데이터프레임 내 자료를 자르는 방법 (Pandas)
참고자료: soyyeong
qcut()
- 상대구간(퍼센타일)으로 값을 나눔
- 단일 값: 구간을 몇 개로 나눌 것인지
- 리스트 형태의 다중 값: 해당 값들을 기준으로 구간을 나눔
- 각 구간의 데이터 개수가 동일하도록 데이터 기준 분리
cut()
- 절대구간(특정 값 기준)으로 값을 나눔
Parameters
def create_bins(series, method='quantile', bins=10, labels=None) :
if method == 'quantile' :
binned = pd.qcut(series, q=bins, labels=labels, duplicates='drop')
# qcut: 상대구간(퍼센타일)으로 값을 나눔
elif method == 'uniform' :
binned = pd.cut(series, bins=bins, labels=labels)
# cut: 절대구간(기준)으로 값을 나눔
else :
raise ValueError("method는 'quentile' 또는 'uniform만 가능합니다.")
return binned- series: 데이터 매트릭스(df)
- method: 연속형 데이터의 구간화 형태 (quantile / uniform)
- q or bins : 데이터 구분 기준 (구간 수 & 특정 값 등)
- labels : 구간 이름 리스트 (default None -> 자동 생성)
- duplicates : qcut(상수값 처리) 시 중복값 처리 방법
| 구간화 종류 | quantile | uniform |
|---|---|---|
| 구간 분리 기준 | 데이터 개수 | 컬럼값의 전체 범위 |
| 사용 함수 | pd.qcut() | pd.cut() |
| 사용 상황 | 데이터 분포가 치우쳐 있고 bin별로 균등한 비교가 필요한 경우 | 값의 범위 자체가 중요할 때 |
구간 분리의 이점
- 데이터 노이즈 감소
- 해석이 단순해짐
- 연속값 자체(count)가 아닌 비율로서 판단하므로, 목표 변수에 대한 영향도를 보다 정확히 측정 가능
구간 분리의 유의점
- 데이터 손실 가능
- 이상치(또는 특정값) 고려 어려울 수 있음
결과값 해석
temp = create_bins(df['TotalCharges'])
print(temp)| 원본 데이터 | qcut 후 데이터 |
|---|---|
 | 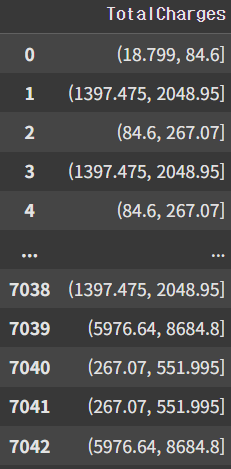 |
- qcut 후 각 데이터의 의미 : 기존 데이터가 어느 구간에 속해있는가
- (a.b] : a이상 b미만

Analyse the world