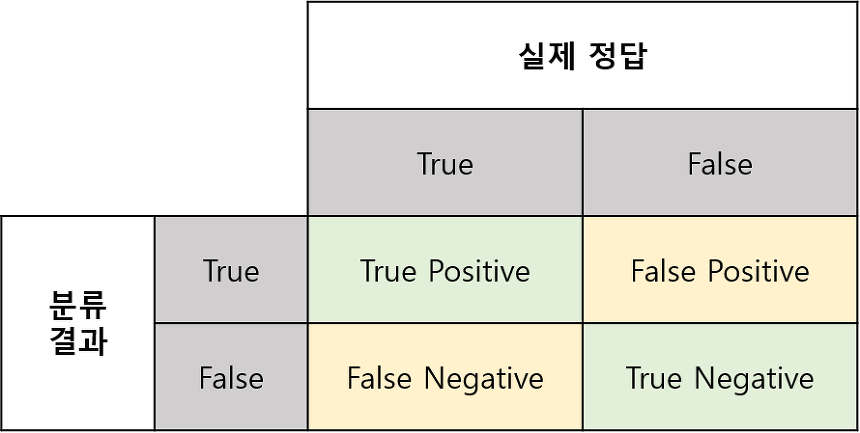
- True Positive(TP) : 실제 True인 정답을 True라고 예측 (정답)
- False Positive(FP) : 실제 False인 정답을 True라고 예측 (오답)
- False Negative(FN) : 실제 True인 정답을 False라고 예측 (오답)
- True Negative(TN) : 실제 False인 정답을 False라고 예측 (정답)
1. Precision (정밀도)
: 모델이 True라고 분류한 것 중에서 실제 True인 것의 비율
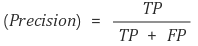
2. Recall (재현율)
: 실제 True인 것 중에서 모델이 True라고 예측한 것의 비율
- Recall의 경우, 확실하지 않은 경우는 아예 예측을 보류하여 FP 경우의 수를 줄이도록 할 수 있음
- 이를 통해 Precision 극대화 가능
- 다만, 이상적으로 신뢰도/정확도가 높은 모델이라고 판단하기는 어려움
- 따라서 Precision도 함께 고려해야 함
* 두 모델 모두 값이 높을수록 좋음
* Precision과 Recall은 상호보완적 관계
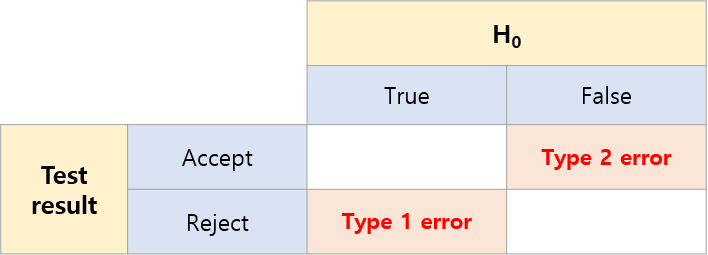
- 1종 오류와 2종 오류는 trade-off 관계

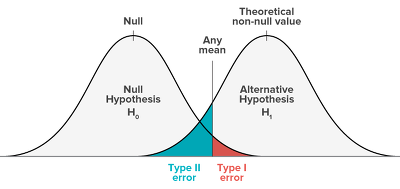
- 1종 오류에서 Any mean을 기준으로 H0 관점에서 빨간색 영역이 기각역
- 이 기각역에 따라 2종 오류도 정해짐
- Any mean을 좌우로 조정함에 따라 1종/2종오류의 크기가 변함
- 1종 오류가 커지면/작아지면 2종 오류가 작아짐/커짐
- 즉, 두 오류는 서로 trade-off의 관계
sion과 Recall은 TP를 분자로써 같이하고 분모에는 TP에 Type 1, 2 error에 해당하는 FN, FP를 더하여 계산한다. 이 때 FN, FP는 각각 Type 1, 2 error에 있으므로 Precision과 Recall 또한 trade-off 관계에 있다고 할 수 있음
3. Accuracy (정확도)
: True를 True라고 예측한 것 + False를 False라고 옳게 예측한 것을 모두 고려하는 지표

- 도메인의 편중(bias)를 고려해야 함
- 확인하려는 도메인의 데이터 자체가 불균형할 경우, 특정 예측값에 대한 정확도 성능이 높을 수밖에 없음
- 이를 보완하기 위해 다른 지표를 함께 확인해야 함
4. F1-Score
: Precision과 Recall의 조화평균
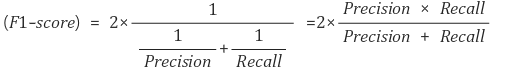
- 데이터 label이 불균형 구조일 때, 모델의 성능을 정확하게 평가할 수 있는 지표
- 성능을 하나의 숫자로 표현
- 조화평균을 사용하여 데이터의 불균형을 보완하고 편중을 줄임
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score추가 지표
1. Fall-out
: FPR(False Positive Rate), 실제 False인 data 중에서 모델이 True라고 예측한 비율
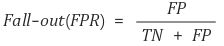
2. ROC(Receiver Operating Characteristic) curve
: 여러 임계값들을 기준으로 Recall-Fallout의 변화를 시각화
- Fallout과 Recall 지표를 기준으로 그래프를 그림
- Fallout은 실제 False인 data 중에서 모델이 True로 분류한 비율
- Recall은 실제 True인 data 중에서 모델이 True로 분류한 비율
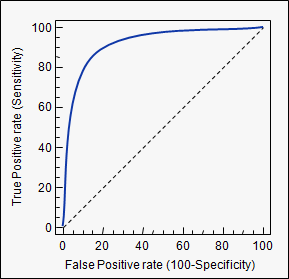
- curve가 왼쪽 위 모서리에 가까울수록 모델의 성능이 좋다고 평가
- 즉, Recall이 크고 Fall-out이 작은 모형이 좋은 모형인 것
- 또한 y=x 그래프보다 상단에 위치해야 어느정도 성능이 있다고 말할 수 있음
3. AUC(Area Under Curve)
: ROC Curve의 그래프 아래 면적값을 이용해 성능을 측정하는 방법
- ROC curve는 그래프이기 때문에 명확한 수치로써 비교하기가 어려움
- 최대값은 1이며 좋은 모델일수록(즉, Fall-out에 비해 Recall 값이 클수록) 1에 가까운 값
참고자료

Analyse the world