[논문리뷰|NLP]Boosting LLM Reasoning: Push the Limits of Few-shot Learning with Reinforced In-Context Pruning
논문리뷰
https://arxiv.org/pdf/2312.08901.pdf
논문리뷰
CoT로 few-shot learning을 할 때에 더 많은 sample들을 넣으면 general하게 성능이 올라가는 경향을 보이던데,
input length에 제한이 있으므로
pruning을 통해 unimportant token을 줄이고 최대한 few-shot으로 많은 sample을 주면 성능이 오르지 않을까?
거기에 더해 가장 도움이 되는 sample들은 어떻게 고를 수 있을까?
- 꽤나 중요한 문제
what’s the upper limit of LLM performance gain in math reasoning achievable through inputting as many few-shot CoTs as possible?
그리고 이를 해결하고자 CoT-Influx를 고안했다고 한다.
Pilot Study
살펴보면 sample이 증가할 수록 성능도 상승되는 경향이 나타났다고 한다.
sample들 선택은 top-k 방법으로 했다고 나온다.
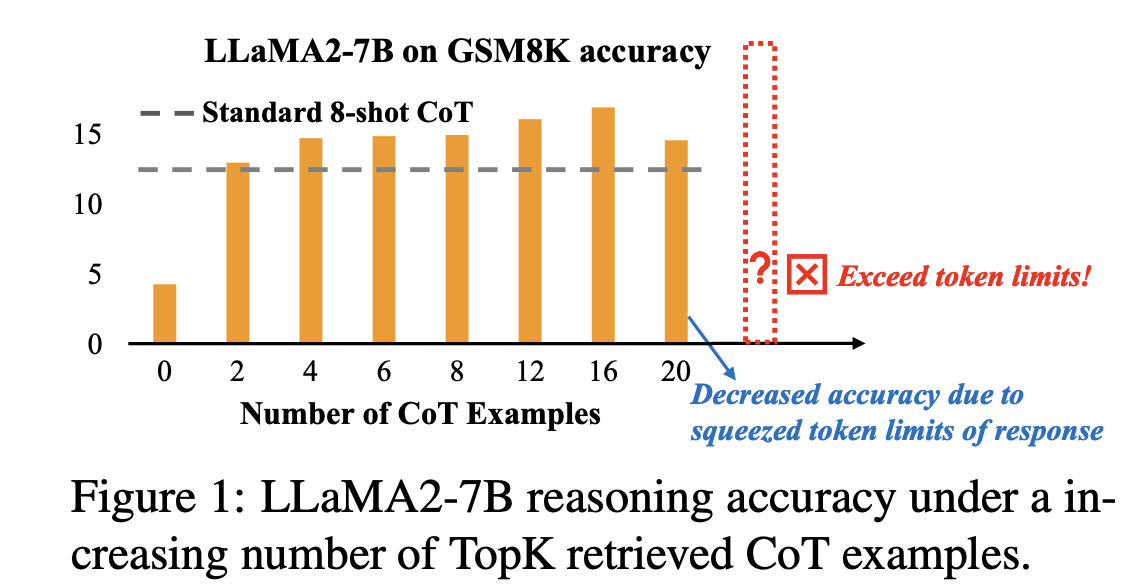
또한, sample들의 선택이 성능에 큰 영향을 미쳤다고 한다.
- 좋은 sample을 쓰는 것이 sample 수보다 성능에 더 큰 영향을 미친다는 것

math reasoning에서 반복적으로 등장하는 token이 있는데 이들은 pruning을 해주어 더 많은 informative content를 추가할 수 있다.
그러나 함부로 삭제하는 것은 위험할 수 있다
- 숫자 같은 것은 중요하기 때문
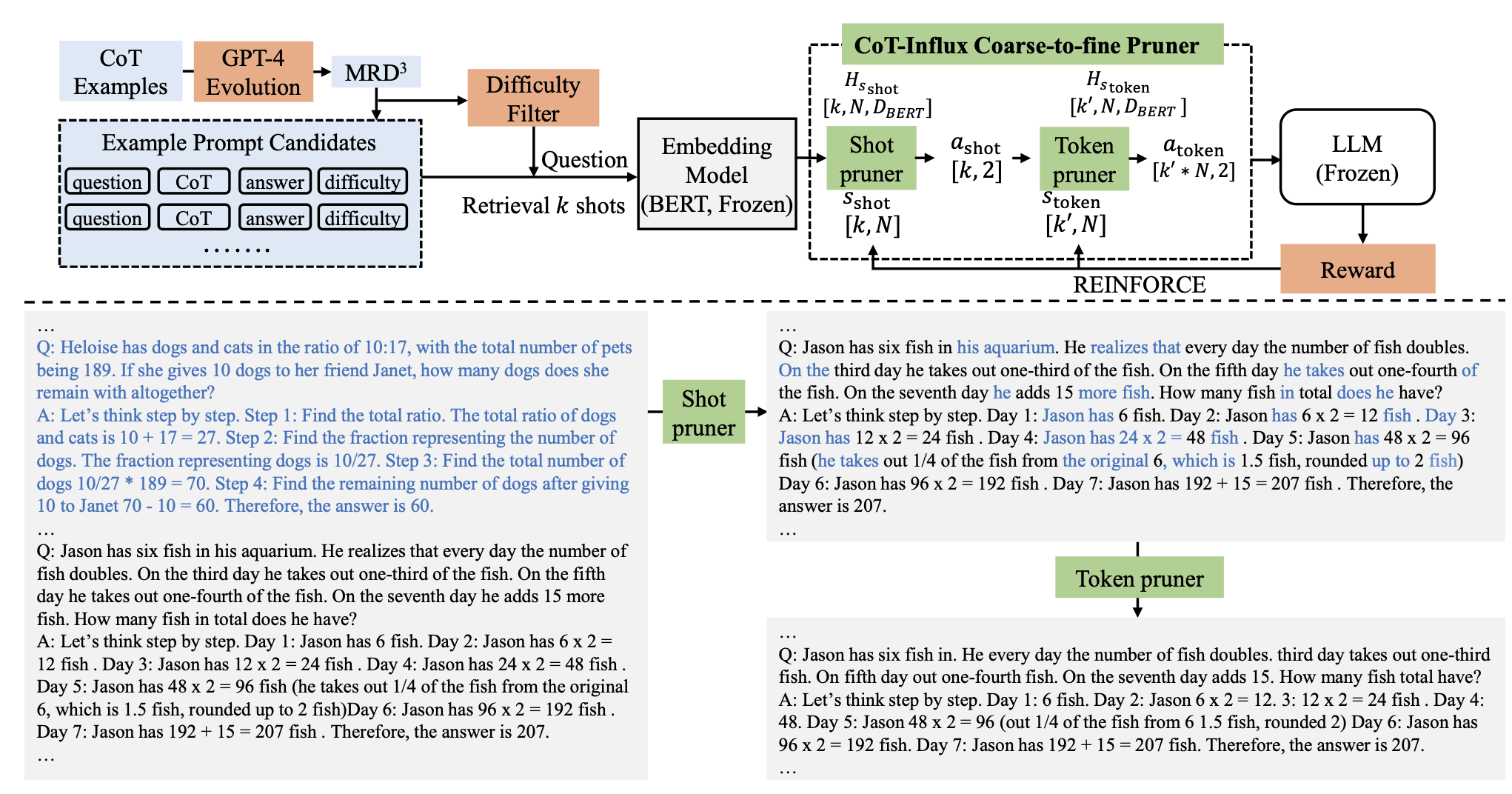
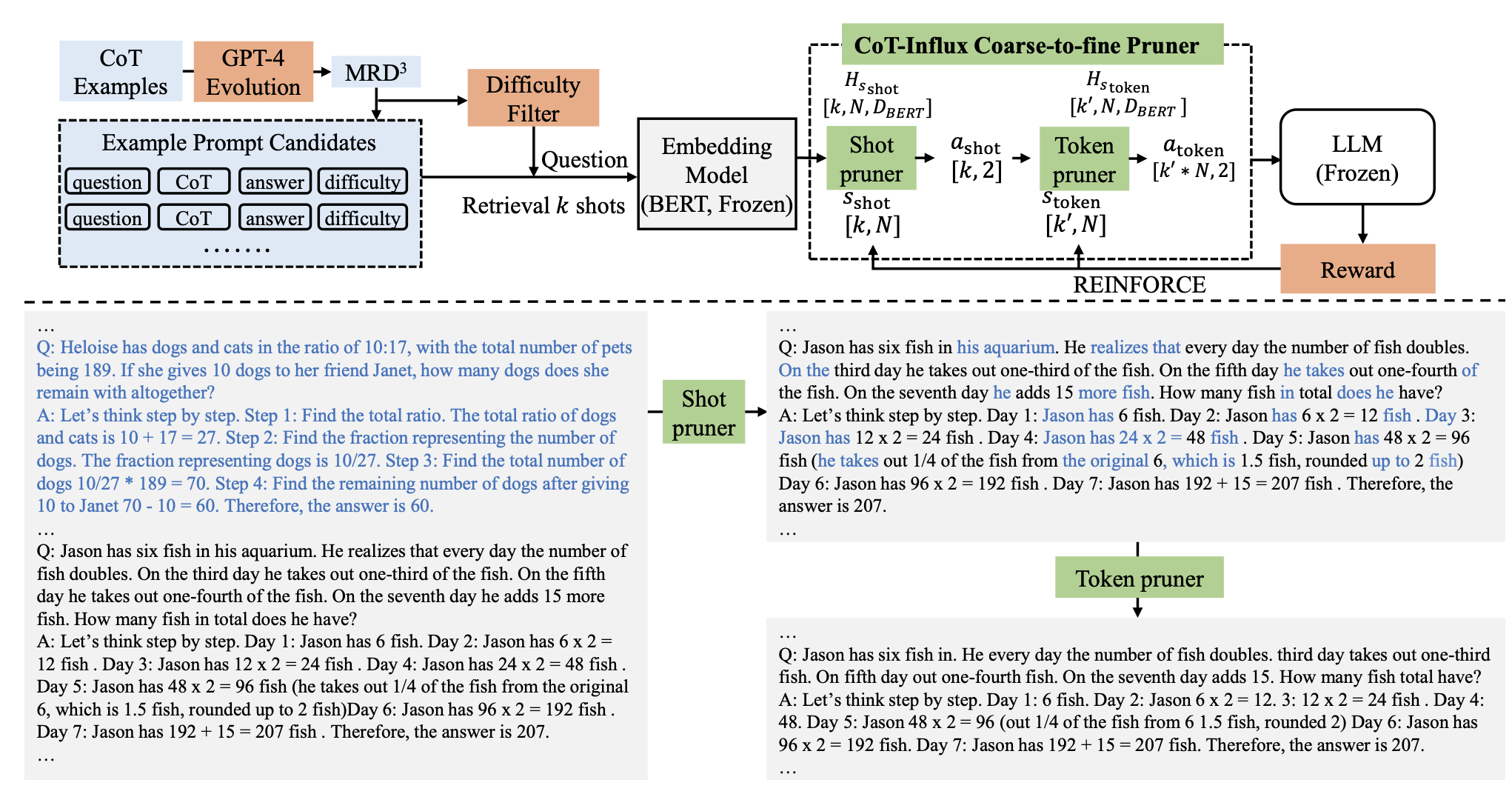
CoT-Influx Methodology
GPT-4로 데이터셋에 대해 reasoning 생성 지시
- 이때 few-shot learning으로 동일한 format을 유지하는 것이 중요하다고 한다.
그리고 각각에 대해 GPT-4로 하여금 1~10 사이의 난이도를 체크하라고 한다.
- 2~4에 쏠려있어서 Wizardmath에서 사용한 방식으로 mutation을 했다고 하는데 중요해보이지는 않는다.
그렇게 모은 데이터를 라고 부른다
이렇게 모은 데이터에서 k개를 sampling한다.
이때, token수는 LLM window length limit(T)를 넘게 되기에 CoT-Influx가 2step으로 pruning 진행
1. 먼저, 유용하지 않은 CoT sample들 pruning
2. 그리고 중복되는 token들을 제거함
그렇게 만들어진 prompt와 query(question)을 합쳐서 input으로 만들고 LLM에 제공
이 과정을 위해 BERT를 사용.
1. BERT를 통해 sentence embedding과 token embedding을 추출
2. 이들을 MLP를 태워서 삭제할지 말지를 결정
이 과정으로 선택된 것들에 대한 multi-objective reward를 새롭게 구현

LLM에서 발생한 loss와 실제 성능을 합쳐 reward를 만들었다.
w를 T를 t가 넘을지 말지에 대한 조정을 해주는 hyperparameter
만약 format이 깨지거나 주요한 token이 삭제된 경우에는 를 -0.1로 주었다고 함
- 그에 대한 이유는 없음
그리고 해당 reward와 REINFORCE(Williams, 1992)을 통해 MLP에 넘겨줄 reward를 구했다.
![]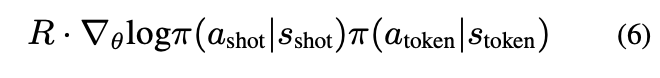
전체적인 모습은 아래와 같다.
Result
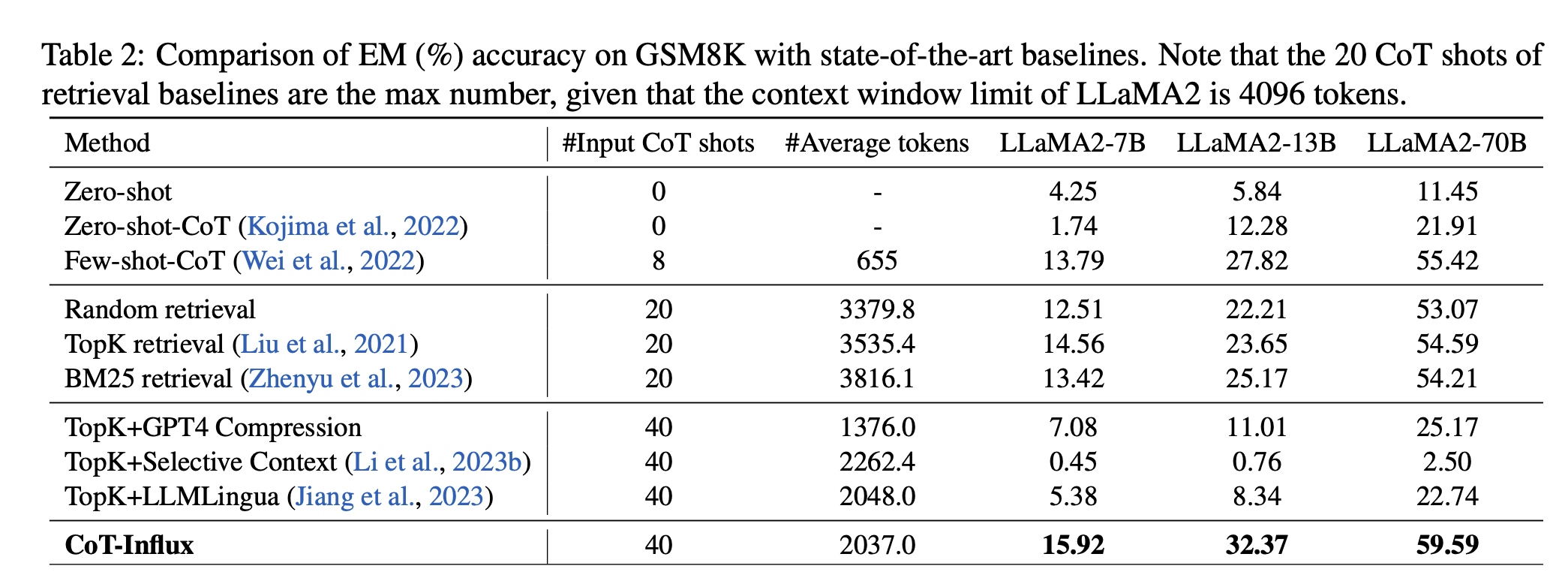
성능이 생각보다 엄청 올랐다라고 하기에는 shot 개수가 20개가 차이가 나서 애매한 것 같다.
그래도 compression 중에서는 높은 성과
✏️ 발전방향
policy를 어떻게든 update하기 위해 REINFORCE방법을 사용하고 BERT를 사용해서 embedding을 구하고 pruning을 시도했다는 점은 인상깊었다.
token과 sample에 대해 evaluate를 진행해 선택했다는 점은 생각해볼만한 지점
token은 제외하고 sample들만을 그렇게 선택했을 때에도 성능이 괜찮은지가 궁금하기는 하다.
- 그렇게 되면, 도움되는 sample들을 고를 수 있는 좋은 전략이 될 것 같다.
retrieval방법보다 token수는 줄었으나 성능은 높았다는 점에서 efficient하기도 하다.
고도화해볼 수 있는 지점이 꽤나 많은 논문인 것 같다.
