'n_estimators': trial.suggest_int('n_estimators', 50, 300),
'min_child_samples': trial.suggest_int('min_child_samples', 5, 100),
'feature_fraction': trial.suggest_uniform('feature_fraction', 0.4, 1.0),
'bagging_fraction': trial.suggest_uniform('bagging_fraction', 0.4, 1.0),
'bagging_freq': trial.suggest_int('bagging_freq', 1, 7),
'reg_alpha': trial.suggest_loguniform('reg_alpha', 1e-8, 10.0),
'reg_lambda': trial.suggest_loguniform('reg_lambda', 1e-8, 10.0),
'random_state': 42
}
model = lgb.LGBMClassifier(**param)
# 다른 모델 추가하고 싶으면 하단에 elif 분기로 추기
# Model training and evaluation
# Optuna는 train-validation을 학습시킨 뒤 각 조합에서 어떻게 결과가 나왔는지, best trial은 무엇인지에 대한 것.
# CrossValidation를 수행하기 위해선 OptunaSearchCV wrapper를 활용할 수 있음
# from optuna.integration import OptunaSearchCV
# 사용자가 직접 지정한 train-validation split
model.fit(X_train, y_train)
y_pred = model.predict(X_valid)
# 1.성능 지표 계산
f1 = f1_score(y_valid, y_pred)
precision = precision_score(y_valid, y_pred)
recall = recall_score(y_valid, y_pred)
roc_auc = roc_auc_score(y_valid, y_pred)
accuracy = accuracy_score(y_valid, y_pred)
# 2. 최종적으로 가장 최적화하고 싶은 것을 return
return accuracy
#return accuracy, roc_auc
study = optuna.create_study(direction='maximize')
# objective 함수 구성에 따라 다르게 study 설정 가능
# study = optuna.create_study(directions=['maximize', 'maximize'])
study.optimize(objective, n_trials=10)
print('Number of finished trials:', len(study.trials))
print('Best trial:', study.best_trial.params)
print('Best accuracy:', study.best_value)- 결과
Number of finished trials: 10
Best trial: {'classifier': 'LightGBM', 'num_leaves': 28, 'max_depth': 5, 'learning_rate': 0.040654569686204275, 'n_estimators': 151, 'min_child_samples': 72, 'feature_fraction': 0.7663710558769723, 'bagging_fraction': 0.5588317156910854, 'bagging_freq': 1, 'reg_alpha': 0.0003681518033200165, 'reg_lambda': 3.7016272682914537}
Best accuracy: 0.8101997896950578# Multi-objective 문제를 푸는 경우 study.best_trials로서 접근가능
study.best_trials[0]# Optuna 시각화
from optuna.visualization import plot_optimization_history, plot_param_importances
# 최적화 과정 시각화
plot_optimization_history(study)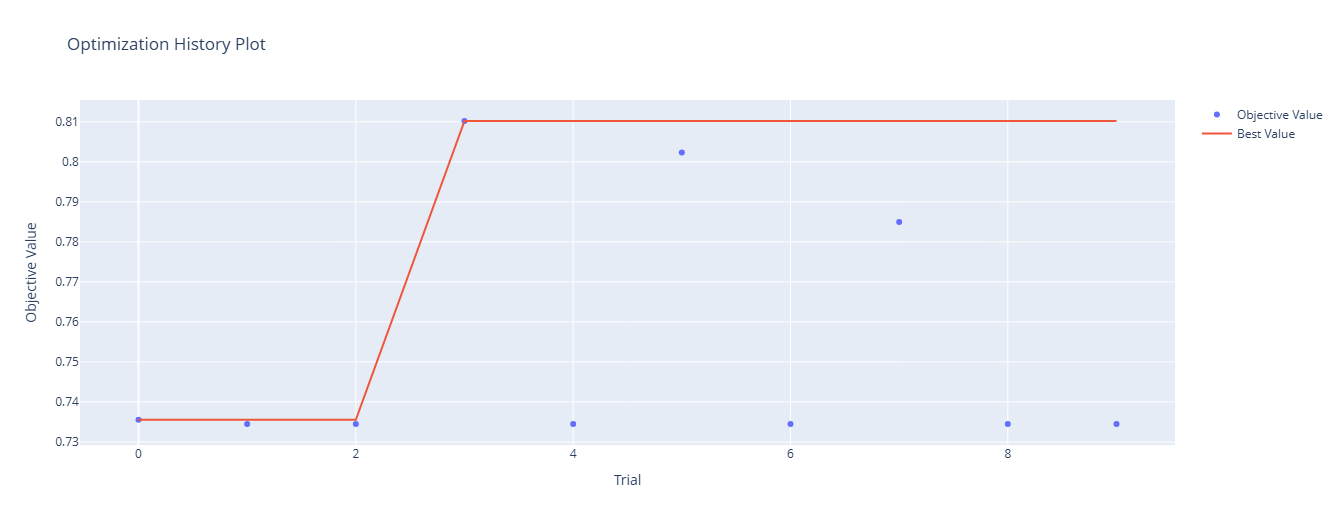
Best param 조합으로 훈련
# 모델 훈련을 위한 est_params 불러오기
best_params = study.best_params
# 가장 좋은 알고리즘은 무엇이었는지
best_model_name = best_params.pop('classifier')
# 훈련 진행
# Add other model initializations here if needed based on best_model_name
if best_model_name == "Random Forest":
best_model = RandomForestClassifier(**best_params, random_state=42)
elif best_model_name == "XGBoost":
best_model = XGBClassifier(**best_params, random_state=42)
elif best_model_name == "LightGBM":
best_model = LGBMClassifier(**best_params, random_state=42)
best_model.fit(X_train, y_train)
# 3) Valid Set 성능 확인
val_preds = best_model.predict(X_valid)
val_accuracy = accuracy_score(y_valid, val_preds)
val_f1 = f1_score(y_valid, val_preds)
val_precision = precision_score(y_valid, val_preds)
val_recall = recall_score(y_valid, val_preds)
val_roc_auc = roc_auc_score(y_valid, val_preds)
print("Final validation accuracy with best model: ", val_accuracy)
print("Final validation f1 with best model: ", val_f1)
print("Final validation precision with best model: ", val_precision)
print("Final validation recall with best model: ", val_recall)
print("Final validation roc_auc with best model: ", val_roc_auc)- 결과
Final validation accuracy with best model: 0.8101997896950578
Final validation f1 with best model: 0.6002214839424141
Final validation precision with best model: 0.6809045226130653
Final validation recall with best model: 0.5366336633663367
Final validation roc_auc with best model: 0.7228622862286229모델 성능 지표 의미 및 해석
-
Accuracy (0.808)
- 의미: 전체 데이터 중 모델이 맞춘 비율
- 장점: 직관적, 전체적인 성능 파악 가능
- 단점: 클래스 불균형에 취약
- 비즈니스 해석: 고객 이탈 예측과 같이 불균형 데이터에서는 단순 참고용. 높은 정확도가 실제로 중요한 고객을 잘 잡는다는 의미는 아님
-
Precision (0.674)
- 의미: 모델이 긍정(예: 이탈)으로 예측한 고객 중 실제로 맞는 비율
- 중요 비즈니스 상황:
- 마케팅/프로모션 비용이 제한적일 때
- 예: 비용이 높은 프로모션은 실제 이탈 가능성이 높은 고객만 선택
-
Recall (0.537)
- 의미: 실제 긍정 고객 중 모델이 잡아낸 비율
- 중요 비즈니스 상황:
- 놓치는 고객이 큰 손실로 이어질 때
- 예: 고객 이탈을 막는 것이 수익에 직결 → 가능한 많은 이탈 고객 포착 필요
-
F1 Score (0.598)
- 의미: Precision과 Recall의 조화 평균 → 불균형 데이터에서 균형 잡힌 성능 평가
-
ROC-AUC (0.72)
- 의미: 전체 클래스 구분 능력, threshold에 상관없이 모델 성능 평가
- 비즈니스 해석: 전체 고객군을 대상으로 모델이 얼마나 잘 이탈/비이탈을 구분하는지 평가.
현재 성능 기반 개선 방향성 탐구
- 제한된 마케팅 자원을 가진 상황 → Precision 우선: 낭비 최소화
- 이탈 고객 수를 최대한 막고 싶다면 → Recall 개선 필요
- F1 Score → Precision/Recall 균형 확인
- ROC-AUC → 전체 모델 신뢰도 평가, threshold 조정 시 성능 최적화 가능
모델 해석
Feature Importance
-
의미: 모델이 예측을 할 때, 각 입력 피처가 결과에 얼마나 영향을 주는지를 보고자하는 지표
-
용도:
- 모델 해석 가능성 확보
- 중요한 피처를 식별하여 데이터 전처리/선별 (e.g. Baseline을 fitting 시키고 -> 피쳐 중요도 TOP10만 사용하는 방식 등을 활용할 수 있음)
if hasattr(best_model, 'coef_'):
feature_importances = pd.Series(best_model.coef_[0], index=X_train.columns)
title = "Feature Importances (Coefficients)"
elif hasattr(best_model, 'feature_importances_'):
# feature importance의 경우 tree 기반 모형에 attribute로 저장됨
feature_importances = pd.Series(best_model.feature_importances_, index=X_train.columns)
title = "Feature Importances"
else:
feature_importances = None
print("Feature importances are not available for this model type.")
if feature_importances is not None:
# Sort importances and select top N (e.g., top 20)
top_n = 20
top_feature_importances = feature_importances.nlargest(top_n)
plt.figure(figsize=(10, 6))
top_feature_importances.plot(kind='barh')
plt.title(title)
plt.xlabel("Importance")
plt.ylabel("Feature")
plt.gca().invert_yaxis() # Display most important at the top
plt.show()SHAP
- 의미: 게임 이론 기반으로 각 피처가 예측값에 기여한 정도를 정량화
- 특징:
- 전역(Global) 해석: 전체 모델에서 피처 영향 확인
- 국소(Local) 해석: 특정 샘플 예측에 대한 피처 기여 확인
- 하위 플롯 종류:
- Summary Plot
- 모든 피처의 영향도와 분포 시각화
- 색상: 피처 값 크기 (high/low)
- Dependence Plot
- 특정 피처 값 변화에 따른 SHAP 값 변동
- 다른 피처와 상호작용 관계 확인 가능
- Force Plot
- 단일 예측에 대한 피처 기여 시각화
- 예측값이 baseline에서 어떻게 이동했는지 보여줌
- Bar Plot
- 각 피처 평균 절댓값 SHAP 값 기준 중요도 표시
- Summary Plot
import shap
# SHAPExplainer 생성
if isinstance(best_model, (XGBClassifier, LGBMClassifier, RandomForestClassifier)):
explainer = shap.TreeExplainer(best_model)
elif isinstance(best_model, LogisticRegression):
explainer = shap.LinearExplainer(best_model, X_train)
shap_values = explainer.shap_values(X_valid)
print("SHAP values calculated.")
print("Shape of shap_values:", [s.shape for s in shap_values] if isinstance(shap_values, list) else shap_values.shape)- 결과
SHAP values calculated.
Shape of shap_values: (1902, 7094)# SHAP summary plot 시각화
if isinstance(best_model, (XGBClassifier, LGBMClassifier, RandomForestClassifier)):
# TreeExplainer의 경우 shap_values는 리스트 형태 (클래스별)
# 보통 이진 분류에서는 클래스 1에 대한 SHAP 값 사용함
if isinstance(shap_values, list):
shap.summary_plot(shap_values[1], X_valid, feature_names=X_valid.columns)
else:
shap.summary_plot(shap_values, X_valid, feature_names=X_valid.columns)
elif isinstance(best_model, LogisticRegression):
if isinstance(shap_values, list):
shap.summary_plot(shap_values[1], X_valid, feature_names=X_valid.columns)
else:
shap.summary_plot(shap_values, X_valid, feature_names=X_valid.columns)
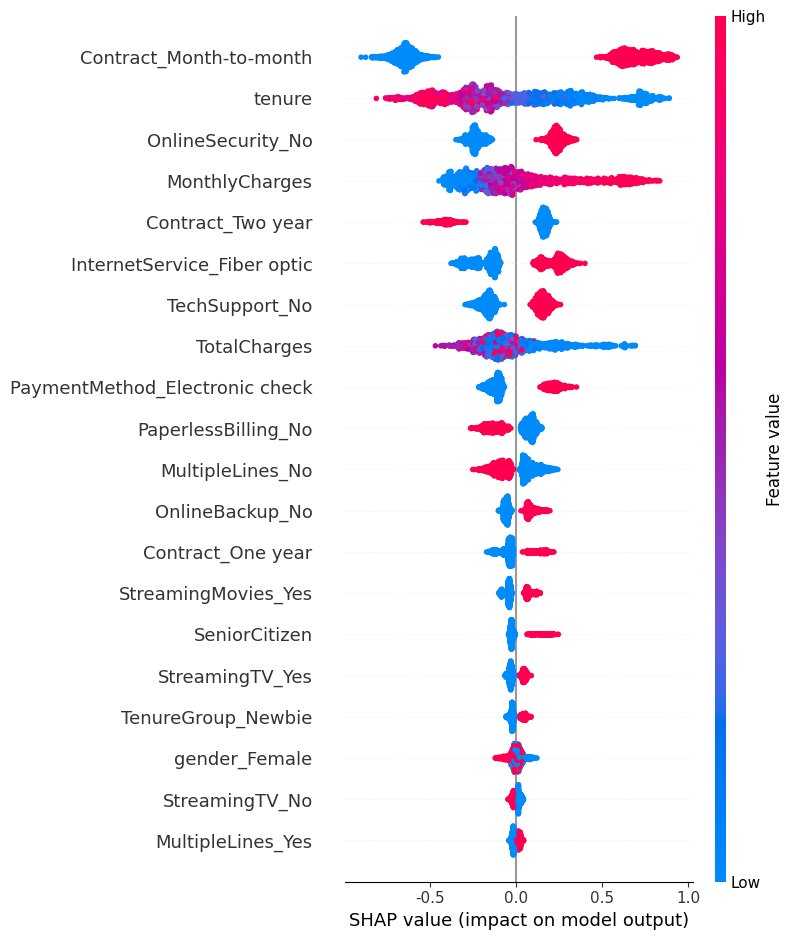
SHAP Summary Plot 해석 방법
- 각 점: 실제 데이터 포인트
-
X축 (SHAP value)
- 피처가 예측 결과에 미치는 영향의 크기와 방향
- 양수(+): 예측을 1(positive) 방향으로 밀어줌
- 음수(−): 예측을 0(negative) 방향으로 밀어줌
-
Y축 (Feature)
- 피처 이름
- 위쪽에 있을수록 모델 전체에서 영향력이 큰 피처
-
점 색상 (Feature 값 크기)
- 빨강(High): 피처 값이 큼
- 파랑(Low): 피처 값이 작음
모델 피쳐 해석
-
가장 영향력 큰 피처:
Contract_Month-to-month: 값이 높을수록(빨간 점) 이탈 가능성을 높임 (SHAP 양수 방향)tenure: 값이 높을수록(빨간 점) SHAP 음수 방향 → 장기 고객일수록 이탈 가능성 낮음MonthlyCharges: 값이 높을수록(빨간 점) 이탈 가능성 증가OnlineSecurity_No,TechSupport_No: 서비스 부재(1)일수록 이탈 가능성 증가
-
인사이트 도출:
- Contract 타입: Month-to-month 계약 고객은 이탈 가능성이 높고, 2년 계약은 낮음
- 서비스 관련 피처: 온라인 보안/기술 지원 없으면 이탈 확률 상승
- tenure(가입 기간): 오래 가입할수록 이탈 가능성 낮음
- 요금 관련(MonthlyCharges): 요금이 높으면 이탈 확률 상승
-
비즈니스 인사이트:
- 단기 계약 고객, 고요금, 서비스 미가입 고객에게 맞춤형 유지 전략 필요
tenure와 결합하면 장기 고객 유지를 위한 보상 정책 설계 가능

Analyse the world