들어가며
ArrayParser는 자체적으로 구현한 JSON parser이다. 객체타입을 지원하기 위해 기능확장을 하였는데 리팩토링에 손을 대지 못하였다. 리팩토링을 하지 못한 이유는 프로그램의 동작이 명료하지 않기 때문이다.
설계가 왜 명확하게 떠오르지 않고,구현할때 어려웠던 것일까?
구현하면서 어려웠던점과 고민됬던점을 풀어보고자 한다.
1. 자잘한 로직을 함수로 만드는게 필요할까?
예를 들어 isLeftBracket 함수가 필요한지와, 다른 클래스에서도 필요한지를 생각해보자.
isLeftBracket(token) {
const startParentToken = ['{', '['];
return startParentToken.includes(token)
}개인적으로 함수가 많아지면 프로그램의 코드가 주렁 주렁 달린다고 생각했고, 길어지면 관리하기 어렵다고 생각해서 함수를 최대한 안만드려고 생각했었다.
그러나 객체의 자잘한 로직을 함수화 하면 세부적인 동작은 숨길 수 있어 가독성 측면에서 좋아진다. 가독성이 좋아지면 객체의 동작이 좀 더 명확해진다.
물론 함수로 만들면 재사용성도 높지만 아직 규모가 큰 코드를 짜본적이 없어 재사용성의 이득은 크게 못 보고있다.
하지만 가독성 측면에서만 보더라도 자잘한 로직은 함수로 만드는것은 메리트가 있고 코드스쿼드에서도 함수가 한가지역할만 하도록 자잘한 로직은 함수로 나눌것을 적극 권장하고 있다.
또한 다른 클래스에서 이러한 함수들이 필요할지는(재사용성) 자연스럽게 확장해가며 생각하는것이 고민을 줄일 수 있는 방법이다.
2. 함수를 어떻게 만들어야하지?
그런데 막상 자잘한 역할을 하는 함수를 만드려고 하니, 첫번째로 input은 무엇으로 받아야할지, return은 무엇으로 해야할지 정하는것이 어려웠다.
input은 그냥 token인가? return은 무엇을 해야하지? true,false 를 return해야하나? return 값이 없어도 되나?
두번째로 함수가 하는 역할과 범위를 정하기가 너무 애매했다.
메인함수의 로직을 유틸함수로 분리해서 해결하고자 하는데,
예를들어 Tokenizer의 cutInput 함수의 경우 1) 토큰을 검사하는 함수, 토큰을 배열에 넣는 함수가 필요하다. 2) 그런데 인풋을 한글자씩 처리할것이므로 null, false , true는 축적이 되어야하고 'null'은 문자열로 처리되어야한다. 이런 다양한 조건을 처리할때, 메인함수에서 전부처리하면 상관이없는데 유틸함수로 나누어 처리하면 유틸함수에 어떤 정보를 보내야하고 어떤 값을 받아와야하지?
이부분까지 함수에서 처리해줬으면 좋겠어! 라고 생각했는데 그러면, 재사용이 안될것같은데? 그렇다고 함수를 많이 만들기에는 함수도 잘 못만들겠고, 이렇게 한줄짜리 함수를 만들거면 함수를 뭐하러 만들지?
2.1 함수의 종류
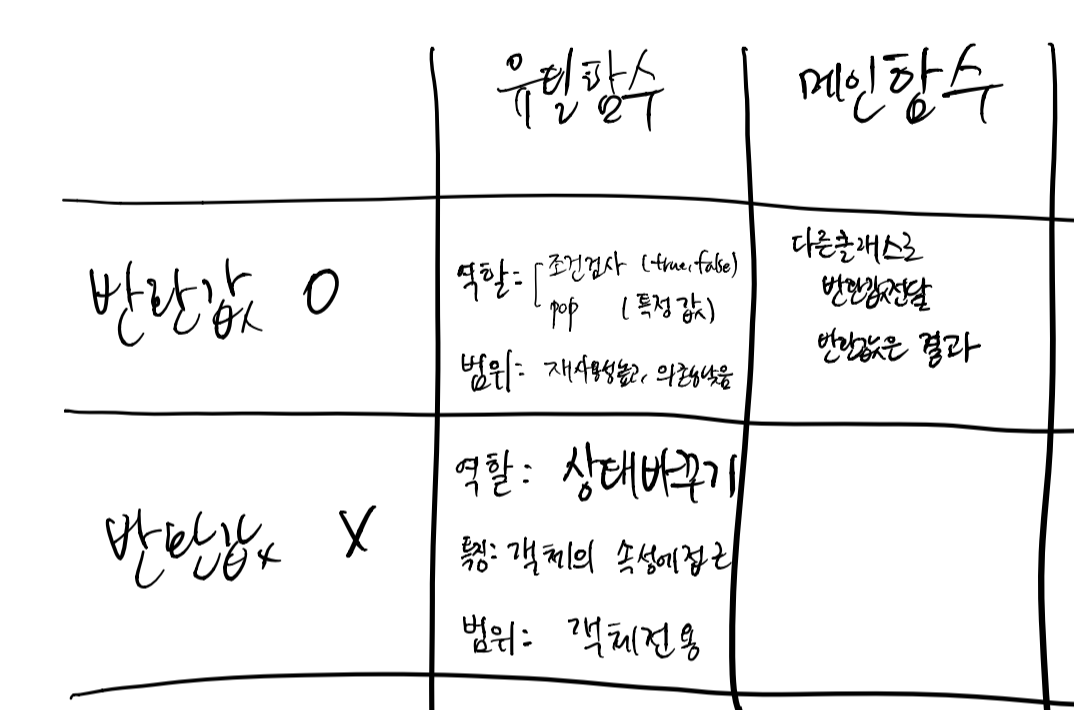
위의 그림은 내가 임의로 함수를 나눠보았다. 크기와 반환값에 따라 4가지 범위로 나누어 보았다.
2.1.1 메인함수
주로 메인함수는 조건을 검사하고, 조건에 따라실행하는 함수이다. 실행이 한줄이면 함수로 만들지 않고 여러줄이고 내부속성을 바꾸면 함수로 만들어 처리한다. 이 경우 단계가 하나로 조건을검사하는 함수와, 그에 따른 실행으로 로직을 만들 수 있다.
반면 Lexer의 createNode와 같이 메인함수에서 단계를 나누고 각 단계안에서 조건에 따른 실행을 하는 경우로도 작성할 수 있다. 메인함수 내부에서 단계별로 함수가 호출되는 경우 프로시저라고 부른다.
createNode(queue) {
const typedTokenQueue = this.setNode(queue);
return this.getNode(typedTokenQueue);
}ArrayParser 앱에서 메인함수는 Tokenizer의 cutInput(inputString), Lexer의 createNode(queue) Parser의 makeTree(queue) 함수이다.
- cutinput 함수는 타입을 검사하고, 검사한만큼을 잘라서 토큰 큐에 넣는다.
- createNode 함수는 토큰 큐의 token에 타입을 부여하고, 타입별로 객체를 만들어 넘긴다.
- makeTree 함수는 타입을 검사하고, 타입별로 stack에 push하거나 array객체의 child에 push하였다.
커맨드별 조건을 검사하는 함수로 만들어도 되고, 커맨드를 객체의 key에 맵핑하고 value에 함수를 연결하여도 된다.
2.1.2 유틸함수 중 반환값이 있는 함수
- true, false를 반환하는 함수
isComma(token) {
return token === ',';
}
isNull(token) {
return token === 'null'
}- 특정 값(string, object , array) 을 반환하는 함수
getToken(){
return this.historyStack.pop()
} getAccumulator(acc, token, cur) {
return token !== '' ? acc.concat([token, cur]) : acc.concat([cur]);
}2.1.3 유틸함수 중 반환값이 없는 함수
반환 값이 없는 함수는 상태를 바꾸는 함수이다.
pushParent(token){
const topIndex = this.historyStack.length -1;
this.historyStack[topIndex].child.push(token);
}
pushParent() 함수는 this.historyStack 의 상태를 바꾼다. this.historyStack이 있는곳에서만 사용가능하므로 현재 객체안에서만 사용이 가능하다.
ArrayParser에서 반환값이 없이 상태를 바꾸는 함수pushParent()는 메인함수makeTree()의 실행을 담당하는 로직의 일부이다.
객체를 벗어나서는 사용할 수 없는 함수이고, 가독성을 높이고 메인함수의 코드양을 줄이고 메인함수의 일부 로직을 객체안에서 단순 재사용만 하기 위해 사용하는 함수이다.
concatParent(token){
delete token.value;
const topToken= this.getToken();
if(this.isKeyToken(topToken)){
this.pushParent(topToken);
const valueToken= this.getToken();
this.pushParent(valueToken);
return
}
if(this.isEmptyStack()){
return topToken
}
this.pushParent(topToken)
}위의 함수는 단순히 메인함수의 코드양을 줄이기 위해 작성한 코드이다. 이런 함수를 최소화 하는것이 좋은 함수를 짜는 방법인것같다.
3. 어쩌다 이렇게 복잡해졌지?
parser에서 key 토큰이 들어오는 경우를 해결하려다 보니 key토큰이 들어왔을때를 해결하기 위해 추가적인 로직이 필요하게 되었다.
else {
this.pushParent(currentLexedObj)
if(this.isKeyToken(this.historyStack[this.historyStack.length-1])){
const keyToken= this.getToken();
this.pushParent(keyToken);
} concatParent(token){
delete token.value;
const topToken= this.getToken();
if(this.isKeyToken(topToken)){
this.pushParent(topToken);
const valueToken= this.getToken();
this.pushParent(valueToken);
return
}
if(this.isEmptyStack()){
return topToken
}
this.pushParent(topToken)
}돌아보면 설계에서 object 객체에 object.assign을 이용해서 {key: 'easy', child:[ ]} 를 붙이면 되었는데 이것을 생각하지 못하고 억지로 로직을 비틀어서 생긴 문제였다.
{ type: 'object', child: [
{key: 'easy', child:[
{ type: 'array',
child: [
{ type: 'string', value: 'hello', child: [] },
{ type: 'object', child: [
{key: 'a', child: [
{type: 'string', value: 'a', child: []}]
}]
},
{ type: 'string', value: 'world', child: [] },
]}
]}
]},마무리하며
- 유틸함수의 반환값이 없는 함수를 최소화하자. 단순 메인함수의 코드양을 줄이기위한 함수를 생성하는 경우를 피하도록 최대한 로직을 잘 짜야한다.
- 설계가 명료하기위해 설계를 문서화 또는 그림으로 만들고, 함수단위로 커밋을 하고 빠른 리팩토링으로 명료한 설계를 계속 유지하자.
