1. 들어가며
나는 ArrayParser를 만들고 있다. 이번에는 들어온 input을 의미별로 자르는 Tokenizer의 메인함수를 만들었는데 이 과정에서 얻은 깨달음을 공유하고자 한다.
메인함수의 로직은 정규표현식이 아닌 한 단어별로 자르고 의미단위로 축적하는 방식으로 구현하고자 하였다. 그 이유는 Tokenizer의 핵심은 에러처리이기 때문인데 (예를들어 DOMTree에서는 다양한 에러처리를 한다.) 정규표현식으로 tokenize를 하면 세밀한 조절이 아닌 일괄처리가 되고, 이것은 마치 수제버거가 아닌 패스트푸트 햄버거처럼 만들어진다고 볼 수 있다.
이 과정에서 나는 cutInput이라는 함수의 로직을 설계할때 조건에 따른 실행 을 위해 프로그램의 동작흐름을 트리모양으로 그려보았다.
그런데 트리의 노드가 함수라면 함수가 3개이면 depth가 3인가? 라는 생각이 들었고, 조건에 따른 실행과 그 조건을 배치하는것은 흐름제어 를 하는것이라는것을 알게되었다.
분명 나름대로 깔끔하게 설계를 했는데 3depth가 나왔다는게 이상했고, 고민을 하다보니 트리를 잘 구성하면 조건이 100개가 있어도 2depth(이것도 별로라고 생각한다.) 혹은 1depth로 코드를 구현할 수 있다는 것을 알게되었다.
2. 설계하기
누가 로직좀 알려줘... 라는 생각이 들었다. 돌아보면 이 로직(조건과 그에 따른 실행)은 계속해서 생각을 하는 방법밖에 없는것같다. 그래서 설계가 오래걸리는것같고, 프로그램이라는게 결국에는 다 비슷한 구조로 돌아가기에 짜다보면 설계를 하는데 걸리는 시간이 줄어들지 않을까? 라고 생각한다. 그리고 다른사람에게 들어도 내가 어느정도 생각안해보면 이해하기가 어려운것같다.
생각해보면 모든(여태까지 내가 봤던, 짰던) 프로그램은 시간순서에 따라 동작하므로 선형적으로 동작하는것같고 그러니까 조건만 잘 따져주고 그 조건에 따라 처리만 잘 하면되는데..(1depth로 구현할 수 있는데) . 그 조건이 무엇이고, 조건에 따라 처리하는게 뭘 해야하지? 이게 너무 햇갈렸다.
처음의 설계
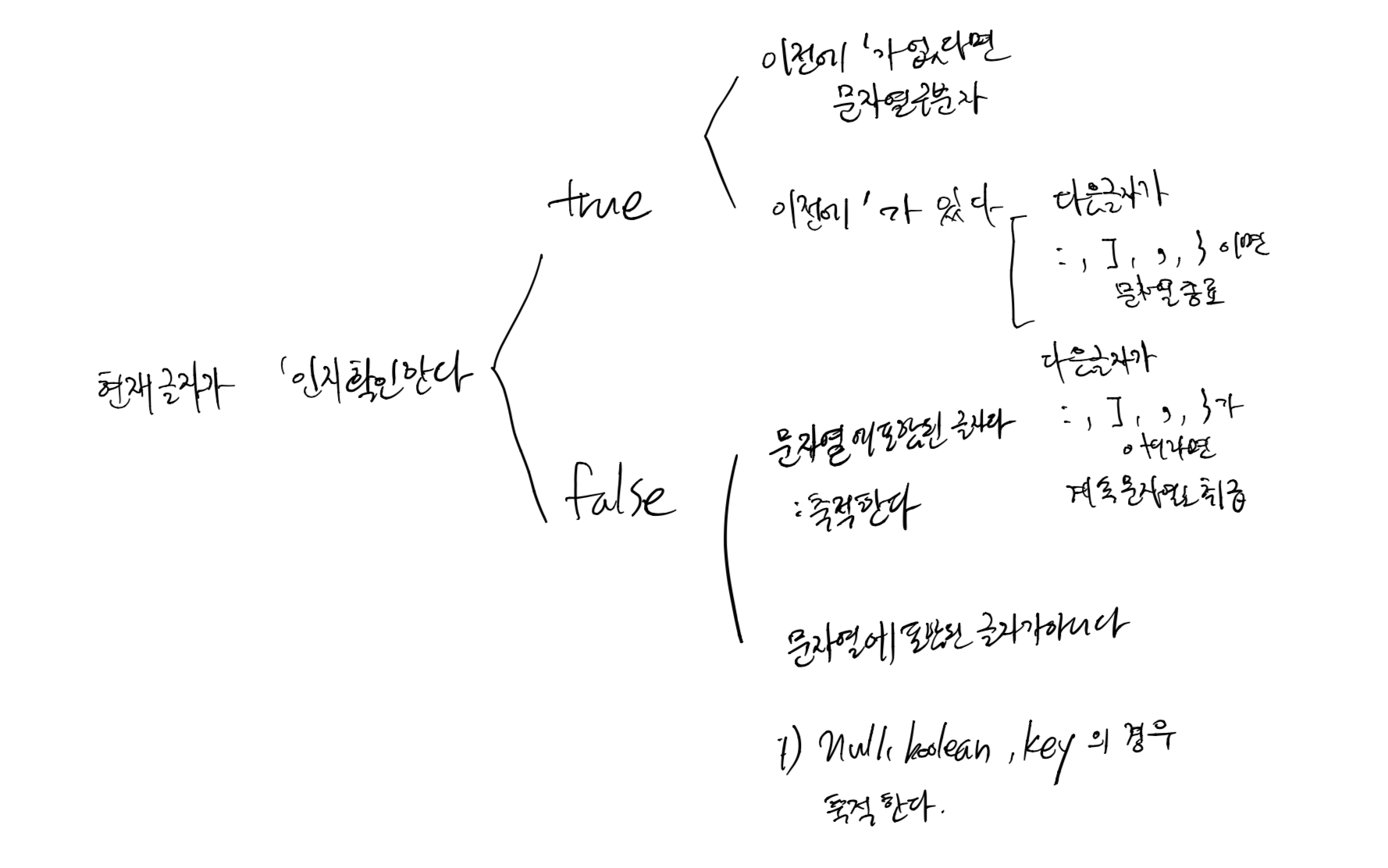
너무 안예뻐서 나름 개발자스럽게 다시 짜보았다.
처음의 설계 리팩토링
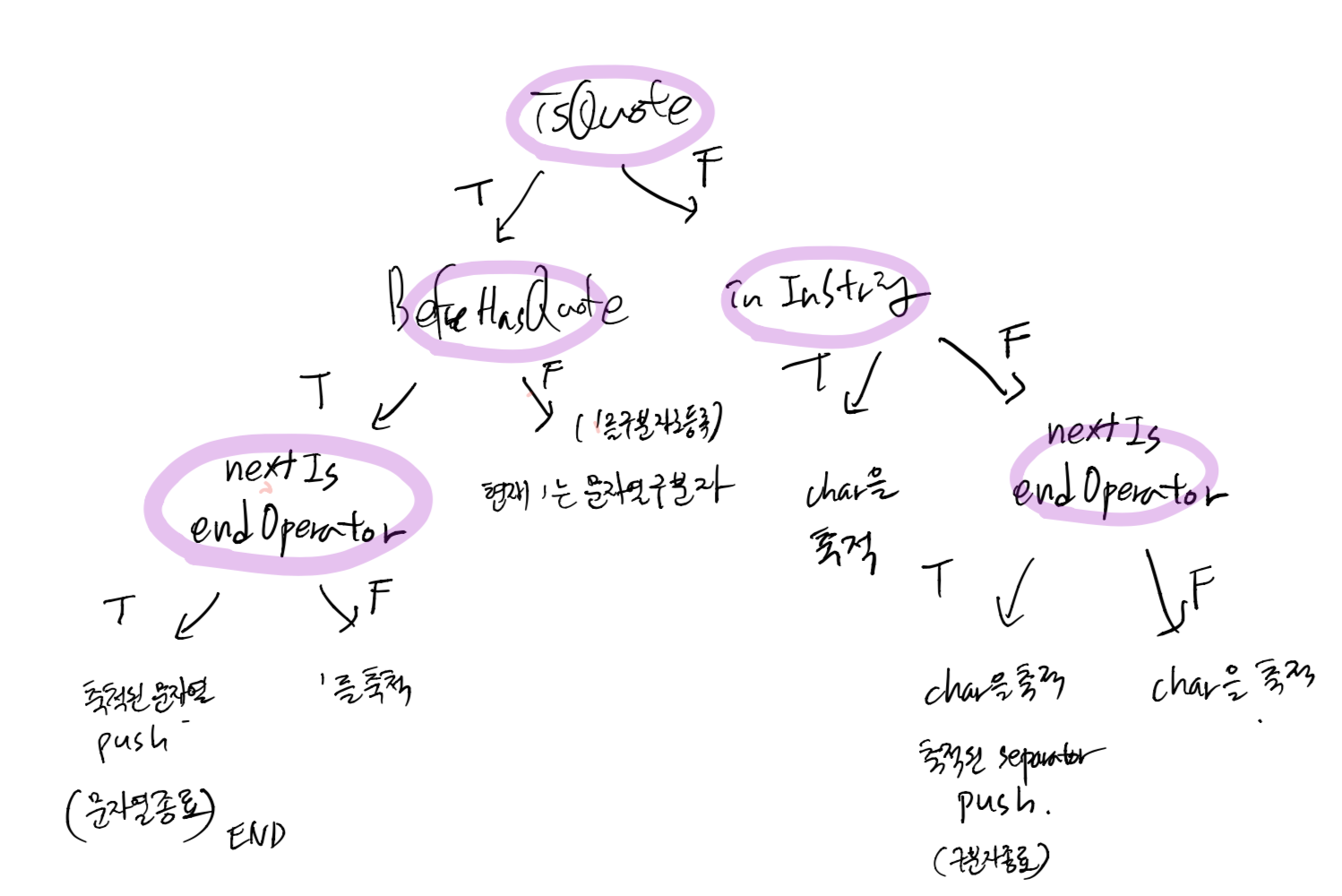
3. 깨달음
''어 이거 완전 skewed tree같은데?''
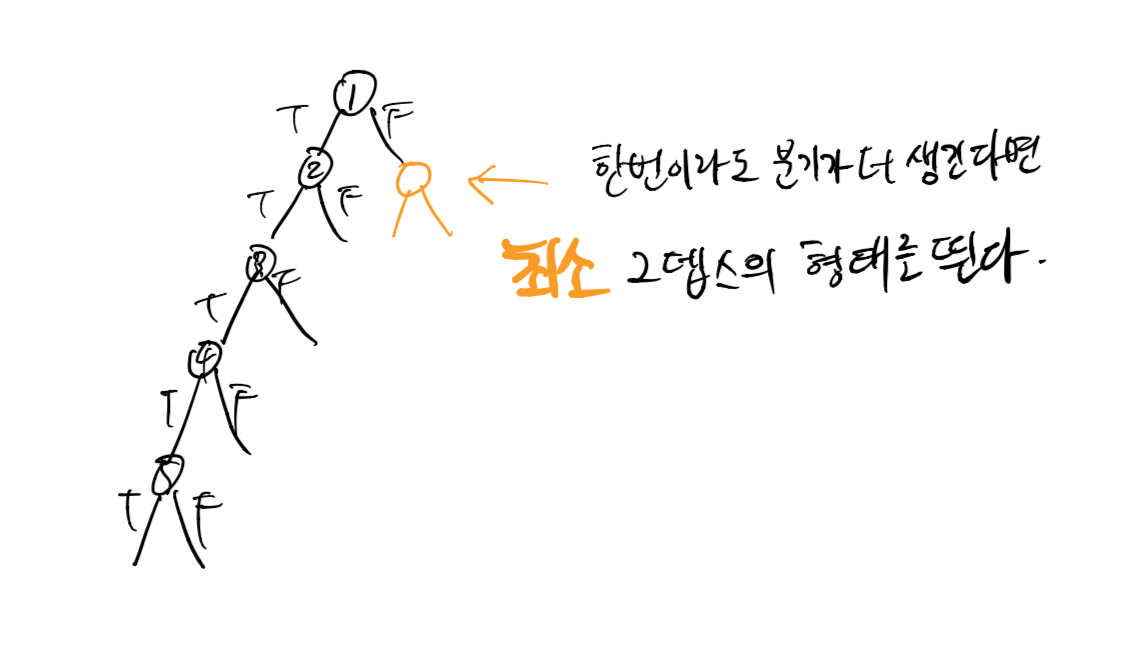
나의 설계는 위와 같이 최소 2depth로 구현할 수 있었고, 프로그램을 잘만 구현하면 질문이 100개여도 1depth로 구현할 수 있다는것을 깨달았다.
왜냐하면 완전히 기울어진 트리는 프로그램이 한방향으로 흐르는것을 의미하기 때문이다. 아래 그림과 같은 이유로 1depth로 구현할 수 있다.
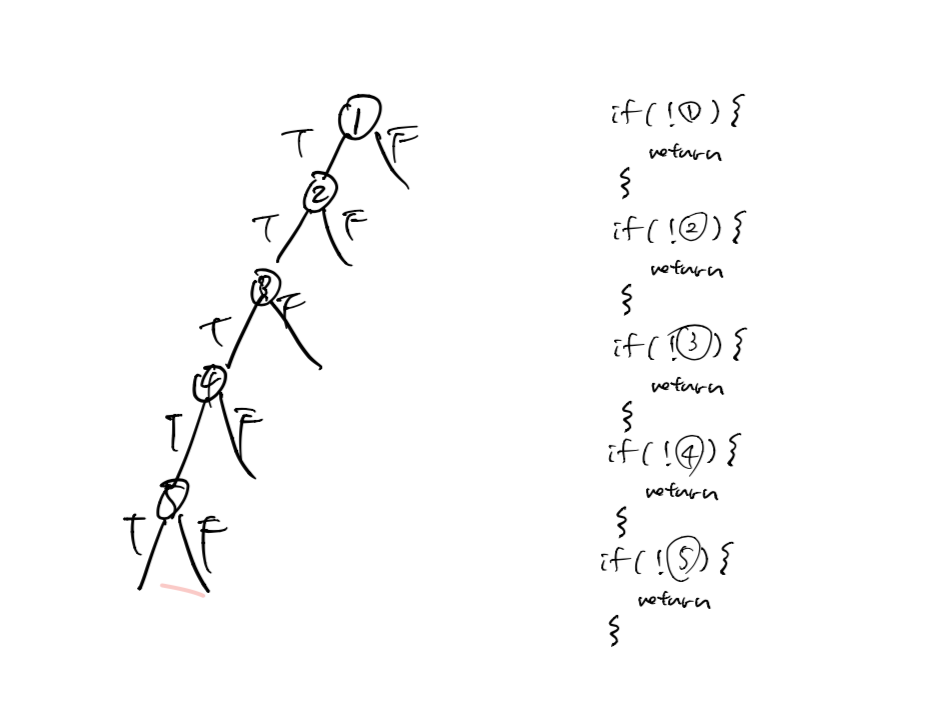
2depth가 안좋은 이유
읽기 좋은 코드가 좋은 코드다 에 따르면 if문이 중첩되면 정신적 스택에 조건을 넣기 때문에 불편하다고 되어있고, 그러므로 선형적인 코드를 작성할것을 권장한다.
일단 나는 너무 오래 설계하고 있었기에 .. 내 설계가 맞는건지 확인하고싶어 2뎁스로라도 코드를 먼저 짜보고싶었다.
4. 구현하기
완벽한 설계?
그렇게 설계를 오래했음에도 불구하고 구현을 하면서 헛점이 발견되었다.
1. isInString 은 beforeHasQuote와 같은 역할을 하는 함수였다.
2. 현재 char이 연산자인지 검증하는 로직이 추가되어야했다.(isSeparator 함수추가)
구현과정에서 설계를 수정하며 구현을 완료하였다!
cutInput(input){
this.input = input.split("");
while(this.input.length){
this.curChar = this.input.shift();
const nextChar = this.input[0];
if(this.isQuote(this.curChar)){
if(this.beforeHasComma(this.tempToken) && !this.isEndSeparator(nextChar)){
this.tempToken += this.curChar;
continue
}
if(this.isEndSeparator(nextChar)){
this.pushCharAndRenewTempToken()
continue
}
this.tempToken += this.curChar;
continue
}
if(this.beforeHasComma(this.tempToken)){
this.tempToken += this.curChar;
continue
}
if(this.isSeparator(this.curChar)){
this.pushCharAndRenewTempToken()
continue
}
if(this.isEndSeparator(nextChar)){
this.pushCharAndRenewTempToken()
continue
}
this.tempToken += this.curChar;
}
return this.tokenQueue
}그리고 이제, 1depth로 리팩토링을 해보기로 했다.
5. 다시 설계하기
1뎁스로 만들기위한 2차설계
양쪽에서 겹치는 함수를 위로 올려보자!
beforeHasQuote 함수는 양쪽에서 다 사용되므로 일단 이것을 첫 질문으로 채택해보았다. 그런데 nextIsEndSep이 양쪽에서 사용되므로 여전히 2depth였다.
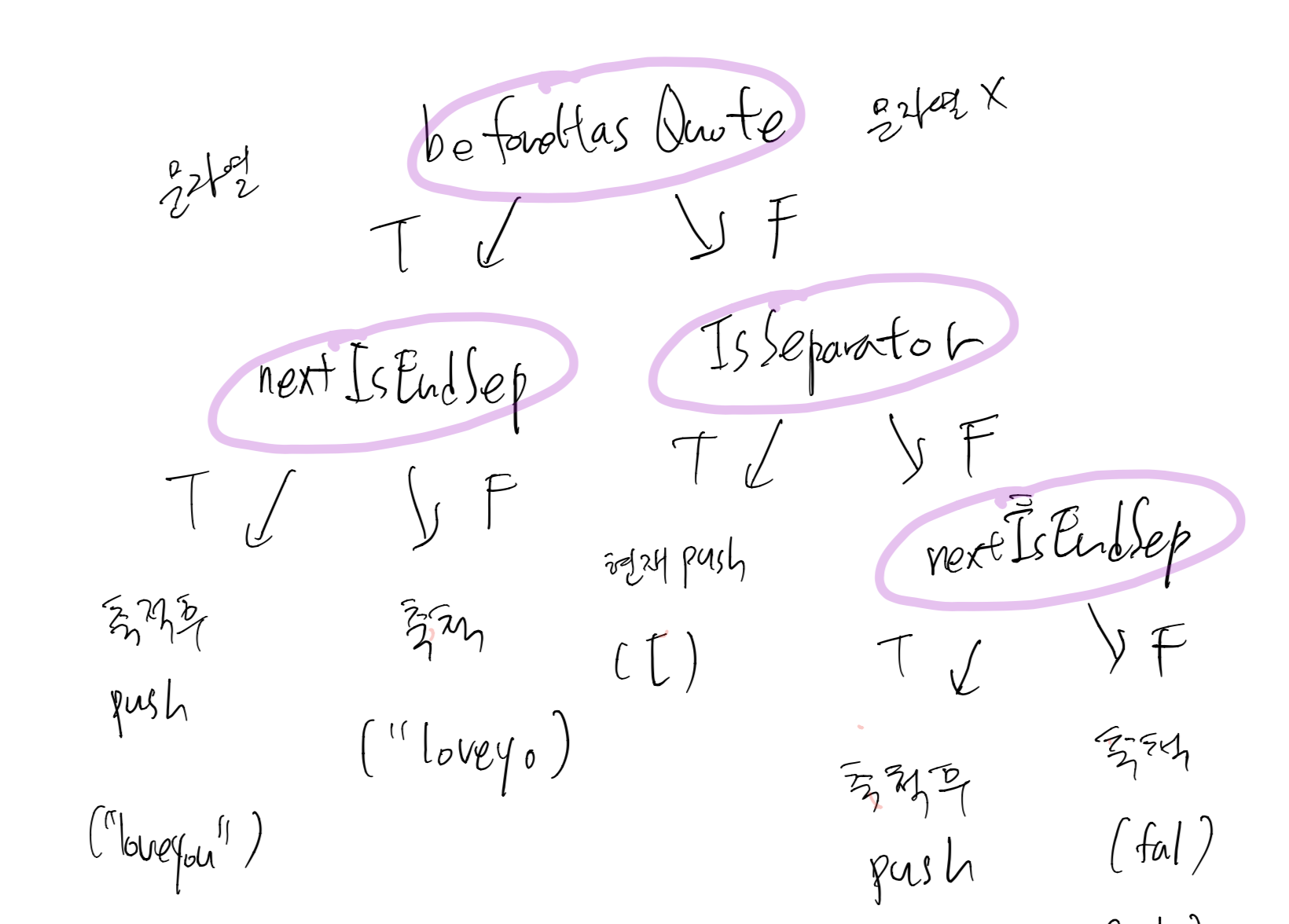
1뎁스로 만들기위한 3차설계
마지막에 양쪽에서 겹치는 함수가 맨 위로 올라와야하는구나!
또는 , 겹치는 결과로직을 하나로 묶어보자 라는 생각으로 nextIsEndSep를 첫번째 질문으로 채택했다.
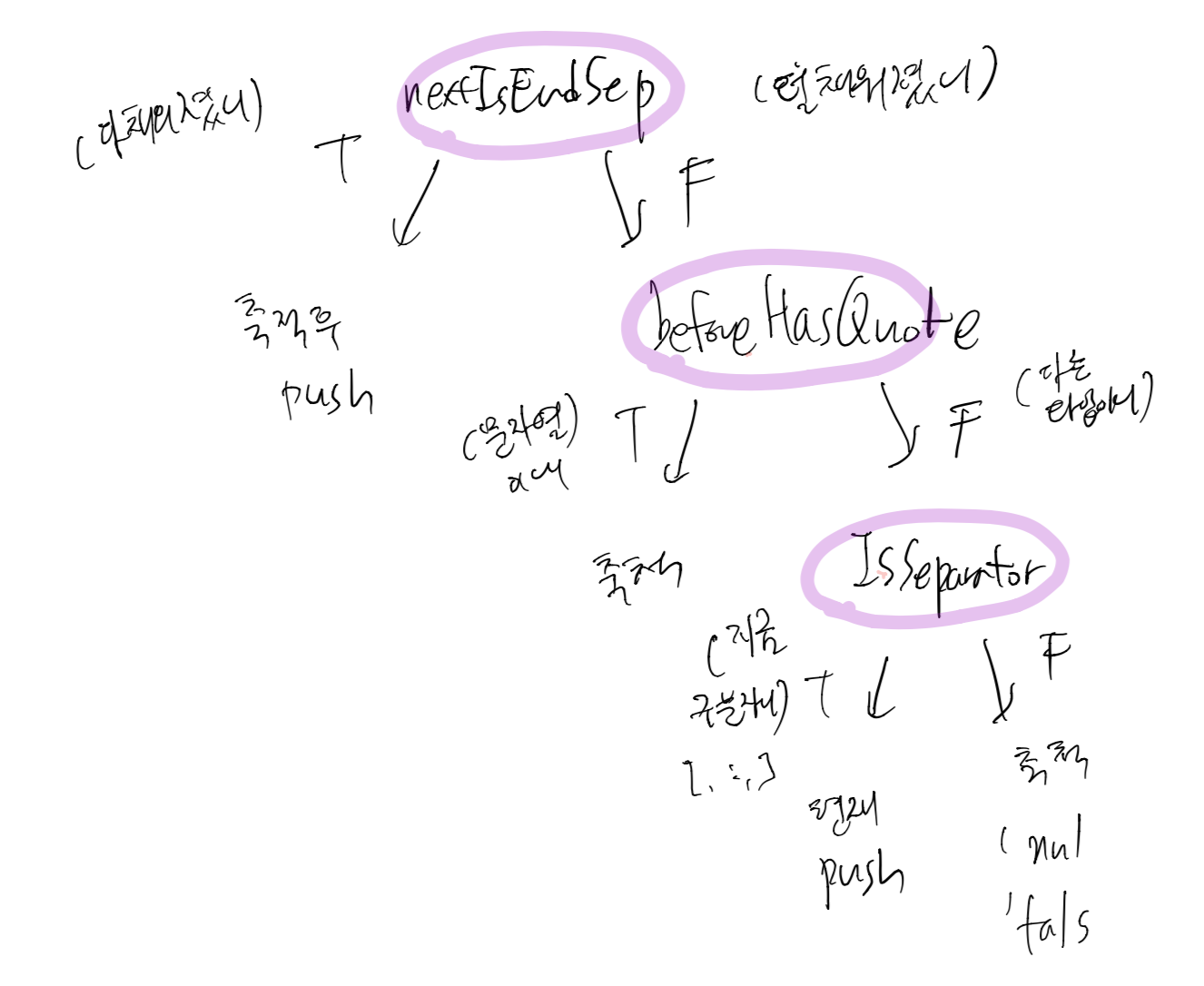
nextIsEndSep을 첫번째 질문으로 채택하니 1depth로 설계가 가능했다!!!!
설계를 마치고 몇가지 의문이 들었다.
- 어떤 질문이 첫번째에 오는 질문인가?
뭔가 트리를 만드는것은 스무고개처럼 넓은 범위의 질문이 첫번째에서 물어봐야하는 질문인가? 라는 생각이 들었었는데 프로그래밍에서는 좀 다른것같다.
fast-return의 형태를 띄고 있으므로 범위가 넓은 질문이 처리된다기보다는 오히려 범위가 작은 질문을 처리한다는게 그나마 맞는것같고, 범위가 작은질문을 순서대로 처리한다기보다는 마지막에 꼭 물어봐야 하는 질문을 우선적으로 질문하여 양쪽에서 질문하지 않도록 하여 depth를 줄인다고 할 수 있다.
- 함수의 순서를 바꿔도 상관이 없나?
함수가 의존성이 없으므로 상관이없다.
- 2뎁스를 1뎁스로 만들때 코드를 좀 수정해야하지 않나?
상태를 처리하는건 if문 내부에서 실행되므로 위치만 바꿔주면 된다.
6. 다시 구현하기
cutInput(input){
this.input = input.split("");
while(this.input.length){
this.curChar = this.input.shift();
const nextChar = this.input[0];
if(this.isEndSeparator(nextChar)){
this.pushCharAndRenewTempToken()
continue
}
if(this.beforeHasComma(this.tempToken)){
this.tempToken += this.curChar;
continue
}
if(this.isSeparator(this.curChar)){
this.pushCharAndRenewTempToken()
continue
}
this.tempToken += this.curChar;
}
return this.tokenQueue
}내부 속성을 바꾸는 로직도 함수로 만들자
pushCharAndRenewTempToken(){
this.tempToken += this.curChar;
this.tokenQueue.push(this.tempToken);
this.tempToken = '';
}이 함수는 단순히 반복되는 연산을 처리하기 위한 함수이다. util함수중에 return이 없는 함수는 만들때도 의존성이 강할까봐 항상 조심스럽다.
그리고 상태를 변경하는 로직은 class 밖에서 접근하면 안되니까 private method로 만들어주는게 좋다. 그런데 js에서 private method를 어떻게 만들어야할지는 아직 모르겠다!
1뎁스로 구현하기 끝!
7. 마무리하며
- 왜 의존성이 없는 함수를 만들 수 있었을까?
설계가 잘 나오니까 내부에 조건을 검사하는 함수는 의존성이 아예없는 완전히 모듈로 빼버릴수 있는 함수가 되었고, 코드가 내 기대보다 훨씬 예뻐졌다. 생각해보면 그 이유는 설계에 확신을 가졌기때문이다. 함수의 역할이 명확해졌기 때문이다.
- 설계를 하는 시간을 지금처럼 오래 해야하나? , 처음에는 왜 이런 설계를 못했지?
확실히 좋은 설계를 하면 코드짜는데 정말 얼마 안걸린다. 2뎁스를 1뎁스로 하는데 걸리는 시간은 로직을 생각하는데는 한시간정도 걸린것같은데 구현은 기존의 코드 위치만 바꿔주는거라 1분밖에 안걸렸다.
근데 생각해보면 어느정도 삽질하고, 그러다 구현도 해봤고 쉬다가 다시 설계를 했던거라 완전 설계만 했던것같지는 않다. 다음번에는 빠르게 의도를 가지고 작게 설계하고, 구현해보고 좀 쉬고, 그 후에 전체를 설계해보려고 한다. (todo앱의 undo,redo도 6-3의 tokenizer 설계하는데 한 2,3일은 걸린것같다.. )
8. 참고문서
9. 추가할것
코드스쿼드의 진생님(JIN)은 beforeHasQuote를 맨처음에 if문으로 전역에서 검사해버리고, (마치 순차실행처럼?)
그 이후에 메인로직의 흐름제어가 일어나는식으로 해서 하나의 조건을 흐름제어에서 빼버리는식으로 코드가 구현되어있는데 이것이 무슨논리고 어떻게 가능한것인지 공부해보려고한다.

좋은글 고마워요~