다중공선성
: 회귀 분석에서 독립변수들 사이에 강한 상관관계가 존재하는 문제
문제점
- 모델의 회귀계수 추정을 불안정하게 함
- 변수의 해석력을 떨어뜨림
판단기준
- 상관행렬(상관계수)가 0.8 또는 0.9 이상
- 분산팽창요인(VIF, Variance Inflation Factor)가 10 이상
- 허용오차(Tolerance)가 0.1 이하
파이썬 코드 예시
- 전통통계 회귀분석 코드
import statsmodels.api as sm
sel_col = [x for x in df1.columns if 'Mean' in x]
X = df1[sel_col]
Y = df1['Mean Radius']
X.drop(columns=['Mean Radius'], inplace=True)
X_const = sm.add_constant(X)
model = sm.OLS(Y, X_const)
res = model.fit()
res.summary()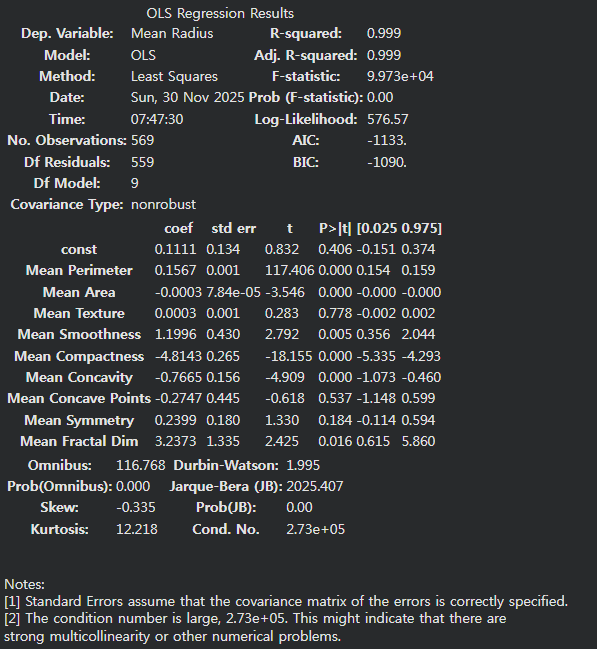
▶ 다중공선성 발생
“The condition number is large, 2.73e+05. This might indicate that there are strong multicollinearity or other numerical problems.”
- 일반적으로
- Cond. No. > 30 → 다중공선성 의심
- Cond. No. > 100 → 문제 심각
- Cond. No. > 1,000 → 매우 심각
- 여기서는 273,000 → 극심한 다중공선성 수준
- 즉, 이 모델은 설명변수들 간에 매우 강한 상관관계가 존재
일관되지 않은 계수(sign flip)
- Mean Compactness: -4.81
- Mean Concavity: -0.77
- Mean Concave Points: -0.27
암 데이터에서는 보통 커질수록 악성 가능성이 높아지고 radius도 커지는 경향인데, 일부 계수가 음수로 튀는 것은 설명변수 간 강한 상관관계로 인한 계수 불안정성을 의미
표준오차가 커짐
- Mean Smoothness std err = 0.43
- Mean Fractal Dimension std err = 1.335
std err가 크면 → t값이 작아져 → 유의성이 떨어짐
VIF 계수 계산
from statsmodels.stats.outliers_influence import variance_inflation_factor
df_VIF = pd.DataFrame()
df_VIF['variable'] = X_const.columns
# VIF 계산
df_VIF['VIF'] = [variance_inflation_factor(X_const.values, i) for i in range(X_const.shape[1])]
df_VIF.sort_values(by = 'VIF', ascending = False)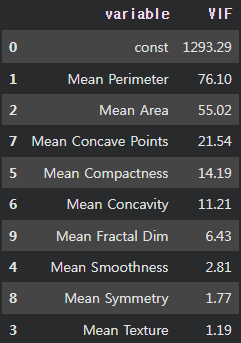
다중공선성 제거 및 모델 개선
# VIF가 10 이하인 변수를 선택
cond1 = df_VIF['VIF'] <= 10
sel_col2 = df_VIF.loc[cond1]['variable'].values
X = df1[sel_col2]
Y = df1['Mean Radius']
X_const = sm.add_constant(X)
model = sm.OLS(Y, X_const)
result = model.fit()
result.summary()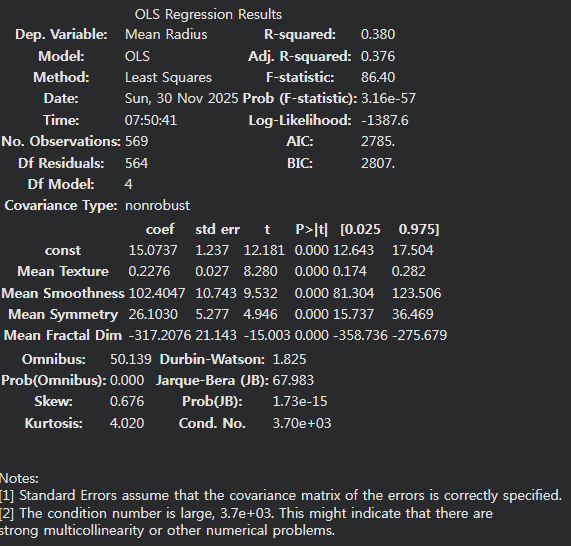

Analyse the world