https://openreview.net/pdf?id=tmsqb6WpLz
Main RQ
해당 논문은 아래의 수식에서 출발한다.

topic은 글의 주제(글이 속하는 domain) style은 글의 유형(전체적인 흐름) 그리고 factual은 글에서 나오는 사실들(글의 구성요소들)로 decomposition을 해 글을 표현했다. 이렇다고 가정했을 때, 각 세가지 요소는 학습과정에서 어떠한 차이점을 보이는가에 대한 질문이 근본적인 RQ이다.
Method
위의 수식을 발전시켜 style A와 style B에 대해 모델의 likelihood ratio 계산을 진행한다.
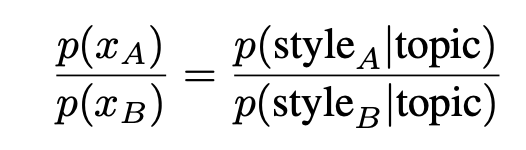
ratio를 조금더 발전시키면 cross entropy loss의 차이를 통해 style에 대한 모델의 preference 혹은 bias를 보일 수 있다.
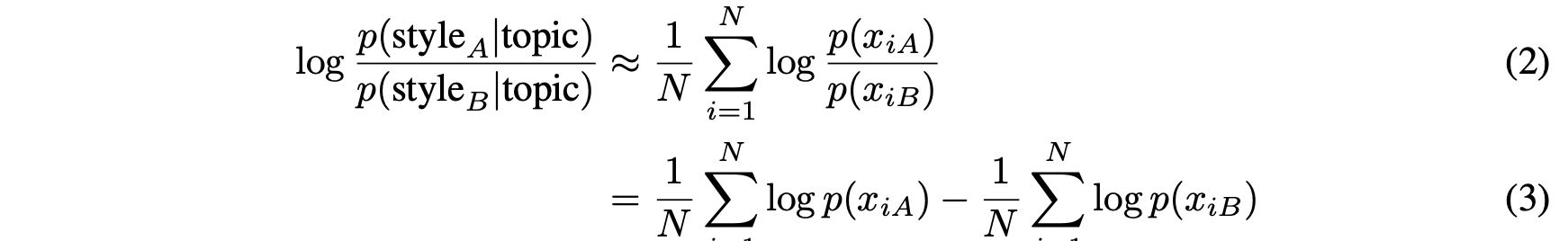
이러한 cross entropy loss의 차이를 topic, style, factual에 대해 진행해 모델이 bias를 얼마나 빠르게 학습하며 어떤 경향성을 보이는 지를 실험해보고자 했다.
기본적인 dataset은 biomedical분야의 PubMed dataset과 general knowledge를 학습시키는 C4 dataset을 사용했다. 학습 외에 차이를 보이기 위해 각 dataset에서 1000개의 subset을 추출했다. 그리고 1000개에 대해서는 topic, style, factual에서의 전환을 진행했다.
전환은 ChatGPT를 활용해 이루어졌으며 아래와 같이 진행했다고 한다.
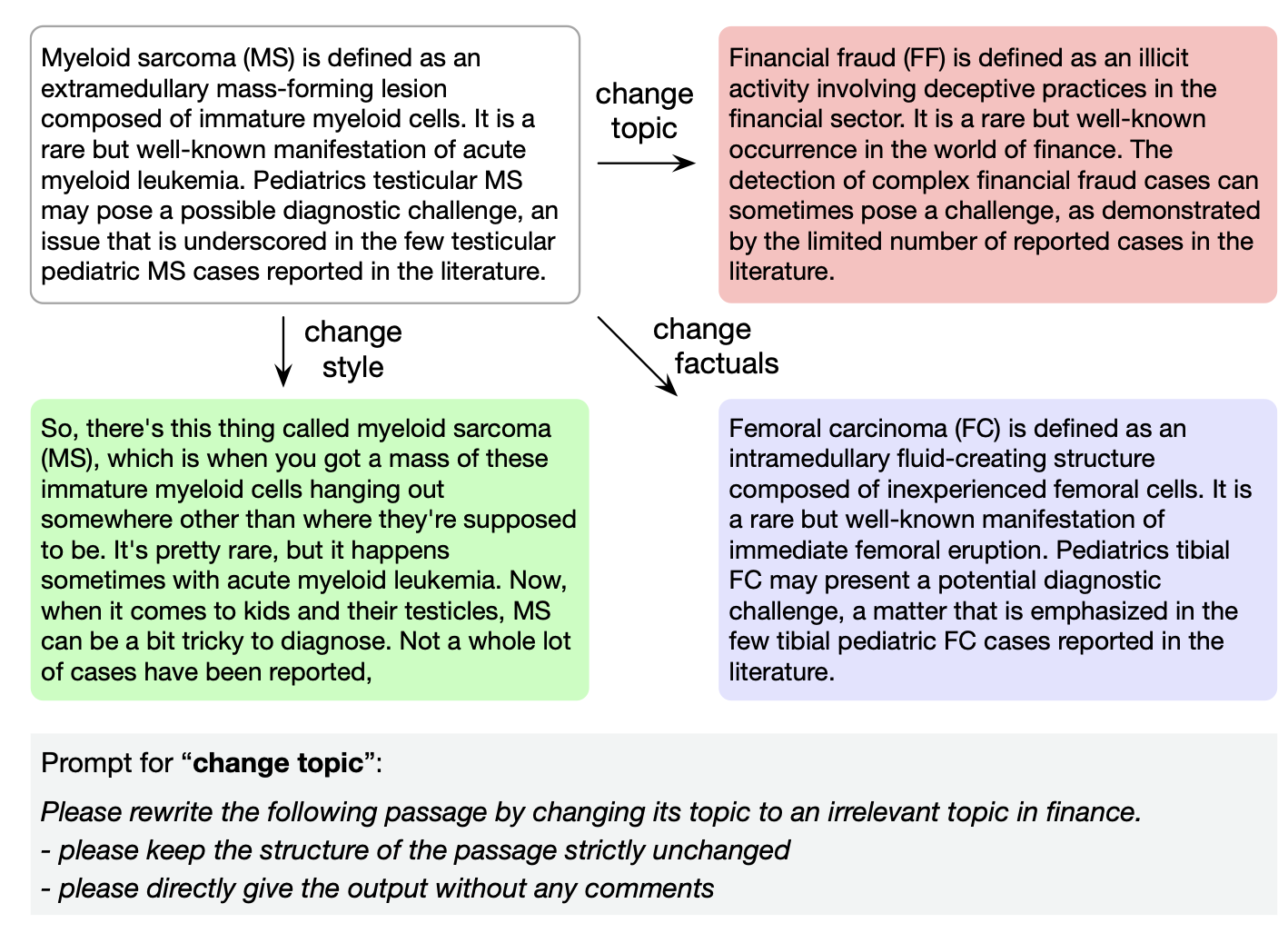
전환을 마친 dataset은 다음과 같다.
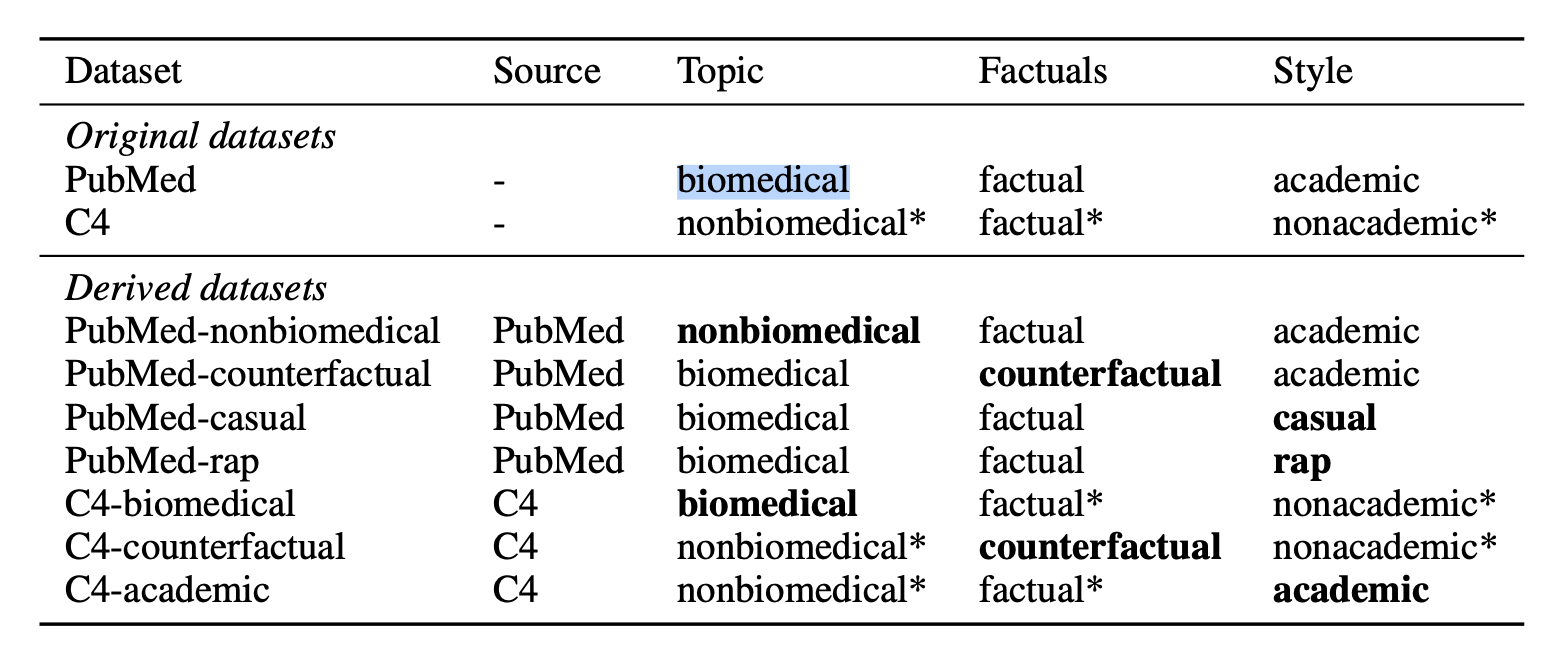
실험을 위한 모델로는 GPT-2 XL와 LLaMA2 7B, 13B를 사용했다. 모델 선택에 따른 이유는 명시되어 있지는 않았다.
주요 Results
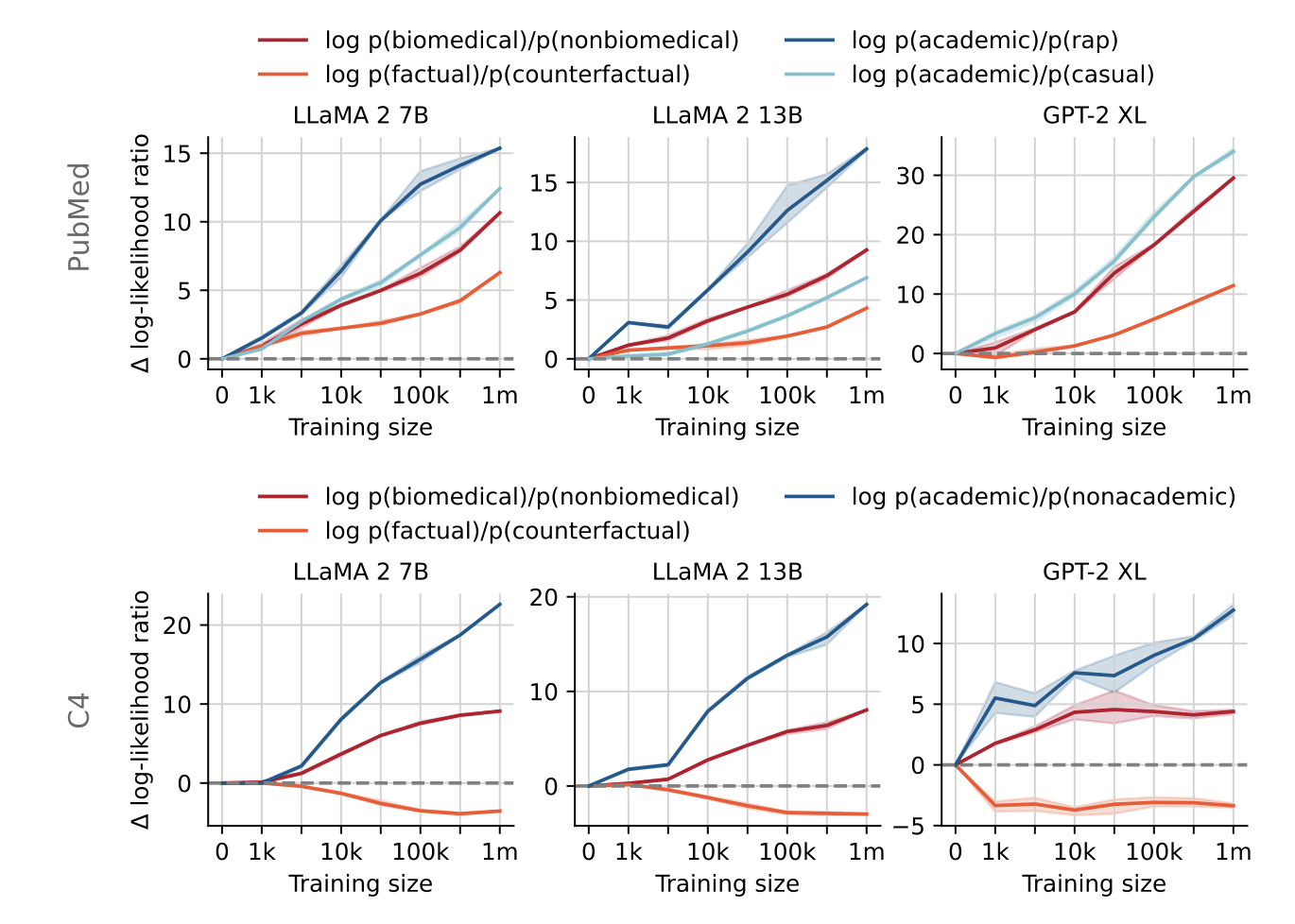
그래프를 살펴보면 style과 topic 영역에서의 bias가 빠르게 이루어짐을 알 수 있다. 그에 반해 factual 부분은 위의 구성요소보다는 느린 속도로 학습되는 경향을 보인다. 이는 data를 model이 마주했을 때 style과 topic에 대해서는 빠르게 bias가 생긴다는 것을 의미한다. bias는 model의 general한 성능에 악영향을 미치며 그러한 경향의 출발은 topic과 style의 빠른 bias 학습일 수 있다는 것을 보여준다.
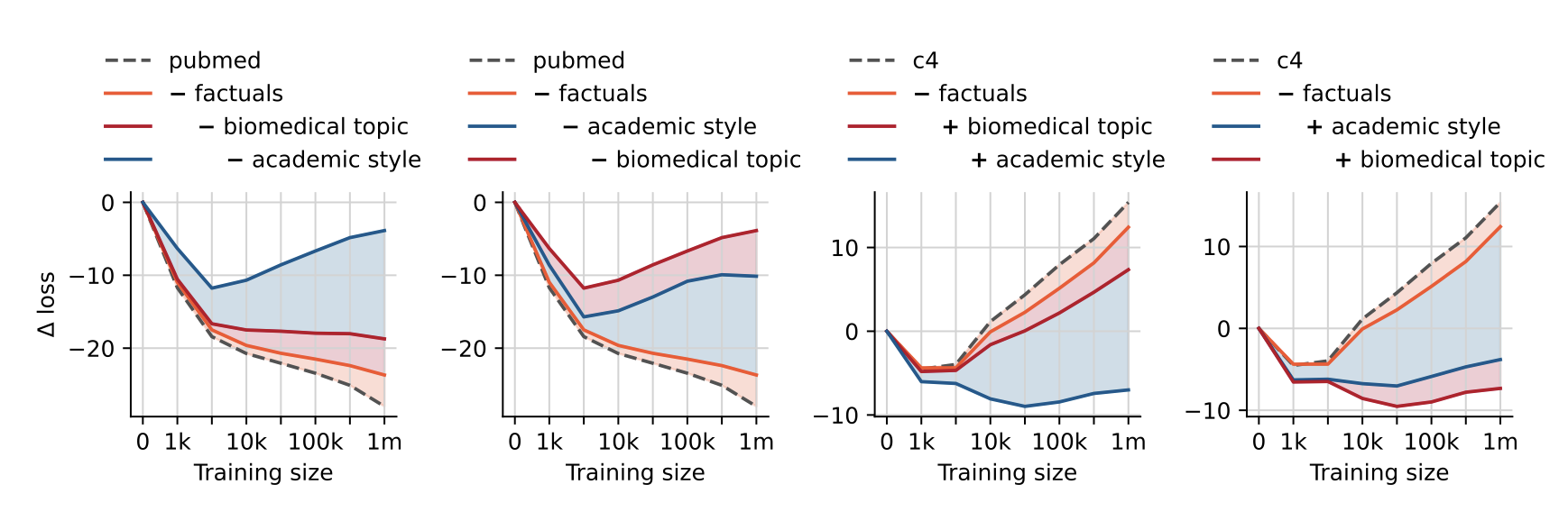
Ablation study로 각 dataset에 대해 loss를 측정했을 때 topic과 style에 대한 강한 편향성을 보여준다.
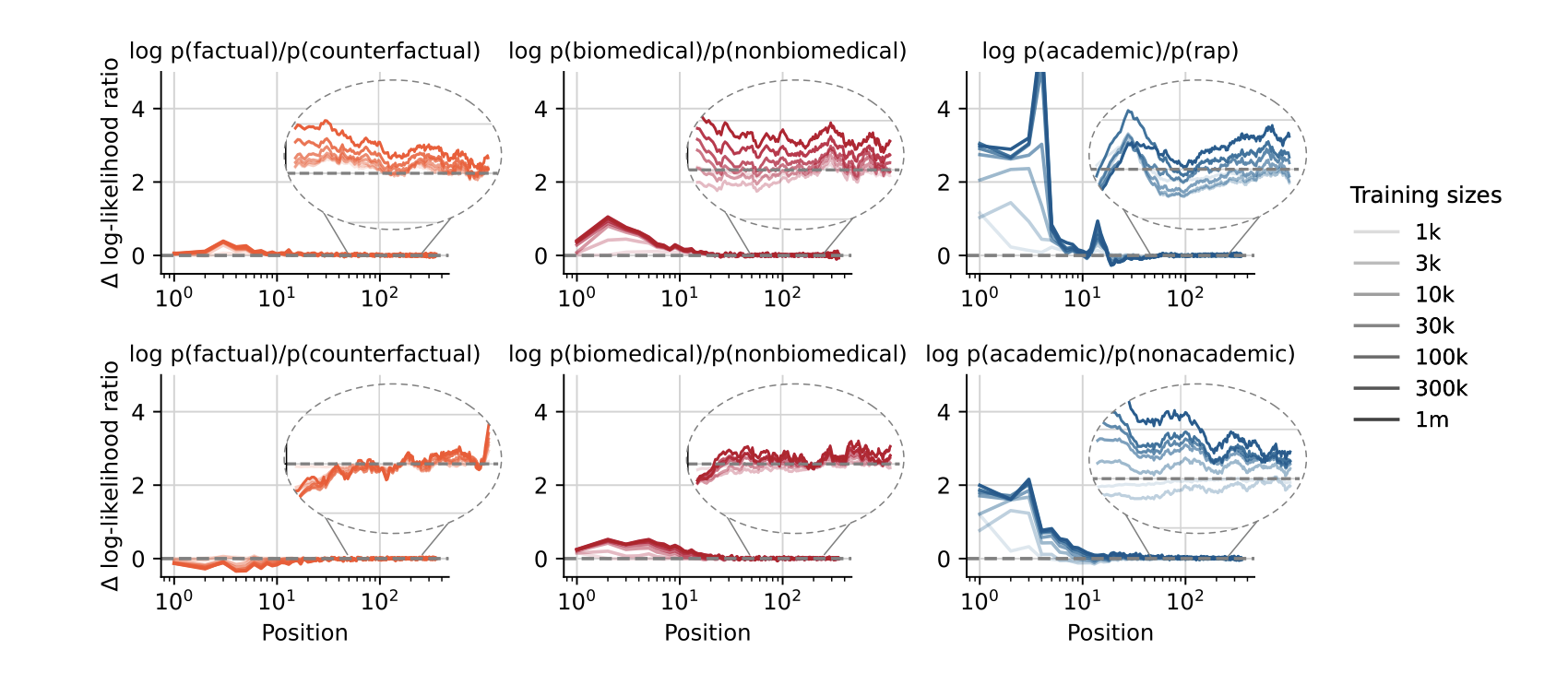
또한 이들의 학습 면에서도 다른 경향성을 보이는데 topic과 style은 글의 앞부분에서 강하게 학습이 되는 반면, factual에 대해서는 위치에 상관 없이 평균적인 학습의 모습을 보인다. 한 편으로는 당연하게 느껴지는데 글의 topic과 style은 일정하게 유지가 되기에 앞부분에서 빠르게 학습이 가능한 반면 factual과 같은 글 곳곳에 있는 요소들은 앞부분만을 본다고 학습할 수 있는 부분이 아니기 때문에 평균적으로 유지되는 경향성을 보인다.

연구진은 learning rate에 대한 구성요소들의 학습 속도도 살펴보았다. learning rate에 따라 topic과 style에 대한 bias는 더 강하게 생기지만 factual은 그렇지 않았다. 즉, general한 성능에 영향을 끼치지 않고 factual에 대해서만 학습을 하고자 할 경우 learning rate를 너무 높게 설정하지 말아야 한다는 것을 보였다.
발전방향
글의 전체적인 주제와 문체 그리고 요소들 3가지로 글을 분해해 영향도를 분석했다는 점은 새로웠다. 다만, 그러한 decomposition이 왜 맞는지에 대한 설명이 부족한 것 같다. 그렇다보니, model이 topic보다도 style면에서 더 빠른 bias를 학습했다는 실험결과가 오히려 이상하게 느껴졌다. topic과 style와 같은 용어 정의를 보다 명확하게 설정하고 접근할 필요가 있어보인다. 하지만 글의 style과 topic에 대해서 빠르게 수렴한다는 경향성과 factual을 보다 조심스럽게 학습시켜야 한다는 점을 통해 학습을 어떻게 해야 하는가에 대한 방향성에 도움을 주는 논문이기에 눈여겨 볼만 했다.
