Anaysis
1.데이터 시각화
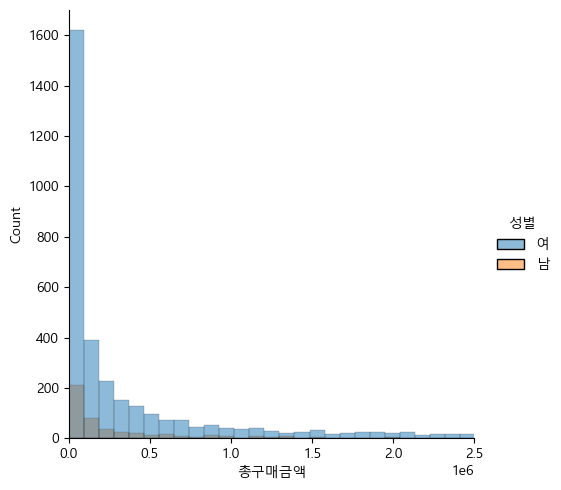
kde(확률밀도함수) -> 연속형 함수(line)로기준 컬럼별 결과를 따로 보고싶다면 col 값 지정연속형변수(숫자범위)에만 적용상자 시작지점 (40) : 25%상자 끝나는 지점 (60) : 75%수염 : (상자 끝나는 지점 - 상자 시작지점) \* 1.5수염 바깥의
2.날짜 데이터 처리

dt.round('단위')기존의 초 단위 값을 '30분 단위'로 반올림하여 병합"연-월-일 시:분:초"까지 표시 (뒷부분은 다 자름)기존의 날짜값을 30분 단위로 바꿈 사용 가능한 단위H : 시간min : 분s : 초L : 밀리초단, 이상치를 가져와서 병합한 경우 데이
3.파일 처리
df1, df2을 concat (행 기준으로 이어붙임) -> 컬럼이 같은 것끼리 아래로 붙여짐열 기준으로 붙일 때에는, (..., axis=1) -> 옆으로 붙여짐ignore_index : 병합되면서 인덱스가 틀어지는 것 방지기존 : 1,2,3,4, ... , 1,2,
4.정규표현식 (Regular Expression)
search / find일치하는 한 구간만 추출findall일치하는 모든 구간을 추출긍정형 전방 탐색\\d : 정수: 0번 이상 등장. : 임의의 문자 하나. : '.' 문자()? : () 패턴이 등장할 수도 있고 아닐 수도 있음(?=L) : L(단위)로 끝나는 경우,
5.확증적 데이터 분석 (CDA)
분포 확인/검정 등데이터 간 연관성 상관성 유사성 등을 가설로 수립하여 객관적인 수치로 검증통계적 가설 검정 기법을 이용해 검정을 실시통계적 가설 검정은 확률 분포를 기반으로 실시확률 분포 : 확률 변수가 어떤 값들을 가질 수 있는지, 그리고 각각의 값이 얼마나 자주
6.결측치 처리

각 컬럼별 결측값 확인제거 : 존재하는 모든 결측값을 없앰대치 : 다른 값으로 결측값 대체()안에 대체할 값 지정 : 0, 평균, min, max ... 모두 가능ffill() : 전방대치bfill() : 후방대치보간법 (time series 시계열)선형보간법을 통해
7.RFM 분석
R : RecencyF : FrequencyM : Monetary최근성 / 빈도 / 금액을 기준으로 고객을 분류얼마나 최근에 주문했는가즉 일수가 작을 수록 좋음 (최근에 주문했다는 뜻이므로, 애용하는 고객)'가장 최근의 주문일자(기준일) - 개별 주문일자'얼마나 많이
8.예측적 데이터 분석 (PDA)

목표변수와 설명변수 간의 관계를 수식화하여, (modeling) 새로 등장할 데이터를 예측하거나 대응전통 통계 : 회귀분석 (모집단 추정)데이터 마이닝 : 모집단 추정이라는 개념을 사용하지 않는다 / 학습 검증하는 단계가 있다전통 통계에서 말하는 회귀분석과 데이터 마이
9.Pyautogui & Pyperclip
화면 상의 어떤 것이라도 제어할 수 있음스크린샷을 찍거나, 마우스를 이동시키고 클릭하거나, 키보드 입력을 자동화할 수 있음이를 통해 데스크탑 애플리케이션 테스팅, 자동화 스크립트 작성 등에 유용파이썬에서 클립보드에 접근하여 텍스트를 복사하고 붙여넣기 할 수 있는 간단한
10.Requests
데이터 크롤링 : 웹사이트에서 자동으로 데이터를 수집하는 과정crawling / scraping \- crawling : 여러 페이지를 자동으로 이동하면서 데이터를 수집 \- scraping : 특정 페이지에서만 데이터를 수집crawling에 사용하는 라이브러리
11.Selenium
12.Crawling & Analysis

크롤링한 데이터를 분석하여 인사이트 도출문제상황vscode 상에서 정상적으로 진행되고, 에러 없이 완료됨그러나, 아무런 결과값도 담겨있지 않음 (내용을 제대로 크롤링하지 못함)원인url = request.get( )으로 이마트몰 접근 시, <Response 429
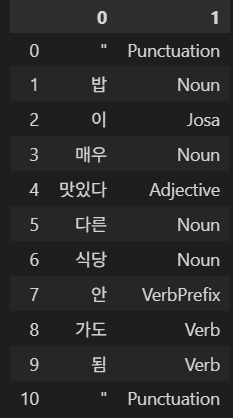
13.Konlpy
.send_keys() : 입력값 전송
14.HTTP Crawling의 작동
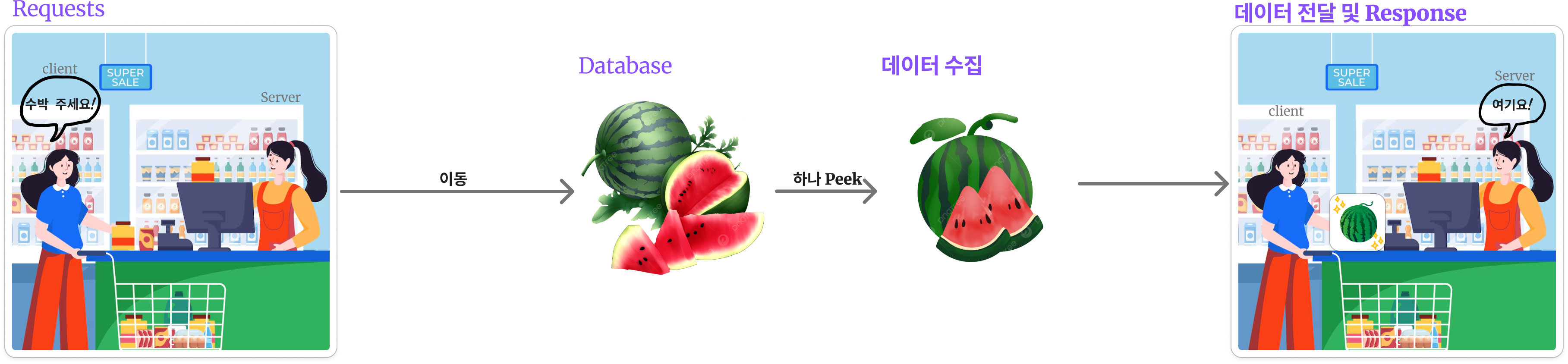
카운터에서 Client가 요청 "수박주세요" : Requests 수박 진열대로 직원이 이동 : 동작 과정 진열대 도착 : Database수박을 Peek : 데이터 수집 카운터로 가져와서 Client에게 전달 : 데이터 전달 Server에서 "여기요"라며 완료됨을 명시
15.Crawling & 자동화 (블로그 작성)
1. 네이버 금융에서 금일 급상승한 주식 종목 크롤링 2. 블로그 포스팅 준비 3. 블로그 자동 포스팅 이미지 내 아이콘을 인식하여 웹 이동 자동화 | 블로그 아이콘 | 글쓰기 버튼 | | ----------- | ---------- | | | | 내용 첨부
16.<Pyautogui.locateOnScreen> Error
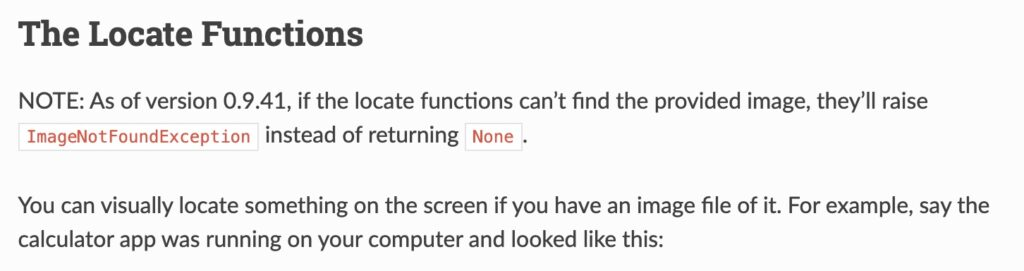
이미지를 인식하여 화면 내 위치를 인식confidence : 제시된 사진을 얼마나 정확하게 인지할 것인가얼마나 정확히 참고할 것인가사진을 인식하지 못하는 에러 발생 (ImageNotFoundException) 해결 시도인식 정확도를 낮추어 예측의 폭을 넓히고자 하였음
17.지도학습 (Supervised Learning)
기계 학습 (Machine Learning) : 컴퓨터가 데이터간의 관계를 학습하여 새로운 수식(model)을 도출하는 작업기계 학습의 핵심 포인트:학습 능력 : 컴퓨터가 얼마나 데이터를 잘 학습하는가?일반화 능력 : 새로운 데이터가 들어왔을 때, 얼마나 잘 예측하는가
18.연속형 데이터 구간 분리 [qcut() & cut()]
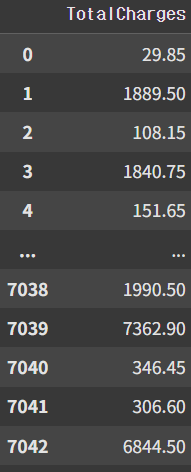
참고자료: soyyeong상대구간(퍼센타일)으로 값을 나눔단일 값: 구간을 몇 개로 나눌 것인지리스트 형태의 다중 값: 해당 값들을 기준으로 구간을 나눔절대구간(특정 값 기준)으로 값을 나눔series: 데이터 매트릭스(df)q or bins : 데이터 구분 기준 (구
19.Kaggle API 연동
20.Hyper Parameter Tuning (with Optuna)
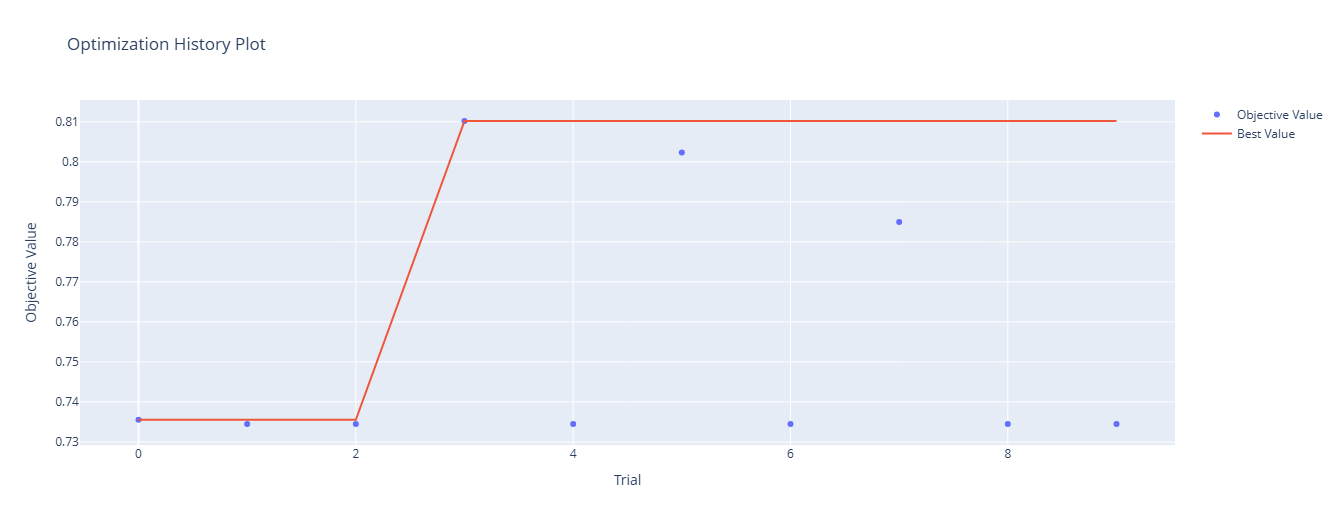
Optuna는 TPE(Tree-structured Parzen Estimator) 알고리즘을 적용하여 이전의 평가 결과를 기반으로 하이퍼파라미터의 새로운 조합을 제안하는 효율적인 하이퍼파라미터 최적화 프레임워크기존의 랜덤 또는 격자(grid) 검색 방법보다 효율적으로
21.Okt 형태소분석기 설치
위의 코드 실행 시 이와 같은 에러가 발생한다면, 실행 환경에서 Java가 설치되어 있지 않거나 경로(JAVA_HOME)가 등록되지 않은 것이 원인Okt 형태소 분석기(Konlpy) 가 내부적으로 Java(JVM)를 사용하기 때문에 설치 필요Java 설치JAVA_HOM
22.다중공선성
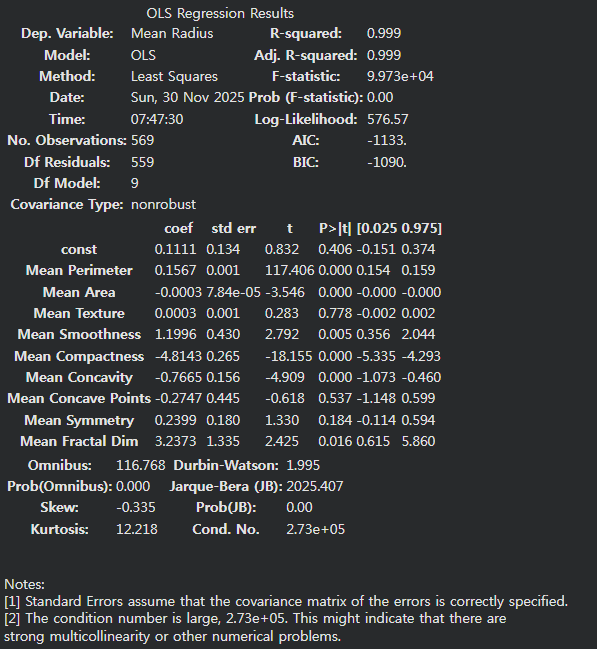
: 회귀 분석에서 독립변수들 사이에 강한 상관관계가 존재하는 문제모델의 회귀계수 추정을 불안정하게 함변수의 해석력을 떨어뜨림상관행렬(상관계수)가 0.8 또는 0.9 이상분산팽창요인(VIF, Variance Inflation Factor)가 10 이상허용오차(Tolera
23.Jupyter Kernel 연결 및 시작 에러 해결
Python 환경 삭제 및 재설치기존 커널 버전(3.11) down grage to 3.10pyzmq 삭제 및 재설치실제로 누군가는 이 패키지 재설치 후 문제가 해결되기도 함즉, 메시징 라이브러리가 꼬이거나(버전 등의 문제로) 통신의 문제로 발생할 경우 이 방법이 효과
24..fit vs .fit_transform
fit( ) vs transform( ) vs fit_transform( )1\. fit( ): "훈련하라"머신러닝이 데이터에 머신러닝 모델을 fit(맞추는) 하는 것학습데이터 세트에서 변환을 위한 기반을 설정하는 함수데이터를 학습시키는 메서드2\. transform(
25.분류모델 성능 평가지표
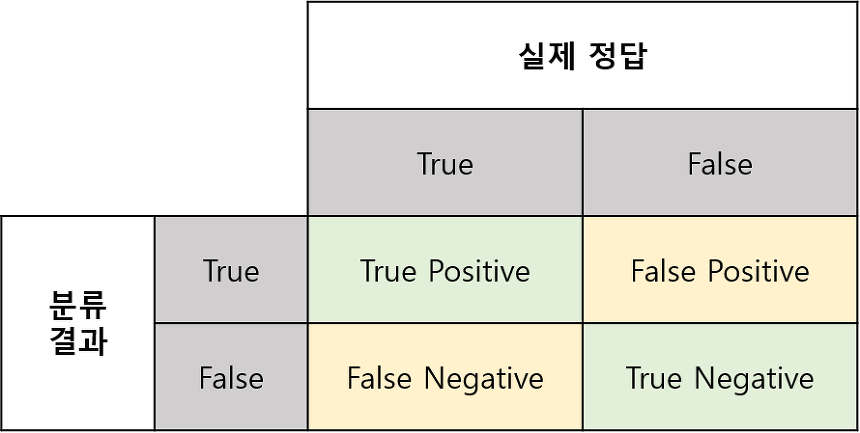
True Positive(TP) : 실제 True인 정답을 True라고 예측 (정답)False Positive(FP) : 실제 False인 정답을 True라고 예측 (오답)False Negative(FN) : 실제 True인 정답을 False라고 예측 (오답)True