
머신러닝에는 확률론이 상당히 중요하다. 본인 역시 인턴 면접에서 확률과 통계에 대한 질문을 받았었다(ex, 기대값, 감마분포 등등) 확률론은 언뜻 보면 매우 쉬워보이지만 확률분포로 넘어가게 되면 그 부분에서 상당히 난해하고 어려웠다. 오늘 역시 공부를 하다가 확률 분포에 대해 깊게 이해하고자 TIL 소재로 뽑았다.
💡 확률 분포는 데이터의 초상화
우리가 관찰한 데이터 공간을 라고 해보자. 여기서 는 이 데이터 공간에서 데이터를 추출한 분포이다. 우리는 이 의 분포를 정확히 알기는 어렵다. 그렇기에 이데아와 현실처럼 데이터의 초상화라고 부르는 것이다.
우리가 관찰하는 데이터는 확률변수로 이해하고 데이터 공간 상에서 관측 가능한 데이터이다. 확률 변수는 우리는 함수로서 이해하게 되는데 임의로 random하게 이 데이터 공간에서 관측하게 되는 함수로 이해하게 된다.
그렇게 우리가 관측한 데이터를 추출할 때 확률 변수를 이용하게 되고 추출한 데이터의 분포를 ~ 라고 하게 된다.
확률변수는 확률분포 에 따라 이산형과 연속형 확률변수로 구분하게 된다. 이때의 분류는 데이터 공간 에 의해서 결정되는 것이 아니라 확률변수의 확률분포의 종류 즉, 의 종류에 따라 구분되는 것이다.
가령, 우리가 실수의 공간에서 나올 수 있는 값들이 이산적이라면 이산형 확률변수가 되는 것이다.
이산형 확률변수는 확률변수가 가질 수 있는 경우의 수를 모두 고려해 확률을 더해서 모델링한다.
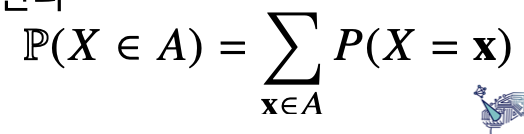
이를 우리는 확률질량함수라고 부른다.
연속형 확률변수는 데이터 공간에 정의된 확률변수의 밀도 웨어스의 적분을 통해 모델링한다.
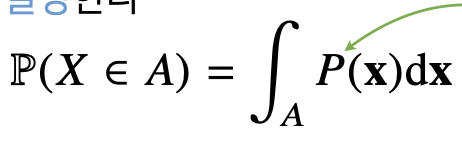
이를 우리는 확률밀도함수라고 부른다.
이러한 연속확률변수는 정규분포, 지수항분포, 감마분포 등 다양한 분포에서 사용되므로 중요하다.
💡 결합분포 (joint distribution)
우리가 확률변수를 어떻게 접근하는가에 따라 분포의 성질이 달라지게 되고 확률분포에 따라서 모델링하는 방법이 달라지게 된다.
이때 전체 데이터가 주어진 상황의 분포를 결합분포 라고 부른다.
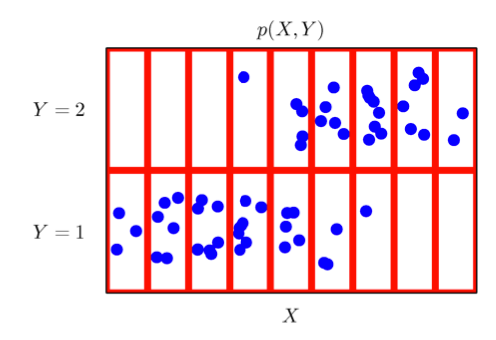
위의 분포처럼 실수 데이터 공간이지만 데이터 공간을 빨간색으로 나눈 각각 공간을 이산형으로 파악해 접근하게 되면 이산 확률 분포처럼 생각하게 될 수 있다.
즉, 원래 확률 분포 가 연속이냐 이산인가에 따라서 의 분포를 연속, 이산으로 구분하는 것 아니다. 모델링 방법에 따라서 결합분포는 결정되고 원래 데이터의 확률 분포를 추출하는 와 실증적 추출은 다를 수 있다는 것이다.
💡 주변확률분포(marginal distribution)
결합 분포가 주어진 상황에서 각각의 입력 x에 대해서 y를 더해주거나 적분을 하게 되면 입력 x에 대한 주변확률분포(marginal distribution)인 를 구할 수 있다.
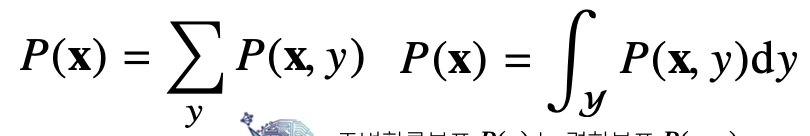
이 경우에는 주변확률분포를 통해 x에 대한 정보를 추정 가능하지만 y에 대한 정보를 주지는 않는다. 하지만, 를 구한다면 y에 대한 정보도 추정이 가능하다.
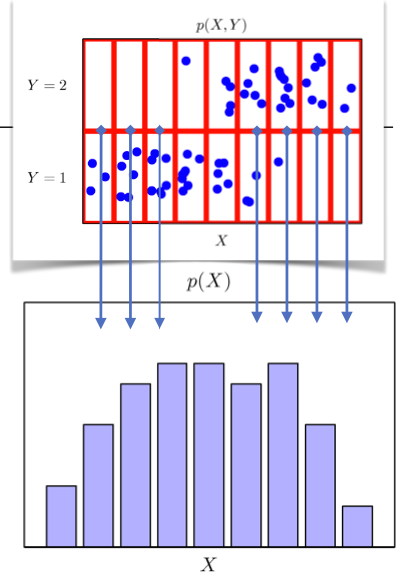
이를 통해 많은 통계적 분석이 가능하다.
💡 조건부확률분포(Conditional Distribution)
조건부확률분포는 y가 주어져 있는 상황에서 x의 확률 분포를 구할 수 있고 반대로 x가 주어진 상황에서 x의 확률 분포를 구할 수도 있다. 이때 전자를 라고 할 수 있을 것이다.
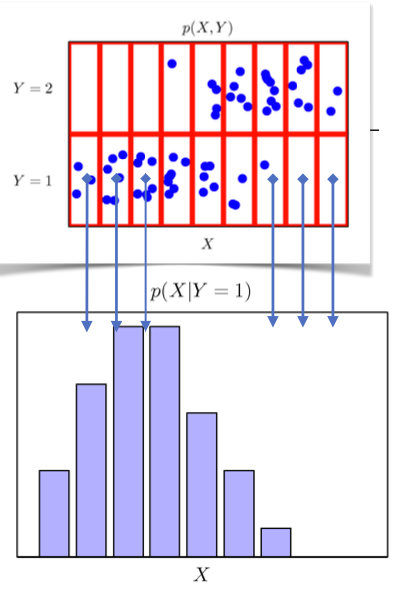
위의 예시의 경우에는 Y가 1인 경우의 X의 분포를 표현한 것이다. 는 특정 클래스가 주어진 조건에서 데이터의 확률분포를 보여주는 것이다. 이때 조건부확률분포는 두 변수의 통계적 관계 모델링이나 예측 모형 생성에 이용이 가능하다. 이처럼 는 데이터 공간에서 입력 x와 출력 y 사이의 관계를 모델링하는 것이다. 주어진 클래스에 x가 어떻게 분포되었는지는 따라서 조건부확률분포를 이용하는 것이 좋다.
결과적으로 확률분포를 통해서 데이터를 우리가 관심을 가지는 관점에 따라서 초상화를 그릴 수 있다는 것이다.
✏️ 조건부확률분포와 기계학습
특히나 조건부확률은 기계학습에서 매우 주요하다.(베이시안 등) 는 우리에게 데이터 x가 주어졌을 때 정답이 y일 확률을 의미하는데 이는 달리 말하면 우리가 만든 모델이 데이터에 대해서 label 혹은 예측값을 y라고 예측할 확률을 의미하는 것이다.
이는 분류문제에서 사용되는 softmax와 매우 유사한데, 데이터 x로 부터 추출된 특징패턴(잠재변수) 와 가중치행렬 W을 통해 조건부확률 를 계산하는 것은 라고 표현할 수 있다.
회귀문제의 경우에는 연속 확률변수를 다루기 때문에 확률로 해석하기는 어렵고 밀도함수로 고려를 해야 하는데 이 경우에는 조건부기대값을 추정한다.
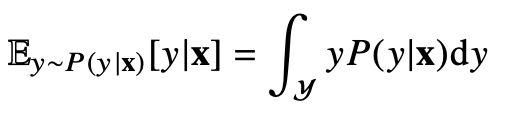
조건부 기대값은 조건부밀도함수에 y를 곱해서 적분을 해주는 것으로 추정해준다.(확률과 label의 곱)
이때 조건부 기대값은 회귀함수에서 사용하는 손실함수인 L2 norm을 최소화하는 함수와 일치하게 된다. 즉, 를 최소화하는 함수 f(x)와 일치하게 되는 것이다. 이는 이산분포에서도 동일하게 적용된다. 이 부분의 수학적 증명은 이후에 다루겠다.
물론, 조건부 기대값이 아닌 예측 통계량을 사용할 수도 있다. 예를 들어 관찰하는 데이터에 대해 강건하게 예측하는 경우에는 중앙값으로 추정하는 것도 가능하다. 즉, 우리의 목적과 목표에 따라서 추정량이 달라질 수 있다는 것이다.
✏️ what is 기대값?
확률분포가 주어지면 데이터를 분석하는 데 사용 가능한 여러 종류의 통계 적 범함수(statistical functional)를 계산할 수 있다. 기대값(expectation)은 데이터를 대표하는 통계량이면서 동시에 확률분포를 통해 다른 통계적 범함수를 계산하는데 사용되는 도구로 볼 수 있다. 즉, 데이터의 분석에 있어서 여러 가지 방면으로 사용될 수 있다.
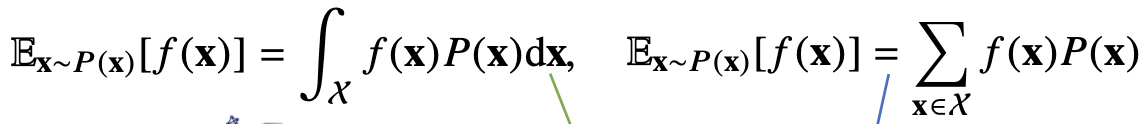
위의 식의 방식을 통해 기대값을 정의해준다. 그리고 이들을 통해 분산, 첨도, 공분산 등 여러 통계량을 계산할 수 있다.
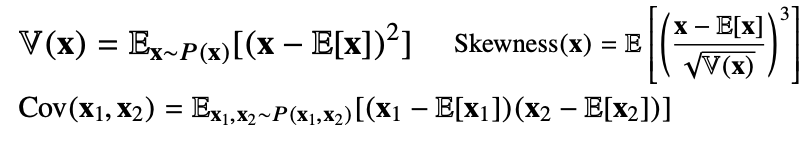
이처럼 기대값을 통해 여러 통계량을 도출해낼 수 있다.
🔥 몬테카를로 샘플링
기계학습의 많은 문제들은 확률분포를 명시적으로 모를 때가 대부분이다. 확률분포를 모를 때 데이터를 이용하여 기대값을 계산해야 하는데 몬테카를로(Monte Carlo) 샘플링 방법이 사용된다. 확률분포를 몰라도 샘플링을 할 수 있다면 기대값 계산이 가능하다.
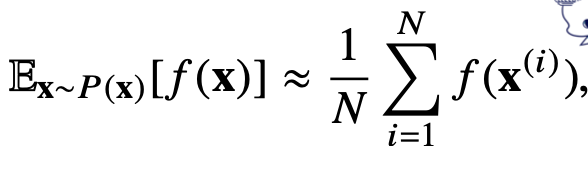
위의 식에서 볼 수 있듯이 타겟으로 하는 함수에 샘플링한 데이터를 대입한 후에 데이터에 따라서 나타나는 값들에 산술평균을 계산하면, 기대값에 근사하게 된다.
이때, 몬테카를로는 이산형이든 연속형이든 상관없이 성립하며, 샘플링을 하는 분포에서 독립적으로 샘플링을 해야만 몬테카를로 샘플링이 적용된다는 것이다. 즉, 몬테카를로 샘플링은 독립추출만 보장된다면 대수의 법칙에 의해 수렴성을 보장한다.
🔥 몬테카를로 샘플링 예제
ex) 함수 의 [-1,1] 상에서의 적분값 구하기.
위의 함수는 확률분포가 아닌 공간에서의 적분이기 때문에 해석적으로 구하는 것은 불가능하다. 그러나 몬테카를로 방법을 통해서 함수에 대한 적분을 근사시킬 수 있다.
적분 구간이 [-1,1]이기 때문에 -1 부터 1 사이에 균등분포에서 데이터를 샘플링하게 된다. 확률 분포로 변화시켜주기 위해서는 적분 구간이 2이기 때문에, 적분값을 1/2로 나누게 되면 균등분포를 사용하는 것과 동일한 적분이 된다.
균등분포는 연속확률변수 가 한 구간의 임의의 점을 '동일한 확률'로 취할 때 는 그 구간에서 균등분포를 따른다고 한다. 균등분포를 고른분포 또는 균일분포라고 하기도 한다.
이때 균등분포의 평균(=기대값의 도출은 다음과 같다)
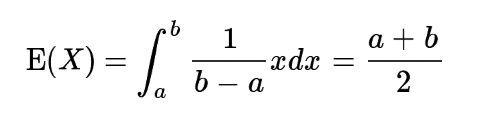
즉, 위의 함수를 밀도함수로 파악하고 기대값을 도출하는 식으로 표현하면 그것은 우리가 몬테카를로 방법을 통해 추정가능한 수치로 변화하게 된다.
이 경우에는 기대값을 계산하는 방법으로 적분값을 구할 수 있다.
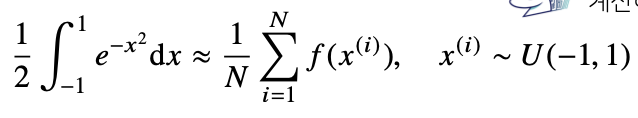
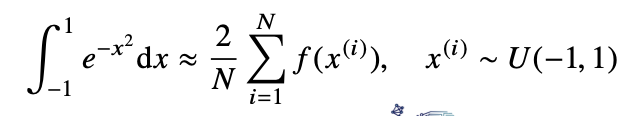
결과적으로는 마지막의 공식을 통해 적분을 해줄 수 있다.
참고 : https://terms.naver.com/entry.naver?docId=3338148&cid=47324&categoryId=47324
네이버 부스트캠프 자료
