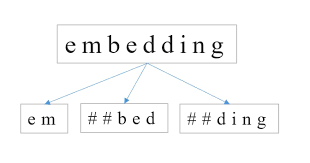
BERT의 논문에 대한 프리뷰이기도 하면서 Byte Pair Embedding에 대한 내용을 정리한 글이다.
해당 내용 역시, 많은 NLP 모델에서 사용되는 SentencePiece, Hugging Face를 이해하기 위한 기초정보라 판단되어 다루고자 한다.
💡 Byte Pair Encoding 왜 등장했을까?
딥러닝 공부를 하고 논문을 읽으며 느꼈던 것은 각각의 모델 혹은 알고리즘은 아무 이유도 없이 출연한 경우는 없다는 것이다. 그리고 이 부분은 사람들이 라이브러리를 점점 더 만들어내는 이유와도 상통한다.
논문의 요약인 Abstract를 제외하면, 가장 먼저 나오는 것은 보통 Background 혹은 Introduction이다. 그리고 그곳에서는 일반적으로 우리의 모델이 혹은 알고리즘이 등장하기 전까지의 고민과 장벽을 얘기한다. 이후 논문은 저자의 모델을 통해 이 부분을 해결하고자 했던 노력과 실험에 대한 것이다.
그렇다면 Byte Pair Encoding은 무엇을 해결하고자 한 모델일까? 단어를 임베딩하는데 큰 문제점은 모든 단어를 token화시키고 학습시킬 수 없다는 것이다. 사람 조차도 모르는 단어가 나오면 찾아보게 되는데 AI는 데이터가 없는 부분에 대한 질문은 매우 취약할 수 밖에 없다.
이러한 상황에서 보통 모델은 OOV(Out-Of-Vocabulary)을 발생시키게 된다. 이를 위해 나타난 서브워드 분리(Subword segmenation) 작업은 하나의 단어는 더 작은 단위의 의미있는 여러 서브워드들(Ex) birthplace = birth + place)의 조합으로 구성된 경우가 많기 때문에, 하나의 단어를 여러 서브워드로 분리해서 단어를 인코딩 및 임베딩하겠다는 의도를 가진 전처리 작업이다.
그리고 여기서 대표적인 것이 BPE인 것이다!
💡 Byte Pair Encoding은 무엇일까?
PE(Byte pair encoding) 알고리즘은 1994년에 제안된 데이터 압축 알고리즘이다. 상당히 오래된 이 알고리즘의 전반적인 흐름은 다음과 같다.
BPE은 기본적으로 연속적으로 가장 많이 등장한 글자의 쌍을 찾아서 하나의 글자로 병합하는 방식을 수행한다.
예를 들어,

위와 같은 단어 set이 있다고 가정하자. BPE는 보통 단어를 쪼갤 수 있는 가장 작은 단위, 영어의 경우 알파벳 단위로 분리하게 된다. 그렇다면 현재의 단어는 아래와 같다.
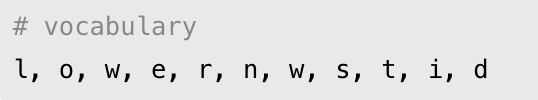
여기서 가장 많이 반복해서 등장하는 쌍을 찾게 된다. 위의 사례에서는 es가 가장 반복해서 등장하므로 이들을 묶고 vocab set에 추가해준다.


이런 식으로 쭉 진행한 후에 위에 없는 예시인 new라는 단어가 등장하게 되면 vocab 데이터에서 찾을 수 있게 된다.

💡 그렇다면 WordPiece Tokenizer란?
WordPiece Tokenizer은 BPE의 변형 알고리즘이다. 해당 알고리즘은 BPE가 빈도수에 기반하여 가장 많이 등장한 쌍을 병합하는 것과는 달리, 병합되었을 때 코퍼스의 우도(Likelihood)를 가장 높이는 쌍을 병합한다.
즉, 가장 먼저 BPE처럼 모든 단어를 나누고 그 후에 가능도에 따라 단어들을 병합시키는 것이다.

Jet는 J와 et로 나누어졌으며, feud는 fe와 ud로 나누어진 것을 확인할 수 있다. WordPiece Tokenizer는 모든 단어의 맨 앞에 _를 붙이고, 단어는 서브 워드(subword)로 통계에 기반하여 띄어쓰기로 분리합니다. 여기서 언더바는 문장 복원을 위한 장치이다.
예컨대, WordPiece Tokenizer의 결과로 나온 문장을 보면, Jet → _J et와 같이 기존에 없던 띄어쓰기가 추가되어 서브 워드(subwords)들을 구분하는 구분자 역할을 하고 있습니다.
그렇다면 여기서 중요한 것은 기존에 있던 띄어쓰기와 구분자 역할의 띄어쓰기를 구별해내는 것이다. 이 역할을 수행하는 것이 단어들 앞에 붙은 언더바 _이다.
WordPiece Tokenizer이 수행된 결과로부터 다시 수행 전의 결과로 돌리는 방법은 현재 있는 모든 띄어쓰기를 전부 제거하고, 언더바를 띄어쓰기로 바꾸면 됩니다.
결과적으로 언더바는 기존의 문장에 있었던 띄어쓰기를 보여주는 장치이다.
🔥 추가적으로 Unigram Language Model Tokenizer란?
유니그램 언어 모델 토크나이저는 각각의 서브워드들에 대해서 손실(loss)을 계산합니다. 여기서 서브 단어의 손실이라는 것은 해당 서브워드가 단어 집합에서 제거되었을 경우, 코퍼스의 우도(Likelihood)가 감소하는 정도를 말합니다. 즉, 이 서브워드가 단어 집합에 얼마나의 가치를 지니는지 평가하는 것이다.
이렇게 측정된 서브워드들을 손실의 정도로 정렬하여, 최악의 영향을 주는 10~20%의 토큰을 제거합니다. 이를 원하는 단어 집합의 크기에 도달할 때까지 반복한다.
