세번째로 선정한 프리뷰는 논문에서 짧게나마 등장하는 시퀀스 계산을 줄이기 위한 모델들을 선정했다.
해당 내용들이 현재는 사용되지 않기 때문에 깊게는 연구해보지 않았으나 어느 정도의 기초체력은 필요하다고 생각해 공부해보았다.
💡 End to End memory
메모리 네트워크에 대해 이야기 하기 전에, Encoder-Decoder의 구조를 기억해보면 Encoder는 문장의 단어들을 혹은 입력을 encoding해서 임베딩 벡터를 만들어낸다. 이러한 임베딩 벡터는 RNN, LSTM 등의 hidden state로 사용된다.
그러나 이 과정에서 발생하는 문제는 입력이 일정하지 않으며 매우 길 수도 있다는 것이다. 이러한 과정에서 hidden state를 만들어낼 때 앞 부분의 입력들을 적절하게 반영한 hidden state vector를 만드는 것은 매우 어렵다.
이러한 문제를 해결하기 위해 제안된 것이 Memory Network이다. 메모리에 저장할 수 있는 만큼 최대한 각 단계에서의 hidden state를 저장하고, 이를 활용하는 것이다. 이를 Memory Network라고 부른다. 하지만 이 방법 또한 문제가 발생하는데, Loss를 구하는 과정이 매우 길고 오래 걸리게 된다는 것이다.
임베딩된 단어 벡터들인 ,…의 입력들과 우리가 찾고자 하는 query q를 받아서 정답 벡터 a를 출력물로 내놓을 것이다. 각 ,그리고 softmax에 해당하는 p, 그리고 질문으로서의 q, 정답 벡터 a는 V개의 단어를 가지는 Vocabulary에서 one-hot encoding과 유사한 형태(p는 one-hot이 아니기에)이다. 즉, 이들은 Bag-of-Words 형태로 볼 수 있다.
(Each of the , q, a contains symbols coming from a dictionary with V words)
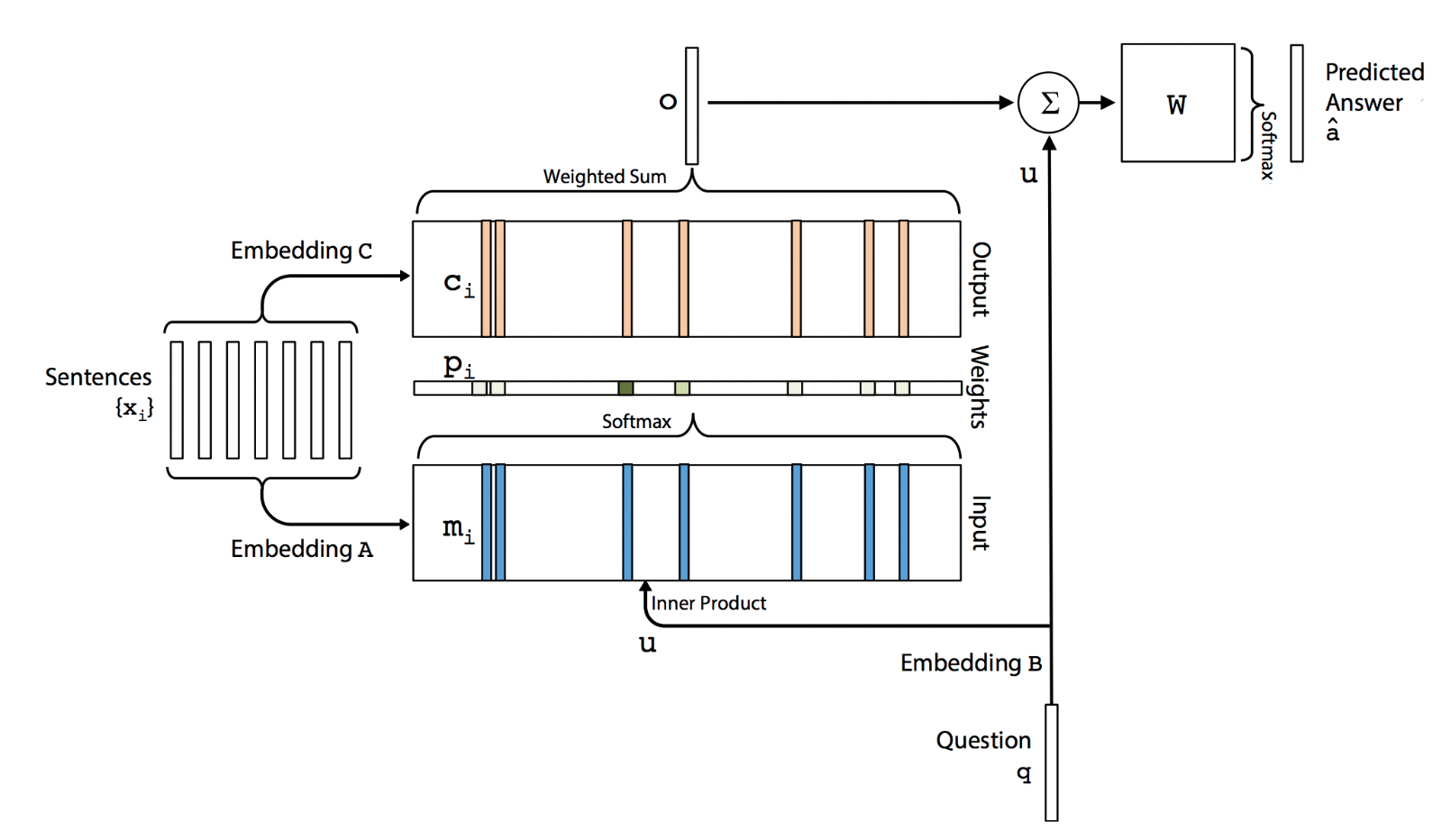
이들을 통해 우리가 진행하고자 하는 대략적인 구조는 위와 같다. 그리고 위의 구조가 겹겹히 쌓여있는 것이다. (약간 Transformer와 유사하게 Q, K, V를 통해 Attention을 만드는 것과 유사)
우리가 의 입력을 받았다고 생각해보자. 이 각 들은 embedding matrix를 통해 one-hot vector에서 d차원의 메모리 벡터 가 된다. 즉, Latent Space로 이동시켜주는 것이다. 이때, 는 BoW 형태로 표현되어 있기에 를 에서의 j번째 index라고 생각한다면, 라고 표현할 수 있다.
query는 이와 같은 과정을 거쳐 d차원으로 embedding 되게 된다. 그리고 query의 embedding vector를 inner state u라고 할 때 u와 가장 유사한 벡터를 구하기 위해 각 들과 내적을 해준다. 그리고 이들을 softmax해주어 최대가 되는 즉, u와 가장 유사한 embedding vector를 찾는다. 이는 로 표현할 수 있고 p는 입력에 대한 확률벡터가 되는 것이다.
또한 다른 embedding matrix C를 사용해, 각 에서 output vector 를 만들어준다.(Transformer에서는 V와 유사한 것이라 보면 된다) 우리의 최종 출력 o는 변형된 입력인 와 p간의 곱 그리고 이들을 모두 sum 처리 해준다. 즉, 으로 생각할 수 있다.
최종적으로 output을 만들기 위해 output vector o와 u를 합쳐서 weight matrix에 넣은 다음 Softmax를 취해줍니다
학습 과정에서는 a와 간의 cross entropy를 최소화하도록 학습을 진행한다. 결국 여기서 우리가 학습시키는 파라미터는 matrix들, A,B,C,W가 되고, 이들은 smooth하므로 미분이 가능해 역전파를 통해 학습을 시킬 수 있다는 것이다. 논문에서는 이를 Multi layer로 구현해 다양한 학습이 가능하도록 만들어주었다.
💡 Extended Neural GPUs
Transformer에서 이 논문을 언급한 이유부터 먼저 생각해보자. Neural Machine Translation은 Attention을 통해 상당히 효과적인 진전을 할 수 있었다. 그러나 Attention을 RNN 혹은 LSTM과 함께 활용하며 결국 병렬화처리는 하지 못했다.
Transformer도 이를 개선하기 위해 내놓은 것은 RNN과 LSTM을 완전히 제거하고 BoW 형태로 단어들을 모두 Embedding하고 Encoder에 넣어주기 전에 positional encoding을 시켜주어 단어의 위치에 대한 정보를 추가해주었다.
그보다도 이전 Sequential Data를 병렬처리 하기 위해 나타난 노력이 바로 Neural GPUs이다. 이 논문에서는 training example들로부터 algorithm을 배우는 이전까지의 연구들이 sequential한 특성에서 벗어나지 못함을 지적한다.
또한 기존의 Sequential한 데이터를 빠르게 학습하도록 하는 방식은 pattern을 미리 기억하고 이를 사용하는 방식이다.

위와 같은 연산은 논리설계에서도 나오지만 뒷자리부터 계산을 해주어야 하기 때문에 미리 이러한 패턴을 외우고 진행하면 훨씬 빠르게 할 수 있다. 그러나 이는 generalization 성능에서는 떨어질 수 밖에 없다고 말한다.
따라서 이들은 input 자체를 완전히 Sequential하게 풀고 여기에 Neural GPUs를 사용하는 방법을 고안했다.
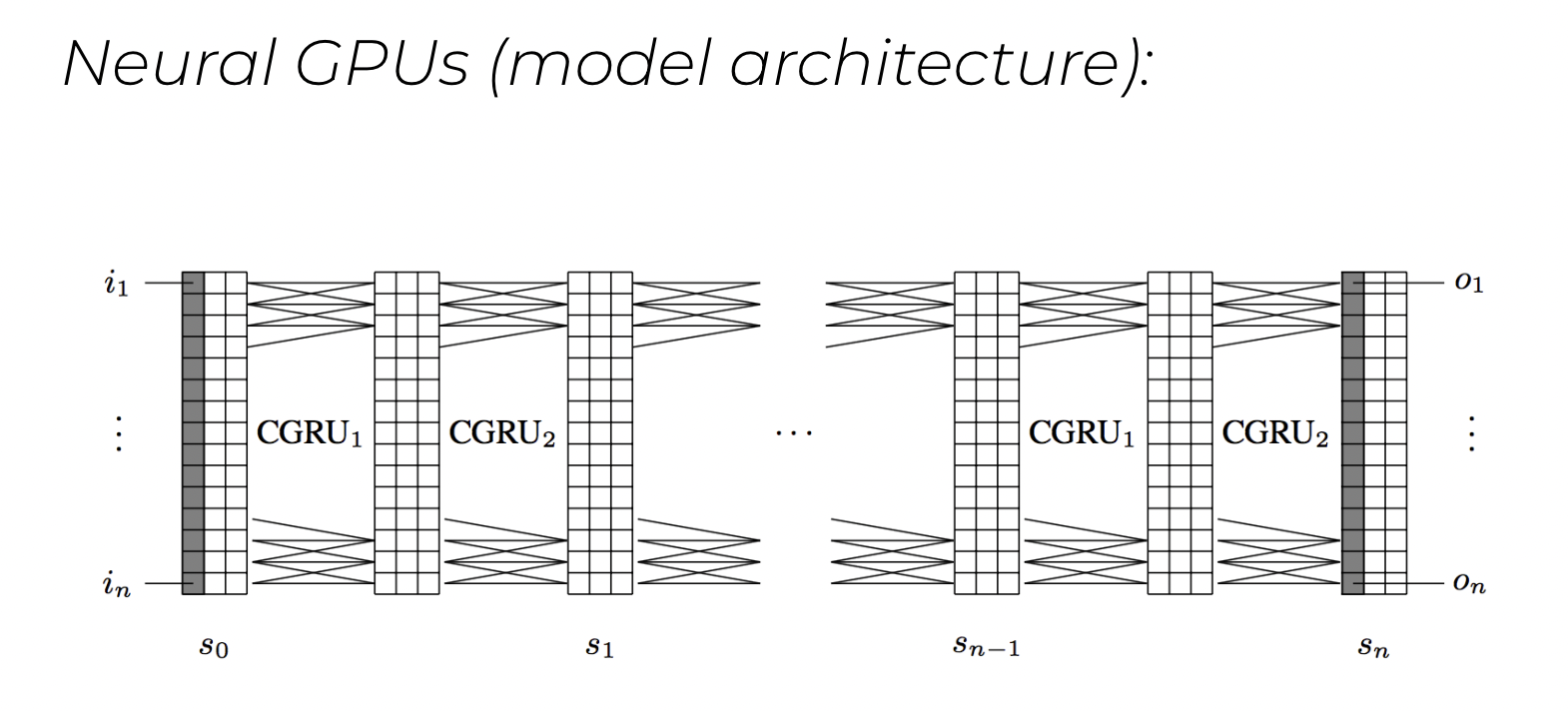
간단하게 요약하자면, GPUs를 구성하는 각각의 CGRU의 기본이 되는 vector x와 current state s를 받아 다음과 같은 연산을 진행한다.
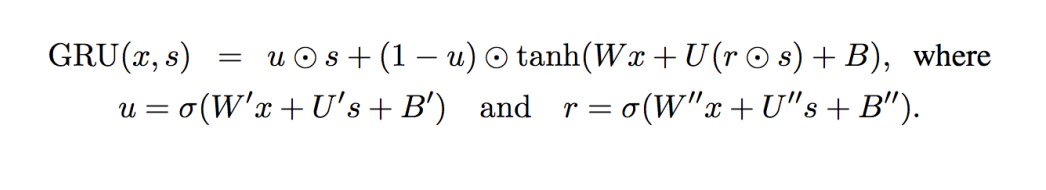
여기서 r은 reset gate로 current state s에 element-wise multiplication을 통해 얼마나 reset해줄지를 학습하는 gate이며, update gate u를 사용하여 current state s와 현재의 입력 x로 부터 얻어지는 representation을 출력에 얼마나 반영할지 결정해주는 역할을 한다.
Neural GPU는 GRU의 변형인 CGRU로 구성된다. 이 친구는 입력으로 current state s만을 갖는다. 즉, current state에 모든 입력 sequence를 다 넣어버리고, CGRU로 recurrent하게 학습을 하는 것. 즉, sequence data의 모든 element가 time step-0에 모두 사용되며 이를 중첩해서 사용해서 학습을 시키는 것이다.
그리고 여기서 Convolution을 차용한다. 이를 통해 Vector의 특징적인 부분만을 추출해 hidden vector처럼 만드렉 된다. 결과적으로 CNN + GRU = CGRU이며 이를 병렬사용하기에 GPU라고 한 것이다.
✏️ 학습 후기
해당 논문의 내용이 2016즈음에 나타난 논문이라 현재는 거의 사용되지는 않는 아이디어들이다. 그러나 Transformer가 이들과 같은 고민을 하고 흐름을 이어가는 문제제기를 했다는 것이 두 논문에서 여실히 드러났다. NLP의 흐름을 파악할 수 있는 논문이었기에 충분히 공부할만 하다고 생각한다.
참고 : https://blog.lunit.io/2017/03/28/neural-gpus-and-extended-neural-gpus/
https://www.quantumdl.com/entry/9%EC%A3%BC%EC%B0%A81-EndtoEnd-Memory-Network
https://kangbk0120.github.io/articles/2018-03/end-to-end-memorynet
