오늘 뭘 했니?
-
랜덤포레스트(분류)를 이용하여 타이타닉 데이터를 예측하여 캐글에 제출
실습파일: 0704-titanic-ensemble-input
- 랜덤포레스트(회귀)를 이용하여 자전거 공유 수요 예측하여 캐글에 제출
실습파일 : 0705-bike-sharing-demand-input
뭘 배웠니?(new)
배깅 (Bagging)
배깅 이란?
- bootstrap aggregating의 약자로 부트스트랩을 통해 조금씩 다른 훈련 데이터에 대해 훈련된 기초 분류기들을 결합시키는 방법
- 배깅은 서로 다른 데이터셋들에 대해 훈련시킴으로써 트리들을 비상관화 시켜주는 과정

부트스트랩
- 주어진 훈련 데이터에서 중복을 허용하여 원 데이터셋과 같은 크기의 데이터셋을 만드는 과정
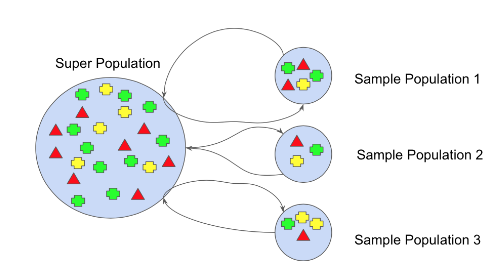
- 트리들의 편향은 유지하면서 분산은 감소시키기 때문에 포레스트의 성능을 향상
- 트리들이 서로 상관화(correlated)되어 있지 않다면 여러 트리들의 평균은 노이즈에 대해 강인
- 여러개의 트리를 만들 수 있기 때문에 오버피팅이 덜 일어날 수 있음
Bagging 훈련과정
- 부트스트랩 방법을 통해 T개의 훈련 데이터셋을 생성 - 부트스트랩
- T개의 기초 분류기(트리)들을 훈련
- 기초 분류기(트리)들을 하나의 분류기(랜던 포레스트)로 집계(평균 또는 과반수투표 방식 이용) - 집계(aggregating)
앙상블 방법(Ensemble Machine Learning Approach)
- 앙상블은 개선된 분류기를 생성하기 위해 일련의 저성능 분류기를 결합한 복합 모델
- 여기서 과반수 투표를 수행하는 개별 분류기 투표 및 최종 예측 레이블이 반환
- 배깅 접근법을 사용하여 분산을 줄이고, 부스팅 접근법을 사용하여 편향을 사용 또는 스태킹 접근법으로 예측 계선
랜덤 포레스트
- 분류 회귀 에 사용되는 앙상블 학습 방법의 일종 (cart)
- 주요 파라미터
- n_estimators : 트리의 수
- criterion: 가지의 분할의 품질을 측정하는 기능입니다.
- max_depth: 트리의 최대 깊이입니다.
- min_samples_split:내부 노드를 분할하는 데 필요한 최소 샘플 수입니다.
- min_samples_leaf: 리프 노드에 있어야 하는 최소 샘플 수입니다.
- max_leaf_nodes: 리프 노드 숫자의 제한치입니다.
- random_state: 추정기의 무작위성을 제어합니다. 실행했을 때 같은 결과가 나오도록 합니다.
랜덤 포레스트 - 위키백과, 우리 모두의 백과사전 (wikipedia.org)
회귀의 평가 방법
MAE
MSE
RMSE
RMSLE(Root Mean Squared Logarithmic Error)
- log 는 1보다 작은 값에서 마이너스 무한대로 수렴. 이를 방지하기 위해 로그를 취하기 전에 1을 더함
하이퍼파라미터 튜닝 복습
from sklearn.model_selection import RandomizedSearchCV
param_distributions = {"n_estimators" : np.random.randint(3,100,10),
"max_depth" : np.random.randint(100,1000,10)}
clf = RandomizedSearchCV(model, param_distributions=param_distributions,
n_iter=5, cv=5, n_jobs=-1, verbose=2, random_state=42)
clf.fit(X_train, y_train)bestestimator
bestscore
cvresults
→데이터 프레임으로 : pd.DataFrame(clf.cvresults)
-
순서대로 나누어 주어야하는 데이터 : 시계열이 있는경우..
-
cross_validate 걸린시간과 스코어
-
cross_val_predict
-
분류와 회귀는 scoring 하는 방법이 다르다
부족한 것
# 학습(훈련)에 사용할 데이터셋 예) 시험의 기출문제
X_train = df.loc[df["count"].notnull(),feature_names]
X_train.shape
# 예측 데이터셋, 예) 실전 시험 문제
X_test = df.loc[df["count"].isnull(), feature_names]
X_test.shape
# 학습(훈련)에 사용할 정답값 예) 기출문제의 정답
Y_train = df.loc[df["count"].notnull(),label_name]
Y_train.shape
#df.loc[조건,열]- cross_validate 걸린시간과 스코어
- cross_val_predict 점수만줭
- cross_val_score
3F
사실(Fact) : 랜덤포레스트(분류)를 이용하여 타이타닉 데이터를 예측, 랜 덤포레스트(회귀)를 이용하여 자전거 공유 수요 예측하여 캐글에 제출했다. 이 과정에서 배깅과 부트스트랩의 개념에 대해 알아보았다.
느낌(Feeling) : 수학적 개념이 나올수록 정신이 안드로메다로 가는중이다. 개념이 차곡차곡 쌓여야 하는데 막 들어오니 정신이 하나도 없다.
교훈(Finding) : 수학…… Aㅏ.. 자기전에 유튜브 좀 들어야겠다

데린이여요