SBERT 논문을 읽던 중에 어떤 모델이 가장 성능이 높은지를 분석하기 위해 STS Dataset의 label과 그것에 대해 모델이 내보낸 값에 대한 상관관계로 Pearson 상관관계가 아닌 Spearman 상관계수를 사용했다고 말한다. 그러면서 이유를 저자의 다른 논문인 해당 논문을 인용했다.
이 부분이 잘 이해가 가지 않고 리뷰를 한 것이 하나도 없어 직접 읽어보고 그 이유를 탐색해보았다.
📌 1. 논문에서 얘기하는 기존의 방식
Performance is assessed by computing the Pearson correlation between machine assigned semantic similarity scores and human judgments (Agirre et al., 2016). Systems with a high Pearson correlation coefficient are considered as “good” STS systems
and would often be the first choice for the system designer of an STS based task.
...
Up to our knowledge, no one published so far results whether
Pearson correlation is a good method to evaluate the performance of different STS systems.
전통적으로 모델의 STS에 대한 성능을 비교하기 위해서는 라벨과 예측값의 MSE와 같은 것이 아니라 Pearson 상관 계수를 이용했다. 즉, 값이 얼만큼 일정하게 나오는가를 측정해 라벨의 범위나 정확도가 일치하지는 않아도 그 의미적인 유사성을 따르는 것에 방점을 두었다고 할 수 있다. 그러나 Pearson 상관계수 외에 다른 방식 시도에 대한 연구는 없다.
그래서 연구진들이 다양한 방법론을 사용해 어떤 방식으로 라벨과 예측값의 상관관계를 구하는 것이 가장 좋은지에 대한 연구를 진행했다.
결론적으로 Pearson 상관계수는 모델의 예측 능력 평가에 매우 효과적이지 못하다고 말한다.
🛠 2. 피어슨 계수의 한계
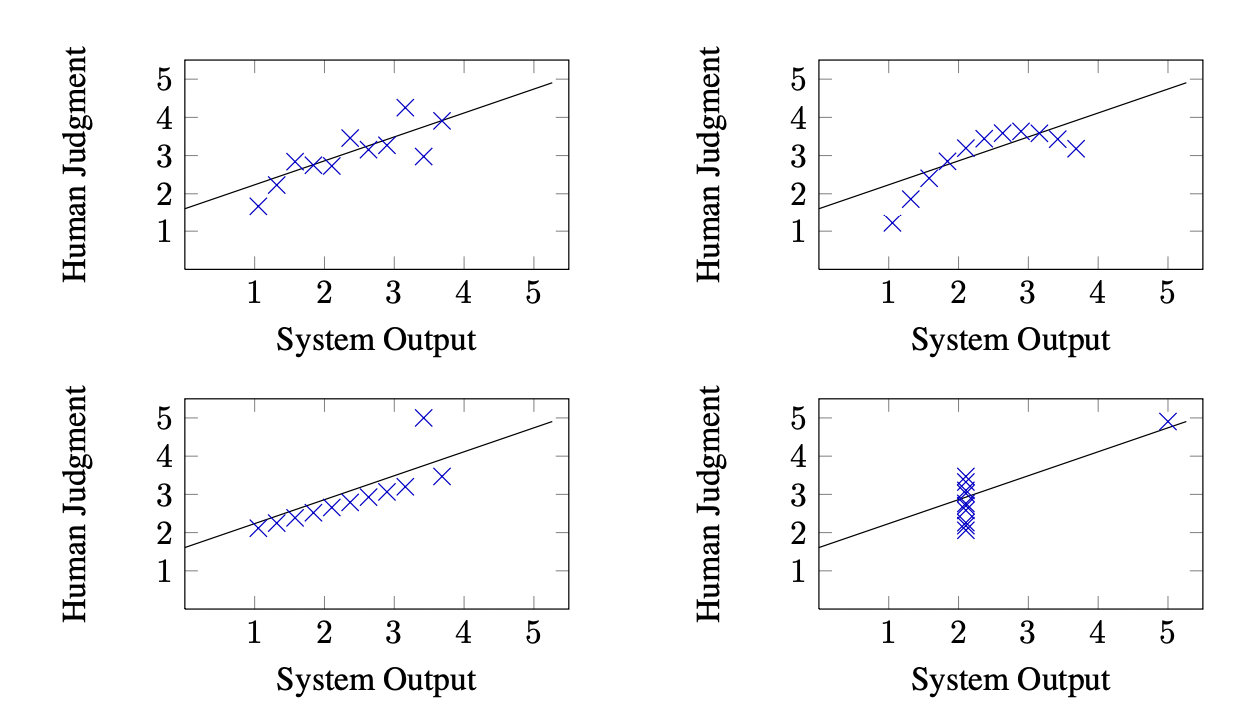
위의 예시는 Anscombe’s quartet이라고 불리며 모두 0.816의 상관관계를 보인다. 즉, 모든 것에 대해 동일한 성능을 가졌다고 평가한다는 것이다. Pearson 상관계수는 비선형 관계에 대해 예민하다. 따라서 outlier들에 대해 매우 예민해 합리적으로 가장 높은 성능을 보이는 왼쪽 아래가 outlier하나로 인해 성능이 매우 떨어지 게 된다. 오른쪽 아래는 하나의 수치가 적합하게 나오자 모든 것이 왜곡되어 좋은 성능을 보인다고 말한다.
이처럼 피어슨 상관계수는 선형 관계와 정규 분포를 따를 때에만 판별에 효과적이며 이는 결과적으로 비교에 용이하지 않다고 말한다. 이를 보완하기 위해 Spearman rank 방식이 오히려 더 좋다고 말한다.
상관관계보다 단순히 ranking을 매기는 방식인 Spearman ranking은 비선형 관계와 이상치에 매우 강력하다.
또한 STS 모델이 적용되는 task 특성상 정확한 수치가 필요하지 않은 경우가 많다. 검색을 사용했을 때에도 threshold 역할을 통해 1차 filter를 하는 역할을 맡으며 top k를 선정하는 방식에서도 상위권만 정확히 매치하면 될 뿐, 하위 순위에 대해 정확한 수치를 내보낼 필요가 없다. 따라서 Spearman의 ranking 방식이 매우 효과적일 수 있다고 말한다. 하지만 이 역시 순위를 통해 결과가 왜곡될 수 있다는 단점이 존재한다. 따라서 연구진은 3가지 측정 방식을 더했다.
1) normalized Cumulative Gain (nCG)
CG는 추천시스템에서 많이 사용되는 평가지표이다. 보통 CG는 상위 p개의 추천 결과들의 관련성(rel)을 합한 누적값을 의미한다. 논문의 수식은 아래와 같다.
rel은 관련이 있는지 없는지에 따라 0 또는 1의 Binary 값을 갖거나, 문제에 따라 세분화된 값을 가질 수 있다. 해당 실험에서는 결과 값들에 대한 평가 지표를 통해 나타난 값에 대한 유사도를 보고자 한다.
특히나 CG가 아닌 nCG를 사용해 normalized 시킨 후 비교하고자 했다. normalized 방식은 max값을 분모로 넣는 형태로 수식은 아래와 같다. iCGk는 최대값을 의미한다. k가 n이 될 때에는 수치가 1이 나타날 수 밖에 없다(top n개를 비교한다는 것은 결국 의미가 없으므로)
2) normalized Discounted Cumulative Gain (nDCG)
CG에서 약간 변형된 형태로 DCG는 CG에서 랭킹 순서에 따라 점점 비중을 줄여가는(Discounted) 관련도를 계산하는 방법이다. 랭킹 순서에 대한 로그함수를 분모에 두면, 하위권으로 갈 수록 같은 rel 대비 작은 DCG 값을 갖게 하여 하위권 결과에 패널티를 주는 방식이다. 즉, 랭킹이 낮아질 수록 점점 그 점수를 낮게 주는 방식이다.
(1)
(2)
기본적인 형태는 (1)이고, 랭킹의 순서보다 관련성에 더 비중을 주고싶은 경우 (2)를 사용한다. 즉, (2)의 경우 순위가 내려가며 분모가 커지기도 하면서 관련성이 매우 다른 경우(큰 경우에는 순서가 바뀔 것이니 없을 것) 더 높은 점수차이가 나도록 만들어 평가하려고 한다. 이와 함께 특정 순위 까지는 discount를 하지 않는 방법 등의 다양한 변형식을 사용하기도 한다.
3) Accuracy
가장 기본적인 평가지표이지만 STS 점수는 연속적이기에 계산을 하는 것은 쉽지 않다. 따라서 임의적으로 구간을 만들고 동일한 구간에 놓이는지를 평가했다.
이와 함께 조화 평균과 macro 평균을 사용했으며 k는 3, 5, 10을 사용해 비교했다.
📃 결과
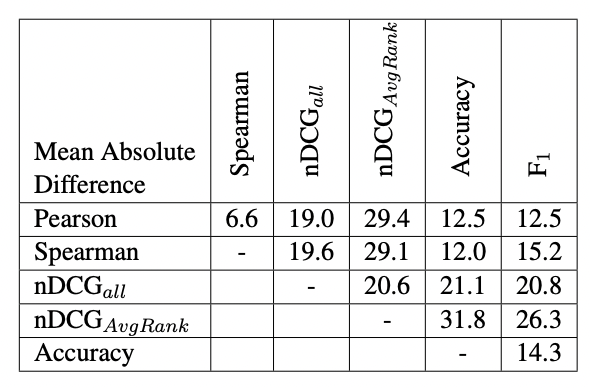
연구에서는 평가를 위해 사용되었던 지표들을 교차로 변경할 때에 얼마나 차이가 나타났는지를 검사했다. 이때에도 피어슨 상관계수와 다른 평가지표의 상관성은 매우 천차만별로 나타났다. 특히나 nDCG와는 매우 큰 격차를 보였다.
🧪 3. 실험을 통한 평가
...
we expect that STS systems achieving good results in an intrinsic evaluation should in general lead to better results in the task and STS systems with weak results should in general lead to worse results for the STS based task.
연구진들이 증명하고 싶었던 것은 STS에서 높지 않은 성능을 보이는 모델은 STS를 베이스로 한 task에 대해서도 성능이 좋을 수 없다는 것을 보이고 싶었다. 그러나 이를 명시적으로 계산하는 것은 불가능하다.
We can measure the resemblance of two rankings using the Mean Absolute Difference (MAD), the Mean Squared Difference (MSD), or the Spearman’s rank correlation coefficient ρ.
따라서 유사성을 MAD, MSD, Spearman ranking을 통해 나온 계수 p를 통해 분석하고자 했다. 여기서 여러 개의 모델이 있으며 i번째 모델의 IR은 Intrinsic Evaluation, ER은 Extrinsic evaluation을 통해 나타나는 ranking을 의미하며 아래와 같은 수식을 통해 계산된다.
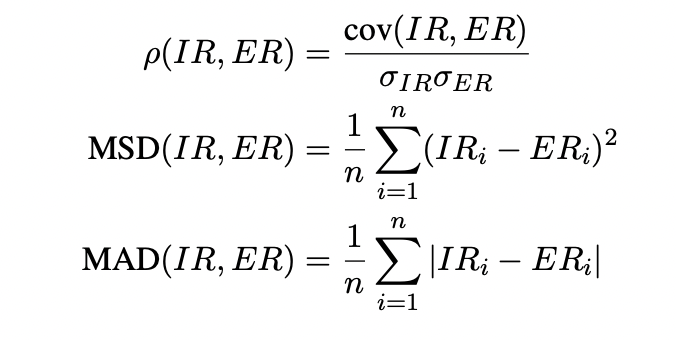
여기서 는 각 분포의 표준편차를 의미한다. 상관관계가 높을 수록 MAD와 MSD는 0으로 근사하고 p는 1로 근사하게 된다.
🔬 Experiments
3가지 STS based task들과 14가지 모델을 통해 연구를 시작했다. 그 전에 먼저 배포된 데이터셋을 통해 STS intrinsic evaluation을 진행했다. 그리고 이는 앞서 소개된 nCG등과 같은 방법들을 포함 16가지의 방식을 통해 성능 측정을 진행했다.
그리고 STS based task들의 extrinsic evaluation을 실시해 상관관계를 분석하고자 했다.
3가지 task는 아래와 같다.
1) Text reuse detection.
- near copy, light revision, heavy revision, and non plagiarized으로 labeling이 되는 task이며, 정확도로 성능을 측정한다.
- 10 fold CV를 통해 가장 높은 성능의 classifier를 선택하는 식으로 진행되었다.
2) binary classification task with the goal to identify whether two articles are related or not
- 보통 문서에 작가가 더 많은 논의가 다루어진 article을 링크해두기 마련인데 이를 활용해 데이터셋을 만들었다.
- 10 fold CV를 통해 가장 높은 성능의 classifier를 선택하는 식으로 진행되었다.
3) detect the two articles that are related to the target article in a set of articles from ZEIT Online.
- target article에 대해 높은 유사도를 가진 문서를 탐색하는 것
- 위에서는 두 문서가 관련이 있느냐를 평가하는 것이라면 여기서는 Retrieval을 한다.
Results
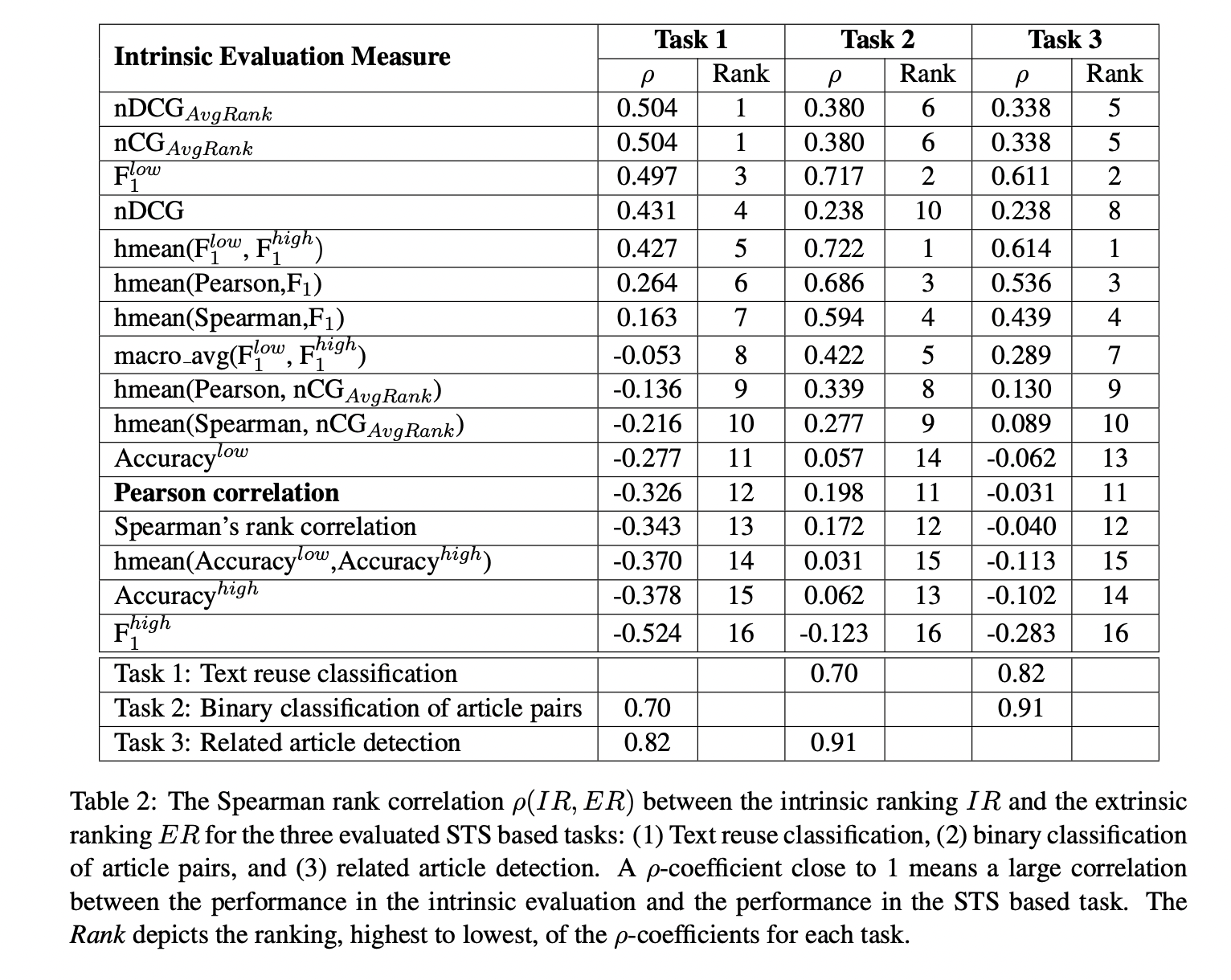
각각의 task에 대해 제일 잘하는 모델과 못하는 모델의 성능은 다음과 같다.
- 70%, 43%
- 77%, 48%
- 67%, 6%
이러한 ER이 등장했을 때 STS에서 잘 하는 모델과 잘 하지 못하는 모델을 분석하고자 했다. 각 방식에 대한 유사도를 ranking을 통해 결과로 나타냈다. 결과에서는 p로만 나와있는데 MAD와 MSD로 나타난 ranking이 거의 유사했기에 이렇게 표현했다.
Discussion
위의 결과를 통해서 볼 때 Pearson 상관계수와 Spearman rank는 STS 모델 능력 측정에 전혀 유효하지 못하고 있음을 보이고 있다. 오히려 음수가 나오며 제대로 못하고 있는 모습이 나타난다. 엔지니어링 관점에서 볼 때 피어슨 상관계수를 사용하는 것은 심각하게 위험한 행위라고 말한다.
다른 평가지표는 이보다는 나은 상황이다. 특히나 STS 기반으로 잘 하는 모델들이 주로 STS based인 3가지 task에서도 잘 하고 있음을 확인할 수 있었다. 이는 task 종류가 상이하지만 잘 하는 모델이 잘한다는 것을 확인 할 수 있었다.
하지만 1등 모델을 모두 예측하는 것에 대해서는 실패했다. 오히려 2등부터 6등 위치 사이에 배치시키기도 했다. 그리고 STS를 가장 잘했던 모델은 오히려 3가지 task에 대해서는 6, 9, 12등을 달성했다.
🚀 그래서 무엇을 쓰면 좋을지에 대한 제안
STS task에 잘 하는 모델은 일반적으로 STS based task에 대해서도 잘 한다. STS에서 유사한 문장 pair를 잘 탐색하는 모델은 다른 데이터셋에 대해서도 그러한 것을 잘 할 것이라고 말한다. 하지만 STS와 STS based tasks들은 다른 필요조건들이 있기에 이들을 잘 확인해야 한다. 따라서 STS based task를 3가지 차원으로 바라볼 필요가 있다고 말한다.
Cardinality
얼마나 많은 텍스트들이 얼마나 많은 다른 문장들과 비교되는가. 1:1일지 1:n인지
Set of interest
어떤 요소가 결과로 사용될지
- ALL
- Threshold
- K - Best
Information
어떤 결과값이 나타나기를 바라는가
- Value
- Rank
- Classification
이러한 것들로 총 9가지로 task를 나누어 거기서 사용되면 좋은 평가지표들을 공개했다
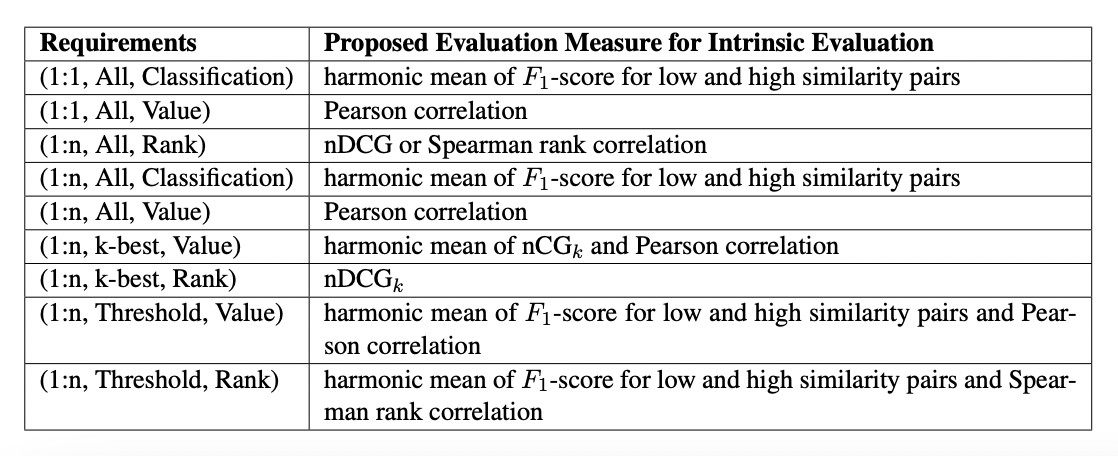
이들을 필수적으로 사용해야 한다기 보다 피어슨 상관계수 외에 좋은 성능을 보였던 평가지표를 반영해 모델을 선택하는 것이 도움이 될 수 있다고 말한다.
✏️ 후기
서술형 자동 채점 프로젝트를 진행하며 가장 어려웠던 것이 평가지표를 스스로 정의하는 것이었다. 채점의 정확성은 모호하기도 하며 사람마다 다르고 어떤 채점이 "좋은" 채점인지 스스로 가이드라인을 만들며 구축하는 것이 어려웠다.
Kaggle이나 대회를 진행하다보면 주최 측에서 제안한 방식으로만 모델을 평가하고 선택하는 경우가 많다. 하지만 이는 항상 옳은 길로 인도하지 않는다고 말한다. STS에서 보편적으로 사용되던 피어슨 상관계수마저 너무 높지 않은 성능을 보이고 있었다.
fine-tuning을 할 때에 평가지표가 하나로만 특정하는 것이 실제 환경에서 모델의 robust성을 해치는 경우가 많다. 이를 보완하기 위해 soft-voting을 사용하는 것처럼 task에 따라 평가지표를 다른 각도로 조정해보는 것이 필요할 것 같다. 유명한 논문은 아니었으나 생각할 지점들을 제공해주었다.
참고 : https://velog.io/@juunho/Normalized-Discounted-Cumulative-Gain-nDCG
