RNN 역시 최적화를 오차역전파를 통해 이루어진다. RNN의 오차역전파에 대해서 학습을 진행을 하던 중에 수식을 이해하고자 직접 Gradient를 구하기 위해 미분을 진행했는데 구글링을 통해 나타난 결과와 상이해 당황했었다.
하지만 수식을 찬찬히 살펴보니 동일한 내용이었고 이를 TIL로 정리하고자 했다.
💡 RNN의 역전파 흐름부터 알아보자
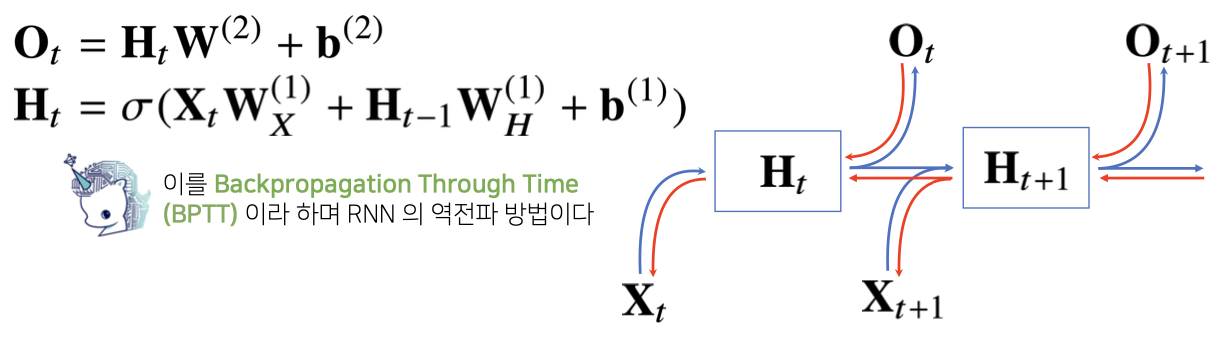
RNN은 기존 머신러닝 알고리즘과 다르게 과거 Sequence에 나타났던 정보들이 그림에서는 을 만나서 잠재변수 로 변화하게 된다. 이 정보는 다음 뉴런으로 이어져서 해당 뉴런의 결과값이자 잠재변수를 도출하는 것에 영향을 미치게 된다.
즉, 우리의 기존 정보들은 가 중첩되어 가면서 정보들이 계속해서 이어지게 되는 것이다. 그리고 해당 뉴런에서 추가적으로 주어지는 현재 정보는 로 들어와 를 만나고 결과 값을 구성하게 된다.
이때, 와 는 모든 Sequence에 대해서 동일한 벡터이다. 우리가 예측을 함에 있어서 각 Sequence에 대해 동일한 가중치를 부여해야만 일정하고 균일된 값을 계산할 수 있기 때문이다.
그렇다면 오차역전파는 어떠한 방식으로 일어날까? RNN의 기본적인 오차역전파는 모든 O 즉, ... 까지의 오차역전파가 종합되어 와 에 영향을 미칠 것이다.
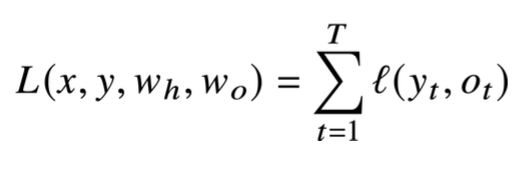
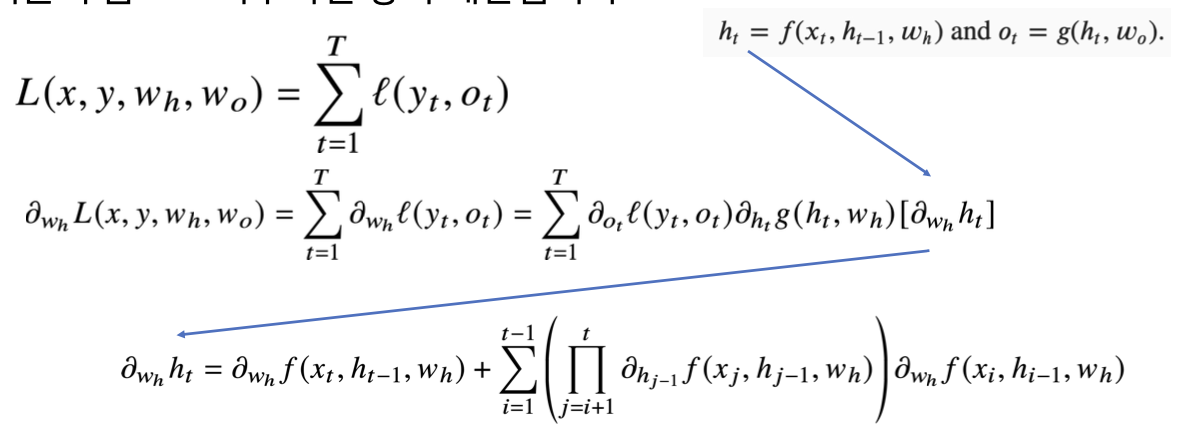
하지만 우리가 수학적으로 도출할 때, 하나의 결과값에 대한 오차역전파만 구할 수 있다면 나머지는 더해주고 종합해주는 방식만 구하면 된다. 따라서 하나의 결과인 에 대한 오차역전파만 수학적으로 구현할 수 있으면 된다.
💡 RNN의 오차역전파의 수학적 구현
그렇다면 마지막 결과값인 에 대한 오차역전파만 수학적으로 구현해보자. 해당 구조는 우리가 해석해야할 RNN 구조이다.
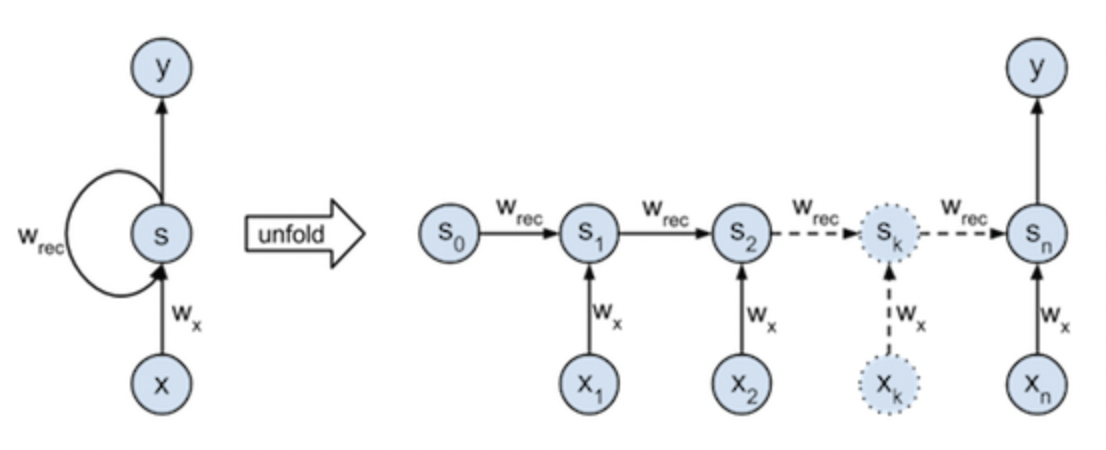
여기서 의아하실 분들이 있으실 수 있다. 의 결과값이 activation function을 거치지 않고 그대로 결과값으로 나타나기 때문이다. 사실, RNN의 activation function은 하이퍼볼릭 탄젠트, sigmoid 등 다양한 함수가 사용되는데 역전파의 흐름을 위한 이해에는 필수적이지 않기 때문에 대부분의 역전파 공식에서 제외하고 고려된다.
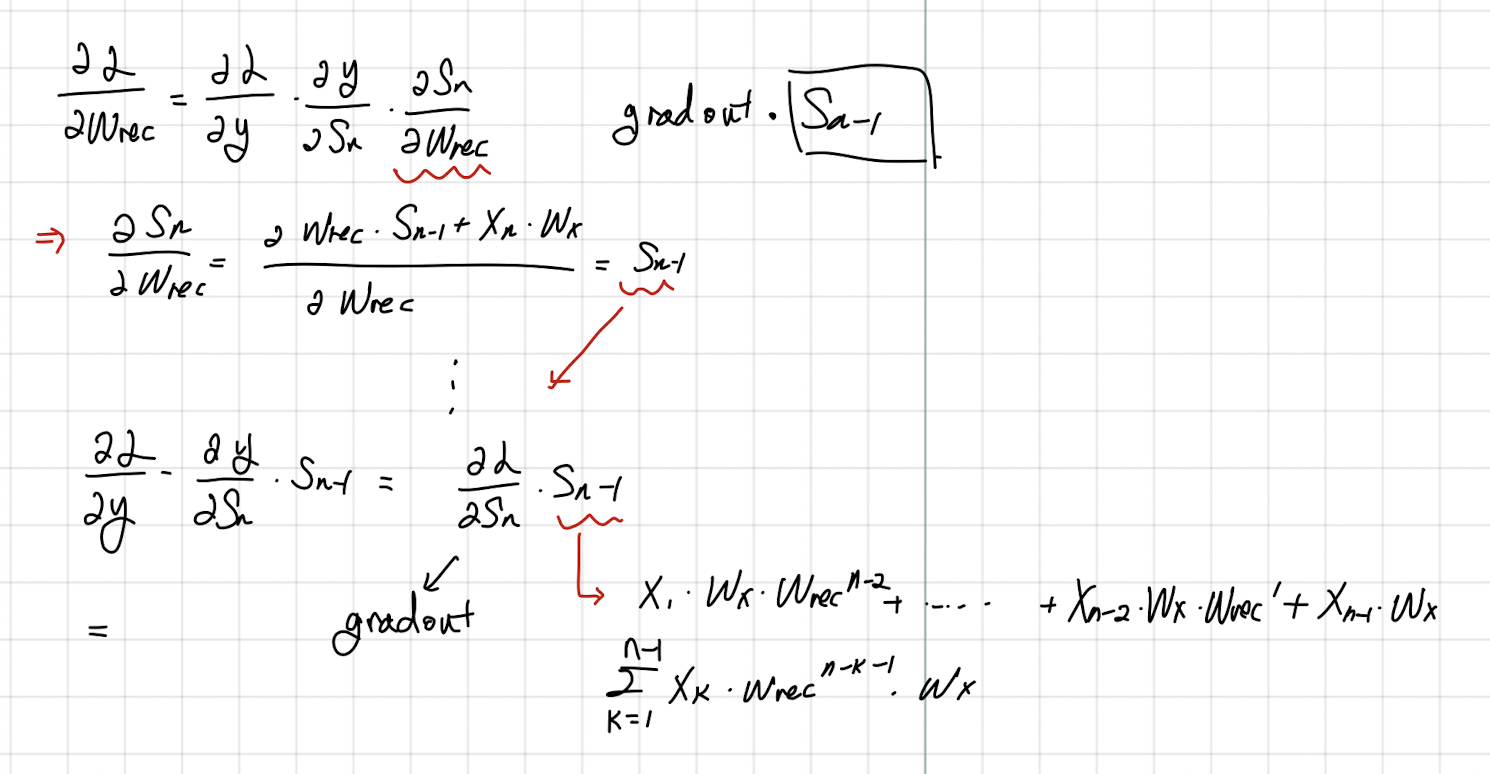
우리가 구현해야 하는 오차역전파는 와 에 대한 것이다. 먼저, 미분을 하기 전, 해당 수식부터 이해하는 것이 필요하다.
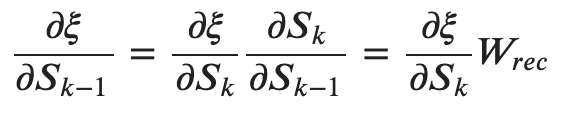
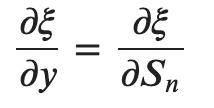
위의 두 수식은 직관적이므로 굳이 설명하지는 않겠다. 이후 이들을 통해 에 대해 미분을 진행하면
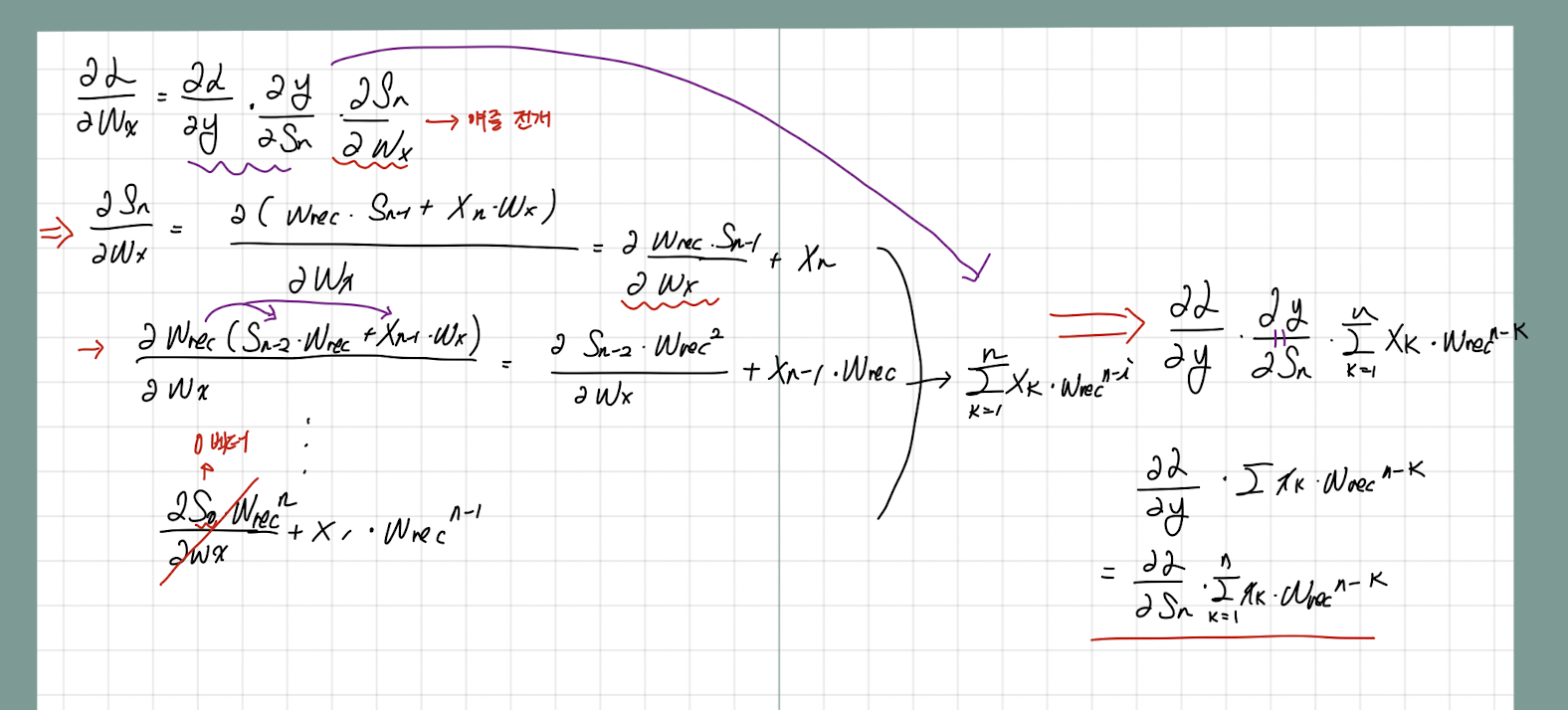
다음과 같다(손글씨 죄송함당,,,) 그런데 RNN에 대한 미분을 구글링해보면 이러한 결과가 아니라 이처럼 나온다.
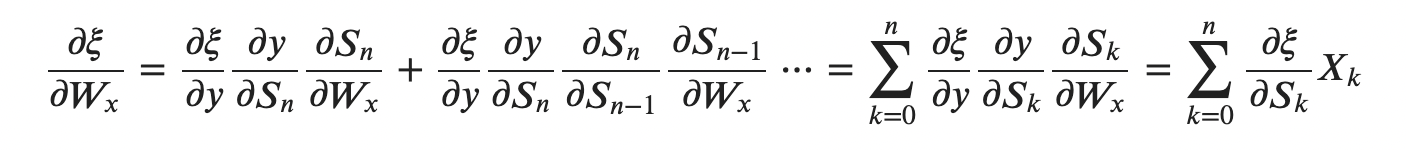
처음에는 두 결과가 다른 것이라고 생각해서 미궁 속에 빠졌었다. 그러나 생각해보면 Loss함수에 대한 미분은 결과적으로 Loss func * 가 계속 중첩되는 형태로 이어질 것이다. 즉, 위 아래의 수식이 동일한 수식이라는 것이다.
그렇다면 왜 저런 과정으로 Gradient가 치환될 수 있을까? 는 각 단계에서 지속적으로 나타나는데 해당 Sequence가 미치는 영향도들을 종합적으로 고려해주는 것을 통해 각 Gradient를 계산할 수 있기 때문이다.
(이 부분이 저어어어엉말 어려웠다..)
마지막으로 에 대한 미분을 진행해보자.
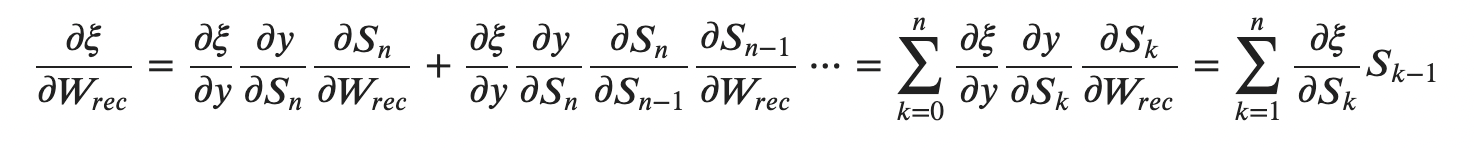
위 아래 수식은 동일한 것이며, 해당 수식들을 코드로 구현하면 다음과 같다
def output_gradient(y, t):
return 2. * (y - t)
def backward_gradient(X, S, grad_out, wRec):
"""
X: input
S: 모든 input 시퀀스에 대한 상태를 담고 있는 행렬
grad_out: output의 gradient
wRec: 재귀적으로 사용되는 학습 파라미터
"""
# grad_over_time: loss의 state 에 대한 gradient
# 초기화
grad_over_time = np.zeros((X.shape[0], X.shape[1]+1))
grad_over_time[:,-1] = grad_out
# gradient accumulations 초기화
wx_grad = 0
wRec_grad = 0
for k in range(X.shape[1], 0, -1):
wx_grad += np.sum(
np.mean(grad_over_time[:,k] * X[:,k-1], axis=0))
wRec_grad += np.sum(
np.mean(grad_over_time[:,k] * S[:,k-1]), axis=0)
grad_over_time[:,k-1] = grad_over_time[:,k] * wRec
return (wx_grad, wRec_grad), grad_over_time여기까지 오늘 TIL 끄으으읕..! 나중에 분명 다시 공부햐야 제대로 머리에 박힐 것 같다.
참고자료 : 네이버 부스트캠프 자료
https://aikorea.org/blog/rnn-tutorial-3/
