RoBERTa에서도 알 수 있듯 Attention을 활용한 Encoder를 쌓은 BERT 구조는 매우 강력한 성능을 자랑한다. 데이터만 확보가 된다면 문장들을 임베딩해 높은 성능의 결과물도 내보내게 된다.
하지만 BERT는 Encoder지만 Encoder 본질의 역할보다는 의도한 결과를 내보내는 것이 목표이다. 이는 높은 성능을 보장하지만 반대로 문장 Pair를 input으로 받아야 한다는 제약성과 높은 연산을 요구한다.
곰파다 프로젝트를 진행하면서 Cross Encoder와 Bi-Encoder 구조인 SBERT 모두 사용했다. 결과적으로 의미를 임베딩한다는 측면에서 SBERT 사용이 더 적절하다고 판단을 했었다. 이에 대한 근거를 논리적으로 풀기 위해 논문 리뷰를 진행했다.
💬 간단 요약
BERT와 RoBERTa 모델이 STS에 대해서 매우 잘 하고 있다. 하지만 이들을 하나의 Encoder에 넣어야 하므로 computational cost가 매우 크다
- 이는 cross-encoder의 단점과 동일
또한 Cross-Encoder 구조는 문장 pair를 input으로 받아 output을 생성하는 것이기 때문에 clustering과 같은 task에 대해서는 적합하지 않다.
- 단일 문장의 임베딩이 아니기 때문에 해당 문장이 지금까지 학습된 문장과 비교해 어떤 위치에 임베딩이 되어야 하는가를 분석해야 하기 때문
연구진은 두 개 혹은 세개의 network로 구성된 SBERT 구조를 고안해냈고 문장의 의미를 잘 반영하는 문장 임베딩 방법론을 모색했다.
결과적으로 해당 방식은 65시간이 걸리는 작업을 단 5초로 단축할 수 있으며 정확도 또한 유지할 수 있었다.
연구진은 SBERT와 SRoBERTa를 활용해 STS와 몇몇 분야에 대해서 상당히 높은 성능을 이루어냈고 기존의 BERT 모델로 할 수 없었던 task에 대해서도 다룰 수 있을 뿐더라, 좋은 성능을 보였다.
📌 1. Introduction
SBERT 구조를 사용하면 그동안 BERT로 해결할 수 없었던 문제들(대량의 유사도 비교, 클러스터링, 의미적 유사성을 통한 검색)에 대해서도 적용할 수 있었다.
기존 BERT는 cross-encoder 방식이다. 즉 한 개의 BERT에 문장 pair가 들어가는 방식이다. 하지만 이것의 치명적인 단점은 STS같은 Task를 수행하면 너무 많은 가지수를 학습시켜야 한다는 것이다. 예를 들어 n개 문장을 pair로 학습시키기 위해서는 의 데이터를 학습해야 한다.
Cross-Encoder는 항상 문장 pair에 대한 유사도만 구할 수 있기에 새로운 문장에 대해 기존에 있는 문장과 가장 유사한 것을 고르기 위해서는 기존의 모든 문장과 유사도 연산을 진행해야 한다. 이처럼 BERT가 문장 pair를 input으로 받는 것은 비효율성을 많이 야기한다.
또한 논문에서는 CLS 토큰을 통해 문장의 임베딩을 구하는 방식도 비판했다. CLS 토큰으로 문장의 임베딩을 구하는 것은 문장의 전체적인 의미를 반영하지 못한다고 논문에서는 말한다. 이들은 이러한 방식으로 임베딩을 구하는 것이 오히려 성능의 저하를 일으킨다고 얘기한다.
이는 CLS 토큰이 구해지는 과정에서의 문제점을 얘기하는데 문장의 전체적인 의미를 파악하기 위해서는 Attention을 이용해 특정 단어에 대해 높은 가중치가 계산되는 문장 벡터가 아니라 동일하게 Mean Pooling을 사용하는 것이 효과적이라고 말한다.
하지만 실제로 이는 큰 차이가 없는 것으로 나타났고 오히려 문장에서 단어가 사용된 문맥적 의미를 파악하기 위해서는 CLS 토큰을 사용하는 것이 좋으며 성능적으로도 별 차이가 없다는 연구도 많다.
SBERT 구조를 사용하면 매우 코사인 유사도나 유클리드 혹은 맨해튼 거리로 계산되는 유사도에 따라 임베딩이 되고 이를 활용하면 리소스 면에서 매우 효율적이다.
이후에는 NLI 데이터셋을 학습시켜 SOTA를 달성했고 세가지 문장 분석이나 다양한 task들에 대해서도 매우 높은 성능을 보였다.
🏷 2. Related Work
BERT의 가장 큰 단점은 단일한 문장 임베딩을 학습하지 않는다는 것이라고 말한다. 즉, 이러한 방식이 문장 그 자체의 임베딩을 방해하고 있다고 말한다. 이것을 보완하기 위해 많은 연구진들이 BERT에 단일 문장을 제공하고 결과를 평균내거나 CLS 토큰을 통해 임베딩을 구하는 방식 등으로 고정 길이의 벡터로 변환시켜준다.
연구진들은 이러한 두 가지 방식은 그리 유효하지 않다고 비판하고 결국에는 BERT 방식에 소요되는 리소스가 너무 크다고 말하며 그것을 타파해주는 SBERT를 소개할 것이라고 한다.
3. Model
SBERT는 기본적으로 Mean Pooling 경우에 따라서는 Max Pooling을 이용해 문장의 임베딩을 얻는다. 그리고 그 임베딩 된 것을 비교할 수 있는 2중 그리고 3중 네트워크 구조를 만들어준다. 이를 통해 의미 있는 임베딩이 구현되도록 만들었다. 그리고 해당 구조들은 task에 따라 구조와 목적함수가 달라지고 이에 따라 학습하도록 만들었다. task들은 아래 3가지의 형태이다.
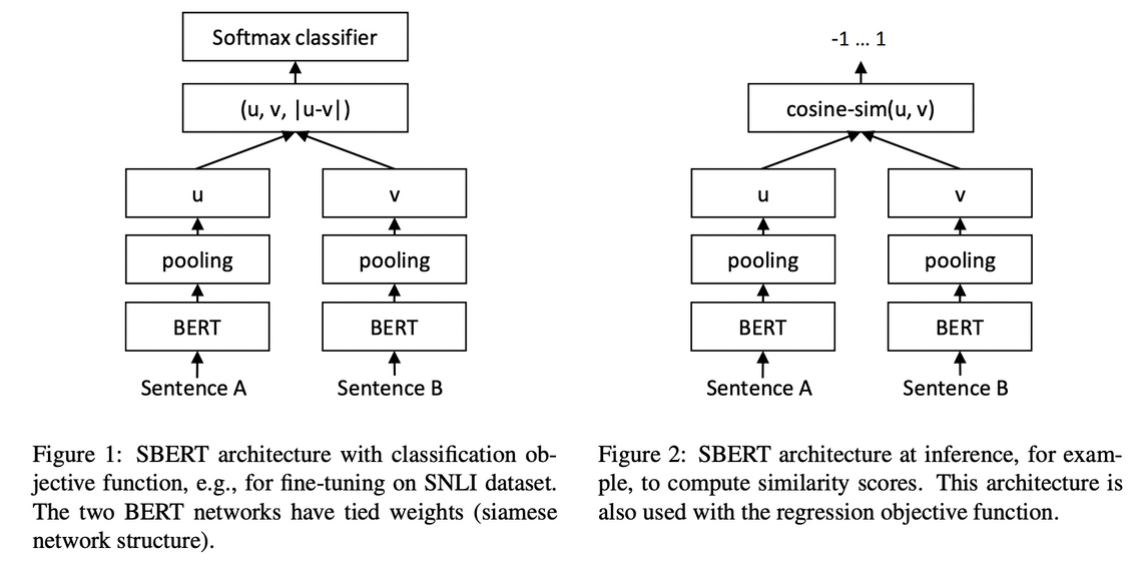
1) Classification Objective Function.
We concatenate the sentence embeddings u and v with the element-wise difference and multiply it with the trainable weight :
where n is the dimension of the sentence embeddings and k the number of labels. We optimize cross-entropy loss. This structure is depicted in Figure 1.
Classification을 위한 형태이다. 연구진들은 Cross-entropy loss를 사용해 학습했다.
2) Regression Objective Function.
The cosine-similarity between the two sentence embeddings u and v is computed (Figure 2). We use mean squared-error loss as the objective function.
Regression을 위한 형태이다. 연구진들은 cosine 유사도를 통해 문장간 유사도를 구하고 이들에 대해 mse를 적용해 학습했다.
3) Triplet Objective Function.
Given an anchor sentence a, a positive sentence p, and a negative sentence n, triplet loss tunes the network such that the distance between a and p is smaller than the distance between a and n. Mathematically, we minimize the following loss function:
with the sentence embedding for a/n/p, || · || a distance metric and margin.
Margin ensures that is at least closer to than . As metric we use Euclidean distance and we set in our experiments.
이 task에서는 기준이 되는 문장 a와 긍정 문장 p와 부정 문장 n을 제공한다. triple loss는 a 문장이 어떤 문장에 더 거리가 멀어야 하는지에 대한 loss를 제공한다.
- 위의 예시에서는 에 더 가까워야 loss가 줄어들 것
은 위의 예시에서 가 적어도 만큼 에 보다 더 가깝다는 의미를 나타낸다. 연구진은 을 1로 사용했다.
3.1 Training Details
- fine-tuning data
- SNLI
- 570,000 sentence pairs
- labels: contradiction, entailment, neutral
- MNLI
- 430,000 sentence pairs
- spoken and written text
- SNLI
- batch size = 16
- optimizer = Adam
- learning rate = 2e-5
- a linear learning rate warm-up over 10% of the training data
- pooling strategy = MEAN
4. Evaluation - STS
Pair로 학습시키면서 복잡한 Regression 함수를 학습시키는 경우가 많은데 이러한 학습은 조합의 폭증으로 리소스 소모가 너무 크고 가늠할 수 조차 없다. 그 대신에 문장의 유사도를 cosine 유사도를 통해 구했다. 유클리드 거리랑 맨해튼 거리도 이용했지만 결과가 거의 유사했다.
4.1 Unsupervised STS
STS Dataset에 있는 문장들은 사용하되 거기에 있는 label은 사용하지 않았다. STS 데이터셋들은 Pearson 상관계수로 유사도가 라벨링이 되어 있는데 이는 STS에 적합하지 않은 형태라고 말한다.
- 왜일까?
대신에 연구진들은 STS 데이터셋에 대해 코사인 유사도를 기반으로 Spearman rank를 계산하는 방식으로 gold label을 계산했다.
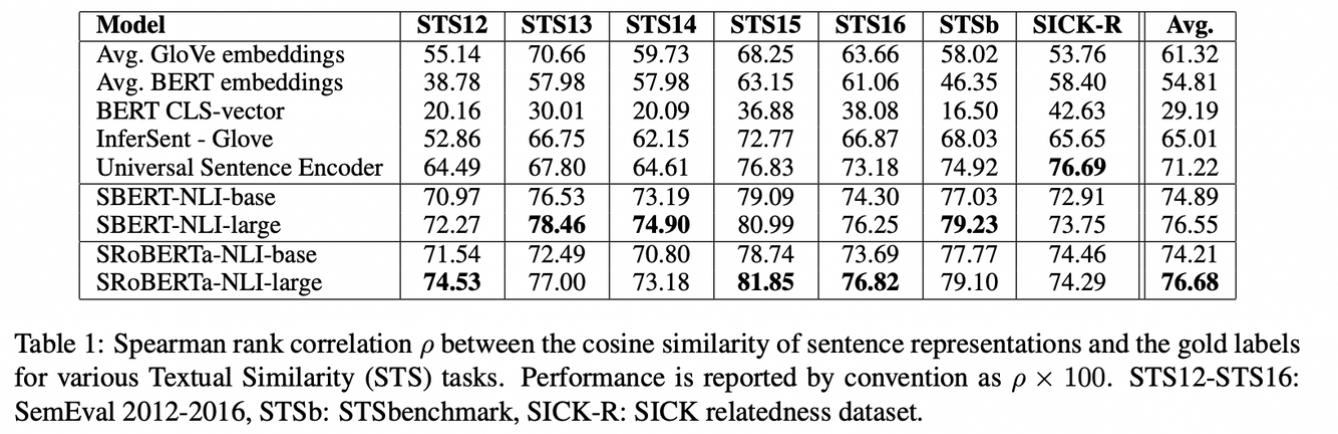
결과적으로 압도적인 성능을 보여주었다. 특히 CLS를 사용하는 임베딩은 매우 낮은 성능을 보였다. 유일하게 Sick-R에서는 낮은 성능이 나타났는데 성능이 높은 Universal은 뉴스와 QA 데이터를 많이 읽어서 그렇다고 연구진들은 말한다.
SBERT와 SRoBERTa는 생각보다 성능 차이가 크지 않았고 오히려 SBERT가 뛰어난 경우도 있었다.
- 아무래도 고전적인 NLI task이기 때문에 RoBERTa에서 NSP를 삭제했으므로 이러한 결과가 나오지 않았을까 싶다.
💡 신기하게 Unsupervised에도 매우 높은 성능이 나왔다.
즉, Clustering을 하며 Embedding을 자체적으로 하는 것에도 매우 높은 성능을 보인다는 것
4.2. Supervised STS
STSb의 supervised dataset(8,628 sentence paris)으로 finetuning을 진행한 후, 성능 비교를 진행했다. 여기서 SBERT는 regression 함수를 통해서 학습했다. 예측을 할 때에는 Encoder에서 나온 문장 임베딩간의 코사인 유사도를 예측하는 방식이다.
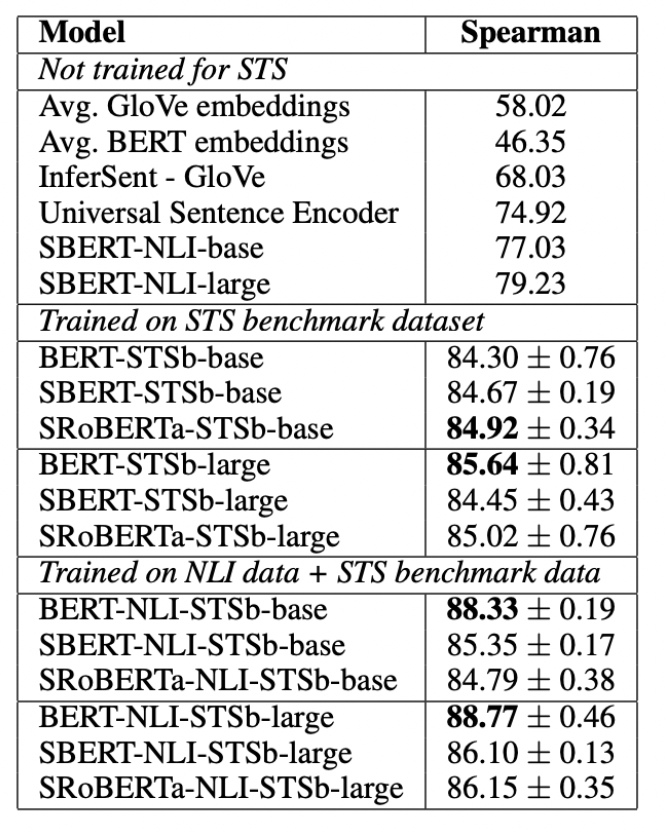
The results are depicted in Table 2. We experimented with two setups: 1) Only training on STSb, and 2) first training on NLI, then training on STSb.
We observe that the later strategy leads to a slight improvement of 1-2 points. This two-step approach had an especially large impact for the BERT cross-encoder, which improved the performance by 3-4 points. We do not observe a significant difference between BERT and RoBERTa.
학습을 NLI 그후 STS로 두번씩 하는 방식으로 하니 BERT에서 엄청난 성능 상승이 있다. 즉, fine-tuning을 2회한 것이 의미가 있는 사례로 볼 수 있을 것이다. 또한 BERT가 전반적으로 매우 높은 성능 상승과 매우 높은 성능을 보이고 있다. 그리고 BERT와 RoBERTa는 여기서도 유의미한 성능 차이가 나지 않았다.
4.3. Argument Facet Similarity
AFS 데이터셋은 논쟁이 있는 세가지 주제(총기 규제, 동성애 결혼, 사형)에 대해 다루며 0 ~ 5까지 문장 pair의 유사도가 측정되어 있다. STS랑 다르게 발췌한 주제 뿐만이 아니라 동일한 주장인지 동일한 이유를 다루고 있는지도 라벨링의 기준이 된다. 그래서 AFS에서 다루고 있는 어휘의 차이(어휘 의미적 차이)가 더 크며 이를 파악하는 것이 매우 어렵고 STS에 대해 좋은 성능을 보이는 모델이 AFS에서 자주 성능이 나쁘다.
모델은 두가지 학습 방식을 사용했다.
1) 첫번째로 데이터셋 논문에서 사용하는 학습방식인 10-fold CV evaluation이다.
- 하지만 이는 서로 다른 topic에 대해 얼마나 잘 generalize되는지 파악이 어렵다
2) 두번째는 cross-topic
이 방법은 세가지 주제 중 두 주제가 학습에 사용되고, 남은 한가지 주제에 대해 평가하는 방식이다. 이와 같은 방식으로 모든 주제에 대해 시행한뒤 metric을 평균하여 보여주었다.
- 해당 방식을 사용하면 왜 좋을까 이에 대한 조사를 해보았지만 딱히 나오는 것은 없었다.
SBERT를 Regression Objective를 거쳐 유사도가 나타나도록 만들었고 유사도 계산은 동일하게 코사인 유사도로 계산했다.
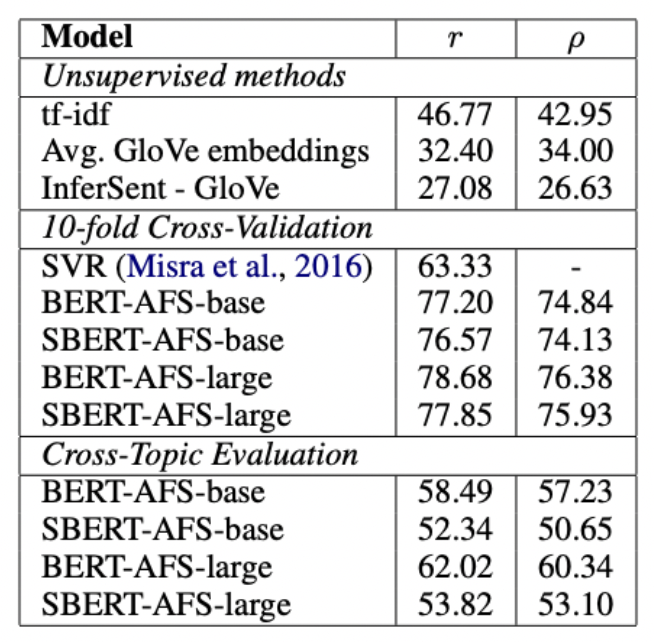
기본적으로 tf-idf, GloVe등이 가장 낮은 성능 수치를 보이고 있다. 10CV로 진행한 SBERT는 기존 BERT와도 근접한 성능을 보이고 있다. 하지만 cross topic evaluation에서는 SBERT에서 Pearson 상관계수를 사용할 때 성능이 매우 하락한 모습을 볼 수 있다. BERT는 문장 자체를 임베딩한다기 보다는 두 문장이 들어왔을 때 Attention을 사용해 각 단어간의 비교로 의미상의 차이를 유추한다. 하지만 SBERT는 아직 train이 되지 못한 문장들을 벡터 공간 적절한 곳에 임베딩시켜야한다.
즉, 연구진은 clustering을 문장의 의미를 파악해서 해야 하므로 더 어려운 주제라고 말하고 있으며 이를 어느 정도 잘 수행하고 있는 결과로 볼 수 있다고 주장한다.
4.4. Wikipedia Sections Distinction
wiki에서 같은 문서라도 같은 section에 있는 문장이면 다른 section에 있는 문장보다 더 가까울 것이라고 가정하고 만든 데이터셋이다.
기준 문장과 positive sample(같은 섹션 문장), negative sample(같은 문서 다른 섹션 문장)을 triplet으로 만들어 제공한다.
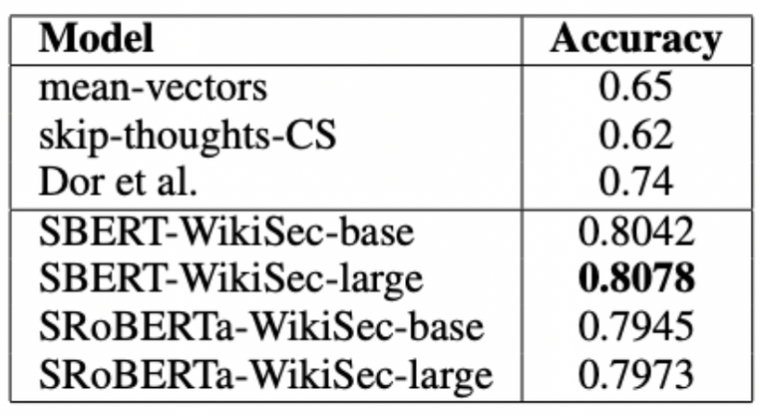
accuracy를 통해 anchor 문장이 어떤 문장에 더 가까운지를 구별하도록 만들었다. 결과적으로 데이터셋에서 사용한 triple loss를 적용한 BiLSTM 보다 SBERT가 우수한 성능을 보여주었다.
🔬 5. Evaluation - SentEval
부가적으로 논문에서는 7개의 classification task를 갖는 SentEval에 대해서도 성능을 측정했다. SentEval은 주로 다양한 task에 대해 모델이 가진 sentence embedding의 질을 평가할때 사용된다.
- MR: Sentiment prediction for movie reviews snippets on a five start scale (Pang and Lee, 2005).
- CR: Sentiment prediction of customer product reviews (Hu and Liu, 2004).
- SUBJ: Subjectivity prediction of sentences from movie reviews and plot summaries(Pang and Lee, 2004).
- MPQA: Phrase level opinion polarity classification from newswire (Wiebe et al., 2005).
- SST: Stanford Sentiment Treebank with binary labels (Socher et al., 2013).
- TREC: Fine grained question-type classification from TREC (Li and Roth, 2002).
- MRPC: Microsoft Research Paraphrase Corpus from parallel news sources (Dolan et al., 2004).
STS이기에 logistic regression classifier을 사용해 예측하며 Accuracy를 metric으로 사용했다. 이전 연구들과 동일하게 10-fold cv를 통해 test set에 대해 에측했다.
- 근데 여기서는 cross-topic을 사용하지 않았고 이유를 찾을 수 조차 없었다.
SBERT는 Transfer Learning 목적에 부합하지 않는다. 따라서 BERT에 비해 성능이 떨어질 것이라고 예측될 수 있다. 왜냐하면 fine-tuning을 통해 BERT는 모든 레이어를 학습하기 때문이다. 하지만 SBERT의 성능을 측정해보니 매우 높은 성능이 나타난다.
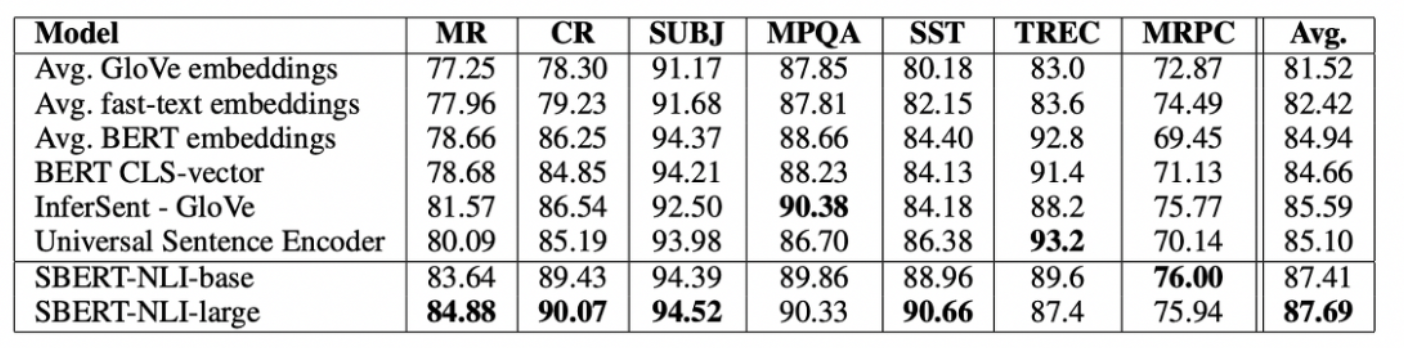
전이학습이 SBERT의 목적이 아님에도 SOTA를 보일 수 있었다. 즉, SBERT의 문장 임베딩이 매우 효과적임을 알 수 있었다. TREC는 질문 문장에 대한 분류인데 Universal Sentence Encoder가 QA 데이터셋으로 학습이 되었기 때문에 성능이 좋을 수 밖에 없다. CLS 토큰을 이용한 BERT가 STS에서는 매우 좋지 않은 성능을 보였지만 SentEval에서는 나쁘지 않은 성능을 보였다. 이 이 이유는 STS에서는 코사인 유사도를 통해 유사도를 계산하기 때문이다. 코사인 유사도는 모든 차원에 대해 동일하게 측정이 된다.
그에 반해 SentEval에서는 logistic Regression으로 문장 임베딩에 대해 계산하는 형식을 사용했다. 즉 BERT에서는 CLS 토큰에 Logistic Regression이 달린다.
따라서 이는 특정 차원이 분류 결과에 크기도 혹은 작기도 한 영향을 줄 수 있도록 학습이 되기 때문이다. 결국 CLS 토큰의 특정 부분이 영향을 더 주도록 설계가 된다.
BERT의 CLS 토큰을 이용하는 방식은 코사인 유사도나 맨해튼, 유클리드 거리를 통해 유사도를 측정하는 것이 좋지 않아보인다. 그리고 전이학습에 대해서도 여러 부문에 다른 모델보다 성능이 딸린다.
하지만 SBERT 구조를 사용하면 NLI 데이터셋들에 대해 SOTA를 달성할 수 있었다.
🧪 6. Ablation Study
SBERT 여러 다른 면들의 상대적 중요성을 이해하기 위해 ablation study 진행했다.
1) Max, Mean, CLS Pooling에 대한 고찰
2) concat시키는 방식에 대한 고찰
NLI는 Classification, STSb는 Regression으로 파악을 진행했다.
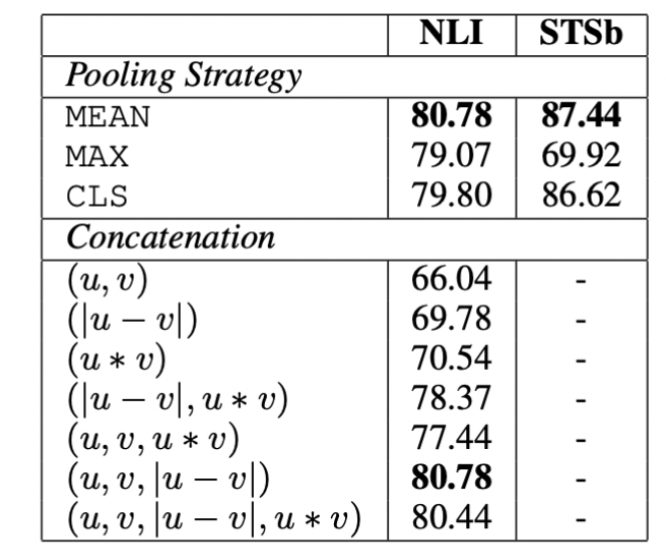
classification에 대해서는 pooling이 큰 영향을 주지는 못했고 오히려 concat의 효과가 매우 컸다. u*v를 input 넣으면 성적이 오히려 떨어졌다. 이는 아무 의미 없는 벡터임을 알 수 있었다. input과 별개로 최종 output에는 u와 v의 코사인 유사도를 통해서만 계산이 된다.
|u-v| 벡터가 매우 중요하게 역할을 하는데 pair에서 나타나는 요소별 차이는 차원의 거리를 표현하게 되고 이를 통해 문장 임베딩의 유사도를 계산하는데 영향을 많이 미치게 된다.
Regression을 진행하면서 Pooling 방식도 영향의 차이가 컸는데 Mean Pooling이 가장 효과적이었다. 특히 MAX가 성능이 매우 좋지 못한 것은 BiLSTM에서 Max를 사용할 때 가장 성능이 좋은 것과는 다른 모습이었다.
🚀 7. Computational Efficiency
기본적으로 문장간 유사도 계산은 많은 계산이 필요하다. 하지만 SBERT를 사용하면 이를 매우 짧은 시간으로 단축할 수 있다.

특히나 GPU를 사용하면 병렬처리가 가능하기에 기존의 Encoder들의 속도를 뛰어넘는 연삭 속도를 보여준다.
✏️ 후기
직접 프로젝트에서 사용했던 구조였기에 공부를 하며 더 깊은 이해를 할 수 있었다. 특히나 BERT 구조를 이제는 도구로 사용해 여러 task에 알맞게 변주한다는 점이 인상 깊었다. BERT의 Encoder 구조는 강력하기에 SBERT 처럼 유사도 뿐만이 아니라 task에 맞는 새로운 구조를 구상하는 능력과 이를 코드로 구현하는 능력도 매우 중요할 것 같다는 생각이 들었다. 여러 가지 점에서 생각도 깊어지게 만들었던 논문이었다.
