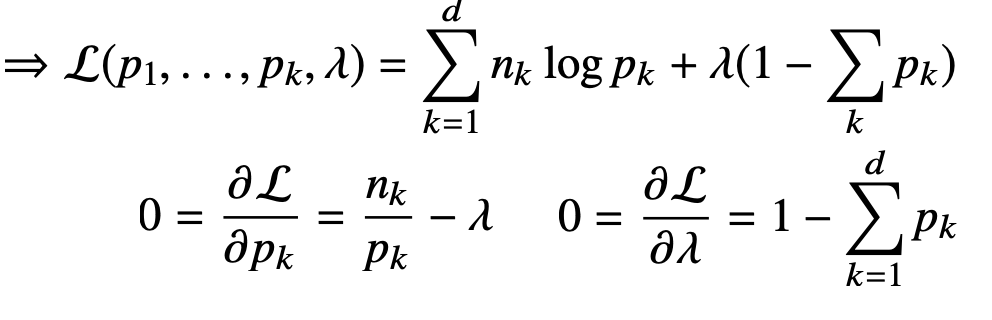이번주차 강의에서 아마 가장 어려웠던 강의가 아니었나 싶다.. 작년 즈음에 머신러닝 이론에 대한 공부를 하던 중에 감마분포를 접하게 되었는데 검은 것은 글씨요 흰 것은 웹페이지 배경이니라...를 느껴버렸...다... ㅋㅋㅋㅋㅋㅋㅋㅋ 그래서 오늘은 가장 기초인 모수와 최대가능도(우도)부터 학습을 시작하고자 한다. 이 내용은 전에 인공지능을 위한 수학이라는 책에서도 봤기에 보는 것을 추천한다. 아무튼 잡설 끝.
💡 통계학과 모수
통계적 모델링은 적절한 가정 위에서 확률분포를 추정(inference)하는 것이 목표이며, 기계학습과 통계학이 공통적으로 추구하는 목표이다. 그러나 유한한 개수의 데이터만 관찰해서 모집단의 분포를 정확하게 알아낸다는 것은 불가능하므로, 근사적으로 확률분포를 추정할 수 밖에 없다. 확률분포도 매우 다양하기에 어떠한 확률분포를 사용(가정)해서 모델링하냐도 매우 중요한 선택의 문제이다.
예측모형의 목적은 분포를 정확하게 맞추는 것보다는 근사적으로 즉, 데이터와 추정 방법의 불확실성을 고려해서 예측의 위험을 최소화하는 방향으로도 충분하다. 왜냐하면 그 이상은 불가능하기 때문...
데이터가 특정 확률분포를 따른다고 선험적으로(a priori) 가정한 후 그 분포를 결정하는 모수(parameter)를 추정하는 방법을 모수적(parametric) 방법론이라 한다.
예를 들어, 정규분포를 가지고 모델링한다면, 정규분포에서는 평균과 분산과 같은 모수가 매우 중요하다. 평균과 분산의 추정을 통해서 데이터를 학습하는 방법을 모수적 방법이라고 말한다
반대로 특정 확률분포를 가정하지 않고 데이터에 따라 모델의 구조 및 모수의 개수가 유연하게 바뀌면 비모수(nonparametric) 방법론이라 말한다. 사실, 기계학습의 많은 방법론은 비모수 방법론이다. 확률분포에는 모수라는 것이 적용되기 마련이고 어떤 확률분포를 가지고 모델링할 때는 모수가 필수적으로 수반된다.
이때, 비모수방법론은 모수가 없다는 것이 아니라 모수가 무한히 많거나 모수의 개수가 데이터에 따라서 바뀌는 경우이다. 비모수 vs 모수 어떤 가정을 미리 부여하는가 그렇지 않은가의 차이이다.
💡 How to 확률분포 가정?
데이터를 보고 특정 확률분포를 가정을 할때는 데이터의 전체적인 모양을 관찰하고 확률분포를 가정한다. ex, 히스토그램, 통계치 등 등
- 데이터가 2개의 값(0 또는 1)만 가지는 경우 → 베르누이분포
- 데이터가 n개의 이산적인 값을 가지는 경우 → 카테고리분포, 다항분포 등
- 데이터가 [0,1] 사이에서 실수값을 가지는 경우 → 베타분포 등
- 데이터가 0 이상의 값, 혹은 실수 전체를 가지는 경우 → 감마분포, 로그정규분포 등
- 데이터가 R 전체에서 값을 가지는 경우 → 정규분포, 라플라스분포 등
기계적으로 확률분포를 가정하는 것이 아니라, 데이터를 생성하는 원리를 먼저 고려하는 것이 원칙이다. 데이터를 관찰한 후에 어떤 확률본포를 적절한지를 분석하고 선택해야 한다. 모수 추정 후 통계적 검증을 통해 검정을 해야 한다
💡 데이터를 통한 모수 추정
데이터의 확률분포를 가정했다면 모수를 추정해볼 수 있다. 예를 들어 정규분포의 경우, 모수는 평균 μ 과 분산 σ2 으로 이를 추정하는 통계량(statistic)은 다음과 같다.
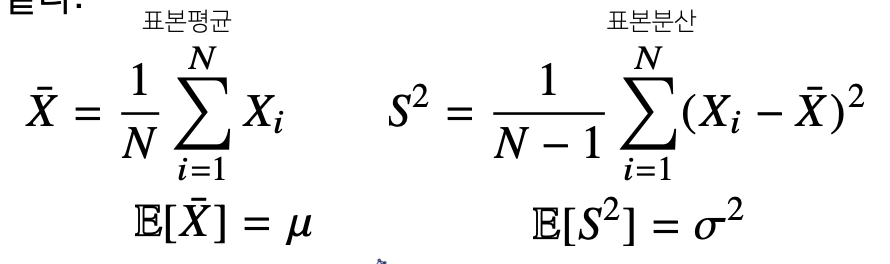
표본평균은 주어진 데이터의 산술평균이다. 이 표본평균의 기대값은 원래 데이터에서 관찰되는 평균과 일치하게 된다. 이 표본평균을 통해 표본 분산을 도출할 수 있다. 이때, 특이하게 산술평균을 시켜줄 때 N-1개로 나누어서 정의한다. 이는 불편추정량을 구하기 위해서이며 이를 통해 기대값을 취했을 때 원래 모집단의 모수와 일치하도록 만들어주기 위함이다.
참고 : https://blog.naver.com/ao9364/222023124818
이런 식으로 주어진 데이터를 가지고 데이터의 확률 분포의 모수를 추정할 수 있고 데이터의 정보와 성질을 취합할 수 있고 이를 통해 예측을 하거나 의사결정을 할 때 통계량이 사용된다.
통계량의 확률분포를 표집분포(sampling distribution)라 부르며, 특히 표 본평균의 표집분포는 N 이 커질수록 정규분포 𝒩(μ, σ2/N) 를 따릅니다.
이때의 표집분포는 표본분포와는 다르다. 표본분포는 표본의 분포, 표집분포는 표본분포에서의 추정량(ex, 표본평균, 표본분산)의 분포를 의미한다. 특히, 표본평균의 표집분포는 데이터를 많이 모을 수롤 정규분포를 따르며 이를 중심극한정리(Central Limit Theorem)이라 부르며, 모집단의 분포가 정규분포를 따르지 않아도 성립한다.(모집단의 본포와는 상관 X)
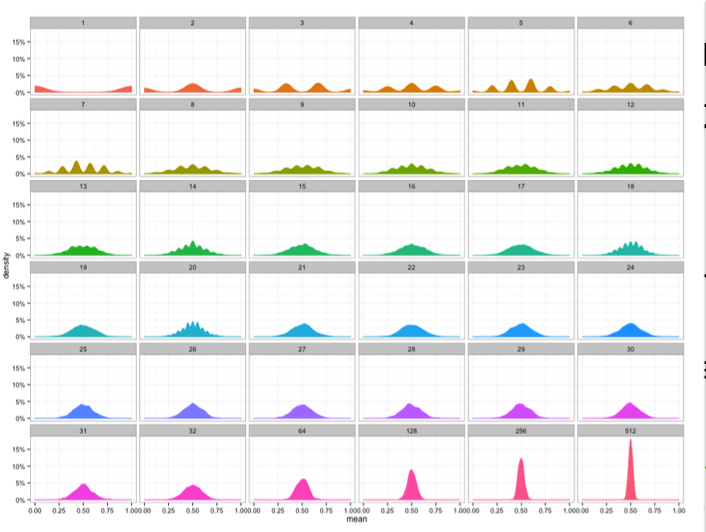
위의 그림은 베루누이 확률분포에 따르는 분포에서 데이터가 늘어날 수록 표본평균의 표집분포의 변화 모습을 보여준다.
💡 최대 가능도를 추정해보자
표본평균이나 표본분산은 중요한 통계량이지만 확률분포마다 사용하는 모 수가 다르므로 적절한 통계량이 달라지게 된다. 즉, 우리가 추정해야 하는 모수는 항상 평균과 분산이 아니다. 이때 이론적으로 가장 가능성이 높은 모수를 추정하는 방법 중 하나는 최대가능도 추정법(maximum likelihood estimation, MLE)이다. 최대가능도 추정법을 이용하면 주어진 확률 분포의 가정에 상관없이 이론적으로 가능성이 높은 파라미터를 추정이 가능하다. 즉, 분포에 상관없이 데이터에 따라 가장 그럴 듯한 모수를 추정하는 방법이다.
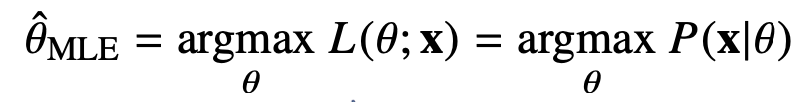
위의 함수가 가능도 함수이며, 이는 확률밀도함수 혹은 확률밀도함수와 같은 것이다. 단지, 관점이 다른 것인데 원래 확률밀도함수는 모수 θ가 주어졌을 때 x에 대한 함수로 생각하지만 가능도함수는 주어진 데이터 x에 대해 모수 θ를 변수로 둔 함수이다.
즉, 모수 θ를 변화함에 따라서 분포가 변화하고 그 분포에서 우리가 데이터 x를 관찰할 가능성을 의미한다. 이는 가능성이지 확률이 아니다. 가능도는 오로지, θ에 대해서 대소비교가 가능한 대상이다.
이를 통해 우리는 θ를 변화시키고 가능도의 비교를 통해 적절한 θ를 찾아나갈 것이다.
데이터 집합 X 가 독립적으로 추출되었을 경우, 로그가능도를 최적화한다. 이는 확률분포가 독립적으로 추출되었을 때, 각각의 확률밀도함수 혹은 확률질량함수의 곱으로 표현할 수 있다.
이는 독립사건이 연달아서 일어날 확률과 동일하기 때문에 가능도 또한 모수 θ에 대해 우리가 관찰한 데이터가 계속해서 나올 확률을 곱해주면
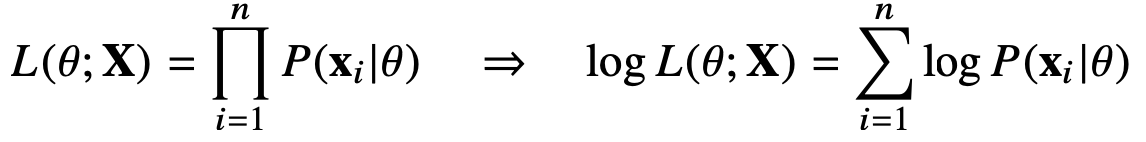
이를 log를 취해주어서 곱셈을 덧셈으로 만들어 보다 계산을 용이하게 만든다. 로그가능도를 최적화하는 모수 θ 는 가능도를 최적화하는 MLE가 된다. 데이터의 숫자가 적으면 상관없지만 만일 데이터의 숫자가 수억 단위가 된다면 컴퓨터의 정확도로는 가능도를 계산하는 것은 불가능하다.
데이터가 독립일 경우, 로그를 사용하면 가능도의 곱셈을 로그가능도의 덧셈으로 바꿀 수 있기 때문에 컴퓨터로 연산이 가능해집니다 경사하강법으로 가능도를 최적화할 때 미분 연산을 사용하게 되는데, 로그
가능도를 사용하면 연산량을 에서 O(n) 으로 줄여준다.
이때 손실함수 경우 최대화를 목표로 하는 경우가 많기 때문에 경사하강법을 사용하므로 음의 로그가능도 (negative log-likelihood)를 최적화하게 된다.
🔥 예제 정규분포의 최대가능도 추정법
ex) 정규분포를 따르는 확률변수 X 로부터 독립적인 표본 {x1, ..., xn} 을 얻었을 때 최대가능도 추정법을 이용하여 모수를 추정하자.
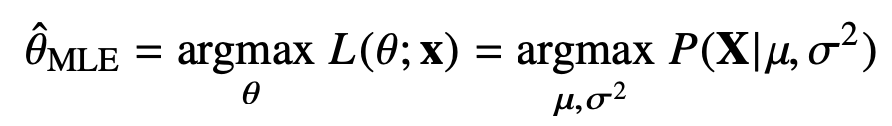
결과적으로 우리는 데이터를 가지고 수식을 최적화하는 θ를 찾는 것이다.
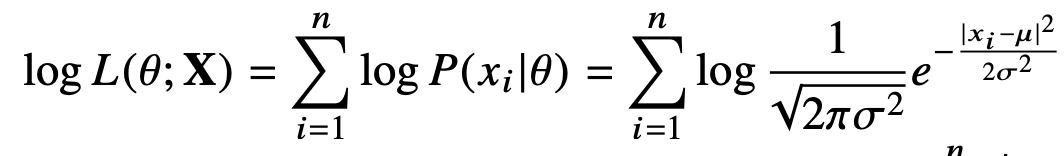
현재 정규분포로 추정한 상황에서 이때의 적절한 평균과 분산을 추정한다. 이는 다음의 식으로 나눌 수 있다.
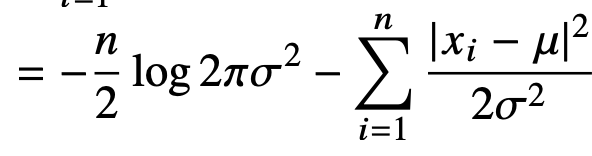
이들을 각각의 모수에 대해 미분하면, 아래와 같다.
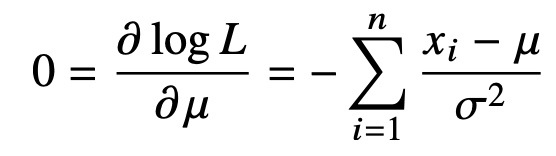
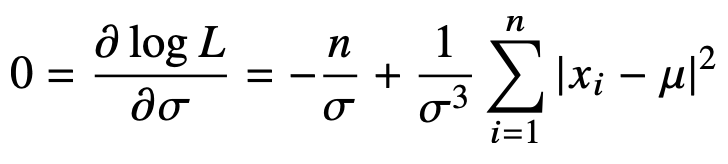
이들의 최적화를 위해 각각의 미분값이 0이 되는 것을 찾아주면 된다.
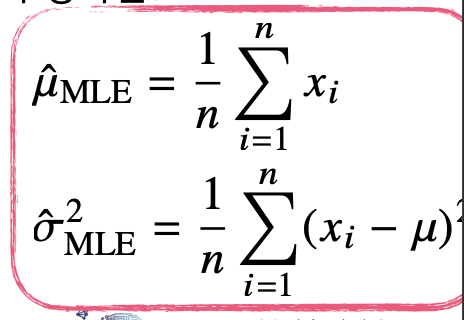
이 결론은 모수를 추정하는 방법과 매우 유사하다. 그러나 분산의 경우는 다르다. 즉, 최대가능도 추정은 불편추정량을 보장하지는 않는다는 것이다.
🔥 예제 카테고리분포의 최대가능도 추정법
카테고리 분포는 두 개의 값중 하나를 선택하는 베르누이 분포를 다차원으로 확장한 것이다. 그렇기에 d개의 각 차원에서 어떤 하나의 확률변수를 선택하게 되면 선택한 변수는 1이고 나머지는 0이되는 one-hot vector로 변화하게 된다.
이제, 카테고리 분포 Multinoulli(x; p1, ..., pd) 를 따르는 확률변수 X 로부 터 독립적인 표본 {x1, ..., xn} 을 얻었을 때 최대가능도 추정법을 이용하여 모수를 추정하자. x의 는 1에서부터 d차원까지 각각의 차원에서 값이 1 또는 0이 될 확률을 의미한다. 그렇기에 p1 ~ pd의 합은 1이 되어야 한다.
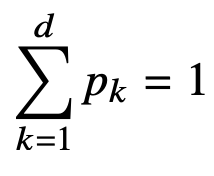
이때의 최대 가능도 추정은 아래와 같다.
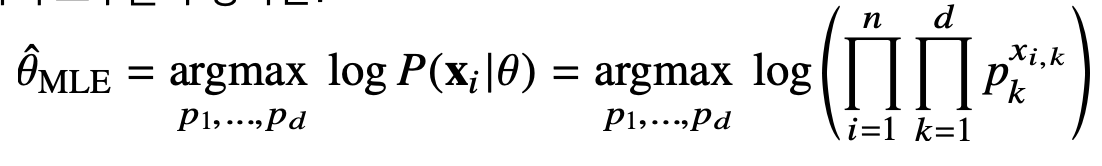
이는 모수 pk에 해당하는 값에 주어진 데이터 의 k번째 차원에 해당하는 값을 승수를 취해주는 형태로 나타난다. 결과적으로 가 0이되면 pk는 1이 될 것이고 1이라면 pk의 값을 가질 것이다.
이를 통해 각각의 확률변수에 대해 0인 것 즉, 선택하지 않은 것의 확률을 제외하고 우리가 추정해야 하는 확률로서의 모수들을 곱한 것을 커지도록 만들어주는 함수가 될 것이다.
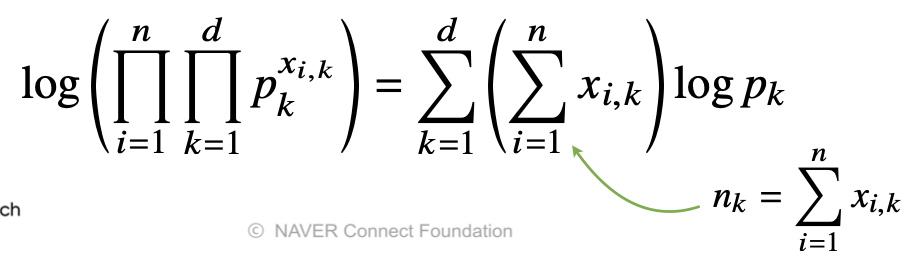
log의 성질을 통해 덧셈으로 교체해줄 수 있고 여기에 pk에 대해 미분을 해주면 는 log 바깥으로 나오게 되고 pk는 log pk로 변화하게 된다. 이때, 는 전부 0또는 1이기 때문에 가 1인 경우를 종합한 로 파악할 수 있다.
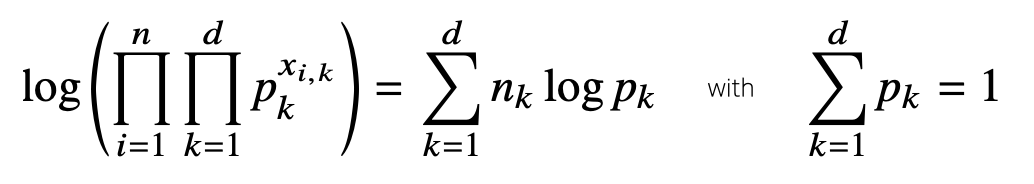
결과적으로 우리가 도출한 식과 제약식이 주어진 상황이다. 오른쪽 식을 만족하면서 왼쪽 목적식을 최대화해야 한다. 이는 라그랑주 승스법을 통해 최적화 문제를 해결할 수 있다.